 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DTGAN: Differential Private Training for Tabular GANs
Jul 06, 2021
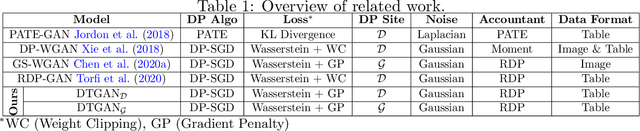
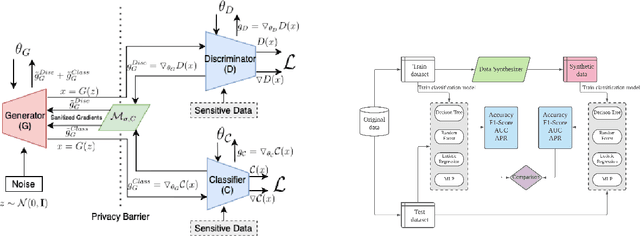

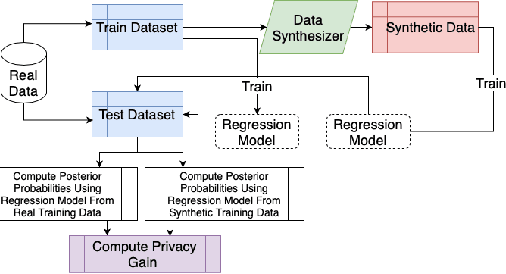
Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
Latent Event-Predictive Encodings through Counterfactual Regularization
May 12, 2021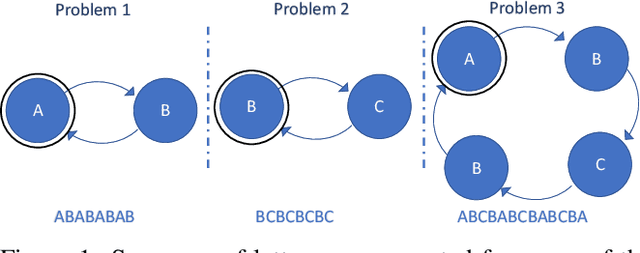

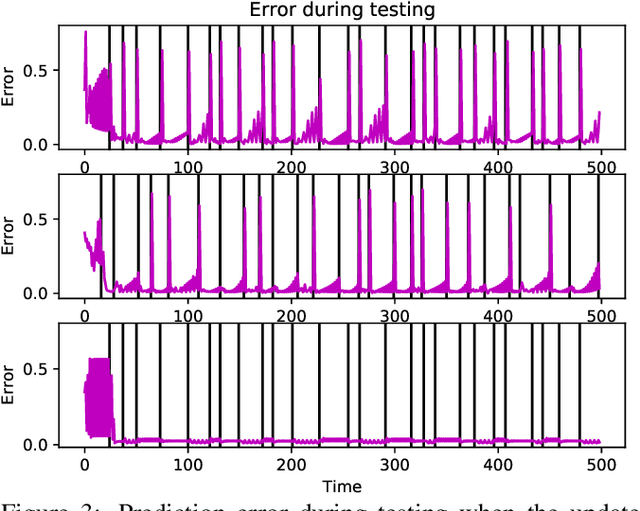
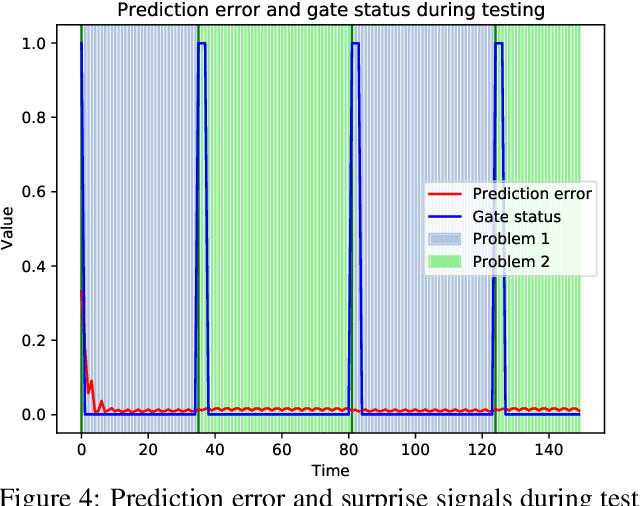
A critical challenge for any intelligent system is to infer structure from continuous data streams. Theories of event-predictive cognition suggest that the brain segments sensorimotor information into compact event encodings, which are used to anticipate and interpret environmental dynamics. Here, we introduce a SUrprise-GAted Recurrent neural network (SUGAR) using a novel form of counterfactual regularization. We test the model on a hierarchical sequence prediction task, where sequences are generated by alternating hidden graph structures. Our model learns to both compress the temporal dynamics of the task into latent event-predictive encodings and anticipate event transitions at the right moments, given noisy hidden signals about them. The addition of the counterfactual regularization term ensures fluid transitions from one latent code to the next, whereby the resulting latent codes exhibit compositional properties. The implemented mechanisms offer a host of useful applications in other domains, including hierarchical reasoning, planning, and decision making.
