 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QZNs: Quantum Z-numbers
Apr 12, 2021
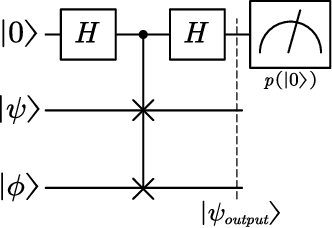
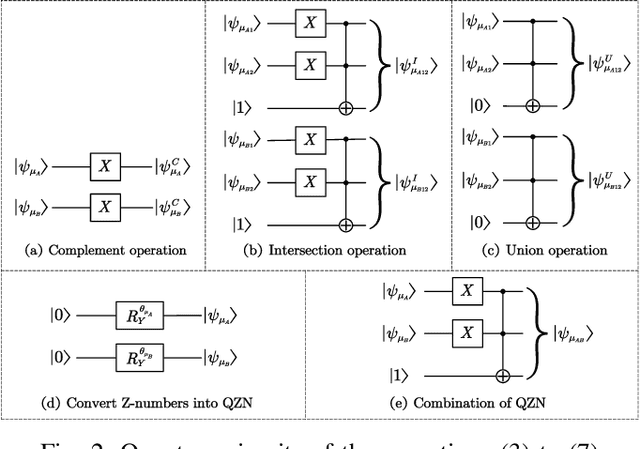
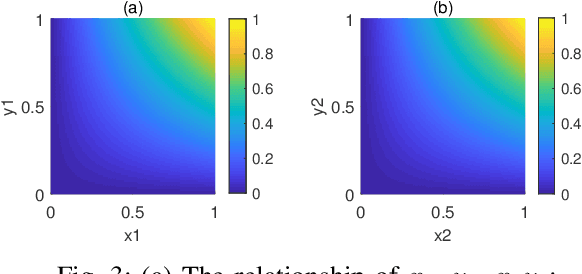
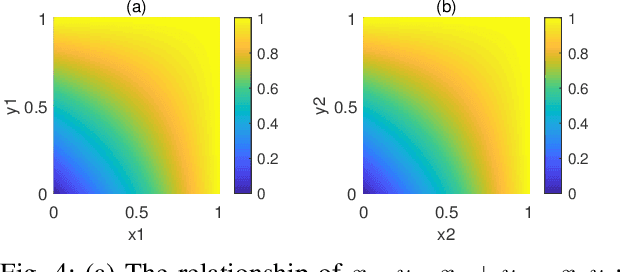
Because of the efficiency of modeling fuzziness and vagueness, Z-number plays an important role in real practice. However, Z-numbers, defined in the real number field, lack the ability to process the quantum information in quantum environment. It is reasonable to generalize Z-number into its quantum counterpart. In this paper, we propose quantum Z-numbers (QZNs), which are the quantum generalization of Z-numbers. In addition, seven basic quantum fuzzy operations of QZNs and their corresponding quantum circuits are presented and illustrated by numerical examples. Moreover, based on QZNs, a novel quantum multi-attributes decision making (MADM) algorithm is proposed and applied in medical diagnosis. The results show that, with the help of quantum computation, the proposed algorithm can make diagnoses correctly and efficiently.
