 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coupled Feature Learning for Multimodal Medical Image Fusion
Feb 17, 2021
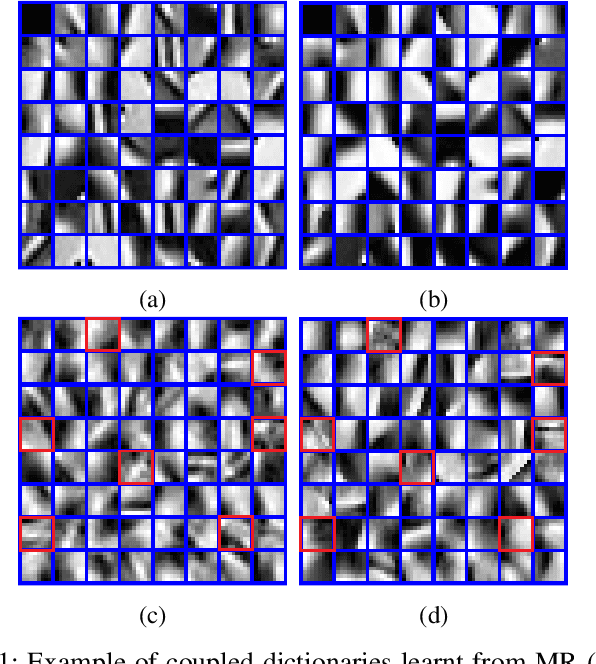
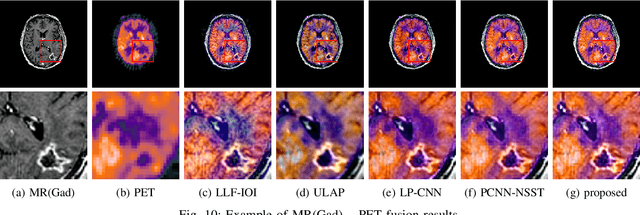
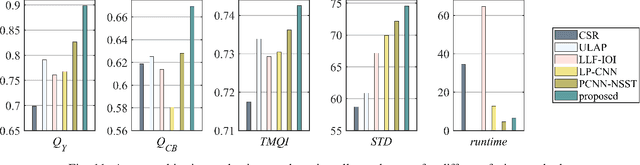
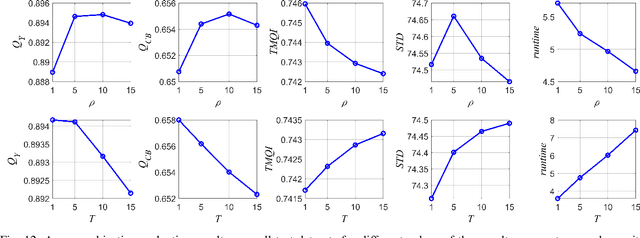
Multimodal image fusion aims to combine relevant information from images acquired with different sensors. In medical imaging, fused images play an essential role in both standard and automated diagnosis. In this paper, we propose a novel multimodal image fusion method based on coupled dictionary learning. The proposed method is general and can be employed for different medical imaging modalities. Unlike many current medical fusion methods, the proposed approach does not suffer from intensity attenuation nor loss of critical information. Specifically, the images to be fused are decomposed into coupled and independent components estimated using sparse representations with identical supports and a Pearson correlation constraint, respectively. An alternating minimization algorithm is designed to solve the resulting optimization problem. The final fusion step uses the max-absolute-value rule. Experiments are conducted using various pairs of multimodal inputs, including real MR-CT and MR-PET images. The resulting performance and execution times show the competitiveness of the proposed method in comparison with state-of-the-art medical image fusion methods.