AMSS-Net: Audio Manipulation on User-Specified Sources with Textual Queries
Apr 28, 2021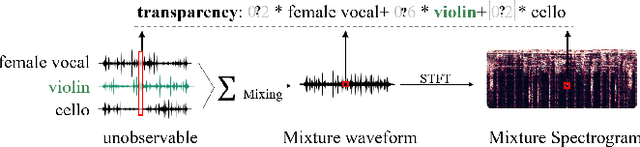

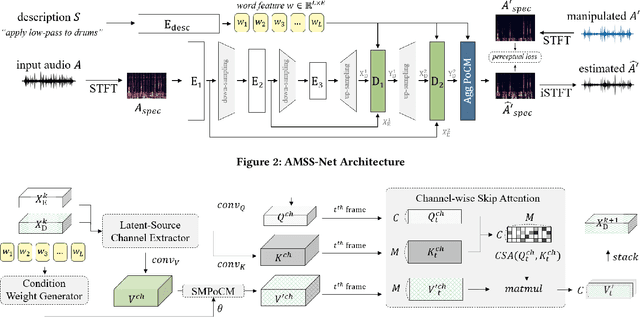
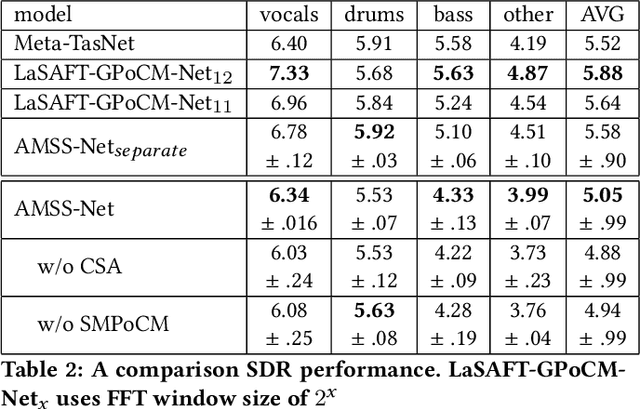
This paper proposes a neural network that performs audio transformations to user-specified sources (e.g., vocals) of a given audio track according to a given description while preserving other sources not mentioned in the description. Audio Manipulation on a Specific Source (AMSS) is challenging because a sound object (i.e., a waveform sample or frequency bin) is `transparent'; it usually carries information from multiple sources, in contrast to a pixel in an image. To address this challenging problem, we propose AMSS-Net, which extracts latent sources and selectively manipulates them while preserving irrelevant sources. We also propose an evaluation benchmark for several AMSS tasks, and we show that AMSS-Net outperforms baselines on several AMSS tasks via objective metrics and empirical verification.
