 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tossing Quantum Coins and Dice
Mar 31, 2021
The procedure of tossing quantum coins and dice is described. This case is an important example of a quantum procedure because it presents a typical framework employed in quantum information processing and quantum computing. The emphasis is on the clarification of the difference between quantum and classical conditional probabilities. These probabilities are designed for characterizing different systems, either quantum or classical, and they, generally, cannot be reduced to each other. Thus the L\"{u}ders probability cannot be treated as a generalization of the classical conditional probability. The analogies between quantum theory of measurements and quantum decision theory are elucidated.
* 26 pages
Standardizing and Benchmarking Crisis-related Social Media Datasets for Humanitarian Information Processing
Apr 29, 2020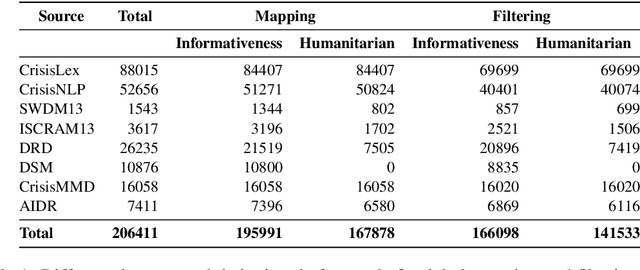
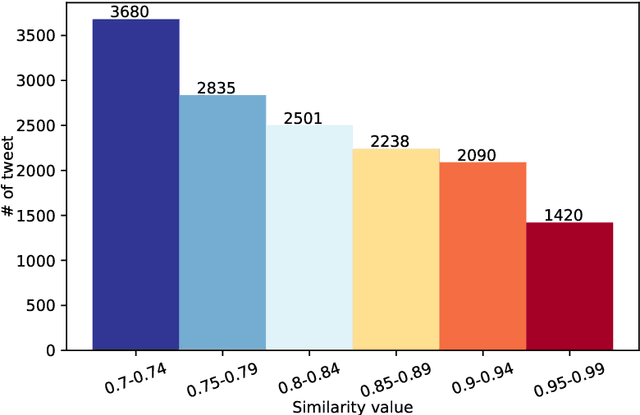
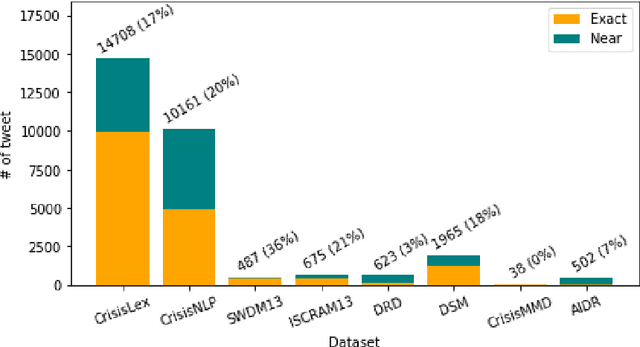
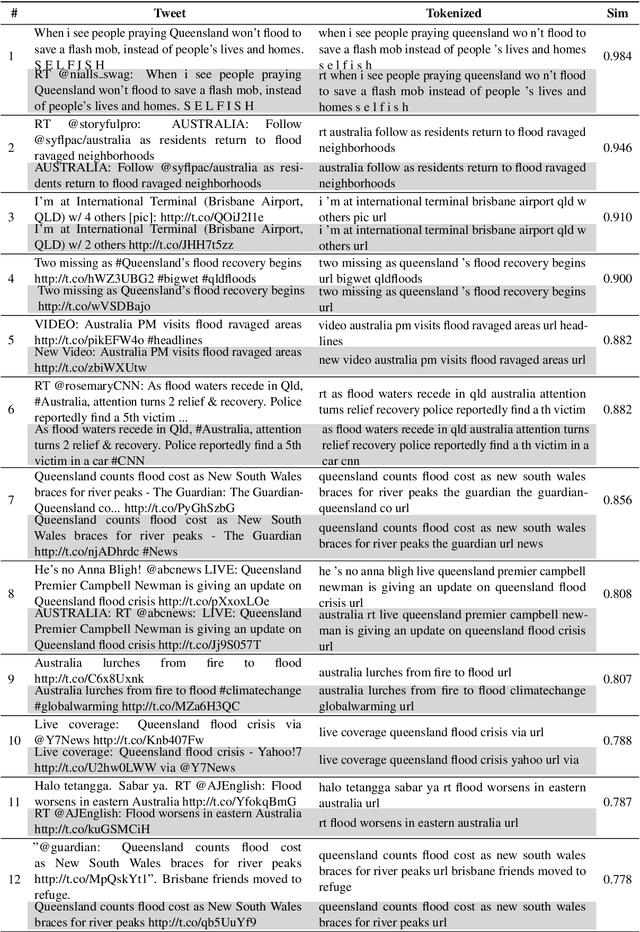
Time-critical analysis of social media streams is important for humanitarian organizations to plan rapid response during disasters. The crisis informatics research community has developed several techniques and systems to process and classify big crisis related data posted on social media. However, due to the dispersed nature of the datasets used in the literature, it is not possible to compare the results and measure the progress made towards better models for crisis informatics. In this work, we attempt to bridge this gap by standardizing various existing crisis-related datasets. We