A Generalized A* Algorithm for Finding Globally Optimal Paths in Weighted Colored Graphs
Dec 24, 2020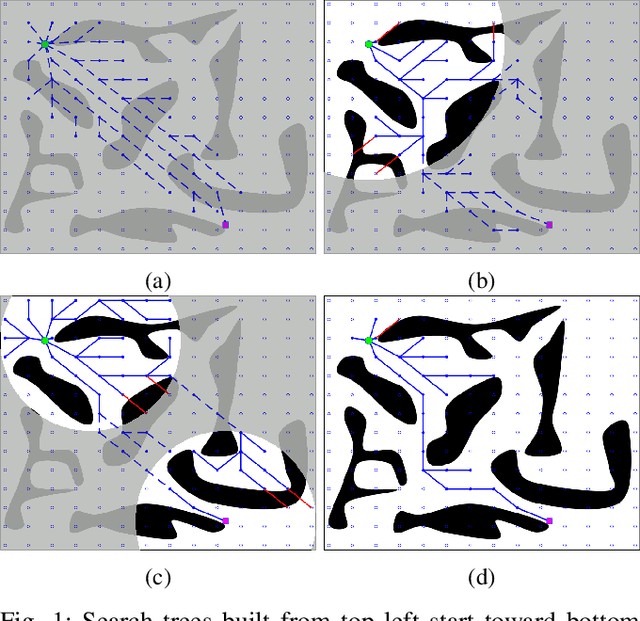
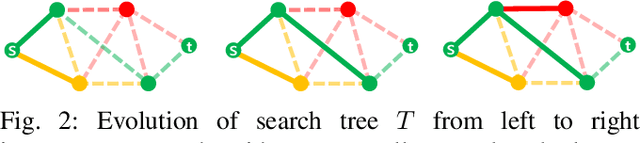
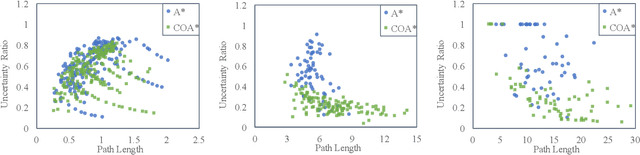
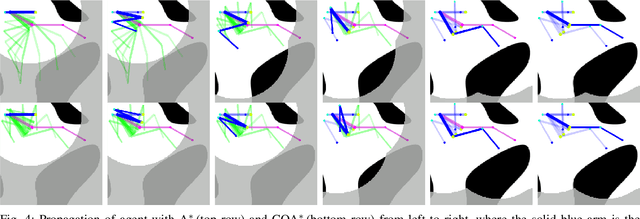
Both geometric and semantic information of the search space is imperative for a good plan. We encode those properties in a weighted colored graph (geometric information in terms of edge weight and semantic information in terms of edge and vertex color), and propose a generalized A* to find the shortest path among the set of paths with minimal inclusion of low-ranked color edges. We prove the completeness and optimality of this Class-Ordered A* (COA*) algorithm with respect to the hereto defined notion of optimality. The utility of COA* is numerically validated in a ternary graph with feasible, infeasible, and unknown vertices and edges for the cases of a 2D mobile robot, a 3D robotic arm, and a 5D robotic arm with limited sensing capabilities. We compare the results of COA* to that of the regular A* algorithm, the latter of which finds the shortest path regardless of uncertainty, and we show that the COA* dominates the A* solution in terms of finding less uncertain paths.
