 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TA&AT: Enhancing Task-Oriented Dialog with Turn-Level Auxiliary Tasks and Action-Tree Based Scheduled Sampling
Jan 28, 2024
Task-oriented dialog systems have witnessed substantial progress due to conversational pre-training techniques. Yet, two significant challenges persist. First, most systems primarily utilize the latest turn's state label for the generator. This practice overlooks the comprehensive value of state labels in boosting the model's understanding for future generations. Second, an overreliance on generated policy often leads to error accumulation, resulting in suboptimal responses when adhering to incorrect actions. To combat these challenges, we propose turn-level multi-task objectives for the encoder. With the guidance of essential information from labeled intermediate states, we establish a more robust representation for both understanding and generation. For the decoder, we introduce an action tree-based scheduled sampling technique. Specifically, we model the hierarchical policy as trees and utilize the similarity between trees to sample negative policy based on scheduled sampling, hoping the model to generate invariant responses under perturbations. This method simulates potential pitfalls by sampling similar negative policy, bridging the gap between task-oriented dialog training and inference. Among methods without continual pre-training, our approach achieved state-of-the-art (SOTA) performance on the MultiWOZ dataset series and was also competitive with pre-trained SOTA methods.
Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Jan 28, 2024Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments, which will be pseudo-labels. With these pseudo-labels as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several VideoQA benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
Harnessing Network Effect for Fake News Mitigation: Selecting Debunkers via Self-Imitation Learning
Jan 28, 2024This study aims to minimize the influence of fake news on social networks by deploying debunkers to propagate true news. This is framed as a reinforcement learning problem, where, at each stage, one user is selected to propagate true news. A challenging issue is episodic reward where the "net" effect of selecting individual debunkers cannot be discerned from the interleaving information propagation on social networks, and only the collective effect from mitigation efforts can be observed. Existing Self-Imitation Learning (SIL) methods have shown promise in learning from episodic rewards, but are ill-suited to the real-world application of fake news mitigation because of their poor sample efficiency. To learn a more effective debunker selection policy for fake news mitigation, this study proposes NAGASIL - Negative sampling and state Augmented Generative Adversarial Self-Imitation Learning, which consists of two improvements geared towards fake news mitigation: learning from negative samples, and an augmented state representation to capture the "real" environment state by integrating the current observed state with the previous state-action pairs from the same campaign. Experiments on two social networks show that NAGASIL yields superior performance to standard GASIL and state-of-the-art fake news mitigation models.
Do Not (Always) Look Right: Investigating the Capabilities of Decoder-Based Large Language Models for Sequence Labeling
Jan 25, 2024Pre-trained language models based on masked language modeling (MLM) objective excel in natural language understanding (NLU) tasks. While fine-tuned MLM-based encoders consistently outperform causal language modeling decoders of comparable size, a recent trend of scaling decoder models to multiple billion parameters resulted in large language models (LLMs), making them competitive with MLM-based encoders. Although scale amplifies their prowess in NLU tasks, LLMs fall short of SOTA results in information extraction (IE) tasks, many framed as sequence labeling (SL). However, whether this is an intrinsic limitation of LLMs or whether their SL performance can be improved remains unclear. To address this, we explore strategies to enhance the SL performance of "open" LLMs (Llama2 and Mistral) on IE tasks. We investigate bidirectional information flow within groups of decoder blocks, applying layer-wise removal or enforcement of the causal mask (CM) during LLM fine-tuning. This approach yields performance gains competitive with SOTA SL models, matching or outperforming the results of CM removal from all blocks. Our findings hold for diverse SL tasks, proving that "open" LLMs with layer-dependent CM removal outperform strong MLM-based encoders and instruction-tuned LLMs. However, we observe no effect from CM removal on a small scale when maintaining an equivalent model size, pre-training steps, and pre-training and fine-tuning data.
