 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Peptipedia: a comprehensive database for peptide research supported by Assembled predictive models and Data Mining approaches
Jan 28, 2021
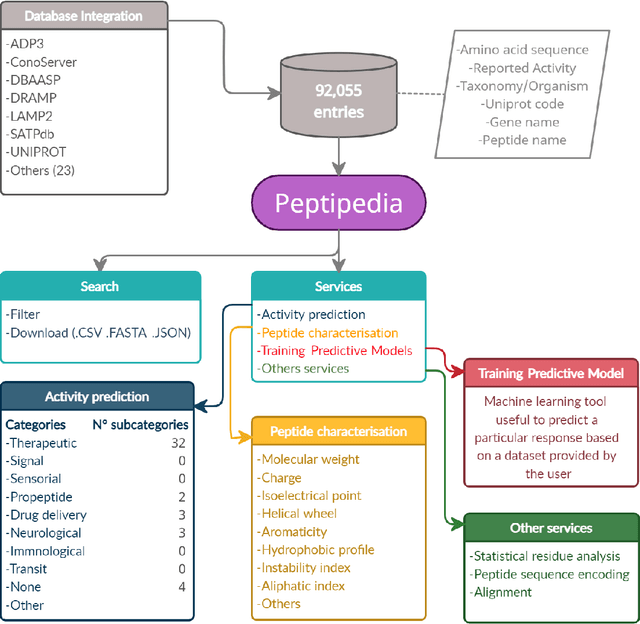
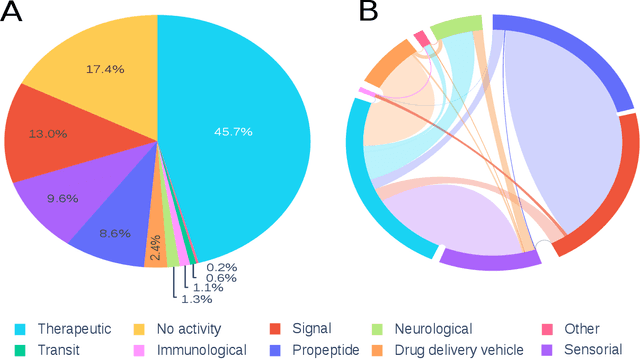
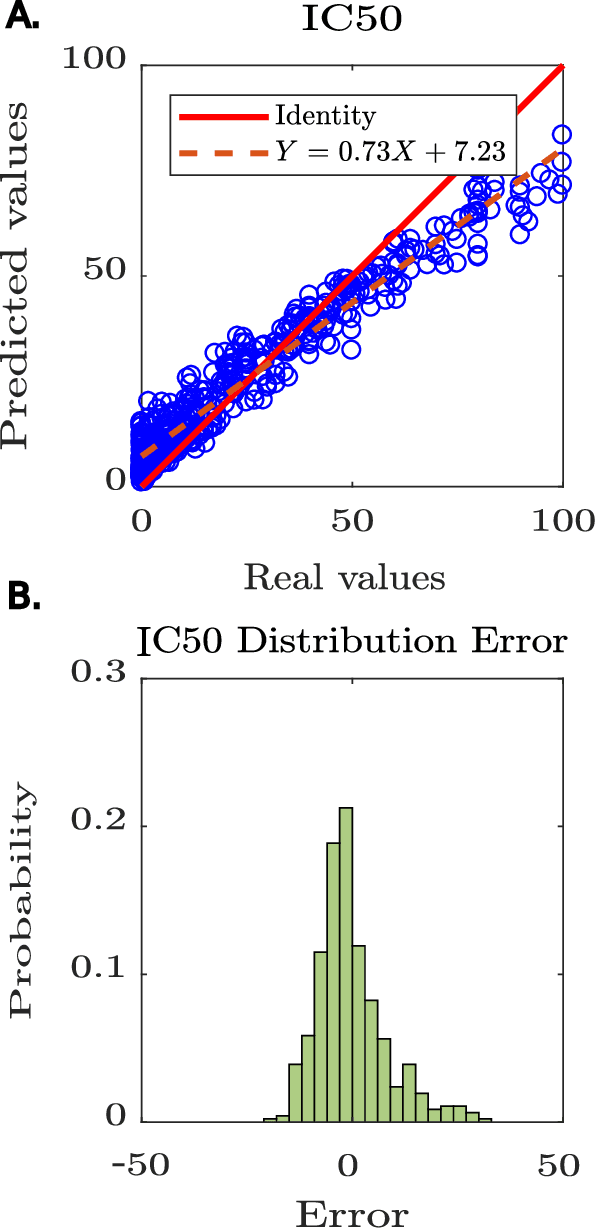
Motivation: Peptides have attracted the attention in this century due to their remarkable therapeutic properties. Computational tools are being developed to take advantage of existing information, encapsulating knowledge and making it available in a simple way for general public use. However, these are property-specific redundant data systems, and usually do not display the data in a clear way. In some cases, information download is not even possible. This data needs to be available in a simple form for drug design and other biotechnological applications. Results: We developed Peptipedia, a user-friendly database and web application to search, characterise and analyse peptide sequences. Our tool integrates the information from thirty previously reported databases, making it the largest repository of peptides with recorded activities so far. Besides, we implemented a variety of services to increase our tool's usability. The significant differences of our tools with other existing alternatives becomes a substantial contribution to develop biotechnological and bioengineering applications for peptides. Availability: Peptipedia is available for non-commercial use as an open-access software, licensed under the GNU General Public License, version GPL 3.0. The web platform is publicly available at pesb2.cl/peptipedia. Both the source code and sample datasets are available in the GitHub repository https://github.com/CristoferQ/PeptideDatabase. Contact: david.medina@cebib.cl, ana.sanchez@ing.uchile.cl
Feedback Coding for Active Learning
Feb 28, 2021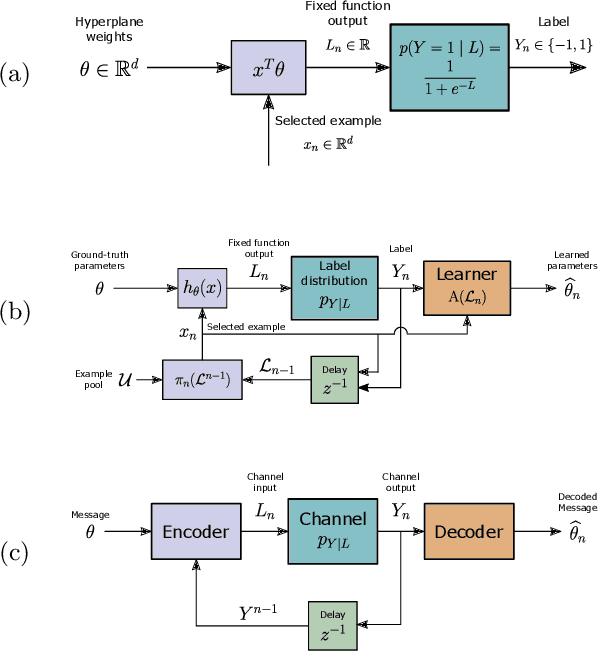
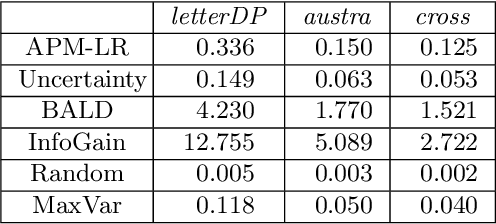
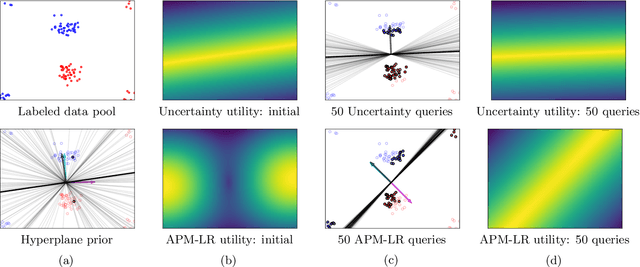
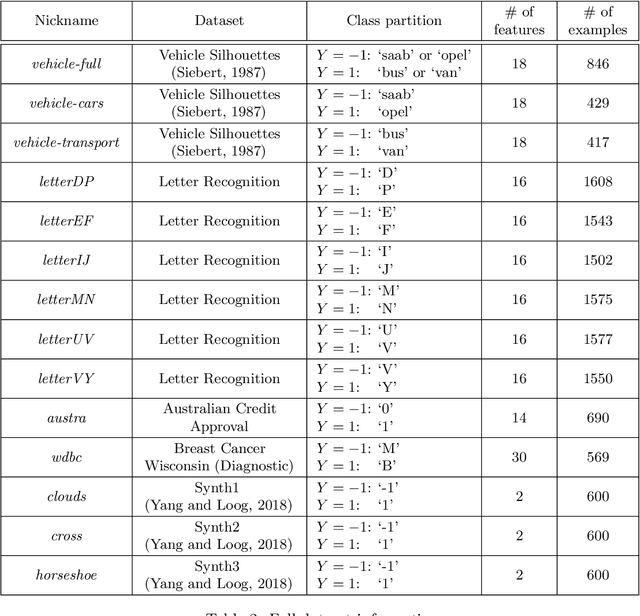
The iterative selection of examples for labeling in active machine learning is conceptually similar to feedback channel coding in information theory: in both tasks, the objective is to seek a minimal sequence of actions to encode information in the presence of noise. While this high-level overlap has been previously noted, there remain open questions on how to best formulate active learning as a communications system to leverage existing analysis and algorithms in feedback coding. In this work, we formally identify and leverage the structural commonalities between the two problems, including the characterization of encoder and noisy channel components, to design a new algorithm. Specifically, we develop an optimal transport-based feedback coding scheme called Approximate Posterior Matching (APM) for the task of active