Demystifying the Better Performance of Position Encoding Variants for Transformer
Apr 18, 2021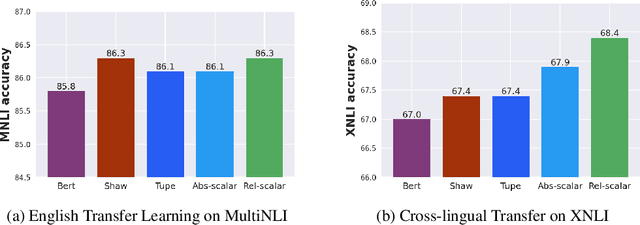

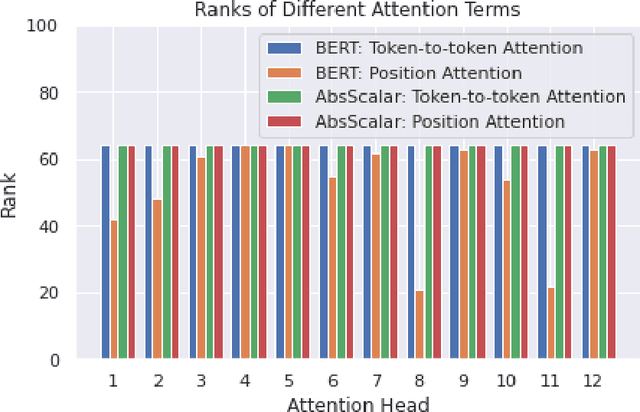

Transformers are state of the art models in NLP that map a given input sequence of vectors to an output sequence of vectors. However these models are permutation equivariant, and additive position embeddings to the input are used to supply the information about the order of the input tokens. Further, for some tasks, additional additive segment embeddings are used to denote different types of input sentences. Recent works proposed variations of positional encodings with relative position encodings achieving better performance. In this work, we do a systematic study comparing different position encodings and understanding the reasons for differences in their performance. We demonstrate a simple yet effective way to encode position and segment into the Transformer models. The proposed method performs on par with SOTA on GLUE, XTREME and WMT benchmarks while saving computation costs.
Self-harm: detection and support on Twitter
Apr 01, 2021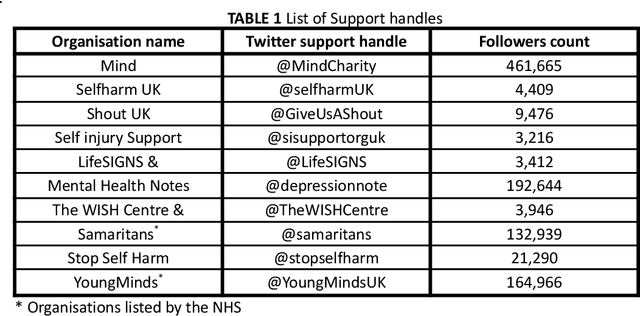
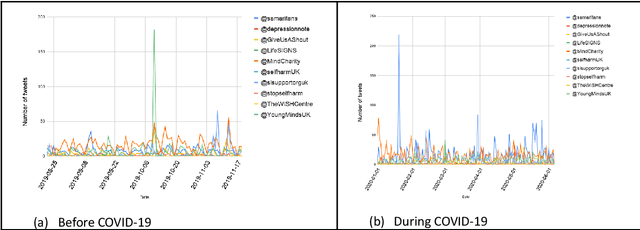
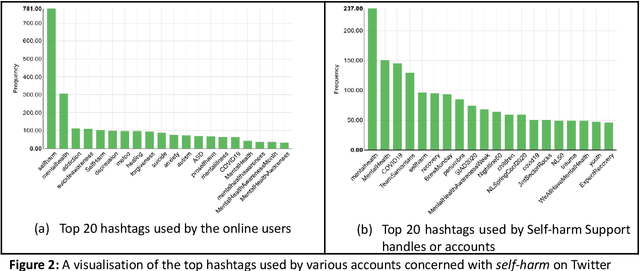
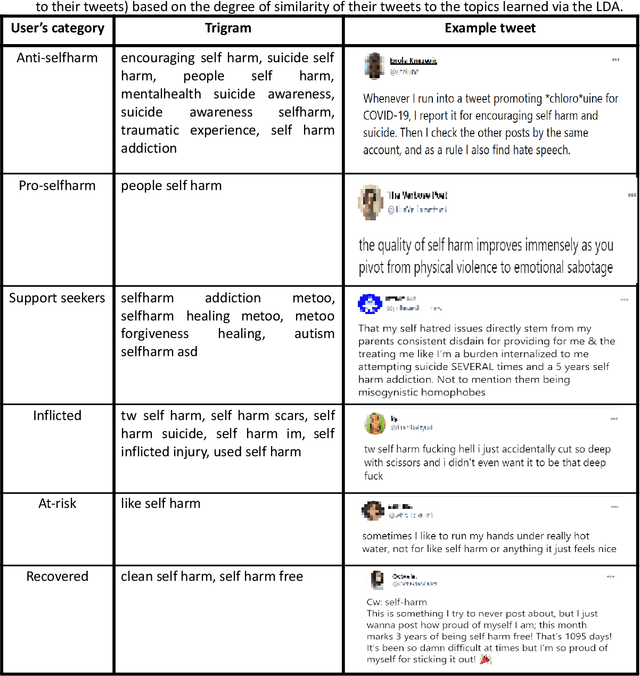
Since the advent of online social media platforms such as Twitter and Facebook, useful health-related studies have been conducted using the information posted by online participants. Personal health-related issues such as mental health, self-harm and depression have been studied because users often share their stories on such platforms. Online users resort to sharing because the empathy and support from online communities are crucial in helping the affected individuals. A preliminary analysis shows how contents related to non-suicidal self-injury (NSSI) proliferate on Twitter. Thus, we use Twitter to collect relevant data, analyse, and proffer ways of supporting users prone to NSSI behaviour. Our approach utilises a custom