 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Domain Invariant Representation Learning with Domain Density Transformations
Feb 14, 2021
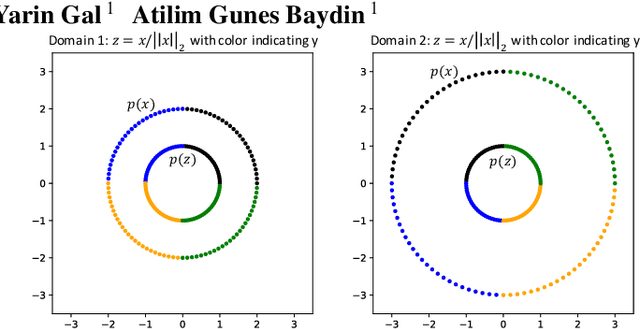
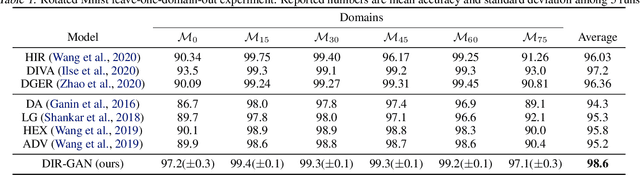
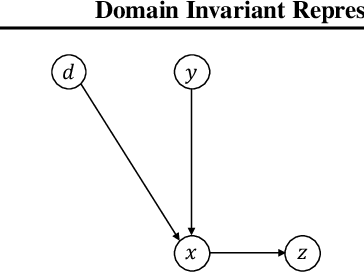
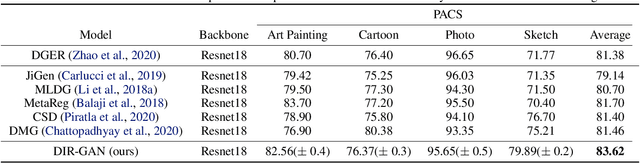
Domain generalization refers to the problem where we aim to train a model on data from a set of source domains so that the model can generalize to unseen target domains. Naively training a model on the aggregate set of data (pooled from all source domains) has been shown to perform suboptimally, since the information learned by that model might be domain-specific and generalize imperfectly to target domains. To tackle this problem, a predominant approach is to find and learn some domain-invariant information in order to use it for the prediction task. In this paper, we propose a theoretically grounded method to learn a domain-invariant representation by enforcing the representation network to be invariant under all transformation functions among domains. We also show how to use generative adversarial networks to learn such domain transformations to implement our method in practice. We demonstrate the effectiveness of our method on several widely used datasets for the domain generalization problem, on all of which we achieve competitive results with state-of-the-art models.
FoveaTer: Foveated Transformer for Image Classification
May 29, 2021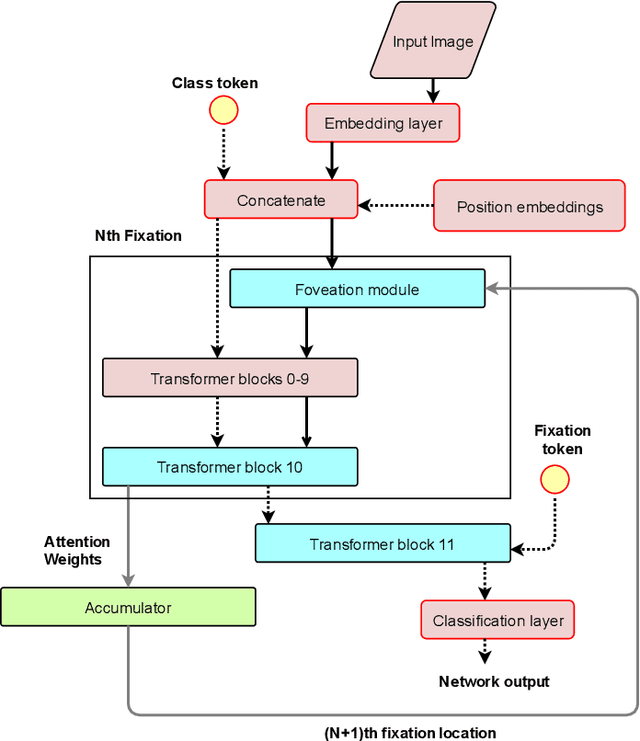
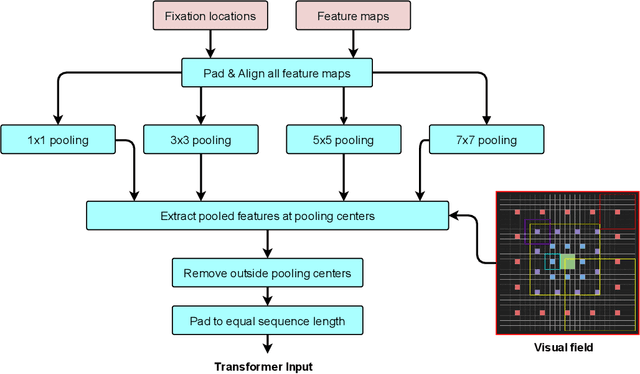
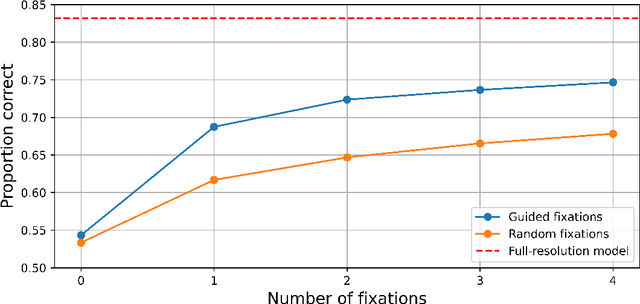
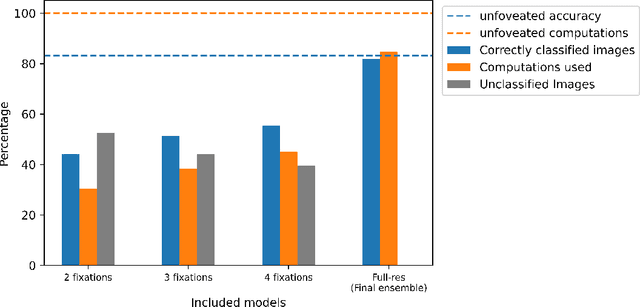
Many animals and humans process the visual field with a varying spatial resolution (foveated vision) and use peripheral processing to make eye movements and point the fovea to acquire high-resolution information about objects of interest. This architecture results in computationally efficient rapid scene exploration. Recent progress in vision Transformers has brought about new alternatives to the traditionally convolution-reliant computer vision systems. However, these models do not explicitly model the foveated properties of the visual system nor the interaction between eye movements and the classification task. We propose foveated Transformer (FoveaTer) model, which uses pooling regions and saccadic movements to perform object classification tasks using a vision Transformer architecture. Our proposed model pools the image features using squared pooling regions, an approximation to the biologically-inspired foveated architecture, and uses the pooled features as an input to a Transformer Network. It decides on the following fixation location based on the attention assigned by the Transformer to various locations from previous and present fixations. The model uses a confidence threshold to stop scene exploration, allowing to dynamically allocate more fixation/computational resources to more challenging images. We construct an ensemble model using our proposed model and unfoveated model, achieving an accuracy 1.36% below the unfoveated model with 22% computational savings. Finally, we demonstrate our model's robustness against adversarial attacks, where it outperforms the unfoveated model.
