 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Extended Feedback Codes
May 04, 2021
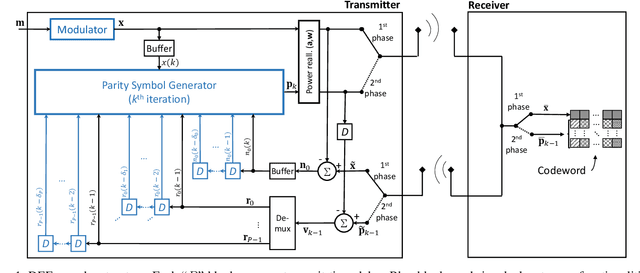
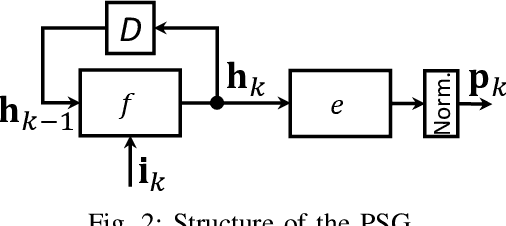
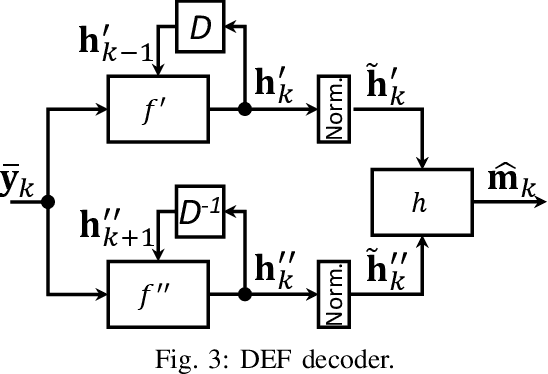
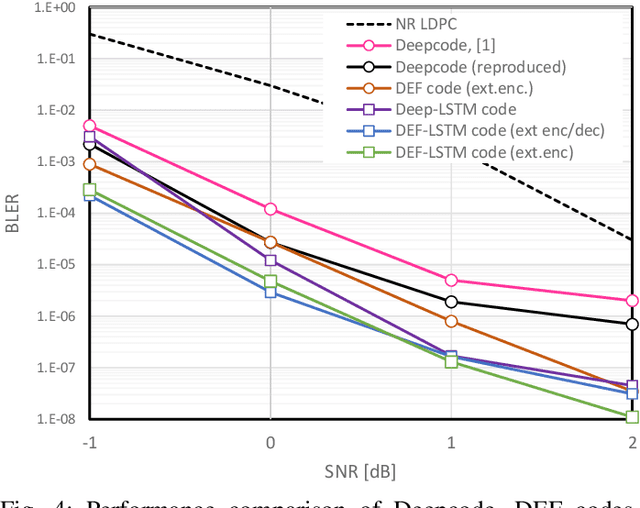
A new deep-neural-network (DNN) based error correction encoder architecture for channels with feedback, called Deep Extended Feedback (DEF), is presented in this paper. The encoder in the DEF architecture transmits an information message followed by a sequence of parity symbols which are generated based on the message as well as the observations of the past forward channel outputs sent to the transmitter through a feedback channel. DEF codes generalize Deepcode [1] in several ways: parity symbols are generated based on forward-channel output observations over longer time intervals in order to provide better error correction capability; and high-order modulation formats are deployed in the encoder so as to achieve increased spectral efficiency. Performance evaluations show that DEF codes have better performance compared to other DNN-based codes for channels with feedback.