example selection and explore its application to Bayesian logistic regression, a popular model in active learning. We evaluate APM on a variety of datasets and demonstrate learning performance comparable to existing active learning methods, at a reduced computational cost. These results demonstrate the potential of directly deploying concepts from feedback channel coding to design efficient active learning strategies.
The Online Pivot: Lessons Learned from Teaching a Text and Data Mining Course in Lockdown, Enhancing online Teaching with Pair Programming and Digital Badges
May 03, 2021

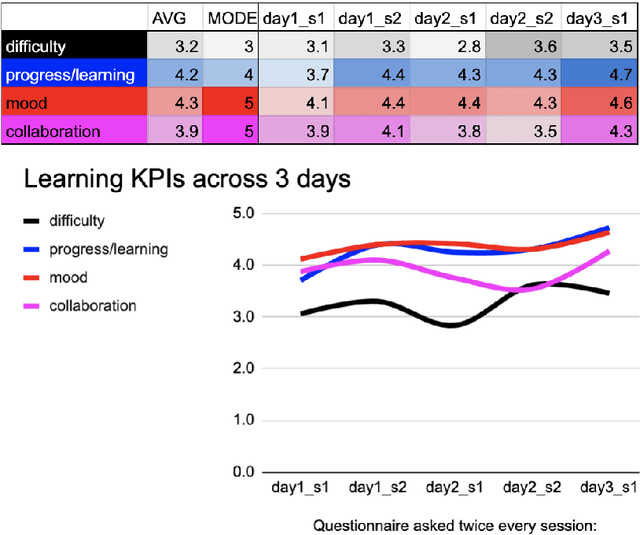

In this paper we provide an account of how we ported a text and data mining course online in summer 2020 as a result of the COVID-19 pandemic and how we improved it in a second pilot run. We describe the course, how we adapted it over the two pilot runs and what teaching techniques we used to improve students' learning and community building online. We also provide information on the relentless feedback collected during the course which helped us to adapt our teaching from one session to the next and one pilot to the next. We discuss the lessons learned and promote the use of innovative teaching techniques applied to the digital such as digital badges and pair programming in break-out rooms for teaching Natural Language Processing courses to beginners and students with different backgrounds.