Aggregated Network for Massive MIMO CSI Feedback
Jan 17, 2021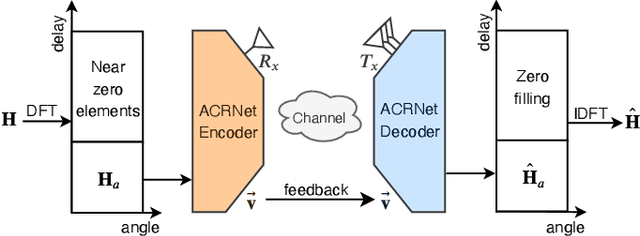
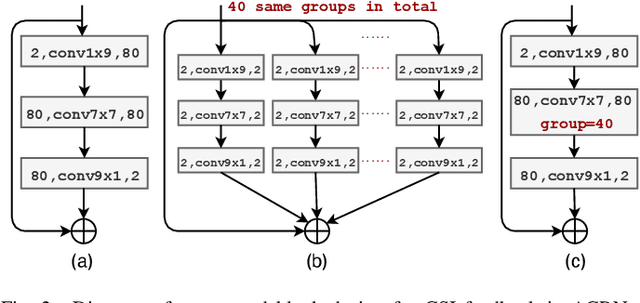
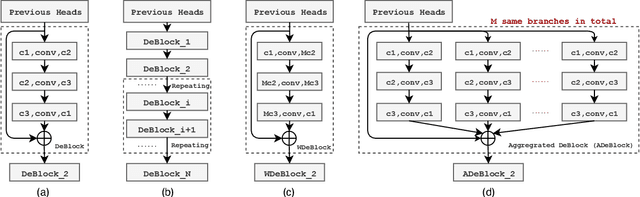
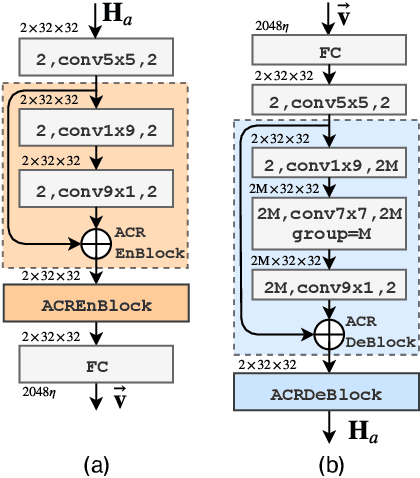
In frequency division duplexing (FDD) mode, it is necessary to send the channel state information (CSI) from user equipment to base station. The downlink CSI is essential for the massive multiple-input multiple-output (MIMO) system to acquire the potential gain. Recently, deep learning is widely adopted to massive MIMO CSI feedback task and proved to be effective compared with traditional compressed sensing methods. In this paper, a novel network named ACRNet is designed to boost the feedback performance with network aggregation and parametric RuLU activation. Moreover, valid approach to expand the network architecture in exchange of better performance is first discussed in CSI feedback task. Experiments show that ACRNet outperforms loads of previous state-of-the-art feedback networks without any extra information.
Emerging Properties in Self-Supervised Vision Transformers
Apr 29, 2021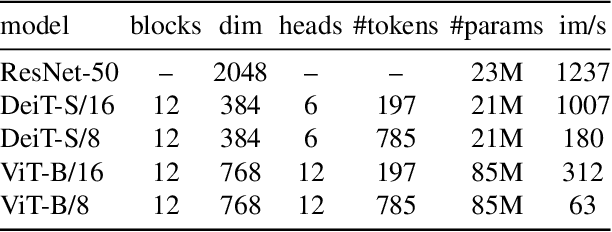
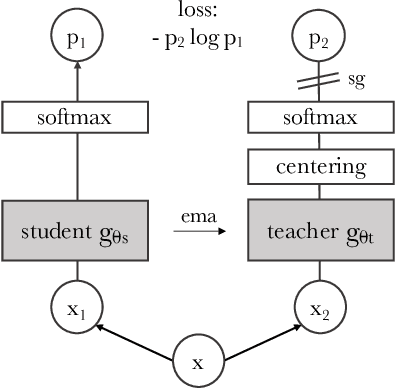
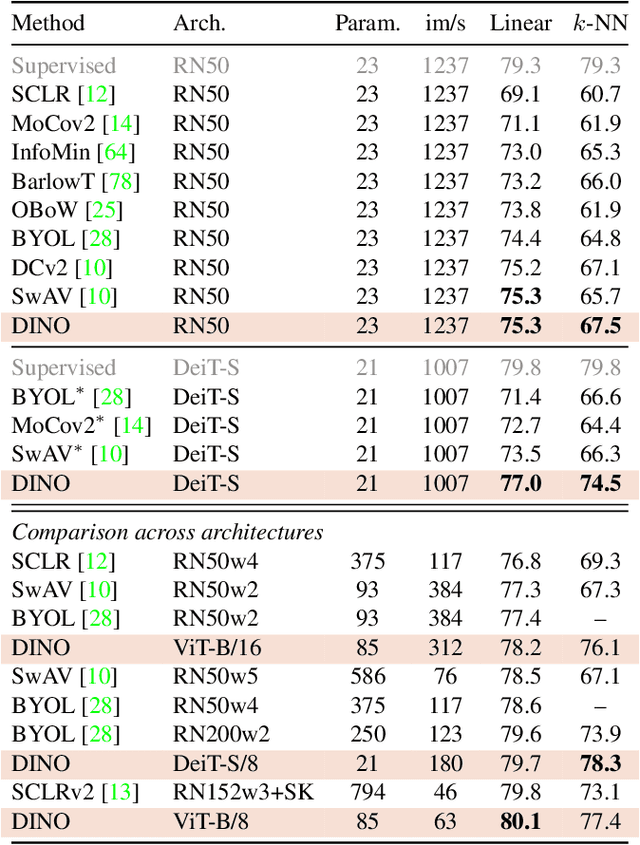
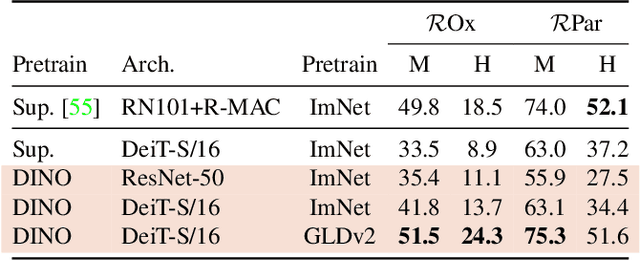
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works particularly well, we make the following observations: first, self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets. Second, these features are also excellent