 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recognition of handwritten MNIST digits on low-memory 2 Kb RAM Arduino board using LogNNet reservoir neural network
Apr 20, 2021
The presented compact algorithm for recognizing handwritten digits of the MNIST database, created on the LogNNet reservoir neural network, reaches the recognition accuracy of 82%. The algorithm was tested on a low-memory Arduino board with 2 Kb static RAM low-power microcontroller. The dependences of the accuracy and time of image recognition on the number of neurons in the reservoir have been investigated. The memory allocation demonstrates that the algorithm stores all the necessary information in RAM without using additional data storage, and operates with original images without preliminary processing. The simple structure of the algorithm, with appropriate training, can be adapted for wide practical application, for example, for creating mobile biosensors for early diagnosis of adverse events in medicine. The study results are important for the implementation of artificial intelligence on peripheral constrained IoT devices and for edge computing.
SketchGen: Generating Constrained CAD Sketches
Jun 04, 2021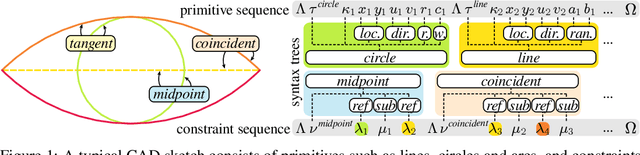

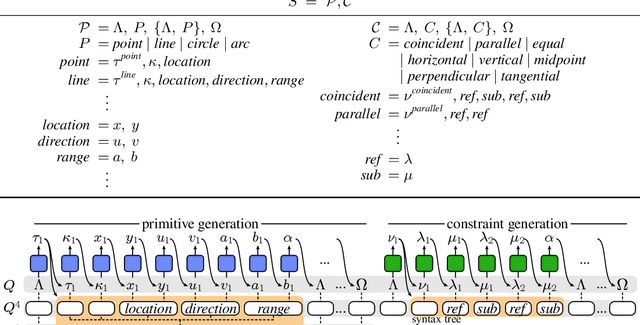
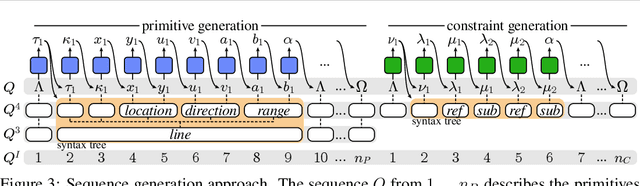
Computer-aided design (CAD) is the most widely used modeling approach for technical design. The typical starting point in these designs is 2D sketches which can later be extruded and combined to obtain complex three-dimensional assemblies. Such sketches are typically composed of parametric primitives, such as points, lines, and circular arcs, augmented with geometric constraints linking the primitives, such as coincidence, parallelism, or orthogonality. Sketches can be represented as graphs, with the primitives as nodes and the constraints as edges. Training a model to automatically generate CAD sketches can enable several novel workflows, but is challenging due to the complexity of the graphs and the heterogeneity of the primitives and constraints. In particular, each type of primitive and constraint may require a record of different size and parameter types. We propose SketchGen as a generative model based on a transformer architecture to address the heterogeneity problem by carefully designing a sequential language for the primitives and constraints that allows distinguishing between different primitive or constraint types and their parameters, while encouraging our model to re-use information across related parameters, encoding shared structure. A particular highlight of our work is the ability to produce primitives linked via constraints that enables the final output to be further regularized via a constraint solver. We evaluate our model by demonstrating constraint prediction for given sets of primitives and full sketch generation from scratch, showing that our approach significantly out performs the state-of-the-art in CAD sketch generation.