consolidate labels of eight annotated data sources and provide 166.1k and 141.5k tweets for informativeness and humanitarian classification tasks, respectively. The consolidation results in a larger dataset that affords the ability to train more sophisticated models. To that end, we provide baseline results using CNN and BERT models. We make the dataset available at https://crisisnlp.qcri.org/crisis_datasets_benchmarks.html.
Applying the Affective Aware Pseudo Association Method to Enhance the Top-N Recommendations Distribution to Users in Group Emotion Recommender Systems
Feb 08, 2021
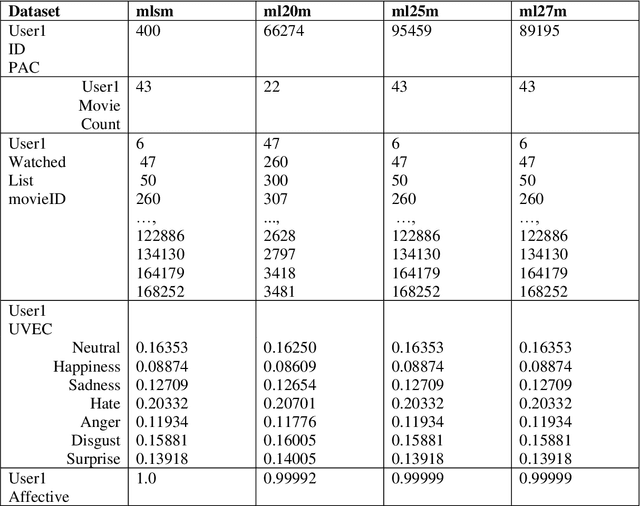
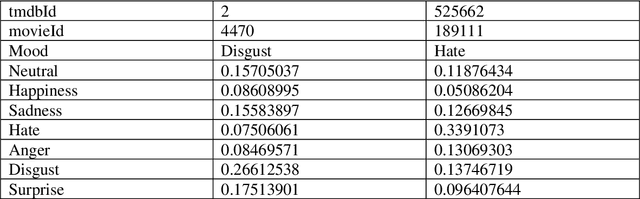

Recommender Systems are a subclass of information retrieval systems, or more succinctly, a class of information filtering systems that seeks to predict how close is the match of the user's preference to a recommended item. A common approach for making recommendations for a user group is to extend Personalized Recommender Systems' capability. This approach gives the impression that group recommendations are retrofits of the Personalized Recommender Systems. Moreover, such an approach not taken the dynamics of group emotion and individual emotion into the consideration in making top_N recommendations. Recommending items to a group of two or more users has certainly raised unique challenges in group behaviors that influence group decision-making that researchers only partially understand. This study applies the Affective Aware Pseudo Association Method in studying group formation and dynamics in group decision-making. The method shows its adaptability to group's moods change when making recommendations.
