 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LSG-CPD: Coherent Point Drift with Local Surface Geometry for Point Cloud Registration
Mar 28, 2021
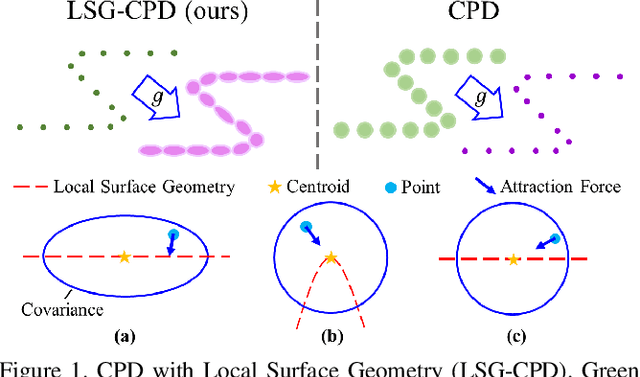
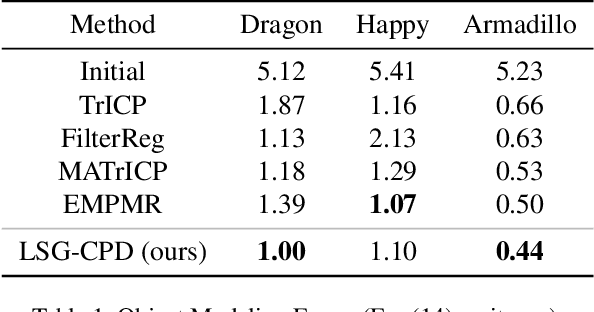
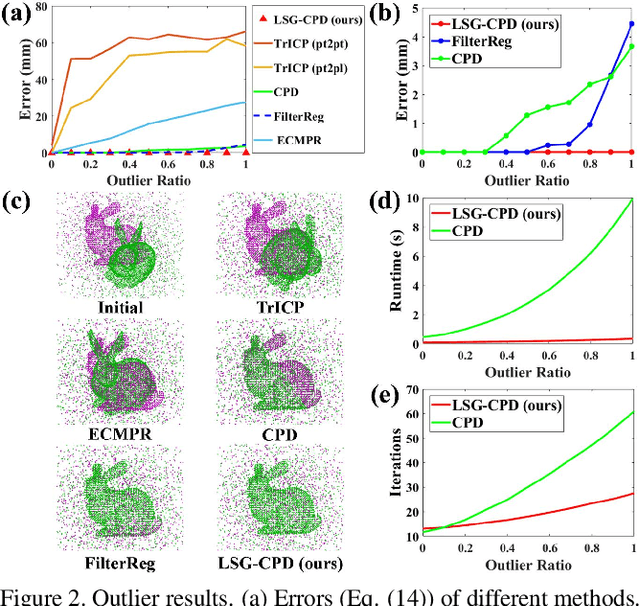
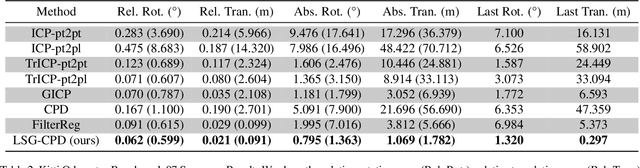
Probabilistic point cloud registration methods are becoming more popular because of their robustness. However, unlike point-to-plane variants of iterative closest point (ICP) which incorporate local surface geometric information such as surface normals, most probabilistic methods (e.g., coherent point drift (CPD)) ignore such information and build Gaussian mixture models (GMMs) with isotropic Gaussian covariances. This results in sphere-like GMM components which only penalize the point-to-point distance between the two point clouds. In this paper, we propose a novel method called CPD with Local Surface Geometry (LSG-CPD) for rigid point cloud registration. Our method adaptively adds different levels of point-to-plane penalization on top of the point-to-point penalization based on the flatness of the local surface. This results in GMM components with anisotropic covariances. We formulate point cloud registration as a maximum likelihood estimation (MLE) problem and solve it with the Expectation-Maximization (EM) algorithm. In the E step, we demonstrate that the computation can be recast into simple matrix manipulations and efficiently computed on a GPU. In the M step, we perform an unconstrained optimization on a matrix Lie group to efficiently update the rigid transformation of the registration. The proposed method outperforms state-of-the-art algorithms in terms of accuracy and robustness on various datasets captured with range scanners, RGBD cameras, and LiDARs. Also, it is significantly faster than modern implementations of CPD. The code will be released.
Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark
May 06, 2021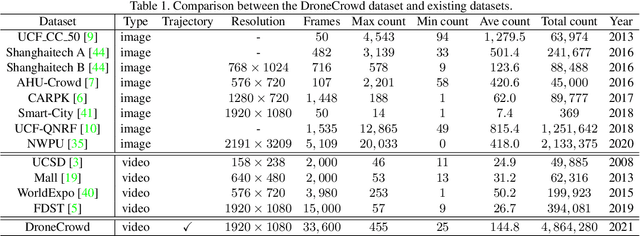

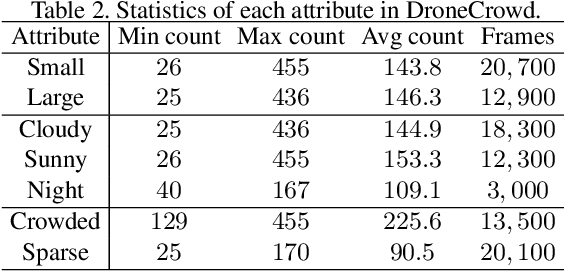
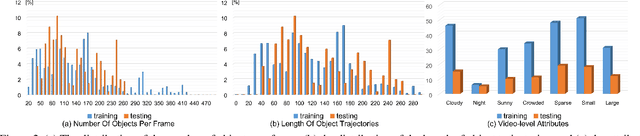
To promote the developments of object detection, tracking and counting algorithms in drone-captured videos, we construct a benchmark with a new drone-captured largescale dataset, named as DroneCrowd, formed by 112 video clips with 33,600 HD frames in various scenarios. Notably, we annotate 20,800 people trajectories with 4.8 million heads and several video-level attributes. Meanwhile, we design the Space-Time Neighbor-Aware Network (STNNet) as a strong baseline to solve object detection, tracking and counting jointly in dense crowds. STNNet is formed by the feature extraction module, followed by the density map estimation heads, and localization and association subnets. To exploit the context information of neighboring objects, we design the neighboring context loss to guide the association subnet training, which enforces consistent relative position of nearby objects in temporal domain. Extensive experiments on our DroneCrowd dataset demonstrate that STNNet performs favorably against the state-of-the-arts.
DBNet: A Dual-branch Network Architecture Processing on Spectrum and Waveform for Single-channel Speech Enhancement
May 06, 2021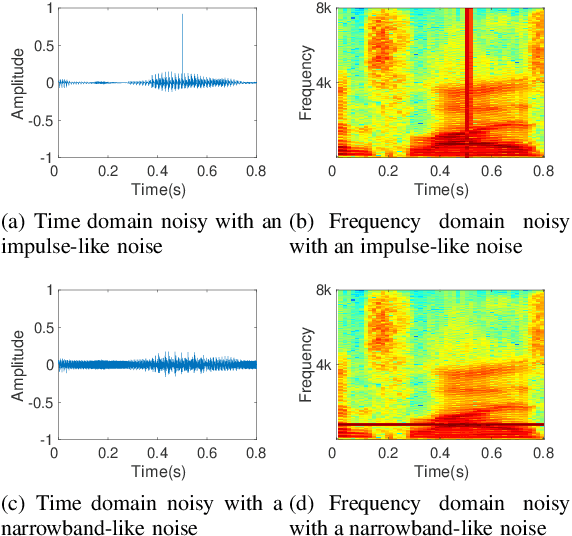
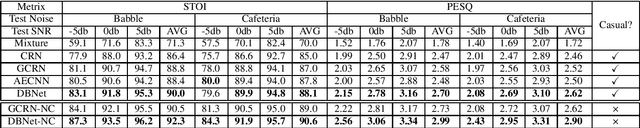
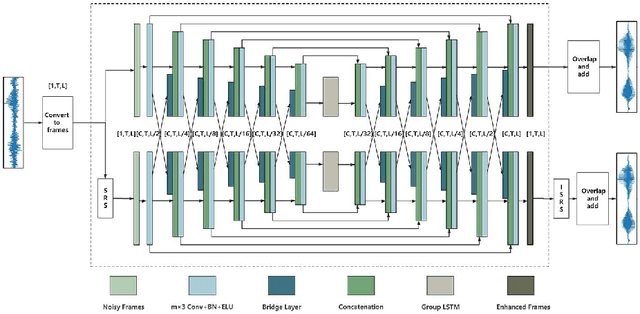

In real acoustic environment, speech enhancement is an arduous task to improve the quality and intelligibility of speech interfered by background noise and reverberation. Over the past years, deep learning has shown great potential on speech enhancement. In this paper, we propose a novel real-time framework called DBNet which is a dual-branch structure with alternate interconnection. Each branch incorporates an encoder-decoder architecture with skip connections. The two branches are responsible for spectrum and waveform modeling, respectively. A bridge layer is adopted to exchange information between the two branches. Systematic evaluation and comparison show that the proposed system substantially outperforms related algorithms under very challenging environments. And in INTERSPEECH 2021 Deep Noise Suppression (DNS) challenge, the proposed system ranks the top 8 in real-time track 1 in terms of the Mean Opinion Score (MOS) of the ITU-T P.835 framework.