Demographic-Guided Attention in Recurrent Neural Networks for Modeling Neuropathophysiological Heterogeneity
Apr 15, 2021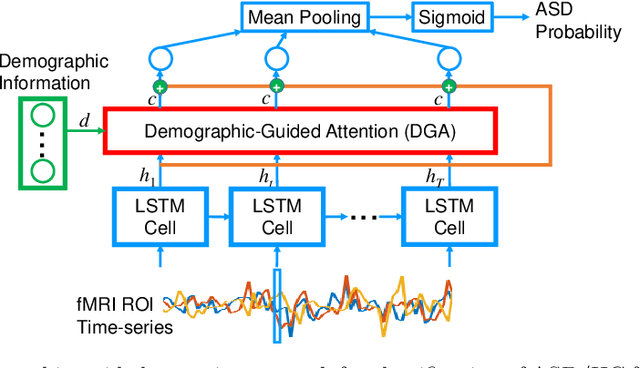
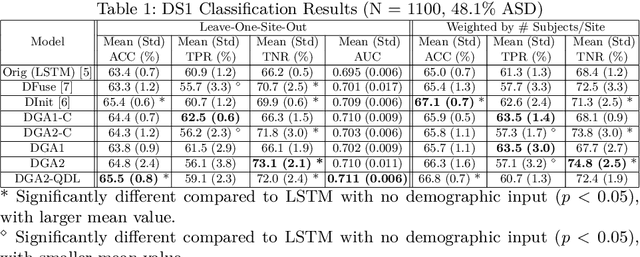
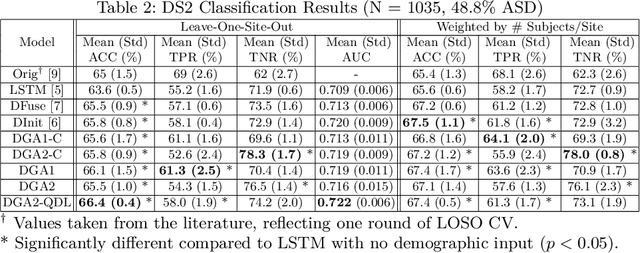
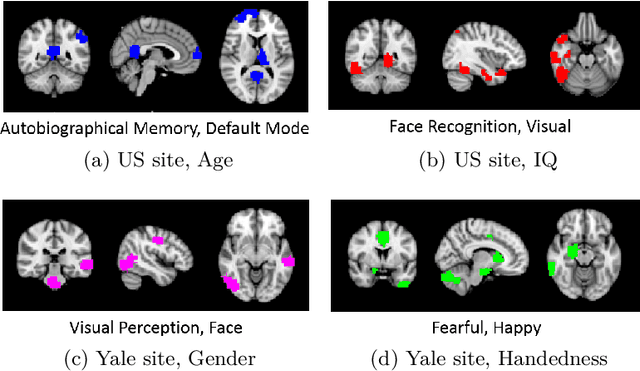
Heterogeneous presentation of a neurological disorder suggests potential differences in the underlying pathophysiological changes that occur in the brain. We propose to model heterogeneous patterns of functional network differences using a demographic-guided attention (DGA) mechanism for recurrent neural network models for prediction from functional magnetic resonance imaging (fMRI) time-series data. The context computed from the DGA head is used to help focus on the appropriate functional networks based on individual demographic information. We demonstrate improved classification on 3 subsets of the ABIDE I dataset used in published studies that have previously produced state-of-the-art results, evaluating performance under a leave-one-site-out cross-validation framework for better generalizeability to new data. Finally, we provide examples of interpreting functional network differences based on individual demographic variables.