crawler to retrieve relevant tweets from self-reporting users and relevant organisations interested in combating self-harm. Through textual analysis, we identify six major categories of self-harming users consisting of inflicted, anti-self-harm, support seekers, recovered, pro-self-harm and at risk. The inflicted category dominates the collection. From an engagement perspective, we show how online users respond to the information posted by self-harm support organisations on Twitter. By noting the most engaged organisations, we apply a useful technique to uncover the organisations' strategy. The online participants show a strong inclination towards online posts associated with mental health related attributes. Our study is based on the premise that social media can be used as a tool to support proactive measures to ease the negative impact of self-harm. Consequently, we proffer ways to prevent potential users from engaging in self-harm and support affected users through a set of recommendations. To support further research, the dataset will be made available for interested researchers.
Differentiable Patch Selection for Image Recognition
Apr 07, 2021
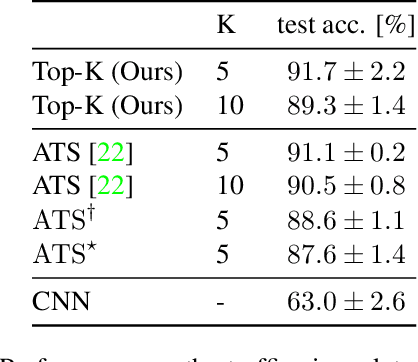
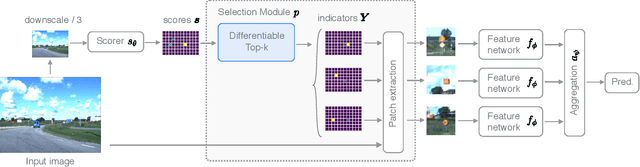
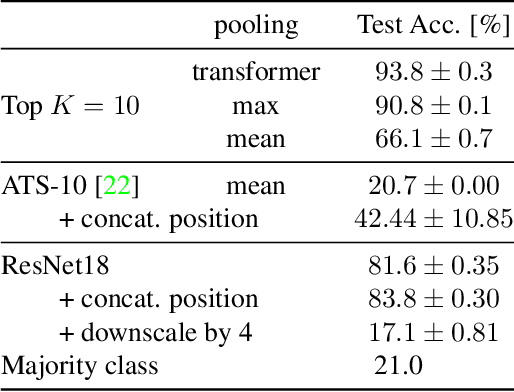
Neural Networks require large amounts of memory and compute to process high resolution images, even when only a small part of the image is actually informative for the task at hand. We propose a method based on a differentiable Top-K operator to select the most relevant parts of the input to efficiently process high resolution images. Our method may be interfaced with any downstream neural network, is able to aggregate information from different patches in a flexible way, and allows the whole model to be trained end-to-end using backpropagation. We show results for traffic sign recognition, inter-patch relationship reasoning, and fine-grained recognition without using object/part bounding box annotations during training.