Zero-shot learning approach to adaptive Cybersecurity using Explainable AI
Jun 21, 2021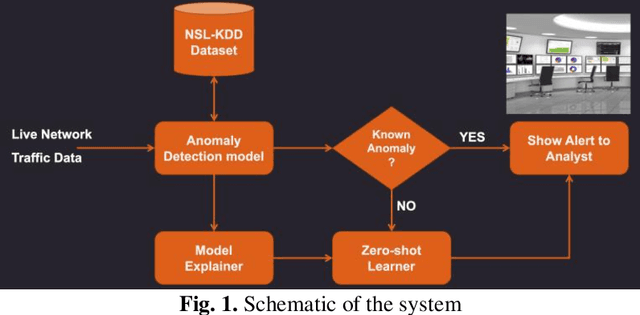
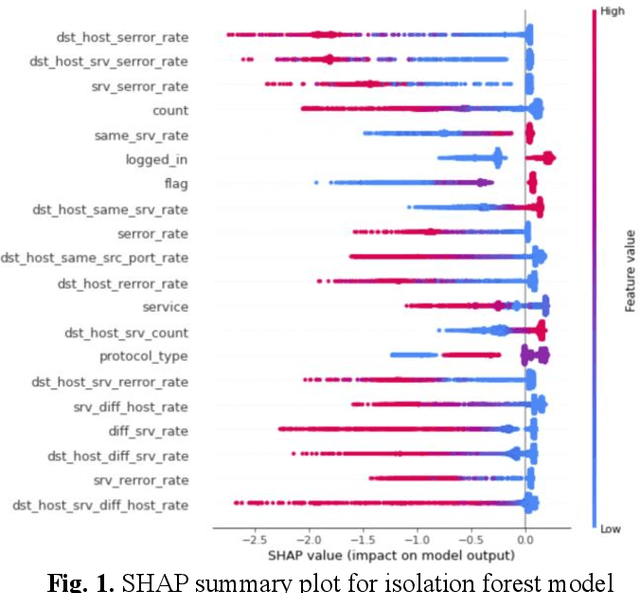
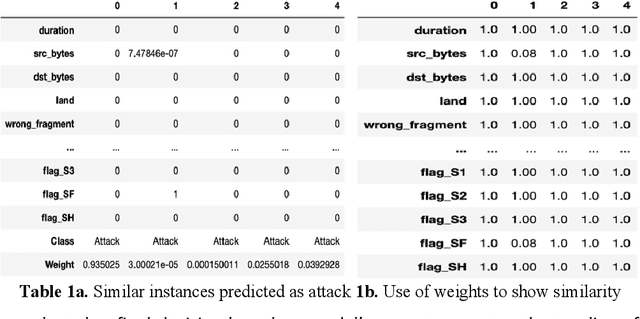

Cybersecurity is a domain where there is constant change in patterns of attack, and we need ways to make our Cybersecurity systems more adaptive to handle new attacks and categorize for appropriate action. We present a novel approach to handle the alarm flooding problem faced by Cybersecurity systems like security information and event management (SIEM) and intrusion detection (IDS). We apply a zero-shot learning method to machine learning (ML) by leveraging explanations for predictions of anomalies generated by a ML model. This approach has huge potential to auto detect alarm labels generated in SIEM and associate them with specific attack types. In this approach, without any prior knowledge of attack, we try to identify it, decipher the features that contribute to classification and try to bucketize the attack in a specific category - using explainable AI. Explanations give us measurable factors as to what features influence the prediction of a cyber-attack and to what degree. These explanations generated based on game-theory are used to allocate credit to specific features based on their influence on a specific prediction. Using this allocation of credit, we propose a novel zero-shot approach to categorize novel attacks into specific new classes based on feature influence. The resulting system demonstrated will get good at separating attack traffic from normal flow and auto-generate a label for attacks based on features that contribute to the attack. These auto-generated labels can be presented to SIEM analyst and are intuitive enough to figure out the nature of attack. We apply this approach to a network flow dataset and demonstrate results for specific attack types like ip sweep, denial of service, remote to local, etc. Paper was presented at the first Conference on Deployable AI at IIT-Madras in June 2021.
Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Feb 03, 2021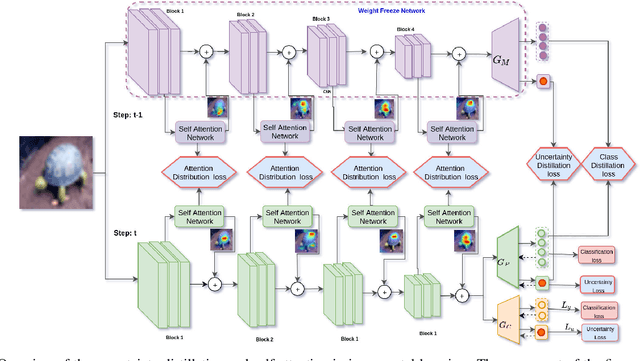
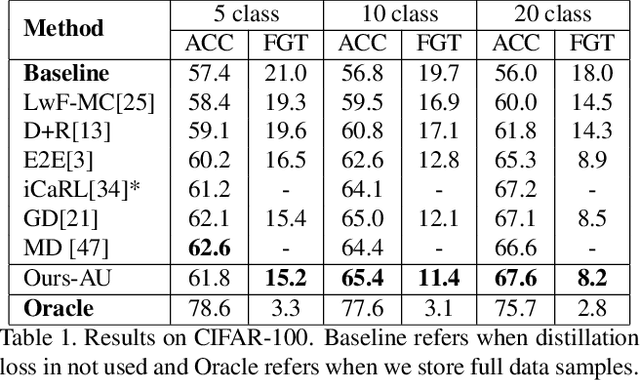
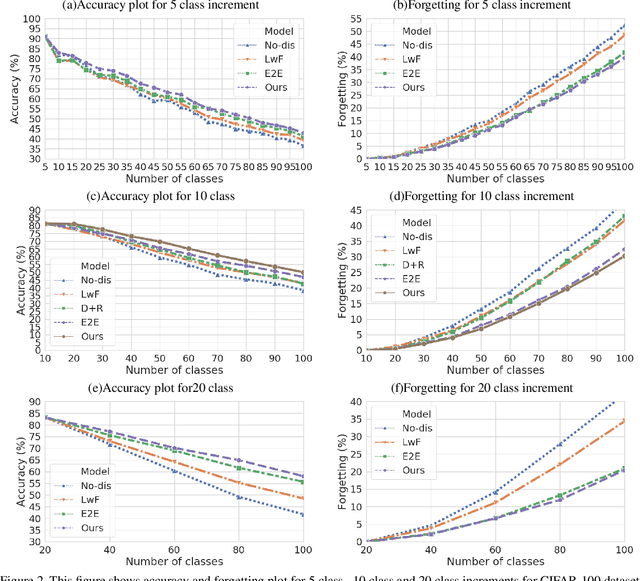
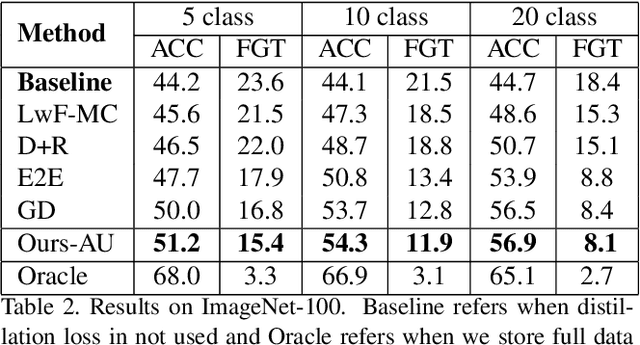
One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
* Accepted WACV 2021
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 17, 2021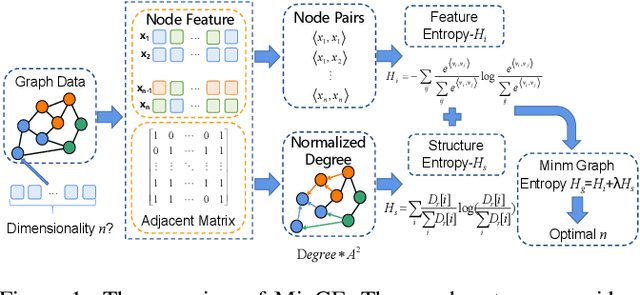
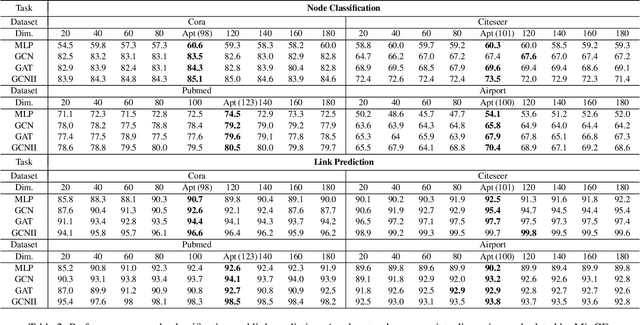
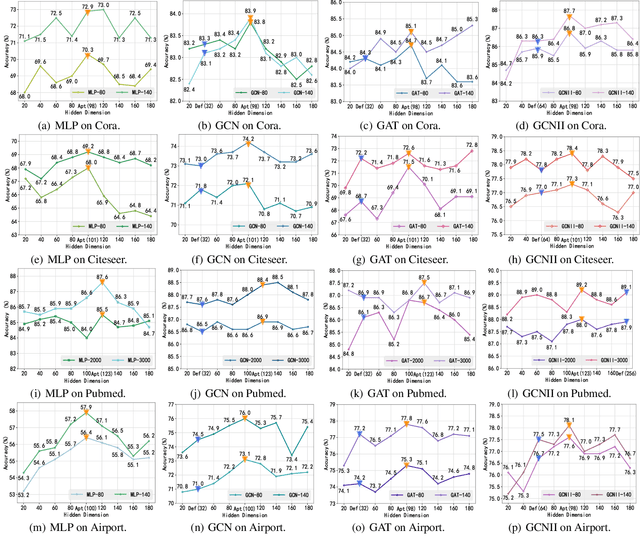
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
Aggregation of Classifiers: A Justifiable Information Granularity Approach
Mar 15, 2017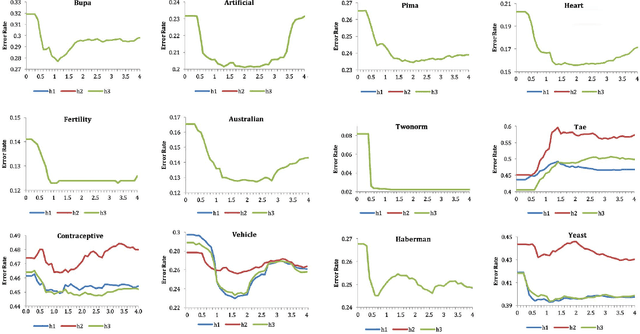
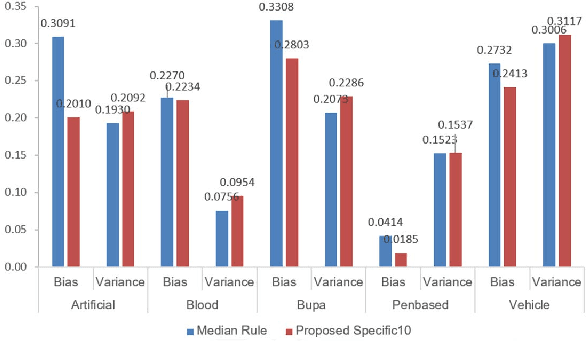

In this study, we introduce a new approach to combine multi-classifiers in an ensemble system. Instead of using numeric membership values encountered in fixed combining rules, we construct interval membership values associated with each class prediction at the level of meta-data of observation by using concepts of information granules. In the proposed method, uncertainty (diversity) of findings produced by the base classifiers is quantified by interval-based information granules. The discriminative decision model is generated by considering both the bounds and the length of the obtained intervals. We select ten and then fifteen learning algorithms to build a heterogeneous ensemble system and then conducted the experiment on a number of UCI datasets. The experimental results demonstrate that the proposed approach performs better than the benchmark algorithms including six fixed combining methods, one trainable combining method, AdaBoost, Bagging, and Random Subspace.
