 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lex2vec: making Explainable Word Embedding via Distant Supervision
Mar 03, 2021
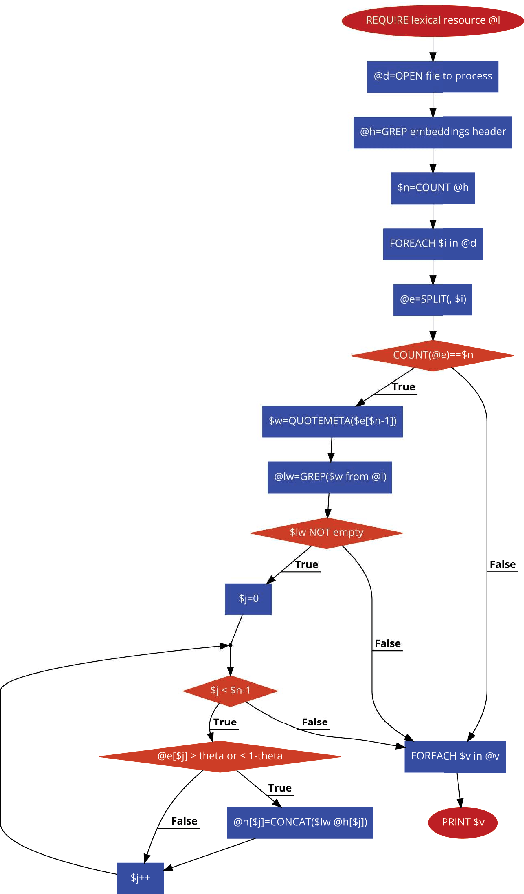
In this technical report we propose an algorithm, called Lex2vec, that exploits lexical resources to inject information into word embeddings and name the embedding dimensions by means of distant supervision. We evaluate the optimal parameters to extract a number of informative labels that is readable and has a good coverage for the embedding dimensions.
Volta at SemEval-2021 Task 9: Statement Verification and Evidence Finding with Tables using TAPAS and Transfer Learning
Jun 01, 2021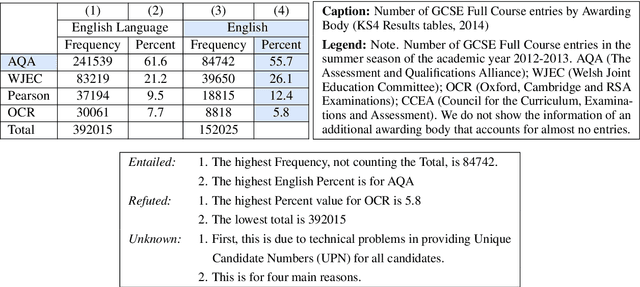

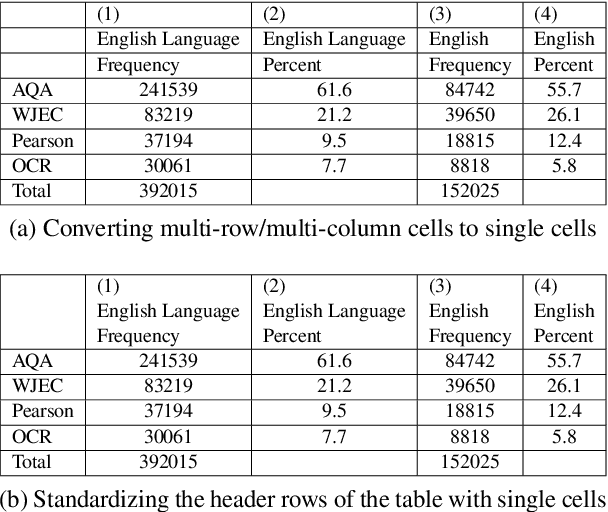

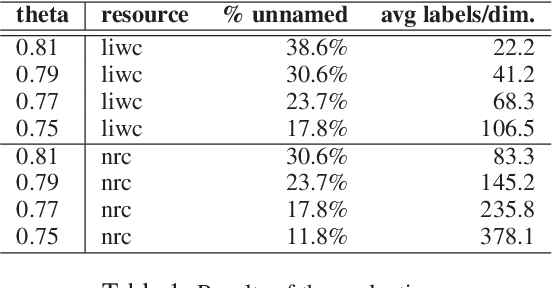
Tables are widely used in various kinds of documents to present information concisely. Understanding tables is a challenging problem that requires an understanding of language and table structure, along with numerical and logical reasoning. In this paper, we present our systems to solve Task 9 of SemEval-2021: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACTS). The task consists of two subtasks: (A) Given a table and a statement, predicting whether the table supports the statement and (B) Predicting which cells in the table provide evidence for/against the statement. We fine-tune TAPAS (a model which extends BERT's architecture to capture tabular