 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative Filtering with Side Information: a Gaussian Process Perspective
Jun 08, 2017
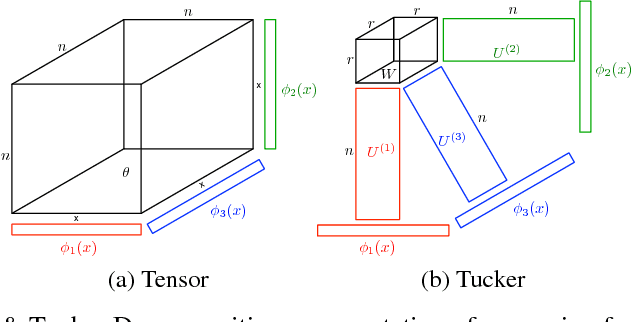
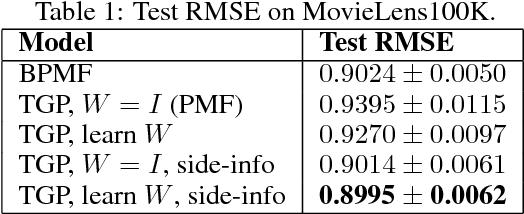
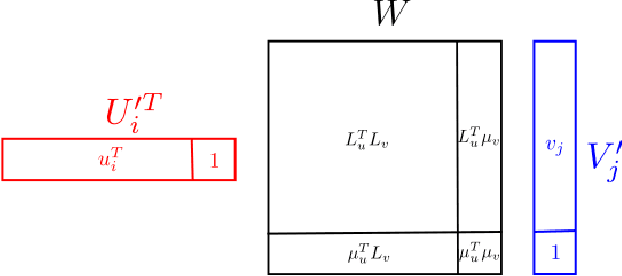

We tackle the problem of collaborative filtering (CF) with side information, through the lens of Gaussian Process (GP) regression. Driven by the idea of using the kernel to explicitly model user-item similarities, we formulate the GP in a way that allows the incorporation of low-rank matrix factorisation, arriving at our model, the Tucker Gaussian Process (TGP). Consequently, TGP generalises classical Bayesian matrix factorisation models, and goes beyond them to give a natural and elegant method for incorporating side information, giving enhanced predictive performance for CF problems. Moreover we show that it is a novel model for regression, especially well-suited to grid-structured data and problems where the dependence on covariates is close to being separable.
Automated Timeline Length Selection for Flexible Timeline Summarization
May 29, 2021
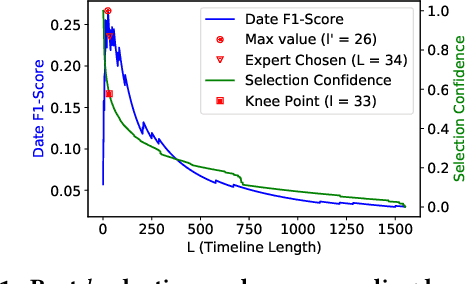
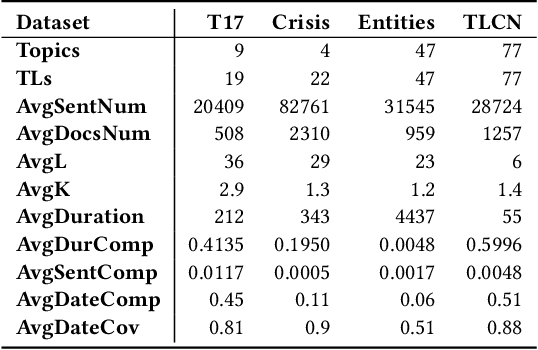
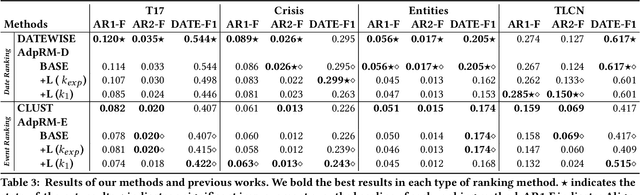
By producing summaries for long-running events, timeline summarization (TLS) underpins many information retrieval tasks. Successful TLS requires identifying an appropriate set of key dates (the timeline length) to cover. However, doing so is challenging as the right length can change from one topic to another. Existing TLS solutions either rely on an event-agnostic fixed length or an expert-supplied setting. Neither of the strategies is desired for real-life TLS scenarios. A fixed, event-agnostic setting ignores the diversity of events and their development and hence can lead to low-quality TLS. Relying on expert-crafted settings is neither scalable nor sustainable for processing many dynamically changing events. This paper presents a better TLS approach for automatically and dynamically determining the TLS timeline length. We achieve this by employing the established elbow method from the machine learning community to automatically find the minimum number of dates within the time series to generate concise and informative summaries. We applied our approach to four TLS datasets of English and Chinese and compared them against three prior methods. Experimental results show that our approach delivers comparable or even better summaries over state-of-art TLS methods, but it achieves this without expert involvement.
