 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
May 07, 2021
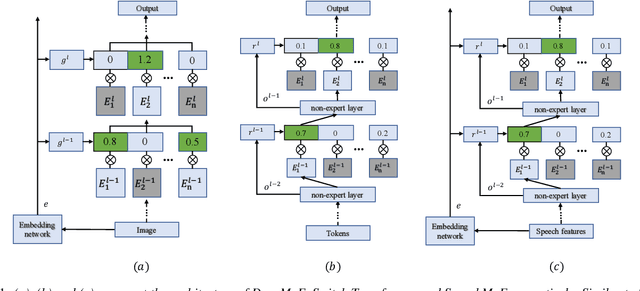
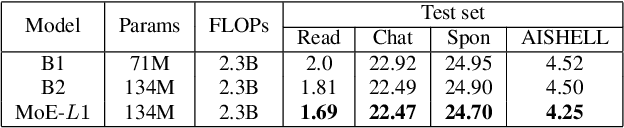
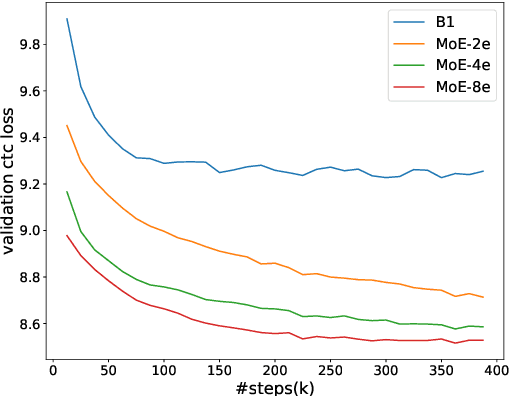
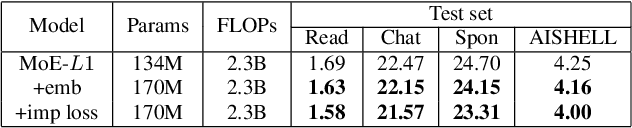
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.
Analysis and Optimisation of Bellman Residual Errors with Neural Function Approximation
Jun 16, 2021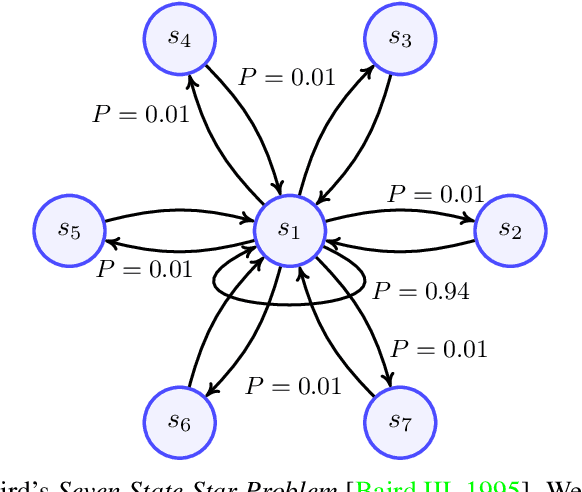
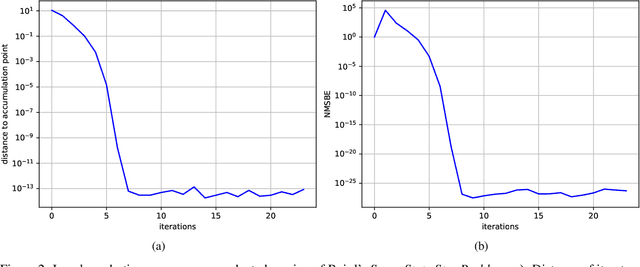
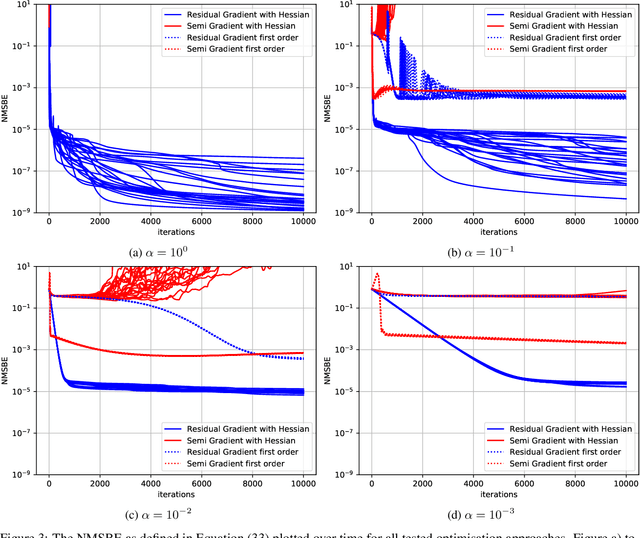
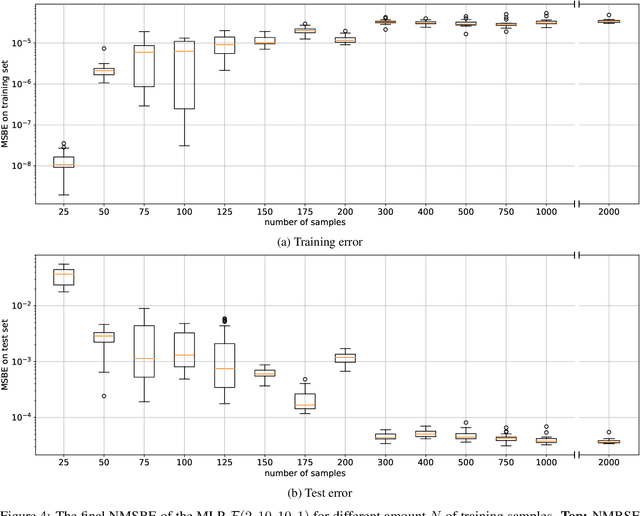
Recent development of Deep Reinforcement Learning has demonstrated superior performance of neural networks in solving challenging problems with large or even continuous state spaces. One specific approach is to deploy neural networks to approximate value functions by minimising the Mean Squared Bellman Error function. Despite great successes of Deep Reinforcement Learning, development of reliable and efficient numerical algorithms to minimise the Bellman Error is still of great scientific interest and practical demand. Such a challenge is partially due to the underlying optimisation problem being highly non-convex or using incorrect gradient information as done in Semi-Gradient algorithms. In this work, we analyse the Mean Squared Bellman Error from a smooth optimisation perspective combined with a Residual Gradient formulation. Our contribution is two-fold. First, we analyse critical points of the error function and provide technical insights on the optimisation procure and design choices for neural networks. When the existence of global minima is assumed and the objective fulfils certain conditions we can eliminate suboptimal local minima when using over-parametrised neural networks. We can construct an efficient Approximate Newton's algorithm based on our analysis and confirm theoretical properties of this algorithm such as being locally quadratically convergent to a global minimum numerically. Second, we demonstrate feasibility and generalisation capabilities of the proposed algorithm empirically using continuous control problems and provide a numerical verification of our critical point analysis. We outline the short coming of Semi-Gradients. To benefit from an approximate Newton's algorithm complete derivatives of the Mean Squared Bellman error must be considered during training.