HyperRNN: Deep Learning-Aided Downlink CSI Acquisition via Partial Channel Reciprocity for FDD Massive MIMO
May 02, 2021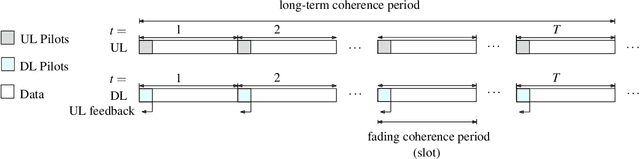
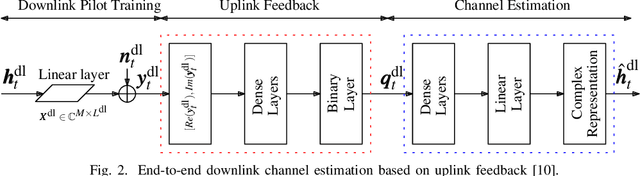
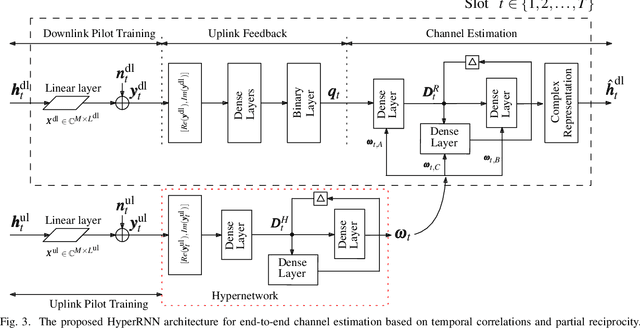
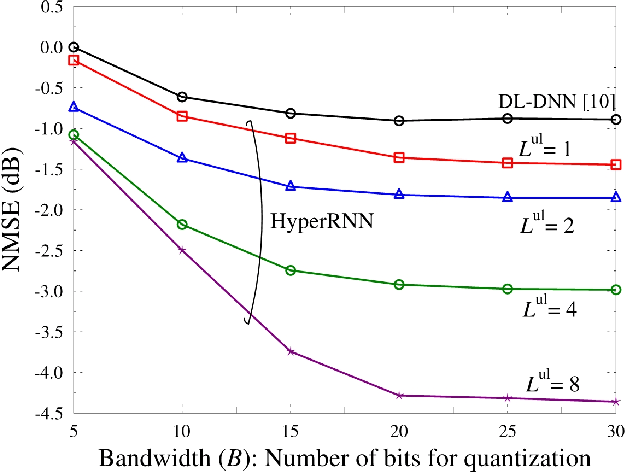
In order to unlock the full advantages of massive multiple input multiple output (MIMO) in the downlink, channel state information (CSI) is required at the base station (BS) to optimize the beamforming matrices. In frequency division duplex (FDD) systems, full channel reciprocity does not hold, and CSI acquisition generally requires downlink pilot transmission followed by uplink feedback. Prior work proposed the end-to-end design of pilot transmission, feedback, and CSI estimation via deep learning. In this work, we introduce an enhanced end-to-end design that leverages partial uplink-downlink reciprocity and temporal correlation of the fading processes by utilizing jointly downlink and uplink pilots. The proposed method is based on a novel deep learning architecture -- HyperRNN -- that combines hypernetworks and recurrent neural networks (RNNs) to optimize the transfer of long-term channel features from uplink to downlink. Simulation results demonstrate that the HyperRNN achieves a lower normalized mean square error (NMSE) performance, and that it reduces requirements in terms of pilot lengths.
