 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Unsupervised Hashing by Distilled Smooth Guidance
May 13, 2021
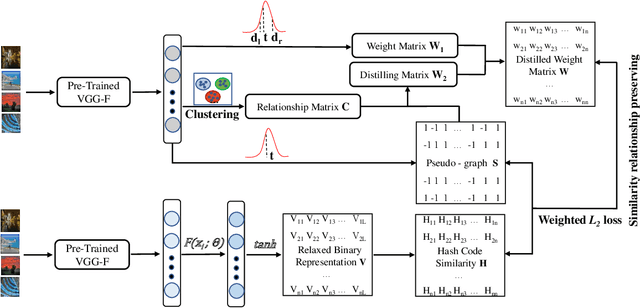
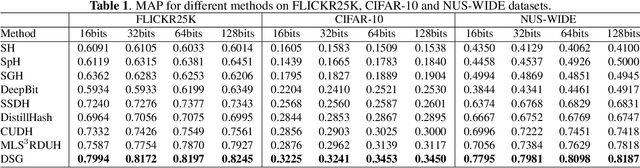

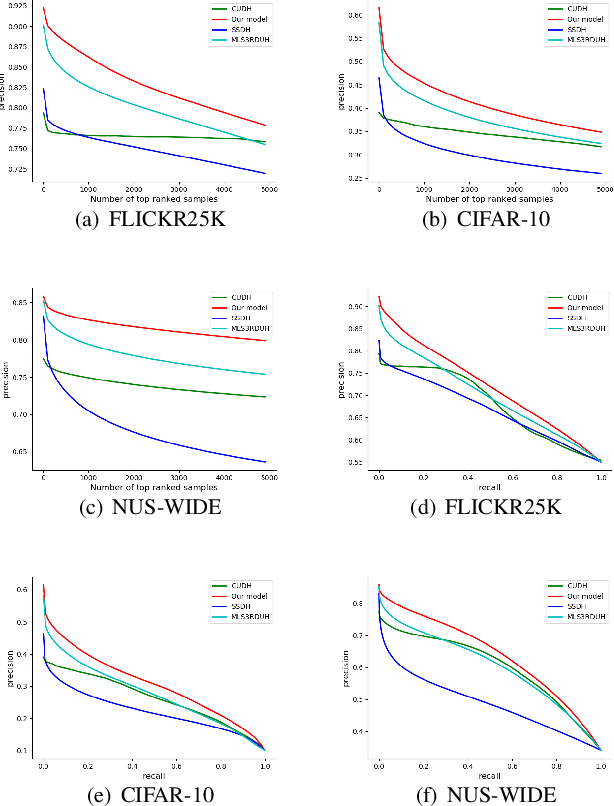
Hashing has been widely used in approximate nearest neighbor search for its storage and computational efficiency. Deep supervised hashing methods are not widely used because of the lack of labeled data, especially when the domain is transferred. Meanwhile, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable similarity signals. To tackle this problem, we propose a novel deep unsupervised hashing method, namely Distilled Smooth Guidance (DSG), which can learn a distilled dataset consisting of similarity signals as well as smooth confidence signals. To be specific, we obtain the similarity confidence weights based on the initial noisy similarity signals learned from local structures and construct a priority loss function for smooth similarity-preserving learning. Besides, global information based on clustering is utilized to distill the image pairs by removing contradictory similarity signals. Extensive experiments on three widely used benchmark datasets show that the proposed DSG consistently outperforms the state-of-the-art search methods.