Advances on image interpolation based on ant colony algorithm
Apr 12, 2021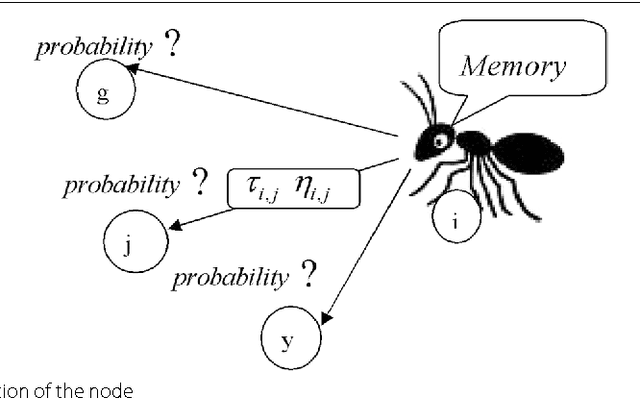

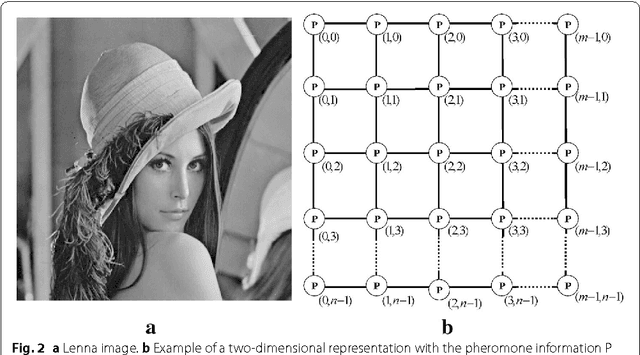

This paper presents an advance on image interpolation based on ant colony algorithm (AACA) for high-resolution image scaling. The difference between the proposed algorithm and the previously proposed optimization of bilinear interpolation based on ant colony algorithm (OBACA) is that AACA uses global weighting, whereas OBACA uses a local weighting scheme. The strength of the proposed global weighting of the AACA algorithm depends on employing solely the pheromone matrix information present on any group of four adjacent pixels to decide which case deserves a maximum global weight value or not. Experimental results are further provided to show the higher performance of the proposed AACA algorithm with reference to the algorithms mentioned in this paper.
* 17 pages, 14 figures, 3 tables
Audio-Visual Speech Separation Using Cross-Modal Correspondence Loss
Mar 02, 2021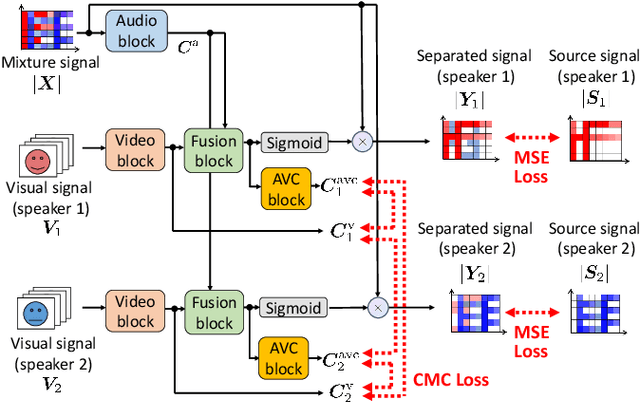
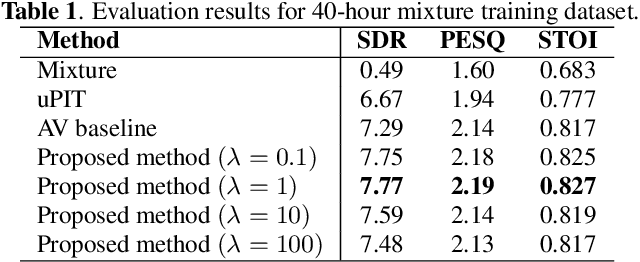
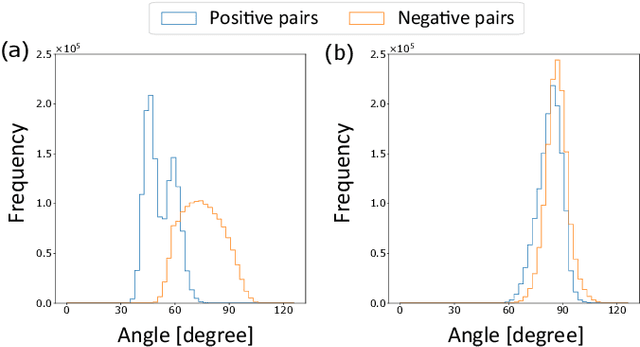

We present an audio-visual speech separation learning method that considers the correspondence between the separated signals and the visual signals to reflect the speech characteristics during training. Audio-visual speech separation is a technique to estimate the individual speech signals from a mixture using the visual signals of the speakers. Conventional studies on audio-visual speech separation mainly train the separation model on the audio-only loss, which reflects the distance between the source signals and the separated signals. However, conventional losses do not reflect the characteristics of the speech signals, including the speaker's