 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Navigating A Mobile Robot Using Switching Distributed Sensor Networks
Jun 25, 2021
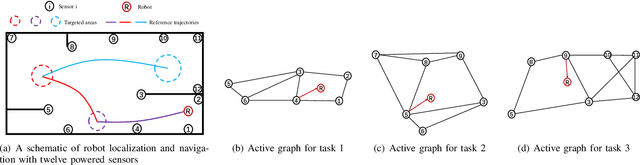
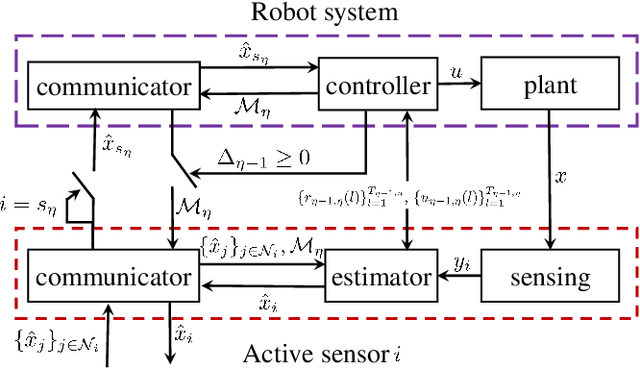
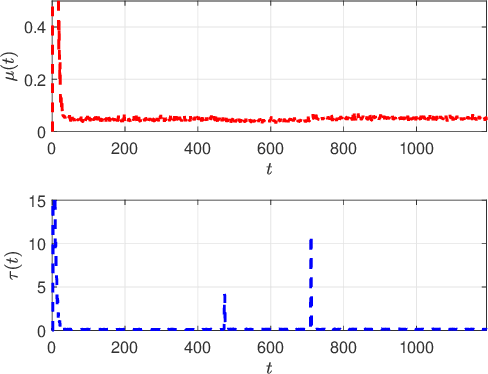
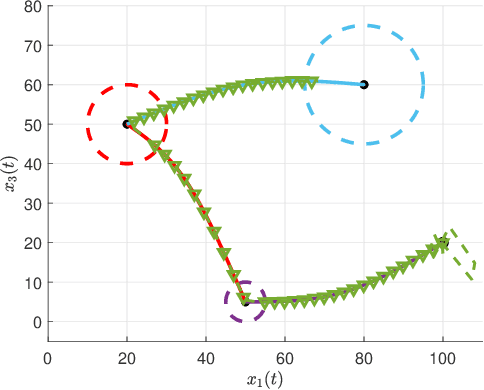
This paper proposes a method to navigate a mobile robot by estimating its state over a number of distributed sensor networks (DSNs) such that it can successively accomplish a sequence of tasks, i.e., its state enters each targeted set and stays inside no less than the desired time, under a resource-aware, time-efficient, and computation- and communication-constrained setting.We propose a new robot state estimation and navigation architecture, which integrates an event-triggered task-switching feedback controller for the robot and a two-time-scale distributed state estimator for each sensor. The architecture has three major advantages over existing approaches: First, in each task only one DSN is active for sensing and estimating the robot state, and for different tasks the robot can switch the active DSN by taking resource saving and system performance into account; Second, the robot only needs to communicate with one active sensor at each time to obtain its state information from the active DSN; Third, no online optimization is required. With the controller, the robot is able to accomplish a task by following a reference trajectory and switch to the next task when an event-triggered condition is fulfilled. With the estimator, each active sensor is able to estimate the robot state. Under proper conditions, we prove that the state estimation error and the trajectory tracking deviation are upper bounded by two time-varying sequences respectively, which play an essential role in the event-triggered condition. Furthermore, we find a sufficient condition for accomplishing a task and provide an upper bound of running time for the task. Numerical simulations of an indoor robot's localization and navigation are provided to validate the proposed architecture.
