 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
General-Purpose Speech Representation Learning through a Self-Supervised Multi-Granularity Framework
Feb 03, 2021
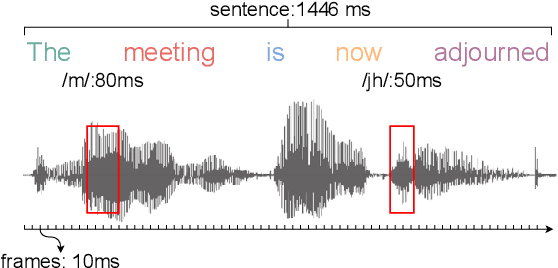
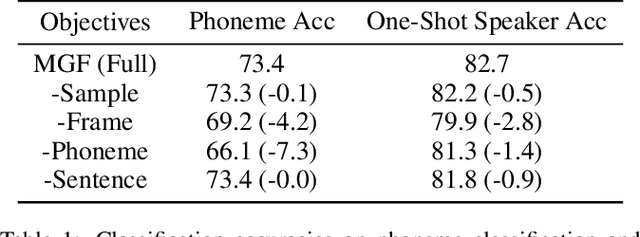
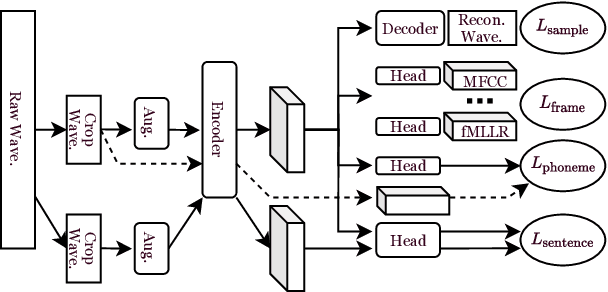
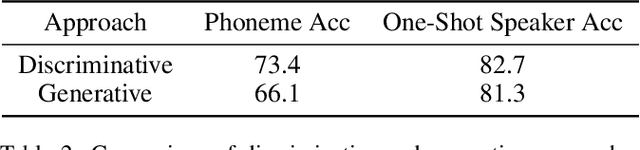
This paper presents a self-supervised learning framework, named MGF, for general-purpose speech representation learning. In the design of MGF, speech hierarchy is taken into consideration. Specifically, we propose to use generative learning approaches to capture fine-grained information at small time scales and use discriminative learning approaches to distill coarse-grained or semantic information at large time scales. For phoneme-scale learning, we borrow idea from the masked language model but tailor it for the continuous speech signal by replacing classification loss with a contrastive loss. We corroborate our design by evaluating MGF representation on various downstream tasks, including phoneme classification, speaker classification, speech recognition, and emotion classification. Experiments verify that training at different time scales needs different training targets and loss functions, which in general complement each other and lead to a better performance.
Single-Server Private Linear Transformation: The Individual Privacy Case
Jun 09, 2021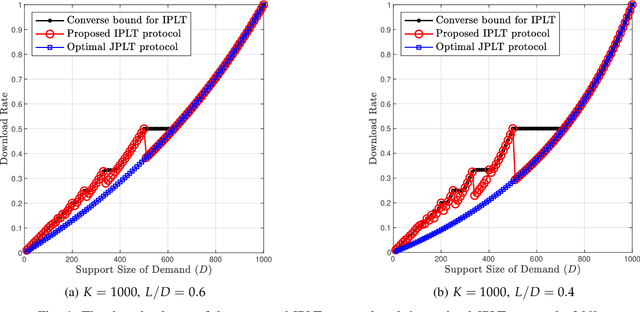
This paper considers the single-server Private Linear Transformation (PLT) problem with individual privacy guarantees. In this problem, there is a user that wishes to obtain $L$ independent linear combinations of a $D$-subset of messages belonging to a dataset of $K$ messages stored on a single server. The goal is to minimize the download cost while keeping the identity of each message required for the computation individually private. The individual privacy requirement ensures that the identity of each individual message required for the computation is kept private. This is in contrast to the stricter notion of joint privacy that protects the entire set of identities of all messages used for the computation, including the correlations between these identities. The notion of individual privacy captures a broad set of practical applications. For example, such notion is relevant when the dataset contains information about individuals, each of them requires privacy guarantees for their data access patterns. We focus on the setting in which the required linear transformation is associated with a maximum distance separable (MDS) matrix. In particular, we require that the matrix of coefficients pertaining to the required linear combinations is the generator matrix of an MDS code. We establish lower and upper bounds on the capacity of PLT with individual privacy, where the capacity is defined as the supremum of all achievable download rates. We show that our bounds are tight under certain conditions.