Developing Annotated Resources for Internal Displacement Monitoring
Apr 12, 2021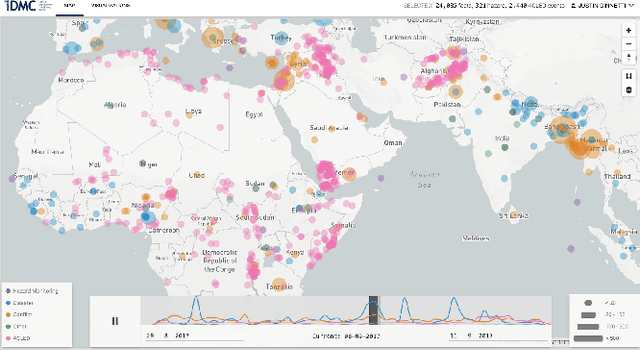
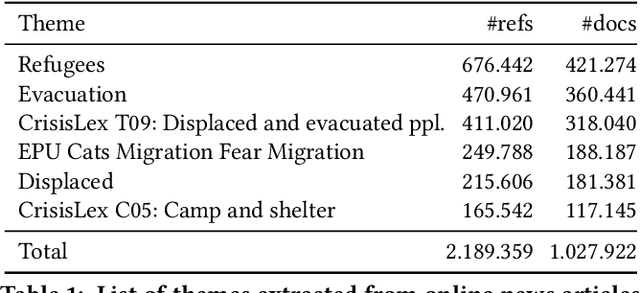
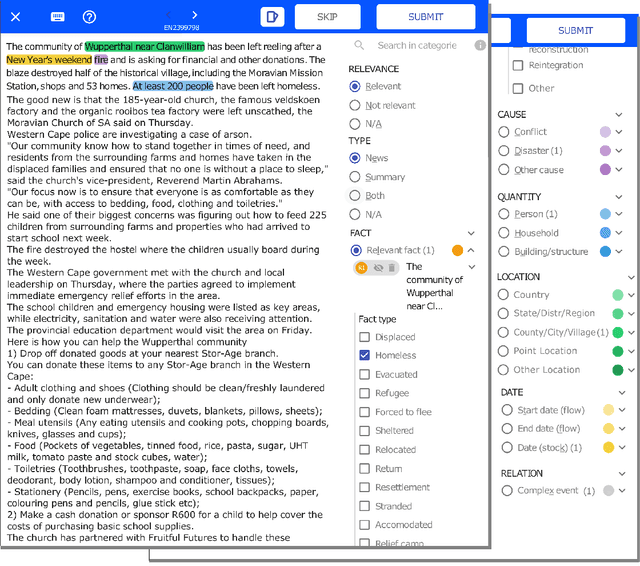
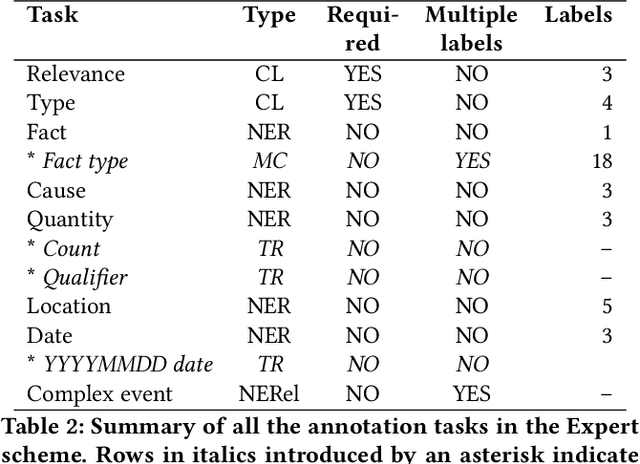
This paper describes in details the design and development of a novel annotation framework and of annotated resources for Internal Displacement, as the outcome of a collaboration with the Internal Displacement Monitoring Centre, aimed at improving the accuracy of their monitoring platform IDETECT. The schema includes multi-faceted description of the events, including cause, quantity of people displaced, location and date. Higher-order facets aimed at improving the information extraction, such as document relevance and type, are proposed. We also report a case study of machine learning application to the document classification tasks. Finally, we discuss the importance of standardized schema in dataset benchmark development and its impact on the development of reliable disaster monitoring infrastructure.