Detection of Clouds in Multiple Wind Velocity Fields using Ground-based Infrared Sky Images
Jun 03, 2021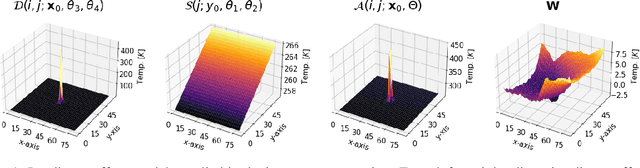
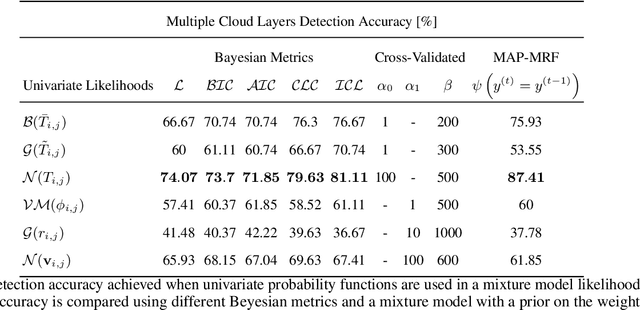
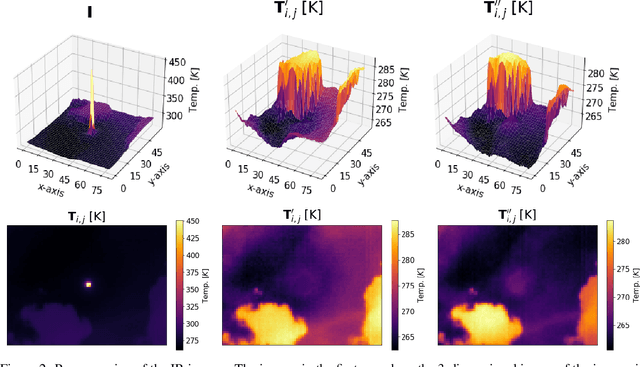
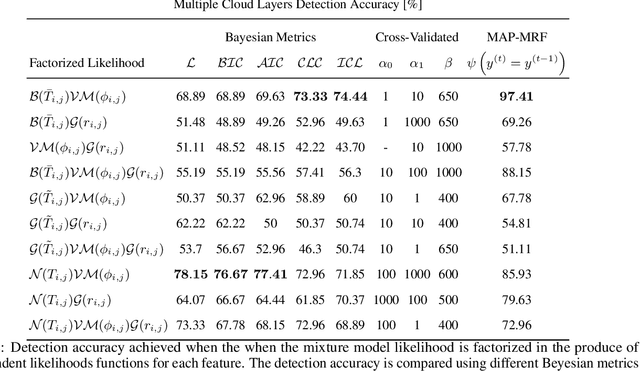
Horizontal atmospheric wind shear causes wind velocity fields to have different directions and speeds. In images of clouds acquired using ground-based sky imagers, clouds may be moving in different wind layers. To increase the performance of an intra-hour global solar irradiance forecasting algorithm, it is important to detect multiple layers of clouds. The information provided by a solar forecasting algorithm is necessary to optimize and schedule the solar generation resources and storage devices in a smart grid. This investigation studies the performance of unsupervised learning techniques when detecting the number of cloud layers in infrared sky images. The images are acquired using an innovative infrared sky imager mounted on a solar tracker. Different mixture models are used to infer the distribution of the cloud features. The optimal decision criterion to find the number of clusters in the mixture models is analyzed and compared between different Bayesian metrics and a sequential hidden Markov model. The motion vectors are computed using a weighted implementation of the Lucas-Kanade algorithm. The correlations between the cloud velocity vectors and temperatures are analyzed to find the method that leads to the most accurate results. We have found that the sequential hidden Markov model outperformed the detection accuracy of the Bayesian metrics.