STOPPAGE: Spatio-temporal Data Driven Cloud-Fog-Edge Computing Framework for Pandemic Monitoring and Management
Apr 04, 2021
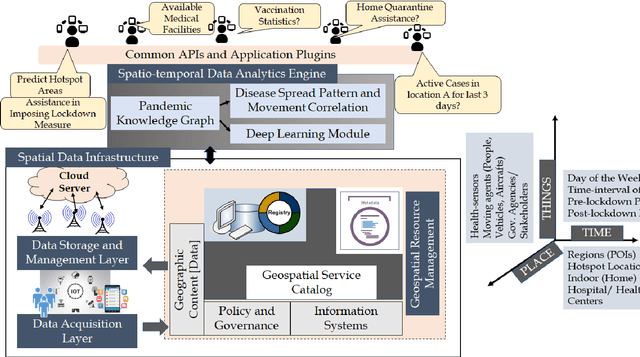
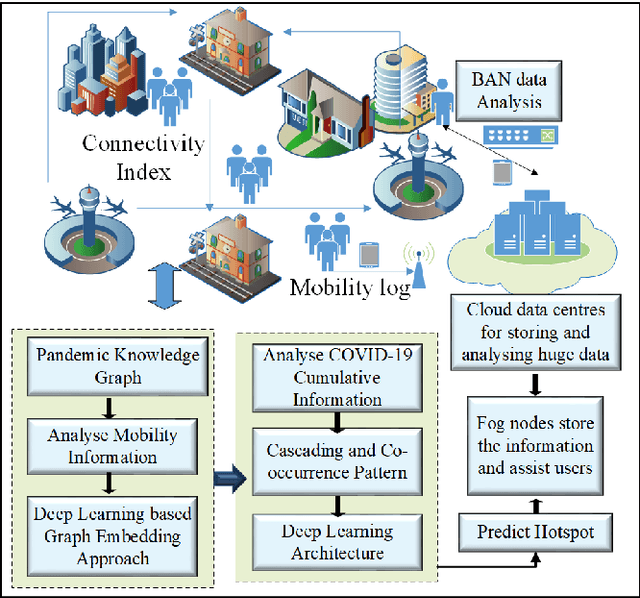
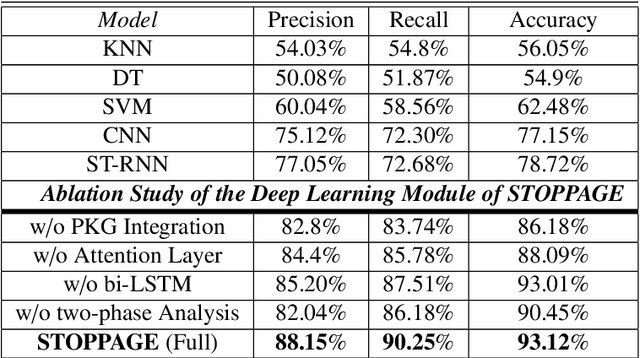
Several researches and evidence show the increasing likelihood of pandemics (large-scale outbreaks of infectious disease) which has far reaching sequels in all aspects of human lives ranging from rapid mortality rates to economic and social disruption across the world. In the recent time, COVID-19 (Coronavirus Disease 2019) pandemic disrupted normal human lives, and motivated by the urgent need of combating COVID-19, researchers have put significant efforts in modelling and analysing the disease spread patterns for effective preventive measures (in addition to developing pharmaceutical solutions, like vaccine). In this regards, it is absolutely necessary to develop an analytics framework by extracting and incorporating the knowledge of heterogeneous datasources to deliver insights in improving administrative policy and enhance the preparedness to combat the pandemic. Specifically, human mobility, travel history and other transport statistics have significant impacts on the spread of any infectious disease. In this direction, this paper proposes a spatio-temporal knowledge mining framework, named STOPPAGE to model the impact of human mobility and other contextual information over large geographic area in different temporal scales. The framework has two major modules: (i) Spatio-temporal data and computing infrastructure using fog/edge based architecture; and (ii) Spatio-temporal data analytics module to efficiently extract knowledge from heterogeneous data sources. Typically, we develop a Pandemic-knowledge graph to discover correlations among mobility information and disease spread, a deep learning architecture to predict the next hot-spot zones; and provide necessary support in home-health monitoring utilizing Femtolet and fog/edge based solutions. The experimental evaluations on real-life datasets related to COVID-19 in India illustrate the efficacy of the proposed methods.