Ellipsoidal Trust Region Methods and the Marginal Value of Hessian Information for Neural Network Training
May 22, 2019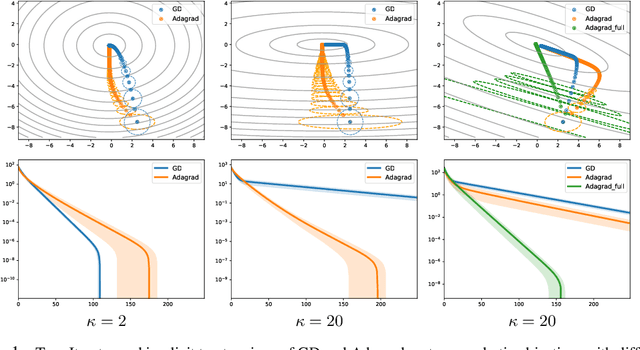

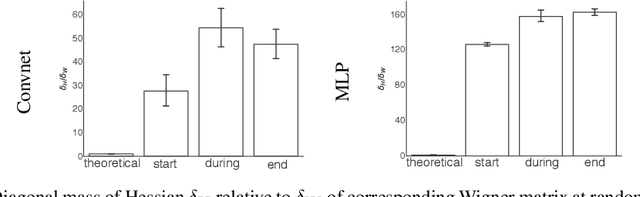
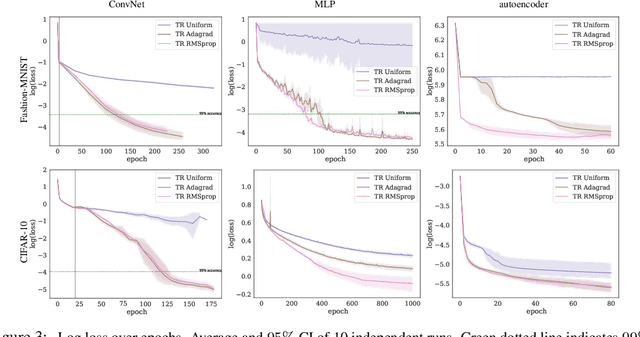
We investigate the use of ellipsoidal trust region constraints for second-order optimization of neural networks. This approach can be seen as a higher-order counterpart of adaptive gradient methods, which we here show to be interpretable as first-order trust region methods with ellipsoidal constraints. In particular, we show that the preconditioning matrix used in RMSProp and Adam satisfies the necessary conditions for convergence of (first- and) second-order trust region methods and report that this ellipsoidal constraint constantly outperforms its spherical counterpart in practice. We furthermore set out to clarify the long-standing question of the potential superiority of Newton methods in deep learning. In this regard, we run extensive benchmarks across different datasets and architectures to find that comparable performance to gradient descent algorithms can be achieved but using Hessian information does not give rise to better limit points and comes at the cost of increased hyperparameter tuning.
