 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepMI: Deep Multi-lead ECG Fusion for Identifying Myocardial Infarction and its Occurrence-time
Mar 31, 2021
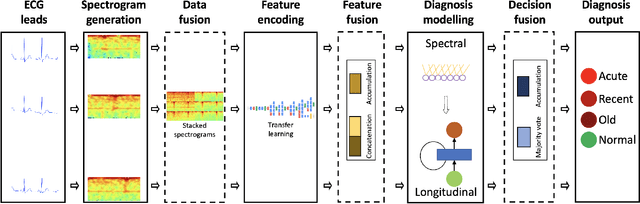
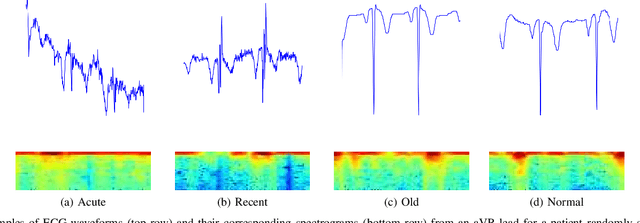
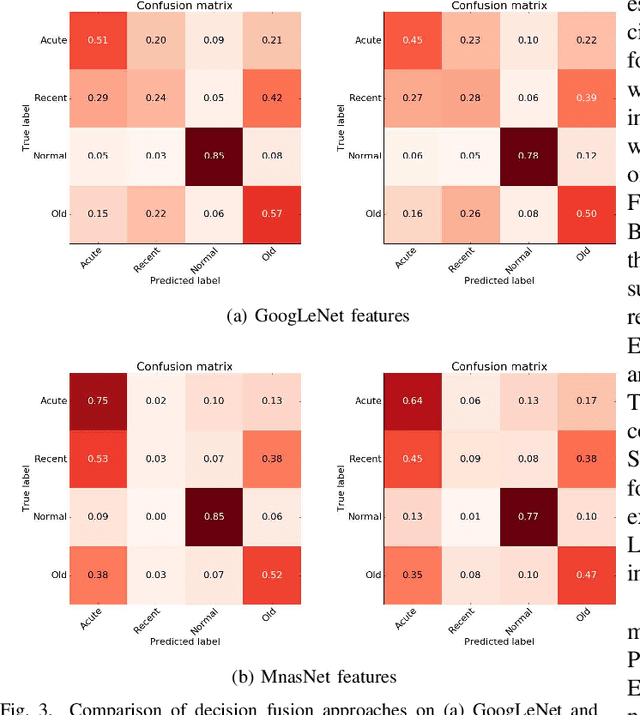

Myocardial Infarction (MI) has the highest mortality of all cardiovascular diseases (CVDs). Detection of MI and information regarding its occurrence-time in particular, would enable timely interventions that may improve patient outcomes, thereby reducing the global rise in CVD deaths. Electrocardiogram (ECG) recordings are currently used to screen MI patients. However, manual inspection of ECGs is time-consuming and prone to subjective bias. Machine learning methods have been adopted for automated ECG diagnosis, but most approaches require extraction of ECG beats or consider leads independently of one another. We propose an end-to-end deep learning approach, DeepMI, to classify MI from normal cases as well as identifying the time-occurrence of MI (defined as acute, recent and old), using a collection of fusion strategies on 12 ECG leads at data-, feature-, and decision-level. In order to minimise computational overhead, we employ transfer learning using existing computer vision networks. Moreover, we use recurrent neural networks to encode the longitudinal information inherent in ECGs. We validated DeepMI on a dataset collected from 17,381 patients, in which over 323,000 samples were extracted per ECG lead. We were able to classify normal cases as well as acute, recent and old onset cases of MI, with AUROCs of 96.7%, 82.9%, 68.6% and 73.8%, respectively. We have demonstrated a multi-lead fusion approach to detect the presence and occurrence-time of MI. Our end-to-end framework provides flexibility for different levels of multi-lead ECG fusion and performs feature extraction via transfer learning.