Interpretation of multi-label classification models using shapley values
Apr 21, 2021
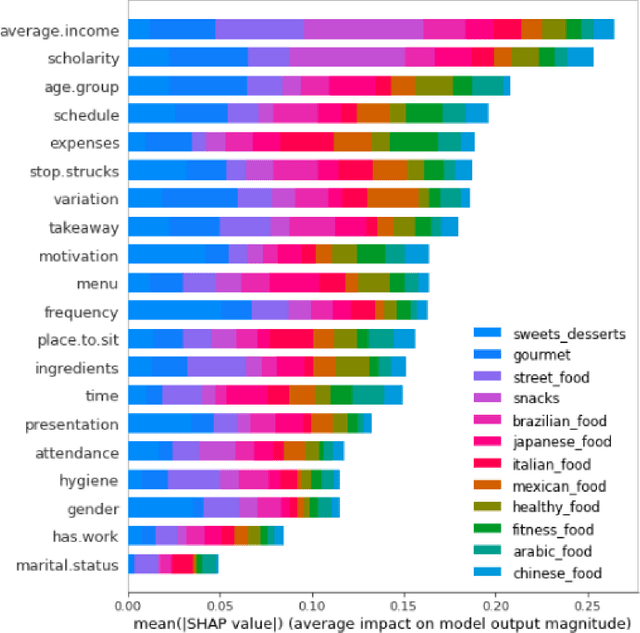
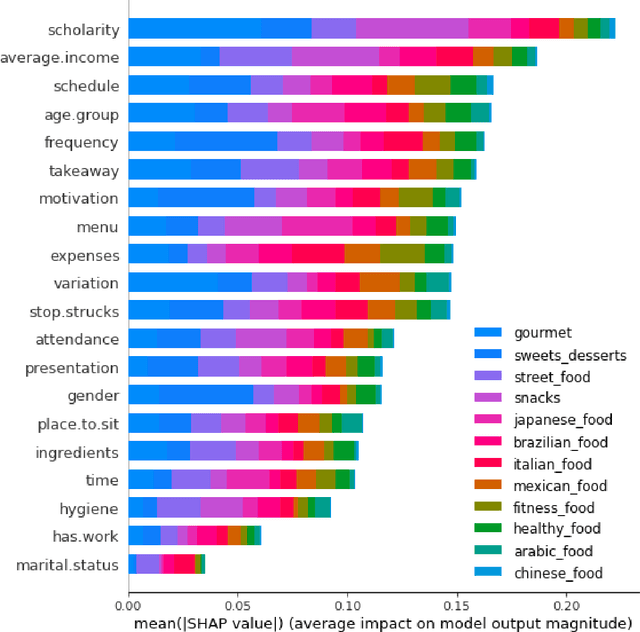
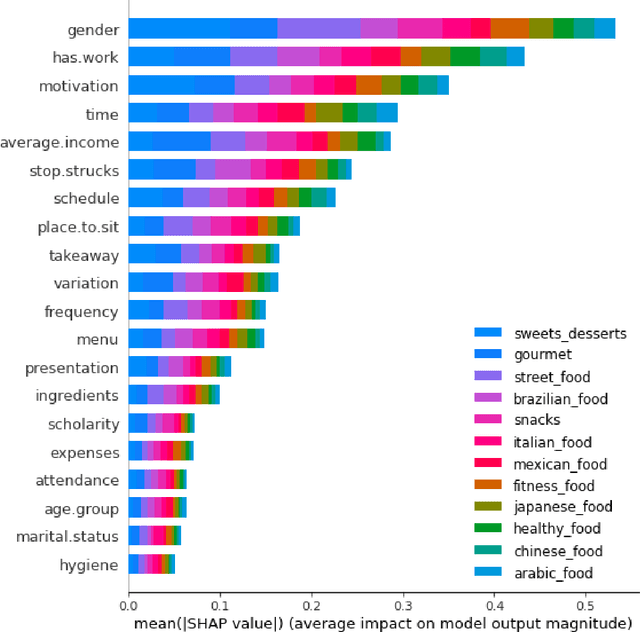
Multi-label classification is a type of classification task, it is used when there are two or more classes, and the data point we want to predict may belong to none of the classes or all of them at the same time. In the real world, many applications are actually multi-label involved, including information retrieval, multimedia content annotation, web mining, and so on. A game theory-based framework known as SHapley Additive exPlanations (SHAP) has been applied to explain various supervised learning models without being aware of the exact model. Herein, this work further extends the explanation of multi-label classification task by using the SHAP methodology. The experiment demonstrates a comprehensive comparision of different algorithms on well known multi-label datasets and shows the usefulness of the interpretation.
