 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-Neighbors Also Matter to Kriging: A New Contrastive-Prototypical Learning
Jan 23, 2024
Kriging aims at estimating the attributes of unsampled geo-locations from observations in the spatial vicinity or physical connections, which helps mitigate skewed monitoring caused by under-deployed sensors. Existing works assume that neighbors' information offers the basis for estimating the attributes of the unobserved target while ignoring non-neighbors. However, non-neighbors could also offer constructive information, and neighbors could also be misleading. To this end, we propose ``Contrastive-Prototypical'' self-supervised learning for Kriging (KCP) to refine valuable information from neighbors and recycle the one from non-neighbors. As a pre-trained paradigm, we conduct the Kriging task from a new perspective of representation: we aim to first learn robust and general representations and then recover attributes from representations. A neighboring contrastive module is designed that coarsely learns the representations by narrowing the representation distance between the target and its neighbors while pushing away the non-neighbors. In parallel, a prototypical module is introduced to identify similar representations via exchanged prediction, thus refining the misleading neighbors and recycling the useful non-neighbors from the neighboring contrast component. As a result, not all the neighbors and some of the non-neighbors will be used to infer the target. To encourage the two modules above to learn general and robust representations, we design an adaptive augmentation module that incorporates data-driven attribute augmentation and centrality-based topology augmentation over the spatiotemporal Kriging graph data. Extensive experiments on real-world datasets demonstrate the superior performance of KCP compared to its peers with 6% improvements and exceptional transferability and robustness. The code is available at https://github.com/bonaldli/KCP
ARCNet: An Asymmetric Residual Wavelet Column Correction Network for Infrared Image Destriping
Jan 28, 2024Infrared image destriping seeks to restore high-quality content from degraded images. Recent works mainly address this task by leveraging prior knowledge to separate stripe noise from the degraded image. However, constructing a robust decoupling model for that purpose remains challenging, especially when significant similarities exist between the stripe noise and vertical background structure. Addressing that, we introduce Asymmetric Residual wavelet Column correction Network (ARCNet) for image destriping, aiming to consistently preserve spatially precise high-resolution representations. Our neural model leverages a novel downsampler, residual haar discrete wavelet transform (RHDWT), stripe directional prior knowledge and data-driven learning to induce a model with enriched feature representation of stripe noise and background. In our technique, the inverse wavelet transform is replaced by transposed convolution for feature upsampling, which can suppress noise crosstalk and encourage the network to focus on robust image reconstruction. After each sampling, a proposed column non-uniformity correction module (CNCM) is leveraged by our method to enhance column uniformity, spatial correlation, and global self-dependence between each layer component. CNCM can establish structural characteristics of stripe noise and utilize contextual information at long-range dependencies to distinguish stripes with varying intensities and distributions. Extensive experiments on synthetic data, real data, and infrared small target detection tasks show that the proposed method outperforms state-of-the-art single-image destriping methods both visually and quantitatively by a considerable margin. Our code will be made publicly available at \url{https://github.com/xdFai}.
Evaluating Gender Bias in Large Language Models via Chain-of-Thought Prompting
Jan 28, 2024There exist both scalable tasks, like reading comprehension and fact-checking, where model performance improves with model size, and unscalable tasks, like arithmetic reasoning and symbolic reasoning, where model performance does not necessarily improve with model size. Large language models (LLMs) equipped with Chain-of-Thought (CoT) prompting are able to make accurate incremental predictions even on unscalable tasks. Unfortunately, despite their exceptional reasoning abilities, LLMs tend to internalize and reproduce discriminatory societal biases. Whether CoT can provide discriminatory or egalitarian rationalizations for the implicit information in unscalable tasks remains an open question. In this study, we examine the impact of LLMs' step-by-step predictions on gender bias in unscalable tasks. For this purpose, we construct a benchmark for an unscalable task where the LLM is given a list of words comprising feminine, masculine, and gendered occupational words, and is required to count the number of feminine and masculine words. In our CoT prompts, we require the LLM to explicitly indicate whether each word in the word list is a feminine or masculine before making the final predictions. With counting and handling the meaning of words, this benchmark has characteristics of both arithmetic reasoning and symbolic reasoning. Experimental results in English show that without step-by-step prediction, most LLMs make socially biased predictions, despite the task being as simple as counting words. Interestingly, CoT prompting reduces this unconscious social bias in LLMs and encourages fair predictions.
Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition
Jan 25, 2024Unsupervised skeleton based action recognition has achieved remarkable progress recently. Existing unsupervised learning methods suffer from severe overfitting problem, and thus small networks are used, significantly reducing the representation capability. To address this problem, the overfitting mechanism behind the unsupervised learning for skeleton based action recognition is first investigated. It is observed that the skeleton is already a relatively high-level and low-dimension feature, but not in the same manifold as the features for action recognition. Simply applying the existing unsupervised learning method may tend to produce features that discriminate the different samples instead of action classes, resulting in the overfitting problem. To solve this problem, this paper presents an Unsupervised spatial-temporal Feature Enrichment and Fidelity Preservation framework (U-FEFP) to generate rich distributed features that contain all the information of the skeleton sequence. A spatial-temporal feature transformation subnetwork is developed using spatial-temporal graph convolutional network and graph convolutional gate recurrent unit network as the basic feature extraction network. The unsupervised Bootstrap Your Own Latent based learning is used to generate rich distributed features and the unsupervised pretext task based learning is used to preserve the information of the skeleton sequence. The two unsupervised learning ways are collaborated as U-FEFP to produce robust and discriminative representations. Experimental results on three widely used benchmarks, namely NTU-RGB+D-60, NTU-RGB+D-120 and PKU-MMD dataset, demonstrate that the proposed U-FEFP achieves the best performance compared with the state-of-the-art unsupervised learning methods. t-SNE illustrations further validate that U-FEFP can learn more discriminative features for unsupervised skeleton based action recognition.
Conditional Neural Video Coding with Spatial-Temporal Super-Resolution
Jan 25, 2024This document is an expanded version of a one-page abstract originally presented at the 2024 Data Compression Conference. It describes our proposed method for the video track of the Challenge on Learned Image Compression (CLIC) 2024. Our scheme follows the typical hybrid coding framework with some novel techniques. Firstly, we adopt Spynet network to produce accurate motion vectors for motion estimation. Secondly, we introduce the context mining scheme with conditional frame coding to fully exploit the spatial-temporal information. As for the low target bitrates given by CLIC, we integrate spatial-temporal super-resolution modules to improve rate-distortion performance. Our team name is IMCLVC.
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024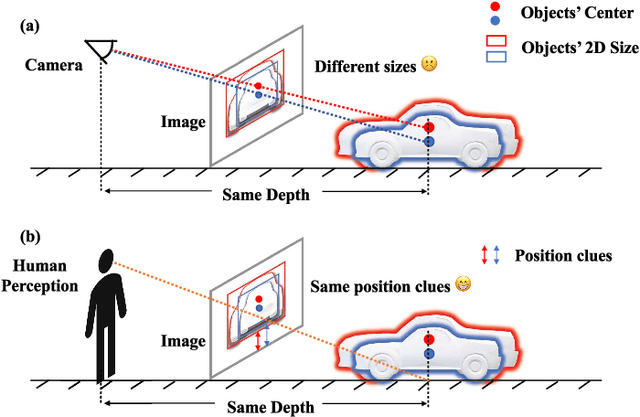
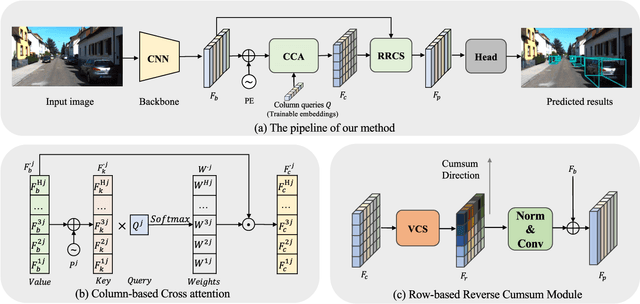
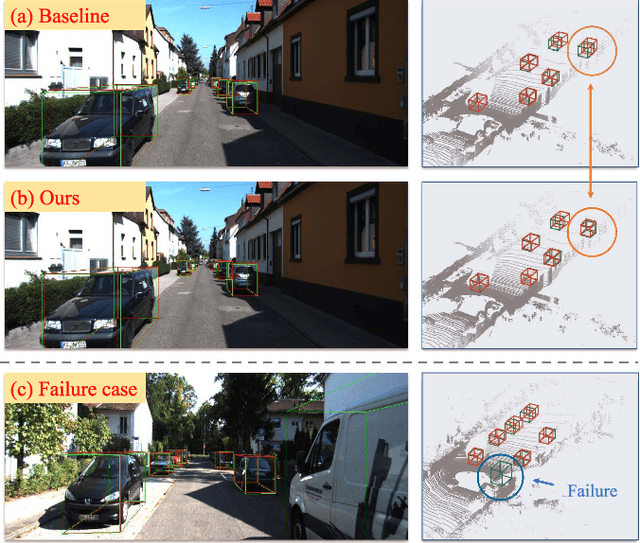
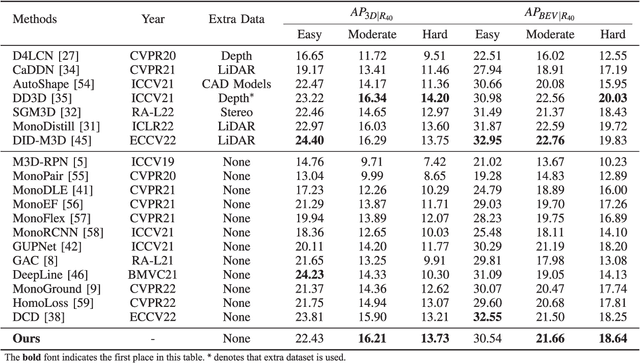
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
Jan 27, 2024Federated reinforcement learning (FRL) has emerged as a promising paradigm for reducing the sample complexity of reinforcement learning tasks by exploiting information from different agents. However, when each agent interacts with a potentially different environment, little to nothing is known theoretically about the non-asymptotic performance of FRL algorithms. The lack of such results can be attributed to various technical challenges and their intricate interplay: Markovian sampling, linear function approximation, multiple local updates to save communication, heterogeneity in the reward functions and transition kernels of the agents' MDPs, and continuous state-action spaces. Moreover, in the on-policy setting, the behavior policies vary with time, further complicating the analysis. In response, we introduce FedSARSA, a novel federated on-policy reinforcement learning scheme, equipped with linear function approximation, to address these challenges and provide a comprehensive finite-time error analysis. Notably, we establish that FedSARSA converges to a policy that is near-optimal for all agents, with the extent of near-optimality proportional to the level of heterogeneity. Furthermore, we prove that FedSARSA leverages agent collaboration to enable linear speedups as the number of agents increases, which holds for both fixed and adaptive step-size configurations.
