 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Design principles for a hybrid intelligence decision support system for business model validation
May 07, 2021
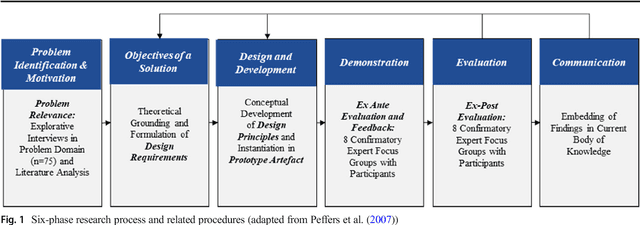
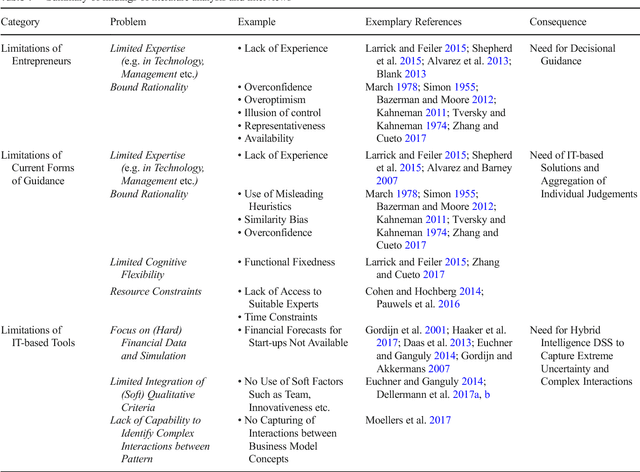
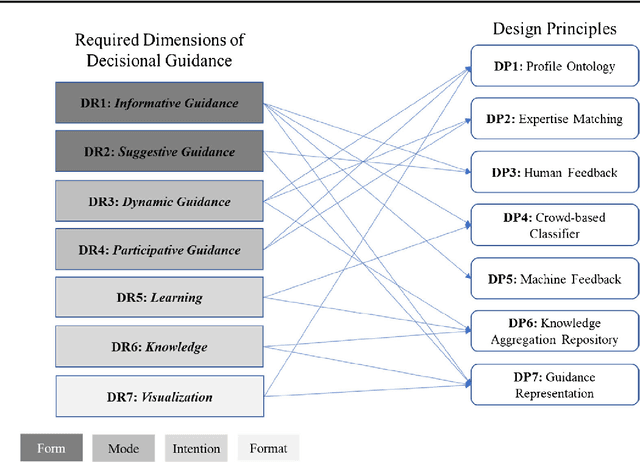
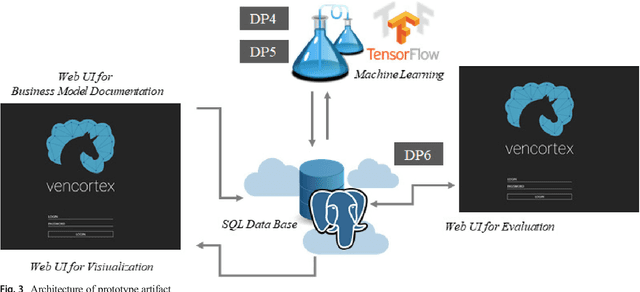
One of the most critical tasks for startups is to validate their business model. Therefore, entrepreneurs try to collect information such as feedback from other actors to assess the validity of their assumptions and make decisions. However, previous work on decisional guidance for business model validation provides no solution for the highly uncertain and complex context of earlystage startups. The purpose of this paper is, thus, to develop design principles for a Hybrid Intelligence decision support system (HI-DSS) that combines the complementary capabilities of human and machine intelligence. We follow a design science research approach to design a prototype artifact and a set of design principles. Our study provides prescriptive knowledge for HI-DSS and contributes to previous work on decision support for business models, the applications of complementary strengths of humans and machines for making decisions, and support systems for extremely uncertain decision-making problems.
