 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Application of Monte Carlo algorithms to cardiac imaging reconstruction
May 27, 2021
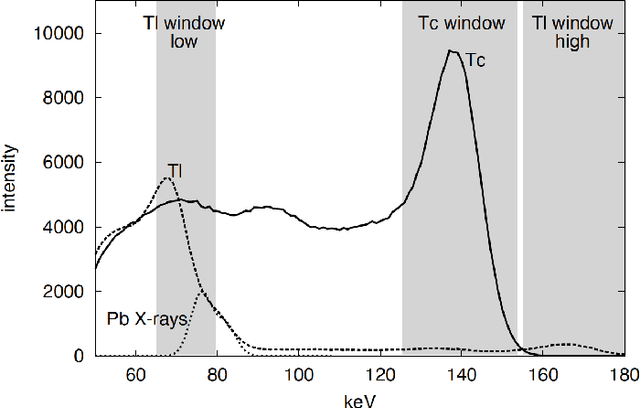
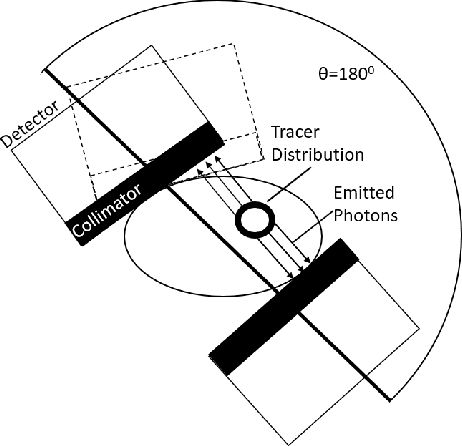
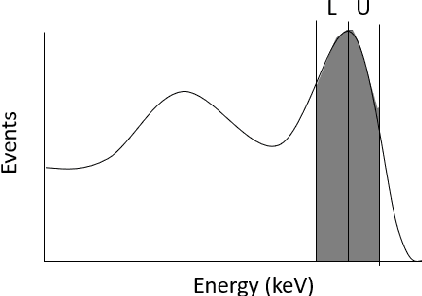
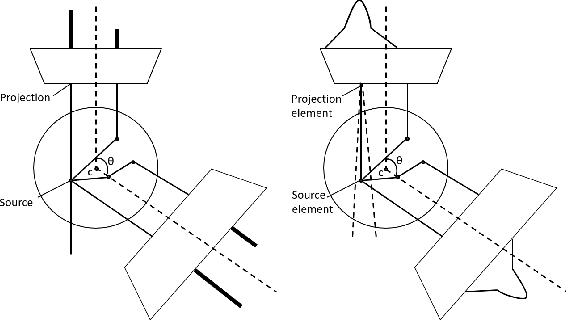
Monte Carlo algorithms have a growing impact on nuclear medicine reconstruction processes. One of the main limitations of myocardial perfusion imaging (MPI) is the effective mitigation of the scattering component, which is particularly challenging in Single Photon Emission Computed Tomography (SPECT). In SPECT, no timing information can be retrieved to locate the primary source photons. Monte Carlo methods allow an event-by-event simulation of the scattering kinematics, which can be incorporated into a model of the imaging system response. This approach was adopted since the late Nineties by several authors, and recently took advantage of the increased computational power made available by high-performance CPUs and GPUs. These recent developments enable a fast image reconstruction with an improved image quality, compared to deterministic approaches. Deterministic approaches are based on energy-windowing of the detector response, and on the cumulative estimate and subtraction of the scattering component. In this paper, we review the main strategies and algorithms to correct for the scattering effect in SPECT and focus on Monte Carlo developments, which nowadays allow the three-dimensional reconstruction of SPECT cardiac images in a few seconds.