AutoCone: An OmniDirectional Robot for Lane-Level Cone Placement
Apr 29, 2021
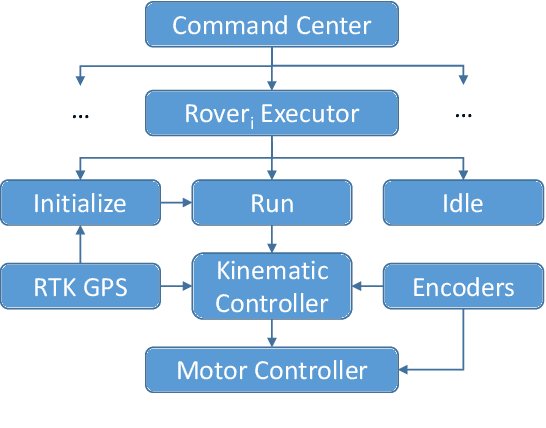
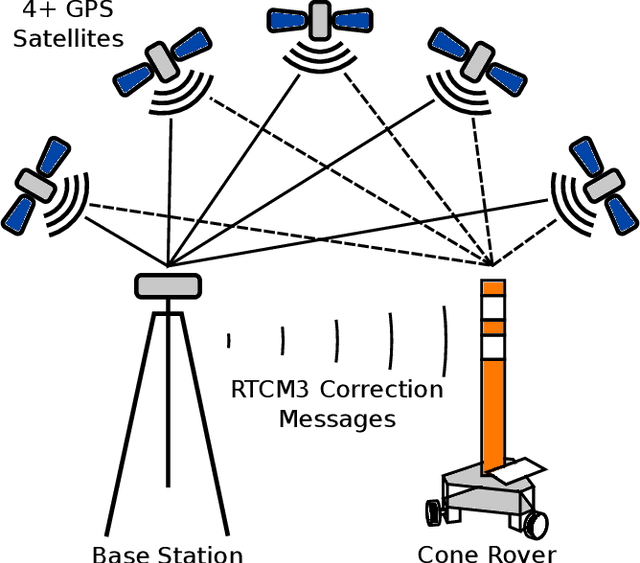
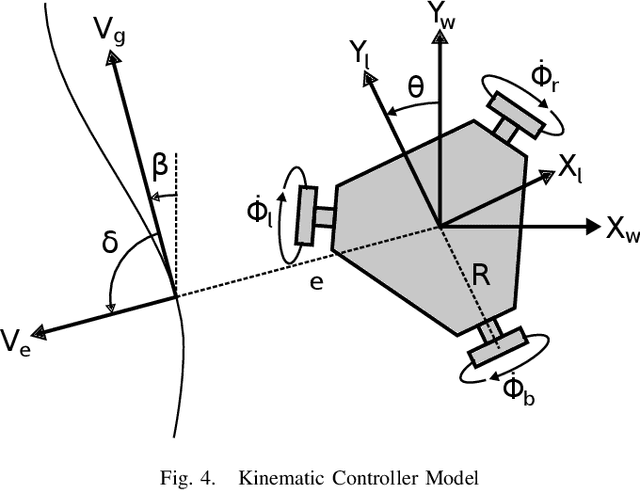
This paper summarizes the progress in developing a rugged, low-cost, automated ground cone robot network capable of traffic delineation at lane-level precision. A holonomic omnidirectional base with a traffic delineator was developed to allow flexibility in initialization. RTK GPS was utilized to reduce minimum position error to 2 centimeters. Due to recent developments, the cost of the platform is now less than $1,600. To minimize the effects of GPS-denied environments, wheel encoders and an Extended Kalman Filter were implemented to maintain lane-level accuracy during operation and a maximum error of 1.97 meters through 50 meters with little to no GPS signal. Future work includes increasing the operational speed of the platforms, incorporating lanelet information for path planning, and cross-platform estimation.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 16, 2021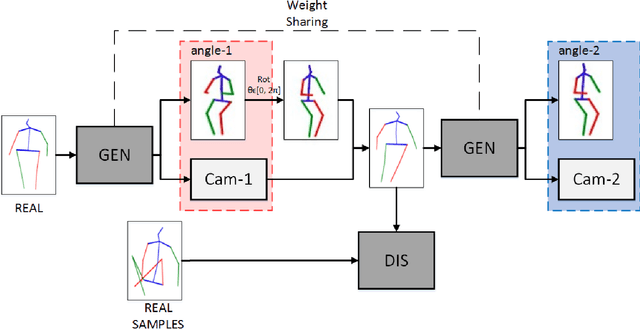
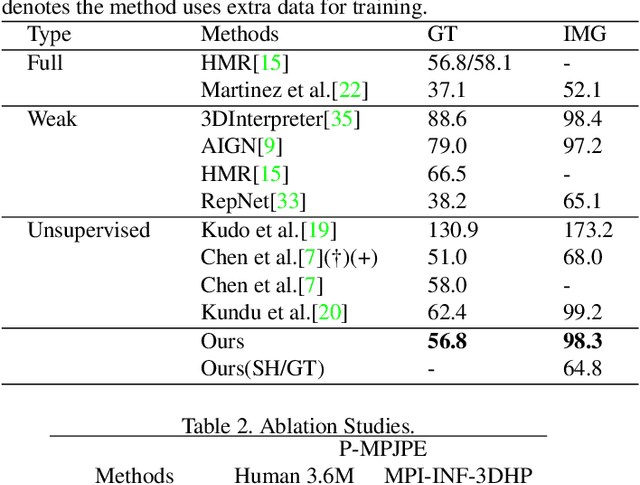
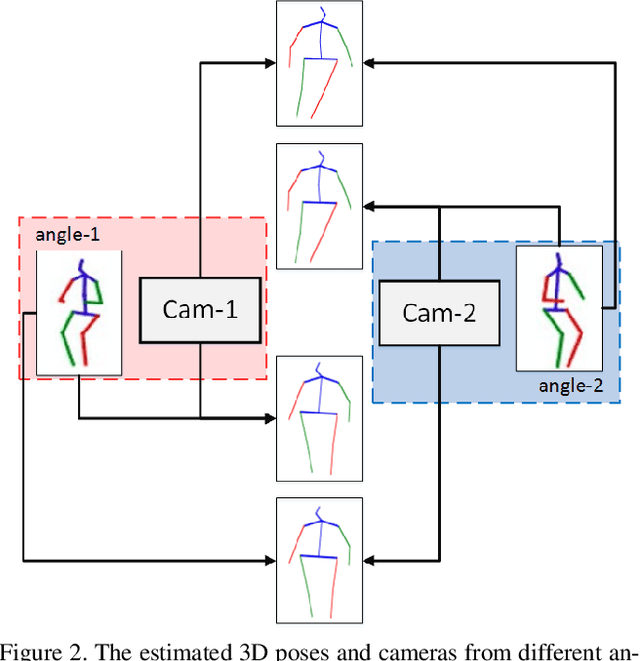
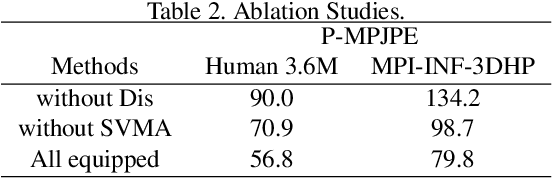