Robust Embeddings Via Distributions
Apr 17, 2021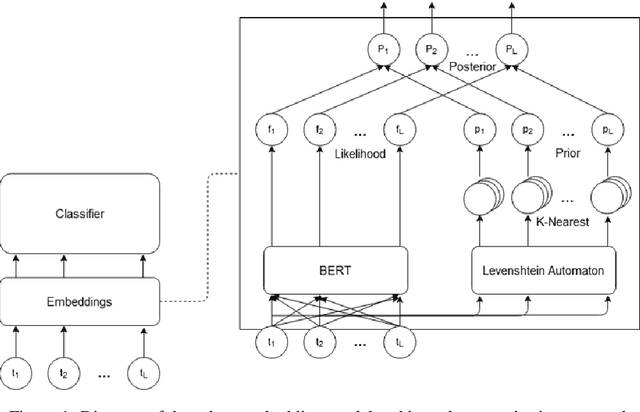
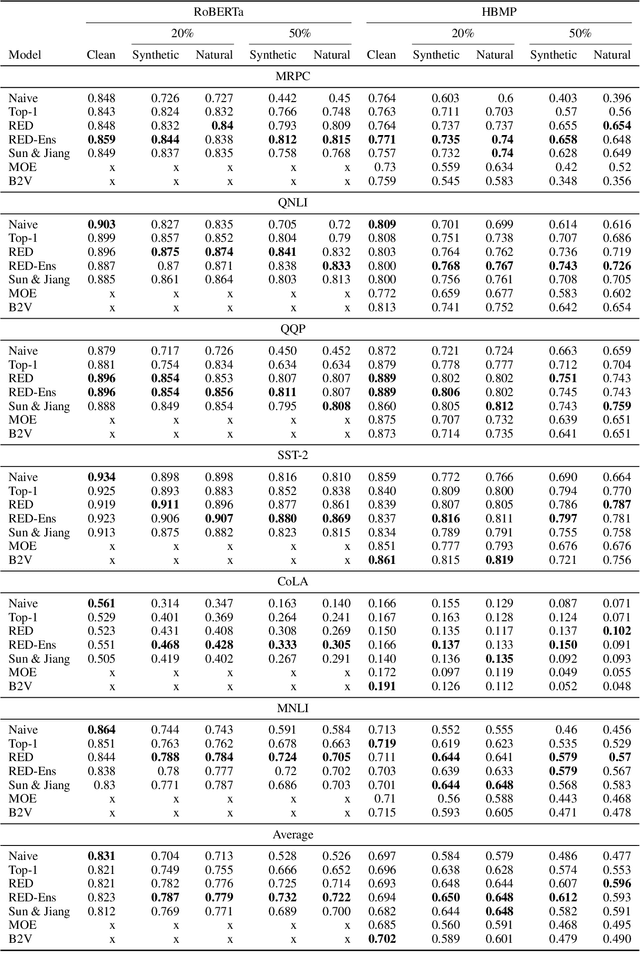
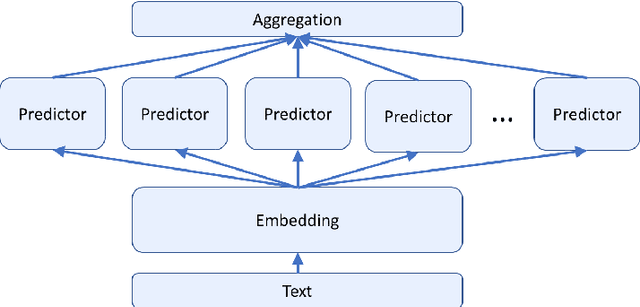

Despite recent monumental advances in the field, many Natural Language Processing (NLP) models still struggle to perform adequately on noisy domains. We propose a novel probabilistic embedding-level method to improve the robustness of NLP models. Our method, Robust Embeddings via Distributions (RED), incorporates information from both noisy tokens and surrounding context to obtain distributions over embedding vectors that can express uncertainty in semantic space more fully than any deterministic method. We evaluate our method on a number of downstream tasks using existing state-of-the-art models in the presence of both natural and synthetic noise, and demonstrate a clear improvement over other embedding approaches to robustness from the literature.