structure) for both the subtasks as it has shown state-of-the-art performance in various table understanding tasks. In subtask A, we evaluate how transfer learning and standardizing tables to have a single header row improves TAPAS' performance. In subtask B, we evaluate how different fine-tuning strategies can improve TAPAS' performance. Our systems achieve an F1 score of 67.34 in subtask A three-way classification, 72.89 in subtask A two-way classification, and 62.95 in subtask B.
Is Image Size Important? A Robustness Comparison of Deep Learning Methods for Multi-scale Cell Image Classification Tasks: from Convolutional Neural Networks to Visual Transformers
May 16, 2021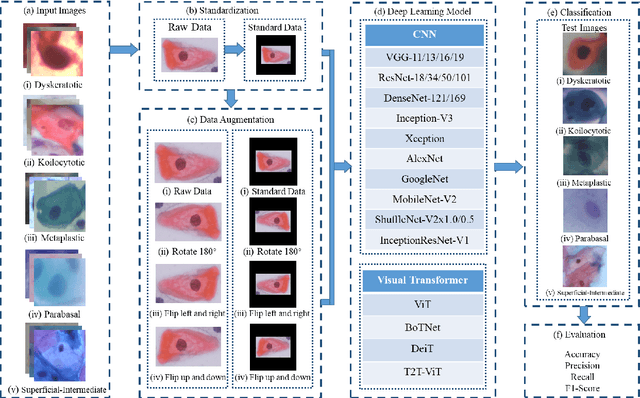

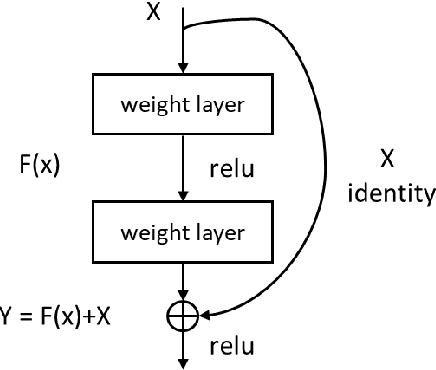
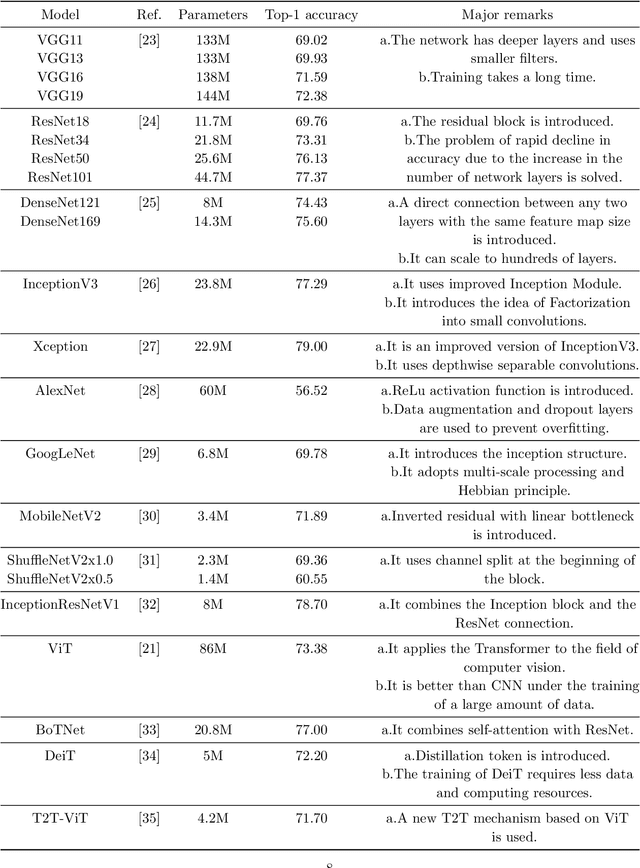
Cervical cancer is a very common and fatal cancer in women, but it can be prevented through early examination and treatment. Cytopathology images are often used to screen for cancer. Then, because of the possibility of artificial errors due to the large number of this method, the computer-aided diagnosis system based on deep learning is developed. The image input required by the deep learning method is usually consistent, but the size of the clinical medical image is inconsistent. The internal information is lost after resizing the image directly, so it is unreasonable. A lot of research is to directly resize the image, and the results are still