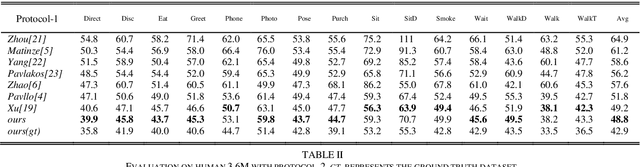
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.
Rhetorical relations for information retrieval
Apr 05, 2017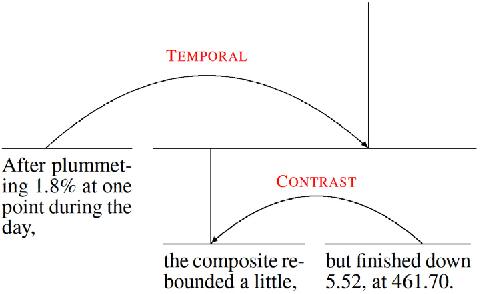

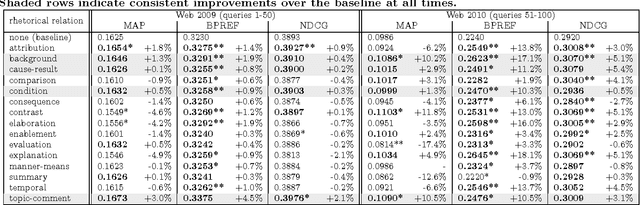
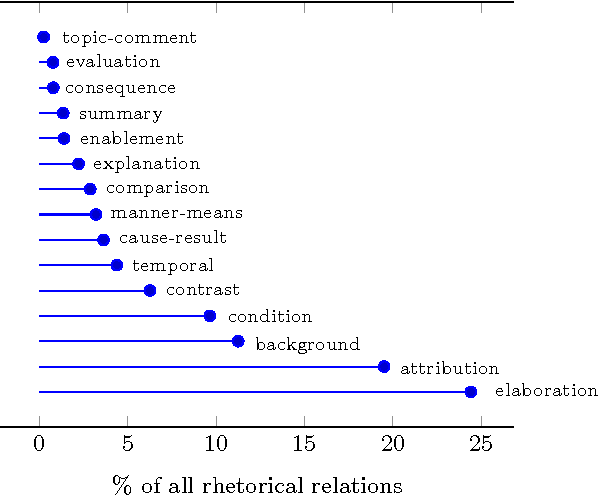
Typically, every part in most coherent text has some plausible reason for its presence, some function that it performs to the overall semantics of the text. Rhetorical relations, e.g. contrast, cause, explanation, describe how the parts of a text are linked to each other. Knowledge about this socalled discourse structure has been applied successfully to several natural language processing tasks. This work studies the use of rhetorical relations for Information Retrieval (IR): Is there a correlation between certain rhetorical relations and retrieval performance? Can knowledge about a document's rhetorical relations be useful to IR? We present a language model modification that considers rhetorical relations when estimating the relevance of a document to a query. Empirical evaluation of different versions of our model on TREC settings shows that certain rhetorical relations can benefit retrieval effectiveness notably (> 10% in mean average precision over a state-of-the-art baseline).