k-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder, multi-crop training, and the use of small patches with ViTs. We implement our findings into a simple self-supervised method, called DINO, which we interpret as a form of self-distillation with no labels. We show the synergy between DINO and ViTs by achieving 80.1% top-1 on ImageNet in linear evaluation with ViT-Base.
e-ACJ: Accurate Junction Extraction For Event Cameras
Jan 27, 2021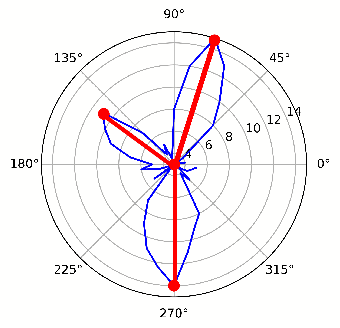
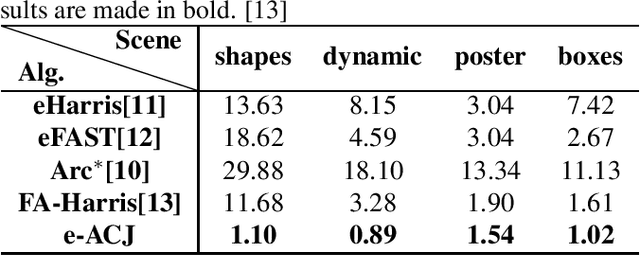

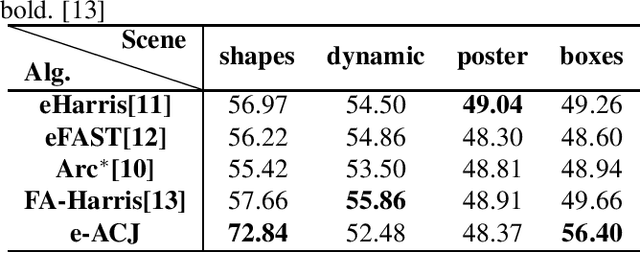
Junctions reflect the important geometrical structure information of the image, and are of primary significance to applications such as image matching and motion analysis. Previous event-based feature extraction methods are mainly focused on corners, which mainly find their locations, however, ignoring the geometrical structure information like orientations and scales of edges. This paper adapts the frame-based a-contrario junction detector(ACJ) to event data, proposing the event-based a-contrario junction detector(e-ACJ), which yields junctions' locations while giving the scales and orientations of their branches. The proposed method relies on an a-contrario model and can operate on asynchronous events directly without generating synthesized event frames. We evaluate the performance on public event datasets. The result shows our method successfully finds the orientations and scales of branches, while maintaining high accuracy in junction's location.