A Two-stream Neural Network for Pose-based Hand Gesture Recognition
Jan 22, 2021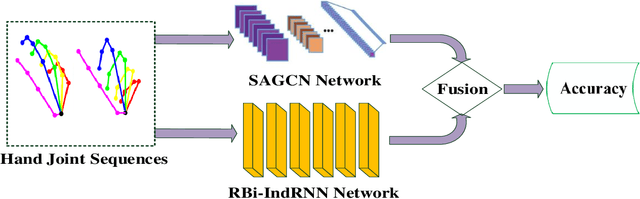
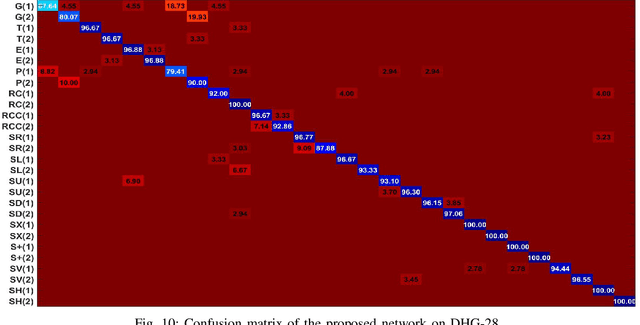

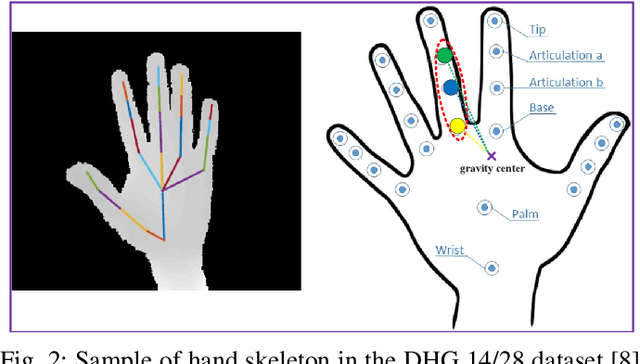
Pose based hand gesture recognition has been widely studied in the recent years. Compared with full body action recognition, hand gesture involves joints that are more spatially closely distributed with stronger collaboration. This nature requires a different approach from action recognition to capturing the complex spatial features. Many gesture categories, such as "Grab" and "Pinch", have very similar motion or temporal patterns posing a challenge on temporal processing. To address these challenges, this paper proposes a two-stream neural network with one stream being a self-attention based graph convolutional network (SAGCN) extracting the short-term temporal information and hierarchical spatial information, and the other being a residual-connection enhanced bidirectional Independently Recurrent Neural Network (RBi-IndRNN) for extracting long-term temporal information. The self-attention based graph convolutional network has a dynamic self-attention mechanism to adaptively exploit the relationships of all hand joints in addition to the fixed topology and local feature extraction in the GCN. On the other hand, the residual-connection enhanced Bi-IndRNN extends an IndRNN with the capability of bidirectional processing for temporal modelling. The two streams are fused together for recognition. The Dynamic Hand Gesture dataset and First-Person Hand Action dataset are used to validate its effectiveness, and our method achieves state-of-the-art performance.
Techniques for Jointly Extracting Entities and Relations: A Survey
Mar 10, 2021
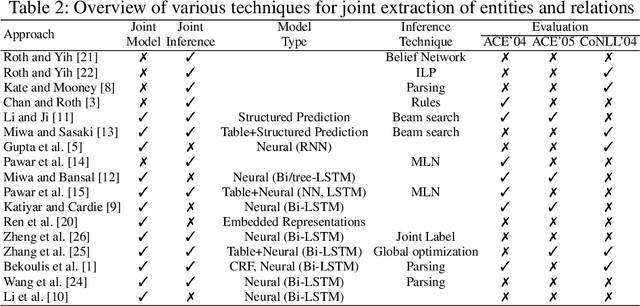
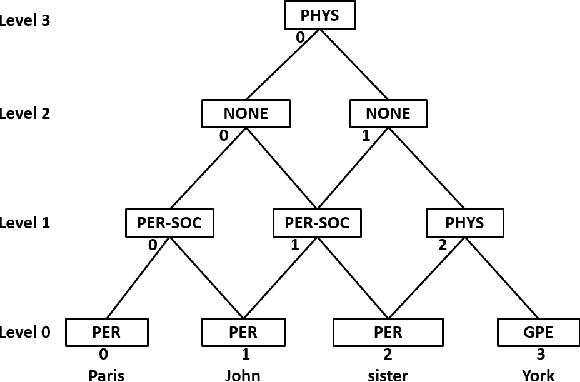
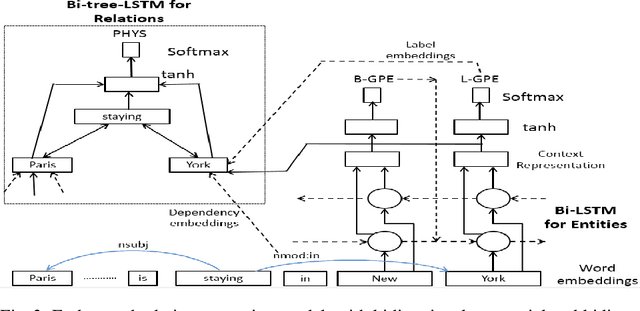
Relation Extraction is an important task in Information Extraction which deals with identifying semantic relations between entity mentions. Traditionally, relation extraction is carried out after entity extraction in a "pipeline" fashion, so that relation extraction only focuses on determining whether any semantic relation exists between a pair of extracted entity mentions. This