Efficiently Explaining CSPs with Unsatisfiable Subset Optimization
May 25, 2021
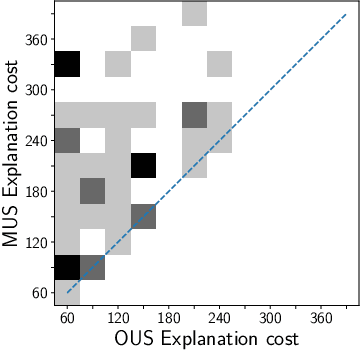
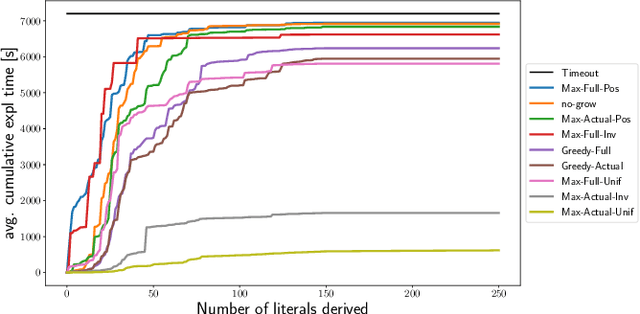
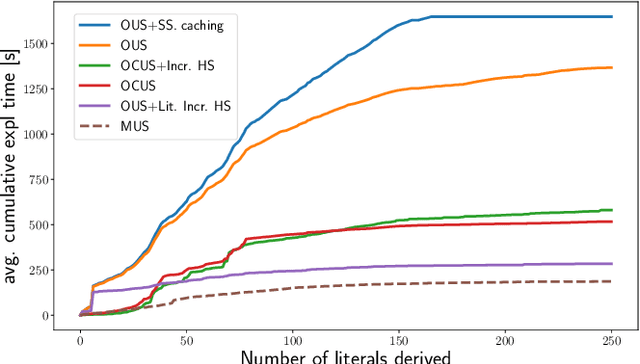
We build on a recently proposed method for explaining solutions of constraint satisfaction problems. An explanation here is a sequence of simple inference steps, where the simplicity of an inference step is measured by the number and types of constraints and facts used, and where the sequence explains all logical consequences of the problem. We build on these formal foundations and tackle two emerging questions, namely how to generate explanations that are provably optimal (with respect to the given cost metric) and how to generate them efficiently. To answer these questions, we develop 1) an implicit hitting set algorithm for finding optimal unsatisfiable subsets; 2) a method to reduce multiple calls for (optimal) unsatisfiable subsets to a single call that takes constraints on the subset into account, and 3) a method for re-using relevant information over multiple calls to these algorithms. The method is also applicable to other problems that require finding cost-optimal unsatiable subsets. We specifically show that this approach can be used to effectively find sequences of optimal explanation steps for constraint satisfaction problems like logic grid puzzles.