Distilling a Powerful Student Model via Online Knowledge Distillation
Mar 29, 2021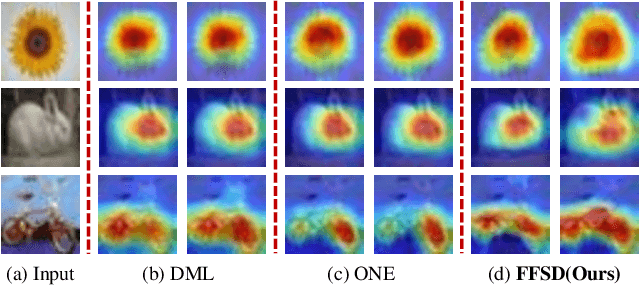
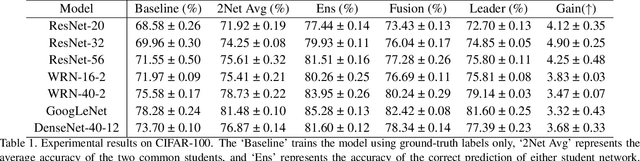
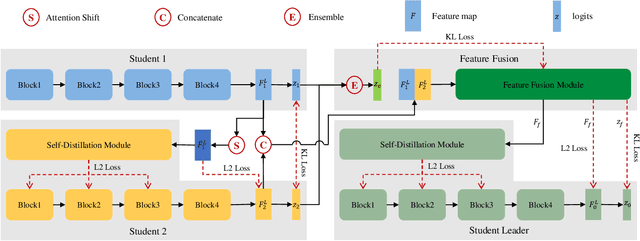
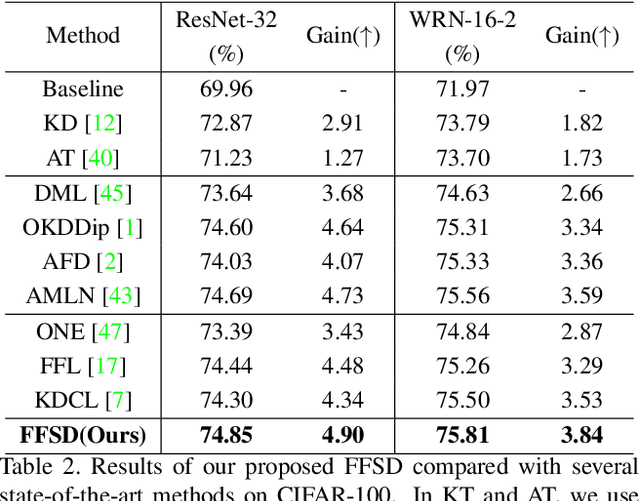
Existing online knowledge distillation approaches either adopt the student with the best performance or construct an ensemble model for better holistic performance. However, the former strategy ignores other students' information, while the latter increases the computational complexity. In this paper, we propose a novel method for online knowledge distillation, termed FFSD, which comprises two key components: Feature Fusion and Self-Distillation, towards solving the above problems in a unified framework. Different from previous works, where all students are treated equally, the proposed FFSD splits them into a student leader and a common student set. Then, the feature fusion module converts the concatenation of feature maps from all common students into a fused feature map. The fused representation is used to assist the learning of the student leader. To enable the student leader to absorb more diverse information, we design an enhancement strategy to increase the diversity among students. Besides, a self-distillation module is adopted to convert the feature map of deeper layers into a shallower one. Then, the shallower layers are encouraged to mimic the transformed feature maps of the deeper layers, which helps the students to generalize better. After training, we simply adopt the student leader, which achieves superior performance, over the common students, without increasing the storage or inference cost. Extensive experiments on CIFAR-100 and ImageNet demonstrate the superiority of our FFSD over existing works. The code is available at https://github.com/SJLeo/FFSD.
