 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021
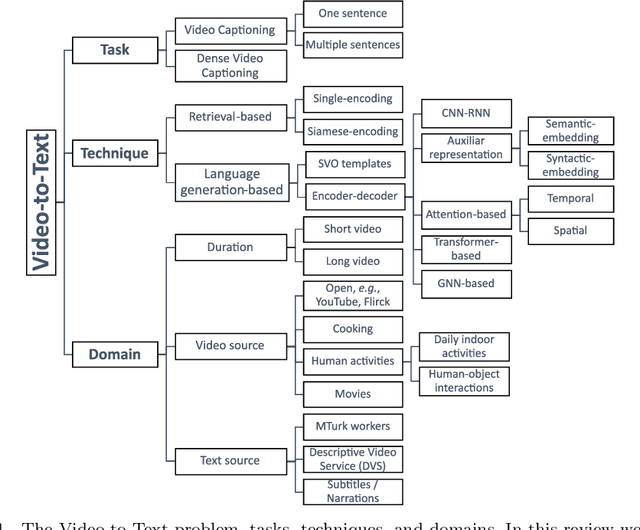
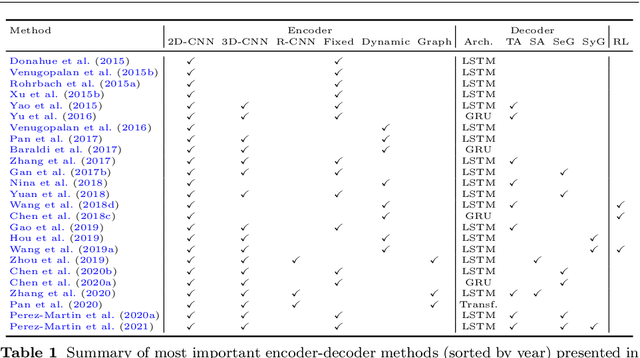
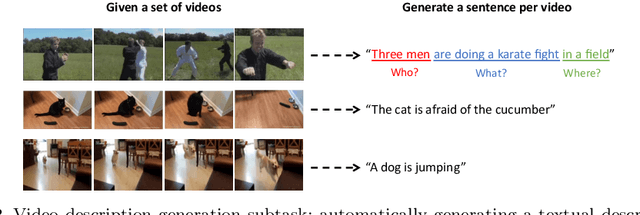
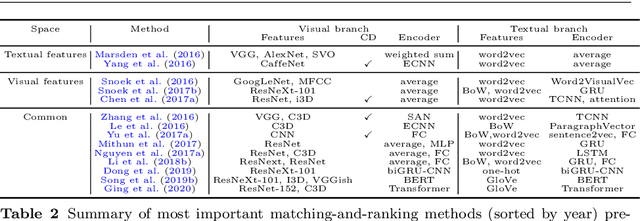
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
An Intelligent Hybrid Model for Identity Document Classification
Jun 07, 2021
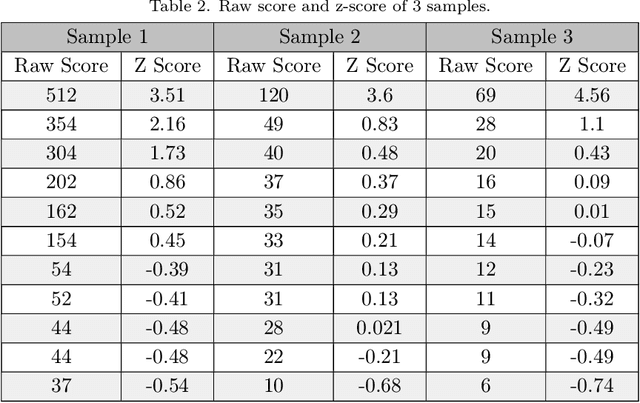
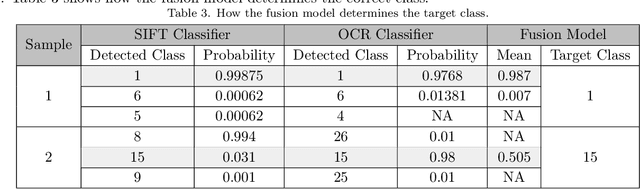
Digitization, i.e., the process of converting information into a digital format, may provide various opportunities (e.g., increase in productivity, disaster recovery, and environmentally friendly solutions) and challenges for businesses. In this context, one of the main challenges would be to accurately classify numerous scanned documents uploaded every day by customers as usual business processes. For example, processes in banking (e.g., applying for loans) or the Government Registry of BDM (Births, Deaths, and Marriages) applications may involve uploading several documents such as a driver's license and passport. There are not many studies available to address the challenge as an application of image classification. Although some studies are available which used various methods, a more accurate model is still required. The current study has proposed a robust fusion model to define the type of identity documents accurately. The proposed approach is based on two different methods in which images are classified based on their visual features and text features. A novel model based on statistics and regression has been proposed to calculate the confidence level for the feature-based classifier. A fuzzy-mean fusion model has been proposed to combine the classifier results based on their confidence score. The proposed approach has been implemented using Python and experimentally validated on synthetic and real-world datasets. The performance of the proposed model is evaluated using the Receiver Operating Characteristic (ROC) curve analysis.