leads to propagation of errors from entity extraction stage to relation extraction stage. Also, entity extraction is carried out without any knowledge about the relations. Hence, it was observed that jointly performing entity and relation extraction is beneficial for both the tasks. In this paper, we survey various techniques for jointly extracting entities and relations. We categorize techniques based on the approach they adopt for joint extraction, i.e. whether they employ joint inference or joint modelling or both. We further describe some representative techniques for joint inference and joint modelling. We also describe two standard datasets, evaluation techniques and performance of the joint extraction approaches on these datasets. We present a brief analysis of application of a general domain joint extraction approach to a Biomedical dataset. This survey is useful for researchers as well as practitioners in the field of Information Extraction, by covering a broad landscape of joint extraction techniques.
Towards 3D Metric GPR Imaging Based on DNN Noise Removal and Dielectric Estimation
May 15, 2021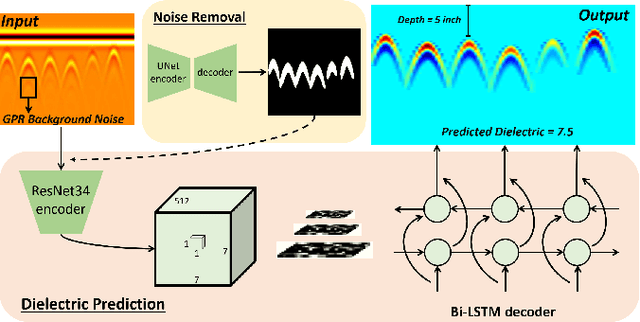

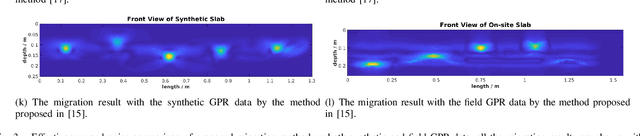
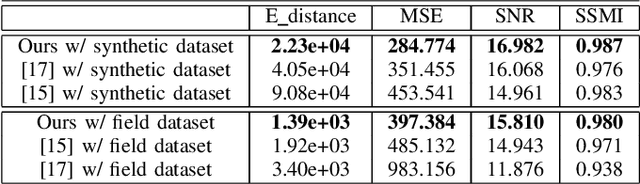
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) devices to detect subsurface objects (i.e., rebars, utility pipes) and reveal the underground scene. The two biggest challenges in GPR-based inspection are the GPR data collection and subsurface target imaging. To address these challenges, we propose a robotic solution that automates the GPR data collection process with a free motion pattern. It facilitates the 3D metric GPR imaging by tagging the pose information with GPR measurement in real-time. We also introduce a deep neural network (DNN) based GPR data analysis method which includes a noise removal segmentation module to clear the noise in GPR raw data and a DielectricNet to estimate the dielectric value of subsurface media in each GPR B-scan data. We use both the field and synthetic data to verify the proposed method. Experimental results demonstrate that our proposed method can achieve better performance and faster processing speed in GPR data collection and 3D GPR imaging than other methods.