Analysis of Twitter Users' Lifestyle Choices using Joint Embedding Model
Apr 07, 2021
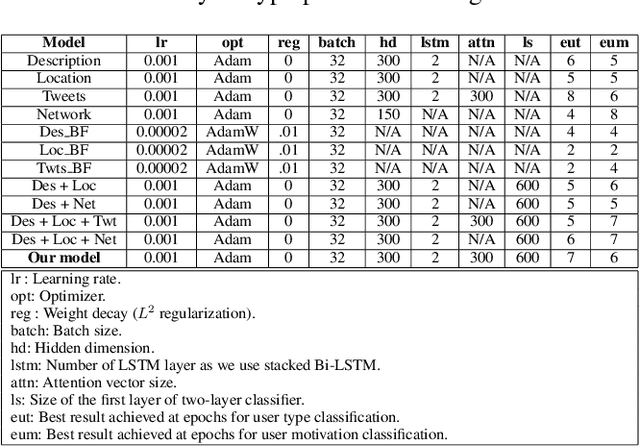
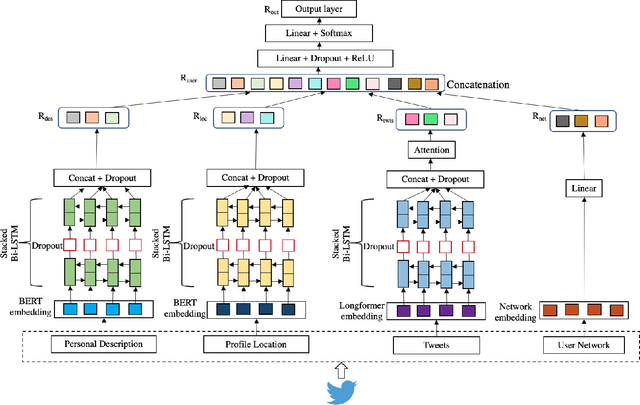
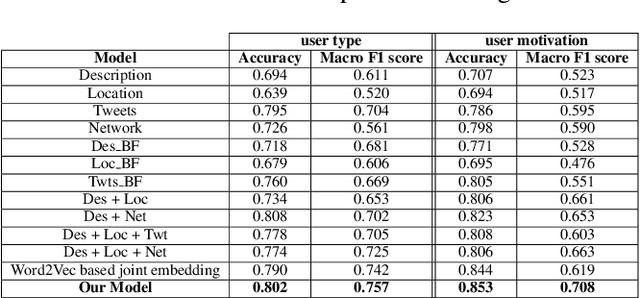
Multiview representation learning of data can help construct coherent and contextualized users' representations on social media. This paper suggests a joint embedding model, incorporating users' social and textual information to learn contextualized user representations used for understanding their lifestyle choices. We apply our model to tweets related to two lifestyle activities, `Yoga' and `Keto diet' and use it to analyze users' activity type and motivation. We explain the data collection and annotation process in detail and provide an in-depth analysis of users from different classes based on their Twitter content. Our experiments show that our model results in performance improvements in both domains.
Interpretable machine learning for high-dimensional trajectories of aging health
May 07, 2021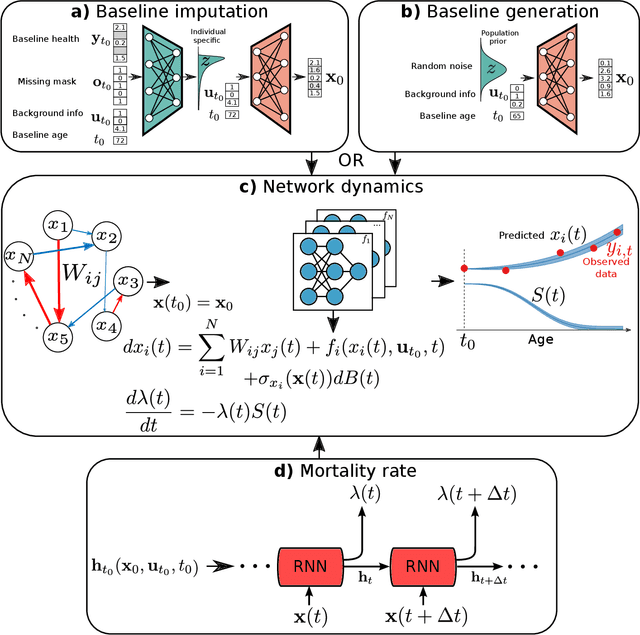
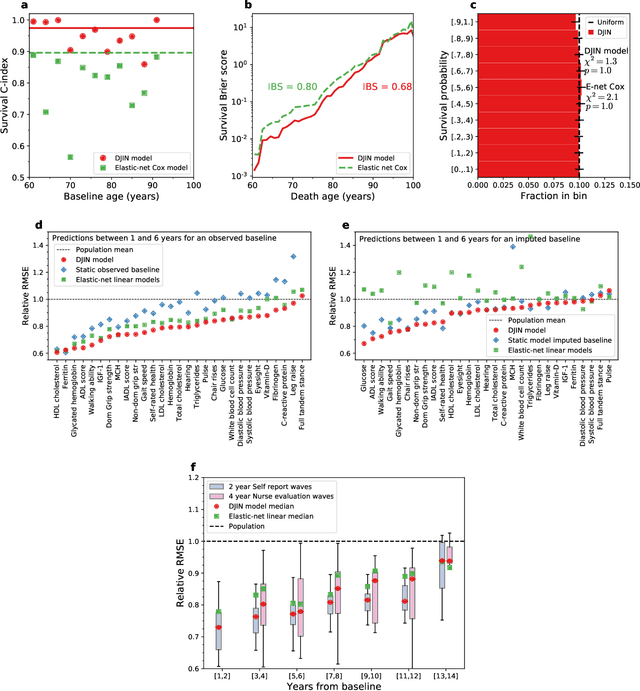
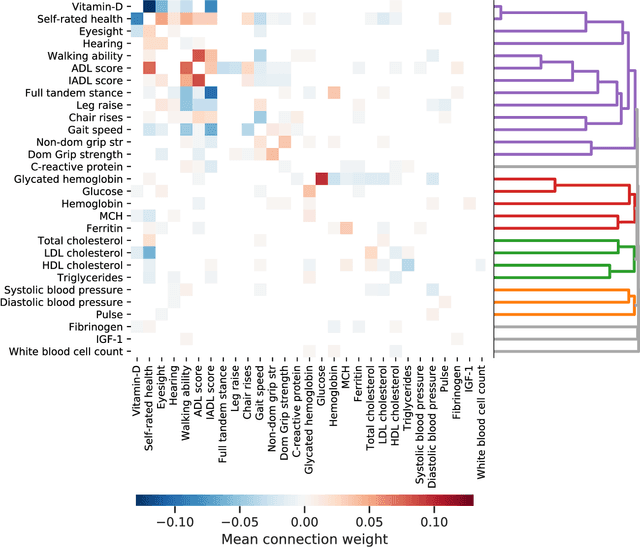
We have built a computational model for individual aging trajectories of health and survival, which contains physical, functional, and biological variables, and is conditioned on demographic, lifestyle, and medical background information. We combine techniques of modern machine learning with an interpretable interaction network, where health variables are coupled by explicit pair-wise interactions within a stochastic dynamical system. Our model is scalable to large longitudinal data sets, is predictive of individual high-dimensional health trajectories and survival from baseline health states, and infers an interpretable network of directed interactions between the health variables. The