Polynomial magic! Hermite polynomials for private data generation
Jun 09, 2021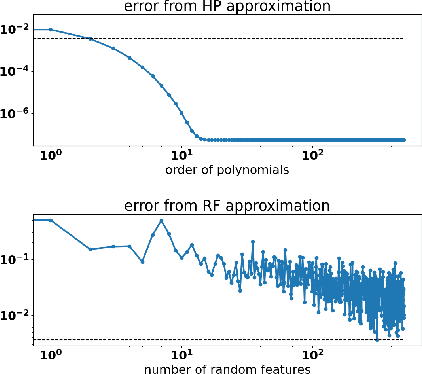

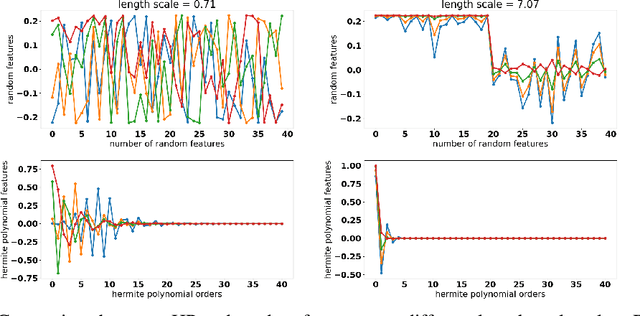
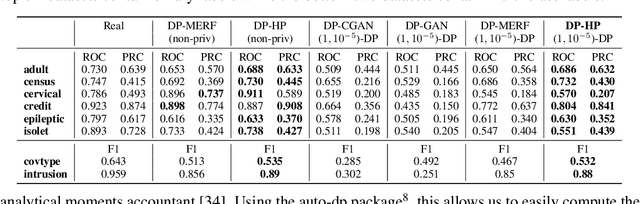
Kernel mean embedding is a useful tool to compare probability measures. Despite its usefulness, kernel mean embedding considers infinite-dimensional features, which are challenging to handle in the context of differentially private data generation. A recent work proposes to approximate the kernel mean embedding of data distribution using finite-dimensional random features, where the sensitivity of the features becomes analytically tractable. More importantly, this approach significantly reduces the privacy cost, compared to other known privatization methods (e.g., DP-SGD), as the approximate kernel mean embedding of the data distribution is privatized only once and can then be repeatedly used during training of a generator without incurring any further privacy cost. However, the required number of random features is excessively high, often ten thousand to a hundred thousand, which worsens the sensitivity of the approximate kernel mean embedding. To improve the sensitivity, we propose to replace random features with Hermite polynomial features. Unlike the random features, the Hermite polynomial features are ordered, where the features at the low orders contain more information on the distribution than those at the high orders. Hence, a relatively low order of Hermite polynomial features can more accurately approximate the mean embedding of the data distribution compared to a significantly higher number of random features. As a result, using the Hermite polynomial features, we significantly improve the privacy-accuracy trade-off, reflected in the high quality and diversity of the generated data, when tested on several heterogeneous tabular datasets, as well as several image benchmark datasets.