characteristics and phonetic information, which leads to distortion or remaining noise. To address this problem, we propose the cross-modal correspondence (CMC) loss, which is based on the cooccurrence of the speech signal and the visual signal. Since the visual signal is not affected by background noise and contains speaker and phonetic information, using the CMC loss enables the audio-visual speech separation model to remove noise while preserving the speech characteristics. Experimental results demonstrate that the proposed method learns the cooccurrence on the basis of CMC loss, which improves separation performance.
Complex-valued reservoir computing for aspect classification and slope-angle estimation with low computational cost and high resolution in interferometric synthetic aperture radar
Apr 22, 2021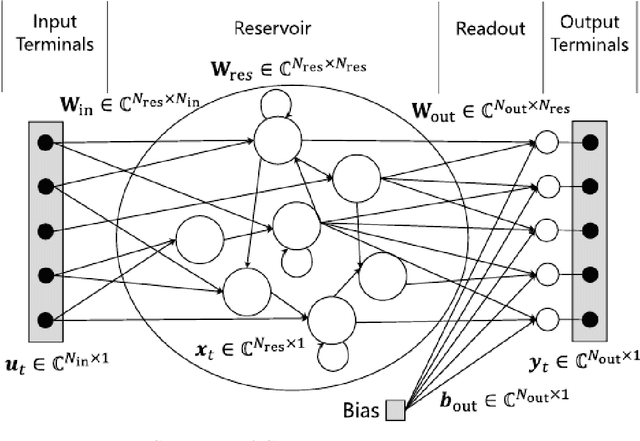

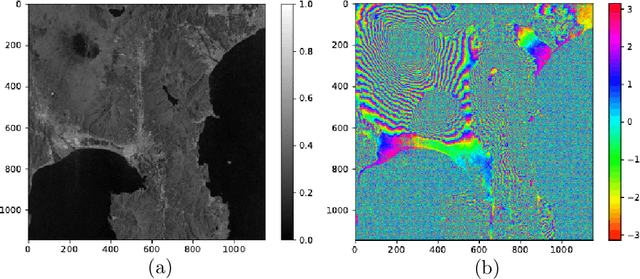

Synthetic aperture radar (SAR) is widely used for ground surface classification since it utilizes information on vegetation and soil unavailable in optical observation. Image classification often employs convolutional neural networks. However, they have serious problems such as long learning time and resolution degradation in their convolution and pooling processes. In this paper, we propose complex-valued reservoir computing (CVRC) to deal with complex-valued images in interferometric SAR (InSAR). We classify InSAR image data by using CVRC successfully with a higher resolution and a lower computational cost, i.e., one-hundredth learning time and one-fifth classification time, than convolutional neural networks. We also conduct experiments on slope angle estimation. CVRC is found applicable to quantitative tasks dealing with continuous values as well as discrete classification tasks with a higher accuracy.