Subspace Representation Learning for Few-shot Image Classification
May 02, 2021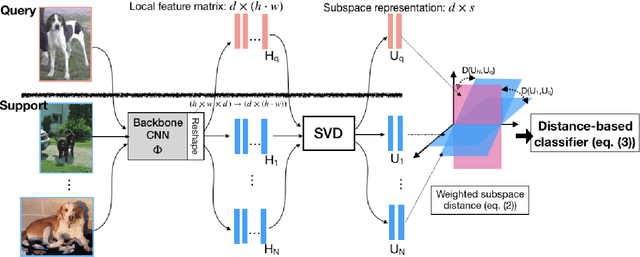
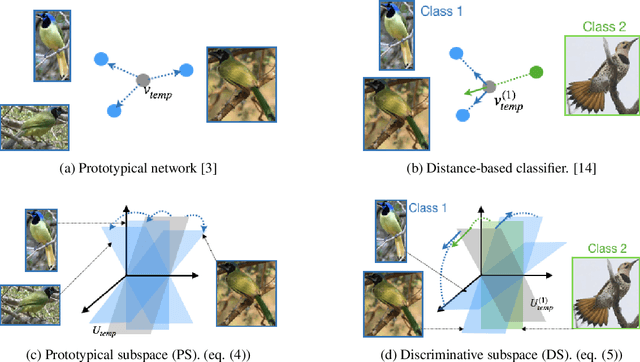
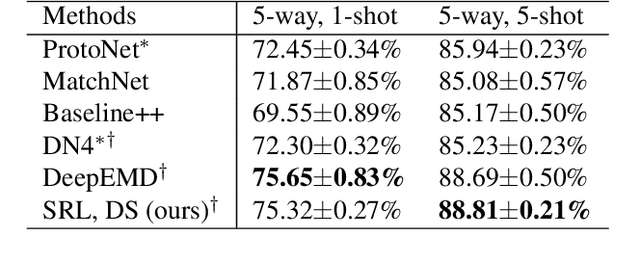
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021



Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
Leveraging Two Types of Global Graph for Sequential Fashion Recommendation
May 18, 2021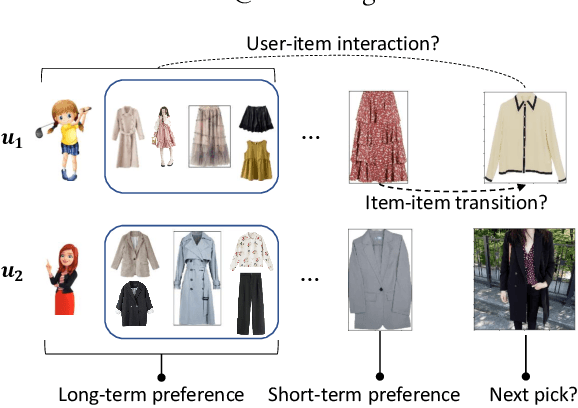
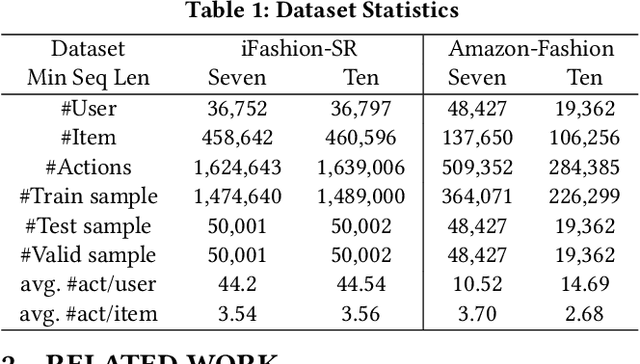
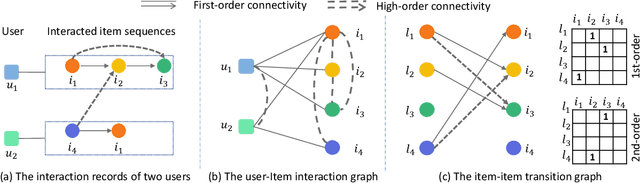
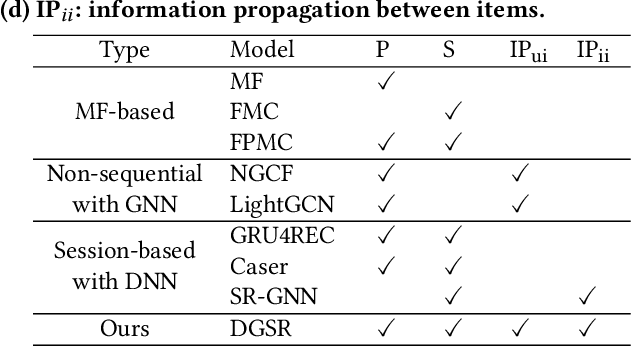
Sequential fashion recommendation is of great significance in online fashion shopping, which accounts for an increasing portion of either fashion retailing or online e-commerce. The key to building an effective sequential fashion recommendation model lies in capturing two types of patterns: the personal fashion preference of users and the transitional relationships between adjacent items. The two types of patterns are usually related to user-item interaction and item-item transition modeling respectively. However, due to the large sets of users and items as well as the sparse historical interactions, it is difficult to train an effective and efficient sequential fashion recommendation model. To tackle these problems, we propose to leverage two types of global graph, i.e., the user-item interaction graph and item-item transition graph, to obtain enhanced user and item representations by incorporating higher-order connections over the graphs. In addition, we