Fairness in Ranking: A Survey
Mar 25, 2021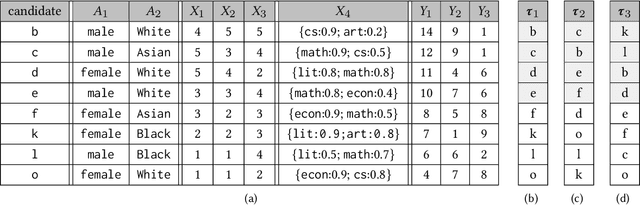

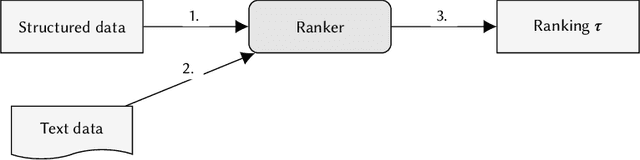
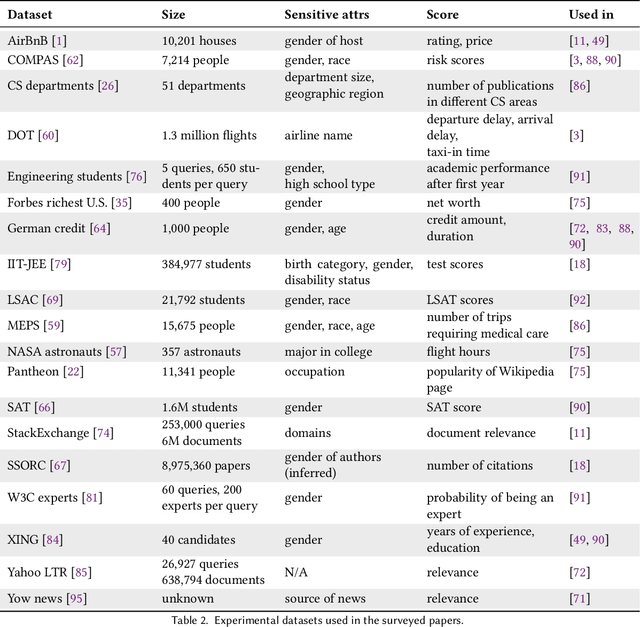
In the past few years, there has been much work on incorporating fairness requirements into algorithmic rankers, with contributions coming from the data management, algorithms, information retrieval, and recommender systems communities. In this survey we give a systematic overview of this work, offering a broad perspective that connects formalizations and algorithmic approaches across subfields. An important contribution of our work is in developing a common narrative around the value frameworks that motivate specific fairness-enhancing interventions in ranking. This allows us to unify the presentation of mitigation objectives and of algorithmic techniques to help meet those objectives or identify trade-offs.
Toward Word Embedding for Personalized Information Retrieval
Jun 22, 2016
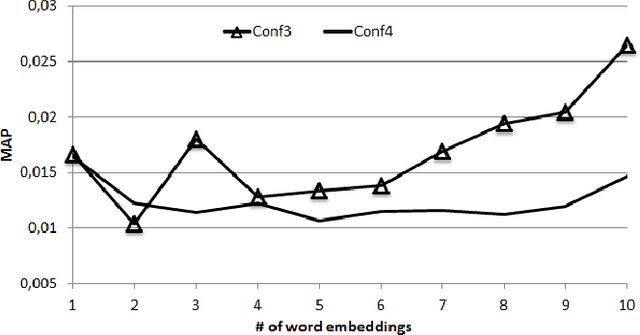

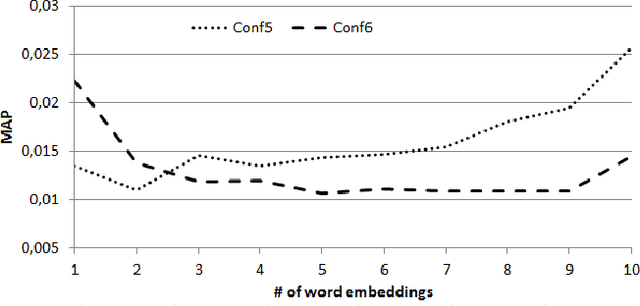
This paper presents preliminary works on using Word Embedding (word2vec) for query expansion in the context of Personalized Information Retrieval. Traditionally, word embeddings are learned on a general corpus, like Wikipedia. In this work we try to personalize the word embeddings learning, by achieving the learning on the user's profile. The word embeddings are then in the same context than the user interests. Our proposal is evaluated on the CLEF Social Book Search 2016 collection. The results obtained show that some efforts should be made in the way to apply Word Embedding in the context of Personalized Information Retrieval.
