 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
Jun 22, 2021
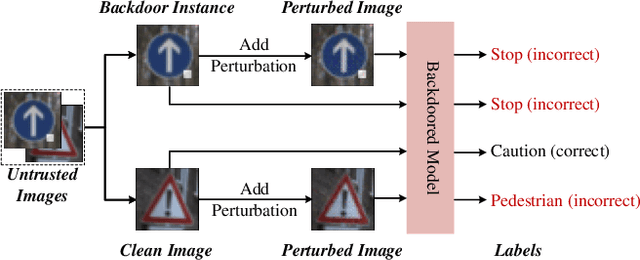
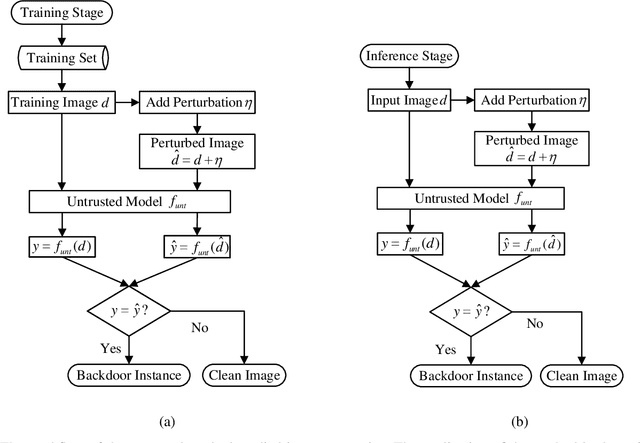


Recent researches show that deep learning model is susceptible to backdoor attacks. Many defenses against backdoor attacks have been proposed. However, existing defense works require high computational overhead or backdoor attack information such as the trigger size, which is difficult to satisfy in realistic scenarios. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether an image contains a trigger, which can be applied in both the training stage and the inference stage (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the image intentionally. If the prediction of the model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. Compared with most existing defense works, the proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the backdoor detection rate