Model-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021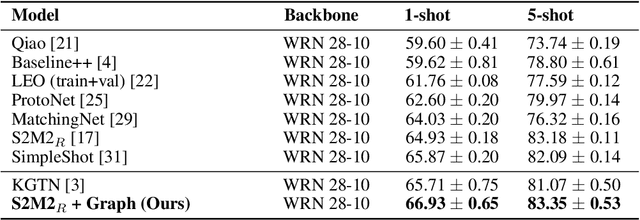
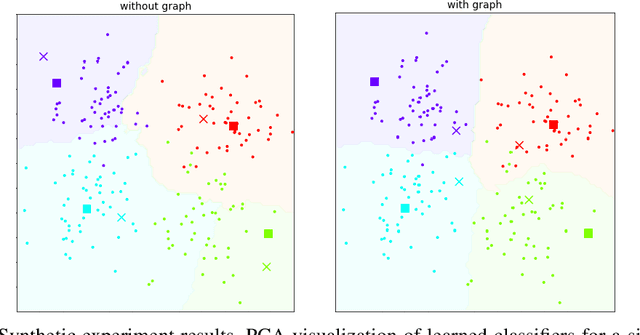
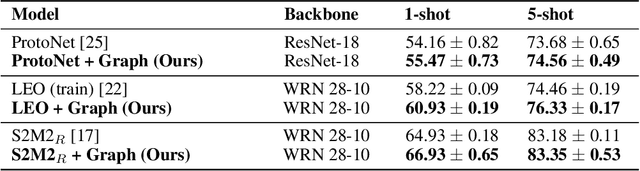
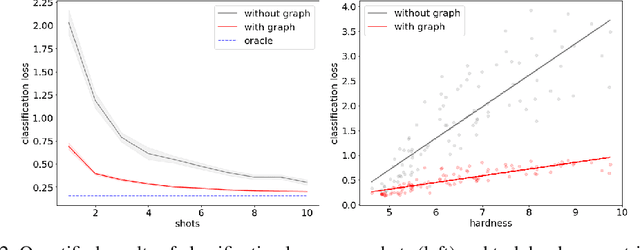
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.
Local Granger Causality
Oct 26, 2020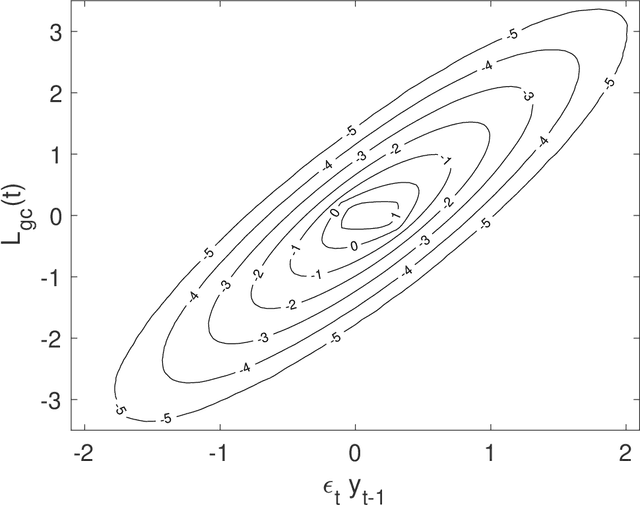
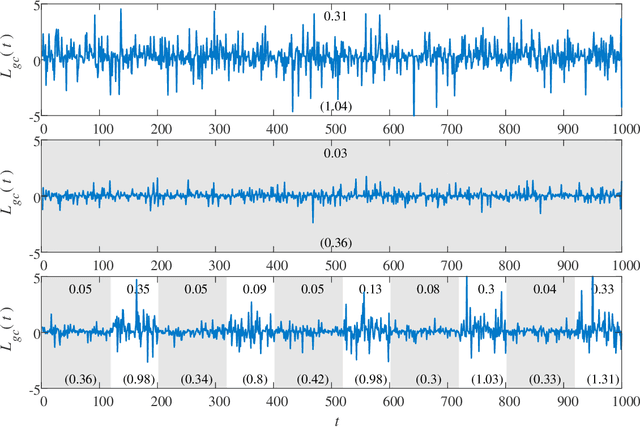
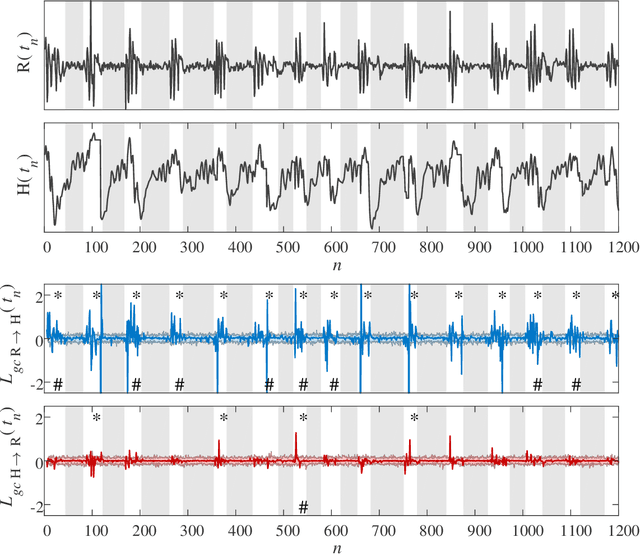
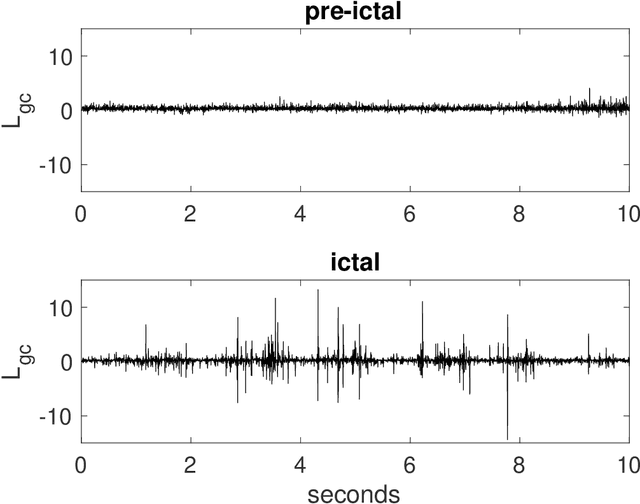
Granger causality is a statistical notion of causal influence based on prediction via vector autoregression. For Gaussian variables it is equivalent to transfer entropy, an information-theoretic measure of time-directed information transfer between jointly dependent processes. We exploit such equivalence and calculate exactly the 'local Granger causality', i.e. the profile of the information transfer at each discrete time point in Gaussian processes; in this frame Granger causality is the average of its local version. Our approach offers a robust and computationally fast method to follow the information transfer along the time history of linear stochastic processes, as well as of nonlinear complex systems studied in the Gaussian approximation.
Natural continual learning: success is a journey, not (just) a destination
Jun 15, 2021
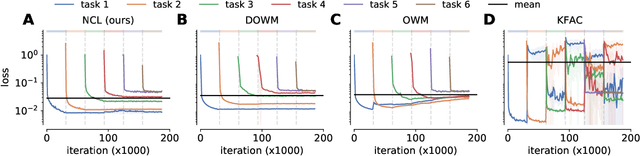
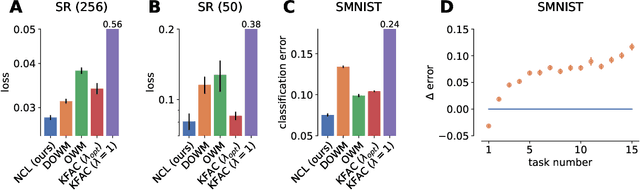
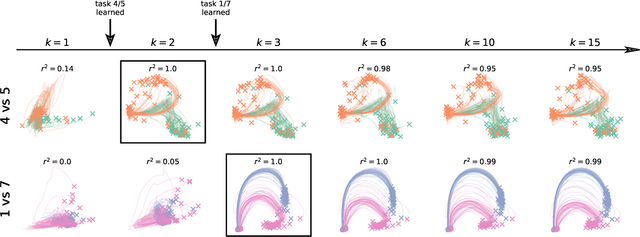