Exploring Instance Relations for Unsupervised Feature Embedding
May 07, 2021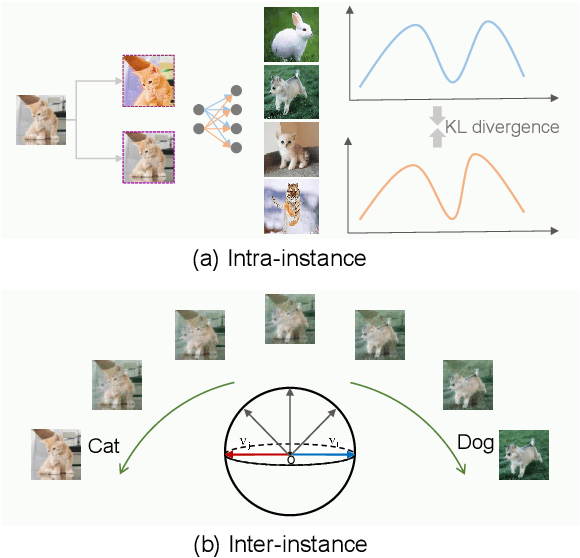
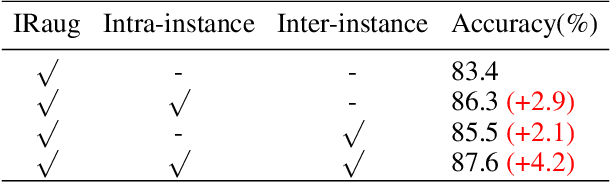
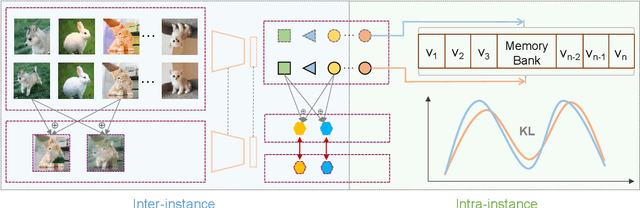
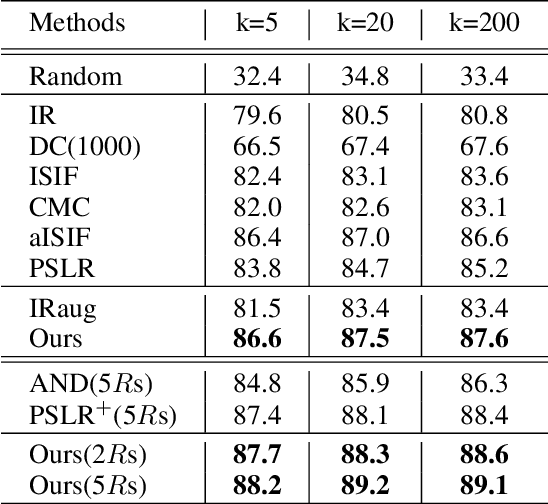
Despite the great progress achieved in unsupervised feature embedding, existing contrastive learning methods typically pursue view-invariant representations through attracting positive sample pairs and repelling negative sample pairs in the embedding space, while neglecting to systematically explore instance relations. In this paper, we explore instance relations including intra-instance multi-view relation and inter-instance interpolation relation for unsupervised feature embedding. Specifically, we embed intra-instance multi-view relation by aligning the distribution of the distance between an instance's different augmented samples and negative samples. We explore inter-instance interpolation relation by transferring the ratio of information for image sample interpolation from pixel space to feature embedding space. The proposed approach, referred to as EIR, is simple-yet-effective and can be easily inserted into existing view-invariant contrastive learning based methods. Experiments conducted on public benchmarks for image classification and retrieval report state-of-the-art or comparable performance.