Impact of Spatial Frequency Based Constraints on Adversarial Robustness
Apr 26, 2021
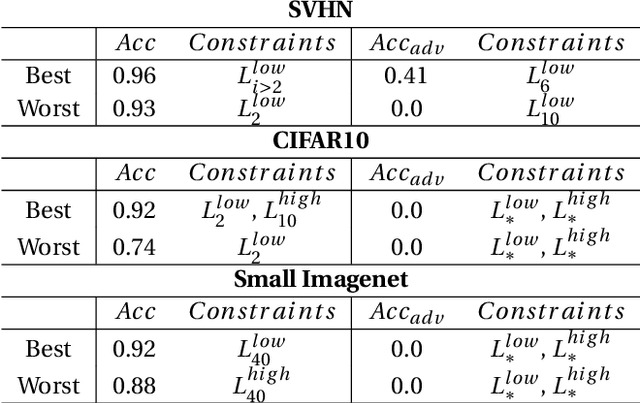
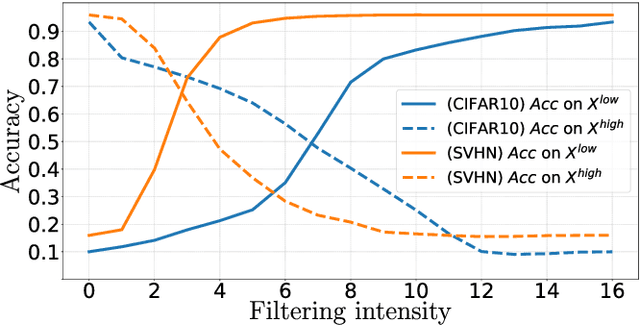
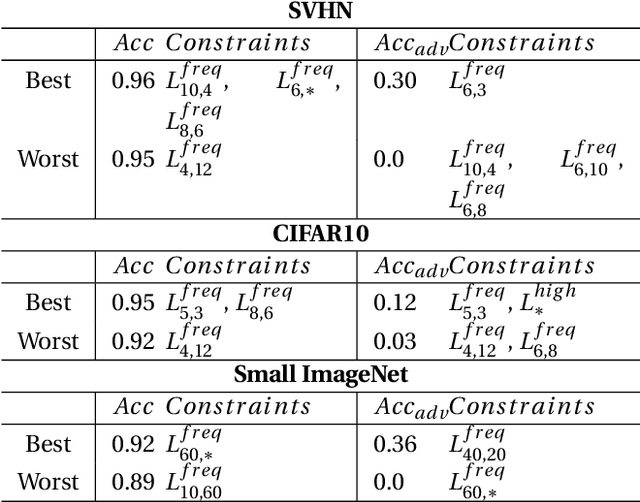
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
Item Silk Road: Recommending Items from Information Domains to Social Users
Jun 10, 2017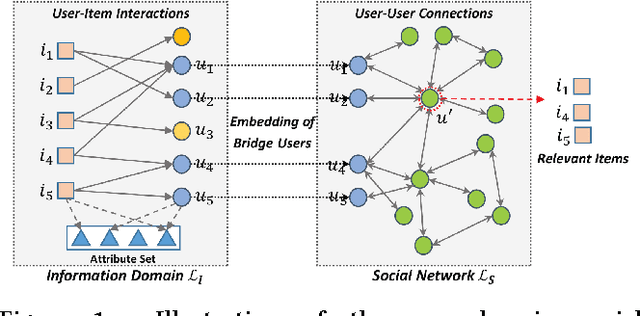
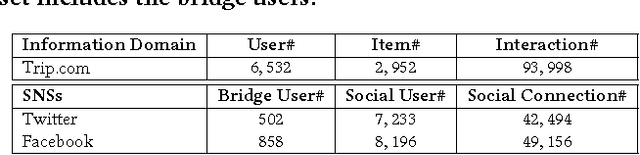
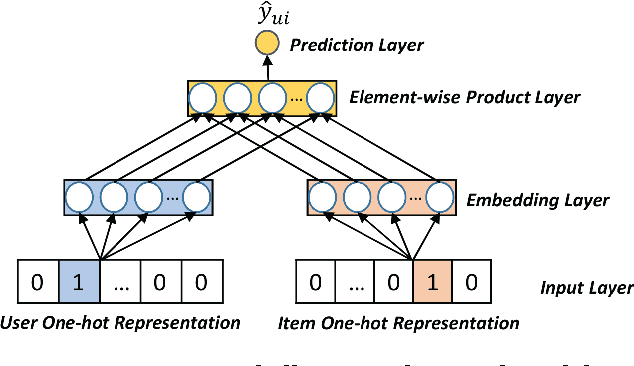
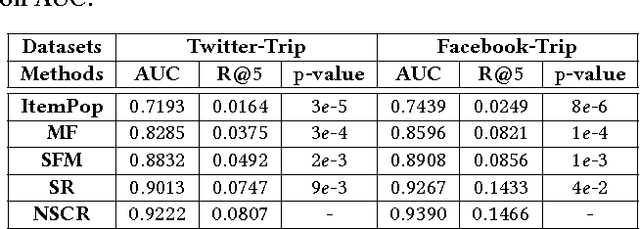
Online platforms can be divided into information-oriented and social-oriented domains. The former refers to forums or E-commerce sites that emphasize user-item interactions, like Trip.com and Amazon; whereas the latter refers to social networking services (SNSs) that have rich user-user connections, such as Facebook and Twitter. Despite their heterogeneity, these two domains can be bridged by a few overlapping users, dubbed as bridge users. In this work, we address the problem of cross-domain social recommendation, i.e., recommending relevant items of information domains to potential users of social networks. To our knowledge, this is a new problem that has rarely been studied before. Existing cross-domain recommender systems are unsuitable for this task since they have either focused on homogeneous information domains or assumed that users are fully overlapped. Towards this end, we present a novel Neural Social Collaborative Ranking (NSCR) approach, which seamlessly sews up the user-item interactions in information domains and user-user connections in SNSs. In the information domain part, the attributes of users and items are