Progressive Depth Learning for Single Image Dehazing
Feb 21, 2021
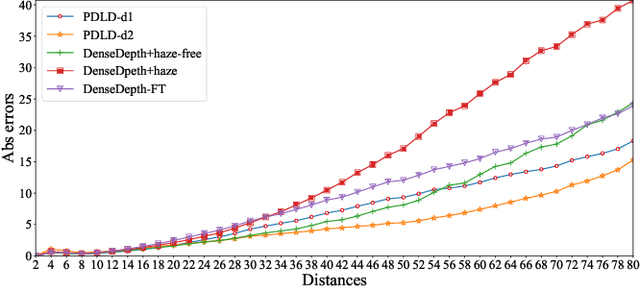
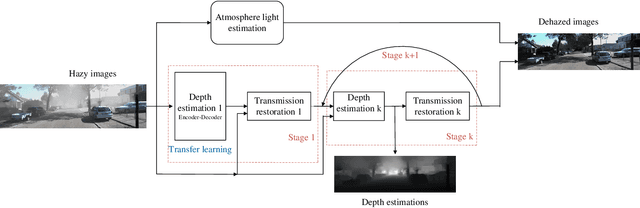

The formulation of the hazy image is mainly dominated by the reflected lights and ambient airlight. Existing dehazing methods often ignore the depth cues and fail in distant areas where heavier haze disturbs the visibility. However, we note that the guidance of the depth information for transmission estimation could remedy the decreased visibility as distances increase. In turn, the good transmission estimation could facilitate the depth estimation for hazy images. In this paper, a deep end-to-end model that iteratively estimates image depths and transmission maps is proposed to perform an effective depth prediction for hazy images and improve the dehazing performance with the guidance of depth information. The image depth and transmission map are progressively refined to better restore the dehazed image. Our approach benefits from explicitly modeling the inner relationship of image depth and transmission map, which is especially effective for distant hazy areas. Extensive results on the benchmarks demonstrate that our proposed network performs favorably against the state-of-the-art dehazing methods in terms of depth estimation and haze removal.