Visual Grounding with Transformers
May 10, 2021
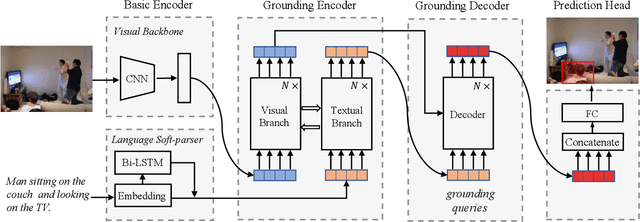
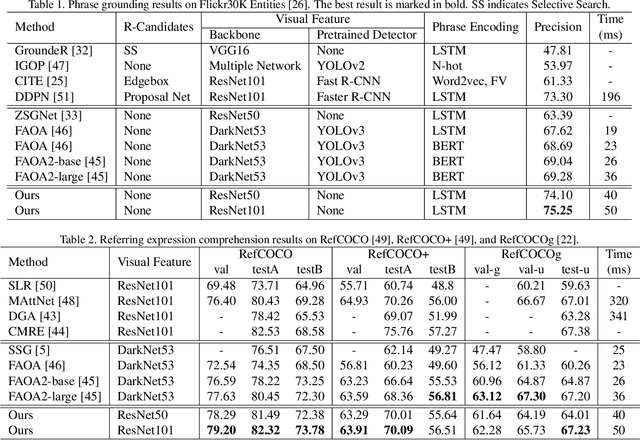
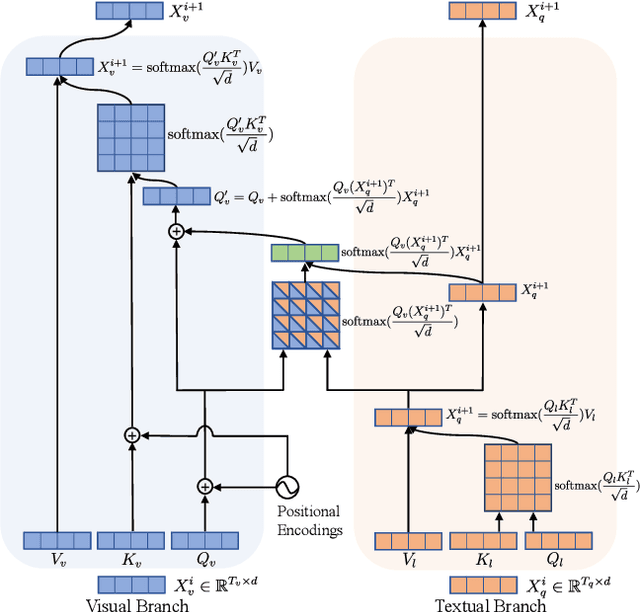
In this paper, we propose a transformer based approach for visual grounding. Unlike previous proposal-and-rank frameworks that rely heavily on pretrained object detectors or proposal-free frameworks that upgrade an off-the-shelf one-stage detector by fusing textual embeddings, our approach is built on top of a transformer encoder-decoder and is independent of any pretrained detectors or word embedding models. Termed VGTR -- Visual Grounding with TRansformers, our approach is designed to learn semantic-discriminative visual features under the guidance of the textual description without harming their location ability. This information flow enables our VGTR to have a strong capability in capturing context-level semantics of both vision and language modalities, rendering us to aggregate accurate visual clues implied by the description to locate the interested object instance. Experiments show that our method outperforms state-of-the-art proposal-free approaches by a considerable margin on five benchmarks while maintaining fast inference speed.