Application of Monte Carlo algorithms to cardiac imaging reconstruction
May 27, 2021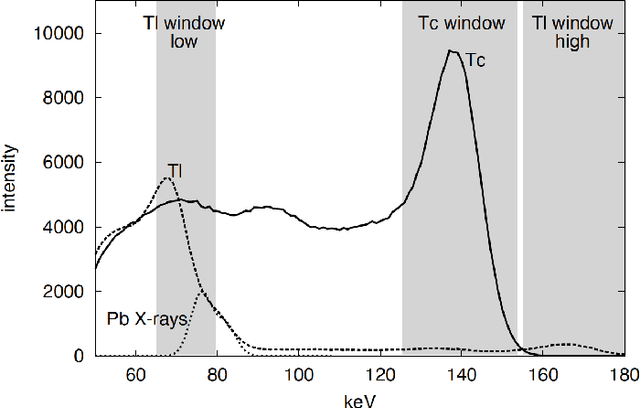
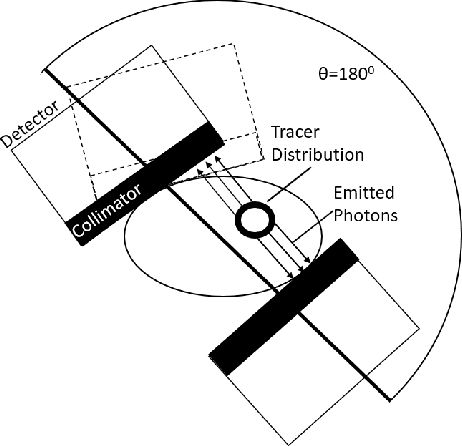
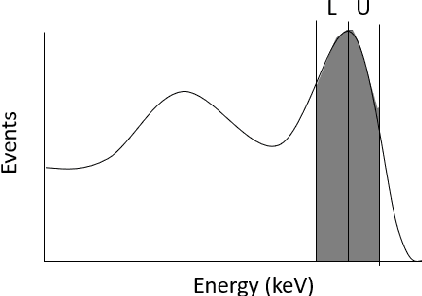
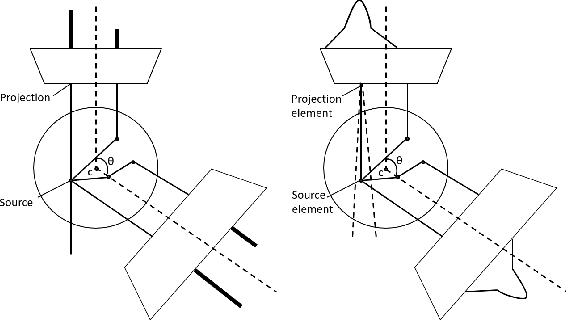
Monte Carlo algorithms have a growing impact on nuclear medicine reconstruction processes. One of the main limitations of myocardial perfusion imaging (MPI) is the effective mitigation of the scattering component, which is particularly challenging in Single Photon Emission Computed Tomography (SPECT). In SPECT, no timing information can be retrieved to locate the primary source photons. Monte Carlo methods allow an event-by-event simulation of the scattering kinematics, which can be incorporated into a model of the imaging system response. This approach was adopted since the late Nineties by several authors, and recently took advantage of the increased computational power made available by high-performance CPUs and GPUs. These recent developments enable a fast image reconstruction with an improved image quality, compared to deterministic approaches. Deterministic approaches are based on energy-windowing of the detector response, and on the cumulative estimate and subtraction of the scattering component. In this paper, we review the main strategies and algorithms to correct for the scattering effect in SPECT and focus on Monte Carlo developments, which nowadays allow the three-dimensional reconstruction of SPECT cardiac images in a few seconds.
Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains
Jun 03, 2021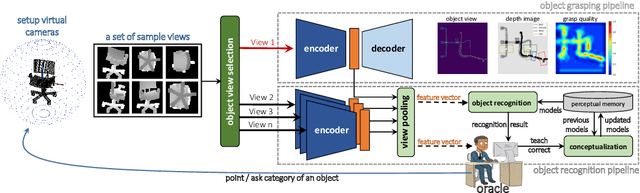
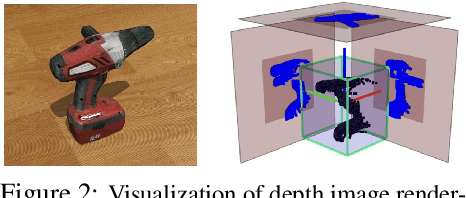
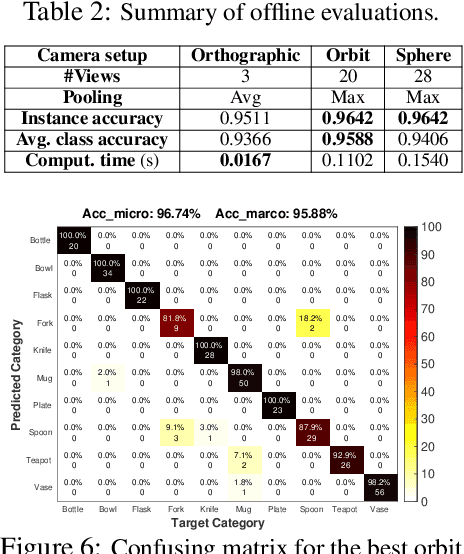
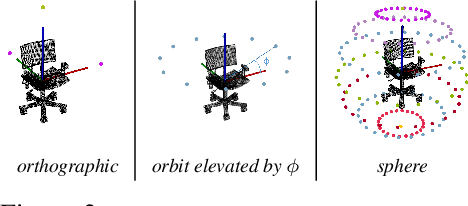
A robot working in human-centric environments needs to know which kind of objects exist in the scene, where they are, and how to grasp and manipulate various objects in different situations to help humans in everyday tasks. Therefore, object recognition and grasping are two key functionalities for such robots. Most state-of-the-art tackles object recognition and grasping as two separate problems while both use visual input. Furthermore, the knowledge of the robot is fixed after the training phase. In such cases, if the robot faces new object categories, it must retrain from scratch to incorporate new information without catastrophic interference. To address this problem, we propose a deep learning architecture with augmented memory capacities to handle open-ended object recognition and grasping simultaneously. In particular, our approach takes multi-views of an object as input and jointly estimates pixel-wise grasp configuration as well as a deep scale- and rotation-invariant representation as outputs. The obtained representation is then used for open-ended object recognition through a meta-active learning technique. We demonstrate the ability of our approach to grasp never-seen-before objects and to rapidly learn new object categories using very few examples on-site in both simulation and real-world settings.
Socially-Aware Self-Supervised Tri-Training for Recommendation
Jun 15, 2021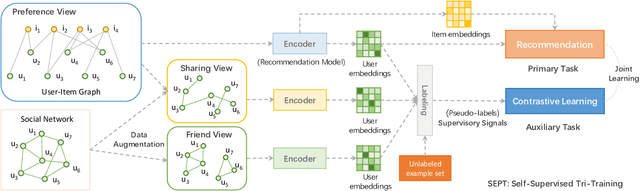
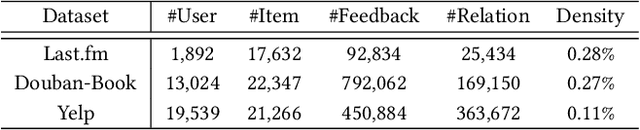
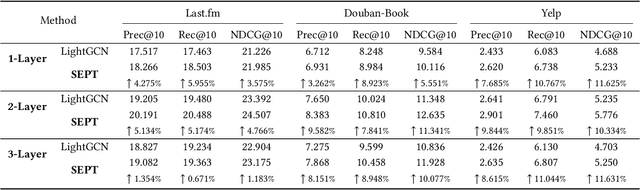
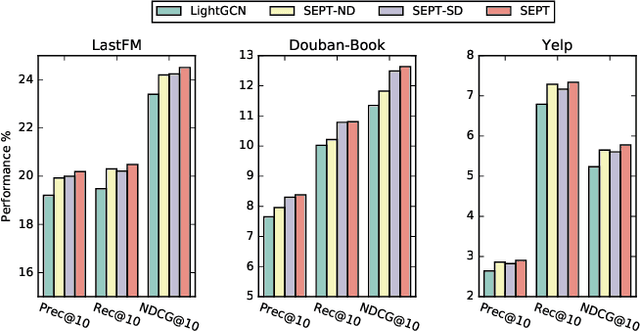
Self-supervised learning (SSL), which can automatically generate ground-truth samples from raw data, holds vast potential to improve recommender systems. Most existing SSL-based methods perturb the raw data graph with uniform node/edge dropout to generate new data views and then conduct the self-discrimination based contrastive learning over different views