 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-Shot Electronic Health Record Coding through Graph Contrastive Learning
Jun 29, 2021
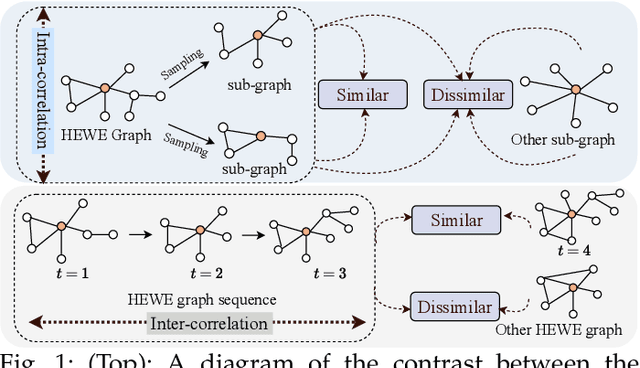
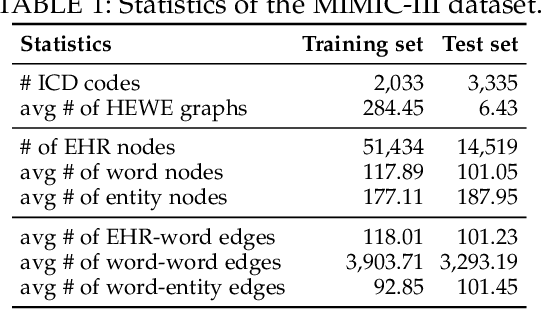
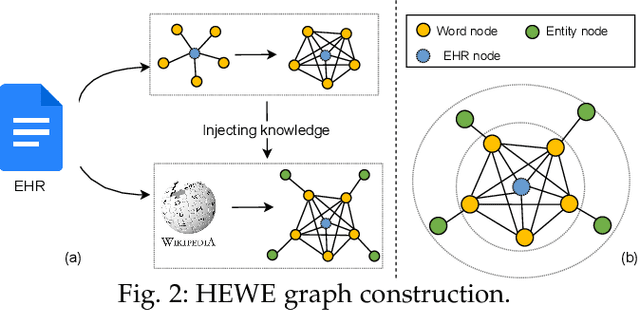
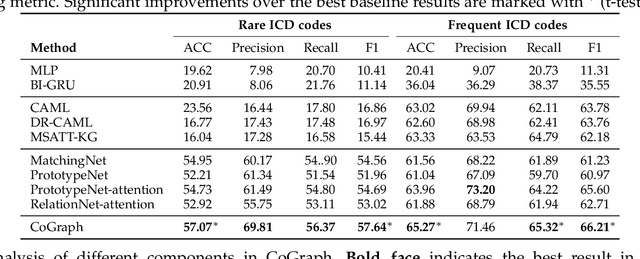
Electronic health record (EHR) coding is the task of assigning ICD codes to each EHR. Most previous studies either only focus on the frequent ICD codes or treat rare and frequent ICD codes in the same way. These methods perform well on frequent ICD codes but due to the extremely unbalanced distribution of ICD codes, the performance on rare ones is far from satisfactory. We seek to improve the performance for both frequent and rare ICD codes by using a contrastive graph-based EHR coding framework, CoGraph, which re-casts EHR coding as a few-shot learning task. First, we construct a heterogeneous EHR word-entity (HEWE) graph for each EHR, where the words and entities extracted from an EHR serve as nodes and the relations between them serve as edges. Then, CoGraph learns similarities and dissimilarities between HEWE graphs from different ICD codes so that information can be transferred among them. In a few-shot learning scenario, the model only has access to frequent ICD codes during training, which might force it to encode features that are useful for frequent ICD codes only. To mitigate this risk, CoGraph devises two graph contrastive learning schemes, GSCL and GECL, that exploit the HEWE graph structures so as to encode transferable features. GSCL utilizes the intra-correlation of different sub-graphs sampled from HEWE graphs while GECL exploits the inter-correlation among HEWE graphs at different clinical stages. Experiments on the MIMIC-III benchmark dataset show that CoGraph significantly outperforms state-of-the-art methods on EHR coding, not only on frequent ICD codes, but also on rare codes, in terms of several evaluation indicators. On frequent ICD codes, GSCL and GECL improve the classification accuracy and F1 by 1.31% and 0.61%, respectively, and on rare ICD codes CoGraph has more obvious improvements by 2.12% and 2.95%.