Information-theoretic Limits for Community Detection in Network Models
May 22, 2018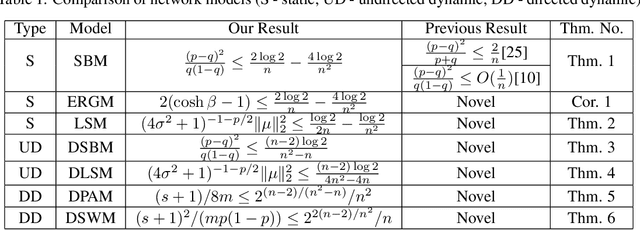
We analyze the information-theoretic limits for the recovery of node labels in several network models. This includes the Stochastic Block Model, the Exponential Random Graph Model, the Latent Space Model, the Directed Preferential Attachment Model, and the Directed Small-world Model. For the Stochastic Block Model, the non-recoverability condition depends on the probabilities of having edges inside a community, and between different communities. For the Latent Space Model, the non-recoverability condition depends on the dimension of the latent space, and how far and spread are the communities in the latent space. For the Directed Preferential Attachment Model and the Directed Small-world Model, the non-recoverability condition depends on the ratio between homophily and neighborhood size. We also consider dynamic versions of the Stochastic Block Model and the Latent Space Model.
Are Top School Students More Critical of Their Professors? Mining Comments on RateMyProfessor.com
Jan 23, 2021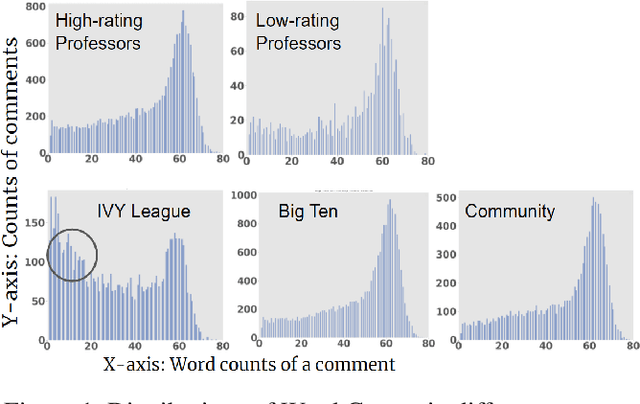
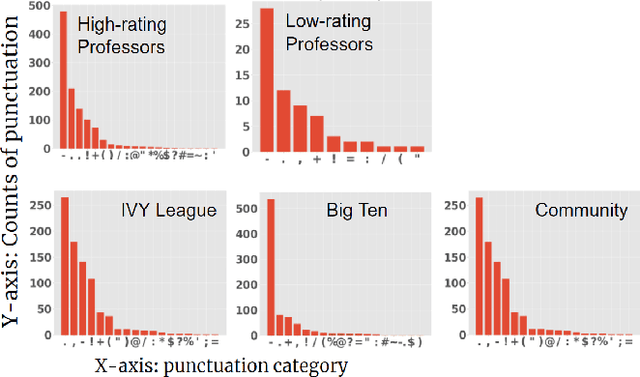
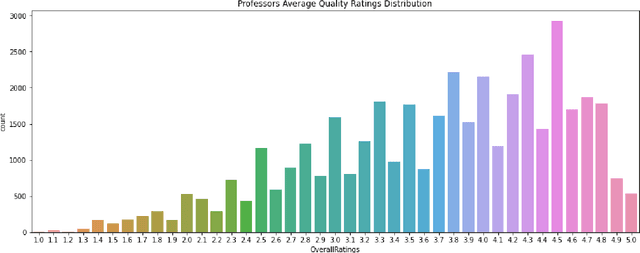
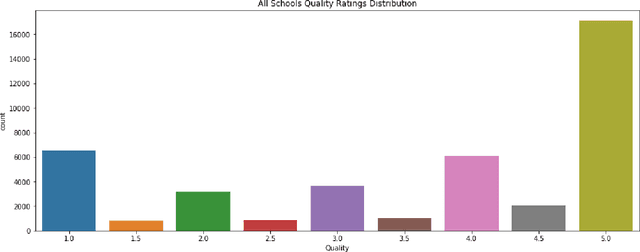
Student reviews and comments on RateMyProfessor.com reflect realistic learning experiences of students. Such information provides a large-scale data source to examine the teaching quality of the lecturers. In this paper, we propose an in-depth analysis of these comments. First, we partition our data into different comparison groups. Next, we perform exploratory data analysis to delve into the data. Furthermore, we employ Latent Dirichlet Allocation and sentiment analysis to extract topics and understand the sentiments associated with the comments. We uncover interesting insights about the characteristics of both college students and professors. Our study proves that student reviews and comments contain crucial information and can serve as essential references for enrollment in courses and universities.