Spatio-attentive Graphs for Human-Object Interaction Detection
Dec 11, 2020
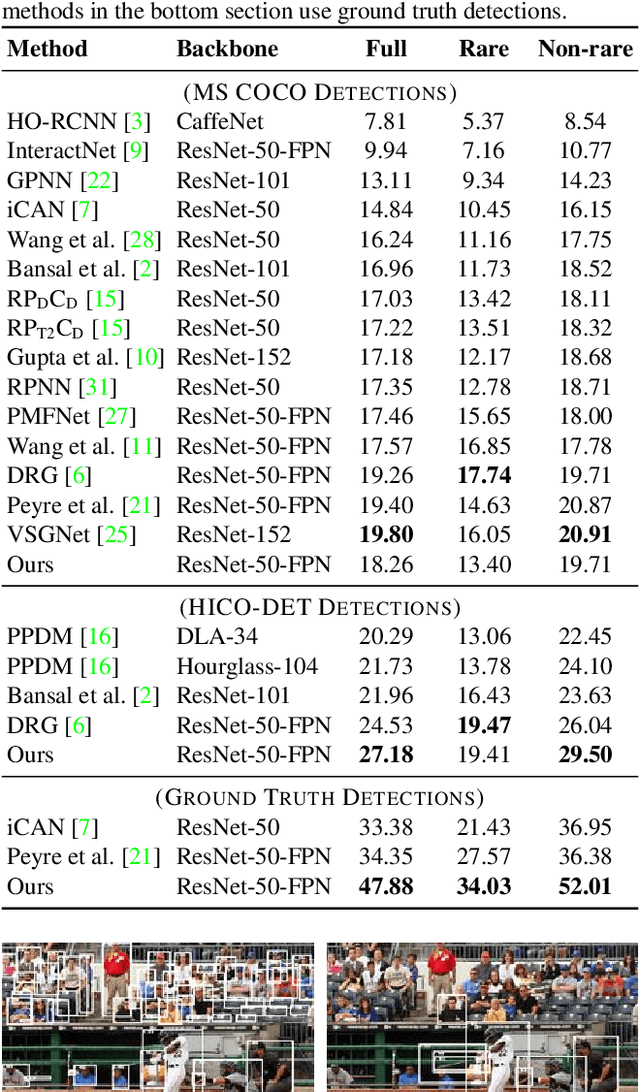
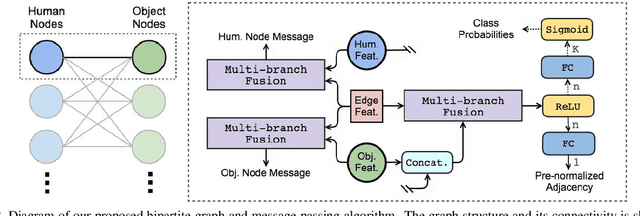
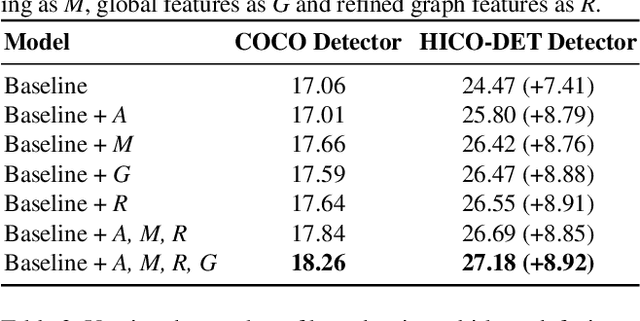
We address the problem of detecting human--object interactions in images using graphical neural networks. Our network constructs a bipartite graph of nodes representing detected humans and objects, wherein messages passed between the nodes encode relative spatial and appearance information. Unlike existing approaches that separate appearance and spatial features, our method fuses these two cues within a single graphical model allowing information conditioned on both modalities to influence the prediction of interactions with neighboring nodes. Through extensive experimentation we demonstrate the advantages of fusing relative spatial information with appearance features in the computation of adjacency structure, message passing and the ultimate refined graph features. On the popular HICO-DET benchmark dataset, our model outperforms state-of-the-art with an mAP of 27.18, a 10% relative improvement.