Deep neural network loses attention to adversarial images
Jun 10, 2021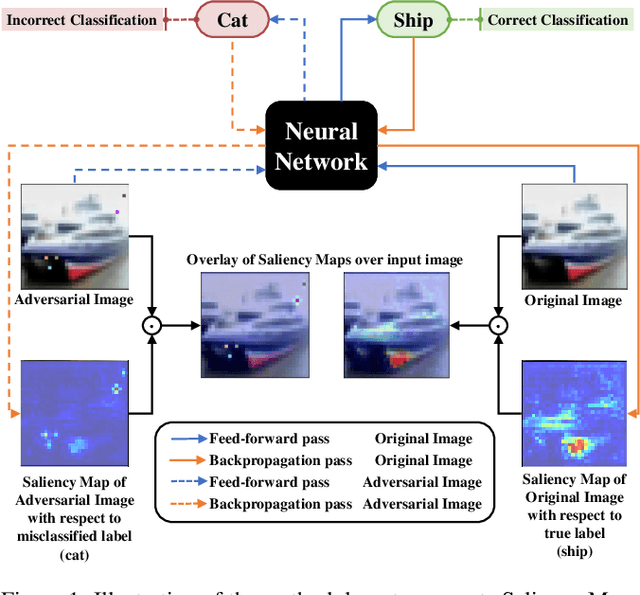



Adversarial algorithms have shown to be effective against neural networks for a variety of tasks. Some adversarial algorithms perturb all the pixels in the image minimally for the image classification task in image classification. In contrast, some algorithms perturb few pixels strongly. However, very little information is available regarding why these adversarial samples so diverse from each other exist. Recently, Vargas et al. showed that the existence of these adversarial samples might be due to conflicting saliency within the neural network. We test this hypothesis of conflicting saliency by analysing the Saliency Maps (SM) and Gradient-weighted Class Activation Maps (Grad-CAM) of original and few different types of adversarial samples. We also analyse how different adversarial samples distort the attention of the neural network compared to original samples. We show that in the case of Pixel Attack, perturbed pixels either calls the network attention to themselves or divert the attention from them. Simultaneously, the Projected Gradient Descent Attack perturbs pixels so that intermediate layers inside the neural network lose attention for the correct class. We also show that both attacks affect the saliency map and activation maps differently. Thus, shedding light on why some defences successful against some attacks remain vulnerable against other attacks. We hope that this analysis will improve understanding of the existence and the effect of adversarial samples and enable the community to develop more robust neural networks.
Multimodal Fusion with BERT and Attention Mechanism for Fake News Detection
Apr 27, 2021
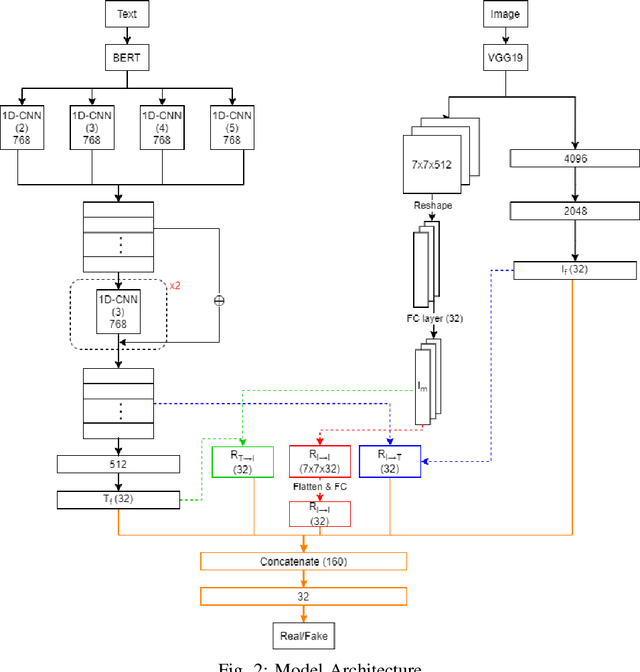
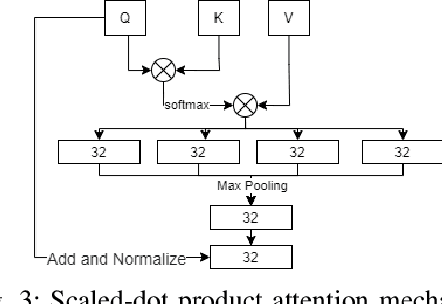

Fake news detection is an important task for increasing the credibility of information on the media since fake news is constantly spreading on social media every day and it is a very serious concern in our society. Fake news is usually created by manipulating images, texts, and videos. In this paper, we present a novel method for detecting fake news by fusing multimodal features derived from textual and visual data. Specifically, we used a pre-trained BERT model to learn text features and a VGG-19 model pre-trained on the ImageNet dataset to extract image features. We proposed a scale-dot product attention mechanism to capture the relationship between text features and visual features. Experimental results showed that our approach performs better than the current state-of-the-art method on a public Twitter dataset by 3.1% accuracy.
