 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
Dec 25, 2020
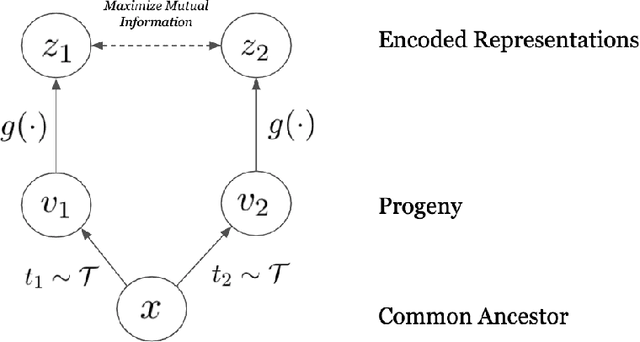
Self-supervised representation learning of biological sequence embeddings alleviates computational resource constraints on downstream tasks while circumventing expensive experimental label acquisition. However, existing methods mostly borrow directly from large language models designed for NLP, rather than with bioinformatics philosophies in mind. Recently, contrastive mutual information maximization methods have achieved state-of-the-art representations for ImageNet. In this perspective piece, we discuss how viewing evolution as natural sequence augmentation and maximizing information across phylogenetic "noisy channels" is a biologically and theoretically desirable objective for pretraining encoders. We first provide a review of current contrastive learning literature, then provide an illustrative example where we show that contrastive learning using evolutionary augmentation can be used as a representation learning objective which maximizes the mutual information between biological sequences and their conserved function, and finally outline rationale for this approach.
Loss function based second-order Jensen inequality and its application to particle variational inference
Jun 09, 2021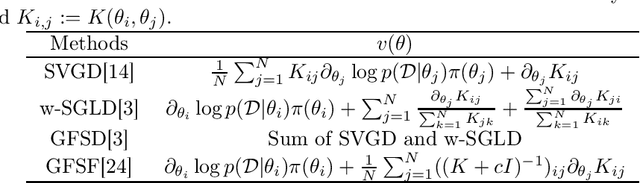
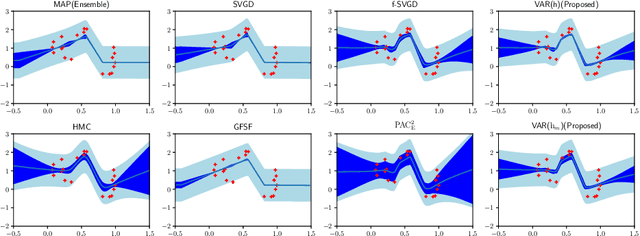
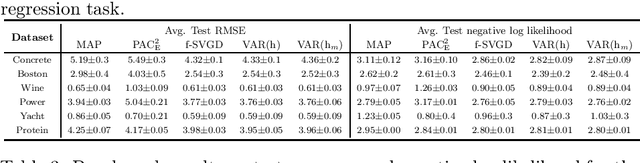
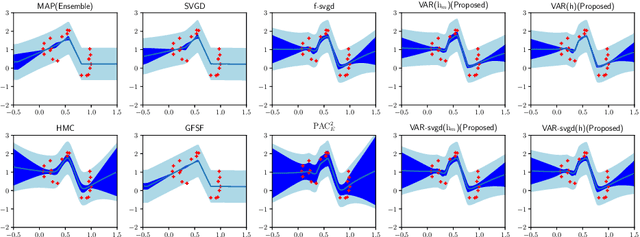
Bayesian model averaging, obtained as the expectation of a likelihood function by a posterior distribution, has been widely used for prediction, evaluation of uncertainty, and model selection. Various approaches have been developed to efficiently capture the information in the posterior distribution; one such approach is the optimization of a set of models simultaneously with interaction to ensure the diversity of the individual models in the same way as ensemble learning. A representative approach is particle variational inference (PVI), which uses an ensemble of models as an empirical approximation for the posterior distribution. PVI iteratively updates each model with a repulsion force to ensure the diversity of the optimized models. However, despite its promising performance, a theoretical understanding of this repulsion and its association with the generalization ability remains unclear. In this paper, we tackle this problem in light of PAC-Bayesian analysis. First, we provide a new second-order Jensen inequality, which has the repulsion term based on the loss function. Thanks to the repulsion term, it is tighter than the standard Jensen inequality. Then, we derive a novel generalization error bound and show that it can be reduced by enhancing the diversity of models. Finally, we derive a new PVI that optimizes the generalization error bound directly. Numerical experiments demonstrate that the performance of the proposed PVI compares favorably with existing methods in the experiment.