Iterative DNA Coding Scheme With GC Balance and Run-Length Constraints Using a Greedy Algorithm
Mar 05, 2021
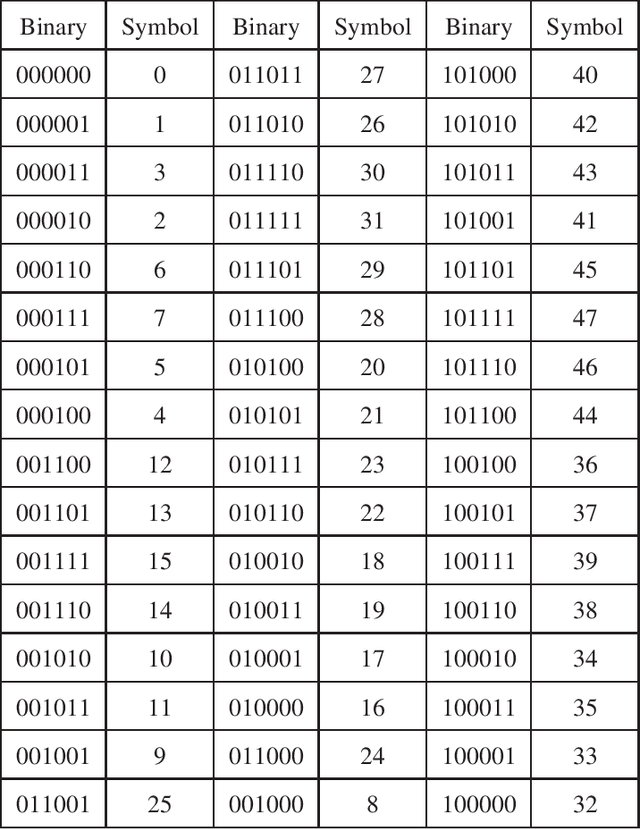
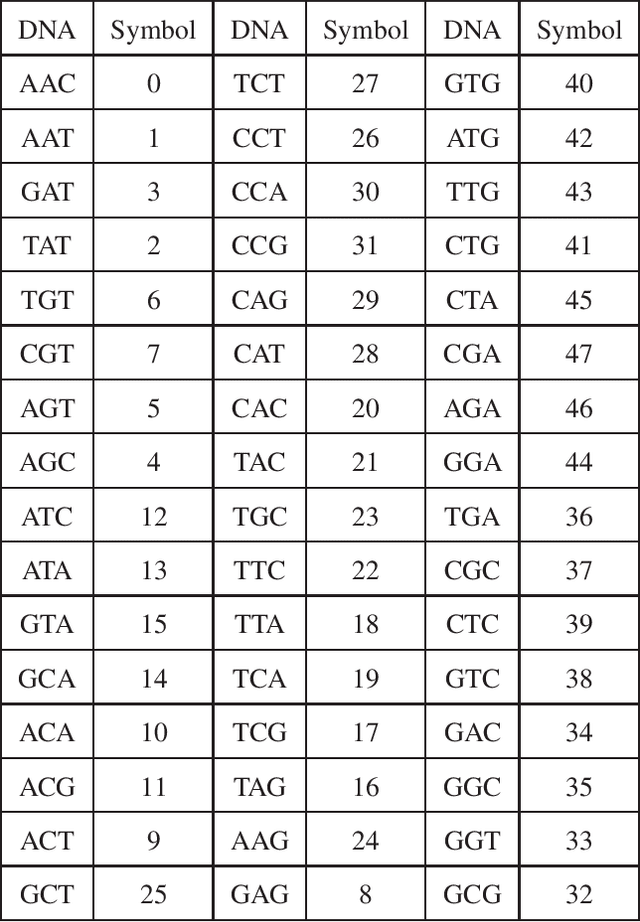
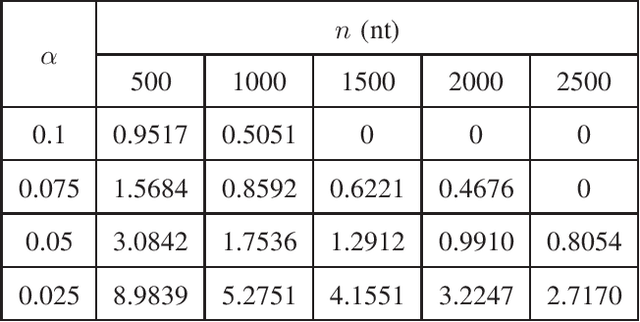
In this paper, we propose a novel iterative encoding algorithm for DNA storage to satisfy both the GC balance and run-length constraints using a greedy algorithm. DNA strands with run-length more than three and the GC balance ratio far from 50\% are known to be prone to errors. The proposed encoding algorithm stores data at high information density with high flexibility of run-length at most $m$ and GC balance between $0.5\pm\alpha$ for arbitrary $m$ and $\alpha$. More importantly, we propose a novel mapping method to reduce the average bit error compared to the randomly generated mapping method, using a greedy algorithm. The proposed algorithm is implemented through iterative encoding, consisting of three main steps: randomization, M-ary mapping, and verification. It has an information density of 1.8616 bits/nt in the case of $m=3$, which approaches the theoretical upper bound of 1.98 bits/nt, while satisfying two constraints. Also, the average bit error caused by the one nt error is 2.3455 bits, which is reduced by $20.5\%$, compared to the randomized mapping.