Response Ranking with Deep Matching Networks and External Knowledge in Information-seeking Conversation Systems
May 09, 2018
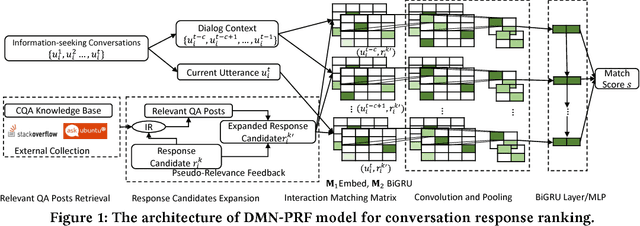
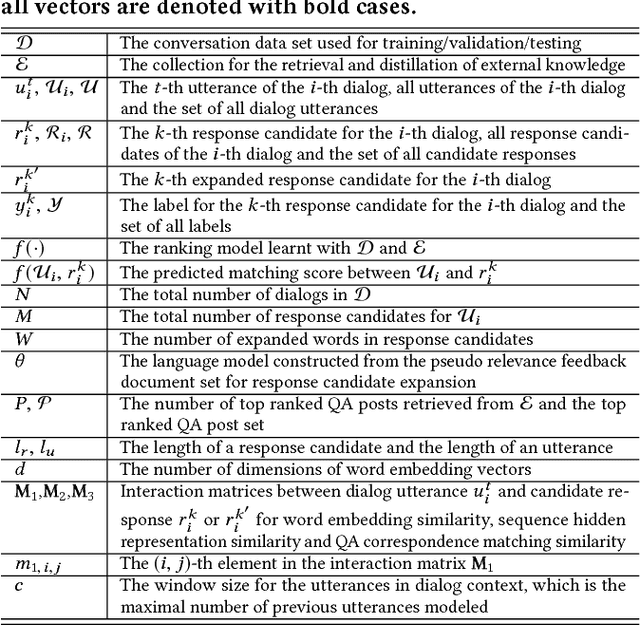
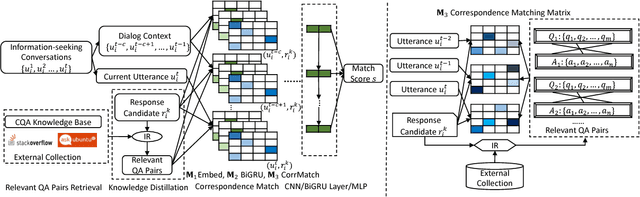
Intelligent personal assistant systems with either text-based or voice-based conversational interfaces are becoming increasingly popular around the world. Retrieval-based conversation models have the advantages of returning fluent and informative responses. Most existing studies in this area are on open domain "chit-chat" conversations or task / transaction oriented conversations. More research is needed for information-seeking conversations. There is also a lack of modeling external knowledge beyond the dialog utterances among current conversational models. In this paper, we propose a learning framework on the top of deep neural matching networks that leverages external knowledge for response ranking in information-seeking conversation systems. We incorporate external knowledge into deep neural models with pseudo-relevance feedback and QA correspondence knowledge distillation. Extensive experiments with three information-seeking conversation data sets including both open benchmarks and commercial data show that, our methods outperform various baseline methods including several deep text matching models and the state-of-the-art method on response selection in multi-turn conversations. We also perform analysis over different response types, model variations and ranking examples. Our models and research findings provide new insights on how to utilize external knowledge with deep neural models for response selection and have implications for the design of the next generation of information-seeking conversation systems.