Predicting Aqueous Solubility of Organic Molecules Using Deep Learning Models with Varied Molecular Representations
May 27, 2021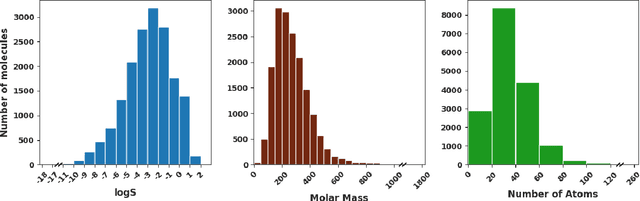
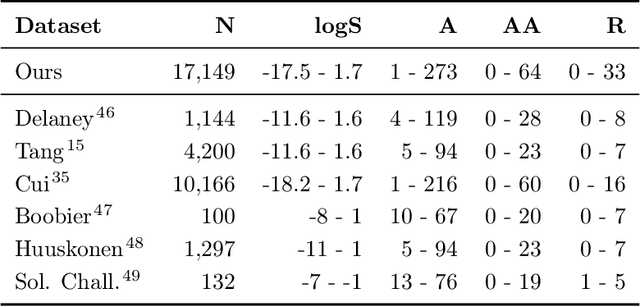
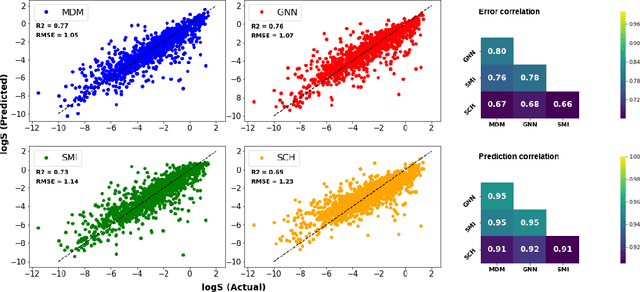
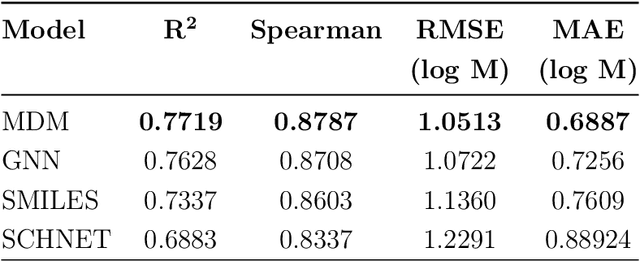
Determining the aqueous solubility of molecules is a vital step in many pharmaceutical, environmental, and energy storage applications. Despite efforts made over decades, there are still challenges associated with developing a solubility prediction model with satisfactory accuracy for many of these applications. The goal of this study is to develop a general model capable of predicting the solubility of a broad range of organic molecules. Using the largest currently available solubility dataset, we implement deep learning-based models to predict solubility from molecular structure and explore several different molecular representations including molecular descriptors, simplified molecular-input line-entry system (SMILES) strings, molecular graphs, and three-dimensional (3D) atomic coordinates using four different neural network architectures - fully connected neural networks (FCNNs), recurrent neural networks (RNNs), graph neural networks (GNNs), and SchNet. We find that models using molecular descriptors achieve the best performance, with GNN models also achieving good performance. We perform extensive error analysis to understand the molecular properties that influence model performance, perform feature analysis to understand which information about molecular structure is most valuable for prediction, and perform a transfer learning and data size study to understand the impact of data availability on model performance.