to learn generalizable representations. Under this scheme, only a bijective mapping is built between nodes in two different views, which means that the self-supervision signals from other nodes are being neglected. Due to the widely observed homophily in recommender systems, we argue that the supervisory signals from other nodes are also highly likely to benefit the representation learning for recommendation. To capture these signals, a general socially-aware SSL framework that integrates tri-training is proposed in this paper. Technically, our framework first augments the user data views with the user social information. And then under the regime of tri-training for multi-view encoding, the framework builds three graph encoders (one for recommendation) upon the augmented views and iteratively improves each encoder with self-supervision signals from other users, generated by the other two encoders. Since the tri-training operates on the augmented views of the same data sources for self-supervision signals, we name it self-supervised tri-training. Extensive experiments on multiple real-world datasets consistently validate the effectiveness of the self-supervised tri-training framework for improving recommendation. The code is released at https://github.com/Coder-Yu/QRec.
IAIA-BL: A Case-based Interpretable Deep Learning Model for Classification of Mass Lesions in Digital Mammography
Mar 23, 2021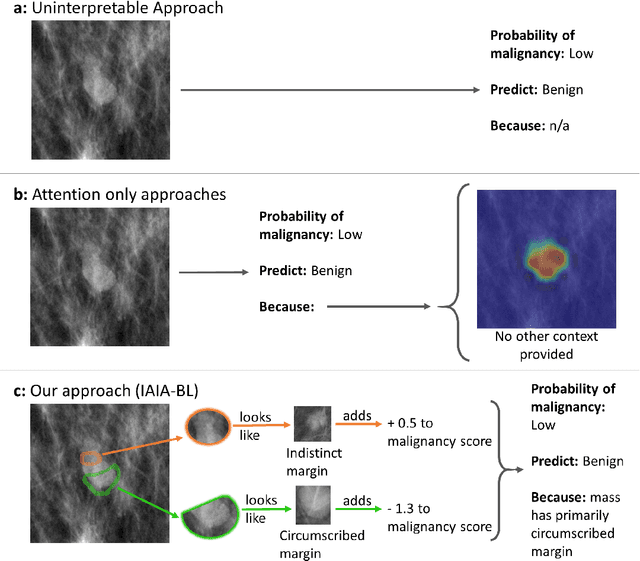
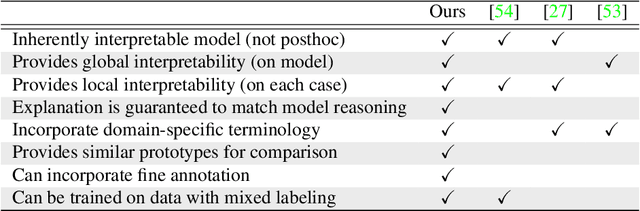
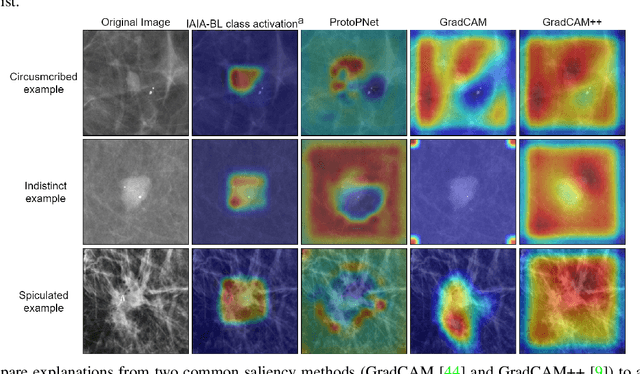
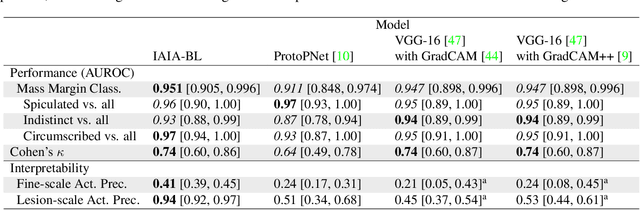
Interpretability in machine learning models is important in high-stakes decisions, such as whether to order a biopsy based on a mammographic exam. Mammography poses important challenges that are not present in other computer vision tasks: datasets are small, confounding information is present, and it can be difficult even for a radiologist to decide between watchful waiting and biopsy based on a mammogram alone. In this work, we present a framework for interpretable machine learning-based mammography. In addition to predicting whether a lesion is malignant or benign, our work aims