of the proposed defense method is 99.63%, 99.76% and 99.91% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the l2 norm of the added perturbation are as low as 2.8715, 3.0513 and 2.4362 on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. In addition, it is also demonstrated that the proposed method can achieve high defense performance against backdoor attacks under different attack settings (trigger transparency, trigger size and trigger pattern). Compared with the existing defense work (STRIP), the proposed method has better detection performance on all the three datasets, and is more efficient than STRIP.
Subspace Representation Learning for Few-shot Image Classification
May 02, 2021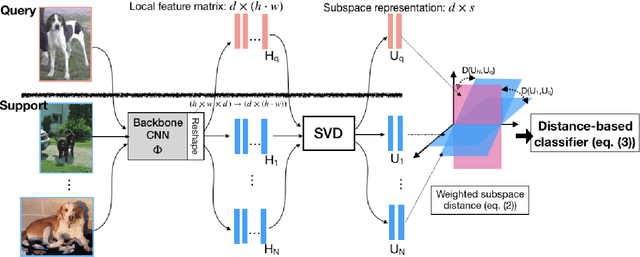
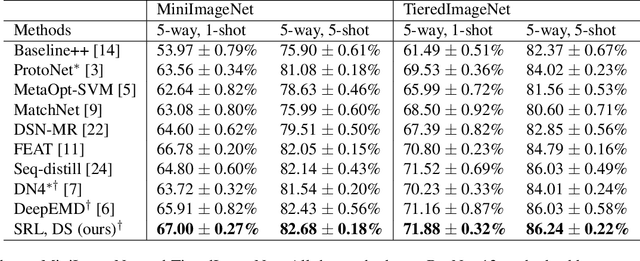
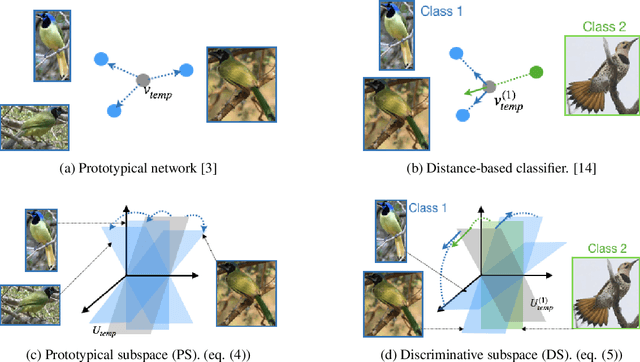
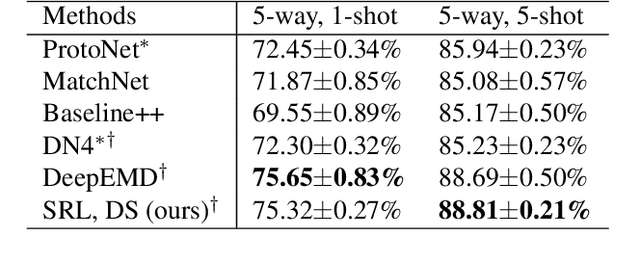
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