MIG Median Detectors with Manifold Filter
May 27, 2021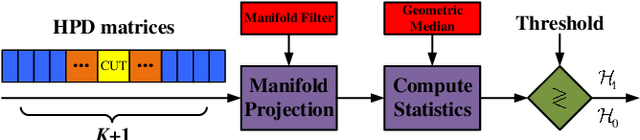
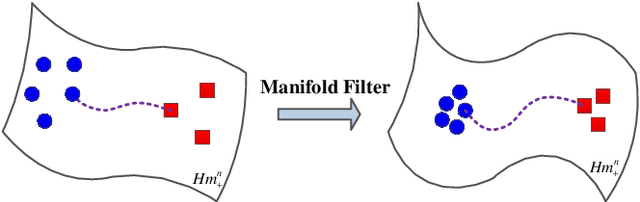
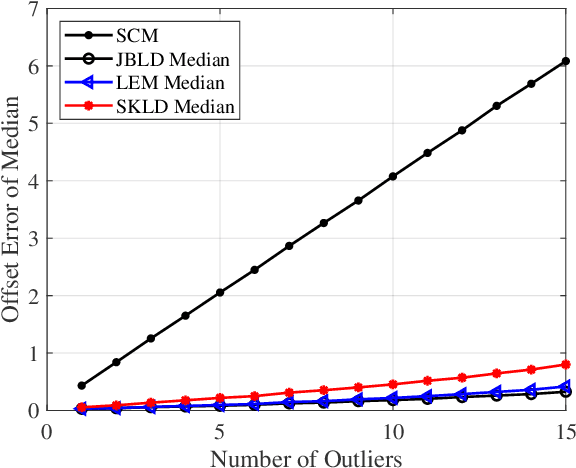
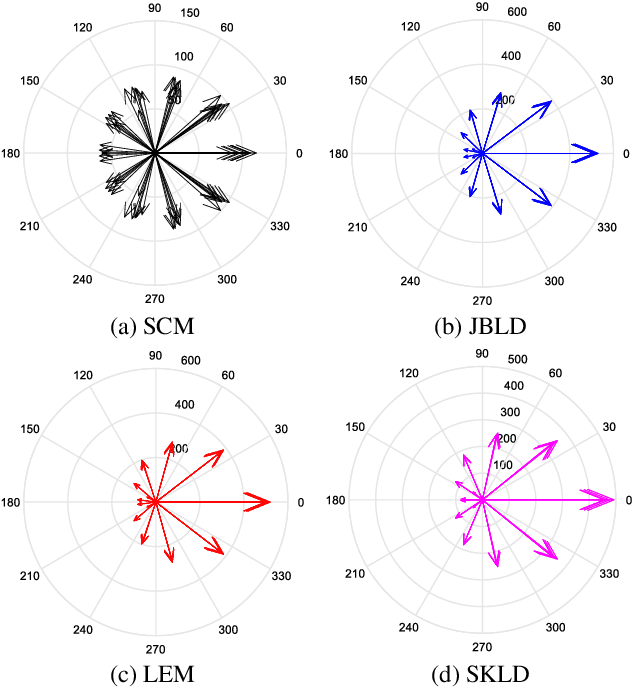
In this paper, we propose a class of median-based matrix information geometry (MIG) detectors with a manifold filter and apply them to signal detection in nonhomogeneous environments. As customary, the sample data is assumed to be modeled as Hermitian positive-definite (HPD) matrices, and the geometric median of a set of HPD matrices is interpreted as an estimate of the clutter covariance matrix (CCM). Then, the problem of signal detection can be reformulated as discriminating two points on the manifold of HPD matrices, one of which is the HPD matrix in the cell under test while the other represents the CCM. By manifold filter, we map a set of HPD matrices to another set of HPD matrices by weighting them, that consequently improves the discriminative power by reducing the intra-class distances while increasing the inter-class distances. Three MIG median detectors are designed by resorting to three geometric measures on the matrix manifold, and the corresponding geometric medians are shown to be robust to outliers. Numerical simulations show the advantage of the proposed MIG median detectors in comparison with their state-of-the-art counterparts as well as the conventional detectors in nonhomogeneous environments.
