 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021
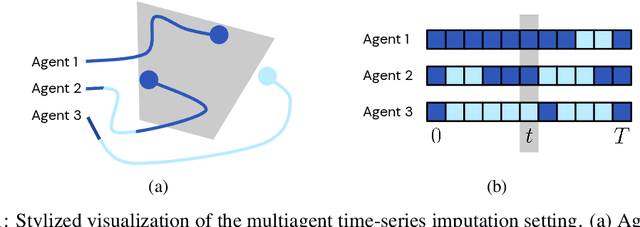
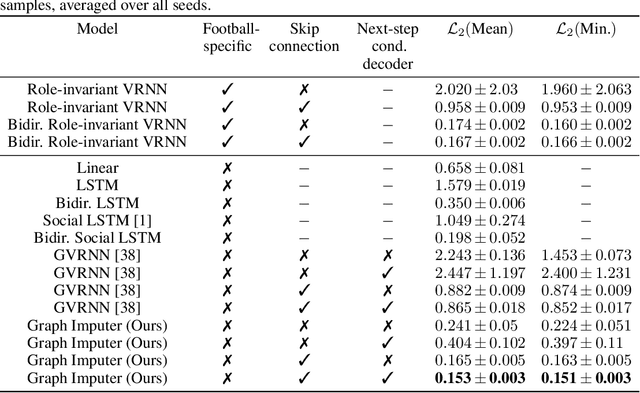
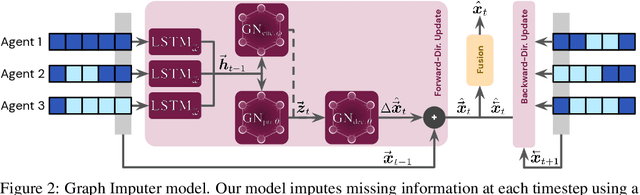
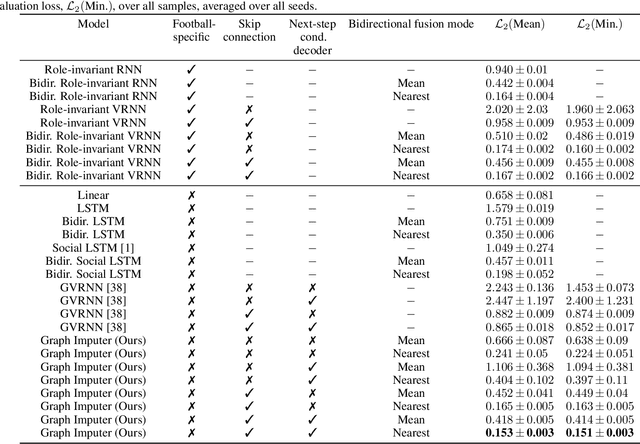
In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
Analyzing Online Political Advertisements
May 09, 2021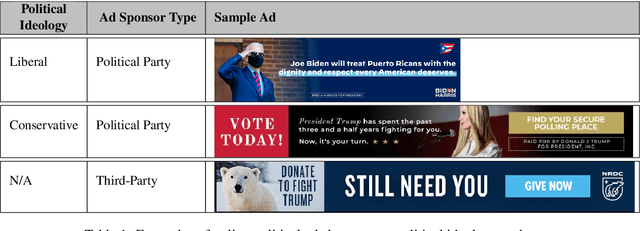


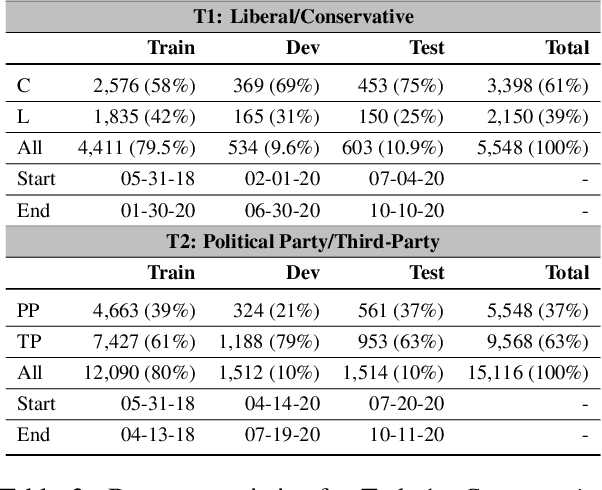
Online political advertising is a central aspect of modern election campaigning for influencing public opinion. Computational analysis of political ads is of utmost importance in political science to understand characteristics of digital campaigning. It is also important in computational linguistics to study features of political discourse and communication on a large scale. In this work, we present the first computational study on online political ads with the aim to (1) infer the political ideology of an ad sponsor; and (2) identify whether the sponsor is an official political party or a third-party organization. We develop two new large datasets for the two tasks consisting of ads from the U.S.. Evaluation results show that our approach that combines textual and visual information from pre-trained neural models outperforms a state-of-the-art method for generic commercial ad classification. Finally, we provide an in-depth analysis of the limitations of our best performing models and a linguistic analysis to study the characteristics of political ads discourse.