robust. In order to find a reasonable explanation, 22 deep learning models are used to process images of different scales, and experiments are conducted on the SIPaKMeD dataset. The conclusion is that the deep learning method is very robust to the size changes of images. This conclusion is also validated on the Herlev dataset.
Neural Ranking Models for Document Retrieval
Feb 23, 2021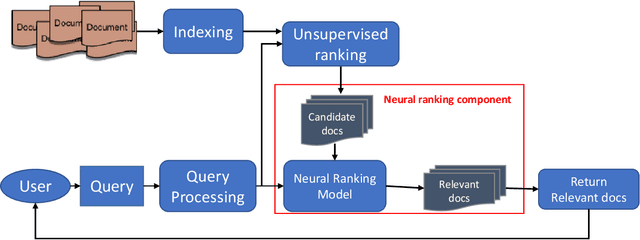
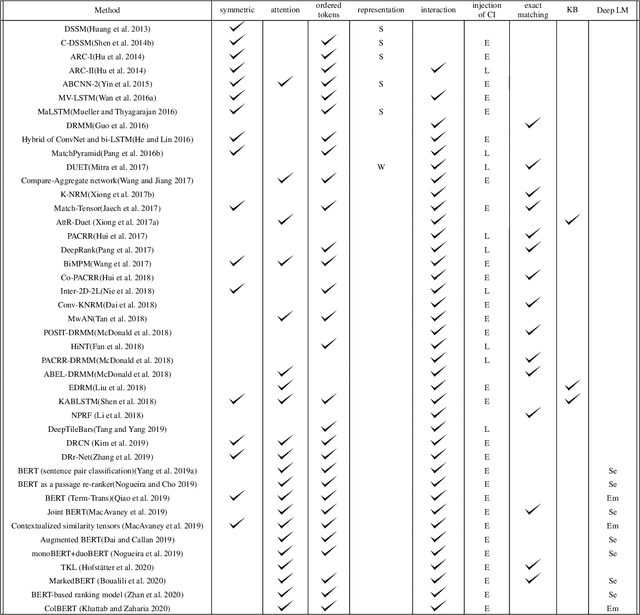
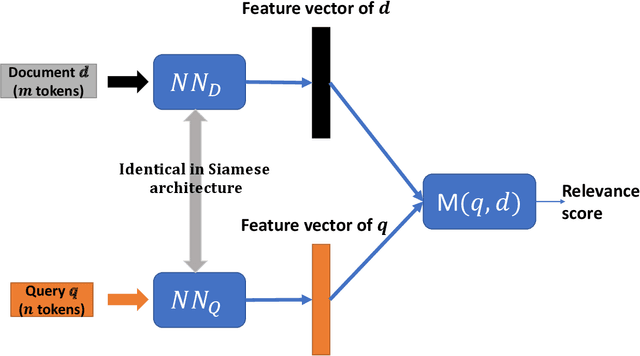
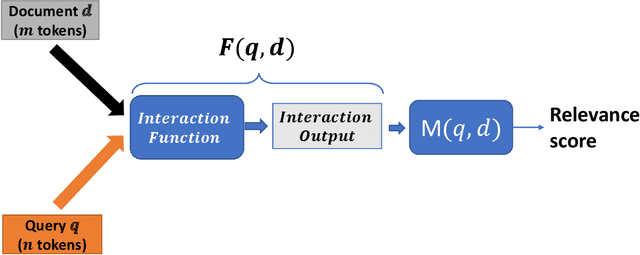
Ranking models are the main components of information retrieval systems. Several approaches to ranking are based on traditional machine learning algorithms using a set of hand-crafted features. Recently, researchers have leveraged deep learning models in information retrieval. These models are trained end-to-end to extract features from the raw data for ranking tasks, so that they overcome the limitations of hand-crafted features. A variety of deep learning models have been proposed, and each model presents a set of neural network components to extract features that are used for ranking. In this paper, we compare the proposed models in the literature along different dimensions in order to understand the major contributions and limitations of each model. In our discussion of the literature, we analyze the promising neural components, and propose future research directions. We also show the analogy between document retrieval and other retrieval tasks where the items to be ranked are structured documents, answers, images and videos.
