 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Context-Former: Stitching via Latent Conditioned Sequence Modeling
Feb 03, 2024
Offline reinforcement learning (RL) algorithms can improve the decision making via stitching sub-optimal trajectories to obtain more optimal ones. This capability is a crucial factor in enabling RL to learn policies that are superior to the behavioral policy. On the other hand, Decision Transformer (DT) abstracts the decision-making as sequence modeling, showcasing competitive performance on offline RL benchmarks, however, recent studies demonstrate that DT lacks of stitching capability, thus exploit stitching capability for DT is vital to further improve its performance. In order to endow stitching capability to DT, we abstract trajectory stitching as expert matching and introduce our approach, ContextFormer, which integrates contextual information-based imitation learning (IL) and sequence modeling to stitch sub-optimal trajectory fragments by emulating the representations of a limited number of expert trajectories. To validate our claim, we conduct experiments from two perspectives: 1) We conduct extensive experiments on D4RL benchmarks under the settings of IL, and experimental results demonstrate ContextFormer can achieve competitive performance in multi-IL settings. 2) More importantly, we conduct a comparison of ContextFormer with diverse competitive DT variants using identical training datasets. The experimental results unveiled ContextFormer's superiority, as it outperformed all other variants, showcasing its remarkable performance.
The Bigger the Better? Rethinking the Effective Model Scale in Long-term Time Series Forecasting
Feb 03, 2024Long-term time series forecasting (LTSF) represents a critical frontier in time series analysis, distinguished by its focus on extensive input sequences, in contrast to the constrained lengths typical of traditional approaches. While longer sequences inherently convey richer information, potentially enhancing predictive precision, prevailing techniques often respond by escalating model complexity. These intricate models can inflate into millions of parameters, incorporating parameter-intensive elements like positional encodings, feed-forward networks and self-attention mechanisms. This complexity, however, leads to prohibitive model scale, particularly given the time series data's semantic simplicity. Motivated by the pursuit of parsimony, our research employs conditional correlation and auto-correlation as investigative tools, revealing significant redundancies within the input data. Leveraging these insights, we introduce the HDformer, a lightweight Transformer variant enhanced with hierarchical decomposition. This novel architecture not only inverts the prevailing trend toward model expansion but also accomplishes precise forecasting with drastically fewer computations and parameters. Remarkably, HDformer outperforms existing state-of-the-art LTSF models, while requiring over 99\% fewer parameters. Through this work, we advocate a paradigm shift in LTSF, emphasizing the importance to tailor the model to the inherent dynamics of time series data-a timely reminder that in the realm of LTSF, bigger is not invariably better.
An explainable machine learning-based approach for analyzing customers' online data to identify the importance of product attributes
Feb 03, 2024Online customer data provides valuable information for product design and marketing research, as it can reveal the preferences of customers. However, analyzing these data using artificial intelligence (AI) for data-driven design is a challenging task due to potential concealed patterns. Moreover, in these research areas, most studies are only limited to finding customers' needs. In this study, we propose a game theory machine learning (ML) method that extracts comprehensive design implications for product development. The method first uses a genetic algorithm to select, rank, and combine product features that can maximize customer satisfaction based on online ratings. Then, we use SHAP (SHapley Additive exPlanations), a game theory method that assigns a value to each feature based on its contribution to the prediction, to provide a guideline for assessing the importance of each feature for the total satisfaction. We apply our method to a real-world dataset of laptops from Kaggle, and derive design implications based on the results. Our approach tackles a major challenge in the field of multi-criteria decision making and can help product designers and marketers, to understand customer preferences better with less data and effort. The proposed method outperforms benchmark methods in terms of relevant performance metrics.