Biological agents are known to learn many different tasks over the course of their lives, and to be able to revisit previous tasks and behaviors with little to no loss in performance. In contrast, artificial agents are prone to 'catastrophic forgetting' whereby performance on previous tasks deteriorates rapidly as new ones are acquired. This shortcoming has recently been addressed using methods that encourage parameters to stay close to those used for previous tasks. This can be done by (i) using specific parameter regularizers that map out suitable destinations in parameter space, or (ii) guiding the optimization journey by projecting gradients into subspaces that do not interfere with previous tasks. However, parameter regularization has been shown to be relatively ineffective in recurrent neural networks (RNNs), a setting relevant to the study of neural dynamics supporting biological continual learning. Similarly, projection based methods can reach capacity and fail to learn any further as the number of tasks increases. To address these limitations, we propose Natural Continual Learning (NCL), a new method that unifies weight regularization and projected gradient descent. NCL uses Bayesian weight regularization to encourage good performance on all tasks at convergence and combines this with gradient projections designed to prevent catastrophic forgetting during optimization. NCL formalizes gradient projection as a trust region algorithm based on the Fisher information metric, and achieves scalability via a novel Kronecker-factored approximation strategy. Our method outperforms both standard weight regularization techniques and projection based approaches when applied to continual learning problems in RNNs. The trained networks evolve task-specific dynamics that are strongly preserved as new tasks are learned, similar to experimental findings in biological circuits.