SCTN: Sparse Convolution-Transformer Network for Scene Flow Estimation
Jun 02, 2021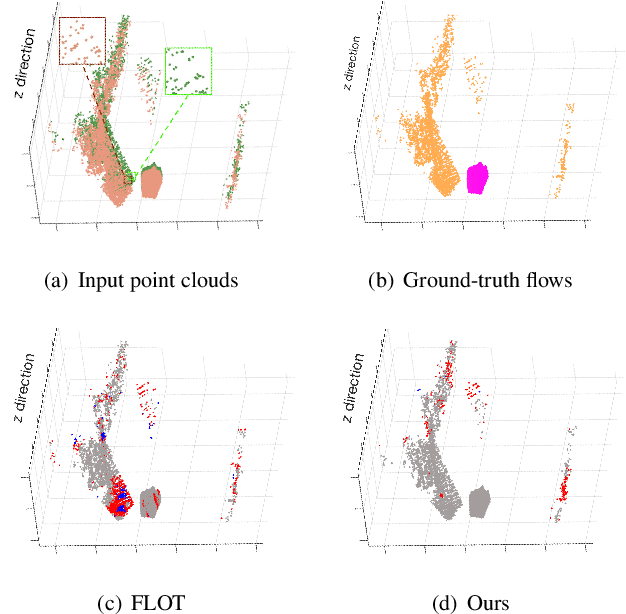
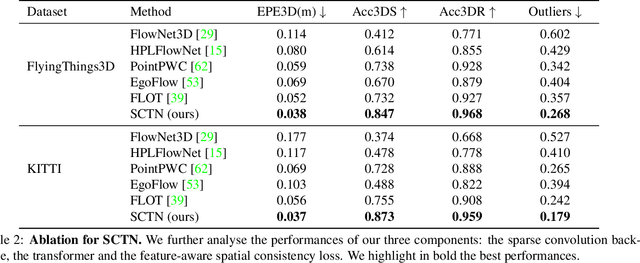
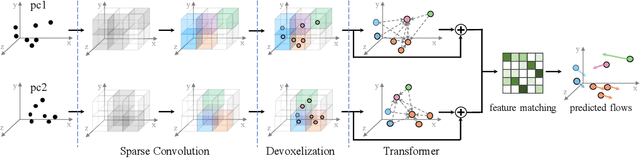
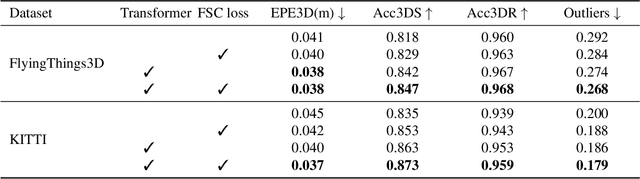
We propose a novel scene flow estimation approach to capture and infer 3D motions from point clouds. Estimating 3D motions for point clouds is challenging, since a point cloud is unordered and its density is significantly non-uniform. Such unstructured data poses difficulties in matching corresponding points between point clouds, leading to inaccurate flow estimation. We propose a novel architecture named Sparse Convolution-Transformer Network (SCTN) that equips the sparse convolution with the transformer. Specifically, by leveraging the sparse convolution, SCTN transfers irregular point cloud into locally consistent flow features for estimating continuous and consistent motions within an object/local object part. We further propose to explicitly learn point relations using a point transformer module, different from exiting methods. We show that the learned relation-based contextual information is rich and helpful for matching corresponding points, benefiting scene flow estimation. In addition, a novel loss function is proposed to adaptively encourage flow consistency according to feature similarity. Extensive experiments demonstrate that our proposed approach achieves a new state of the art in scene flow estimation. Our approach achieves an error of 0.038 and 0.037 (EPE3D) on FlyingThings3D and KITTI Scene Flow respectively, which significantly outperforms previous methods by large margins.