Detection of preventable fetal distress during labor from scanned cardiotocogram tracings using deep learning
Jun 01, 2021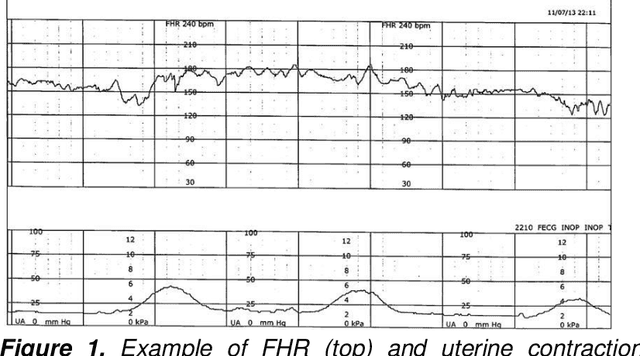
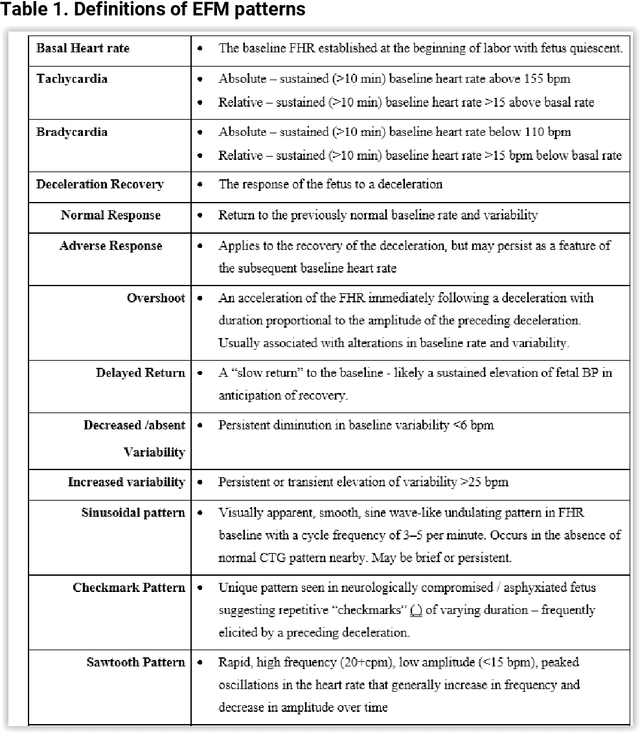
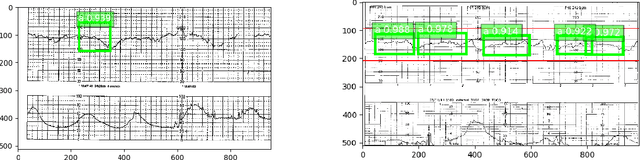
Despite broad application during labor and delivery, there remains considerable debate about the value of electronic fetal monitoring (EFM). EFM includes the surveillance of the fetal heart rate (FHR) patterns in conjunction with the maternal uterine contractions providing a wealth of data about fetal behavior and the threat of diminished oxygenation and perfusion. Adverse outcomes universally associate a fetal injury with the failure to timely respond to FHR pattern information. Historically, the EFM data, stored digitally, are available only as rasterized pdf images for contemporary or historical discussion and examination. In reality, however, they are rarely reviewed systematically. Using a unique archive of EFM collected over 50 years of practice in conjunction with adverse outcomes, we present a deep learning framework for training and detection of incipient or past fetal injury. We report 94% accuracy in identifying early, preventable fetal injury intrapartum. This framework is suited for automating an early warning and decision support system for maintaining fetal well-being during the stresses of labor. Ultimately, such a system could enable a physician to timely respond during labor and prevent adverse outcomes. When adverse outcomes cannot be avoided, they can provide guidance to the early neuroprotective treatment of the newborn.