End-to-End Sequential Sampling and Reconstruction for MR Imaging
May 13, 2021
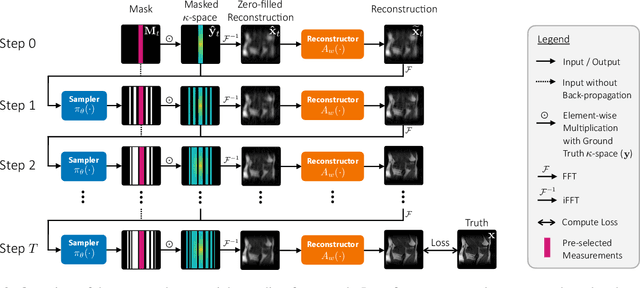


Accelerated MRI shortens acquisition time by subsampling in the measurement k-space. Recovering a high-fidelity anatomical image from subsampled measurements requires close cooperation between two components: (1) a sampler that chooses the subsampling pattern and (2) a reconstructor that recovers images from incomplete measurements. In this paper, we leverage the sequential nature of MRI measurements, and propose a fully differentiable framework that jointly learns a sequential sampling policy simultaneously with a reconstruction strategy. This co-designed framework is able to adapt during acquisition in order to capture the most informative measurements for a particular target (Figure 1). Experimental results on the fastMRI knee dataset demonstrate that the proposed approach successfully utilizes intermediate information during the sampling process to boost reconstruction performance. In particular, our proposed method outperforms the current state-of-the-art learned k-space sampling baseline on up to 96.96% of test samples. We also investigate the individual and collective benefits of the sequential sampling and co-design strategies. Code and more visualizations are available at http://imaging.cms.caltech.edu/seq-mri
Content-Aware Speaker Embeddings for Speaker Diarisation
Feb 12, 2021
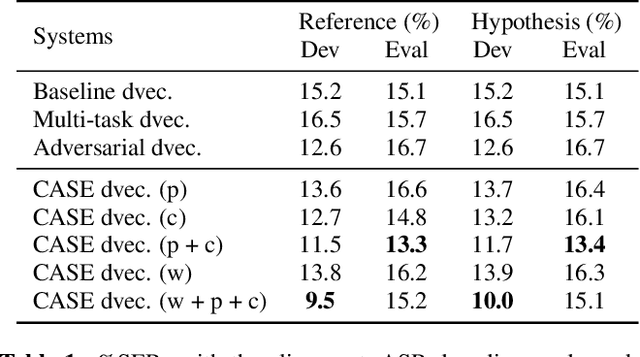
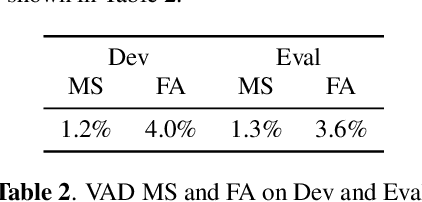
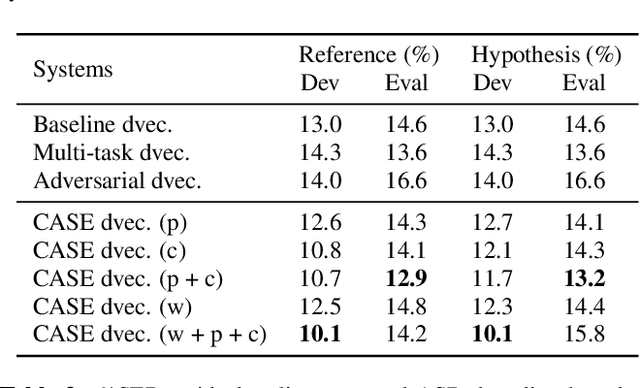
Recent speaker diarisation systems often convert variable length speech segments into fixed-length vector representations for speaker clustering, which are known as speaker embeddings. In this paper, the content-aware speaker embeddings (CASE) approach is proposed, which extends the input of the speaker classifier to include not only acoustic features but also their corresponding speech content, via phone, character, and word embeddings. Compared to alternative methods that leverage similar information, such as multitask or adversarial training, CASE factorises automatic speech recognition (ASR) from speaker recognition to focus on modelling speaker characteristics and correlations with the corresponding content units to derive more expressive representations. CASE is evaluated for speaker re-clustering with a realistic speaker diarisation setup using the AMI meeting transcription dataset, where the content information is obtained by performing ASR based on an automatic segmentation. Experimental results showed that CASE achieved a 17.8% relative speaker error rate reduction over conventional methods.