Permutation invariance and uncertainty in multitemporal image super-resolution
May 26, 2021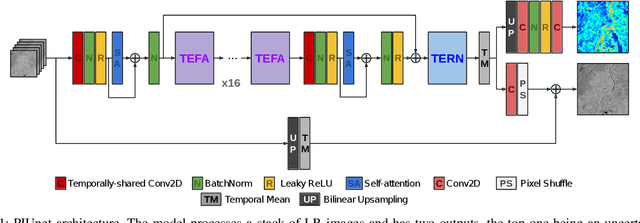
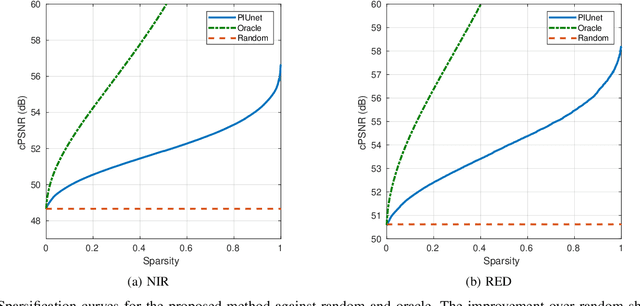
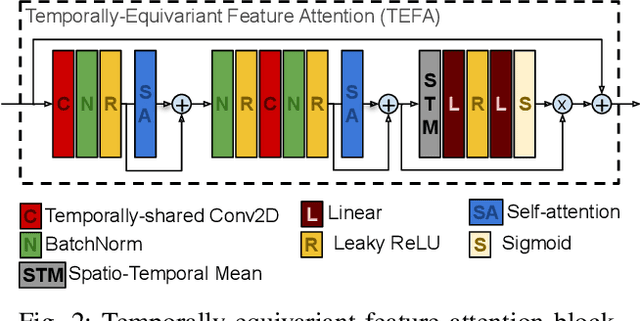
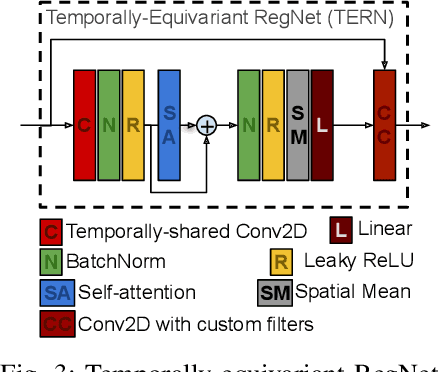
Recent advances have shown how deep neural networks can be extremely effective at super-resolving remote sensing imagery, starting from a multitemporal collection of low-resolution images. However, existing models have neglected the issue of temporal permutation, whereby the temporal ordering of the input images does not carry any relevant information for the super-resolution task and causes such models to be inefficient with the, often scarce, ground truth data that available for training. Thus, models ought not to learn feature extractors that rely on temporal ordering. In this paper, we show how building a model that is fully invariant to temporal permutation significantly improves performance and data efficiency. Moreover, we study how to quantify the uncertainty of the super-resolved image so that the final user is informed on the local quality of the product. We show how uncertainty correlates with temporal variation in the series, and how quantifying it further improves model performance. Experiments on the Proba-V challenge dataset show significant improvements over the state of the art without the need for self-ensembling, as well as improved data efficiency, reaching the performance of the challenge winner with just 25% of the training data.
Joint Activity Detection and Data Decoding in Massive Random Access via a Turbo Receiver
Apr 26, 2021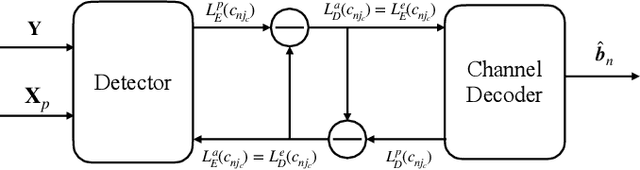
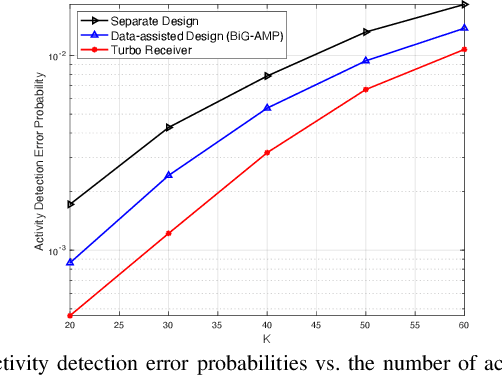
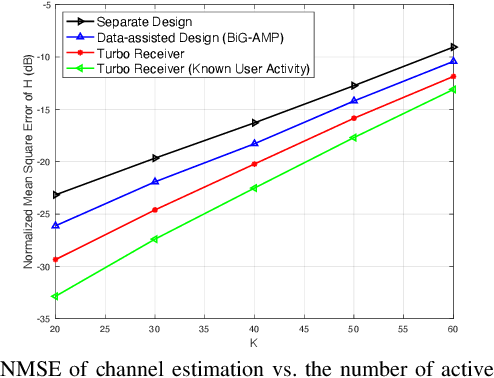
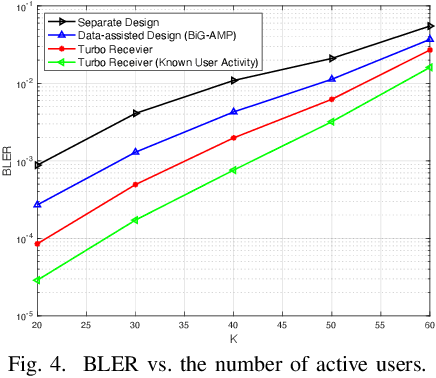