Secret Key Agreement with Physical Unclonable Functions: An Optimality Summary
Dec 16, 2020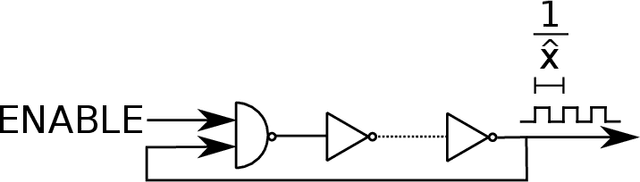


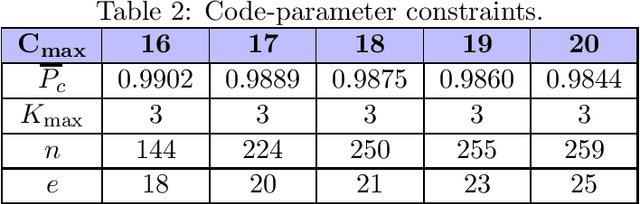
We address security and privacy problems for digital devices and biometrics from an information-theoretic optimality perspective, where a secret key is generated for authentication, identification, message encryption/decryption, or secure computations. A physical unclonable function (PUF) is a promising solution for local security in digital devices and this review gives the most relevant summary for information theorists, coding theorists, and signal processing community members who are interested in optimal PUF constructions. Low-complexity signal processing methods such as transform coding that are developed to make the information-theoretic analysis tractable are discussed. The optimal trade-offs between the secret-key, privacy-leakage, and storage rates for multiple PUF measurements are given. Proposed optimal code constructions that jointly design the vector quantizer and error-correction code parameters are listed. These constructions include modern and algebraic codes such as polar codes and convolutional codes, both of which can achieve small block-error probabilities at short block lengths, corresponding to a small number of PUF circuits. Open problems in the PUF literature from a signal processing, information theory, coding theory, and hardware complexity perspectives and their combinations are listed to stimulate further advancements in the research on local privacy and security.
AMR Parsing with Action-Pointer Transformer
May 18, 2021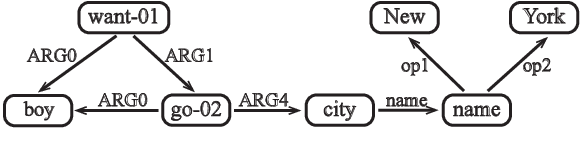
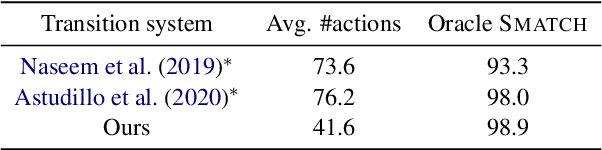

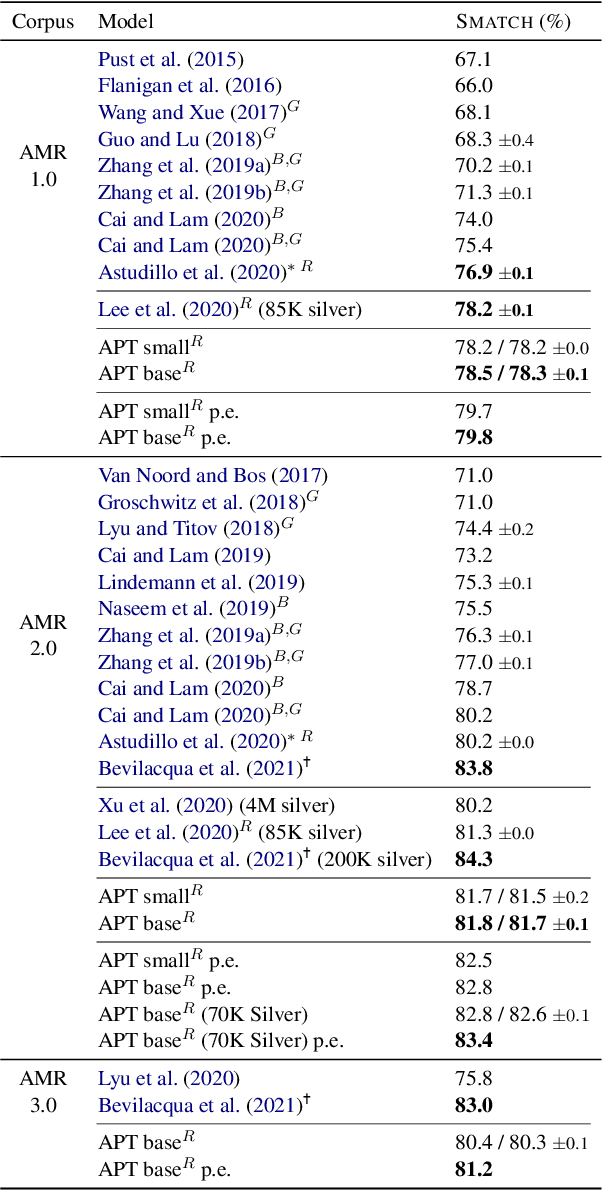
Abstract Meaning Representation parsing is a sentence-to-graph prediction task where target nodes are not explicitly aligned to sentence tokens. However, since graph nodes are semantically based on one or more sentence tokens, implicit alignments can be derived. Transition-based parsers operate over the sentence from left to right, capturing this inductive bias via alignments at the cost of limited expressiveness. In this work, we propose a transition-based system that combines hard-attention over sentences with a target-side action pointer mechanism to decouple source tokens