Graph-signal Reconstruction and Blind Deconvolution for Structured Inputs
Jun 01, 2021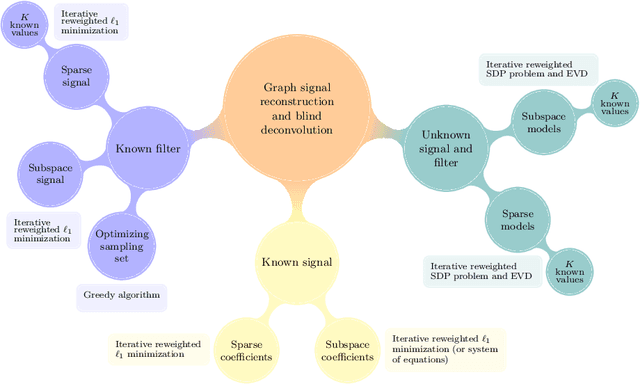
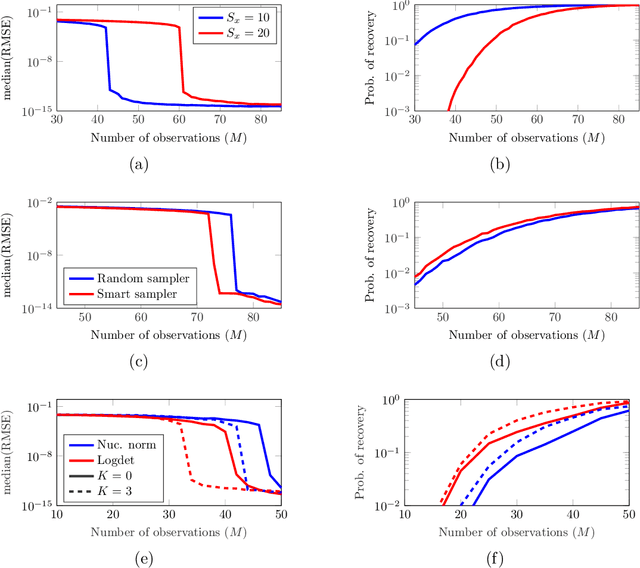
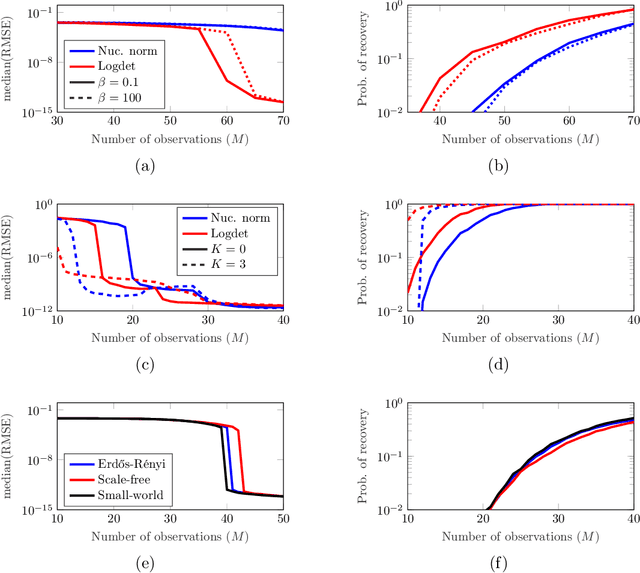
Key to successfully deal with complex contemporary datasets is the development of tractable models that account for the irregular structure of the information at hand. This paper provides a comprehensive and unifying view of several sampling, reconstruction, and recovery problems for signals defined on irregular domains that can be accurately represented by a graph. The workhorse assumption is that the (partially) observed signals can be modeled as the output of a graph filter to a structured (parsimonious) input graph signal. When either the input or the filter coefficients are known, this is tantamount to assuming that the signals of interest live on a subspace defined by the supporting graph. When neither is known, the model becomes bilinear. Upon imposing different priors and additional structure on either the input or the filter coefficients, a broad range of relevant problem formulations arise. The goal is then to leverage those priors, the shift operator of the supporting graph, and the samples of the signal of interest to recover: the signal at the non-sampled nodes (graph-signal interpolation), the input (deconvolution), the filter coefficients (system identification), or any combination thereof (blind deconvolution).