Subspace-based compressive sensing algorithm for raypath separation in a shallow-water waveguide
Mar 26, 2021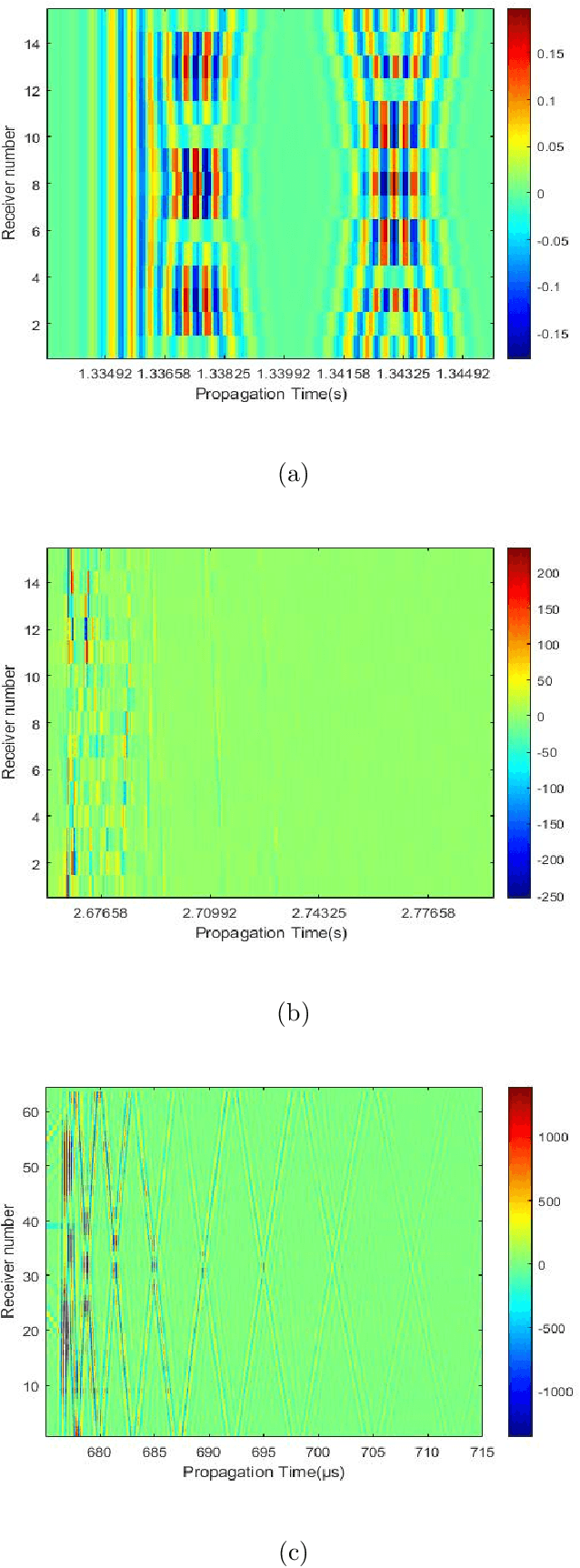
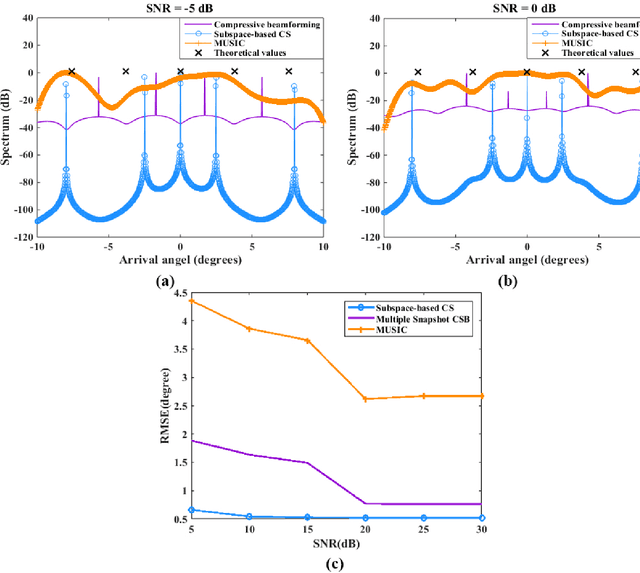
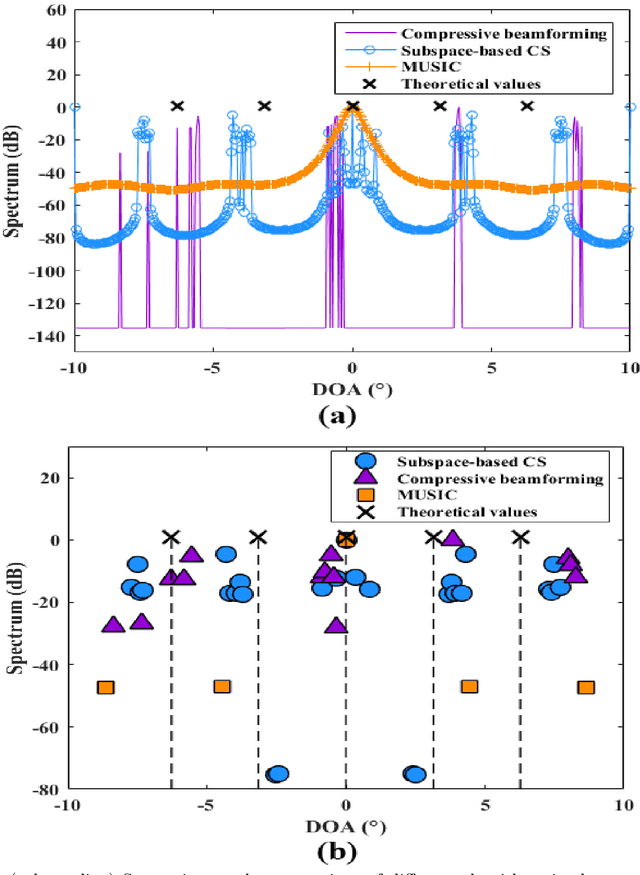
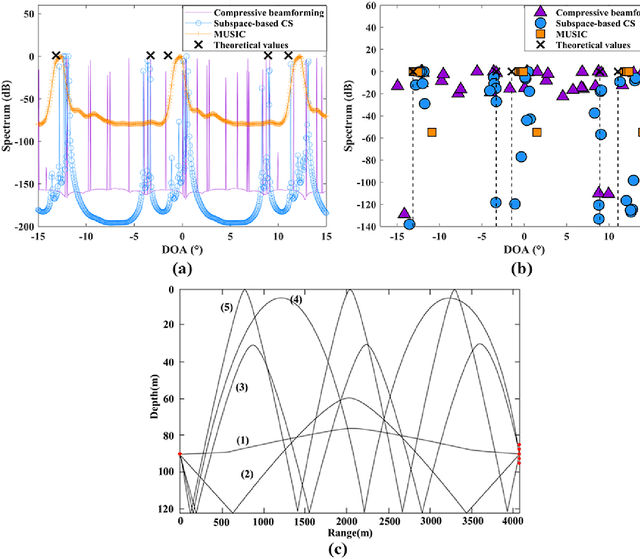
Compressive sensing (CS) has been applied to estimate the direction of arrival (DOA) in underwater acoustics. However, the key problem needed to be resolved in a {multipath} propagation environment is to suppress the interferences between the raypaths. Thus, in this paper, {a subspace-based compressive sensing algorithm that formulates the statistic information of the signal subspace in a CS framework is proposed.} The experiment results show that (1) the proposed algorithm enables the separation of raypaths that arrive closely at the {receiver} array and (2) the existing algorithms fail, especially in a low signal-to-noise ratio (SNR) environment.