Stimulus-Informed Generalized Canonical Correlation Analysis for Group Analysis of Neural Responses
Jan 31, 2024Various new brain-computer interface technologies or neuroscience applications require decoding stimulus-following neural responses to natural stimuli such as speech and video from, e.g., electroencephalography (EEG) signals. In this context, generalized canonical correlation analysis (GCCA) is often used as a group analysis technique, which allows the extraction of correlated signal components from the neural activity of multiple subjects attending to the same stimulus. GCCA can be used to improve the signal-to-noise ratio of the stimulus-following neural responses relative to all other irrelevant (non-)neural activity, or to quantify the correlated neural activity across multiple subjects in a group-wise coherence metric. However, the traditional GCCA technique is stimulus-unaware: no information about the stimulus is used to estimate the correlated components from the neural data of several subjects. Therefore, the GCCA technique might fail to extract relevant correlated signal components in practical situations where the amount of information is limited, for example, because of a limited amount of training data or group size. This motivates a new stimulus-informed GCCA (SI-GCCA) framework that allows taking the stimulus into account to extract the correlated components. We show that SI-GCCA outperforms GCCA in various practical settings, for both auditory and visual stimuli. Moreover, we showcase how SI-GCCA can be used to steer the estimation of the components towards the stimulus. As such, SI-GCCA substantially improves upon GCCA for various purposes, ranging from preprocessing to quantifying attention.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
On the performance of phonetic algorithms in microtext normalization
Feb 04, 2024User-generated content published on microblogging social networks constitutes a priceless source of information. However, microtexts usually deviate from the standard lexical and grammatical rules of the language, thus making its processing by traditional intelligent systems very difficult. As an answer, microtext normalization consists in transforming those non-standard microtexts into standard well-written texts as a preprocessing step, allowing traditional approaches to continue with their usual processing. Given the importance of phonetic phenomena in non-standard text formation, an essential element of the knowledge base of a normalizer would be the phonetic rules that encode these phenomena, which can be found in the so-called phonetic algorithms. In this work we experiment with a wide range of phonetic algorithms for the English language. The aim of this study is to determine the best phonetic algorithms within the context of candidate generation for microtext normalization. In other words, we intend to find those algorithms that taking as input non-standard terms to be normalized allow us to obtain as output the smallest possible sets of normalization candidates which still contain the corresponding target standard words. As it will be stated, the choice of the phonetic algorithm will depend heavily on the capabilities of the candidate selection mechanism which we usually find at the end of a microtext normalization pipeline. The faster it can make the right choices among big enough sets of candidates, the more we can sacrifice on the precision of the phonetic algorithms in favour of coverage in order to increase the overall performance of the normalization system. KEYWORDS: microtext normalization; phonetic algorithm; fuzzy matching; Twitter; texting
* Accepted for publication in journal Expert Systems with Applications
Acoustic Local Positioning With Encoded Emission Beacons
Feb 04, 2024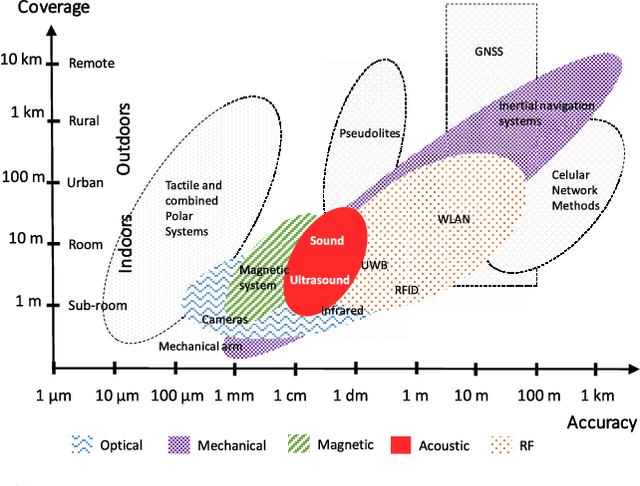
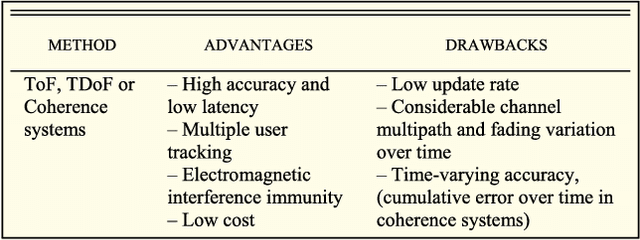
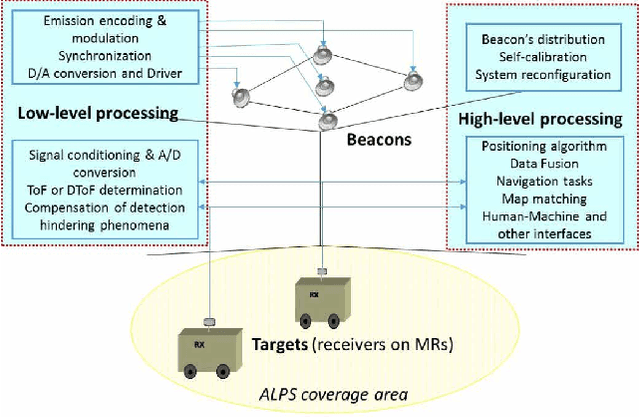
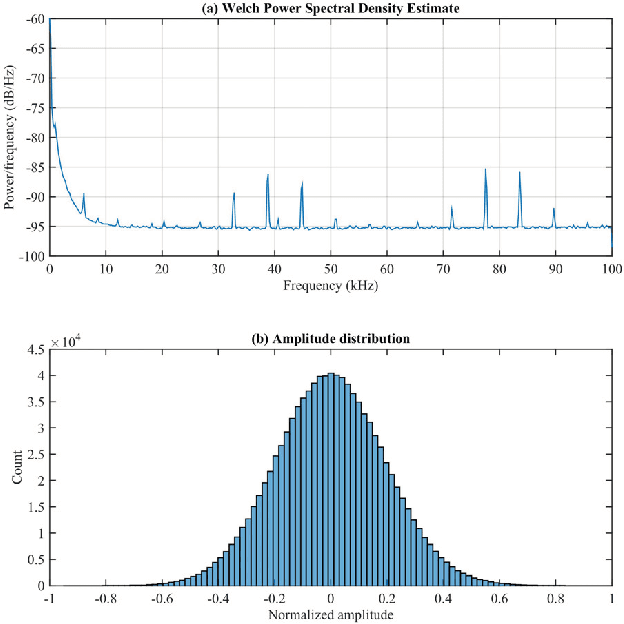
Acoustic local positioning systems (ALPSs) are an interesting alternative for indoor positioning due to certain advantages over other approaches, including their relatively high accuracy, low cost, and room-level signal propagation. Centimeter-level or fine-grained indoor positioning can be an asset for robot navigation, guiding a person to, for instance, a particular piece in a museum or to a specific product in a shop, targeted advertising, or augmented reality. In airborne system applications, acoustic positioning can be based on using opportunistic signals or sounds produced by the person or object to be located (e.g., noise from appliances or the speech from a speaker) or from encoded emission beacons (or anchors) specifically designed for this purpose. This work presents a review of the different challenges that designers of systems based on encoded emission beacons must address in order to achieve suitable performance. At low-level processing, the waveform design (coding and