In this paper, we propose a turbo receiver for joint activity detection and data decoding in grant-free massive random access, which iterates between a detector and a belief propagation (BP)-based channel decoder. Specifically, responsible for user activity detection, channel estimation and soft data symbol detection, the detector is developed based on a bilinear inference problem that exploits the common sparsity pattern in the received pilot and data signals. The bilinear generalized approximate message passing (BiG-AMP) algorithm is adopted to solve the problem using probabilities of the transmitted data symbols estimated by the channel decoder as prior knowledge. In addition, extrinsic information is also derived from the detector to improve the channel decoding accuracy in the decoder. Simulation results show significant improvements achieved by the proposed turbo receiver compared with conventional designs.
Global Attention for Name Tagging
Oct 19, 2020
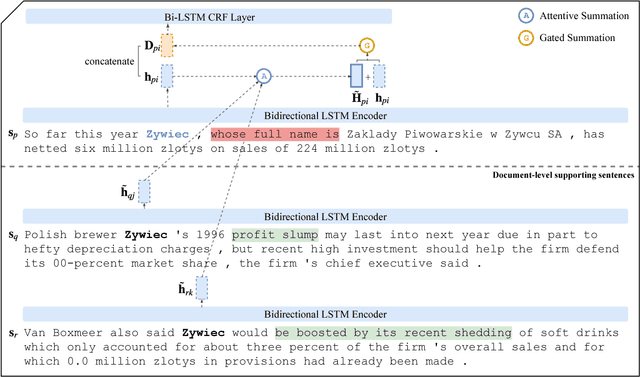
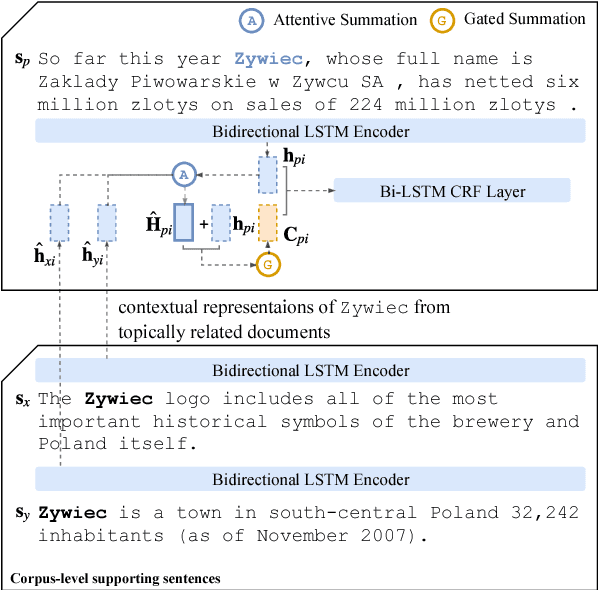
Many name tagging approaches use local contextual information with much success, but fail when the local context is ambiguous or limited. We present a new framework to improve name tagging by utilizing local, document-level, and corpus-level contextual information. We retrieve document-level context from other sentences within the same document and corpus-level context from sentences in other topically related documents. We propose a model that learns to incorporate document-level and corpus-level contextual information alongside local contextual information via global attentions, which dynamically weight their respective contextual information, and gating mechanisms, which determine the influence of this information. Extensive experiments on benchmark datasets show the effectiveness of our approach, which achieves state-of-the-art results for Dutch, German, and Spanish on the CoNLL-2002 and CoNLL-2003 datasets.