NPRF: A Neural Pseudo Relevance Feedback Framework for Ad-hoc Information Retrieval
Oct 30, 2018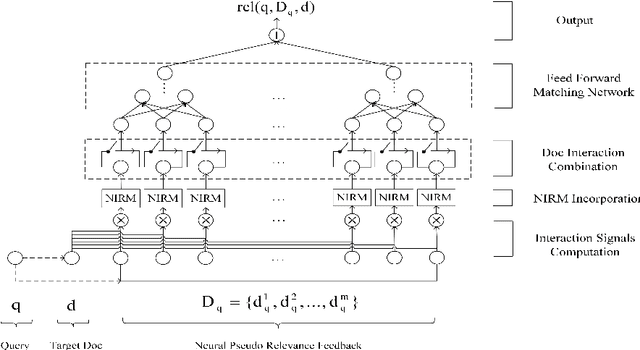
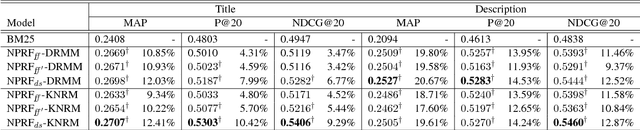
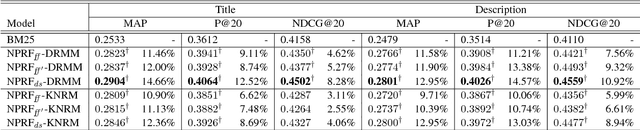
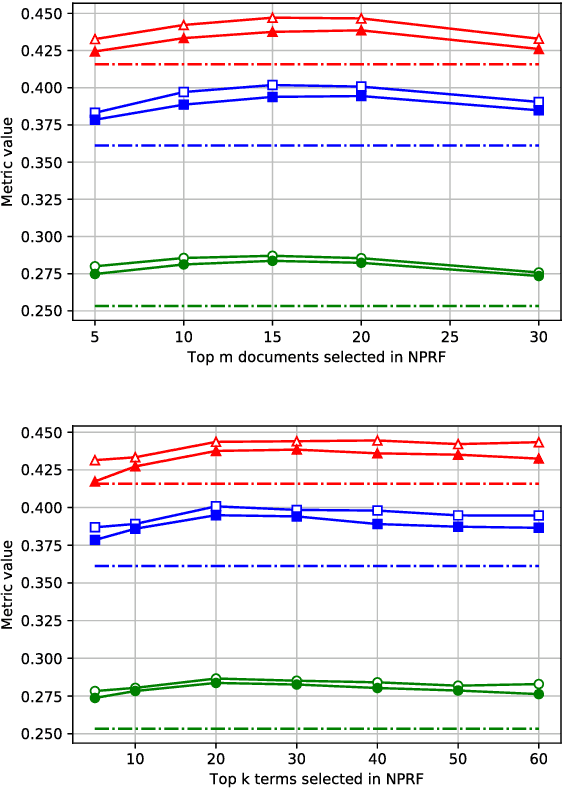
Pseudo-relevance feedback (PRF) is commonly used to boost the performance of traditional information retrieval (IR) models by using top-ranked documents to identify and weight new query terms, thereby reducing the effect of query-document vocabulary mismatches. While neural retrieval models have recently demonstrated strong results for ad-hoc retrieval, combining them with PRF is not straightforward due to incompatibilities between existing PRF approaches and neural architectures. To bridge this gap, we propose an end-to-end neural PRF framework that can be used with existing neural IR models by embedding different neural models as building blocks. Extensive experiments on two standard test collections confirm the effectiveness of the proposed NPRF framework in improving the performance of two state-of-the-art neural IR models.