ManyTypes4Py: A Benchmark Python Dataset for Machine Learning-based Type Inference
Apr 10, 2021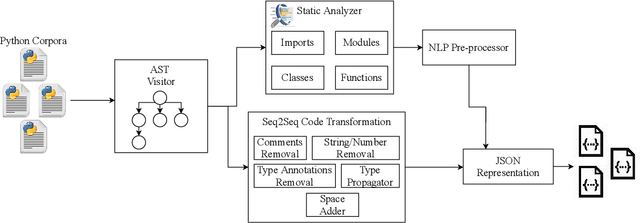
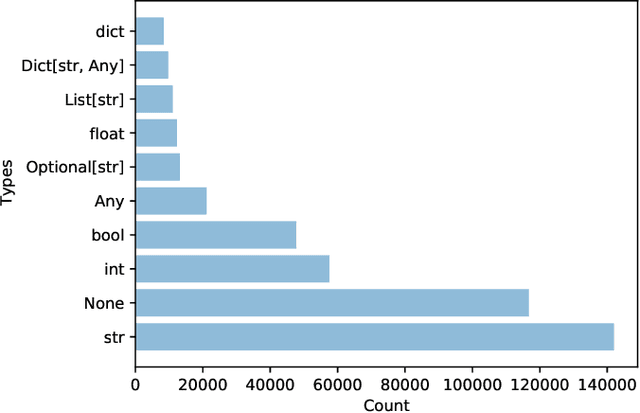

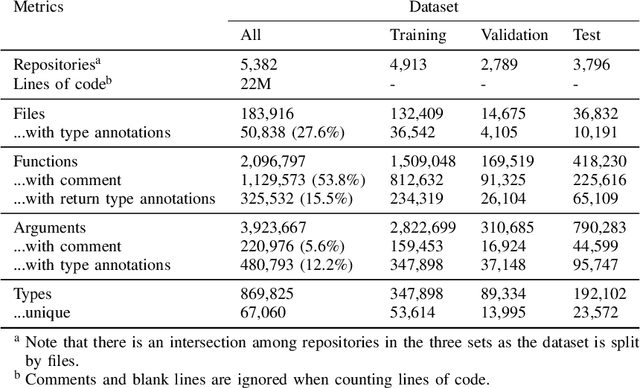
In this paper, we present ManyTypes4Py, a large Python dataset for machine learning (ML)-based type inference. The dataset contains a total of 5,382 Python projects with more than 869K type annotations. Duplicate source code files were removed to eliminate the negative effect of the duplication bias. To facilitate training and evaluation of ML models, the dataset was split into training, validation and test sets by files. To extract type information from abstract syntax trees (ASTs), a lightweight static analyzer pipeline is developed and accompanied with the dataset. Using this pipeline, the collected Python projects were analyzed and the results of the AST analysis were stored in JSON-formatted files. The ManyTypes4Py dataset is shared on zenodo and its tools are publicly available on GitHub.