* under review
Solving Sokoban with forward-backward reinforcement learning
May 22, 2021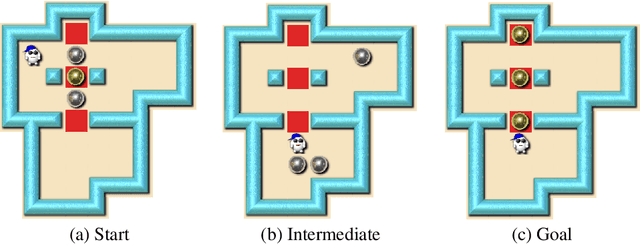
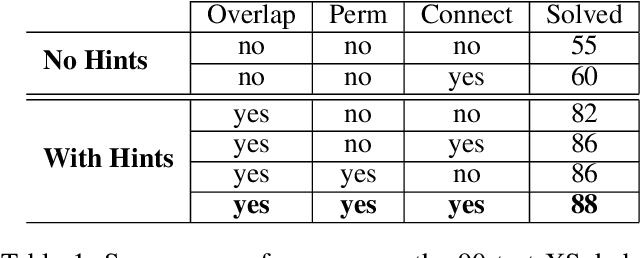
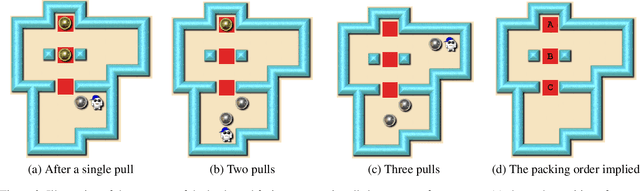
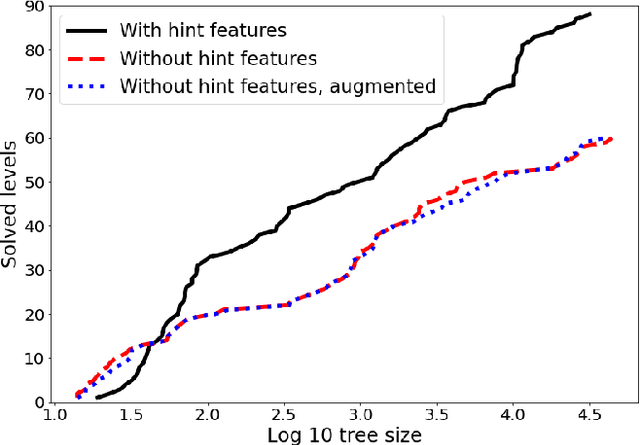
Despite seminal advances in reinforcement learning in recent years, many domains where the rewards are sparse, e.g. given only at task completion, remain quite challenging. In such cases, it can be beneficial to tackle the task both from its beginning and end, and make the two ends meet. Existing approaches that do so, however, are not effective in the common scenario where the strategy needed near the end goal is very different from the one that is effective earlier on. In this work we propose a novel RL approach for such settings. In short, we first train a backward-looking agent with a simple relaxed goal, and then augment the state representation of the forward-looking agent with straightforward hint features. This allows the learned forward agent to leverage information from backward plans, without mimicking their policy. We demonstrate the efficacy of our approach on the challenging game of Sokoban, where we substantially surpass learned solvers that generalize across levels, and are competitive with SOTA performance of the best highly-crafted systems. Impressively, we achieve these results while learning from a small number of practice levels and using simple RL techniques.