Seeking the Shape of Sound: An Adaptive Framework for Learning Voice-Face Association
Mar 12, 2021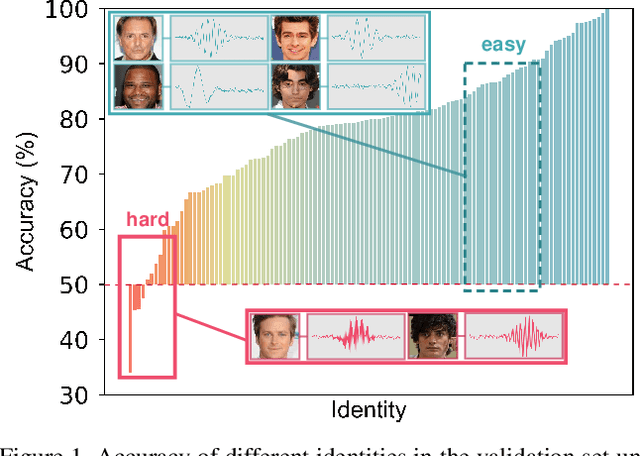
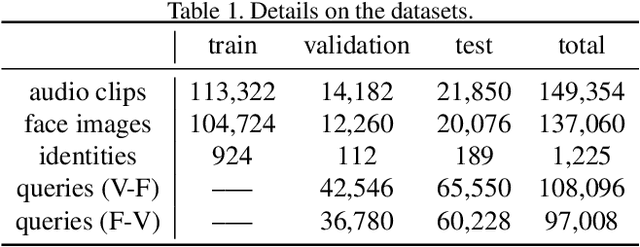
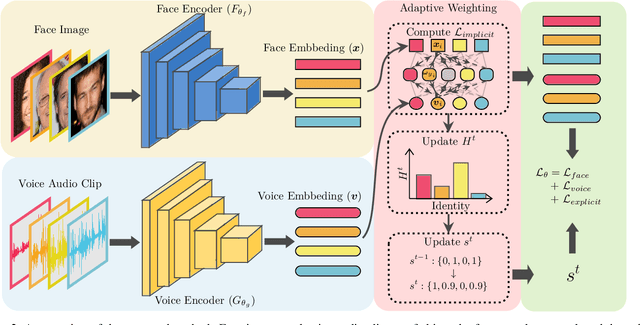
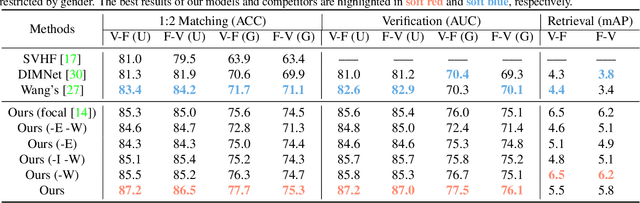
Nowadays, we have witnessed the early progress on learning the association between voice and face automatically, which brings a new wave of studies to the computer vision community. However, most of the prior arts along this line (a) merely adopt local information to perform modality alignment and (b) ignore the diversity of learning difficulty across different subjects. In this paper, we propose a novel framework to jointly address the above-mentioned issues. Targeting at (a), we propose a two-level modality alignment loss where both global and local information are considered. Compared with the existing methods, we introduce a global loss into the modality alignment process. The global component of the loss is driven by the identity classification. Theoretically, we show that minimizing the loss could maximize the distance between embeddings across different identities while minimizing the distance between embeddings belonging to the same identity, in a global sense (instead of a mini-batch). Targeting at (b), we propose a dynamic reweighting