Automatic 2D-3D Registration without Contrast Agent during Neurovascular Interventions
Jun 08, 2021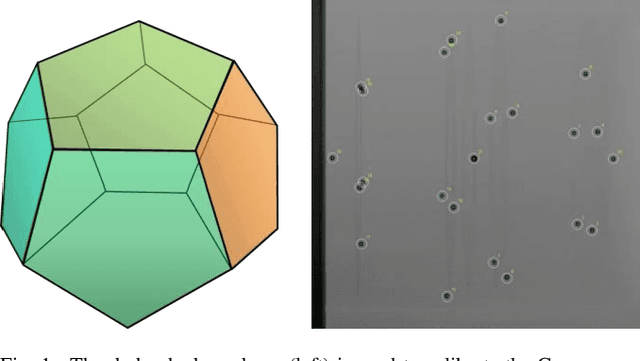
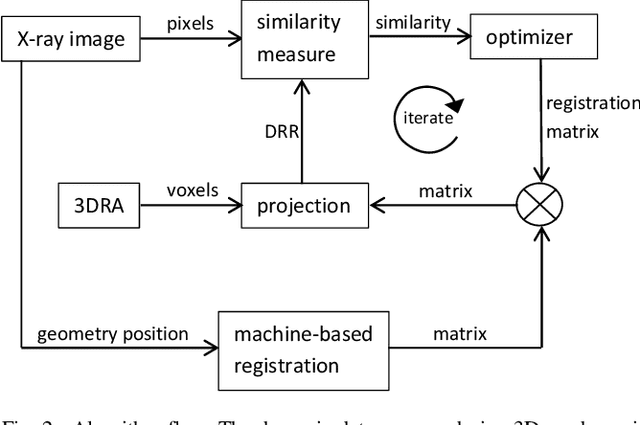
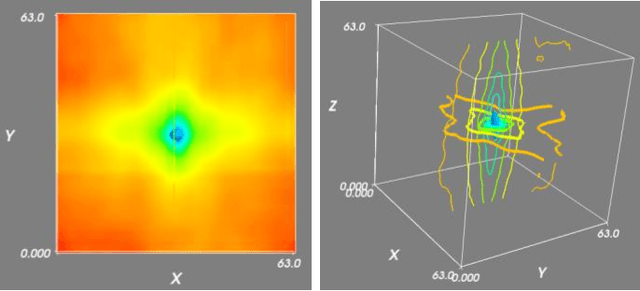
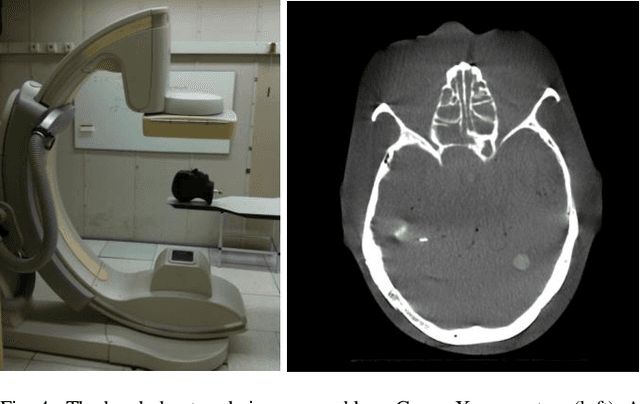
Fusing live fluoroscopy images with a 3D rotational reconstruction of the vasculature allows to navigate endovascular devices in minimally invasive neuro-vascular treatment, while reducing the usage of harmful iodine contrast medium. The alignment of the fluoroscopy images and the 3D reconstruction is initialized using the sensor information of the X-ray C-arm geometry. Patient motion is then corrected by an image-based registration algorithm, based on a gradient difference similarity measure using digital reconstructed radiographs of the 3D reconstruction. This algorithm does not require the vessels in the fluoroscopy image to be filled with iodine contrast agent, but rather relies on gradients in the image (bone structures, sinuses) as landmark features. This paper investigates the accuracy, robustness and computation time aspects of the image-based registration algorithm. Using phantom experiments 97% of the registration attempts passed the success criterion of a residual registration error of less than 1 mm translation and 3{\deg} rotation. The paper establishes a new method for validation of 2D-3D registration without requiring changes to the clinical workflow, such as attaching fiducial markers. As a consequence, this method can be retrospectively applied to pre-existing clinical data. For clinical data experiments, 87% of the registration attempts passed the criterion of a residual translational error of < 1 mm, and 84% possessed a rotational error of < 3{\deg}.