Towards a Query-Optimal and Time-Efficient Algorithm for Clustering with a Faulty Oracle
Jun 18, 2021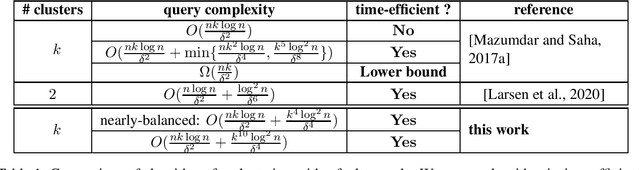
Motivated by applications in crowdsourced entity resolution in database, signed edge prediction in social networks and correlation clustering, Mazumdar and Saha [NIPS 2017] proposed an elegant theoretical model for studying clustering with a faulty oracle. In this model, given a set of $n$ items which belong to $k$ unknown groups (or clusters), our goal is to recover the clusters by asking pairwise queries to an oracle. This oracle can answer the query that ``do items $u$ and $v$ belong to the same cluster?''. However, the answer to each pairwise query errs with probability $\varepsilon$, for some $\varepsilon\in(0,\frac12)$. Mazumdar and Saha provided two algorithms under this model: one algorithm is query-optimal while time-inefficient (i.e., running in quasi-polynomial time), the other is time efficient (i.e., in polynomial time) while query-suboptimal. Larsen, Mitzenmacher and Tsourakakis [WWW 2020] then gave a new time-efficient algorithm for the special case of $2$ clusters, which is query-optimal if the bias $\delta:=1-2\varepsilon$ of the model is large. It was left as an open question whether one can obtain a query-optimal, time-efficient algorithm for the general case of $k$ clusters and other regimes of $\delta$. In this paper, we make progress on the above question and provide a time-efficient algorithm with nearly-optimal query complexity (up to a factor of $O(\log^2 n)$) for all constant $k$ and any $\delta$ in the regime when information-theoretic recovery is possible. Our algorithm is built on a connection to the stochastic block model.
Using natural language processing techniques to extract information on the properties and functionalities of energetic materials from large text corpora
Mar 01, 2019
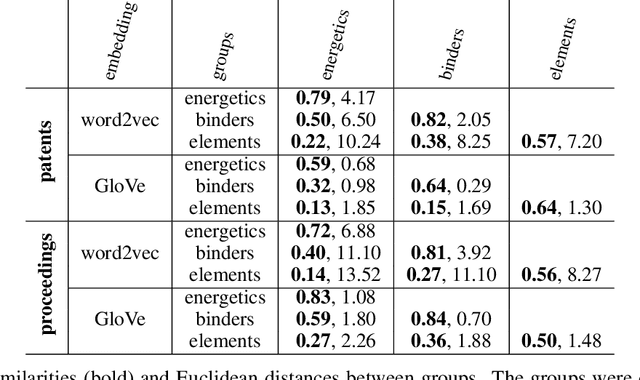


The number of scientific journal articles and reports being published about energetic materials every year is growing exponentially, and therefore extracting relevant information and actionable insights from the latest research is becoming a considerable challenge. In this work we explore how techniques from natural language processing and machine learning can be used to automatically extract chemical insights from large collections of documents. We first describe how to download and process documents from a variety of sources - journal articles, conference proceedings (including NTREM), the US Patent & Trademark Office, and the Defense Technical Information Center archive on archive.org. We present a custom NLP pipeline which uses open source NLP tools to identify the names of chemical compounds and relates them to function words ("underwater", "rocket", "pyrotechnic") and property words ("elastomer", "non-toxic"). After explaining how word embeddings work we compare the utility of two popular word embeddings - word2vec and GloVe. Chemical-chemical and chemical-application relationships are obtained by doing computations with word vectors. We show that word embeddings capture latent information about energetic materials, so that related materials appear close together in the word embedding space.