* 7 pages, 3 figures
Accessing accurate documents by mining auxiliary document information
Apr 15, 2016
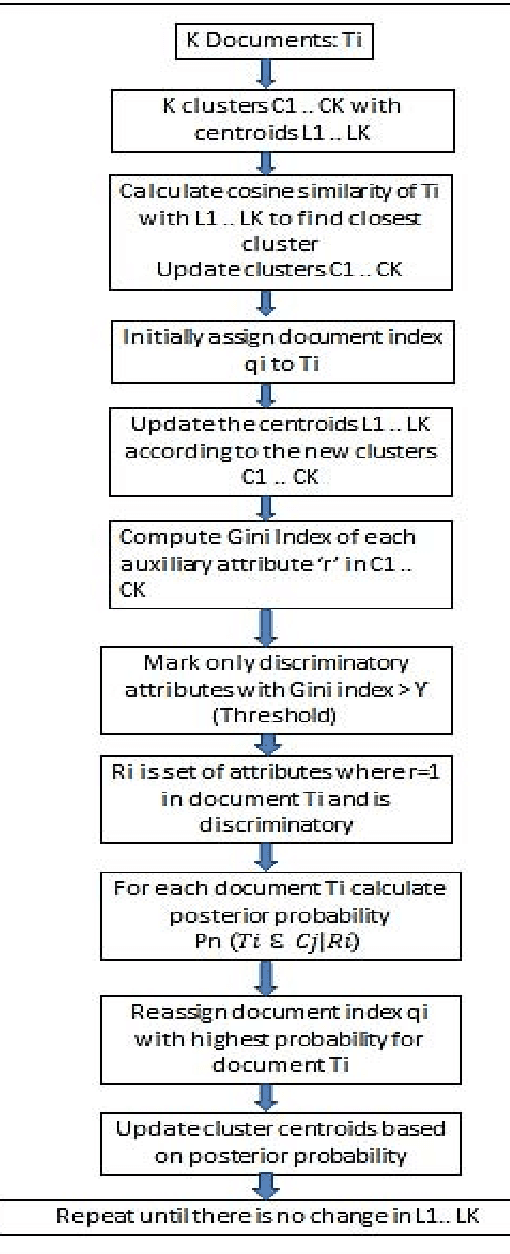
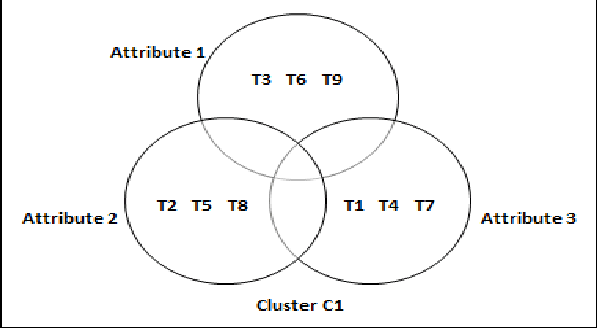
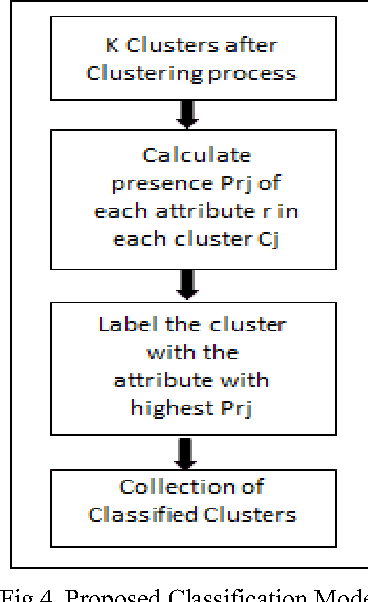
Earlier techniques of text mining included algorithms like k-means, Naive Bayes, SVM which classify and cluster the text document for mining relevant information about the documents. The need for improving the mining techniques has us searching for techniques using the available algorithms. This paper proposes one technique which uses the auxiliary information that is present inside the text documents to improve the mining. This auxiliary information can be a description to the content. This information can be either useful or completely useless for mining. The user should assess the worth of the auxiliary information before considering this technique for text mining. In this paper, a combination of classical clustering algorithms is used to mine the datasets. The algorithm runs in two stages which carry out mining at different levels of abstraction. The clustered documents would then be classified based on the necessary groups. The proposed technique is aimed at improved results of document clustering.