Barbershop: GAN-based Image Compositing using Segmentation Masks
Jun 02, 2021
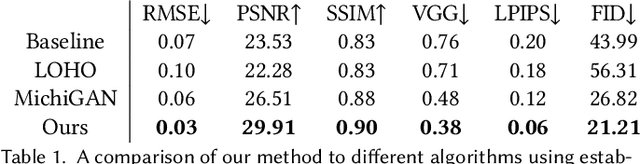
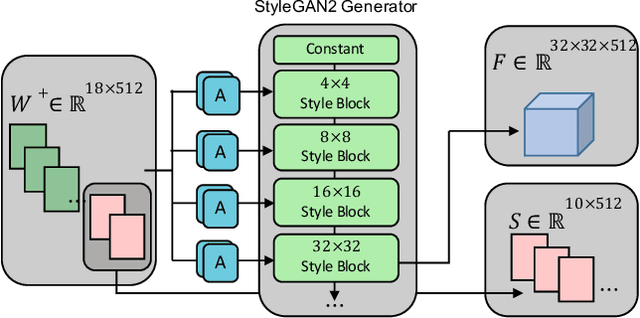

Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
Ember: No-Code Context Enrichment via Similarity-Based Keyless Joins
Jun 02, 2021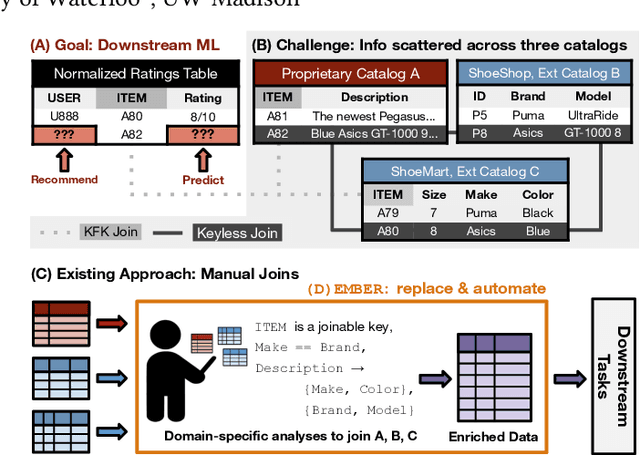
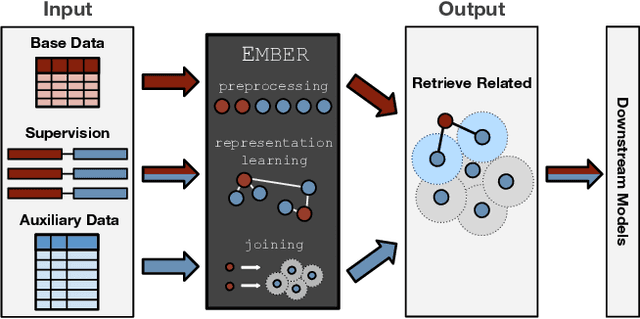
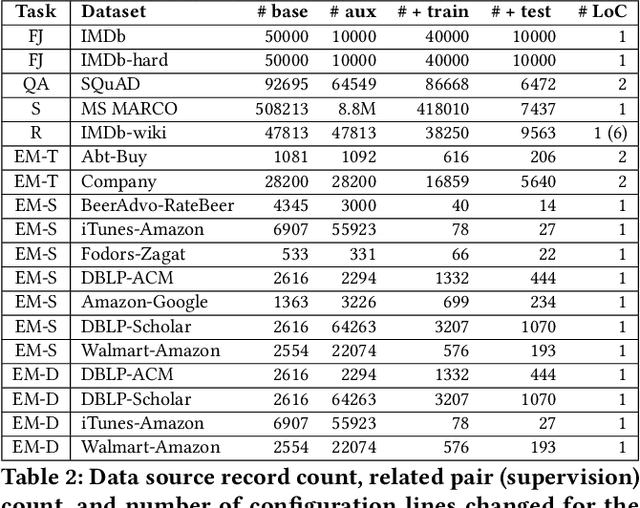
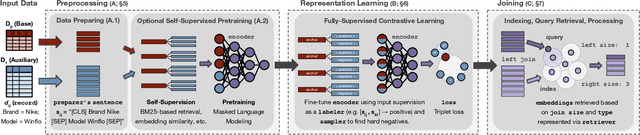
Structured data, or data that adheres to a pre-defined schema, can suffer from fragmented context: information describing a single entity can be scattered across multiple datasets or tables tailored for specific business needs, with no explicit linking keys (e.g., primary key-foreign key relationships or heuristic functions). Context enrichment, or rebuilding fragmented context, using keyless joins is an implicit or explicit step in machine learning (ML) pipelines over structured data sources. This process is tedious, domain-specific, and lacks support in now-prevalent no-code ML systems that let users create ML pipelines using just input data and high-level configuration files. In response, we propose Ember, a system that abstracts and automates keyless joins to generalize context enrichment. Our key insight is that Ember can enable a general keyless join operator by constructing an index populated with task-specific embeddings. Ember learns these embeddings by leveraging Transformer-based representation learning techniques. We describe our core architectural principles and operators when developing Ember, and empirically demonstrate that Ember allows users to develop no-code pipelines for five domains, including search, recommendation and question answering, and can exceed alternatives by up to 39% recall, with as little as a single line configuration change.