Spatio-attentive Graphs for Human-Object Interaction Detection
Dec 11, 2020
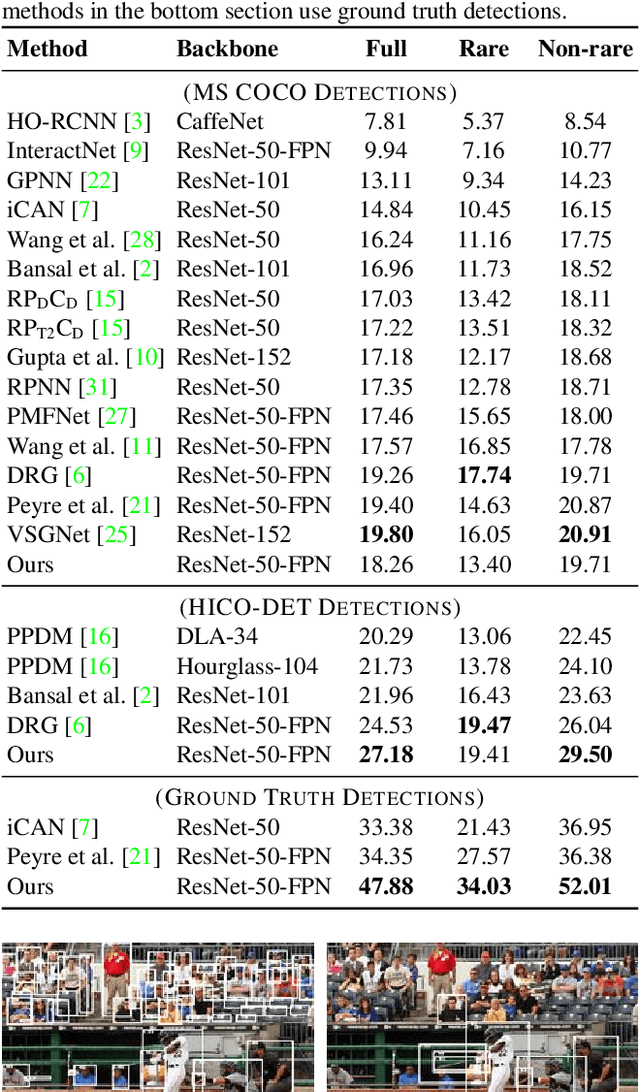
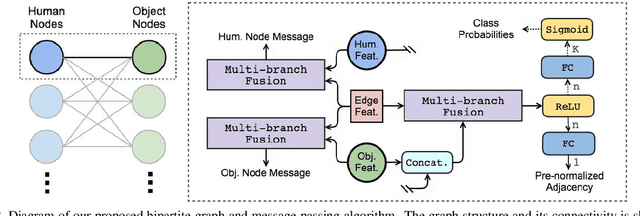
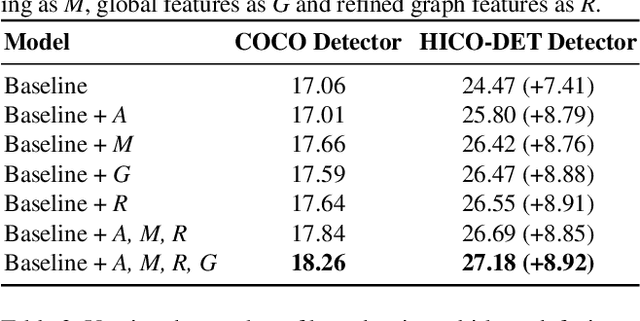
We address the problem of detecting human--object interactions in images using graphical neural networks. Our network constructs a bipartite graph of nodes representing detected humans and objects, wherein messages passed between the nodes encode relative spatial and appearance information. Unlike existing approaches that separate appearance and spatial features, our method fuses these two cues within a single graphical model allowing information conditioned on both modalities to influence the prediction of interactions with neighboring nodes. Through extensive experimentation we demonstrate the advantages of fusing relative spatial information with appearance features in the computation of adjacency structure, message passing and the ultimate refined graph features. On the popular HICO-DET benchmark dataset, our model outperforms state-of-the-art with an mAP of 27.18, a 10% relative improvement.