from node representations and address alignments. We model the transitions as well as the pointer mechanism through straightforward modifications within a single Transformer architecture. Parser state and graph structure information are efficiently encoded using attention heads. We show that our action-pointer approach leads to increased expressiveness and attains large gains (+1.6 points) against the best transition-based AMR parser in very similar conditions. While using no graph re-categorization, our single model yields the second best Smatch score on AMR 2.0 (81.8), which is further improved to 83.4 with silver data and ensemble decoding.
Structure-Aware Face Clustering on a Large-Scale Graph with $\bf{10^{7}}$ Nodes
Mar 27, 2021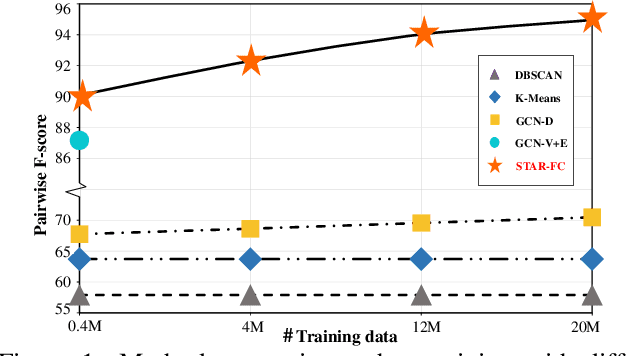

Face clustering is a promising method for annotating unlabeled face images. Recent supervised approaches have boosted the face clustering accuracy greatly, however their performance is still far from satisfactory. These methods can be roughly divided into global-based and local-based ones. Global-based methods suffer from the limitation of training data scale, while local-based ones are difficult to grasp the whole graph structure information and usually take a long time for inference. Previous approaches fail to tackle these two challenges simultaneously. To address the dilemma of large-scale training and efficient inference, we propose the STructure-AwaRe Face Clustering (STAR-FC) method. Specifically, we design a structure-preserved subgraph sampling strategy to explore the power of large-scale training data, which can increase the training data scale from ${10^{5}}$ to ${10^{7}}$. During inference, the STAR-FC performs efficient full-graph clustering with two steps: graph parsing and graph refinement. And the concept of node intimacy is introduced in the second step to mine the local structural information. The STAR-FC gets 91.97 pairwise F-score on partial MS1M within 310s which surpasses the state-of-the-arts. Furthermore, we are the first to train on very large-scale graph with 20M nodes, and achieve superior inference results on 12M testing data. Overall, as a simple and effective method, the proposed STAR-FC provides a strong baseline for large-scale face clustering. Code is available at \url{https://sstzal.github.io/STAR-FC/}.