Markov Modeling of Time-Series Data using Symbolic Analysis
Mar 23, 2021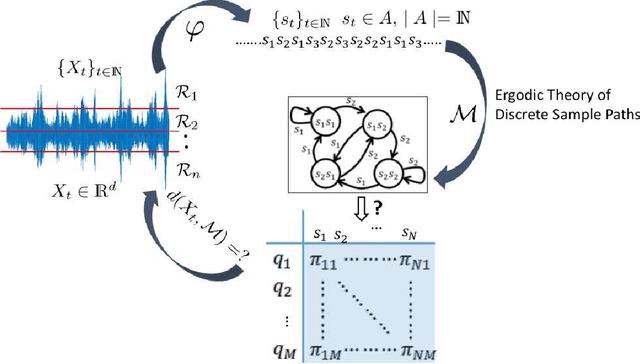

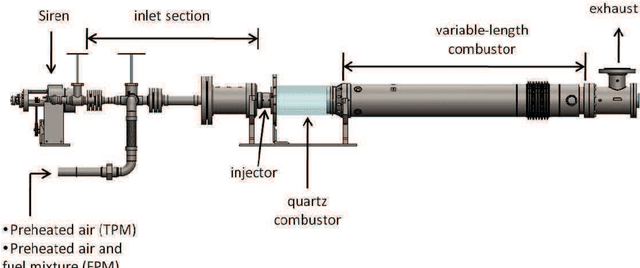
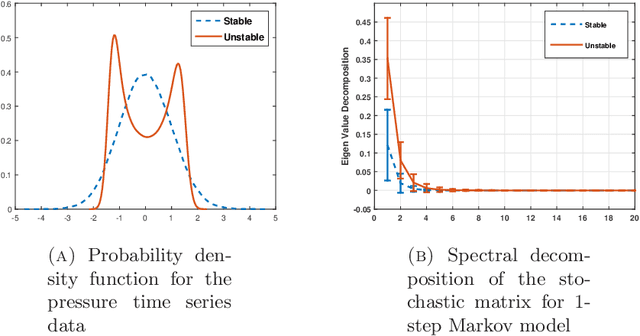
Markov models are often used to capture the temporal patterns of sequential data for statistical learning applications. While the Hidden Markov modeling-based learning mechanisms are well studied in literature, we analyze a symbolic-dynamics inspired approach. Under this umbrella, Markov modeling of time-series data consists of two major steps -- discretization of continuous attributes followed by estimating the size of temporal memory of the discretized sequence. These two steps are critical for the accurate and concise representation of time-series data in the discrete space. Discretization governs the information content of the resultant discretized sequence. On the other hand, memory estimation of the symbolic sequence helps to extract the predictive patterns in the discretized data. Clearly, the effectiveness of signal representation as a discrete Markov process depends on both these steps. In this paper, we will review the different techniques for discretization and memory estimation for discrete stochastic processes. In particular, we will focus on the individual problems of discretization and order estimation for discrete stochastic process. We will present some results from literature on partitioning from dynamical systems theory and order estimation using concepts of information theory and statistical learning. The paper also presents some related problem formulations which will be useful for machine learning and statistical learning application using the symbolic framework of data analysis. We present some results of statistical analysis of a complex thermoacoustic instability phenomenon during lean-premixed combustion in jet-turbine engines using the proposed Markov modeling method.