Towards 3D Metric GPR Imaging Based on DNN Noise Removal and Dielectric Estimation
May 15, 2021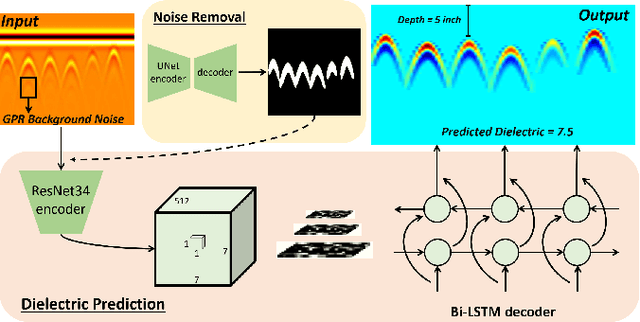

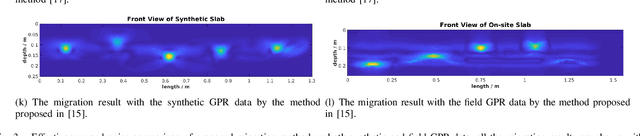
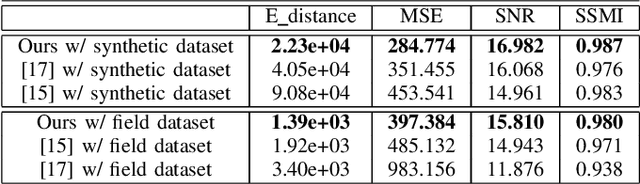
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) devices to detect subsurface objects (i.e., rebars, utility pipes) and reveal the underground scene. The two biggest challenges in GPR-based inspection are the GPR data collection and subsurface target imaging. To address these challenges, we propose a robotic solution that automates the GPR data collection process with a free motion pattern. It facilitates the 3D metric GPR imaging by tagging the pose information with GPR measurement in real-time. We also introduce a deep neural network (DNN) based GPR data analysis method which includes a noise removal segmentation module to clear the noise in GPR raw data and a DielectricNet to estimate the dielectric value of subsurface media in each GPR B-scan data. We use both the field and synthetic data to verify the proposed method. Experimental results demonstrate that our proposed method can achieve better performance and faster processing speed in GPR data collection and 3D GPR imaging than other methods.