Estimation of 3D Human Pose Using Prior Knowledge
May 09, 2021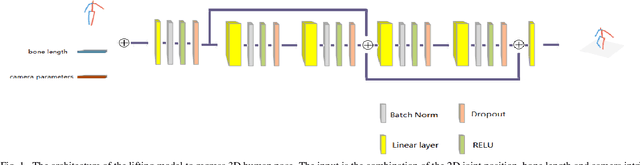
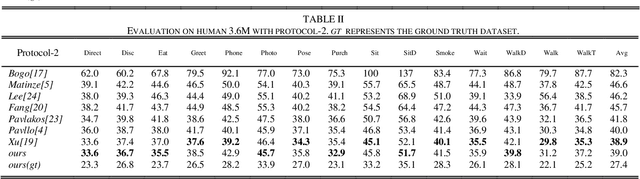
Estimating three-dimensional human poses from the positions of two-dimensional joints has shown promising results.However, using two-dimensional joint coordinates as input loses more information than image-based approaches and results in ambiguity.In order to overcome this problem, we combine bone length and camera parameters with two-dimensional joint coordinates for input.This combination is more discriminative than the two-dimensional joint coordinates in that it can improve the accuracy of the model's prediction depth and alleviate the ambiguity that comes from projecting three-dimensional coordinates into two-dimensional space. Furthermore, we introduce direction constraints which can better measure the difference between the ground truth and the output of the proposed model. The experimental results on the H36M show that the method performed better than other state-of-the-art three-dimensional human pose estimation approaches.
High Order Local Directional Pattern Based Pyramidal Multi-structure for Robust Face Recognition
Dec 12, 2020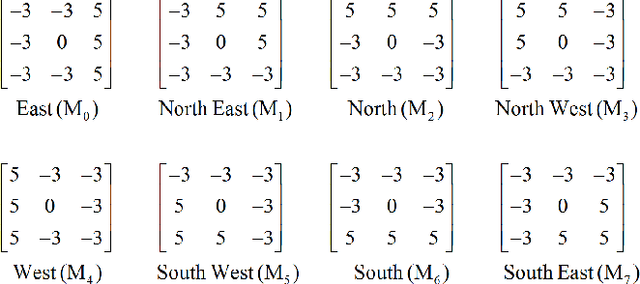
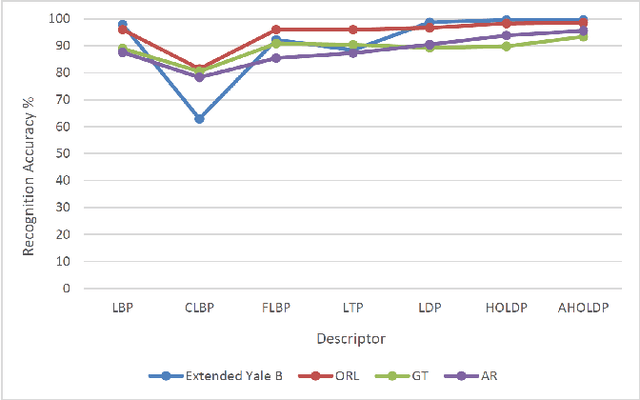

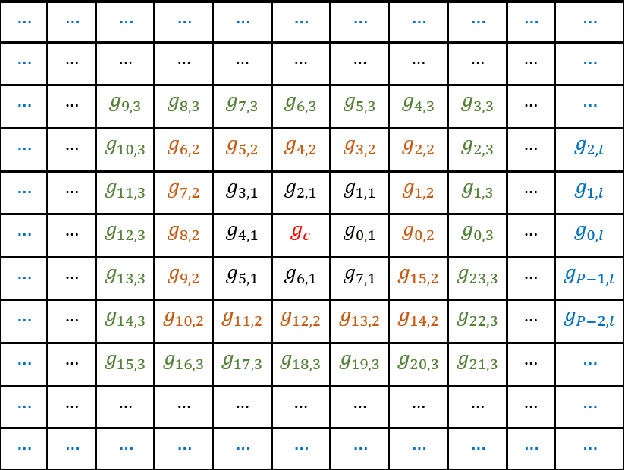
Derived from a general definition of texture in a local neighborhood, local directional pattern (LDP) encodes the directional information in the small local 3x3 neighborhood of a pixel, which may fail to extract detailed information especially during changes in the input image due to illumination variations. Therefore, in this paper we introduce a novel feature extraction technique that calculates the nth order direction variation patterns, named high order local directional pattern (HOLDP). The proposed HOLDP can capture more detailed discriminative information than the conventional LDP. Unlike the LDP operator, our proposed technique extracts nth order local information by encoding various distinctive spatial relationships from each neighborhood layer of a pixel in the pyramidal multi-structure way. Then we concatenate the feature vector of each neighborhood layer to form the final HOLDP feature vector. The performance evaluation of the proposed HOLDP algorithm is conducted on several publicly available face databases and observed the superiority of HOLDP under extreme illumination conditions.