Greedy Sensor Placement for Weighted Linear-Least Squares Estimation under Correlated Noise
Apr 27, 2021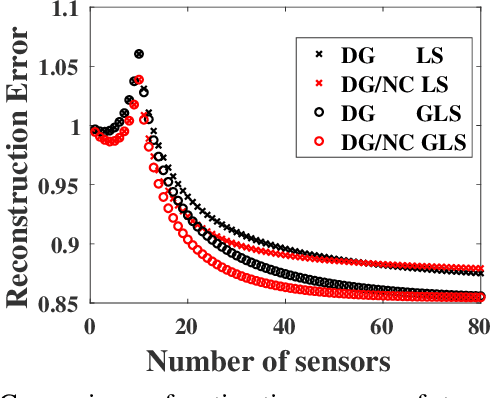
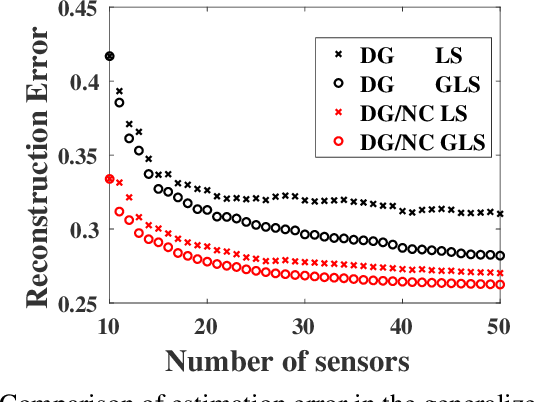
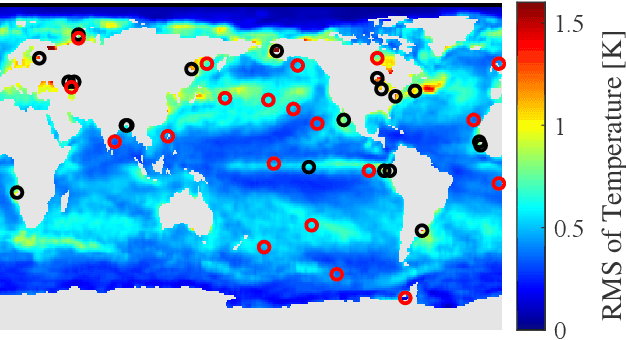
Optimization for sensor placement has been intensely studied to monitor complex, large scale systems, whereas one needs to overcome its intractable nature of the objective function for the optimization. In this study, a fast algorithm for greedy sensor selection is presented for a linear reduced-ordered reconstruction under the assumption of correlated noise on the sensor signals. The presented algorithm accomplishes the maximization of the determinant of the Fisher information matrix in the linear inverse problem, while this study firstly shows that the objective function with correlated noise is neither submodular nor supermodular. Efficient one-rank computations in the greedy selection procedure are introduced in both of the underdetermined and oversampled problem. Several numerical experiments show the effectiveness of the selection algorithm for its accuracy in the estimation of the states of large dimensional measurement data.
Towards Novel Target Discovery Through Open-Set Domain Adaptation
May 06, 2021
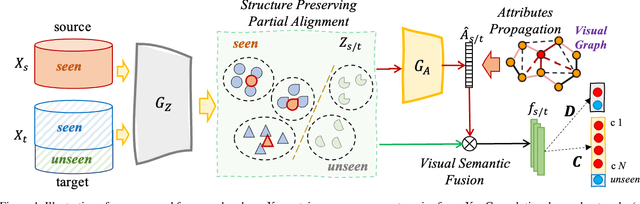
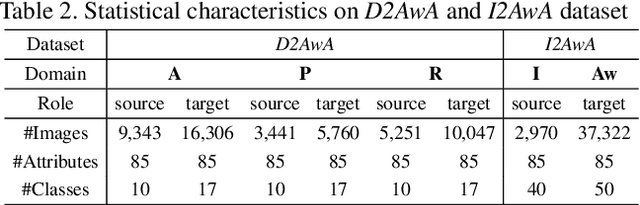
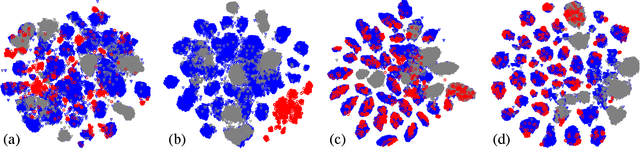
Open-set domain adaptation (OSDA) considers that the target domain contains samples from novel categories unobserved in external source domain. Unfortunately, existing OSDA methods always ignore the demand for the information of unseen categories and simply recognize them as "unknown" set without further explanation. This motivates us to understand the unknown categories more specifically by exploring the underlying structures and recovering their interpretable semantic attributes. In this paper, we propose a novel framework to accurately identify the seen categories in target domain, and effectively recover the semantic attributes for unseen categories. Specifically, structure preserving partial alignment is developed to recognize the seen categories through domain-invariant feature learning. Attribute propagation over visual graph is designed to smoothly transit attributes from seen to unseen categories via visual-semantic mapping. Moreover, two new cross-main benchmarks are constructed to evaluate the proposed framework in the novel and practical challenge. Experimental results on open-set recognition and semantic recovery demonstrate the superiority of the proposed method over other compared baselines.