Inclusion of Domain-Knowledge into GNNs using Mode-Directed Inverse Entailment
May 22, 2021

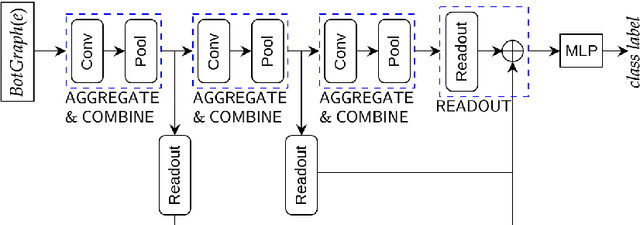
We present a general technique for constructing Graph Neural Networks (GNNs) capable of using multi-relational domain knowledge. The technique is based on mode-directed inverse entailment (MDIE) developed in Inductive Logic Programming (ILP). Given a data instance $e$ and background knowledge $B$, MDIE identifies a most-specific logical formula $\bot_B(e)$ that contains all the relational information in $B$ that is related to $e$. We transform $\bot_B(e)$ into a corresponding "bottom-graph" that can be processed for use by standard GNN implementations. This transformation allows a principled way of incorporating generic background knowledge into GNNs: we use the term `BotGNN' for this form of graph neural networks. For several GNN variants, using real-world datasets with substantial background knowledge, we show that BotGNNs perform significantly better than both GNNs without background knowledge and a recently proposed simplified technique for including domain knowledge into GNNs. We also provide experimental evidence comparing BotGNNs favourably to multi-layer perceptrons (MLPs) that use features representing a "propositionalised" form of the background knowledge; and BotGNNs to a standard ILP based on the use of most-specific clauses. Taken together, these results point to BotGNNs as capable of combining the computational efficacy of GNNs with the representational versatility of ILP.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
May 07, 2021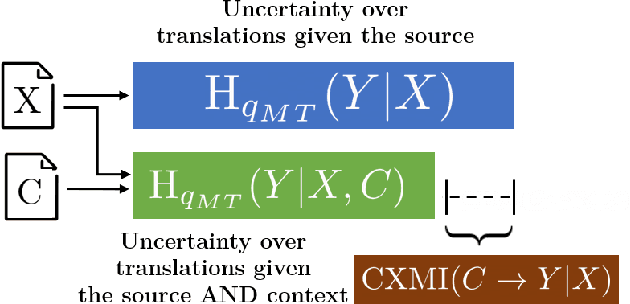

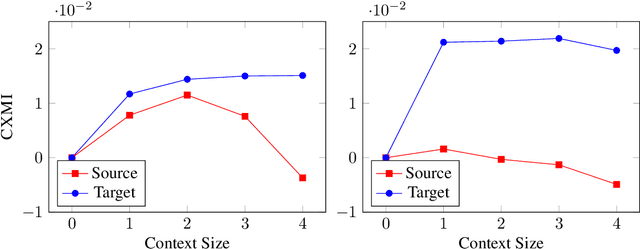
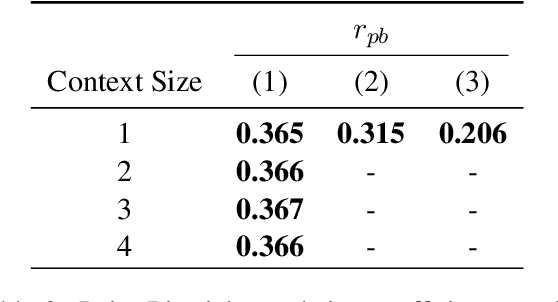