* under review
A Large Visual, Qualitative and Quantitative Dataset of Web Pages
May 15, 2021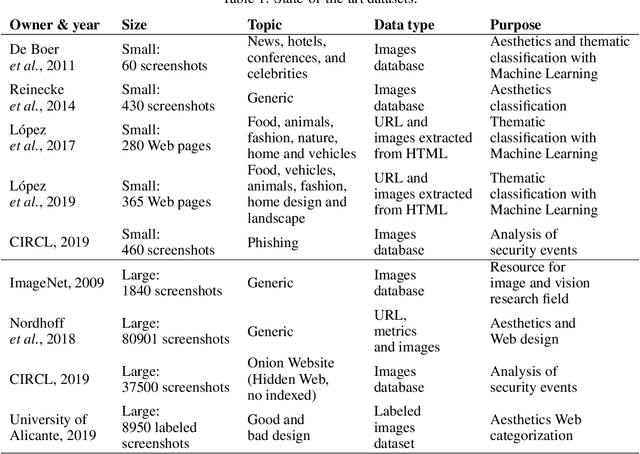

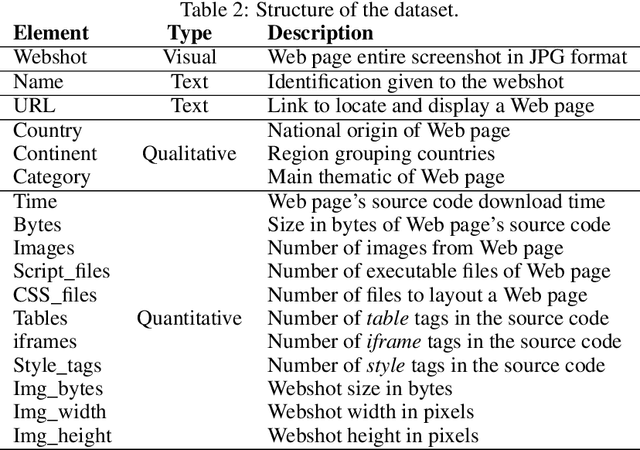
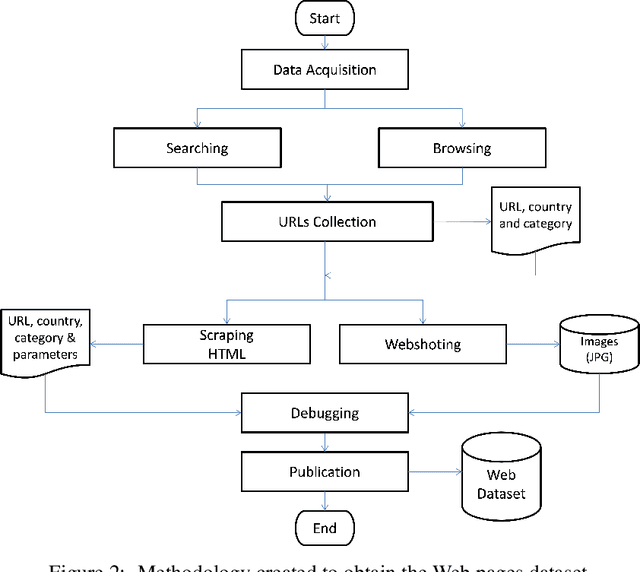
The World Wide Web is not only one of the most important platforms of communication and information at present, but also an area of growing interest for scientific research. This motivates a lot of work and projects that require large amounts of data. However, there is no dataset that integrates the parameters and visual appearance of Web pages, because its collection is a costly task in terms of time and effort. With the support of various computer tools and programming scripts, we have created a large dataset of 49,438 Web pages. It consists of visual, textual and numerical data types, includes all countries worldwide, and considers a broad range of topics such as art, entertainment, economy, business, education, government, news, media, science, and environment, covering different cultural characteristics and varied design preferences. In this paper, we describe the process of collecting, debugging and publishing the final product, which is freely available. To demonstrate the usefulness of our dataset, we expose a binary classification model for detecting error Web pages, and a multi-class Web subject-based categorization, both problems using convolutional neural networks.