Uncertainty Measurement of Basic Probability Assignment Integrity Based on Approximate Entropy in Evidence Theory
May 18, 2021
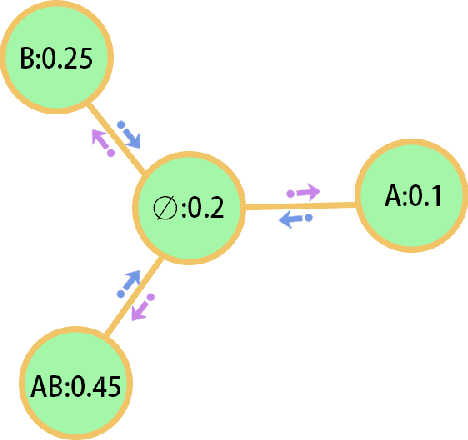
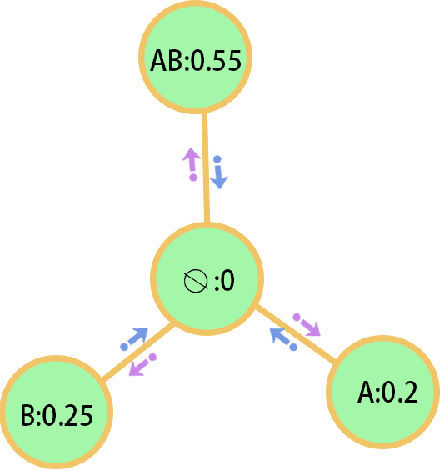
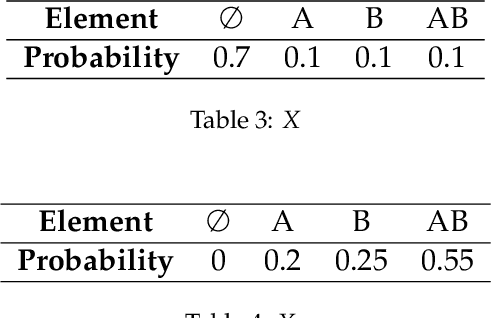
Evidence theory is that the extension of probability can better deal with unknowns and inaccurate information. Uncertainty measurement plays a vital role in both evidence theory and probability theory. Approximate Entropy (ApEn) is proposed by Pincus to describe the irregularities of complex systems. The more irregular the time series, the greater the approximate entropy. The ApEn of the network represents the ability of a network to generate new nodes, or the possibility of undiscovered nodes. Through the association of network characteristics and basic probability assignment (BPA) , a measure of the uncertainty of BPA regarding completeness can be obtained. The main contribution of paper is to define the integrity of the basic probability assignment then the approximate entropy of the BPA is proposed to measure the uncertainty of the integrity of the BPA. The proposed method is based on the logical network structure to calculate the uncertainty of BPA in evidence theory. The uncertainty based on the proposed method represents the uncertainty of integrity of BPA and contributes to the identification of the credibility of BPA.
Intentonomy: a Dataset and Study towards Human Intent Understanding
Nov 11, 2020

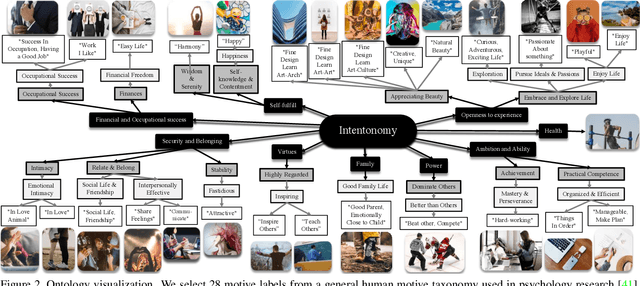
An image is worth a thousand words, conveying information that goes beyond the mere visual content therein. In this paper, we study the intent behind social media images with an aim to analyze how visual information can facilitate recognition of human intent. Towards this goal, we introduce an intent dataset, Intentonomy, comprising 14K images covering a wide range of everyday scenes. These images are manually annotated with 28 intent categories derived from a social psychology taxonomy. We then systematically study whether, and to what extent, commonly used visual information, i.e., object and context, contribute to human motive understanding. Based on our findings, we conduct further study to quantify the effect of attending to object and context classes as well as textual information in the form of hashtags when training an intent classifier. Our results quantitatively and qualitatively shed light on how visual and textual information can produce observable effects when predicting intent.