modulation) and the processing of the received signal are key factors to address such drawbacks as multipath propagation, multiple-access interference, nearfar effect, or Doppler shifting. With regards to high-level system design, the issues to be addressed are related to the distribution of beacons, ease of deployment, and calibration and positioning algorithms, including the possible fusion of information. Apart from theoretical discussions, this work also includes the description of an ALPS that was implemented, installed in a large area and tested for mobile robot navigation. In addition to practical interest for real applications, airborne ALPSs can also be used as an excellent platform to test complex algorithms, which can be subsequently adapted for other positioning systems, such as underwater acoustic systems or ultrawideband radiofrequency (UWB RF) systems.
Identifying Student Profiles Within Online Judge Systems Using Explainable Artificial Intelligence
Jan 29, 2024Online Judge (OJ) systems are typically considered within programming-related courses as they yield fast and objective assessments of the code developed by the students. Such an evaluation generally provides a single decision based on a rubric, most commonly whether the submission successfully accomplished the assignment. Nevertheless, since in an educational context such information may be deemed insufficient, it would be beneficial for both the student and the instructor to receive additional feedback about the overall development of the task. This work aims to tackle this limitation by considering the further exploitation of the information gathered by the OJ and automatically inferring feedback for both the student and the instructor. More precisely, we consider the use of learning-based schemes -- particularly, multi-instance learning (MIL) and classical machine learning formulations -- to model student behavior. Besides, explainable artificial intelligence (XAI) is contemplated to provide human-understandable feedback. The proposal has been evaluated considering a case of study comprising 2500 submissions from roughly 90 different students from a programming-related course in a computer science degree. The results obtained validate the proposal: The model is capable of significantly predicting the user outcome (either passing or failing the assignment) solely based on the behavioral pattern inferred by the submissions provided to the OJ. Moreover, the proposal is able to identify prone-to-fail student groups and profiles as well as other relevant information, which eventually serves as feedback to both the student and the instructor.
Enhanced fringe-to-phase framework using deep learning
Feb 01, 2024In Fringe Projection Profilometry (FPP), achieving robust and accurate 3D reconstruction with a limited number of fringe patterns remains a challenge in structured light 3D imaging. Conventional methods require a set of fringe images, but using only one or two patterns complicates phase recovery and unwrapping. In this study, we introduce SFNet, a symmetric fusion network that transforms two fringe images into an absolute phase. To enhance output reliability, Our framework predicts refined phases by incorporating information from fringe images of a different frequency than those used as input. This allows us to achieve high accuracy with just two images. Comparative experiments and ablation studies validate the effectiveness of our proposed method. The dataset and code are publicly accessible on our project page https://wonhoe-kim.github.io/SFNet.
YTCommentQA: Video Question Answerability in Instructional Videos
Jan 30, 2024Instructional videos provide detailed how-to guides for various tasks, with viewers often posing questions regarding the content. Addressing these questions is vital for comprehending the content, yet receiving immediate answers is difficult. While numerous computational models have been developed for Video Question Answering (Video QA) tasks, they are primarily trained on questions generated based on video content, aiming to produce answers from within the content. However, in real-world situations, users may pose questions that go beyond the video's informational boundaries, highlighting the necessity to determine if a video can provide the answer. Discerning whether a question can be answered by video content is challenging due to the multi-modal nature of videos, where visual and verbal information are intertwined. To bridge this gap, we present the YTCommentQA dataset, which contains naturally-generated questions from YouTube, categorized by their answerability and required modality to answer -- visual, script, or both. Experiments with answerability classification tasks demonstrate the complexity of YTCommentQA and emphasize the need to comprehend the combined role of visual and script information in video reasoning. The dataset is available at https://github.com/lgresearch/YTCommentQA.