scheme to better explore the hard but valuable identities while filtering out the unlearnable identities. Experiments show that the proposed method outperforms the previous methods in multiple settings, including voice-face matching, verification and retrieval.
The Local Approach to Causal Inference under Network Interference
May 11, 2021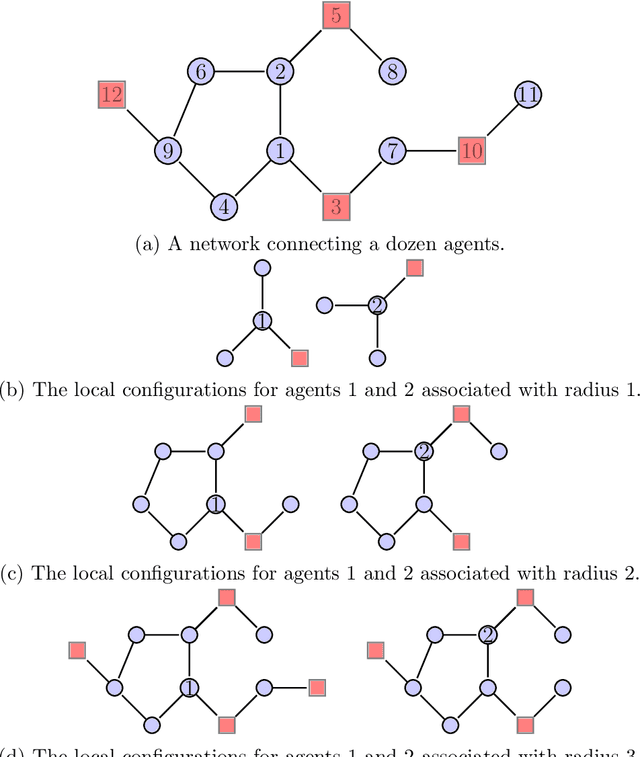
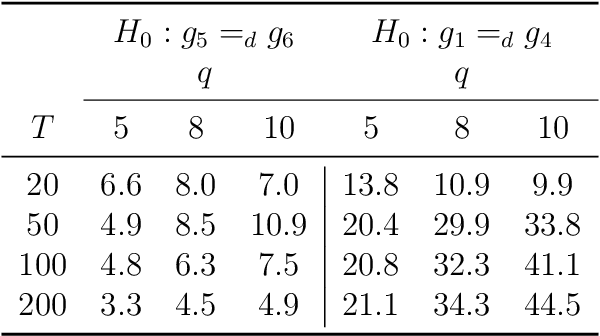
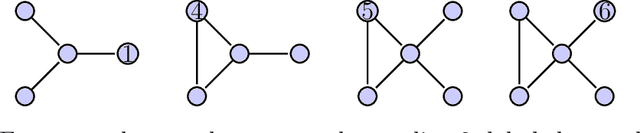
We propose a new unified framework for causal inference when outcomes depend on how agents are linked in a social or economic network. Such network interference describes a large literature on treatment spillovers, social interactions, social learning, information diffusion, social capital formation, and more. Our approach works by first characterizing how an agent is linked in the network using the configuration of other agents and connections nearby as measured by path distance. The impact of a policy or treatment assignment is then learned by pooling outcome data across similarly configured agents. In the paper, we propose a new nonparametric modeling approach and consider two applications to causal inference. The first application is to testing policy irrelevance/no treatment effects. The second application is to estimating policy effects/treatment response. We conclude by evaluating the finite-sample properties of our estimation and inference procedures via simulation.
VSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021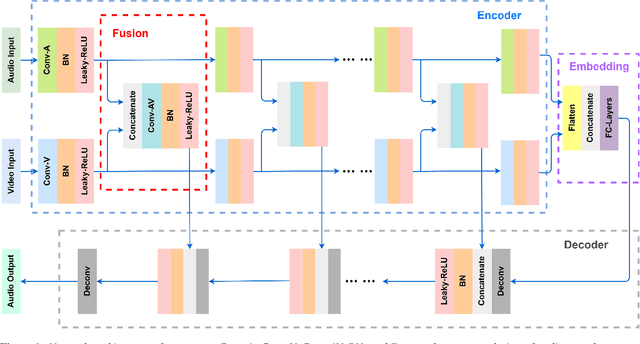

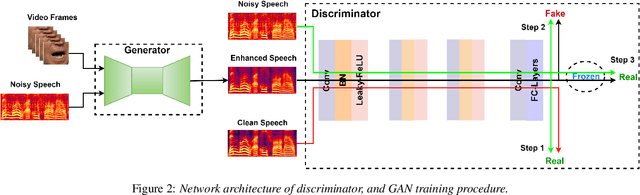
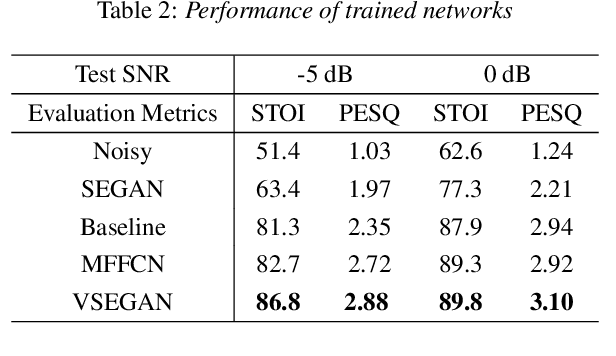
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
Graph-of-Tweets: A Graph Merging Approach to Sub-event Identification
Jan 08, 2021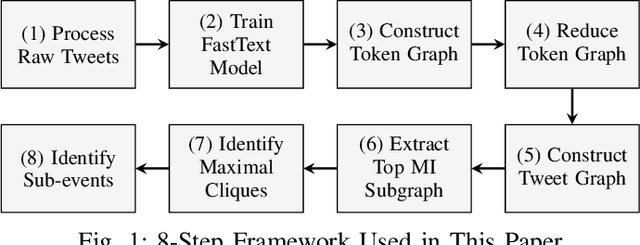
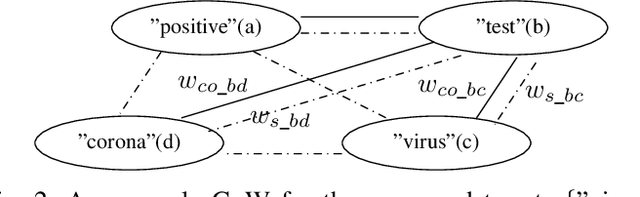


Graph structures are powerful tools for modeling the relationships between textual elements. Graph-of-Words (GoW) has been adopted in many Natural Language tasks to encode the association between terms. However, GoW provides few document-level relationships in cases when the connections between documents are also essential. For identifying sub-events on social media like Twitter, features from both word- and document-level can be useful as they supply different information of the event. We propose a hybrid Graph-of-Tweets (GoT) model which combines the word- and document-level structures for modeling Tweets. To compress large amount of raw data, we propose a graph merging method which utilizes FastText word embeddings to reduce the GoW. Furthermore, we present a novel method to construct GoT with the reduced GoW and a Mutual Information (MI) measure. Finally, we identify maximal cliques to extract popular sub-events. Our model showed promising results on condensing lexical-level information and capturing keywords of sub-events.