Encouraging Intra-Class Diversity Through a Reverse Contrastive Loss for Better Single-Source Domain Generalization
Jun 15, 2021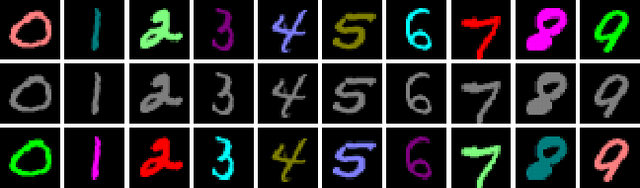
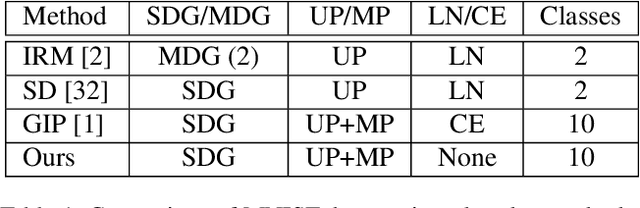
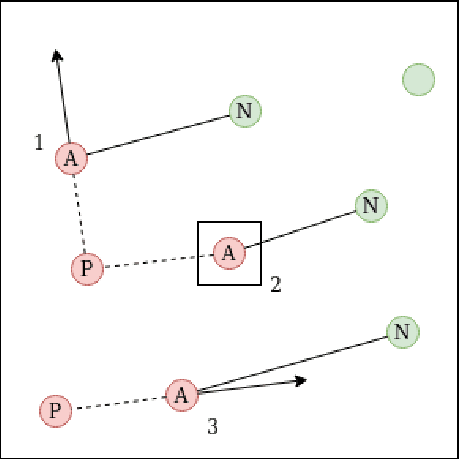
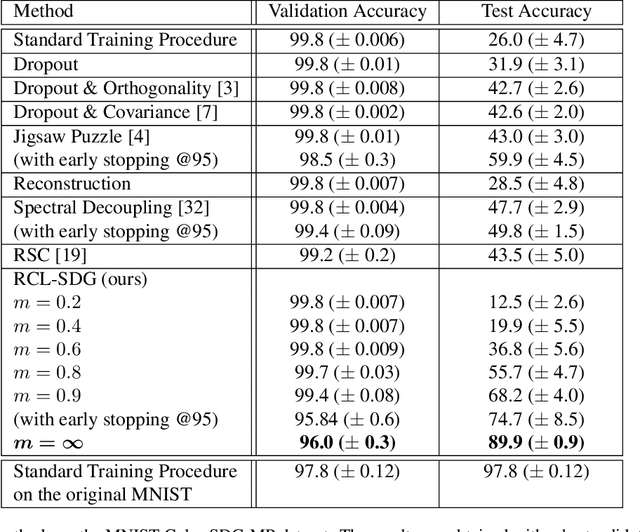
Traditional deep learning algorithms often fail to generalize when they are tested outside of the domain of training data. Because data distributions can change dynamically in real-life applications once a learned model is deployed, in this paper we are interested in single-source domain generalization (SDG) which aims to develop deep learning algorithms able to generalize from a single training domain where no information about the test domain is available at training time. Firstly, we design two simple MNISTbased SDG benchmarks, namely MNIST Color SDG-MP and MNIST Color SDG-UP, which highlight the two different fundamental SDG issues of increasing difficulties: 1) a class-correlated pattern in the training domain is missing (SDG-MP), or 2) uncorrelated with the class (SDG-UP), in the testing data domain. This is in sharp contrast with the current domain generalization (DG) benchmarks which mix up different correlation and variation factors and thereby make hard to disentangle success or failure factors when benchmarking DG algorithms. We further evaluate several state-of-the-art SDG algorithms through our simple benchmark, namely MNIST Color SDG-MP, and show that the issue SDG-MP is largely unsolved despite of a decade of efforts in developing DG algorithms. Finally, we also propose a partially reversed contrastive loss to encourage intra-class diversity and find less strongly correlated patterns, to deal with SDG-MP and show that the proposed approach is very effective on our MNIST Color SDG-MP benchmark.