Optimizing Graph Transformer Networks with Graph-based Techniques
Jun 16, 2021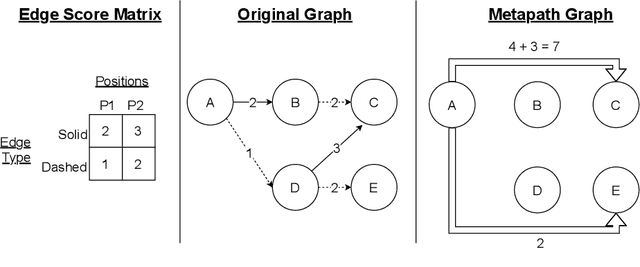
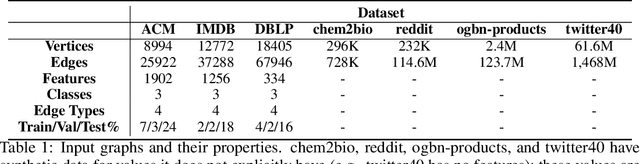
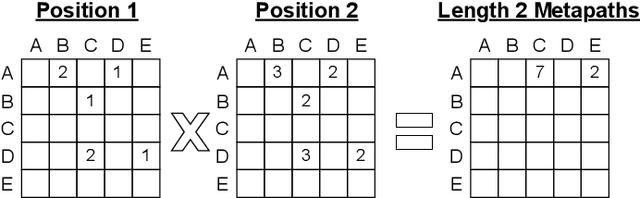
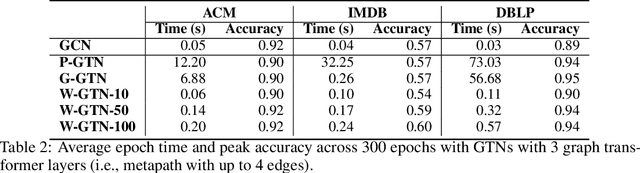
Graph transformer networks (GTN) are a variant of graph convolutional networks (GCN) that are targeted to heterogeneous graphs in which nodes and edges have associated type information that can be exploited to improve inference accuracy. GTNs learn important metapaths in the graph, create weighted edges for these metapaths, and use the resulting graph in a GCN. Currently, the only available implementation of GTNs uses dense matrix multiplication to find metapaths. Unfortunately, the space overhead of this approach can be large, so in practice it is used only for small graphs. In addition, the matrix-based implementation is not fine-grained enough to use random-walk based methods to optimize metapath finding. In this paper, we present a graph-based formulation and implementation of the GTN metapath finding problem. This graph-based formulation has two advantages over the matrix-based approach. First, it is more space efficient than the original GTN implementation and more compute-efficient for metapath sizes of practical interest. Second, it permits us to implement a sampling method that reduces the number of metapaths that must be enumerated, allowing the implementation to be used for larger graphs and larger metapath sizes. Experimental results show that our implementation is $6.5\times$ faster than the original GTN implementation on average for a metapath length of 4, and our sampling implementation is $155\times$ faster on average than this implementation without compromising on the accuracy of the GTN.
Learning Unknown from Correlations: Graph Neural Network for Inter-novel-protein Interaction Prediction
May 20, 2021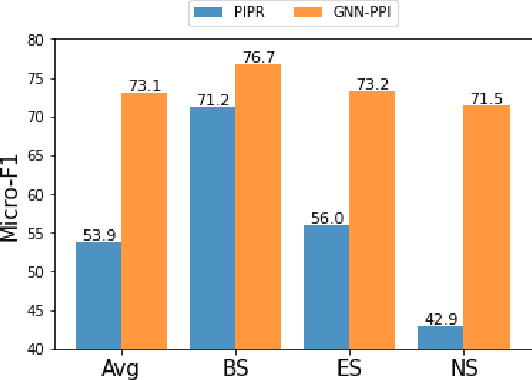
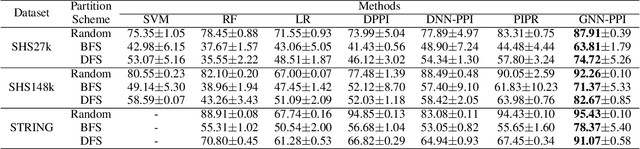
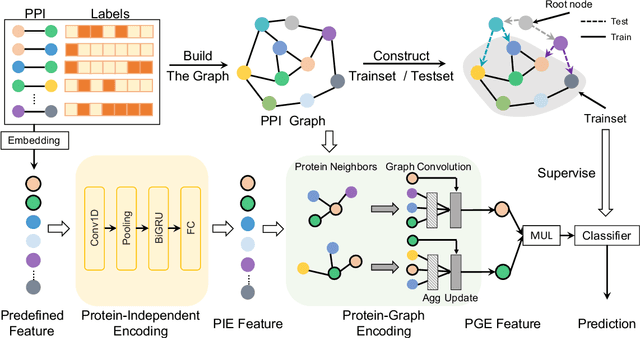
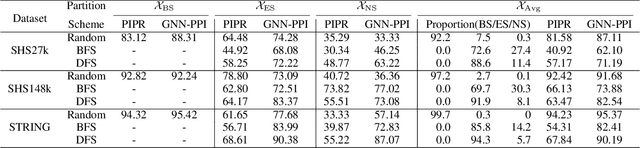
The study of multi-type Protein-Protein Interaction (PPI) is fundamental for understanding biological processes from a systematic perspective and revealing disease mechanisms. Existing methods suffer from significant performance degradation when tested in unseen dataset. In this paper, we investigate the problem and find that it is mainly attributed to the poor performance for inter-novel-protein interaction prediction. However, current evaluations overlook the inter-novel-protein interactions, and