Towards Faithfulness in Open Domain Table-to-text Generation from an Entity-centric View
Feb 17, 2021
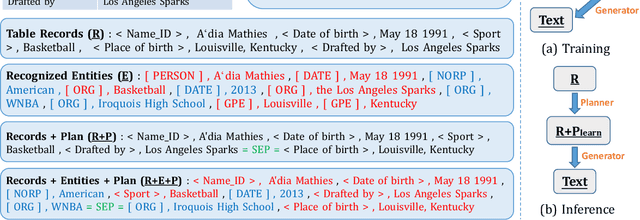
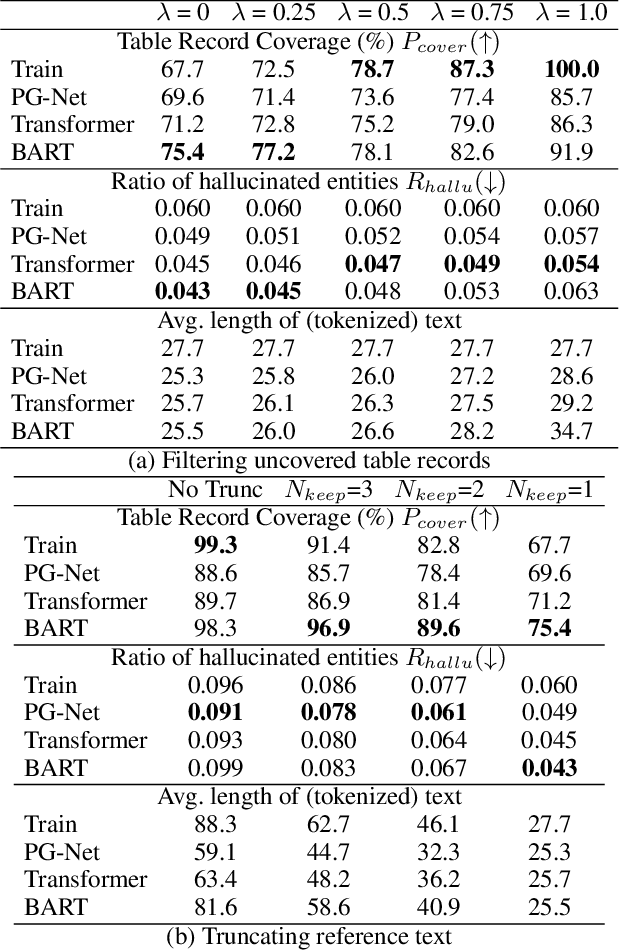
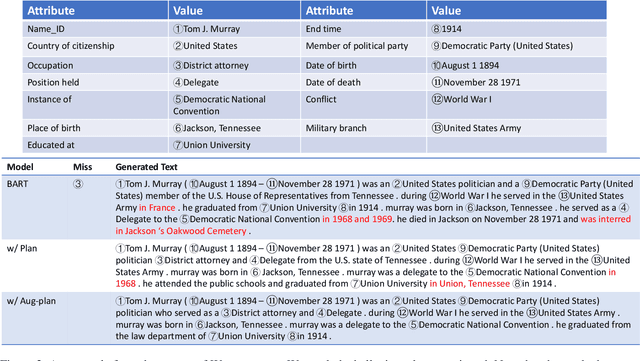
In open domain table-to-text generation, we notice that the unfaithful generation usually contains hallucinated content which can not be aligned to any input table record. We thus try to evaluate the generation faithfulness with two entity-centric metrics: table record coverage and the ratio of hallucinated entities in text, both of which are shown to have strong agreement with human judgements. Then based on these metrics, we quantitatively analyze the correlation between training data quality and generation fidelity which indicates the potential usage of entity information in faithful generation. Motivated by these findings, we propose two methods for faithful generation: 1) augmented training by incorporating the auxiliary entity information, including both an augmented plan-based model and an unsupervised model and 2) training instance selection based on faithfulness ranking. We show these approaches improve generation fidelity in both full dataset setting and few shot learning settings by both automatic and human evaluations.