Closed-Loop Wireless Power Transfer with Adaptive Waveform and Beamforming: Design, Prototype, and Experiment
Jun 07, 2021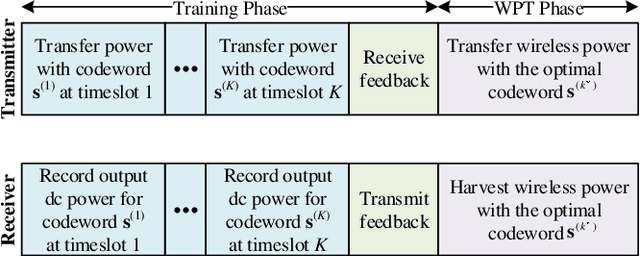
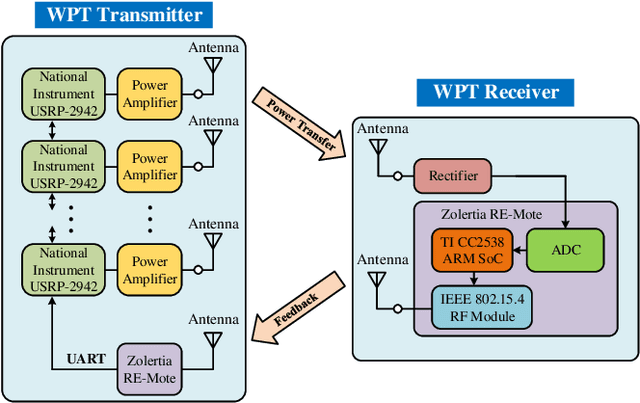

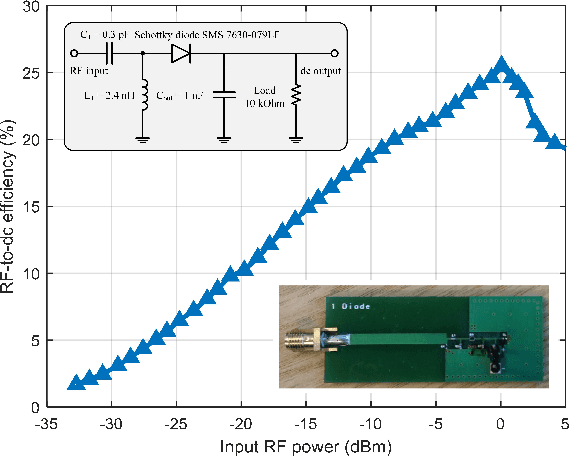
In this paper, we design, prototype, and experiment a closed-loop radiative wireless power transfer (WPT) system with adaptive waveform and beamforming using limited feedback. Spatial and frequency domains are exploited by jointly utilizing multi-sine waveform and multi-antenna beamforming at the transmitter in WPT system to adapt to the multipath fading channel and boost the output dc power. A closed-loop architecture based on a codebook design and a low complexity over-the-air limited feedback using an IEEE 802.15.4 RF interface is proposed. The codebook consists of multiple codewords where each codeword represents particular waveform and beamforming. The transmitter sweeps through the codebook and then the receiver feeds back the index of the optimal codeword, so that the waveform and beamforming can be adapted to the multipath fading channel to maximize the output dc power without requiring explicit channel estimation and the knowledge of accurate Channel State Information. The proposed closed-loop WPT with adaptive waveform and beamforming using limited feedback is prototyped using a Software Defined Radio equipment and measured in a real indoor environment. The measurement results show that the proposed closed-loop WPT with adaptive waveform and beamforming can increase the output dc power by up to 14.7 dB compared with the conventional single-tone and single-antenna WPT system.