thus fail to give an instructive assessment. As a result, we propose to address the problem from both the evaluation and the methodology. Firstly, we design a new evaluation framework that fully respects the inter-novel-protein interactions and gives consistent assessment across datasets. Secondly, we argue that correlations between proteins must provide useful information for analysis of novel proteins, and based on this, we propose a graph neural network based method (GNN-PPI) for better inter-novel-protein interaction prediction. Experimental results on real-world datasets of different scales demonstrate that GNN-PPI significantly outperforms state-of-the-art PPI prediction methods, especially for the inter-novel-protein interaction prediction.
Loss function based second-order Jensen inequality and its application to particle variational inference
Jun 10, 2021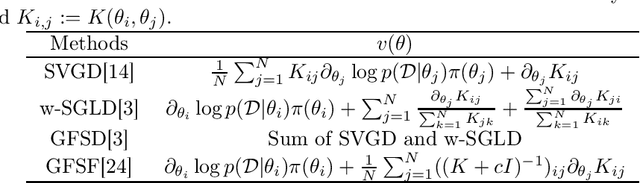
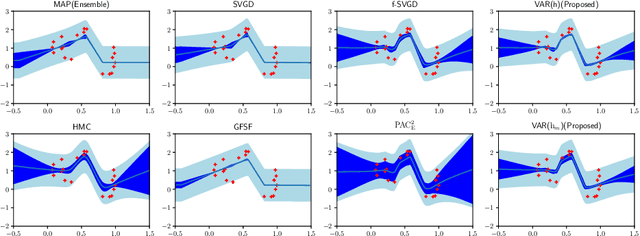
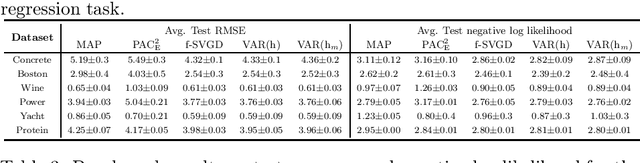
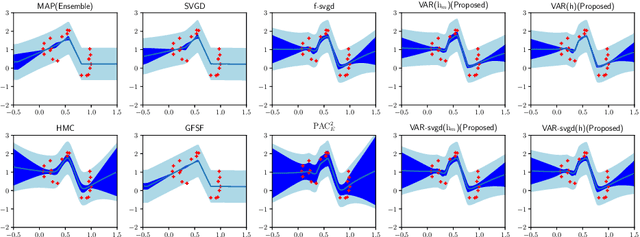
Bayesian model averaging, obtained as the expectation of a likelihood function by a posterior distribution, has been widely used for prediction, evaluation of uncertainty, and model selection. Various approaches have been developed to efficiently capture the information in the posterior distribution; one such approach is the optimization of a set of models simultaneously with interaction to ensure the diversity of the individual models in the same way as ensemble learning. A representative approach is particle variational inference (PVI), which uses an ensemble of models as an empirical approximation for the posterior distribution. PVI iteratively updates each model with a repulsion force to ensure the diversity of the optimized models. However, despite its promising performance, a theoretical understanding of this repulsion and its association with the generalization ability remains unclear. In this paper, we tackle this problem in light of PAC-Bayesian analysis. First, we provide a new second-order Jensen inequality, which has the repulsion term based on the loss function. Thanks to the repulsion term, it is tighter than the standard Jensen inequality. Then, we derive a novel generalization error bound and show that it can be reduced by enhancing the diversity of models. Finally, we derive a new PVI that optimizes the generalization error bound directly. Numerical experiments demonstrate that the performance of the proposed PVI compares favorably with existing methods in the experiment.
Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains
Jun 03, 2021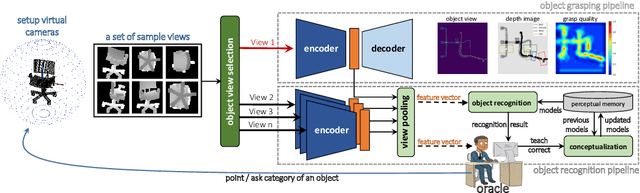
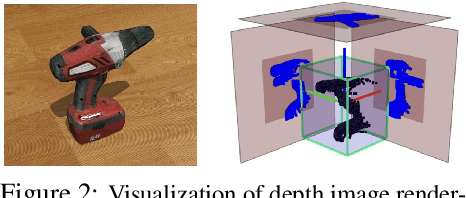
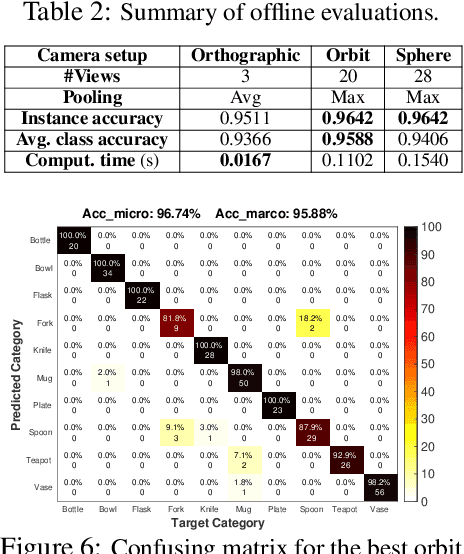
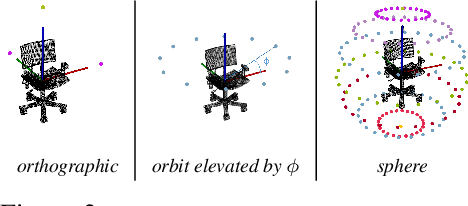
A robot working in human-centric environments needs to know which kind of objects exist in the scene, where they are, and how to grasp and manipulate various objects in different situations to help humans in everyday tasks. Therefore, object recognition and grasping are two key functionalities for such robots. Most state-of-the-art tackles object recognition and grasping as two separate problems while both use visual input. Furthermore, the knowledge of the robot is fixed after the training phase. In such cases, if the robot faces new object categories, it must retrain from scratch to incorporate new information without catastrophic interference. To address this problem, we propose a deep learning architecture with augmented memory capacities to handle open-ended object recognition and grasping simultaneously. In particular, our approach takes multi-views of an object as input and jointly estimates pixel-wise grasp configuration as well as a deep scale- and rotation-invariant representation as outputs. The obtained representation is then used for open-ended object recognition through a meta-active learning technique. We demonstrate the ability of our approach to grasp never-seen-before objects and to rapidly learn new object categories using very few examples on-site in both simulation and real-world settings.