On the Effectiveness of Dataset Embeddings in Mono-lingual,Multi-lingual and Zero-shot Conditions
Mar 05, 2021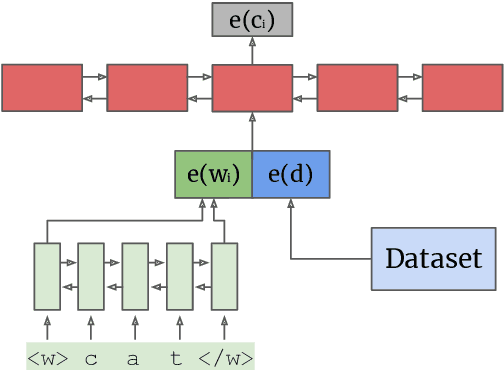

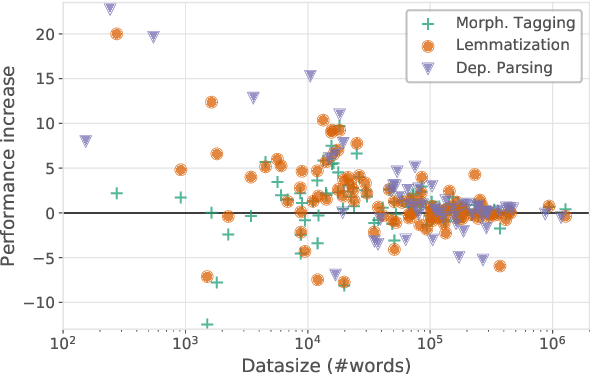
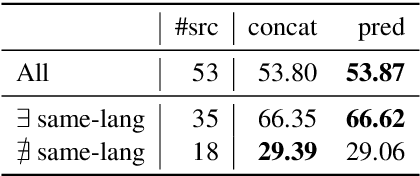
Recent complementary strands of research have shown that leveraging information on the data source through encoding their properties into embeddings can lead to performance increase when training a single model on heterogeneous data sources. However, it remains unclear in which situations these dataset embeddings are most effective, because they are used in a large variety of settings, languages and tasks. Furthermore, it is usually assumed that gold information on the data source is available, and that the test data is from a distribution seen during training. In this work, we compare the effect of dataset embeddings in mono-lingual settings, multi-lingual settings, and with predicted data source label in a zero-shot setting. We evaluate on three morphosyntactic tasks: morphological tagging, lemmatization, and dependency parsing, and use 104 datasets, 66 languages, and two different dataset grouping strategies. Performance increases are highest when the datasets are of the same language, and we know from which distribution the test-instance is drawn. In contrast, for setups where the data is from an unseen distribution, performance increase vanishes.
Opening the Black Box of Deep Neural Networks via Information
Apr 29, 2017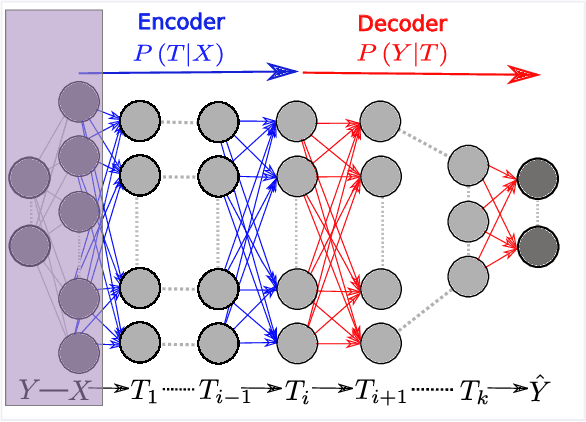
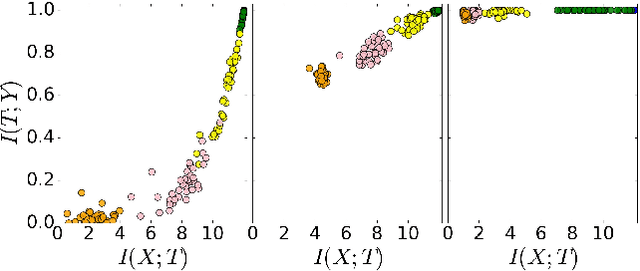
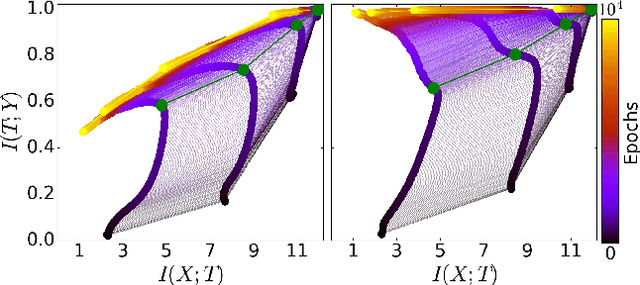
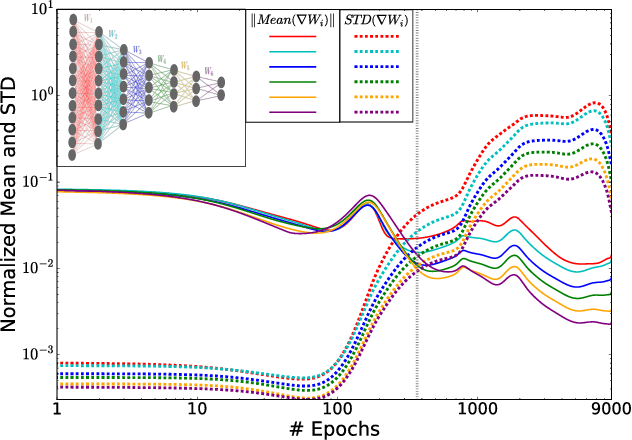
Despite their great success, there is still no comprehensive theoretical understanding of learning with Deep Neural Networks (DNNs) or their inner organization. Previous work proposed to analyze DNNs in the \textit{Information Plane}; i.e., the plane of the Mutual Information values that each layer preserves on the input and output variables. They suggested that the goal of the network is to optimize the Information Bottleneck (IB) tradeoff between compression and prediction, successively, for each layer. In this work we follow up on this idea and demonstrate the effectiveness of the Information-Plane visualization of DNNs. Our main results are: (i) most of the training epochs in standard DL are spent on {\emph compression} of the input to efficient representation and not on fitting the training labels. (ii) The representation compression phase begins when the training errors becomes small and the Stochastic Gradient Decent (SGD) epochs change from a fast drift to smaller training error into a stochastic relaxation, or random diffusion, constrained by the training error value. (iii) The converged layers lie on or very close to the Information Bottleneck (IB) theoretical bound, and the maps from the input to any hidden layer and from this hidden layer to the output satisfy the IB self-consistent equations. This generalization through noise mechanism is unique to Deep Neural Networks and absent in one layer networks. (iv) The training time is dramatically reduced when adding more hidden layers. Thus the main advantage of the hidden layers is computational. This can be explained by the reduced relaxation time, as this it scales super-linearly (exponentially for simple diffusion) with the information compression from the previous layer.
Person Re-Identification with a Locally Aware Transformer
Jun 08, 2021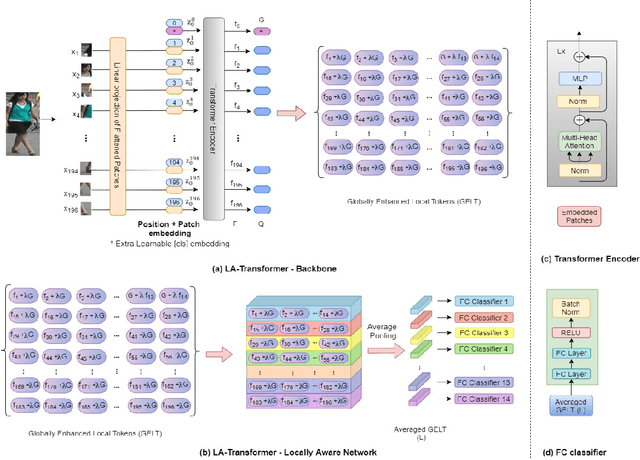
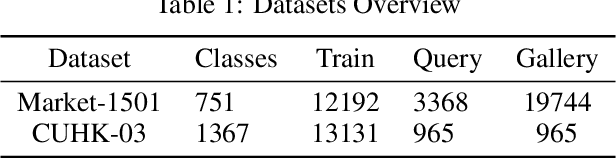
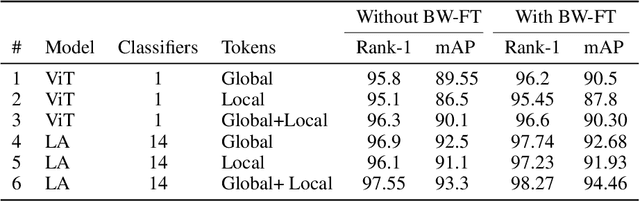
Person Re-Identification is an important problem in computer vision-based surveillance applications, in which the same person is attempted to be identified from surveillance photographs in a variety of nearby zones. At present, the majority of Person re-ID techniques are based on Convolutional Neural Networks (CNNs), but Vision Transformers are beginning to displace pure CNNs for a variety of object recognition tasks. The primary output of a vision transformer is a global classification token, but vision transformers also yield local tokens