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
MILP-based Imitation Learning for HVAC control
Dec 01, 2020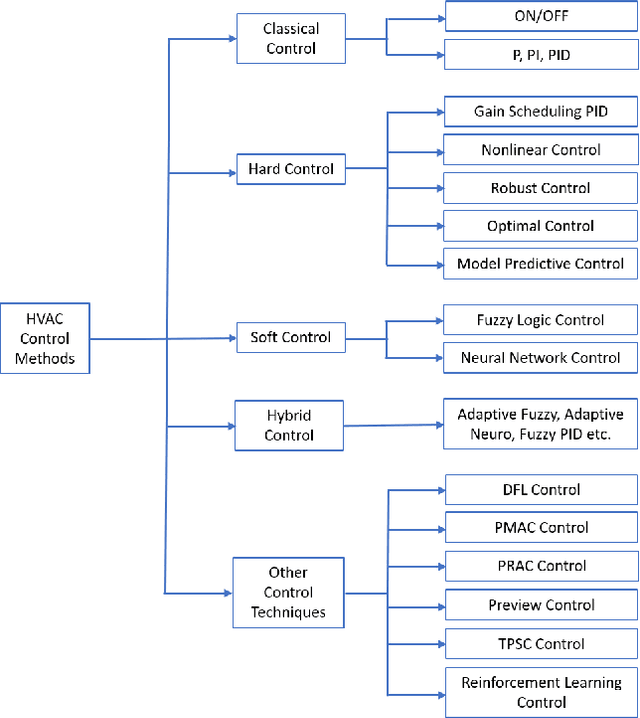
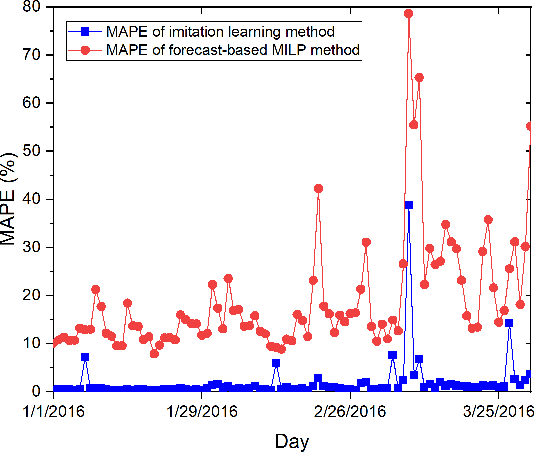
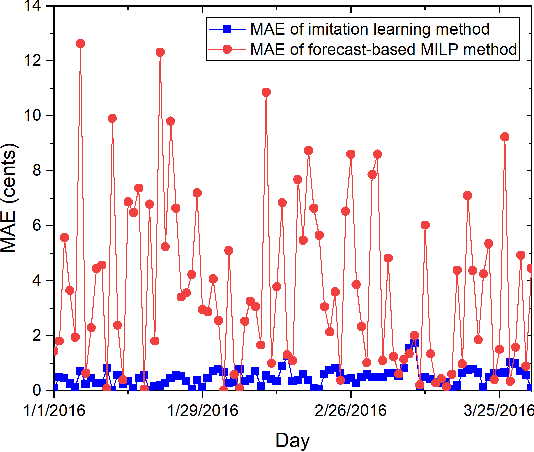
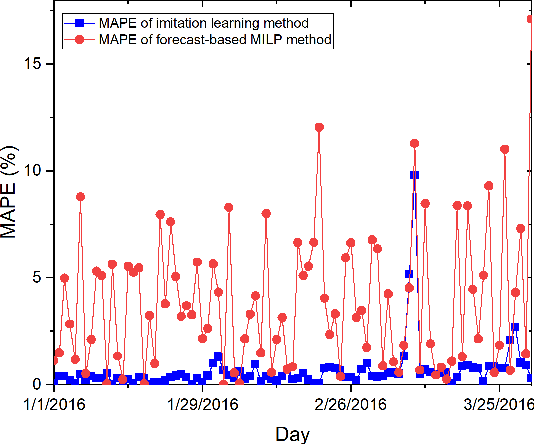
To optimize the operation of a HVAC system with advanced techniques such as artificial neural network, previous studies usually need forecast information in their method. However, the forecast information inevitably contains errors all the time, which degrade the performance of the HVAC operation. Hence, in this study, we propose MILP-based imitation learning method to control a HVAC system without using the forecast information in order to reduce energy cost and maintain thermal comfort at a given level. Our proposed controller is a deep neural network (DNN) trained by using data labeled by a MILP solver with historical data. After training, our controller is used to control the HVAC system with real-time data. For comparison, we also develop a second method named forecast-based MILP which control the HVAC system using the forecast information. The performance of the two methods is verified by using real outdoor temperatures and real day-ahead prices in Detroit city, Michigan, United States. Numerical results clearly show that the performance of the MILP-based imitation learning is better than that of the forecast-based MILP method in terms of hourly power consumption, daily energy cost, and thermal comfort. Moreover, the difference between results of the MILP-based imitation learning method and optimal results is almost negligible. These optimal results are achieved only by using the MILP solver at the end of a day when we have full information on the weather and prices for the day.