network identifies plausible physiological connections between health variables and clusters of strongly connected heath variables. We use English Longitudinal Study of Aging (ELSA) data to train our model and show that it performs better than dedicated linear models for health outcomes and survival. Our model can also be used to generate synthetic individuals that age realistically, to impute missing data, and to simulate future aging outcomes given arbitrary initial health states.
STAGE: Tool for Automated Extraction of Semantic Time Cues to Enrich Neural Temporal Ordering Models
May 15, 2021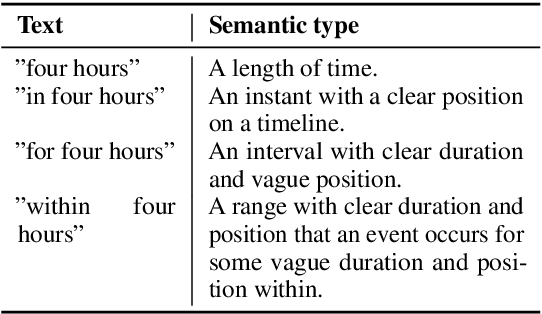
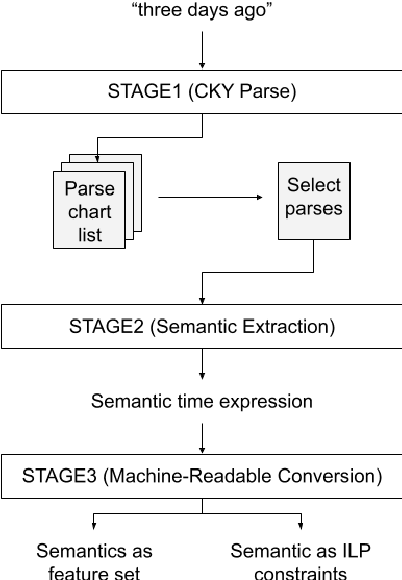
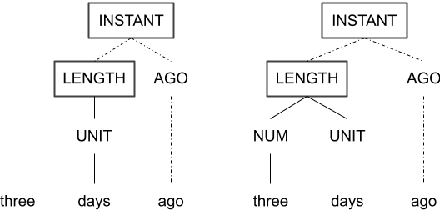

Despite achieving state-of-the-art accuracy on temporal ordering of events, neural models showcase significant gaps in performance. Our work seeks to fill one of these gaps by leveraging an under-explored dimension of textual semantics: rich semantic information provided by explicit textual time cues. We develop STAGE, a system that consists of a novel temporal framework and a parser that can automatically extract time cues and convert them into representations suitable for integration with neural models. We demonstrate the utility of extracted cues by integrating them with an event ordering model using a joint BiLSTM and ILP constraint architecture. We outline the functionality of the 3-part STAGE processing approach, and show two methods of integrating its representations with the BiLSTM-ILP model: (i) incorporating semantic cues as additional features, and (ii) generating new constraints from semantic cues to be enforced in the ILP. We demonstrate promising results on two event ordering datasets, and highlight important issues in semantic cue representation and integration for future research.
HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
Jun 11, 2021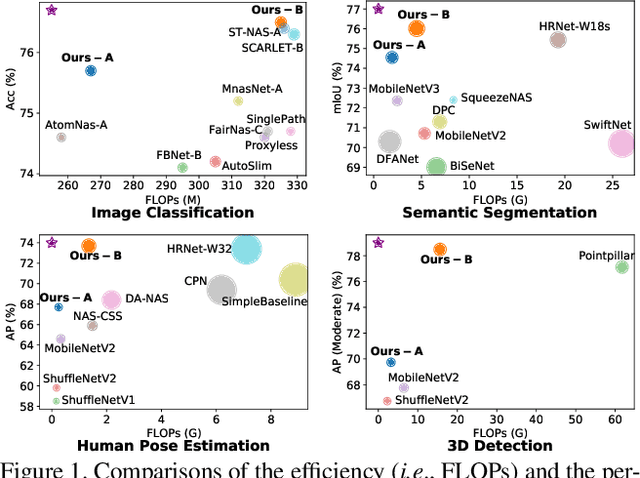
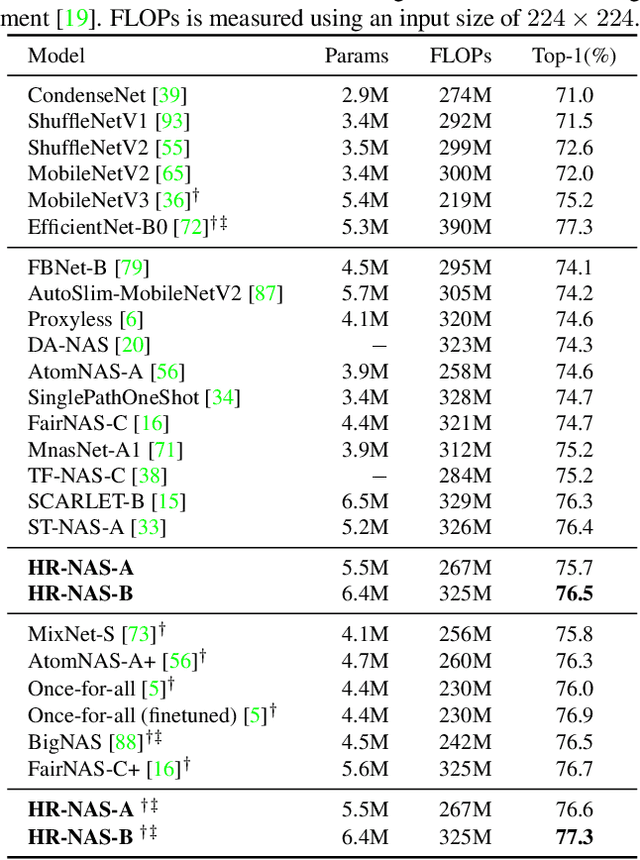
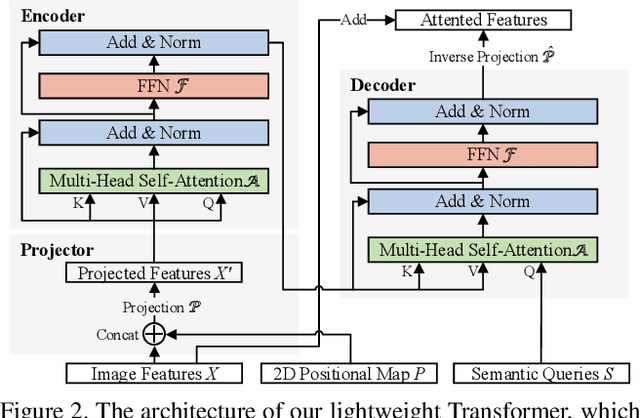
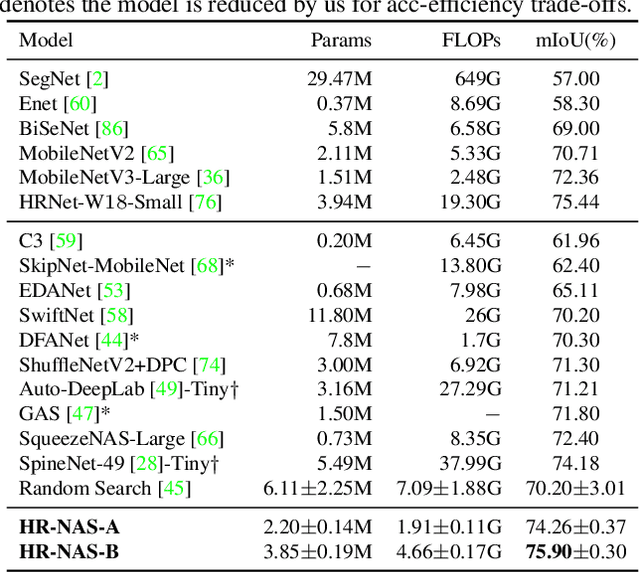
High-resolution representations (HR) are essential for dense prediction tasks such as segmentation, detection, and pose estimation. Learning HR representations is typically ignored in previous Neural Architecture Search (NAS) methods that focus on image classification. This work proposes a novel NAS method, called HR-NAS, which is able to find efficient and accurate networks for different tasks, by effectively encoding multiscale contextual information while maintaining high-resolution representations. In HR-NAS, we renovate the NAS search space as well as its searching strategy. To better encode multiscale image contexts in the search space of HR-NAS, we first carefully design a lightweight transformer, whose computational complexity can be dynamically changed with respect to different objective functions and computation budgets. To maintain high-resolution representations of the learned networks, HR-NAS adopts a multi-branch architecture that provides convolutional encoding of multiple feature resolutions, inspired by HRNet. Last, we proposed an efficient fine-grained search strategy to train HR-NAS, which effectively explores the search space, and finds optimal architectures given various tasks and computation resources. HR-NAS is capable of achieving state-of-the-art trade-offs between performance and FLOPs for three dense prediction tasks and an image classification task, given only small computational budgets. For example, HR-NAS surpasses SqueezeNAS that is specially designed for semantic segmentation while improving efficiency by 45.9%. Code is available at https://github.com/dingmyu/HR-NAS