Visual Sensor Pose Optimisation Using Rendering-based Visibility Models for Robust Cooperative Perception
Jun 09, 2021


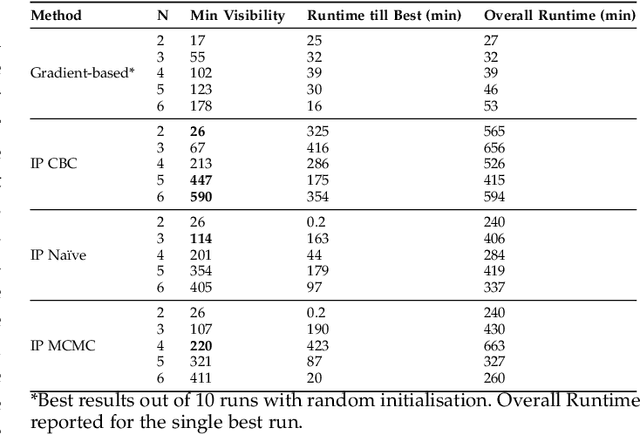
Visual Sensor Networks can be used in a variety of perception applications such as infrastructure support for autonomous driving in complex road segments. The pose of the sensors in such networks directly determines the coverage of the environment and objects therein, which impacts the performance of applications such as object detection and tracking. Existing sensor pose optimisation methods in the literature either maximise the coverage of ground surfaces, or consider the visibility of the target objects as binary variables, which cannot represent various degrees of visibility. Such formulations cannot guarantee the visibility of the target objects as they fail to consider occlusions. This paper proposes two novel sensor pose optimisation methods, based on gradient-ascent and Integer Programming techniques, which maximise the visibility of multiple target objects in cluttered environments. Both methods consider a realistic visibility model based on a rendering engine that provides pixel-level visibility information about the target objects. The proposed methods are evaluated in a complex environment and compared to existing methods in the literature. The evaluation results indicate that explicitly modelling the visibility of target objects is critical to avoid occlusions in cluttered environments. Furthermore, both methods significantly outperform existing methods in terms of object visibility.
NeRF in detail: Learning to sample for view synthesis
Jun 09, 2021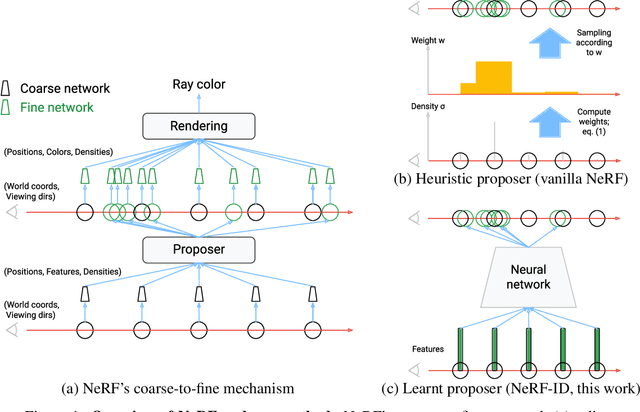
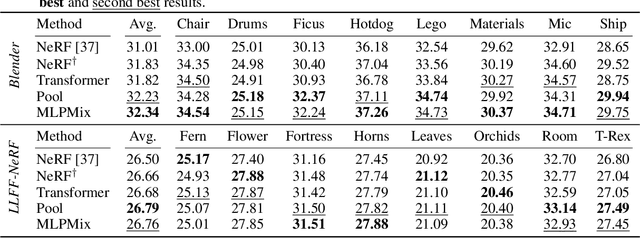
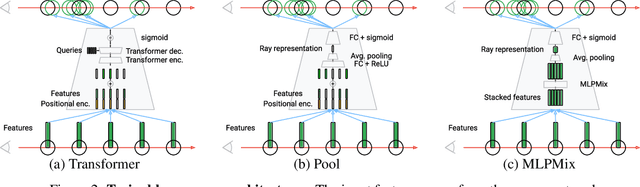

Neural radiance fields (NeRF) methods have demonstrated impressive novel view synthesis performance. The core approach is to render individual rays by querying a neural network at points sampled along the ray to obtain the density and colour of the sampled points, and integrating this information using the rendering equation. Since dense sampling is computationally prohibitive, a common solution is to perform coarse-to-fine sampling. In this work we address a clear limitation of the vanilla coarse-to-fine approach -- that it is based on a heuristic and not trained end-to-end for the task at hand. We introduce a