CapWAP: Captioning with a Purpose
Nov 09, 2020

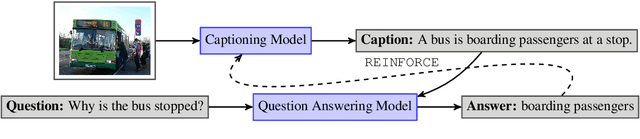

The traditional image captioning task uses generic reference captions to provide textual information about images. Different user populations, however, will care about different visual aspects of images. In this paper, we propose a new task, Captioning with a Purpose (CapWAP). Our goal is to develop systems that can be tailored to be useful for the information needs of an intended population, rather than merely provide generic information about an image. In this task, we use question-answer (QA) pairs---a natural expression of information need---from users, instead of reference captions, for both training and post-inference evaluation. We show that it is possible to use reinforcement learning to directly optimize for the intended information need, by rewarding outputs that allow a question answering model to provide correct answers to sampled user questions. We convert several visual question answering datasets into CapWAP datasets, and demonstrate that under a variety of scenarios our purposeful captioning system learns to anticipate and fulfill specific information needs better than its generic counterparts, as measured by QA performance on user questions from unseen images, when using the caption alone as context.
Global Attention for Name Tagging
Oct 19, 2020
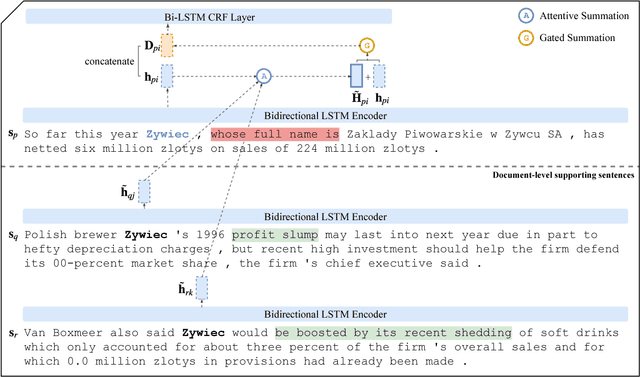
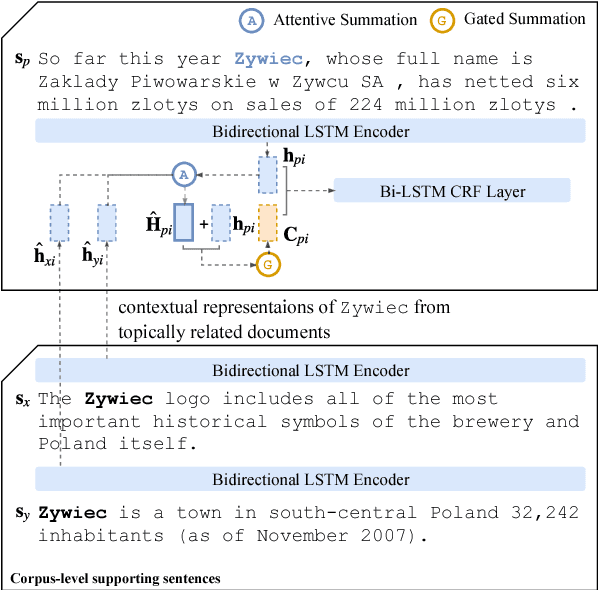
Many name tagging approaches use local contextual information with much success, but fail when the local context is ambiguous or limited. We present a new framework to improve name tagging by utilizing local, document-level, and corpus-level contextual information. We retrieve document-level context from other sentences within the same document and corpus-level context from sentences in other topically related documents. We propose a model that learns to incorporate document-level and corpus-level contextual information alongside local contextual information via global attentions, which dynamically weight their respective contextual information, and gating mechanisms, which determine the influence of this information. Extensive experiments on benchmark datasets show the effectiveness of our approach, which achieves state-of-the-art results for Dutch, German, and Spanish on the CoNLL-2002 and CoNLL-2003 datasets.