A Spectral-Spatial-Dependent Global Learning Framework for Insufficient and Imbalanced Hyperspectral Image Classification
May 29, 2021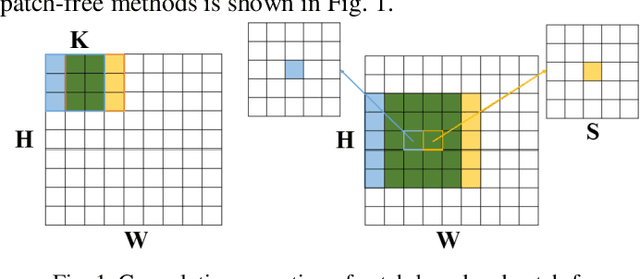
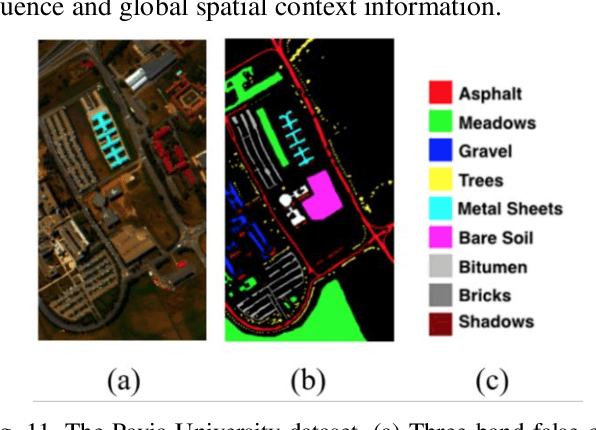

Deep learning techniques have been widely applied to hyperspectral image (HSI) classification and have achieved great success. However, the deep neural network model has a large parameter space and requires a large number of labeled data. Deep learning methods for HSI classification usually follow a patchwise learning framework. Recently, a fast patch-free global learning (FPGA) architecture was proposed for HSI classification according to global spatial context information. However, FPGA has difficulty extracting the most discriminative features when the sample data is imbalanced. In this paper, a spectral-spatial dependent global learning (SSDGL) framework based on global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) is proposed for insufficient and imbalanced HSI classification. In SSDGL, the hierarchically balanced (H-B) sampling strategy and the weighted softmax loss are proposed to address the imbalanced sample problem. To effectively distinguish similar spectral characteristics of land cover types, the GCL module is introduced to extract the long short-term dependency of spectral features. To learn the most discriminative feature representations, the GJAM module is proposed to extract attention areas. The experimental results obtained with three public HSI datasets show that the SSDGL has powerful performance in insufficient and imbalanced sample problems and is superior to other state-of-the-art methods. Code can be obtained at: https://github.com/dengweihuan/SSDGL.
Attention-based Information Fusion using Multi-Encoder-Decoder Recurrent Neural Networks
Nov 13, 2017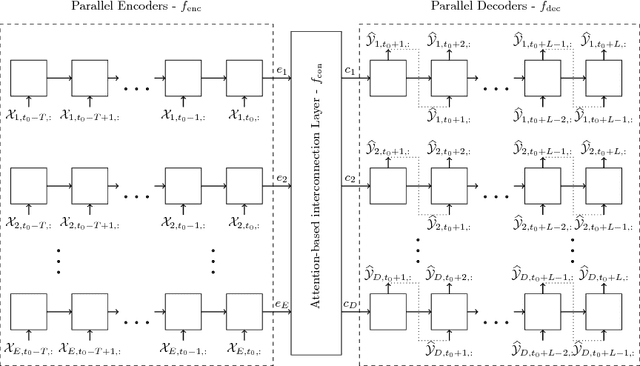
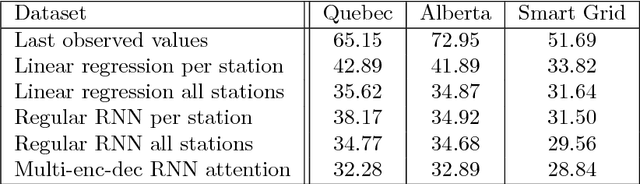
With the rising number of interconnected devices and sensors, modeling distributed sensor networks is of increasing interest. Recurrent neural networks (RNN) are considered particularly well suited for modeling sensory and streaming data. When predicting future behavior, incorporating information from neighboring sensor stations is often beneficial. We propose a new RNN based architecture for context specific information fusion across multiple spatially distributed sensor stations. Hereby, latent representations of multiple local models, each modeling one sensor station, are jointed and weighted, according to their importance for the prediction. The particular importance is assessed depending on the current context using a separate attention function. We demonstrate the effectiveness of our model on three different real-world sensor network datasets.
Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding
Jun 04, 2021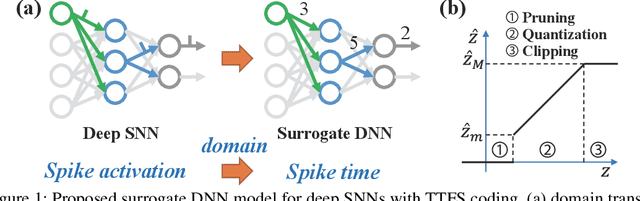
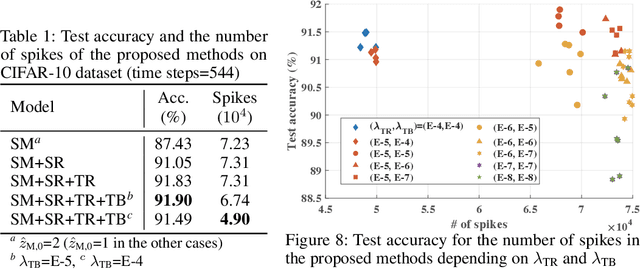
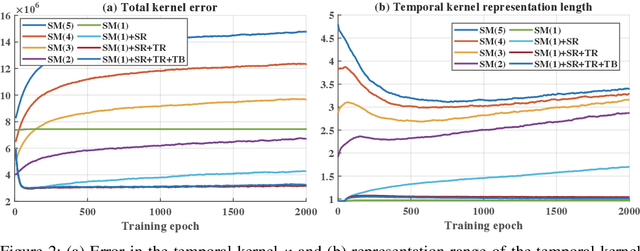
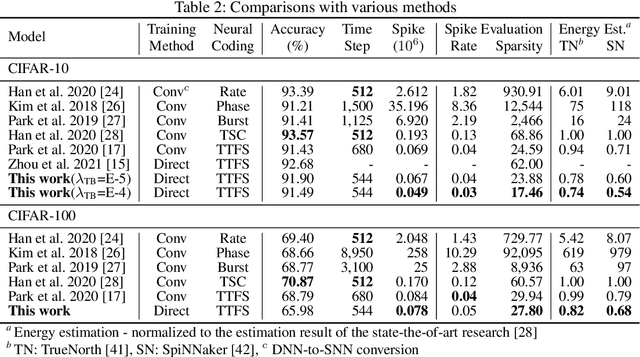
The tremendous energy consumption of deep neural networks (DNNs) has become a serious problem in deep learning. Spiking neural networks (SNNs), which mimic the operations in the human brain, have been studied as prominent energy-efficient neural networks. Due to their event-driven and spatiotemporally sparse operations, SNNs show possibilities for energy-efficient processing. To unlock their potential, deep SNNs have adopted temporal coding such as time-to-first-spike (TTFS)coding, which represents the information between neurons by the first spike time. With TTFS coding, each neuron generates one spike at most, which leads to a significant improvement in energy efficiency. Several studies have successfully introduced TTFS coding in deep SNNs, but they showed restricted efficiency improvement owing to the lack of consideration for efficiency during training. To address the aforementioned issue, this paper presents training methods for energy-efficient deep SNNs with TTFS coding. We introduce a surrogate DNN model to train the deep SNN in a feasible time and analyze the effect of the temporal kernel on training performance and efficiency. Based on the investigation, we propose stochastically relaxed activation and initial value-based regularization for the temporal kernel parameters. In addition, to reduce the number of spikes even further, we present temporal kernel-aware batch normalization. With the proposed methods, we could achieve comparable training results with significantly reduced spikes, which could lead to energy-efficient deep SNNs.