Disentangled Face Attribute Editing via Instance-Aware Latent Space Search
May 27, 2021
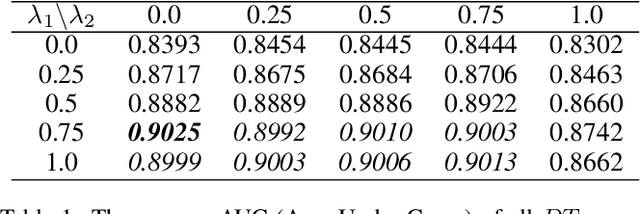
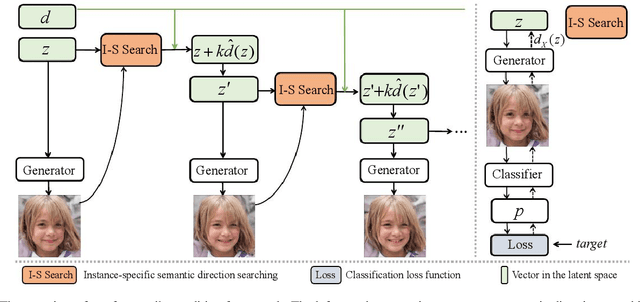

Recent works have shown that a rich set of semantic directions exist in the latent space of Generative Adversarial Networks (GANs), which enables various facial attribute editing applications. However, existing methods may suffer poor attribute variation disentanglement, leading to unwanted change of other attributes when altering the desired one. The semantic directions used by existing methods are at attribute level, which are difficult to model complex attribute correlations, especially in the presence of attribute distribution bias in GAN's training set. In this paper, we propose a novel framework (IALS) that performs Instance-Aware Latent-Space Search to find semantic directions for disentangled attribute editing. The instance information is injected by leveraging the supervision from a set of attribute classifiers evaluated on the input images. We further propose a Disentanglement-Transformation (DT) metric to quantify the attribute transformation and disentanglement efficacy and find the optimal control factor between attribute-level and instance-specific directions based on it. Experimental results on both GAN-generated and real-world images collectively show that our method outperforms state-of-the-art methods proposed recently by a wide margin. Code is available at https://github.com/yxuhan/IALS.
Adaptive Coordinated Motion Control for Swarm Robotics Based on Brain Storm Optimization
May 27, 2021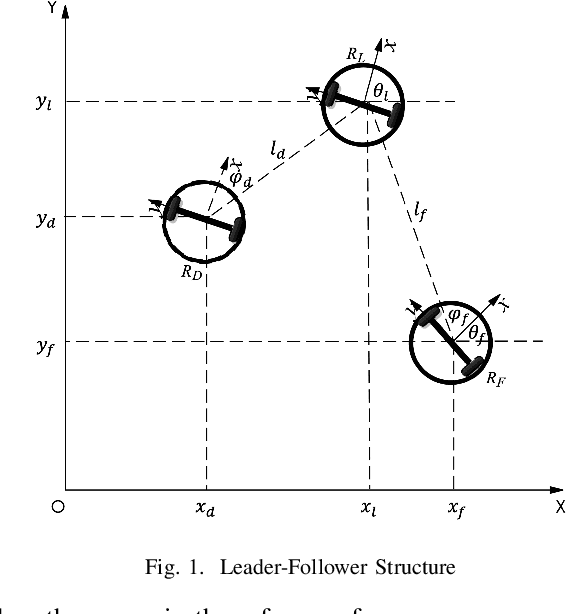
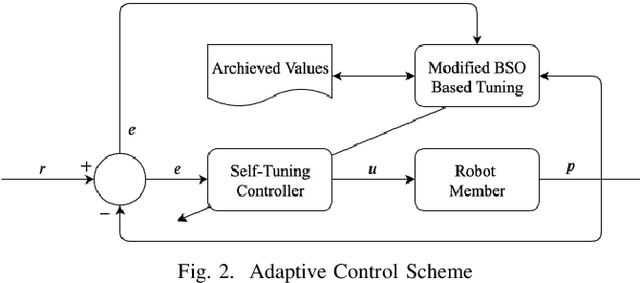
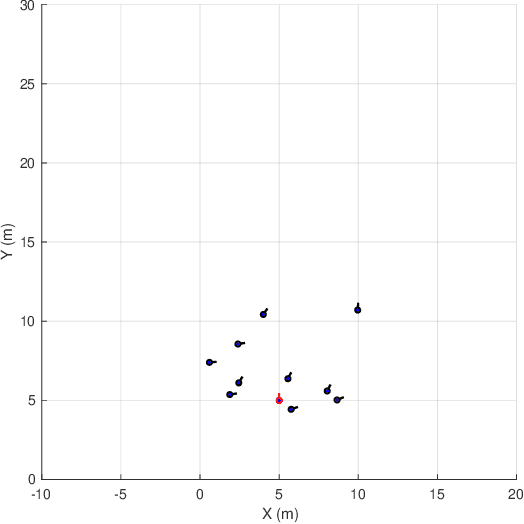
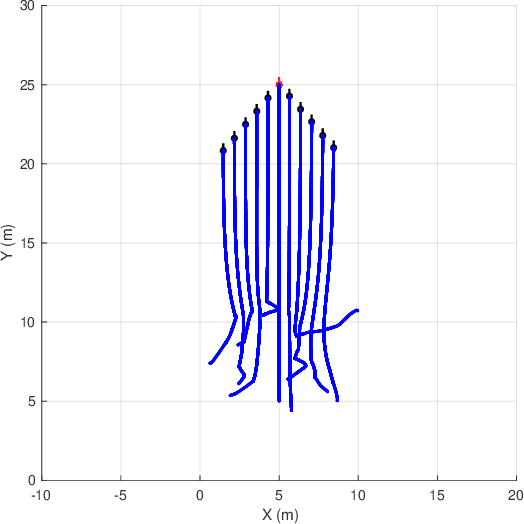
Coordinated motion control in swarm robotics aims to ensure the coherence of members in space, i.e., the robots in a swarm perform coordinated movements to maintain spatial structures. This problem can be modeled as a tracking control problem, in which individuals in the swarm follow a target position with the consideration of