differentiable module that learns to propose samples and their importance for the fine network, and consider and compare multiple alternatives for its neural architecture. Training the proposal module from scratch can be unstable due to lack of supervision, so an effective pre-training strategy is also put forward. The approach, named `NeRF in detail' (NeRF-ID), achieves superior view synthesis quality over NeRF and the state-of-the-art on the synthetic Blender benchmark and on par or better performance on the real LLFF-NeRF scenes. Furthermore, by leveraging the predicted sample importance, a 25% saving in computation can be achieved without significantly sacrificing the rendering quality.
Domain Specific Transporter Framework to Detect Fractures in Ultrasound
Jun 09, 2021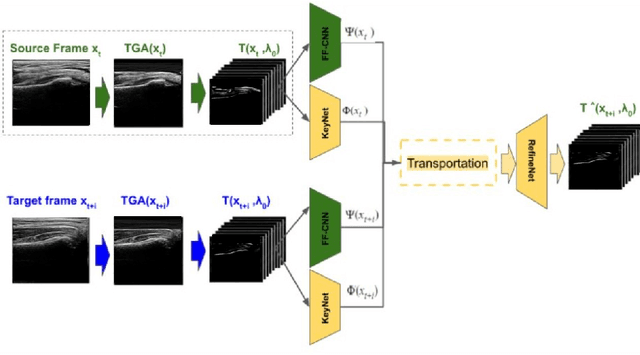
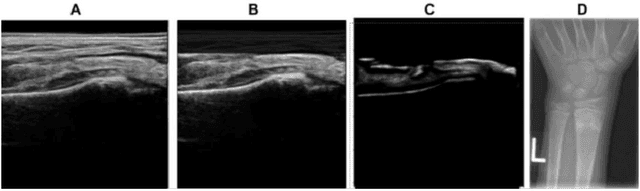
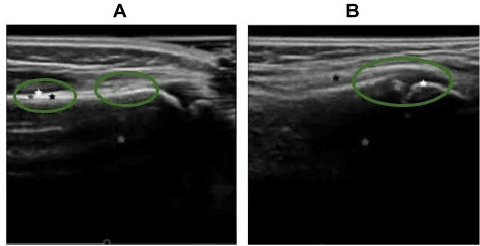
Ultrasound examination for detecting fractures is ideally suited for Emergency Departments (ED) as it is relatively fast, safe (from ionizing radiation), has dynamic imaging capability and is easily portable. High interobserver variability in manual assessment of ultrasound scans has piqued research interest in automatic assessment techniques using Deep Learning (DL). Most DL techniques are supervised and are trained on large numbers of labeled data which is expensive and requires many hours of careful annotation by experts. In this paper, we propose an unsupervised, domain specific transporter framework to identify relevant keypoints from wrist ultrasound scans. Our framework provides a concise geometric representation highlighting regions with high structural variation in a 3D ultrasound (3DUS) sequence. We also incorporate domain specific information represented by instantaneous local phase (LP) which detects bone features from 3DUS. We validate the technique on 3DUS videos obtained from 30 subjects. Each ultrasound scan was independently assessed by three readers to identify fractures along with the corresponding x-ray. Saliency of keypoints detected in the image\ are compared against manual assessment based on distance from relevant features.The transporter neural network was able to accurately detect 180 out of 250 bone regions sampled from wrist ultrasound videos. We expect this technique to increase the applicability of ultrasound in fracture detection.