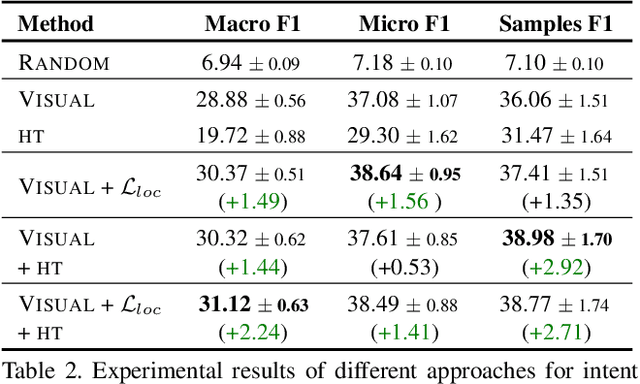
Learning for Detecting Norm Violation in Online Communities
Apr 30, 2021

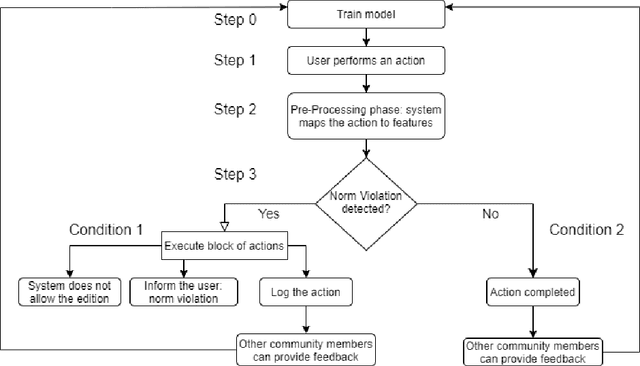
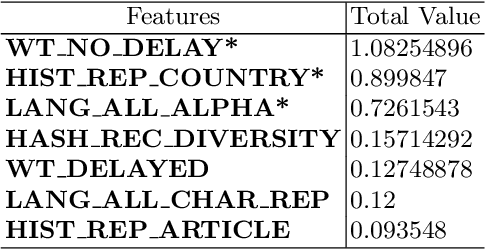
In this paper, we focus on normative systems for online communities. The paper addresses the issue that arises when different community members interpret these norms in different ways, possibly leading to unexpected behavior in interactions, usually with norm violations that affect the individual and community experiences. To address this issue, we propose a framework capable of detecting norm violations and providing the violator with information about the features of their action that makes this action violate a norm. We build our framework using Machine Learning, with Logistic Model Trees as the classification algorithm. Since norm violations can be highly contextual, we train our model using data from the Wikipedia online community, namely data on Wikipedia edits. Our work is then evaluated with the Wikipedia use case where we focus on the norm that prohibits vandalism in Wikipedia edits.
gComm: An environment for investigating generalization in Grounded Language Acquisition
May 09, 2021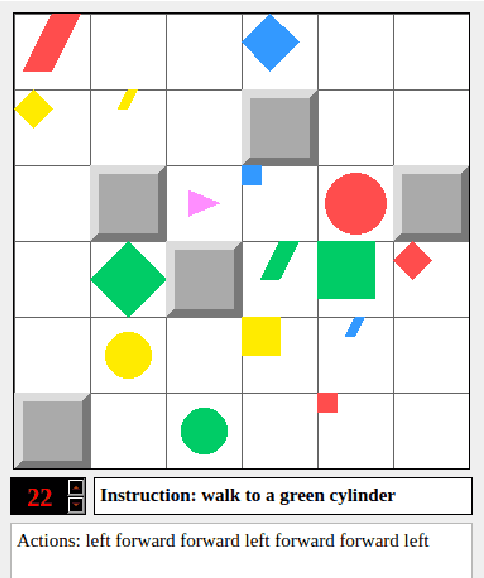
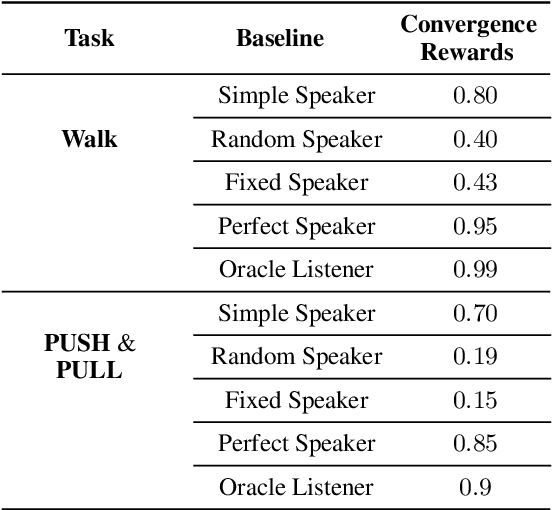
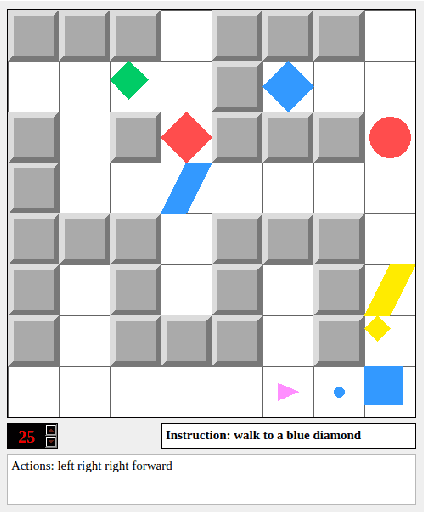
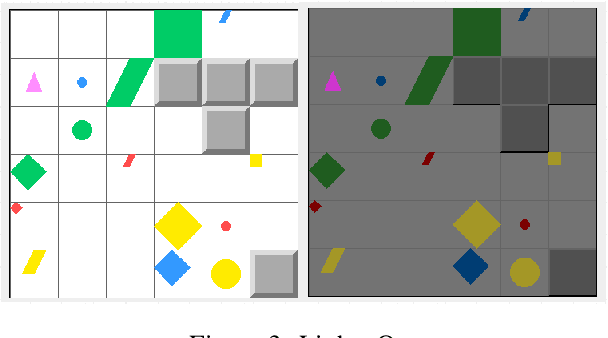
gComm is a step towards developing a robust platform to foster research in grounded language acquisition in a more challenging and realistic setting. It comprises a 2-d grid environment with a set of agents (a stationary speaker and a mobile listener connected via a communication channel) exposed to a continuous array of tasks in a partially observable setting. The key to solving these tasks lies in agents developing linguistic abilities and utilizing them for efficiently exploring the environment. The speaker and listener have access to information provided in different modalities, i.e. the speaker's input is a natural language