Global Attention for Name Tagging
Oct 19, 2020
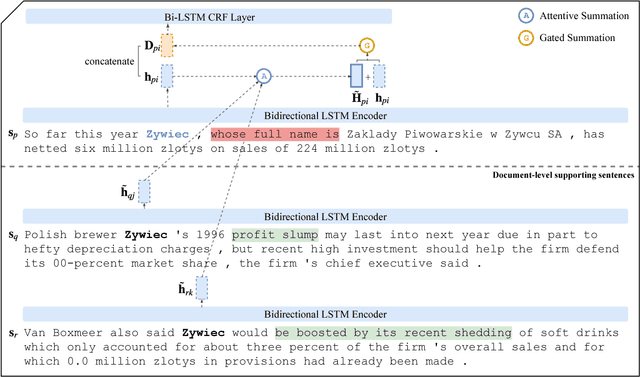
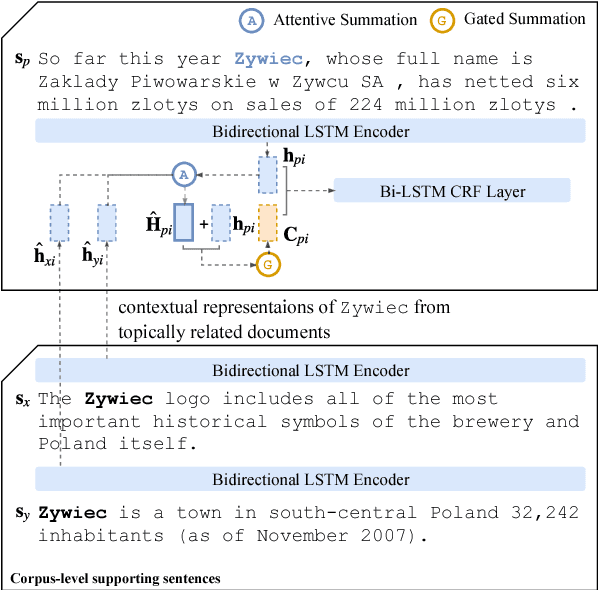
Many name tagging approaches use local contextual information with much success, but fail when the local context is ambiguous or limited. We present a new framework to improve name tagging by utilizing local, document-level, and corpus-level contextual information. We retrieve document-level context from other sentences within the same document and corpus-level context from sentences in other topically related documents. We propose a model that learns to incorporate document-level and corpus-level contextual information alongside local contextual information via global attentions, which dynamically weight their respective contextual information, and gating mechanisms, which determine the influence of this information. Extensive experiments on benchmark datasets show the effectiveness of our approach, which achieves state-of-the-art results for Dutch, German, and Spanish on the CoNLL-2002 and CoNLL-2003 datasets.
Stable Online Control of Linear Time-Varying Systems
Apr 30, 2021
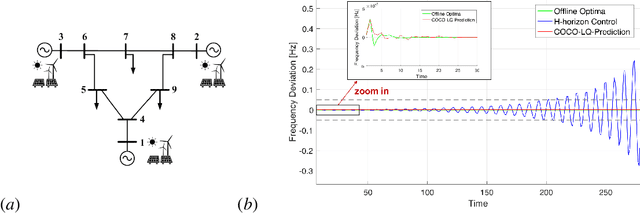

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
OFEI: A Semi-black-box Android Adversarial Sample Attack Framework Against DLaaS
May 25, 2021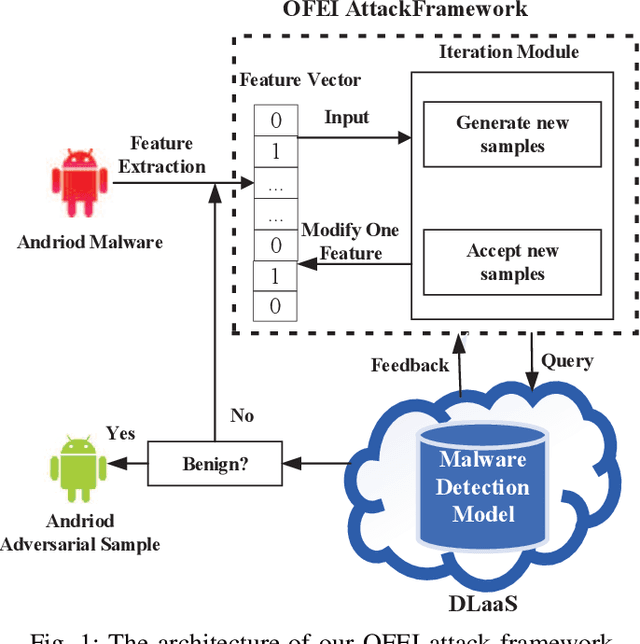