Shadow-Mapping for Unsupervised Neural Causal Discovery
Apr 28, 2021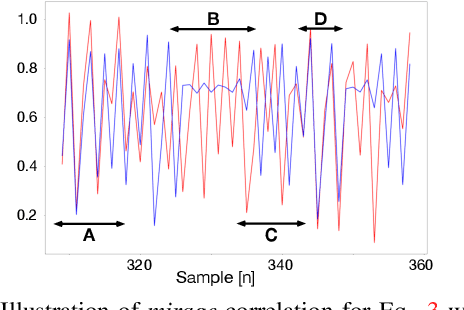
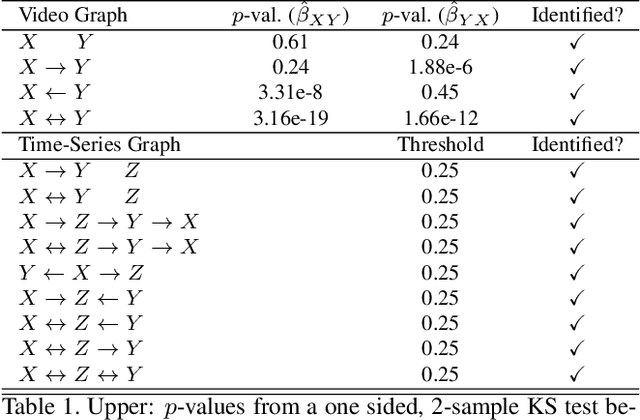
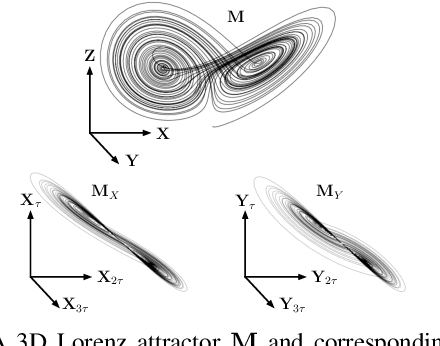
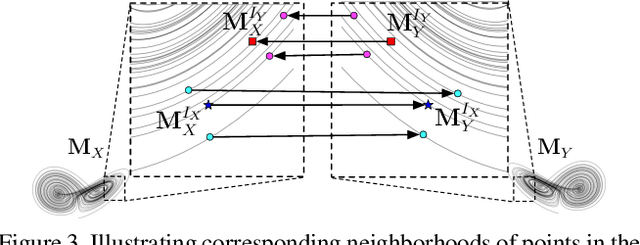
An important goal across most scientific fields is the discovery of causal structures underling a set of observations. Unfortunately, causal discovery methods which are based on correlation or mutual information can often fail to identify causal links in systems which exhibit dynamic relationships. Such dynamic systems (including the famous coupled logistic map) exhibit `mirage' correlations which appear and disappear depending on the observation window. This means not only that correlation is not causation but, perhaps counter-intuitively, that causation may occur without correlation. In this paper we describe Neural Shadow-Mapping, a neural network based method which embeds high-dimensional video data into a low-dimensional shadow representation, for subsequent estimation of causal links. We demonstrate its performance at discovering causal links from video-representations of dynamic systems.
FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild
Jun 21, 2021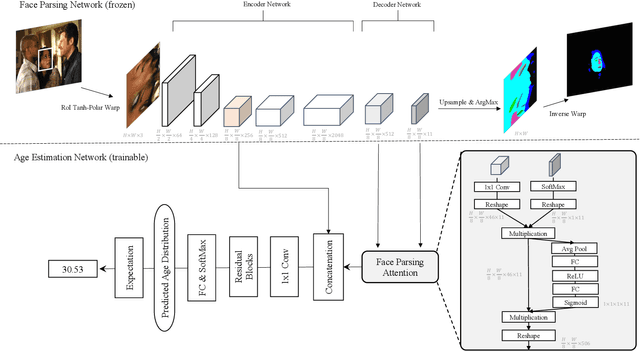
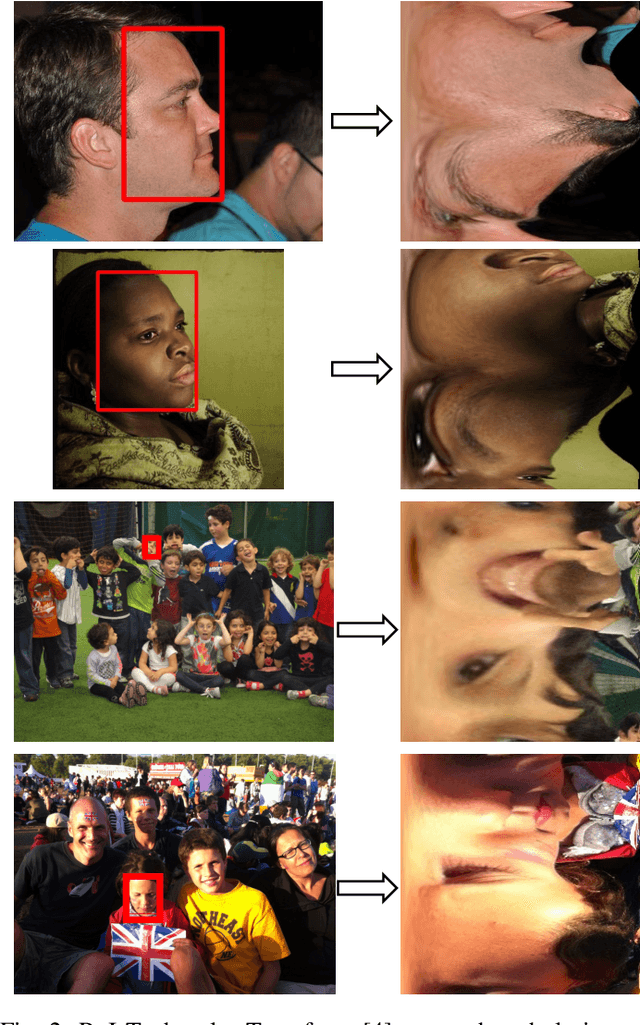

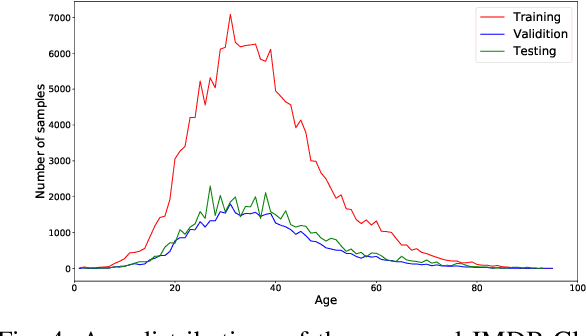