instruction that contains the target and task specifications and the listener's input is its grid-view. Each must rely on the other to complete the assigned task, however, the only way they can achieve the same, is to develop and use some form of communication. gComm provides several tools for studying different forms of communication and assessing their generalization.
Granular conditional entropy-based attribute reduction for partially labeled data with proxy labels
Jan 23, 2021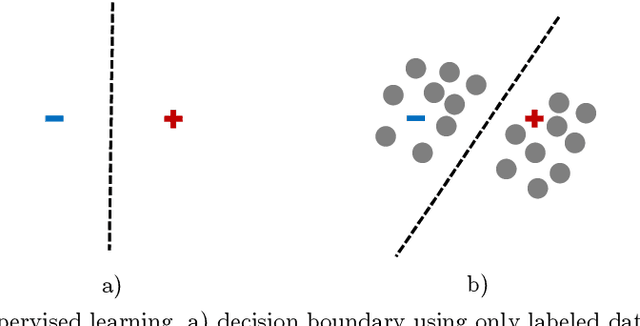
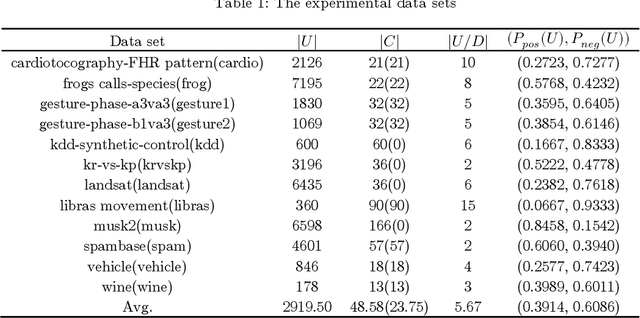
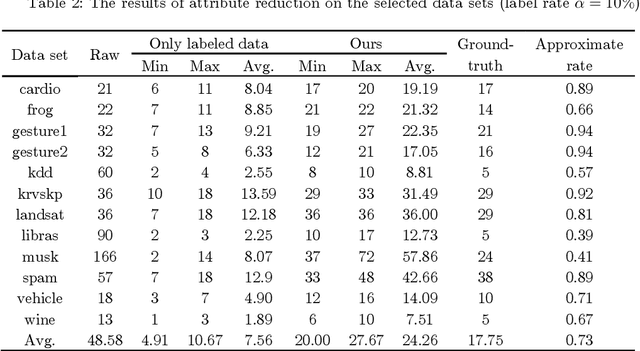
Attribute reduction is one of the most important research topics in the theory of rough sets, and many rough sets-based attribute reduction methods have thus been presented. However, most of them are specifically designed for dealing with either labeled data or unlabeled data, while many real-world applications come in the form of partial supervision. In this paper, we propose a rough sets-based semi-supervised attribute reduction method for partially labeled data. Particularly, with the aid of prior class distribution information about data, we first develop a simple yet effective strategy to produce the proxy labels for unlabeled data. Then the concept of information granularity is integrated into the information-theoretic measure, based on which, a novel granular conditional entropy measure is proposed, and its monotonicity is proved in theory. Furthermore, a fast heuristic algorithm is provided to generate the optimal reduct of partially labeled data, which could accelerate the process of attribute reduction by removing irrelevant examples and excluding redundant attributes simultaneously. Extensive experiments conducted on UCI data sets demonstrate that the proposed semi-supervised attribute reduction method is promising and even compares favourably with the supervised methods on labeled data and unlabeled data with true labels in terms of classification performance.