Gaussian Dynamic Convolution for Efficient Single-Image Segmentation
May 23, 2021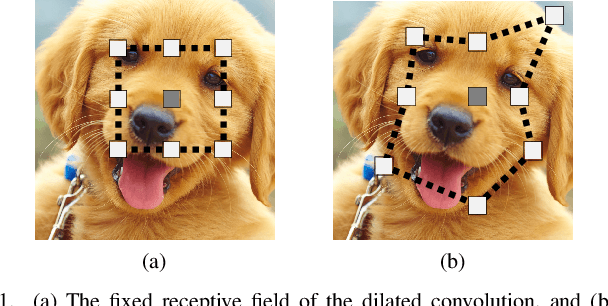
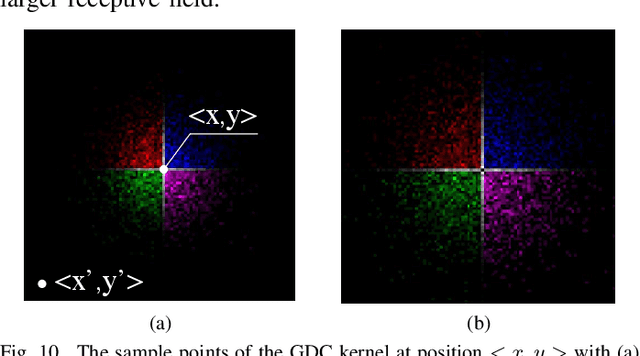

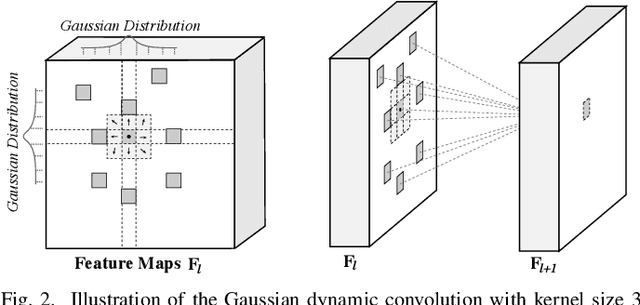
Interactive single-image segmentation is ubiquitous in the scientific and commercial imaging software. In this work, we focus on the single-image segmentation problem only with some seeds such as scribbles. Inspired by the dynamic receptive field in the human being's visual system, we propose the Gaussian dynamic convolution (GDC) to fast and efficiently aggregate the contextual information for neural networks. The core idea is randomly selecting the spatial sampling area according to the Gaussian distribution offsets. Our GDC can be easily used as a module to build lightweight or complex segmentation networks. We adopt the proposed GDC to address the typical single-image segmentation tasks. Furthermore, we also build a Gaussian dynamic pyramid Pooling to show its potential and generality in common semantic segmentation. Experiments demonstrate that the GDC outperforms other existing convolutions on three benchmark segmentation datasets including Pascal-Context, Pascal-VOC 2012, and Cityscapes. Additional experiments are also conducted to illustrate that the GDC can produce richer and more vivid features compared with other convolutions. In general, our GDC is conducive to the convolutional neural networks to form an overall impression of the image.