Examining and Combating Spurious Features under Distribution Shift
Jun 14, 2021

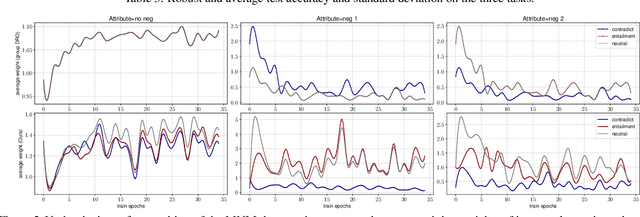
A central goal of machine learning is to learn robust representations that capture the causal relationship between inputs features and output labels. However, minimizing empirical risk over finite or biased datasets often results in models latching on to spurious correlations between the training input/output pairs that are not fundamental to the problem at hand. In this paper, we define and analyze robust and spurious representations using the information-theoretic concept of minimal sufficient statistics. We prove that even when there is only bias of the input distribution (i.e. covariate shift), models can still pick up spurious features from their training data. Group distributionally robust optimization (DRO) provides an effective tool to alleviate covariate shift by minimizing the worst-case training loss over a set of pre-defined groups. Inspired by our analysis, we demonstrate that group DRO can fail when groups do not directly account for various spurious correlations that occur in the data. To address this, we further propose to minimize the worst-case losses over a more flexible set of distributions that are defined on the joint distribution of groups and instances, instead of treating each group as a whole at optimization time. Through extensive experiments on one image and two language tasks, we show that our model is significantly more robust than comparable baselines under various partitions. Our code is available at https://github.com/violet-zct/group-conditional-DRO.
Information Maximizing Exploration with a Latent Dynamics Model
Apr 04, 2018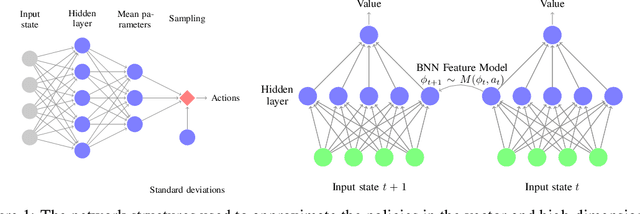


All reinforcement learning algorithms must handle the trade-off between exploration and exploitation. Many state-of-the-art deep reinforcement learning methods use noise in the action selection, such as Gaussian noise in policy gradient methods or $\epsilon$-greedy in Q-learning. While these methods are appealing due to their simplicity, they do not explore the state space in a methodical manner. We present an approach that uses a model to derive reward bonuses as a means of intrinsic motivation to improve model-free reinforcement learning. A key insight of our approach is that this dynamics model can be learned in the latent feature space of a value function, representing the dynamics of the agent and the environment. This method is both theoretically grounded and computationally advantageous, permitting the efficient use of Bayesian information-theoretic methods in high-dimensional state spaces. We evaluate our method on several continuous control tasks, focusing on improving exploration.