STAC: Leveraging Spatio-Temporal Data Associations For Efficient Cross-Camera Streaming and Analytics
Jan 27, 2024We propose an efficient cross-cameras surveillance system called,STAC, that leverages spatio-temporal associations between multiple cameras to provide real-time analytics and inference under constrained network environments. STAC is built using the proposed omni-scale feature learning people reidentification (reid) algorithm that allows accurate detection, tracking and re-identification of people across cameras using the spatio-temporal characteristics of video frames. We integrate STAC with frame filtering and state-of-the-art compression for streaming technique (that is, ffmpeg libx264 codec) to remove redundant information from cross-camera frames. This helps in optimizing the cost of video transmission as well as compute/processing, while maintaining high accuracy for real-time query inference. The introduction of AICity Challenge 2023 Data [1] by NVIDIA has allowed exploration of systems utilizing multi-camera people tracking algorithms. We evaluate the performance of STAC using this dataset to measure the accuracy metrics and inference rate for reid. Additionally, we quantify the reduction in video streams achieved through frame filtering and compression using FFmpeg compared to the raw camera streams. For completeness, we make available our repository to reproduce the results, available at https://github.com/VolodymyrVakhniuk/CS444_Final_Project.
SkipViT: Speeding Up Vision Transformers with a Token-Level Skip Connection
Jan 27, 2024Vision transformers are known to be more computationally and data-intensive than CNN models. These transformer models such as ViT, require all the input image tokens to learn the relationship among them. However, many of these tokens are not informative and may contain irrelevant information such as unrelated background or unimportant scenery. These tokens are overlooked by the multi-head self-attention (MHSA), resulting in many redundant and unnecessary computations in MHSA and the feed-forward network (FFN). In this work, we propose a method to optimize the amount of unnecessary interactions between unimportant tokens by separating and sending them through a different low-cost computational path. Our method does not add any parameters to the ViT model and aims to find the best trade-off between training throughput and achieving a 0% loss in the Top-1 accuracy of the final model. Our experimental results on training ViT-small from scratch show that SkipViT is capable of effectively dropping 55% of the tokens while gaining more than 13% training throughput and maintaining classification accuracy at the level of the baseline model on Huawei Ascend910A.
WAL-Net: Weakly supervised auxiliary task learning network for carotid plaques classification
Jan 27, 2024The classification of carotid artery ultrasound images is a crucial means for diagnosing carotid plaques, holding significant clinical relevance for predicting the risk of stroke. Recent research suggests that utilizing plaque segmentation as an auxiliary task for classification can enhance performance by leveraging the correlation between segmentation and classification tasks. However, this approach relies on obtaining a substantial amount of challenging-to-acquire segmentation annotations. This paper proposes a novel weakly supervised auxiliary task learning network model (WAL-Net) to explore the interdependence between carotid plaque classification and segmentation tasks. The plaque classification task is primary task, while the plaque segmentation task serves as an auxiliary task, providing valuable information to enhance the performance of the primary task. Weakly supervised learning is adopted in the auxiliary task to completely break away from the dependence on segmentation annotations. Experiments and evaluations are conducted on a dataset comprising 1270 carotid plaque ultrasound images from Wuhan University Zhongnan Hospital. Results indicate that the proposed method achieved an approximately 1.3% improvement in carotid plaque classification accuracy compared to the baseline network. Specifically, the accuracy of mixed-echoic plaques classification increased by approximately 3.3%, demonstrating the effectiveness of our approach.