A Large Visual, Qualitative and Quantitative Dataset of Web Pages
May 15, 2021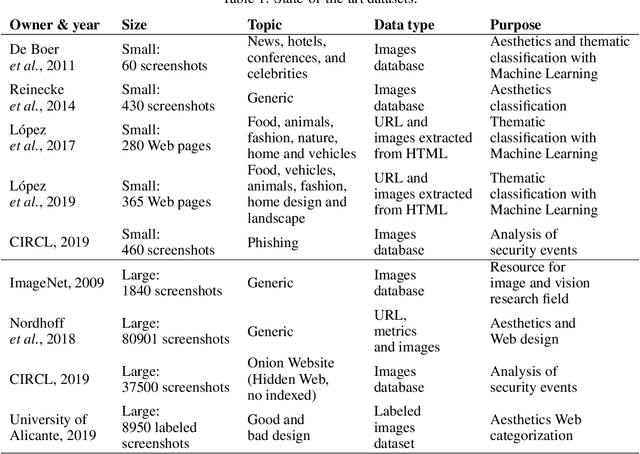

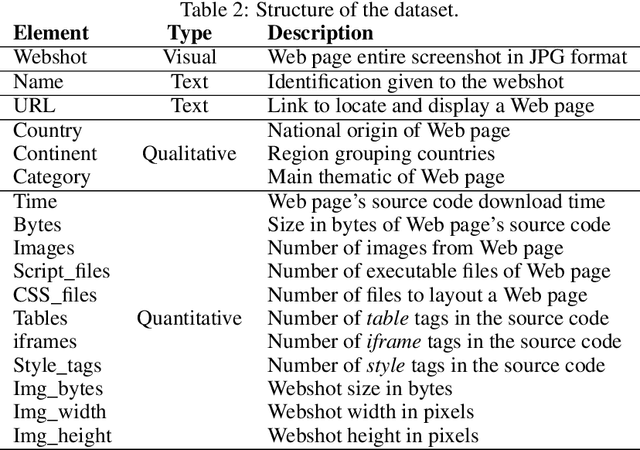
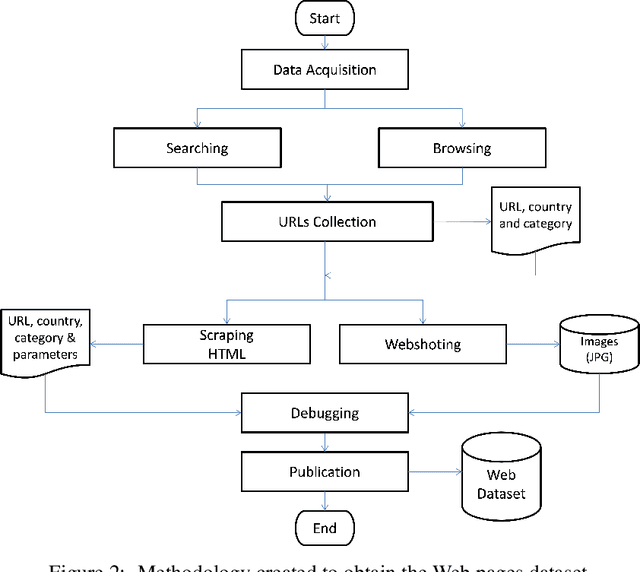
The World Wide Web is not only one of the most important platforms of communication and information at present, but also an area of growing interest for scientific research. This motivates a lot of work and projects that require large amounts of data. However, there is no dataset that integrates the parameters and visual appearance of Web pages, because its collection is a costly task in terms of time and effort. With the support of various computer tools and programming scripts, we have created a large dataset of 49,438 Web pages. It consists of visual, textual and numerical data types, includes all countries worldwide, and considers a broad range of topics such as art, entertainment, economy, business, education, government, news, media, science, and environment, covering different cultural characteristics and varied design preferences. In this paper, we describe the process of collecting, debugging and publishing the final product, which is freely available. To demonstrate the usefulness of our dataset, we expose a binary classification model for detecting error Web pages, and a multi-class Web subject-based categorization, both problems using convolutional neural networks.