leveraged to strengthen the embedding learning of users and items. In the SNS part, the embeddings of bridge users are propagated to learn the embeddings of other non-bridge users. Extensive experiments on two real-world datasets demonstrate the effectiveness and rationality of our NSCR method.
Alternating Fixpoint Operator for Hybrid MKNF Knowledge Bases as an Approximator of AFT
May 24, 2021Approximation fixpoint theory (AFT) provides an algebraic framework for the study of fixpoints of operators on bilattices and has found its applications in characterizing semantics for various classes of logic programs and nonmonotonic languages. In this paper, we show one more application of this kind: the alternating fixpoint operator by Knorr et al. for the study of the well-founded semantics for hybrid MKNF knowledge bases is in fact an approximator of AFT in disguise, which, thanks to the power of abstraction of AFT, characterizes not only the well-founded semantics but also two-valued as well as three-valued semantics for hybrid MKNF knowledge bases. Furthermore, we show an improved approximator for these knowledge bases, of which the least stable fixpoint is information richer than the one formulated from Knorr et al.'s construction. This leads to an improved computation for the well-founded semantics. This work is built on an extension of AFT that supports consistent as well as inconsistent pairs in the induced product bilattice, to deal with inconsistencies that arise in the context of hybrid MKNF knowledge bases. This part of the work can be considered generalizing the original AFT from symmetric approximators to arbitrary approximators.