Feedback Coding for Active Learning
Feb 28, 2021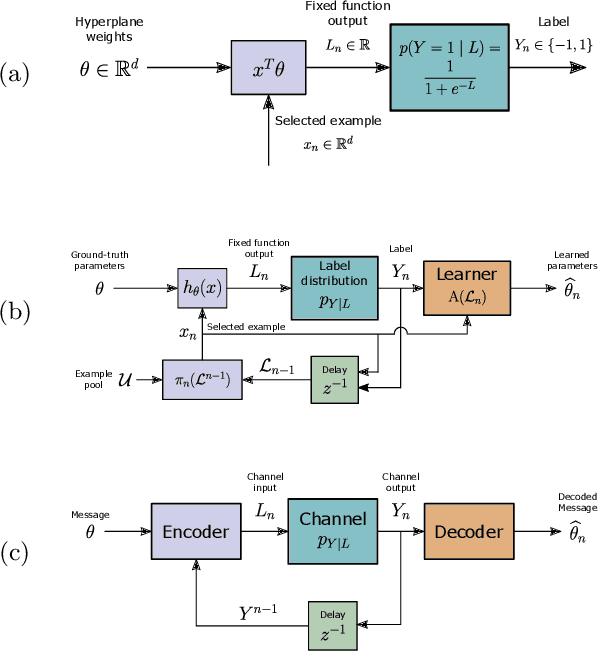
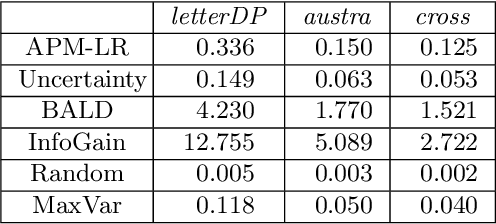
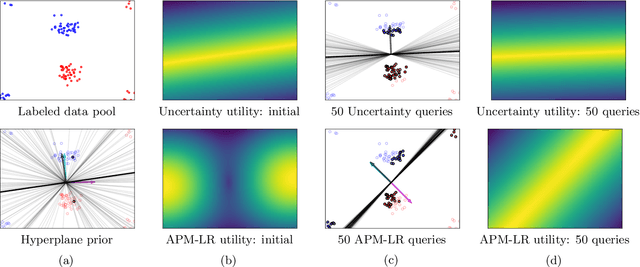
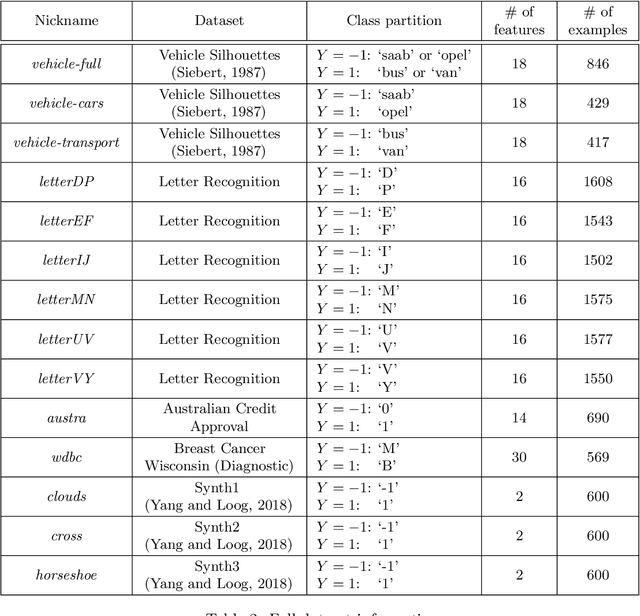
The iterative selection of examples for labeling in active machine learning is conceptually similar to feedback channel coding in information theory: in both tasks, the objective is to seek a minimal sequence of actions to encode information in the presence of noise. While this high-level overlap has been previously noted, there remain open questions on how to best formulate active learning as a communications system to leverage existing analysis and algorithms in feedback coding. In this work, we formally identify and leverage the structural commonalities between the two problems, including the characterization of encoder and noisy channel components, to design a new algorithm. Specifically, we develop an optimal transport-based feedback coding scheme called Approximate Posterior Matching (APM) for the task of active example selection and explore its application to Bayesian logistic regression, a popular model in active learning. We evaluate APM on a variety of datasets and demonstrate learning performance comparable to existing active learning methods, at a reduced computational cost. These results demonstrate the potential of directly deploying concepts from feedback channel coding to design efficient active learning strategies.