Online Behavioral Analysis with Application to Emotion State Identification
Feb 27, 2021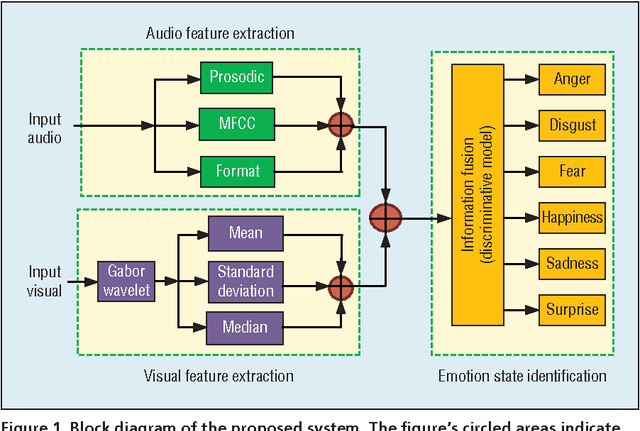

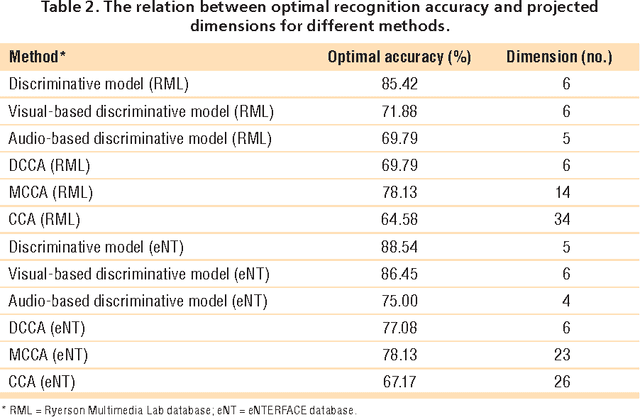
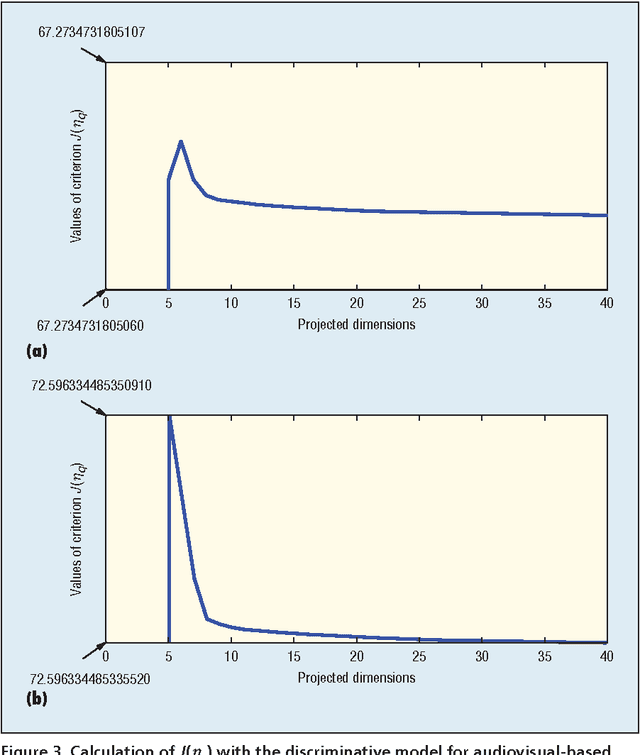
In this paper, we propose a novel discriminative model for online behavioral analysis with application to emotion state identification. The proposed model is able to extract more discriminative characteristics from behavioral data effectively and find the direction of optimal projection efficiently to satisfy requirements of online data analysis, leading to better utilization of the behavioral information to produce more accurate recognition results.
Q-learning algorithm for resource allocation in WDMA-based optical wireless communication networks
May 22, 2021



Visible Light Communication (VLC) has been widely investigated during the last decade due to its ability to provide high data rates with low power consumption. In general, resource management is an important issue in cellular networks that can highly effect their performance. In this paper, an optimisation problem is formulated to assign each user to an optimal access point and a wavelength at a given time. This problem can be solved using mixed integer linear programming (MILP). However, using MILP is not considered a practical solution due to its complexity and memory requirements. In addition, accurate information must be provided to perform the resource allocation. Therefore, the optimisation problem is reformulated using reinforcement learning (RL), which has recently received tremendous interest due to its ability to interact with any environment without prior knowledge. In this paper, we investigate solving the resource allocation optimisation problem in VLC systems using the basic Q-learning algorithm. Two scenarios are simulated to compare the results with the previously proposed MILP model. The results demonstrate the ability of the Q-learning algorithm to provide optimal solutions close to the MILP model without prior knowledge of the system.