Histogram Specification by Assignment of Optimal Unique Values
Feb 04, 2021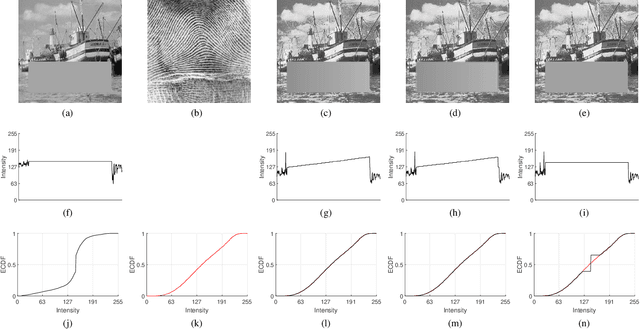
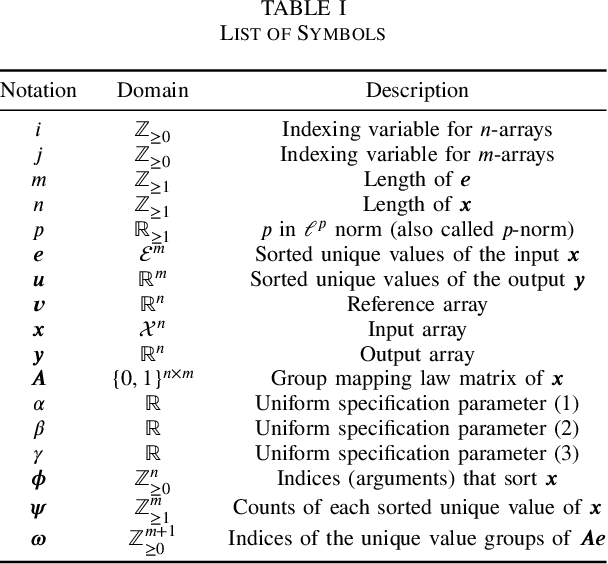
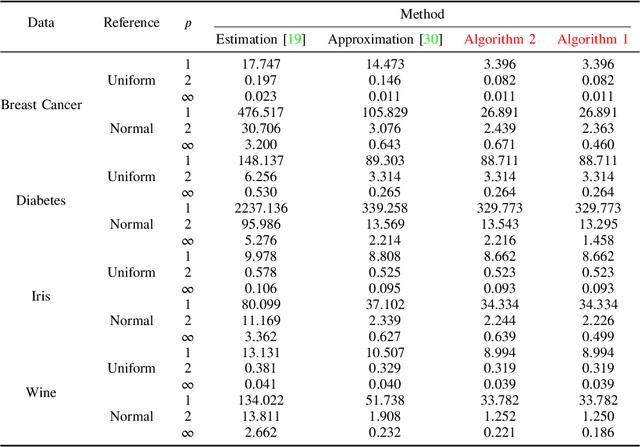
In this paper, we propose two novel algorithms for histogram specification and quantile transformation of data without local information. These are core techniques that can serve as building blocks for applications that require specifying the sample distribution of a given set of data. Histogram specification is best known for its image enhancement applications, whereas quantile transformation is typically employed in data preprocessing for data normalization. In signal processing, methods often require temporal or spatial information; in data preprocessing, methods work by interpolation or by approximation, drawing from results in computational statistics, and have a trade-off between speed and quality. It is nontrivial to accommodate for cases that do not have local information (e.g., tabular data) while also providing a fast, exact solution. For that, we take up a concept in image processing called group mapping law and propose an extension. The proposed extension allows us to formulate a convex functional where we look for the best approximation between the output unique values and the reference histogram. Then, we apply the ordered assignment solution, a result in optimal transport, to reconstruct the output from the optimal unique values. Two sets of results show the effectiveness of the proposed algorithms when compared to traditional and state-of-the-art methods. The proposed algorithms are fast, exact, and least $p$-norm optimal. Further, we define the algorithms as generic data processing methods. Thus, contributions from this paper can be easily incorporated in applications spanning many disciplines, especially in applied data science.