specific relative distance or orientations. To keep the communication cost low, the PID controller can be utilized to achieve the leader-follower tracking control task without the information of leader velocities. However, the controller's parameters need to be optimized to adapt to situations changing, such as the different swarm population, the changing of the target to be followed, and the anti-collision demands, etc. In this letter, we apply a modified Brain Storm Optimization (BSO) algorithm to an incremental PID tracking controller to get the relatively optimal parameters adaptively for leader-follower formation control for swarm robotics. Simulation results show that the proposed method could reach the optimal parameters during robot movements. The flexibility and scalability are also validated, which ensures that the proposed method can adapt to different situations and be a good candidate for coordinated motion control for swarm robotics in more realistic scenarios.
Fast Power Control Adaptation via Meta-Learning for Random Edge Graph Neural Networks
May 02, 2021
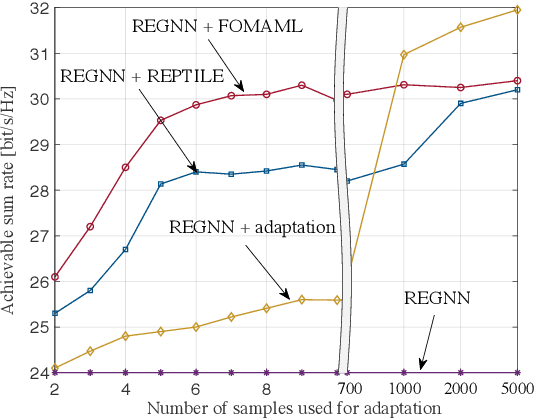
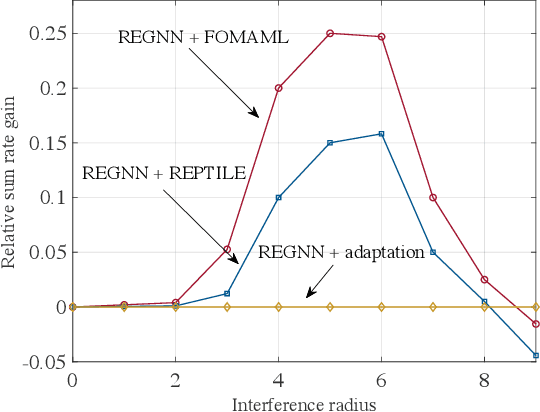
Power control in decentralized wireless networks poses a complex stochastic optimization problem when formulated as the maximization of the average sum rate for arbitrary interference graphs. Recent work has introduced data-driven design methods that leverage graph neural network (GNN) to efficiently parametrize the power control policy mapping channel state information (CSI) to the power vector. The specific GNN architecture, known as random edge GNN (REGNN), defines a non-linear graph convolutional architecture whose spatial weights are tied to the channel coefficients, enabling a direct adaption to channel conditions. This paper studies the higher-level problem of enabling fast adaption of the power control policy to time-varying topologies. To this end, we apply first-order meta-learning on data from multiple topologies with the aim of optimizing for a few-shot adaptation to new network configurations.