Fast Frontier-based Information-driven Autonomous Exploration with an MAV
Feb 13, 2020
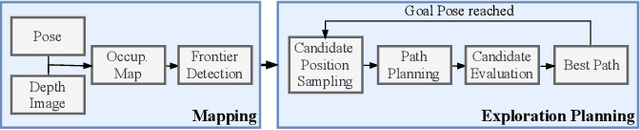

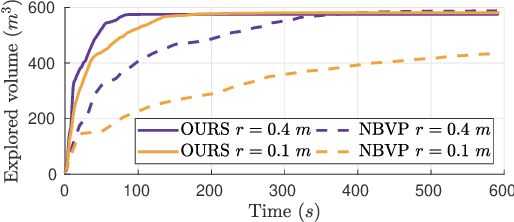
Exploration and collision-free navigation through an unknown environment is a fundamental task for autonomous robots. In this paper, a novel exploration strategy for Micro Aerial Vehicles (MAVs) is presented. The goal of the exploration strategy is the reduction of map entropy regarding occupancy probabilities, which is reflected in a utility function to be maximised. We achieve fast and efficient exploration performance with tight integration between our octree-based occupancy mapping approach, frontier extraction, and motion planning-as a hybrid between frontier-based and sampling-based exploration methods. The computationally expensive frontier clustering employed in classic frontier-based exploration is avoided by exploiting the implicit grouping of frontier voxels in the underlying octree map representation. Candidate next-views are sampled from the map frontiers and are evaluated using a utility function combining map entropy and travel time, where the former is computed efficiently using sparse raycasting. These optimisations along with the targeted exploration of frontier-based methods result in a fast and computationally efficient exploration planner. The proposed method is evaluated using both simulated and real-world experiments, demonstrating clear advantages over state-of-the-art approaches.
Audio-Visual Speech Separation Using Cross-Modal Correspondence Loss
Mar 02, 2021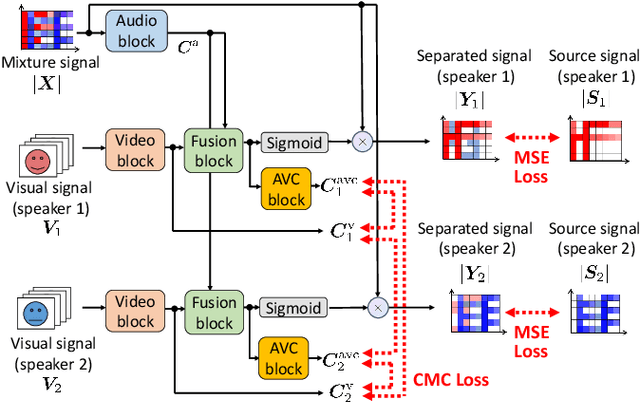
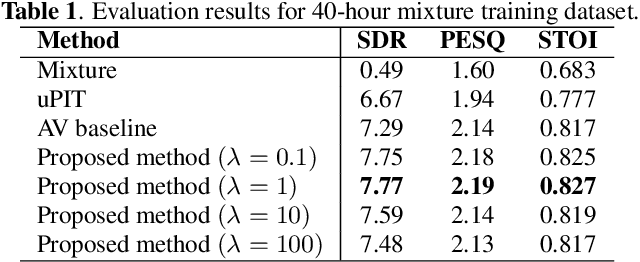

We present an audio-visual speech separation learning method that considers the correspondence between the separated signals and the visual signals to reflect the speech characteristics during training. Audio-visual speech separation is a technique to estimate the individual speech signals from a mixture using the visual signals of the speakers. Conventional studies on audio-visual speech separation mainly train the separation model on the audio-only loss, which reflects the distance between the source signals and the separated signals. However, conventional losses do not reflect the characteristics of the speech signals, including the speaker's characteristics and phonetic information, which leads to distortion or remaining noise. To address this problem, we propose the cross-modal correspondence (CMC) loss, which is based on the cooccurrence of the speech signal and the visual signal. Since the visual signal is not affected by background noise and contains speaker and phonetic information, using the CMC loss enables the audio-visual speech separation model to remove noise while preserving the speech characteristics. Experimental results demonstrate that the proposed method learns the cooccurrence on the basis of CMC loss, which improves separation performance.