Building Safer Autonomous Agents by Leveraging Risky Driving Behavior Knowledge
Mar 16, 2021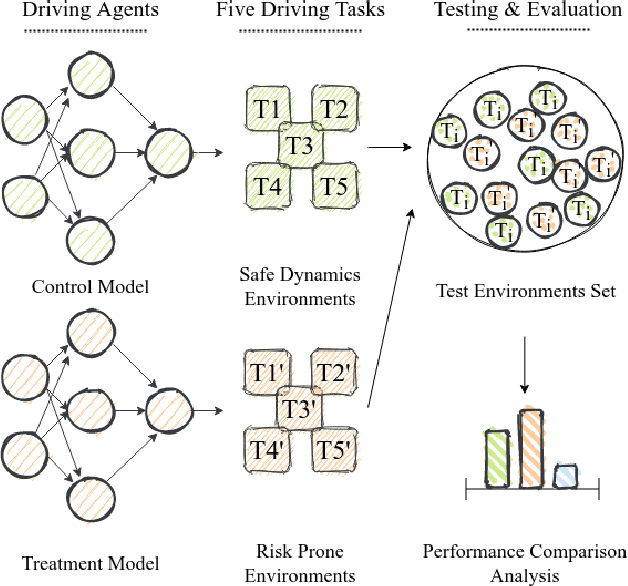
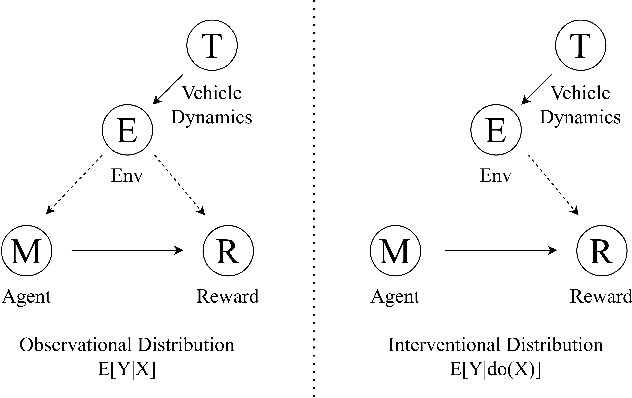
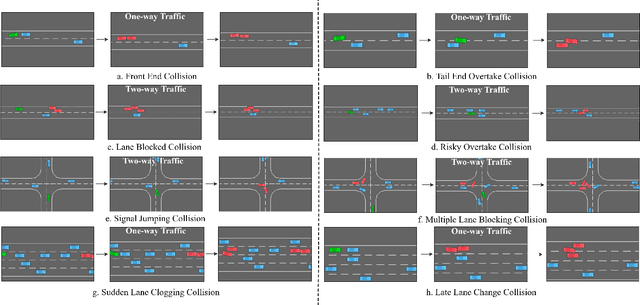
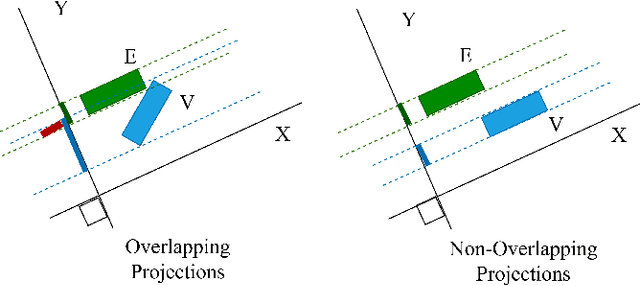
Simulation environments are good for learning different driving tasks like lane changing, parking or handling intersections etc. in an abstract manner. However, these simulation environments often restrict themselves to operate under conservative interactions behavior amongst different vehicles. But, as we know that the real driving tasks often involves very high risk scenarios where other drivers often don't behave in the expected sense. There can be many reasons for this behavior like being tired or inexperienced. The simulation environments doesn't take this information into account while training the navigation agent. Therefore, in this study we especially focus on systematically creating these risk prone scenarios with heavy traffic and unexpected random behavior for creating better model-free learning agents. We generate multiple autonomous driving scenarios by creating new custom Markov Decision Process (MDP) environment iterations in highway-env simulation package. The behavior policy is learnt by agents trained with the help from deep reinforcement learning models. Our behavior policy is deliberated to handle collisions and risky randomized driver behavior. We train model free learning agents with supplement information of risk prone driving scenarios and compare their performance with baseline agents. Finally, we casually measure the impact of adding these perturbations in the training process to precisely account for the performance improvement attained from utilizing the learnings from these scenarios.