Towards Robust Neural Retrieval Models with Synthetic Pre-Training
Apr 15, 2021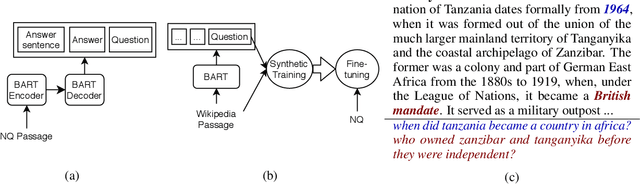


Recent work has shown that commonly available machine reading comprehension (MRC) datasets can be used to train high-performance neural information retrieval (IR) systems. However, the evaluation of neural IR has so far been limited to standard supervised learning settings, where they have outperformed traditional term matching baselines. We conduct in-domain and out-of-domain evaluations of neural IR, and seek to improve its robustness across different scenarios, including zero-shot settings. We show that synthetic training examples generated using a sequence-to-sequence generator can be effective towards this goal: in our experiments, pre-training with synthetic examples improves retrieval performance in both in-domain and out-of-domain evaluation on five different test sets.
Navigating A Mobile Robot Using Switching Distributed Sensor Networks
Jun 25, 2021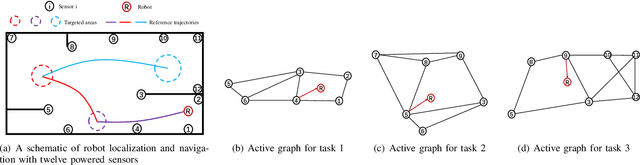
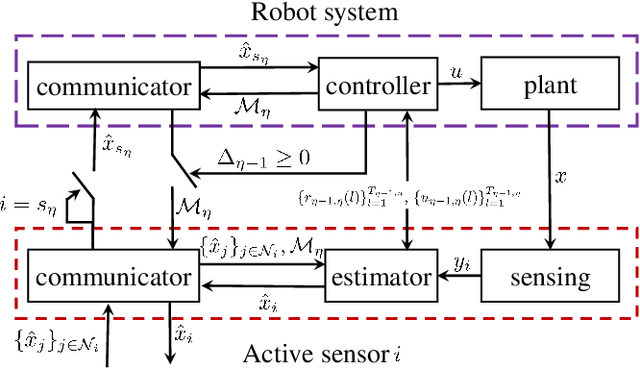
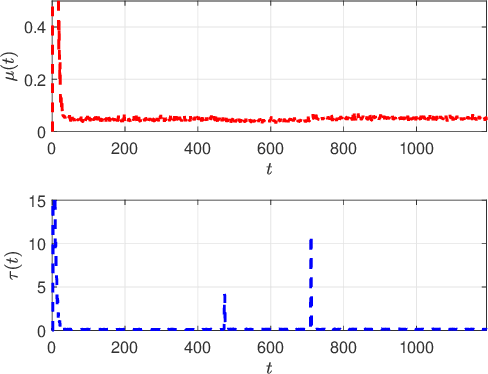
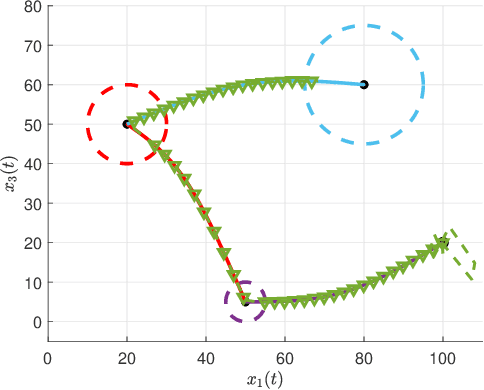
This paper proposes a method to navigate a mobile robot by estimating its state over a number of distributed sensor networks (DSNs) such that it can successively accomplish a sequence of tasks, i.e., its state enters each targeted set and stays inside no less than the desired time, under a resource-aware, time-efficient, and computation- and communication-constrained setting.We propose a new robot state estimation and navigation architecture, which integrates an event-triggered task-switching feedback controller for the robot and a two-time-scale distributed state estimator for each sensor. The architecture has three major advantages over existing approaches: First, in each task only one DSN is active for sensing and estimating the robot state, and for different tasks the robot can switch the active DSN by taking resource saving and system performance into account; Second, the robot only needs to communicate with one active sensor at each time to obtain its state information from the active DSN; Third, no online optimization is required. With the controller, the robot is able to accomplish a task by following a reference trajectory and switch to the next task when an event-triggered condition is fulfilled. With the estimator, each active sensor is able to estimate the robot state. Under proper conditions, we prove that the state estimation error and the trajectory tracking deviation are upper bounded by two time-varying sequences respectively, which play an essential role in the event-triggered condition. Furthermore, we find a sufficient condition for accomplishing a task and provide an upper bound of running time for the task. Numerical simulations of an indoor robot's localization and navigation are provided to validate the proposed architecture.