Dense Regression Activation Maps For Lesion Segmentation in CT scans of COVID-19 patients
May 25, 2021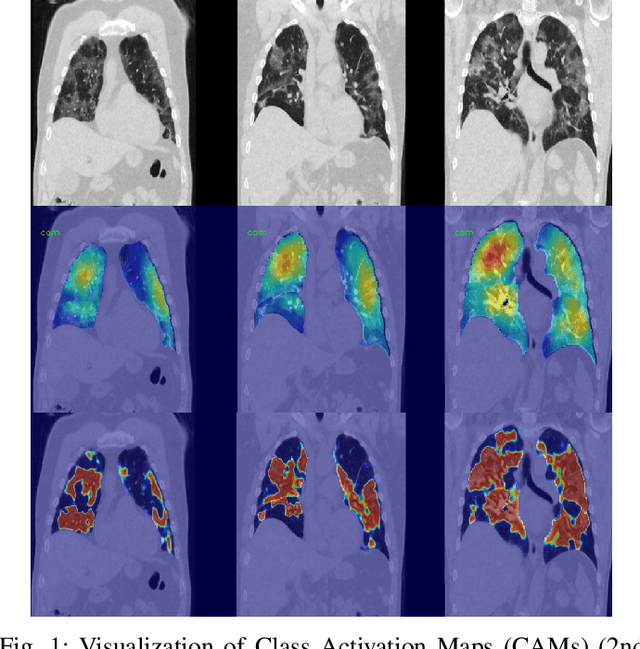
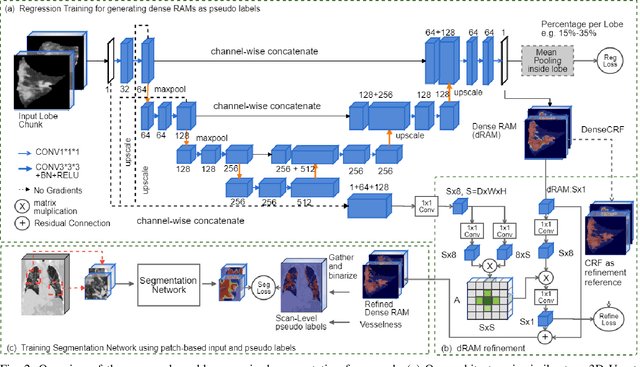

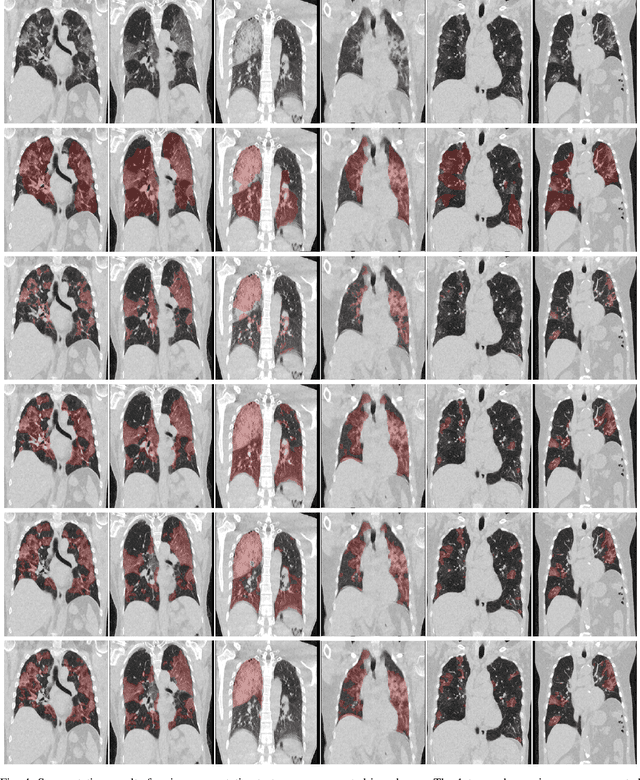
Automatic lesion segmentation on thoracic CT enables rapid quantitative analysis of lung involvement in COVID- 19 infections. Obtaining voxel-level annotations for training segmentation networks is prohibitively expensive. Therefore we propose a weakly-supervised segmentation method based on dense regression activation maps (dRAM). Most advanced weakly supervised segmentation approaches exploit class activation maps (CAMs) to localize objects generated from high-level semantic features at a coarse resolution. As a result, CAMs provide coarse outlines that do not align precisely with the object segmentations. Instead, we exploit dense features from a segmentation network to compute dense regression activation maps (dRAMs) for preserving local details. During training, dRAMs are pooled lobe-wise to regress the per-lobe lesion percentage. In such a way, the network achieves additional information regarding the lesion quantification in comparison with the classification approach. Furthermore, we refine dRAMs based on an attention module and dense conditional random field trained together with the main regression task. The refined dRAMs are served as the pseudo labels for training a final segmentation network. When evaluated on 69 CT scans, our method substantially improves the intersection over union from 0.335 in the CAM-based weakly supervised segmentation method to 0.495.
Understanding and Improvement of Adversarial Training for Network Embedding from an Optimization Perspective
May 17, 2021



Network Embedding aims to learn a function mapping the nodes to Euclidean space contribute to multiple learning analysis tasks on networks. However, the noisy information behind the real-world networks and the overfitting problem both negatively impact the quality of embedding vectors. To tackle these problems, researchers utilize Adversarial Training for Network Embedding (AdvTNE) and achieve