Quotient Space-Based Keyword Retrieval in Sponsored Search
May 26, 2021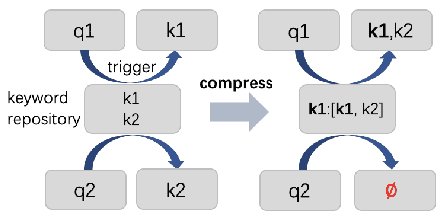
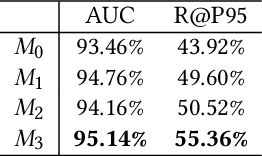
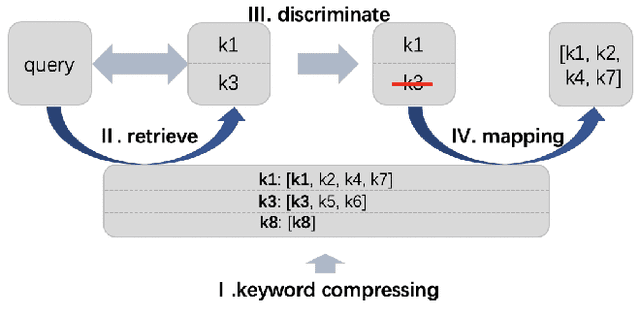
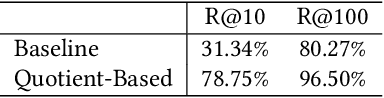
Synonymous keyword retrieval has become an important problem for sponsored search ever since major search engines relax the exact match product's matching requirement to a synonymous level. Since the synonymous relations between queries and keywords are quite scarce, the traditional information retrieval framework is inefficient in this scenario. In this paper, we propose a novel quotient space-based retrieval framework to address this problem. Considering the synonymy among keywords as a mathematical equivalence relation, we can compress the synonymous keywords into one representative, and the corresponding quotient space would greatly reduce the size of the keyword repository. Then an embedding-based retrieval is directly conducted between queries and the keyword representatives. To mitigate the semantic gap of the quotient space-based retrieval, a single semantic siamese model is utilized to detect both the keyword--keyword and query-keyword synonymous relations. The experiments show that with our quotient space-based retrieval method, the synonymous keyword retrieving performance can be greatly improved in terms of memory cost and recall efficiency. This method has been successfully implemented in Baidu's online sponsored search system and has yielded a significant improvement in revenue.