adopt the graph kernel of LightGCN for the information propagation in both graphs and propose a new design for item-item transition graph. Extensive experiments on two established sequential fashion recommendation datasets validate the effectiveness and efficiency of our approach.
Online Preselection with Context Information under the Plackett-Luce Model
Feb 11, 2020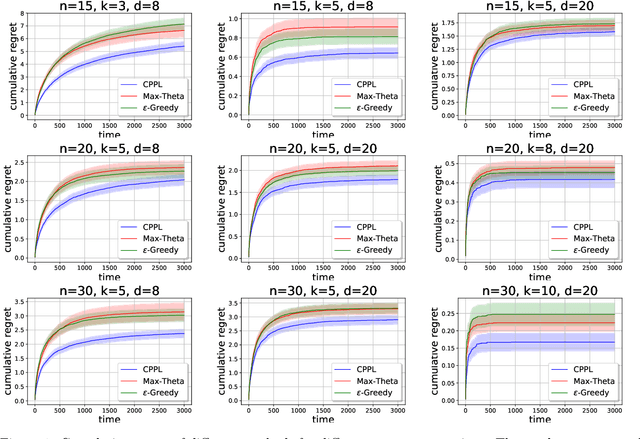
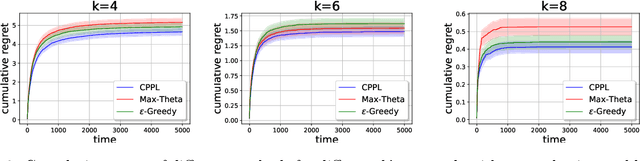
We consider an extension of the contextual multi-armed bandit problem, in which, instead of selecting a single alternative (arm), a learner is supposed to make a preselection in the form of a subset of alternatives. More specifically, in each iteration, the learner is presented a set of arms and a context, both described in terms of feature vectors. The task of the learner is to preselect $k$ of these arms, among which a final choice is made in a second step. In our setup, we assume that each arm has a latent (context-dependent) utility, and that feedback on a preselection is produced according to a Plackett-Luce model. We propose the CPPL algorithm, which is inspired by the well-known UCB algorithm, and evaluate this algorithm on synthetic and real data. In particular, we consider an online algorithm selection scenario, which served as a main motivation of our problem setting. Here, an instance (which defines the context) from a certain problem class (such as SAT) can be solved by different algorithms (the arms), but only $k$ of these algorithms can actually be run.