which contain additional information about local regions of the image. Techniques to make use of these local tokens to improve classification accuracy are an active area of research. We propose a novel Locally Aware Transformer (LA-Transformer) that employs a Parts-based Convolution Baseline (PCB)-inspired strategy for aggregating globally enhanced local classification tokens into an ensemble of $\sqrt{N}$ classifiers, where $N$ is the number of patches. An additional novelty is that we incorporate blockwise fine-tuning which further improves re-ID accuracy. LA-Transformer with blockwise fine-tuning achieves rank-1 accuracy of $98.27 \%$ with standard deviation of $0.13$ on the Market-1501 and $98.7\%$ with standard deviation of $0.2$ on the CUHK03 dataset respectively, outperforming all other state-of-the-art published methods at the time of writing.
Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning
May 12, 2021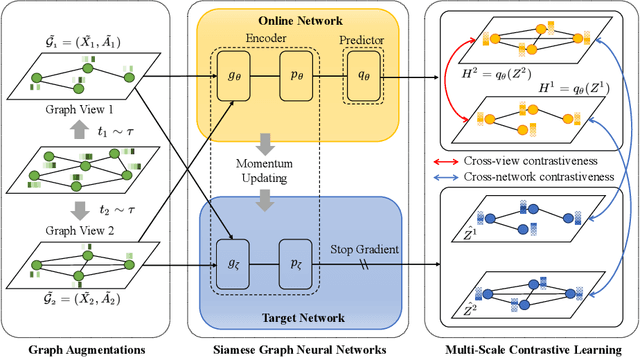
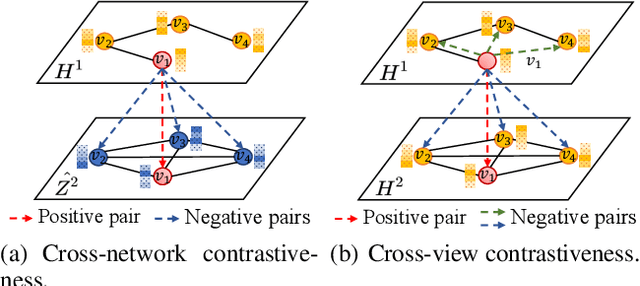
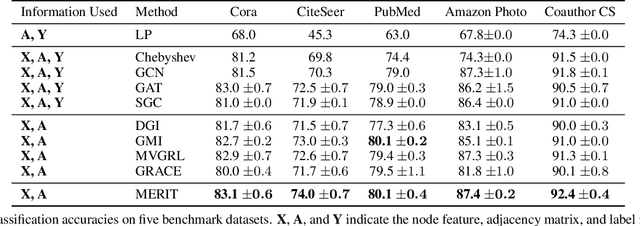
Graph representation learning plays a vital role in processing graph-structured data. However, prior arts on graph representation learning heavily rely on the labeling information. To overcome this problem, inspired by the recent success of graph contrastive learning and Siamese networks in visual representation learning, we propose a novel self-supervised approach in this paper to learn node representations by enhancing Siamese self-distillation with multi-scale contrastive learning. Specifically, we first generate two augmented views from the input graph based on local and global perspectives. Then, we employ two objectives called cross-view and cross-network contrastiveness to maximize the agreement between node representations across different views and networks. To demonstrate the effectiveness of our approach, we perform empirical experiments on five real-world datasets. Our method not only achieves new state-of-the-art results but also surpasses some semi-supervised counterparts by large margins.