to follow the reasoning processes of radiologists in detecting clinically relevant semantic features of each image, such as the characteristics of the mass margins. The framework includes a novel interpretable neural network algorithm that uses case-based reasoning for mammography. Our algorithm can incorporate a combination of data with whole image labelling and data with pixel-wise annotations, leading to better accuracy and interpretability even with a small number of images. Our interpretable models are able to highlight the classification-relevant parts of the image, whereas other methods highlight healthy tissue and confounding information. Our models are decision aids, rather than decision makers, aimed at better overall human-machine collaboration. We do not observe a loss in mass margin classification accuracy over a black box neural network trained on the same data.
Optimizing Reusable Knowledge for Continual Learning via Metalearning
Jun 09, 2021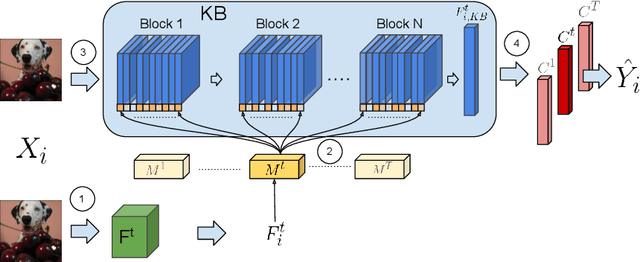
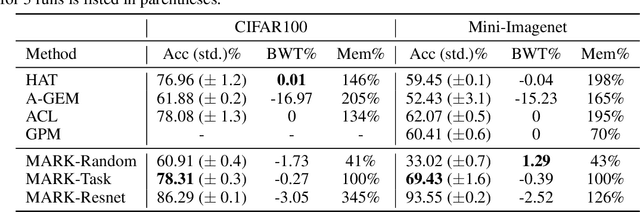
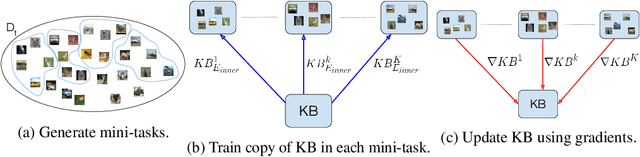
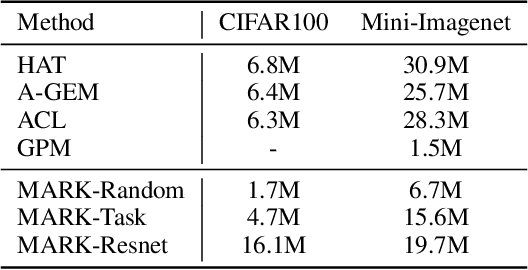
When learning tasks over time, artificial neural networks suffer from a problem known as Catastrophic Forgetting (CF). This happens when the weights of a network are overwritten during the training of a new task causing forgetting of old information. To address this issue, we propose MetA Reusable Knowledge or MARK, a new method that fosters weight reusability instead of overwriting when learning a new task. Specifically, MARK keeps a set of shared weights among tasks. We envision these shared weights as a common Knowledge Base (KB) that is not only used to learn new tasks, but also enriched with new knowledge as the model learns new tasks. Key components behind MARK are two-fold. On the one hand, a metalearning approach provides the key mechanism to incrementally enrich the KB with new knowledge and to foster weight reusability among tasks. On the other hand, a set of trainable masks provides the key mechanism to selectively choose from the KB relevant weights to solve each task. By using MARK, we achieve state of