An Analysis of Indexing and Querying Strategies on a Technologically Assisted Review Task
Apr 20, 2021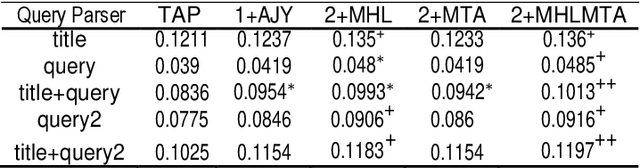
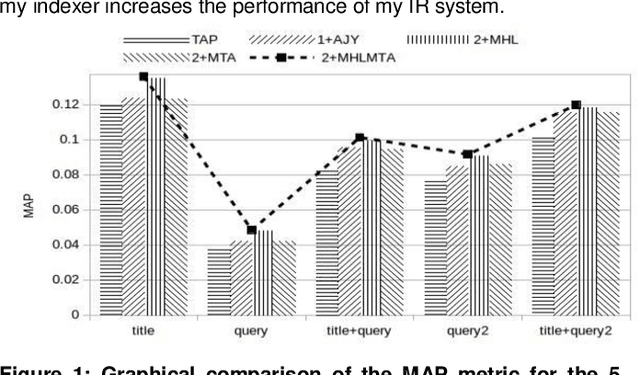
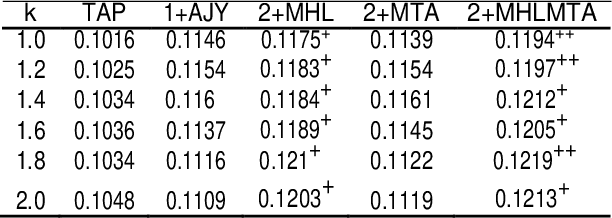
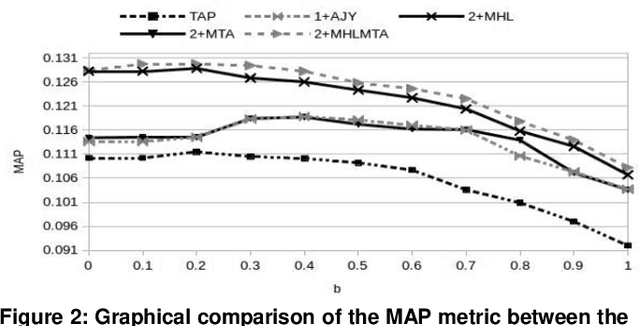
This paper presents a preliminary experimentation study using the CLEF 2017 eHealth Task 2 collection for evaluating the effectiveness of different indexing methodologies of documents and query parsing techniques. Furthermore, it is an attempt to advance and share the efforts of observing the characteristics and helpfulness of various methodologies for indexing PubMed documents and for different topic parsing techniques to produce queries. For this purpose, my research includes experimentation with different document indexing methodologies, by utilising existing tools, such as the Lucene4IR (L4IR) information retrieval system, the Technology Assisted Reviews for Empirical Medicine tool for parsing topics of the CLEF collection and the TREC evaluation tool to appraise system's performance. The results showed that including a greater number of fields to the PubMed indexer of L4IR is a decisive factor for the retrieval effectiveness of L4IR.