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 26, 2021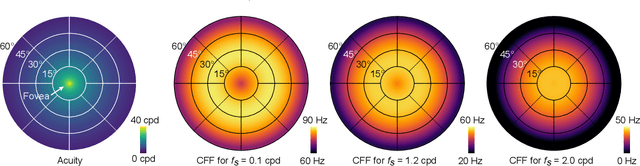
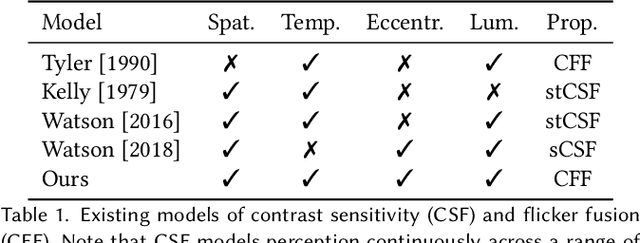

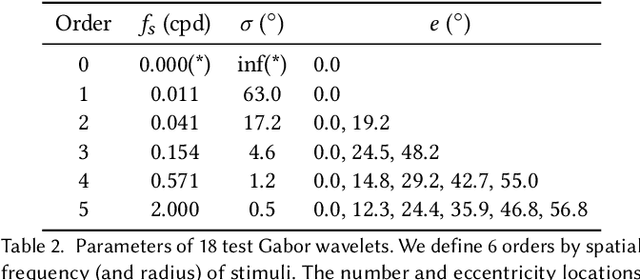
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Zorro: Valid, Sparse, and Stable Explanations in Graph Neural Networks
May 18, 2021
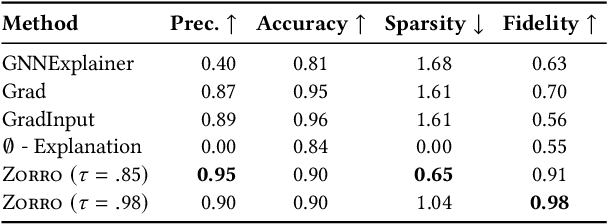
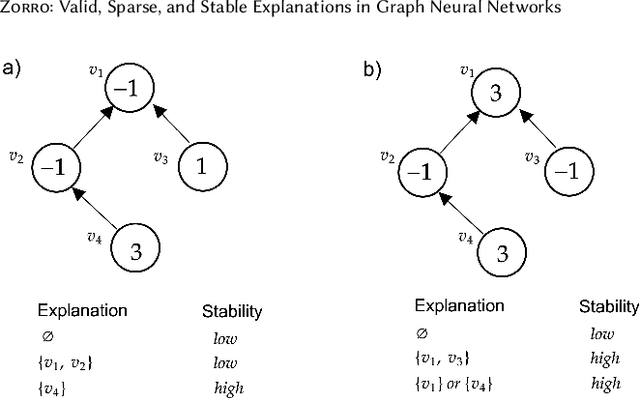
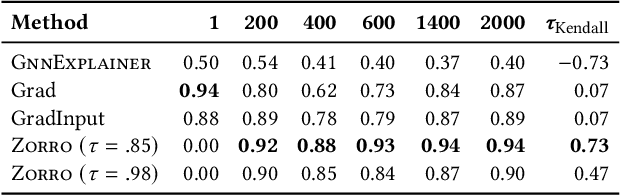
With the ever-increasing popularity and applications of graph neural networks, several proposals have been made to interpret and understand the decisions of a GNN model. Explanations for a GNN model differ in principle from other input settings. It is important to attribute the decision to input features and other related instances connected by the graph structure. We find that the previous explanation generation approaches that maximize the mutual information between the label distribution produced by the GNN model and the explanation to be restrictive. Specifically, existing approaches do not enforce explanations to be predictive, sparse, or robust to input perturbations. In this paper, we lay down some of the fundamental principles that an explanation method for GNNs should follow and introduce a metric fidelity as a measure of the explanation's effectiveness. We propose a novel approach Zorro based on the principles from rate-distortion theory that uses a simple combinatorial procedure to optimize for fidelity. Extensive experiments on real and synthetic datasets reveal that Zorro produces sparser, stable, and more faithful explanations than existing GNN explanation approaches.