the art results in several popular benchmarks, surpassing the best performing methods in terms of average accuracy by over 10% on the 20-Split-MiniImageNet dataset, while achieving almost zero forgetfulness using 55% of the number of parameters. Furthermore, an ablation study provides evidence that, indeed, MARK is learning reusable knowledge that is selectively used by each task.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Nov 24, 2020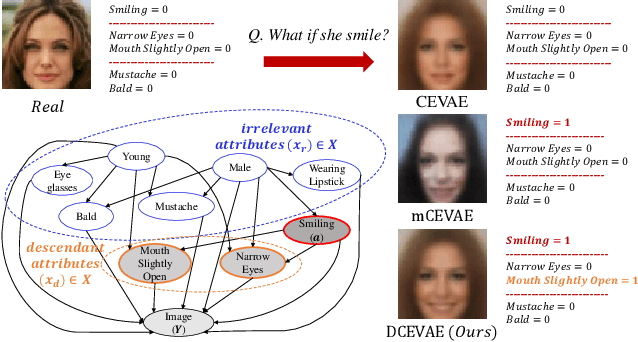
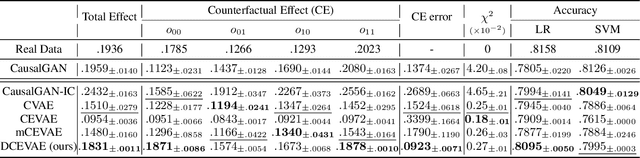
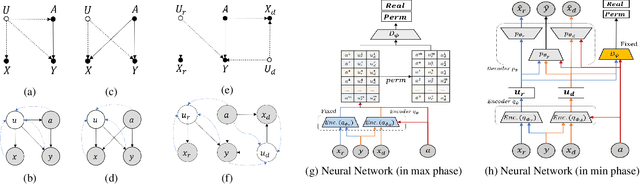
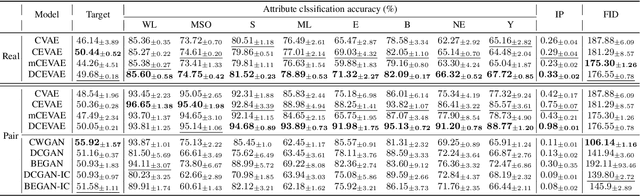
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.
Disentangled Face Attribute Editing via Instance-Aware Latent Space Search
May 27, 2021
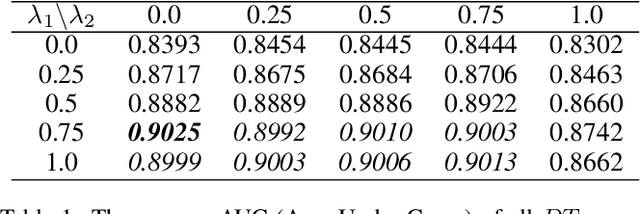
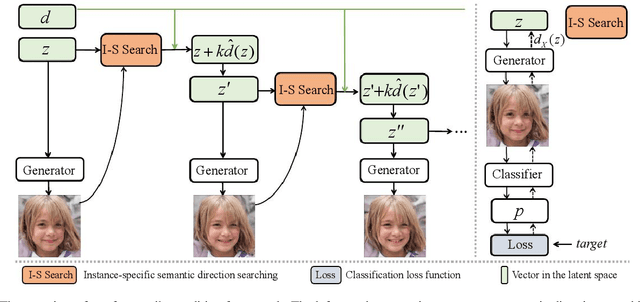

Recent works have shown that a rich set of semantic directions exist in the latent space of Generative Adversarial Networks (GANs), which enables various facial attribute editing applications. However, existing methods may suffer poor attribute variation disentanglement, leading to unwanted change of other attributes when altering the desired one. The semantic directions used by existing methods are at attribute level, which are difficult to model complex attribute correlations, especially in the presence of attribute distribution bias in GAN's training set. In this paper, we propose a novel framework (IALS) that performs Instance-Aware Latent-Space Search to find semantic directions for disentangled attribute editing. The instance information is injected by leveraging the supervision from a set of attribute classifiers evaluated on the input images. We further propose a Disentanglement-Transformation (DT) metric to quantify the attribute transformation and disentanglement efficacy and find the optimal control factor between attribute-level and instance-specific directions based on it. Experimental results on both GAN-generated and real-world images collectively show that our method outperforms state-of-the-art methods proposed recently by a wide margin. Code is available at https://github.com/yxuhan/IALS.