AR Mapping: Accurate and Efficient Mapping for Augmented Reality
Mar 27, 2021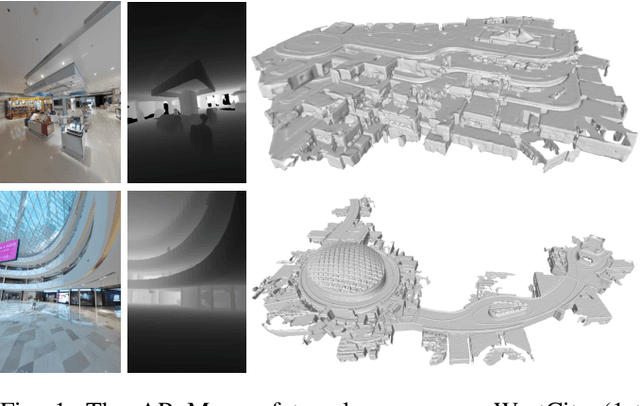

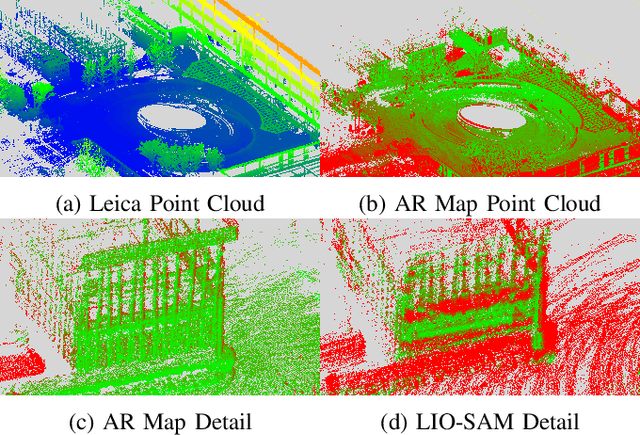

Augmented reality (AR) has gained increasingly attention from both research and industry communities. By overlaying digital information and content onto the physical world, AR enables users to experience the world in a more informative and efficient manner. As a major building block for AR systems, localization aims at determining the device's pose from a pre-built "map" consisting of visual and depth information in a known environment. While the localization problem has been widely studied in the literature, the "map" for AR systems is rarely discussed. In this paper, we introduce the AR Map for a specific scene to be composed of 1) color images with 6-DOF poses; 2) dense depth maps for each image and 3) a complete point cloud map. We then propose an efficient end-to-end solution to generating and evaluating AR Maps. Firstly, for efficient data capture, a backpack scanning device is presented with a unified calibration pipeline. Secondly, we propose an AR mapping pipeline which takes the input from the scanning device and produces accurate AR Maps. Finally, we present an approach to evaluating the accuracy of AR Maps with the help of the highly accurate reconstruction result from a high-end laser scanner. To the best of our knowledge, it is the first time to present an end-to-end solution to efficient and accurate mapping for AR applications.