Norm Enforcement with a Soft Touch: Faster Emergence, Happier Agents
Jan 29, 2024A multiagent system can be viewed as a society of autonomous agents, whose interactions can be effectively regulated via social norms. In general, the norms of a society are not hardcoded but emerge from the agents' interactions. Specifically, how the agents in a society react to each other's behavior and respond to the reactions of others determines which norms emerge in the society. We think of these reactions by an agent to the satisfactory or unsatisfactory behaviors of another agent as communications from the first agent to the second agent. Understanding these communications is a kind of social intelligence: these communications provide natural drivers for norm emergence by pushing agents toward certain behaviors, which can become established as norms. Whereas it is well-known that sanctioning can lead to the emergence of norms, we posit that a broader kind of social intelligence can prove more effective in promoting cooperation in a multiagent system. Accordingly, we develop Nest, a framework that models social intelligence in the form of a wider variety of communications and understanding of them than in previous work. To evaluate Nest, we develop a simulated pandemic environment and conduct simulation experiments to compare Nest with baselines considering a combination of three kinds of social communication: sanction, tell, and hint. We find that societies formed of Nest agents achieve norms faster; moreover, Nest agents effectively avoid undesirable consequences, which are negative sanctions and deviation from goals, and yield higher satisfaction for themselves than baseline agents despite requiring only an equivalent amount of information.
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, ASR Error Detection, and ASR Error Correction
Jan 24, 2024The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1\%.
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Dec 24, 2023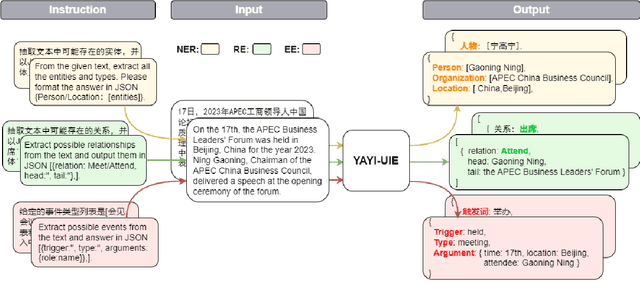
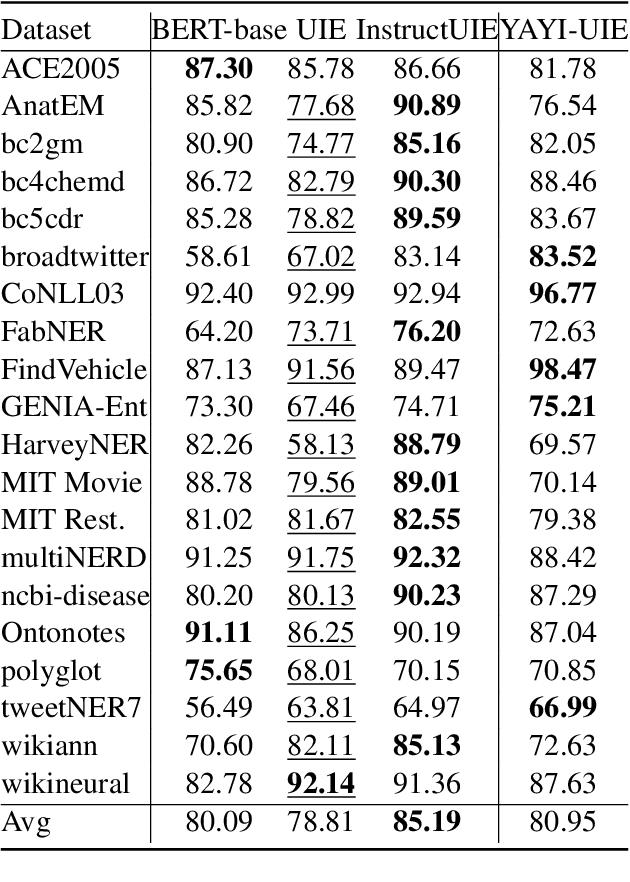
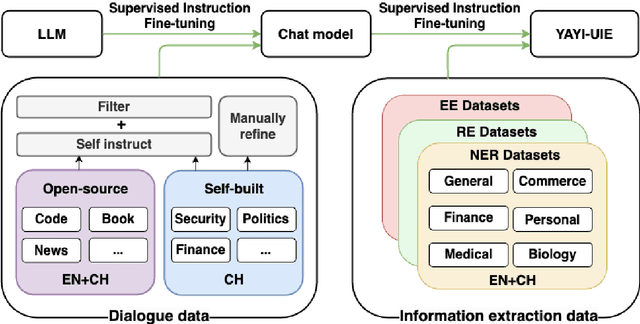
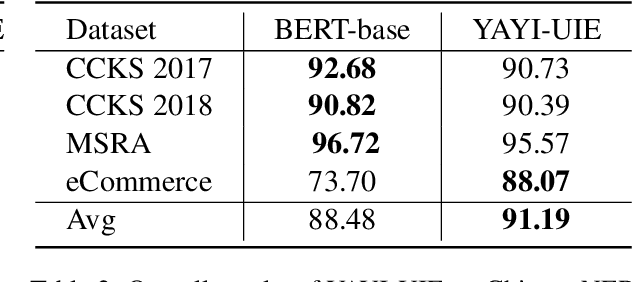
The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.