Video-Streaming Biomedical Implants using Ultrasonic Waves for Communication
Jun 28, 2021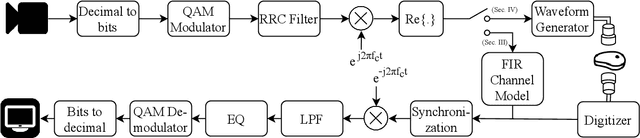
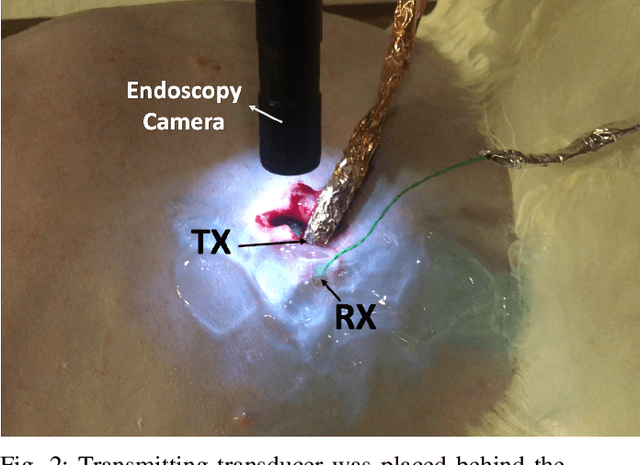


The use of wireless implanted medical devices (IMDs) is growing because they facilitate continuous monitoring of patients during normal activities, simplify medical procedures required for data retrieval and reduce the likelihood of infection associated with trailing wires. However, most of the state-of-the-art IMDs are passive and offline devices. One of the key obstacles to an active and online IMD is the infeasibility of real-time, high-quality video broadcast from the IMD. Such broadcast would help develop innovative devices such as a video-streaming capsule endoscopy (CE) pill with therapeutic intervention capabilities. State-of-the-art IMDs employ radio-frequency electromagnetic waves for information transmission. However, high attenuation of RF-EM waves in tissues and federal restrictions on the transmit power and operable bandwidth lead to fundamental performance constraints for IMDs employing RF links, and prevent achieving high data rates that could accomodate video broadcast. In this work, ultrasonic waves were used for video transmission and broadcast through biological tissues. The proposed proof-of-concept system was tested on a porcine intestine ex vivo and a rabbit in vivo. It was demonstrated that using a millimeter-sized, implanted biocompatible transducer operating at 1.1-1.2 MHz, it was possible to transmit endoscopic video with high resolution (1280 pixels by 720 pixels) through porcine intestine wrapped with bacon, and to broadcast standard definition (640 pixels by 480 pixels) video near real-time through rabbit abdomen in vivo. A media repository that includes experimental demonstrations and media files accompanies this paper. The accompanying media repository can be found at this link: https://bit.ly/3wuc7tk.