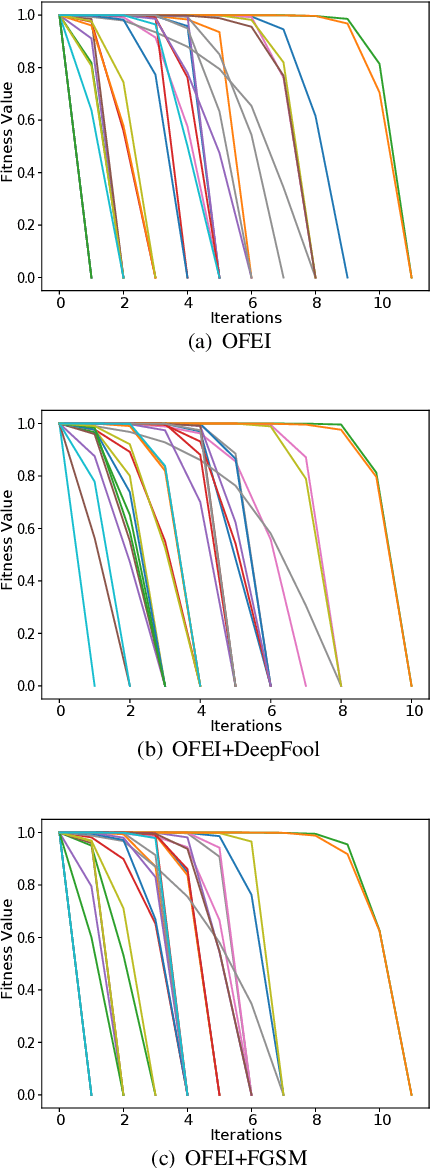
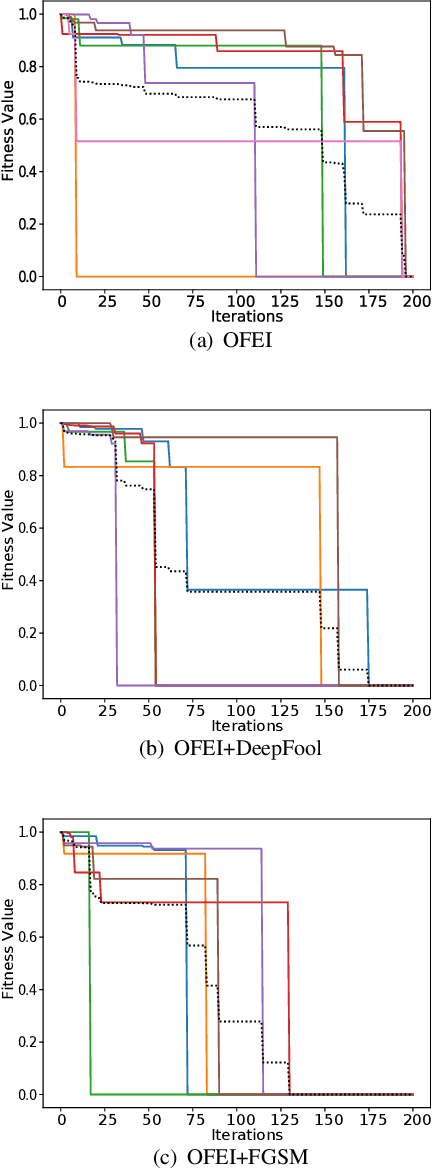
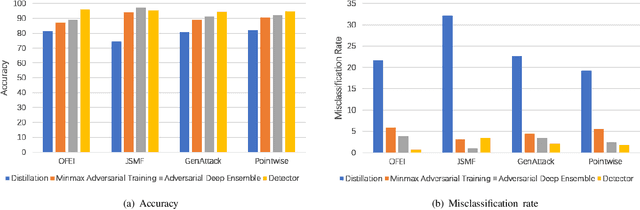
With the growing popularity of Android devices, Android malware is seriously threatening the safety of users. Although such threats can be detected by deep learning as a service (DLaaS), deep neural networks as the weakest part of DLaaS are often deceived by the adversarial samples elaborated by attackers. In this paper, we propose a new semi-black-box attack framework called one-feature-each-iteration (OFEI) to craft Android adversarial samples. This framework modifies as few features as possible and requires less classifier information to fool the classifier. We conduct a controlled experiment to evaluate our OFEI framework by comparing it with the benchmark methods JSMF, GenAttack and pointwise attack. The experimental results show that our OFEI has a higher misclassification rate of 98.25%. Furthermore, OFEI can extend the traditional white-box attack methods in the image field, such as fast gradient sign method (FGSM) and DeepFool, to craft adversarial samples for Android. Finally, to enhance the security of DLaaS, we use two uncertainties of the Bayesian neural network to construct the combined uncertainty, which is used to detect adversarial samples and achieves a high detection rate of 99.28%.