Leveraging Two Types of Global Graph for Sequential Fashion Recommendation
May 18, 2021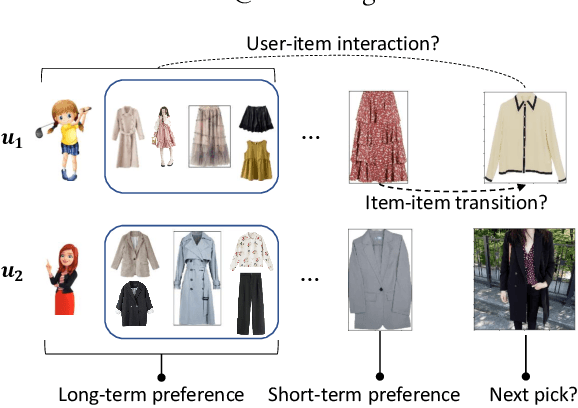
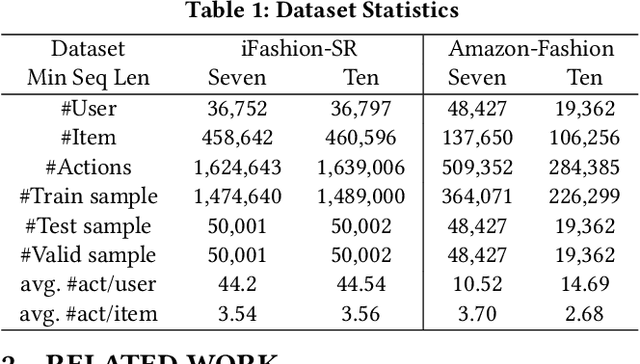
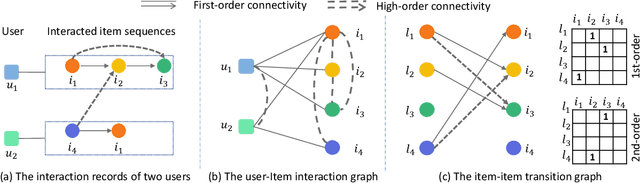
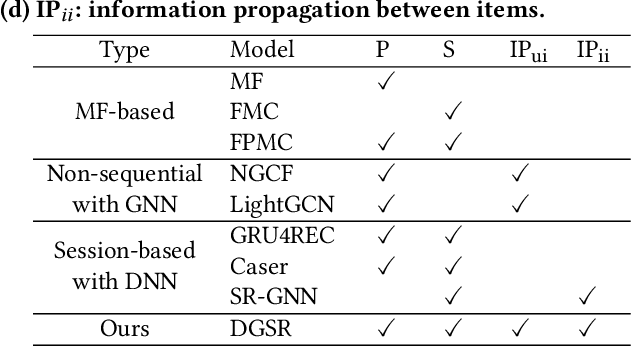
Sequential fashion recommendation is of great significance in online fashion shopping, which accounts for an increasing portion of either fashion retailing or online e-commerce. The key to building an effective sequential fashion recommendation model lies in capturing two types of patterns: the personal fashion preference of users and the transitional relationships between adjacent items. The two types of patterns are usually related to user-item interaction and item-item transition modeling respectively. However, due to the large sets of users and items as well as the sparse historical interactions, it is difficult to train an effective and efficient sequential fashion recommendation model. To tackle these problems, we propose to leverage two types of global graph, i.e., the user-item interaction graph and item-item transition graph, to obtain enhanced user and item representations by incorporating higher-order connections over the graphs. In addition, we adopt the graph kernel of LightGCN for the information propagation in both graphs and propose a new design for item-item transition graph. Extensive experiments on two established sequential fashion recommendation datasets validate the effectiveness and efficiency of our approach.