Estimating mutual information in high dimensions via classification error
Oct 10, 2016
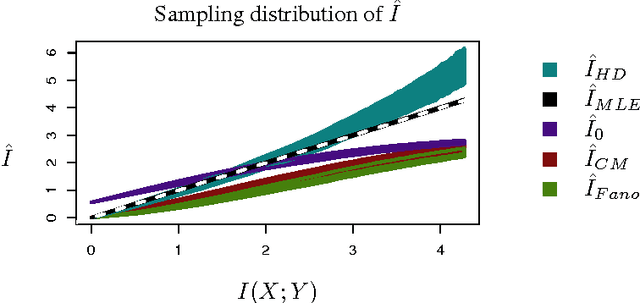
Multivariate pattern analyses approaches in neuroimaging are fundamentally concerned with investigating the quantity and type of information processed by various regions of the human brain; typically, estimates of classification accuracy are used to quantify information. While a extensive and powerful library of methods can be applied to train and assess classifiers, it is not always clear how to use the resulting measures of classification performance to draw scientific conclusions: e.g. for the purpose of evaluating redundancy between brain regions. An additional confound for interpreting classification performance is the dependence of the error rate on the number and choice of distinct classes obtained for the classification task. In contrast, mutual information is a quantity defined independently of the experimental design, and has ideal properties for comparative analyses. Unfortunately, estimating the mutual information based on observations becomes statistically infeasible in high dimensions without some kind of assumption or prior. In this paper, we construct a novel classification-based estimator of mutual information based on high-dimensional asymptotics. We show that in a particular limiting regime, the mutual information is an invertible function of the expected $k$-class Bayes error. While the theory is based on a large-sample, high-dimensional limit, we demonstrate through simulations that our proposed estimator has superior performance to the alternatives in problems of moderate dimensionality.
VisioRed: A Visualisation Tool for Interpretable Predictive Maintenance
Mar 31, 2021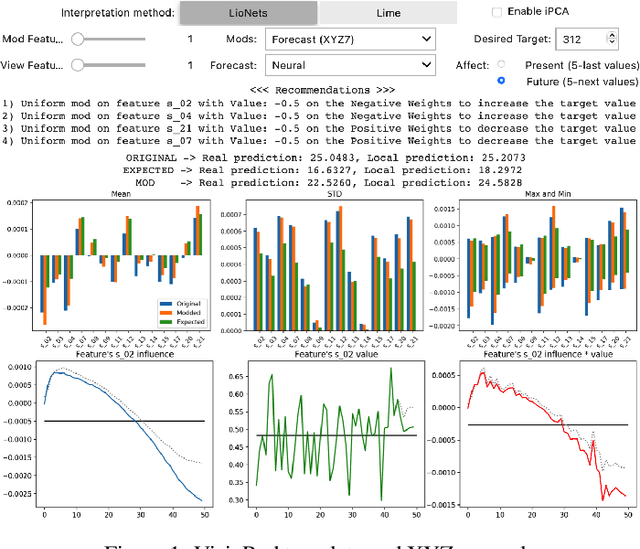
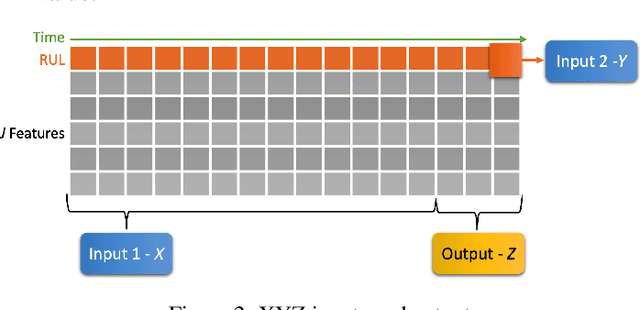
The use of machine learning rapidly increases in high-risk scenarios where decisions are required, for example in healthcare or industrial monitoring equipment. In crucial situations, a model that can offer meaningful explanations of its decision-making is essential. In industrial facilities, the equipment's well-timed maintenance is vital to ensure continuous operation to prevent money loss. Using machine learning, predictive and prescriptive maintenance attempt to anticipate and prevent eventual system failures. This paper introduces a visualisation tool incorporating interpretations to display information derived from predictive maintenance models, trained on time-series data.