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021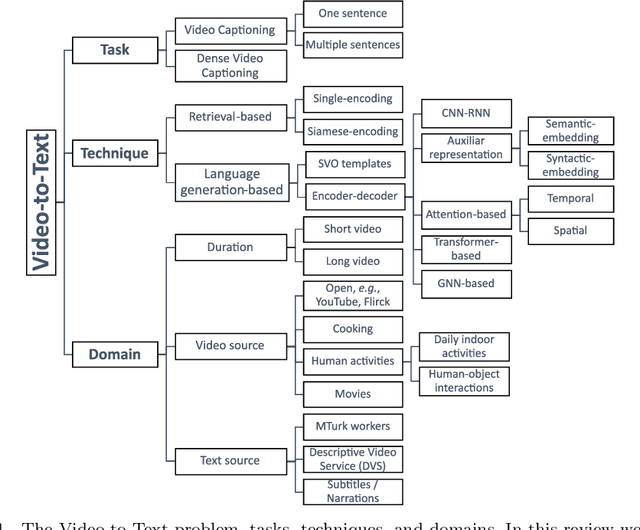
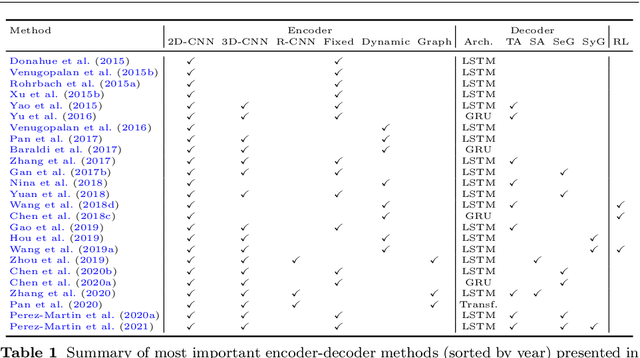
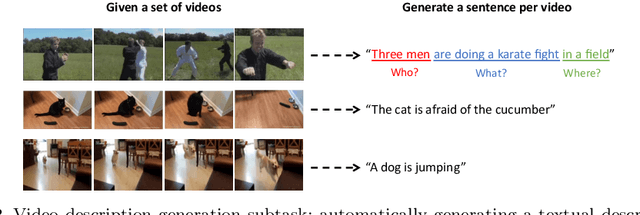
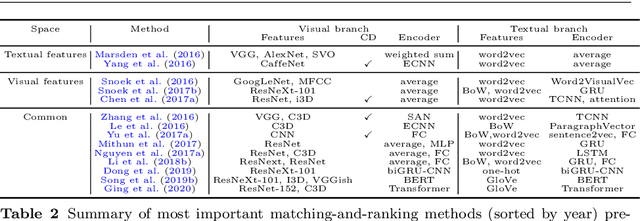
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
Impact of Spatial Frequency Based Constraints on Adversarial Robustness
May 05, 2021
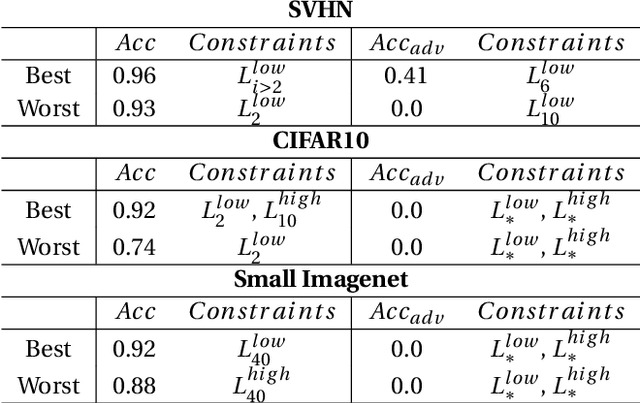
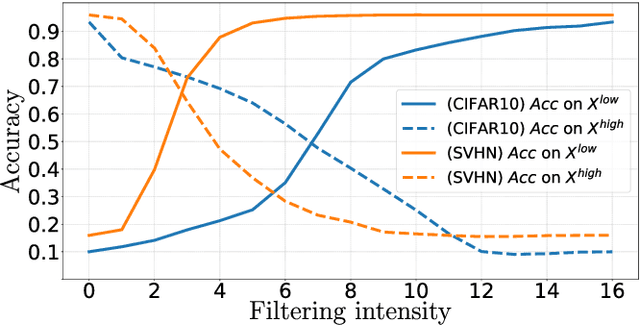
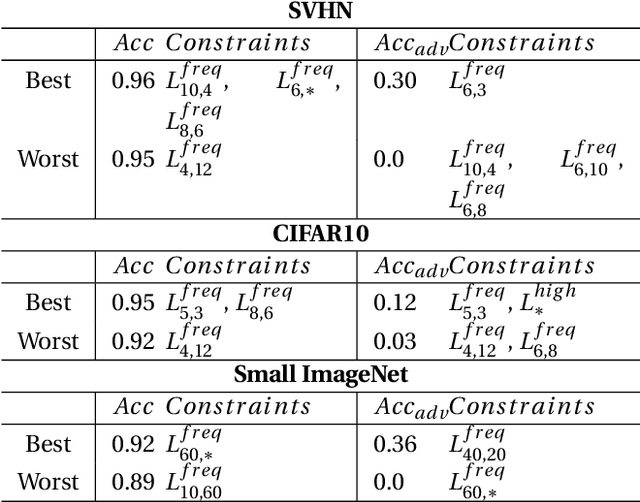
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
Few-Shot Electronic Health Record Coding through Graph Contrastive Learning
Jun 29, 2021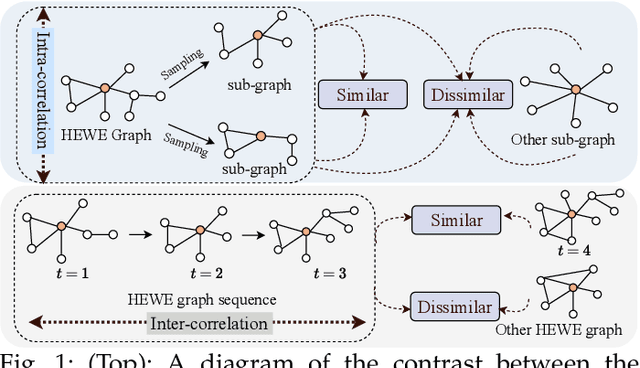
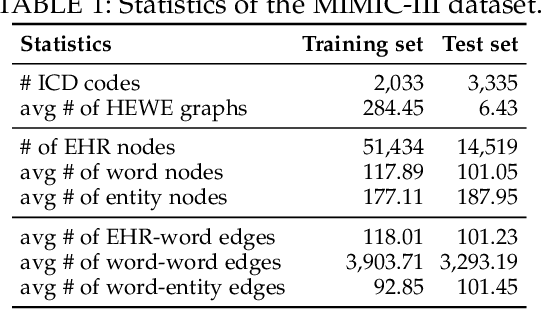
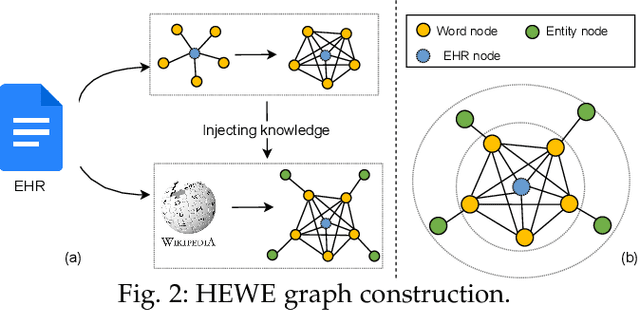
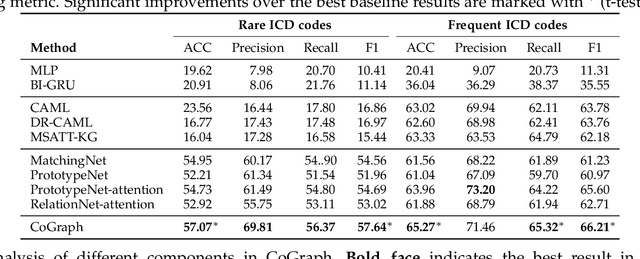
Electronic health record (EHR) coding is the task of assigning ICD codes to each EHR. Most previous studies either only focus on the frequent ICD codes or treat rare and frequent ICD codes in the same way. These methods perform well on frequent ICD codes but due to the extremely unbalanced distribution of ICD codes, the performance on rare ones is far from satisfactory. We seek to improve the performance for both frequent and rare ICD codes by using a contrastive graph-based EHR coding framework, CoGraph, which re-casts EHR coding as a few-shot learning task. First, we construct a heterogeneous EHR word-entity (HEWE) graph for each EHR, where the words and entities extracted from an EHR serve as nodes and the relations between them serve as edges. Then, CoGraph learns similarities and dissimilarities between HEWE graphs from different ICD codes so that information can be transferred among them. In a few-shot learning scenario, the model only has access to frequent ICD codes during training, which might force it to encode features that are useful for frequent ICD codes only. To mitigate this risk, CoGraph devises two graph contrastive learning schemes, GSCL and GECL, that exploit the HEWE graph structures so as to encode transferable features. GSCL utilizes the intra-correlation of different sub-graphs sampled from HEWE graphs while GECL exploits the inter-correlation among HEWE graphs at different clinical stages. Experiments on the MIMIC-III benchmark dataset show that CoGraph significantly outperforms state-of-the-art methods on EHR coding, not only on frequent ICD codes, but also on rare codes, in terms of several evaluation indicators. On frequent ICD codes, GSCL and GECL improve the classification accuracy and F1 by 1.31% and 0.61%, respectively, and on rare ICD codes CoGraph has more obvious improvements by 2.12% and 2.95%.