Iterated Relevance Matrix Analysis (IRMA) for the identification of class-discriminative subspaces
Jan 23, 2024We introduce and investigate the iterated application of Generalized Matrix Learning Vector Quantizaton for the analysis of feature relevances in classification problems, as well as for the construction of class-discriminative subspaces. The suggested Iterated Relevance Matrix Analysis (IRMA) identifies a linear subspace representing the classification specific information of the considered data sets using Generalized Matrix Learning Vector Quantization (GMLVQ). By iteratively determining a new discriminative subspace while projecting out all previously identified ones, a combined subspace carrying all class-specific information can be found. This facilitates a detailed analysis of feature relevances, and enables improved low-dimensional representations and visualizations of labeled data sets. Additionally, the IRMA-based class-discriminative subspace can be used for dimensionality reduction and the training of robust classifiers with potentially improved performance.
ConvoSense: Overcoming Monotonous Commonsense Inferences for Conversational AI
Jan 27, 2024Mastering commonsense understanding and reasoning is a pivotal skill essential for conducting engaging conversations. While there have been several attempts to create datasets that facilitate commonsense inferences in dialogue contexts, existing datasets tend to lack in-depth details, restate information already present in the conversation, and often fail to capture the multifaceted nature of commonsense reasoning. In response to these limitations, we compile a new synthetic dataset for commonsense reasoning in dialogue contexts using GPT, ConvoSense, that boasts greater contextual novelty, offers a higher volume of inferences per example, and substantially enriches the detail conveyed by the inferences. Our dataset contains over 500,000 inferences across 12,000 dialogues with 10 popular inference types, which empowers the training of generative commonsense models for dialogue that are superior in producing plausible inferences with high novelty when compared to models trained on the previous datasets. To the best of our knowledge, ConvoSense is the first of its kind to provide such a multitude of novel inferences at such a large scale.
Gaussian Splashing: Dynamic Fluid Synthesis with Gaussian Splatting
Jan 27, 2024We demonstrate the feasibility of integrating physics-based animations of solids and fluids with 3D Gaussian Splatting (3DGS) to create novel effects in virtual scenes reconstructed using 3DGS. Leveraging the coherence of the Gaussian splatting and position-based dynamics (PBD) in the underlying representation, we manage rendering, view synthesis, and the dynamics of solids and fluids in a cohesive manner. Similar to Gaussian shader, we enhance each Gaussian kernel with an added normal, aligning the kernel's orientation with the surface normal to refine the PBD simulation. This approach effectively eliminates spiky noises that arise from rotational deformation in solids. It also allows us to integrate physically based rendering to augment the dynamic surface reflections on fluids. Consequently, our framework is capable of realistically reproducing surface highlights on dynamic fluids and facilitating interactions between scene objects and fluids from new views. For more information, please visit our project page at \url{https://amysteriouscat.github.io/GaussianSplashing/}.