state-of-the-art performance. Unlike the mainstream methods introducing perturbations on the network structure or the data feature, AdvTNE directly perturbs the model parameters, which provides a new chance to understand the mechanism behind. In this paper, we explain AdvTNE theoretically from an optimization perspective. Considering the Power-law property of networks and the optimization objective, we analyze the reason for its excellent results. According to the above analysis, we propose a new activation to enhance the performance of AdvTNE. We conduct extensive experiments on four real networks to validate the effectiveness of our method in node classification and link prediction. The results demonstrate that our method is superior to the state-of-the-art baseline methods.
There and back again: Cycle consistency across sets for isolating factors of variation
Mar 04, 2021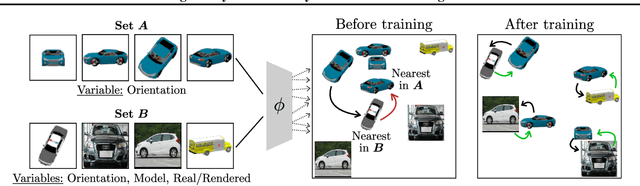



Representational learning hinges on the task of unraveling the set of underlying explanatory factors of variation in data. In this work, we operate in the setting where limited information is known about the data in the form of groupings, or set membership, where the underlying factors of variation is restricted to a subset. Our goal is to learn representations which isolate the factors of variation that are common across the groupings. Our key insight is the use of cycle consistency across sets(CCS) between the learned embeddings of images belonging to different sets. In contrast to other methods utilizing set supervision, CCS can be applied with significantly fewer constraints on the factors of variation, across a remarkably broad range of settings, and only utilizing set membership for some fraction of the training data. By curating datasets from Shapes3D, we quantify the effectiveness of CCS through mutual information between the learned representations and the known generative factors. In addition, we demonstrate the applicability of CCS to the tasks of digit style isolation and synthetic-to-real object pose transfer and compare to generative approaches utilizing the same supervision.