3D Fully Convolutional Neural Networks with Intersection Over Union Loss for Crop Mapping from Multi-Temporal Satellite Images
Feb 15, 2021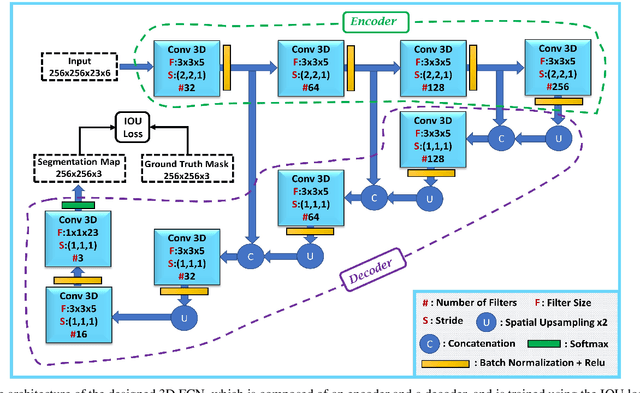
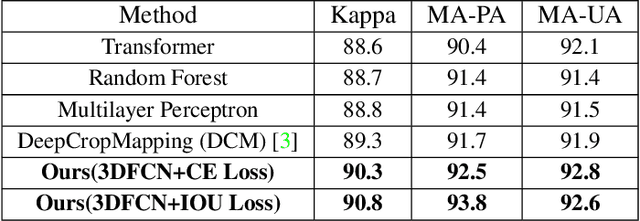
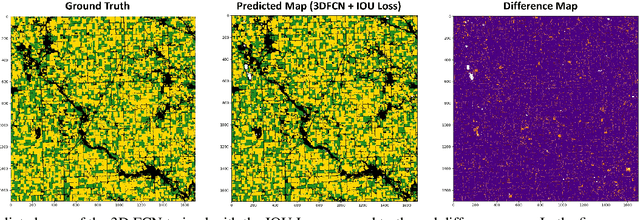
Information on cultivated crops is relevant for a large number of food security studies. Different scientific efforts are dedicated to generate this information from remote sensing images by means of machine learning methods. Unfortunately, these methods do not account for the spatial-temporal relationships inherent in remote sensing images. In our paper, we explore the capability of a 3D Fully Convolutional Neural Network (FCN) to map crop types from multi-temporal images. In addition, we propose the Intersection Over Union (IOU) loss function for increasing the overlap between the predicted classes and ground truth data. The proposed method was applied to identify soybean and corn from a study area situated in the US corn belt using multi-temporal Landsat images. The study shows that our method outperforms related methods, obtaining a Kappa coefficient of 90.8%. We conclude that using the IOU Loss function provides a superior choice to learn individual crop types.
Killing Two Birds with One Stone: Stealing Model and Inferring Attribute from BERT-based APIs
May 23, 2021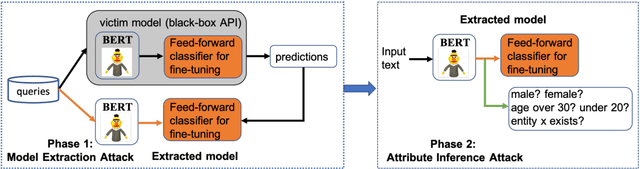
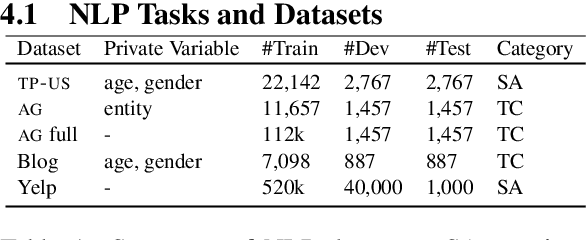
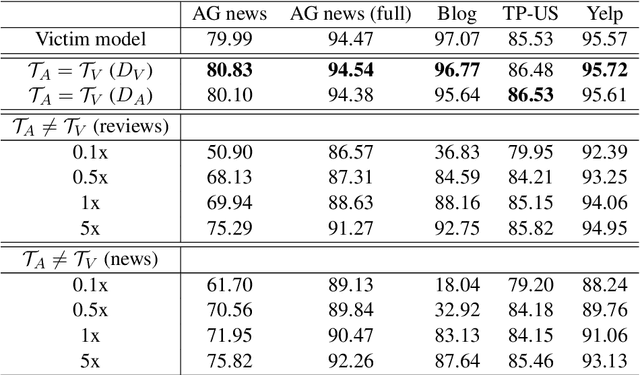
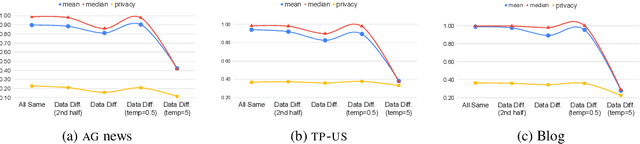
The advances in pre-trained models (e.g., BERT, XLNET and etc) have largely revolutionized the predictive performance of various modern natural language processing tasks. This allows corporations to provide machine learning as a service (MLaaS) by encapsulating fine-tuned BERT-based models as commercial APIs. However, previous works have discovered a series of vulnerabilities in BERT- based APIs. For example, BERT-based APIs are vulnerable to both model extraction attack and adversarial