Learning Multi-agent Implicit Communication Through Actions: A Case Study in Contract Bridge, a Collaborative Imperfect-Information Game
Oct 10, 2018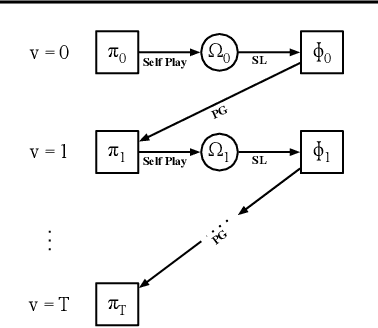

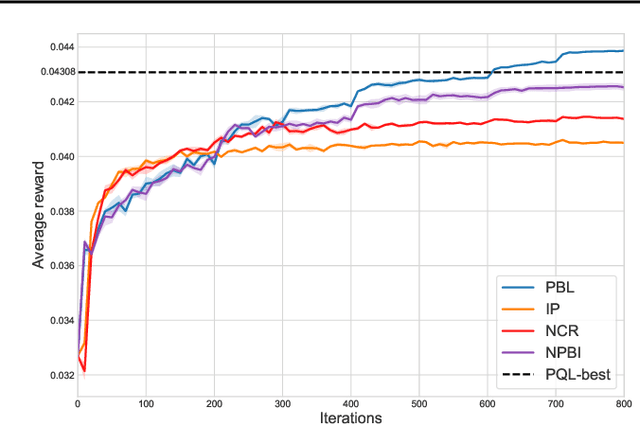
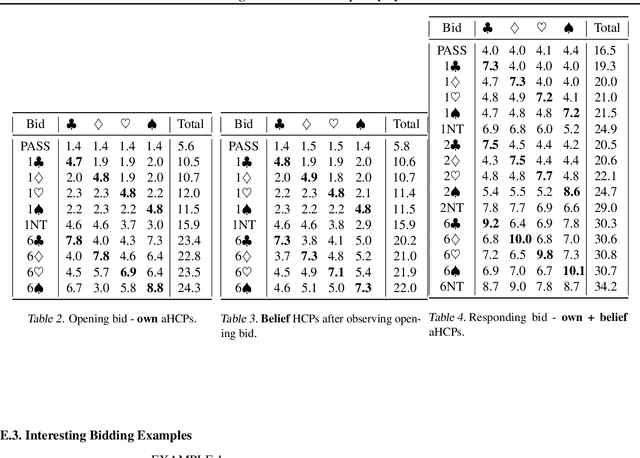
In situations where explicit communication is limited, a human collaborator is typically able to learn to: (i) infer the meaning behind their partner's actions and (ii) balance between taking actions that are exploitative given their current understanding of the state vs. those that can convey private information about the state to their partner. The first component of this learning process has been well-studied in multi-agent systems, whereas the second --- which is equally crucial for a successful collaboration --- has not. In this work, we complete the learning process and introduce our novel algorithm, Policy-Belief-Iteration ("P-BIT"), which mimics both components mentioned above. A belief module models the other agent's private information by observing their actions, whilst a policy module makes use of the inferred private information to return a distribution over actions. They are mutually reinforced with an EM-like algorithm. We use a novel auxiliary reward to encourage information exchange by actions. We evaluate our approach on the non-competitive bidding problem from contract bridge and show that by self-play agents are able to effectively collaborate with implicit communication, and P-BIT outperforms several meaningful baselines that have been considered.