BinarizedAttack: Structural Poisoning Attacks to Graph-based Anomaly Detection
Jun 21, 2021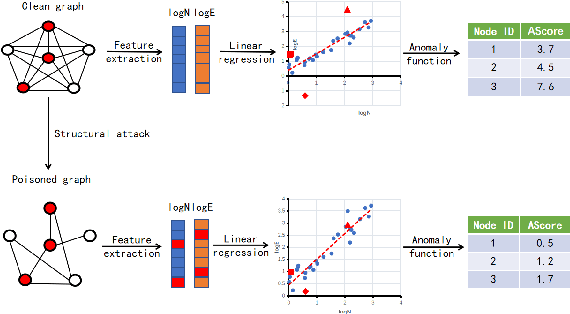
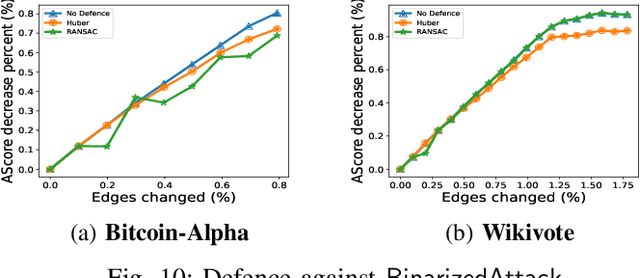
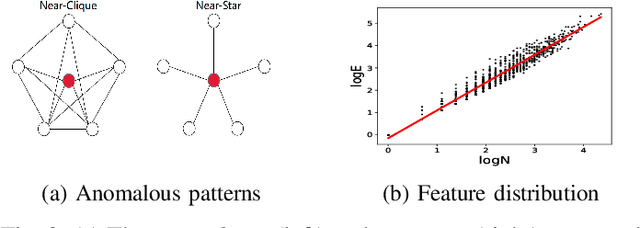
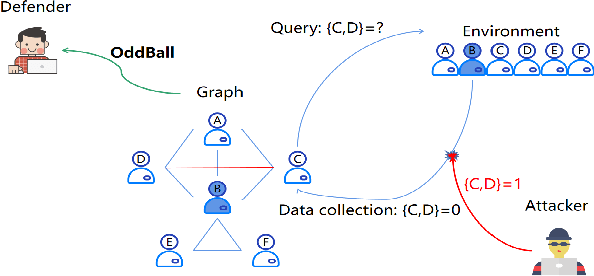
Graph-based Anomaly Detection (GAD) is becoming prevalent due to the powerful representation abilities of graphs as well as recent advances in graph mining techniques. These GAD tools, however, expose a new attacking surface, ironically due to their unique advantage of being able to exploit the relations among data. That is, attackers now can manipulate those relations (i.e., the structure of the graph) to allow some target nodes to evade detection. In this paper, we exploit this vulnerability by designing a new type of targeted structural poisoning attacks to a representative regression-based GAD system termed OddBall. Specially, we formulate the attack against OddBall as a bi-level optimization problem, where the key technical challenge is to efficiently solve the problem in a discrete domain. We propose a novel attack method termed BinarizedAttack based on gradient descent. Comparing to prior arts, BinarizedAttack can better use the gradient information, making it particularly suitable for solving combinatorial optimization problems. Furthermore, we investigate the attack transferability of BinarizedAttack by employing it to attack other representation-learning-based GAD systems. Our comprehensive experiments demonstrate that BinarizedAttack is very effective in enabling target nodes to evade graph-based anomaly detection tools with limited attackers' budget, and in the black-box transfer attack setting, BinarizedAttack is also tested effective and in particular, can significantly change the node embeddings learned by the GAD systems. Our research thus opens the door to studying a new type of attack against security analytic tools that rely on graph data.