example transferrability attack. However, due to the high capacity of BERT-based APIs, the fine-tuned model is easy to be overlearned, what kind of information can be leaked from the extracted model remains unknown and is lacking. To bridge this gap, in this work, we first present an effective model extraction attack, where the adversary can practically steal a BERT-based API (the target/victim model) by only querying a limited number of queries. We further develop an effective attribute inference attack to expose the sensitive attribute of the training data used by the BERT-based APIs. Our extensive experiments on benchmark datasets under various realistic settings demonstrate the potential vulnerabilities of BERT-based APIs.
A hybrid classification-regression approach for 3D hand pose estimation using graph convolutional networks
May 23, 2021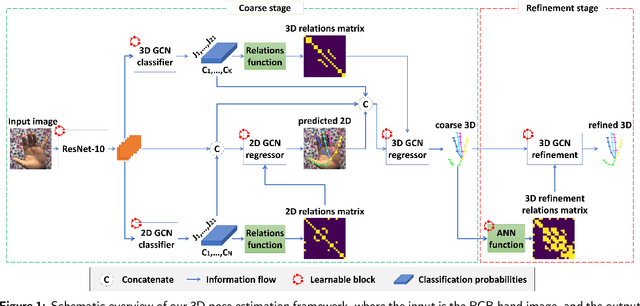
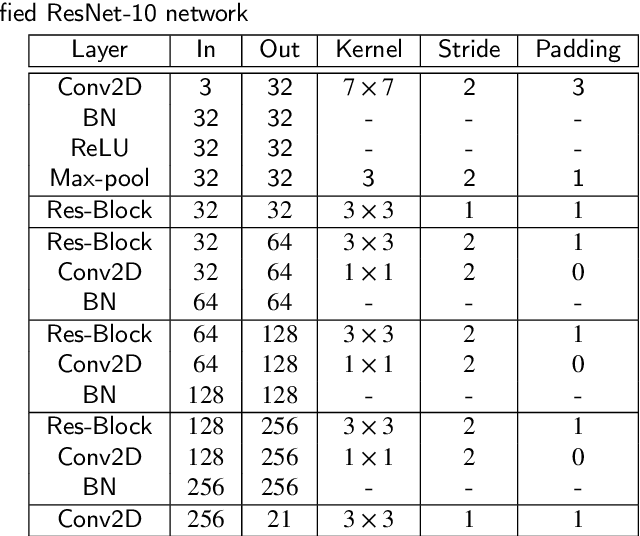
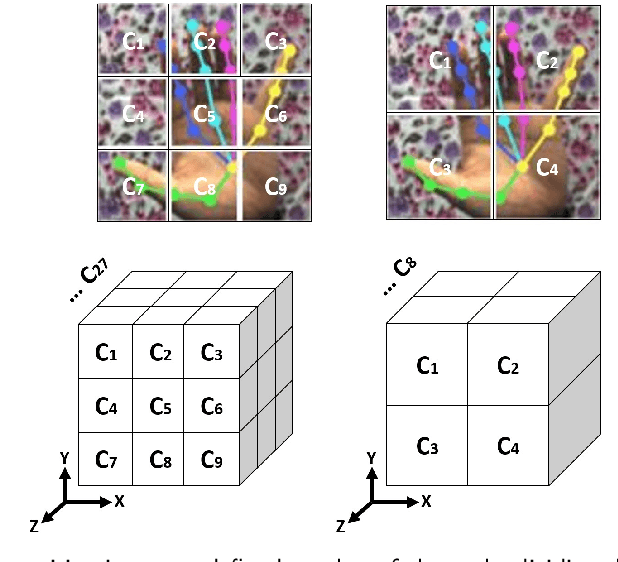
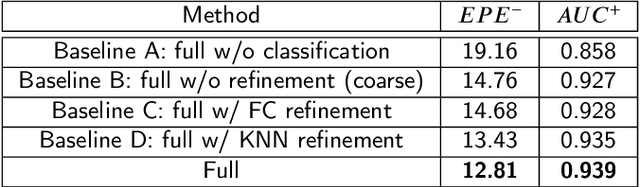
Hand pose estimation is a crucial part of a wide range of augmented reality and human-computer interaction applications. Predicting the 3D hand pose from a single RGB image is challenging due to occlusion and depth ambiguities. GCN-based (Graph Convolutional Networks) methods exploit the structural relationship similarity between graphs and hand joints to model kinematic dependencies between joints. These techniques use predefined or globally learned joint relationships, which may fail to capture pose-dependent constraints. To address this problem, we propose a two-stage GCN-based framework that learns per-pose relationship constraints. Specifically, the first phase quantizes the 2D/3D space to classify the joints into 2D/3D blocks based on their locality. This spatial dependency information guides this phase to estimate reliable 2D and 3D poses. The second stage further improves the 3D estimation through a GCN-based module that uses an adaptative nearest neighbor algorithm to determine joint relationships. Extensive experiments show that our multi-stage GCN approach yields an efficient model that produces accurate 2D/3D hand poses and outperforms the state-of-the-art on two public datasets.