Self-supervised Representation Learning with Relative Predictive Coding
Apr 12, 2021
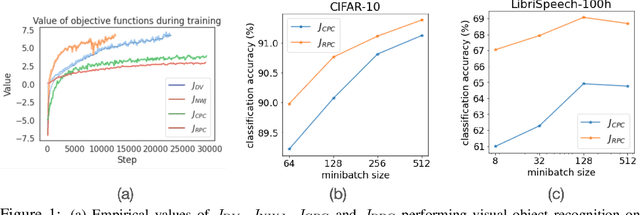
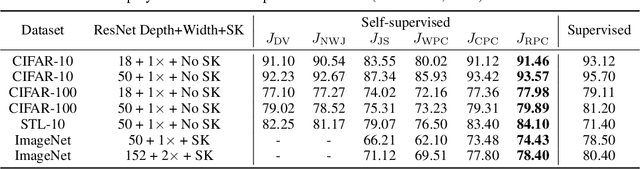
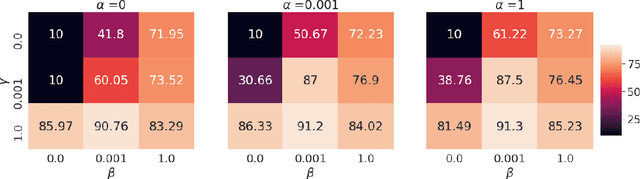
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
Tracking of enriched dialog states for flexible conversational information access
Feb 24, 2018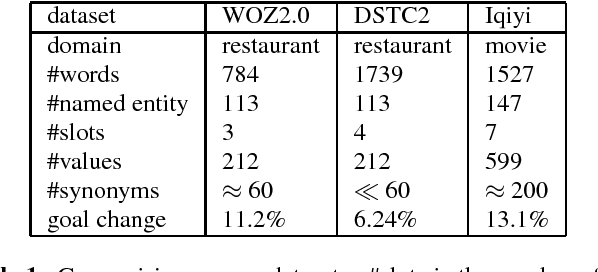
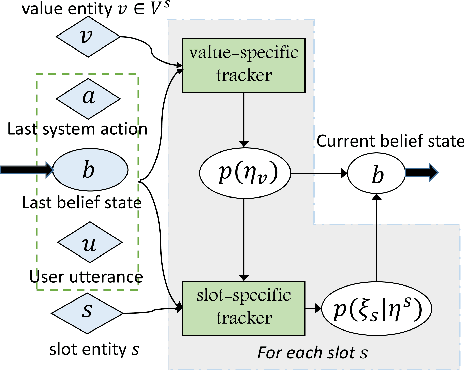
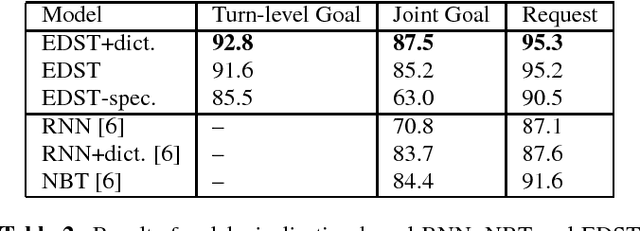
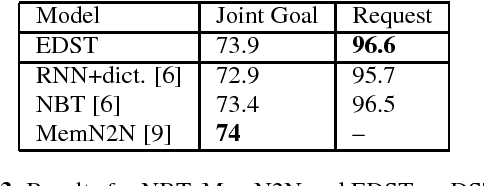
Dialog state tracking (DST) is a crucial component in a task-oriented dialog system for conversational information access. A common practice in current dialog systems is to define the dialog state by a set of slot-value pairs. Such representation of dialog states and the slot-filling based DST have been widely employed, but suffer from three drawbacks. (1) The dialog state can contain only a single value for a slot, and (2) can contain only users' affirmative preference over the values for a slot. (3) Current task-based dialog systems mainly focus on the searching task, while the enquiring task is also very common in practice. The above observations motivate us to enrich current representation of dialog states and collect a brand new dialog dataset about movies, based upon which we build a new DST, called enriched DST (EDST), for flexible accessing movie information. The EDST supports the searching task, the enquiring task and their mixed task. We show that the new EDST method not only achieves good results on Iqiyi dataset, but also outperforms other state-of-the-art DST methods on the traditional dialog datasets, WOZ2.0 and DSTC2.