Building Safer Autonomous Agents by Leveraging Risky Driving Behavior Knowledge
Mar 16, 2021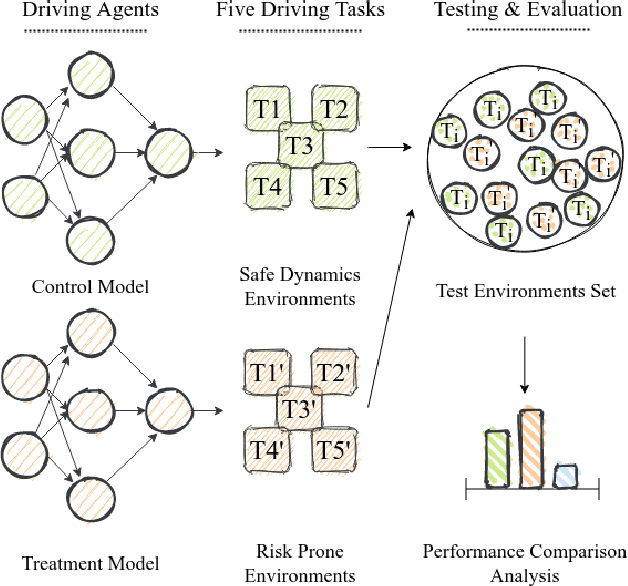
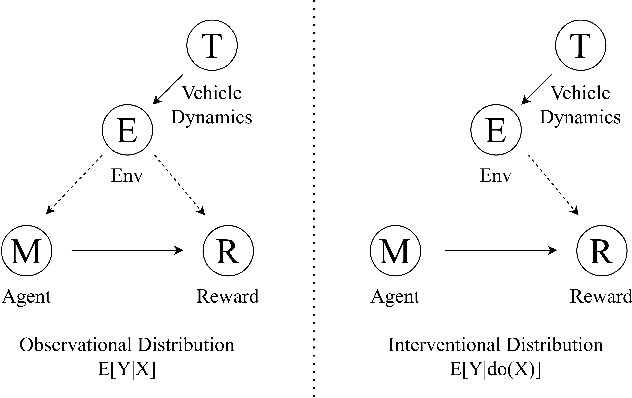
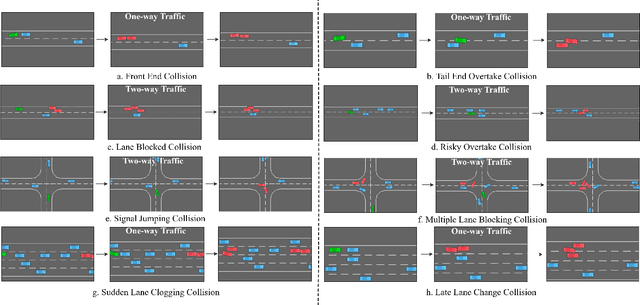
Simulation environments are good for learning different driving tasks like lane changing, parking or handling intersections etc. in an abstract manner. However, these simulation environments often restrict themselves to operate under conservative interactions behavior amongst different vehicles. But, as we know that the real driving tasks often involves very high risk scenarios where other drivers often don't behave in the expected sense. There can be many reasons for this behavior like being tired or inexperienced. The simulation environments doesn't take this information into account while training the navigation agent. Therefore, in this study we especially focus on systematically creating these risk prone scenarios with heavy traffic and unexpected random behavior for creating better model-free learning agents. We generate multiple autonomous driving scenarios by creating new custom Markov Decision Process (MDP) environment iterations in highway-env simulation package. The behavior policy is learnt by agents trained with the help from deep reinforcement learning models. Our behavior policy is deliberated to handle collisions and risky randomized driver behavior. We train model free learning agents with supplement information of risk prone driving scenarios and compare their performance with baseline agents. Finally, we casually measure the impact of adding these perturbations in the training process to precisely account for the performance improvement attained from utilizing the learnings from these scenarios.