Leveraging Event Specific and Chunk Span features to Extract COVID Events from tweets
Dec 18, 2020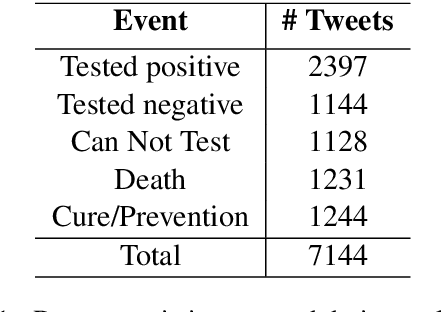


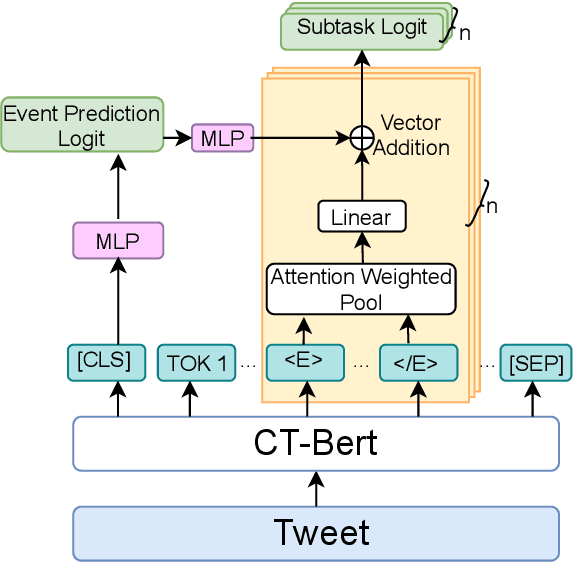
Twitter has acted as an important source of information during disasters and pandemic, especially during the times of COVID-19. In this paper, we describe our system entry for WNUT 2020 Shared Task-3. The task was aimed at automating the extraction of a variety of COVID-19 related events from Twitter, such as individuals who recently contracted the virus, someone with symptoms who were denied testing and believed remedies against the infection. The system consists of separate multi-task models for slot-filling subtasks and sentence-classification subtasks while leveraging the useful sentence-level information for the corresponding event. The system uses COVID-Twitter-Bert with attention-weighted pooling of candidate slot-chunk features to capture the useful information chunks. The system ranks 1st at the leader-board with F1 of 0.6598, without using any ensembles or additional datasets. The code and trained models are available at this https URL.
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021



Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
KddRES: A Multi-level Knowledge-driven Dialogue Dataset for Restaurant Towards Customized Dialogue System
Nov 18, 2020

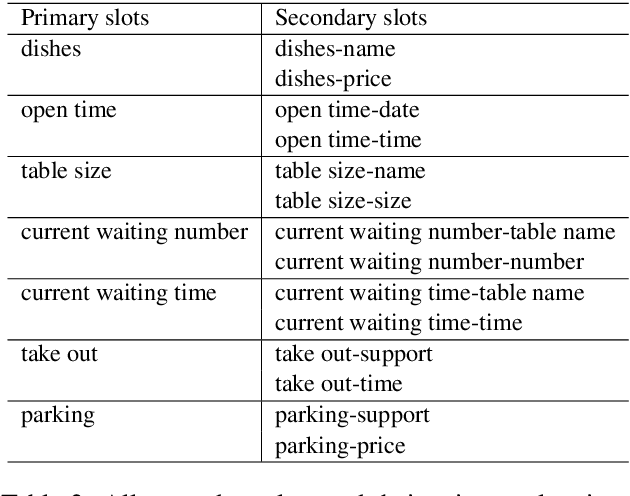
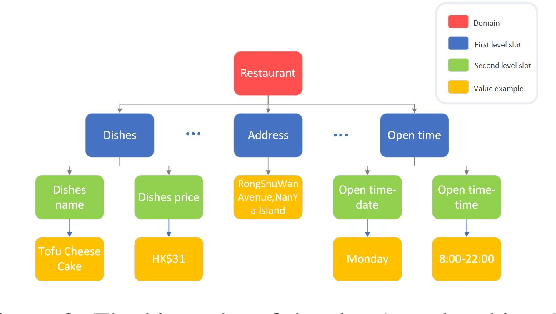
Compared with CrossWOZ (Chinese) and MultiWOZ (English) dataset which have coarse-grained information, there is no dataset which handle fine-grained and hierarchical level information properly. In this paper, we publish a first Cantonese knowledge-driven Dialogue Dataset for REStaurant (KddRES) in Hong Kong, which grounds the information in multi-turn conversations to one specific restaurant. Our corpus contains 0.8k conversations which derive from 10 restaurants with various styles in different regions. In addition to that, we designed fine-grained slots and intents to better capture semantic information. The benchmark experiments and data statistic analysis show the diversity and