Model selection by minimum description length: Lower-bound sample sizes for the Fisher information approximation
Aug 01, 2018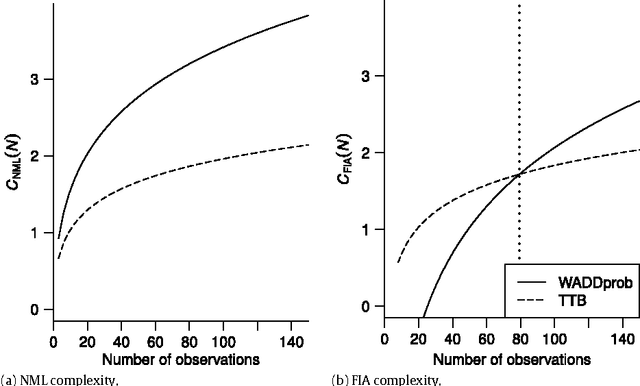
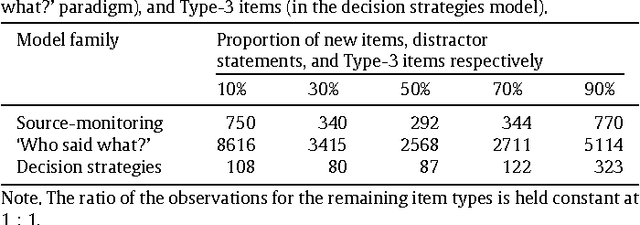
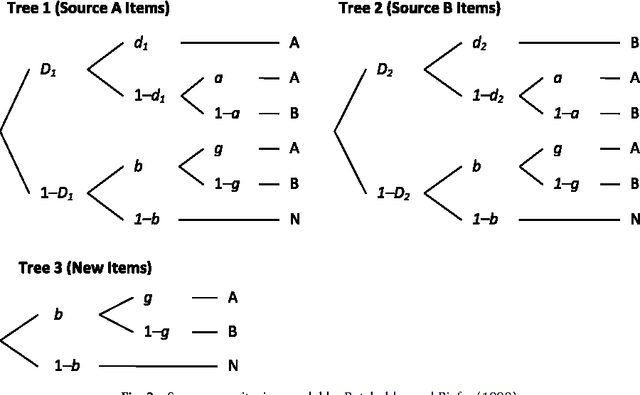
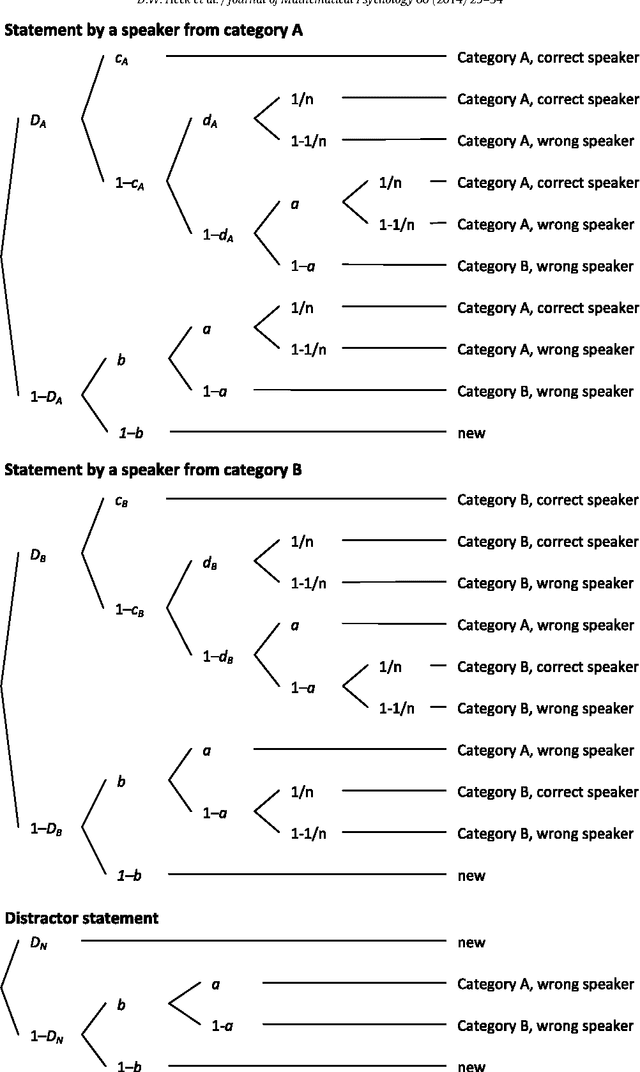
The Fisher information approximation (FIA) is an implementation of the minimum description length principle for model selection. Unlike information criteria such as AIC or BIC, it has the advantage of taking the functional form of a model into account. Unfortunately, FIA can be misleading in finite samples, resulting in an inversion of the correct rank order of complexity terms for competing models in the worst case. As a remedy, we propose a lower-bound $N'$ for the sample size that suffices to preclude such errors. We illustrate the approach using three examples from the family of multinomial processing tree models.