Forensic Analysis of Video Files Using Metadata
May 13, 2021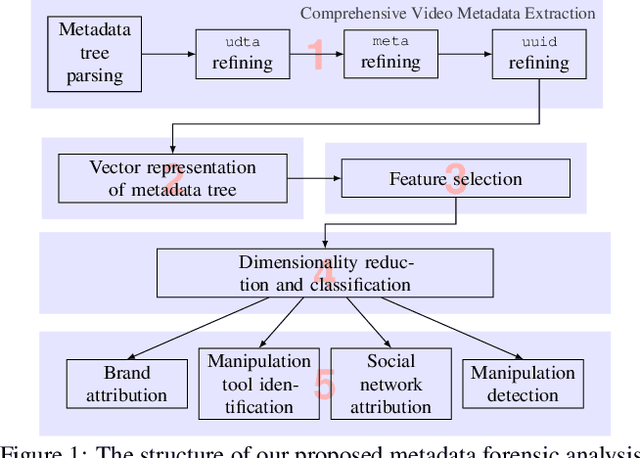

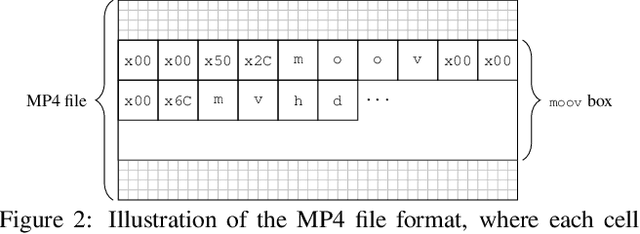
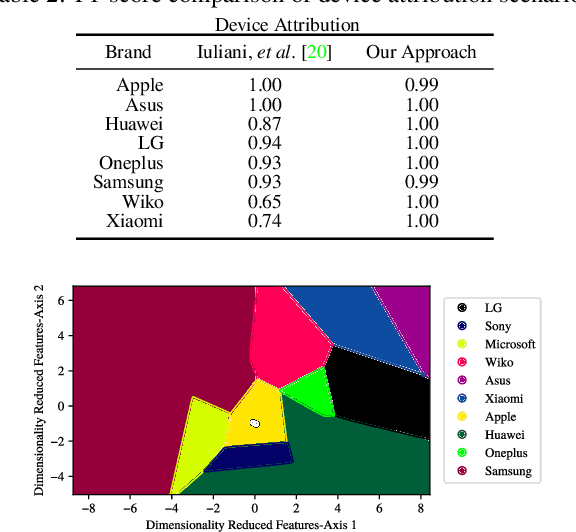
The unprecedented ease and ability to manipulate video content has led to a rapid spread of manipulated media. The availability of video editing tools greatly increased in recent years, allowing one to easily generate photo-realistic alterations. Such manipulations can leave traces in the metadata embedded in video files. This metadata information can be used to determine video manipulations, brand of video recording device, the type of video editing tool, and other important evidence. In this paper, we focus on the metadata contained in the popular MP4 video wrapper/container. We describe our method for metadata extractor that uses the MP4's tree structure. Our approach for analyzing the video metadata produces a more compact representation. We will describe how we construct features from the metadata and then use dimensionality reduction and nearest neighbor classification for forensic analysis of a video file. Our approach allows one to visually inspect the distribution of metadata features and make decisions. The experimental results confirm that the performance of our approach surpasses other methods.
Tensor Random Projection for Low Memory Dimension Reduction
Apr 30, 2021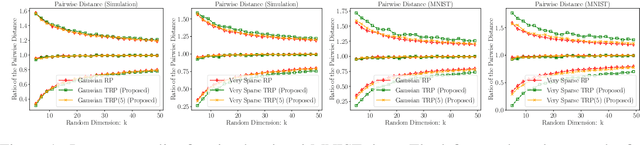

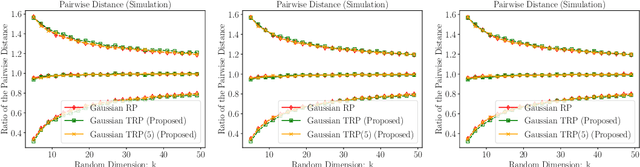
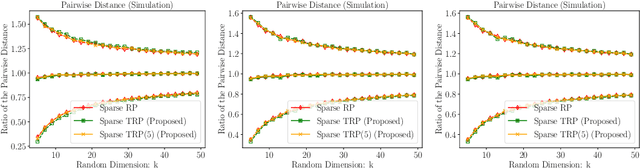
Random projections reduce the dimension of a set of vectors while preserving structural information, such as distances between vectors in the set. This paper proposes a novel use of row-product random matrices in random projection, where we call it Tensor Random Projection (TRP). It requires substantially less memory than existing dimension reduction maps. The TRP map is formed as the Khatri-Rao product of several smaller random projections, and is compatible with any base random projection including sparse maps, which enable dimension reduction with very low query cost and no floating point operations. We also develop a reduced variance extension. We provide a theoretical analysis of the bias and variance of the TRP, and a non-asymptotic error analysis for a TRP composed of two smaller maps. Experiments on both synthetic and MNIST data show that our method performs as well as conventional methods with substantially less storage.