An RF-source-free microwave photonic radar with an optically injected semiconductor laser for high-resolution detection and imaging
Jun 11, 2021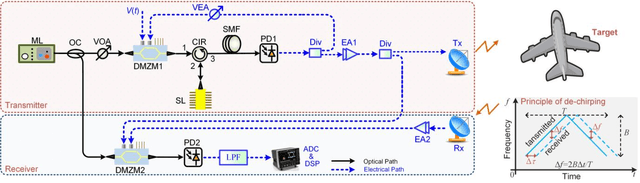
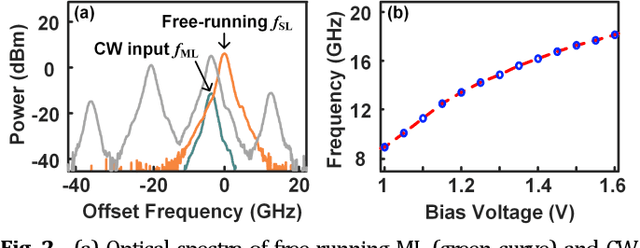
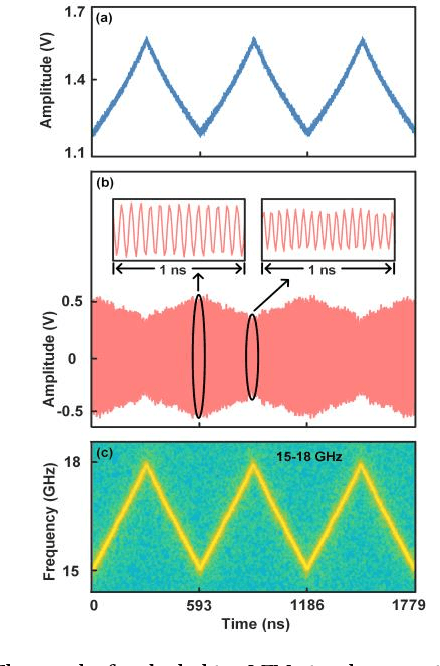
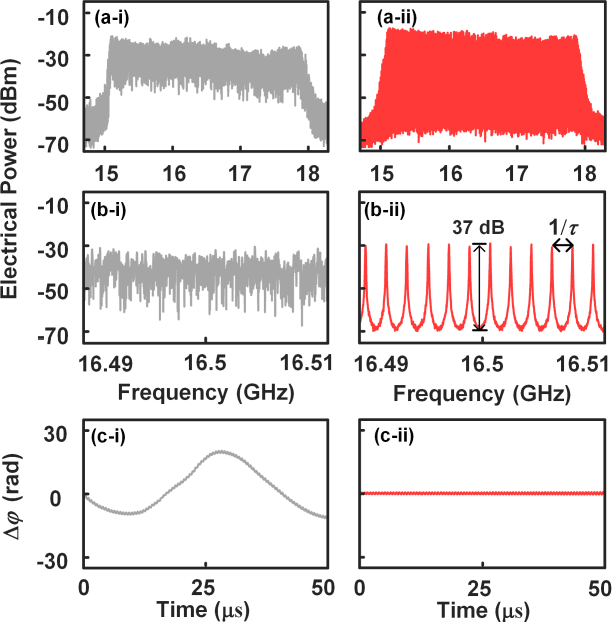
This paper presents a novel microwave photonic (MWP) radar scheme that is capable of optically generating and processing broadband linear frequency-modulated (LFM) microwave signals without using any radio-frequency (RF) sources. In the transmitter, a broadband LFM microwave signal is generated by controlling the period-one (P1) oscillation of an optically injected semiconductor laser. After targets reflection, photonic de-chirping is implemented based on a dual-drive Mach-Zehnder modulator (DMZM), which is followed by a low-speed analog-to-digital converter (ADC) and digital signal processer (DSP) to reconstruct target information. Without the limitations of external RF sources, the proposed radar has an ultra-flexible tunability, and the main operating parameters are adjustable, including central frequency, bandwidth, frequency band, and temporal period. In the experiment, a fully photonics-based Ku-band radar with a bandwidth of 4 GHz is established for high-resolution detection and inverse synthetic aperture radar (ISAR) imaging. Results show that a high range resolution reaching ~1.88 cm, and a two-dimensional (2D) imaging resolution as high as ~1.88 cm x ~2.00 cm are achieved with a sampling rate of 100 MSa/s in the receiver. The flexible tunability of the radar is also experimentally investigated. The proposed radar scheme features low cost, simple structure, and high reconfigurability, which, hopefully, is to be used in future multifunction adaptive and miniaturized radars.