Visual Grounding with Transformers
May 10, 2021
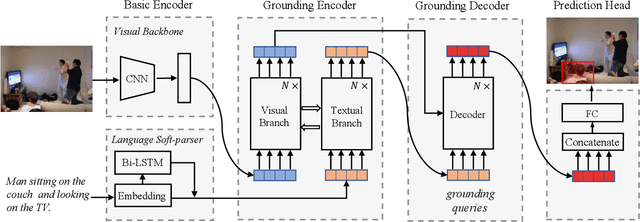
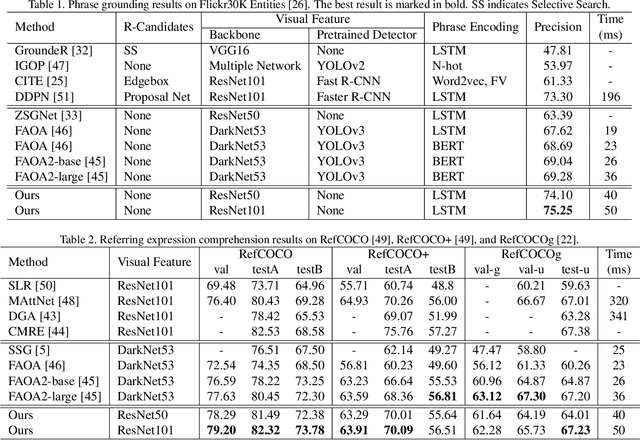
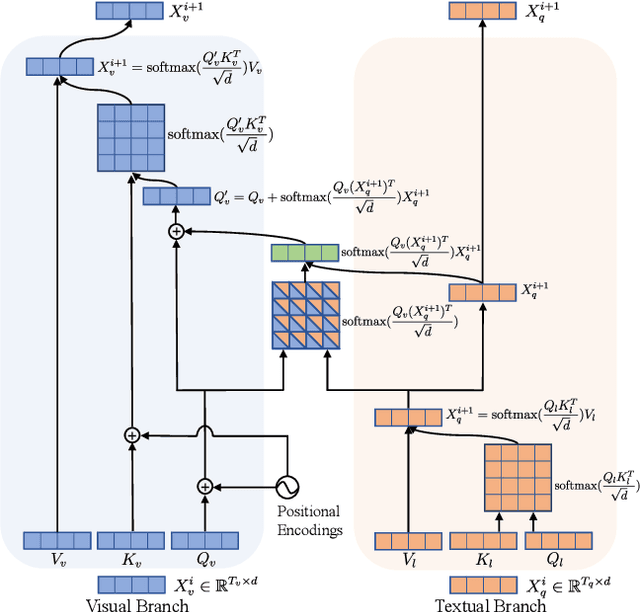
In this paper, we propose a transformer based approach for visual grounding. Unlike previous proposal-and-rank frameworks that rely heavily on pretrained object detectors or proposal-free frameworks that upgrade an off-the-shelf one-stage detector by fusing textual embeddings, our approach is built on top of a transformer encoder-decoder and is independent of any pretrained detectors or word embedding models. Termed VGTR -- Visual Grounding with TRansformers, our approach is designed to learn semantic-discriminative visual features under the guidance of the textual description without harming their location ability. This information flow enables our VGTR to have a strong capability in capturing context-level semantics of both vision and language modalities, rendering us to aggregate accurate visual clues implied by the description to locate the interested object instance. Experiments show that our method outperforms state-of-the-art proposal-free approaches by a considerable margin on five benchmarks while maintaining fast inference speed.