Learning Unknown from Correlations: Graph Neural Network for Inter-novel-protein Interaction Prediction
May 20, 2021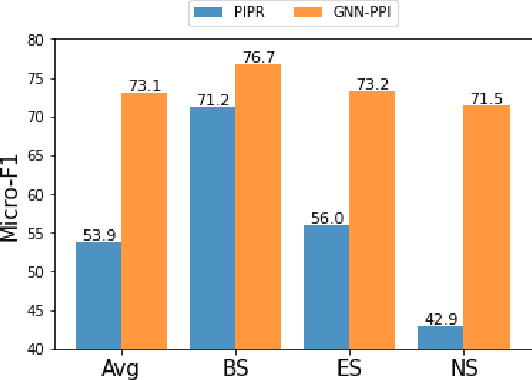
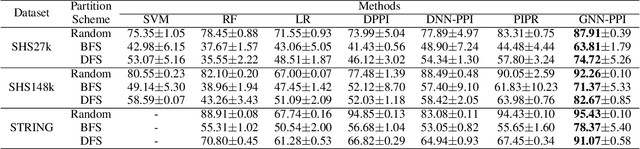
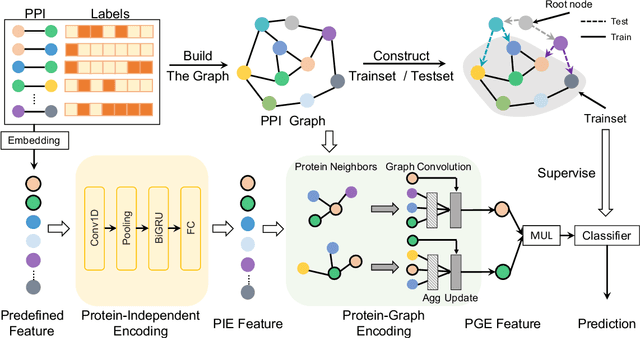
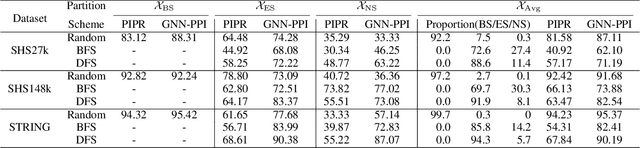
The study of multi-type Protein-Protein Interaction (PPI) is fundamental for understanding biological processes from a systematic perspective and revealing disease mechanisms. Existing methods suffer from significant performance degradation when tested in unseen dataset. In this paper, we investigate the problem and find that it is mainly attributed to the poor performance for inter-novel-protein interaction prediction. However, current evaluations overlook the inter-novel-protein interactions, and thus fail to give an instructive assessment. As a result, we propose to address the problem from both the evaluation and the methodology. Firstly, we design a new evaluation framework that fully respects the inter-novel-protein interactions and gives consistent assessment across datasets. Secondly, we argue that correlations between proteins must provide useful information for analysis of novel proteins, and based on this, we propose a graph neural network based method (GNN-PPI) for better inter-novel-protein interaction prediction. Experimental results on real-world datasets of different scales demonstrate that GNN-PPI significantly outperforms state-of-the-art PPI prediction methods, especially for the inter-novel-protein interaction prediction.