Sampling Based Scene-Space Video Processing
Feb 05, 2021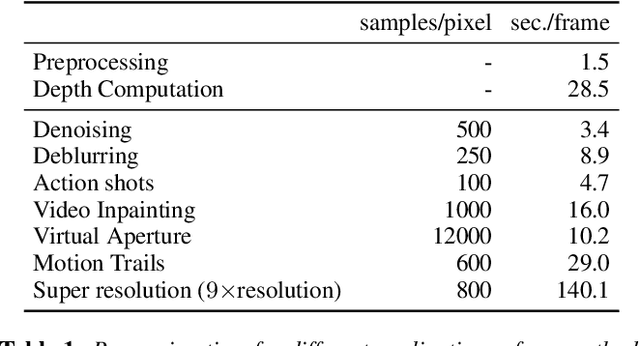
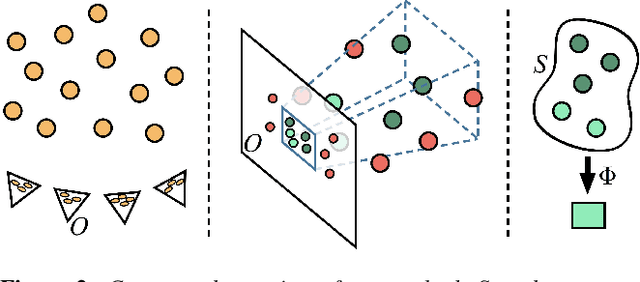

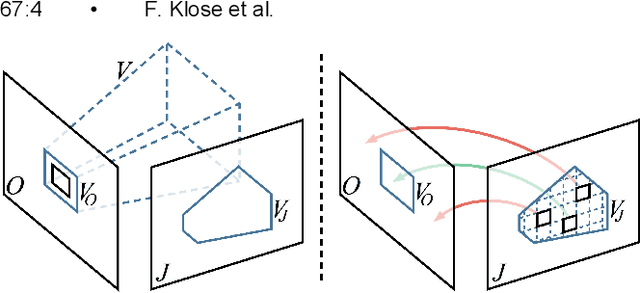
Many compelling video processing effects can be achieved if per-pixel depth information and 3D camera calibrations are known. However, the success of such methods is highly dependent on the accuracy of this "scene-space" information. We present a novel, sampling-based framework for processing video that enables high-quality scene-space video effects in the presence of inevitable errors in depth and camera pose estimation. Instead of trying to improve the explicit 3D scene representation, the key idea of our method is to exploit the high redundancy of approximate scene information that arises due to most scene points being visible multiple times across many frames of video. Based on this observation, we propose a novel pixel gathering and filtering approach. The gathering step is general and collects pixel samples in scene-space, while the filtering step is application-specific and computes a desired output video from the gathered sample sets. Our approach is easily parallelizable and has been implemented on GPU, allowing us to take full advantage of large volumes of video data and facilitating practical runtimes on HD video using a standard desktop computer. Our generic scene-space formulation is able to comprehensively describe a multitude of video processing applications such as denoising, deblurring, super resolution, object removal, computational shutter functions, and other scene-space camera effects. We present results for various casually captured, hand-held, moving, compressed, monocular videos depicting challenging scenes recorded in uncontrolled environments.