Multi-Target Domain Adaptation with Collaborative Consistency Learning
Jun 07, 2021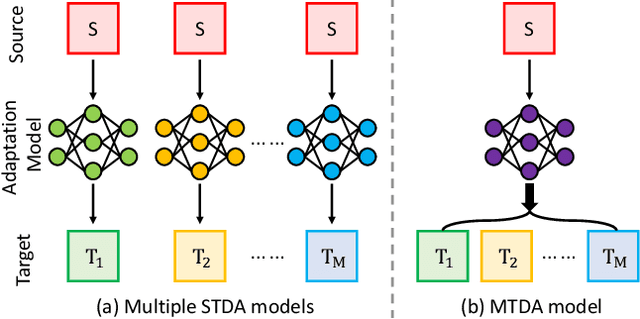
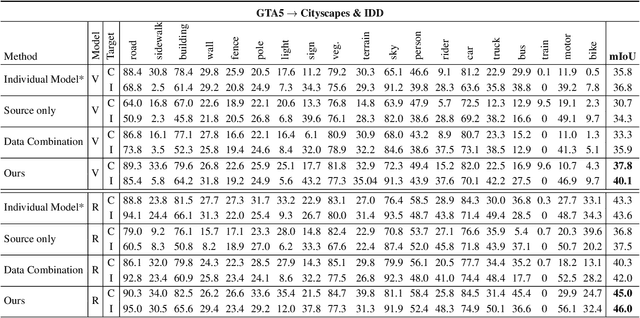
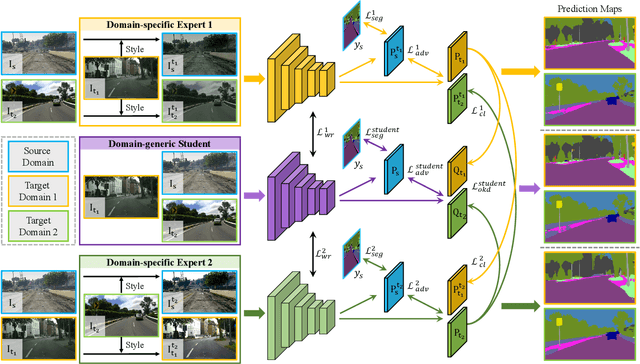
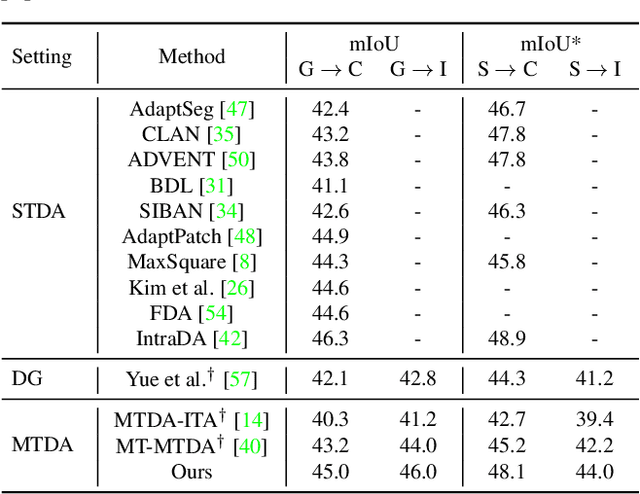
Recently unsupervised domain adaptation for the semantic segmentation task has become more and more popular due to high-cost of pixel-level annotation on real-world images. However, most domain adaptation methods are only restricted to single-source-single-target pair, and can not be directly extended to multiple target domains. In this work, we propose a collaborative learning framework to achieve unsupervised multi-target domain adaptation. An unsupervised domain adaptation expert model is first trained for each source-target pair and is further encouraged to collaborate with each other through a bridge built between different target domains. These expert models are further improved by adding the regularization of making the consistent pixel-wise prediction for each sample with the same structured context. To obtain a single model that works across multiple target domains, we propose to simultaneously learn a student model which is trained to not only imitate the output of each expert on the corresponding target domain, but also to pull different expert close to each other with regularization on their weights. Extensive experiments demonstrate that the proposed method can effectively exploit rich structured information contained in both labeled source domain and multiple unlabeled target domains. Not only does it perform well across multiple target domains but also performs favorably against state-of-the-art unsupervised domain adaptation methods specially trained on a single source-target pair
Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review
May 31, 2021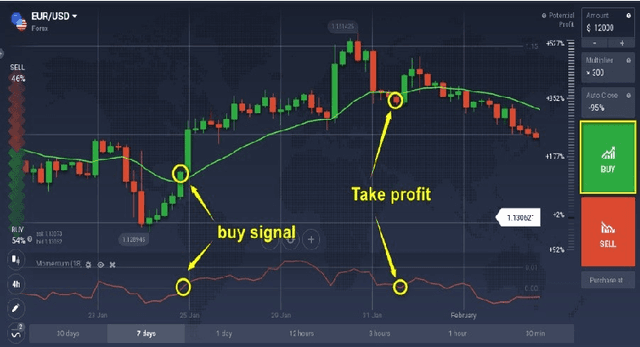
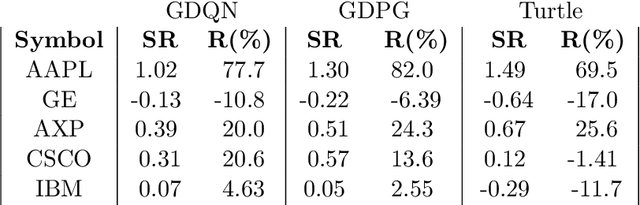
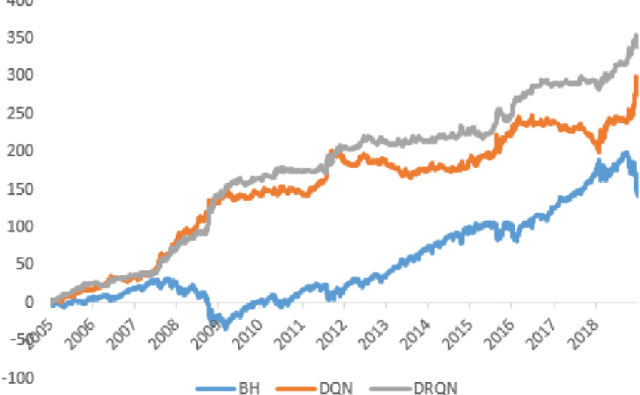
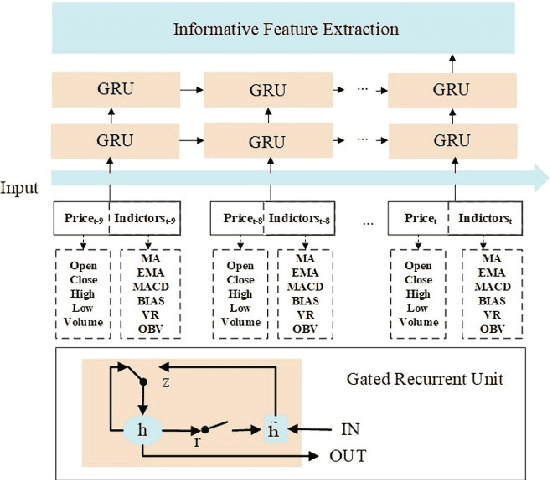
Algorithmic stock trading has become a staple in today's financial market, the majority of trades being now fully automated. Deep Reinforcement Learning (DRL) agents proved to be to a force to be reckon with in many complex games like Chess and Go. We can look at the stock market historical price series and movements as a complex imperfect information environment in which we try to maximize return - profit and minimize risk. This paper reviews the progress made so far with deep reinforcement learning in the subdomain of AI in finance, more precisely, automated low-frequency quantitative stock trading. Many of the reviewed studies had only proof-of-concept ideals with experiments conducted in unrealistic settings and no real-time trading applications. For the majority of the works, despite all showing statistically significant improvements in performance compared to established baseline strategies, no decent profitability level was obtained. Furthermore, there is a lack of experimental testing in real-time, online trading platforms and a lack of meaningful comparisons between agents built on different types of DRL or human traders. We conclude that DRL in stock trading has showed huge applicability potential rivalling professional traders under strong assumptions, but the research is still in the very early stages of development.