rich annotations of our dataset. We believe the publish of KddRES can be a necessary supplement of current dialogue datasets and more suitable and valuable for small and middle enterprises (SMEs) of society, such as build a customized dialogue system for each restaurant. The corpus and benchmark models are publicly available.
Dynamic Federated Learning-Based Economic Framework for Internet-of-Vehicles
Jan 01, 2021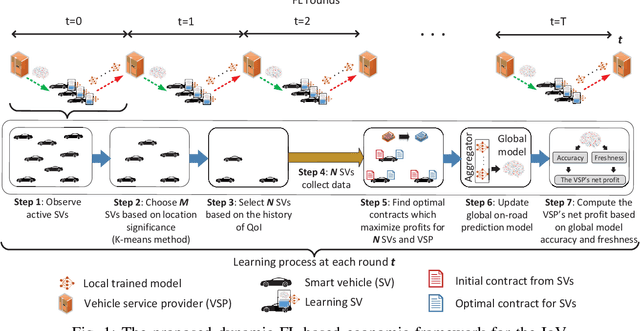
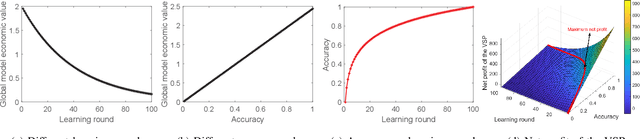
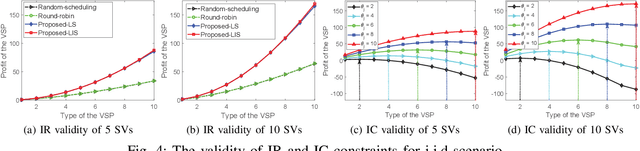
Federated learning (FL) can empower Internet-of-Vehicles (IoV) networks by leveraging smart vehicles (SVs) to participate in the learning process with minimum data exchanges and privacy disclosure. The collected data and learned knowledge can help the vehicular service provider (VSP) improve the global model accuracy, e.g., for road safety as well as better profits for both VSP and participating SVs. Nonetheless, there exist major challenges when implementing the FL in IoV networks, such as dynamic activities and diverse quality-of-information (QoI) from a large number of SVs, VSP's limited payment budget, and profit competition among SVs. In this paper, we propose a novel dynamic FL-based economic framework for an IoV network to address these challenges. Specifically, the VSP first implements an SV selection method to determine a set of the best SVs for the FL process according to the significance of their current locations and information history at each learning round. Then, each selected SV can collect on-road information and offer a payment contract to the VSP based on its collected QoI. For that, we develop a multi-principal one-agent contract-based policy to maximize the profits of the VSP and learning SVs under the VSP's limited payment budget and asymmetric information between the VSP and SVs. Through experimental results using real-world on-road datasets, we show that our framework can converge 57% faster (even with only 10% of active SVs in the network) and obtain much higher social welfare of the network (up to 27.2 times) compared with those of other baseline FL methods.