Image-based age estimation aims to predict a person's age from facial images. It is used in a variety of real-world applications. Although end-to-end deep models have achieved impressive results for age estimation on benchmark datasets, their performance in-the-wild still leaves much room for improvement due to the challenges caused by large variations in head pose, facial expressions, and occlusions. To address this issue, we propose a simple yet effective method to explicitly incorporate facial semantics into age estimation, so that the model would learn to correctly focus on the most informative facial components from unaligned facial images regardless of head pose and non-rigid deformation. To this end, we design a face parsing-based network to learn semantic information at different scales and a novel face parsing attention module to leverage these semantic features for age estimation. To evaluate our method on in-the-wild data, we also introduce a new challenging large-scale benchmark called IMDB-Clean. This dataset is created by semi-automatically cleaning the noisy IMDB-WIKI dataset using a constrained clustering method. Through comprehensive experiment on IMDB-Clean and other benchmark datasets, under both intra-dataset and cross-dataset evaluation protocols, we show that our method consistently outperforms all existing age estimation methods and achieves a new state-of-the-art performance. To the best of our knowledge, our work presents the first attempt of leveraging face parsing attention to achieve semantic-aware age estimation, which may be inspiring to other high level facial analysis tasks.
kMatrix: A Space Efficient Streaming Graph Summarization Technique
May 12, 2021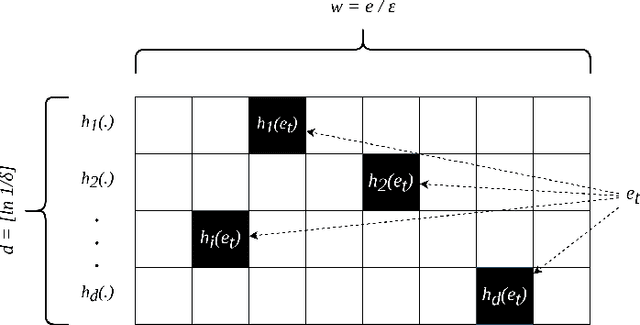
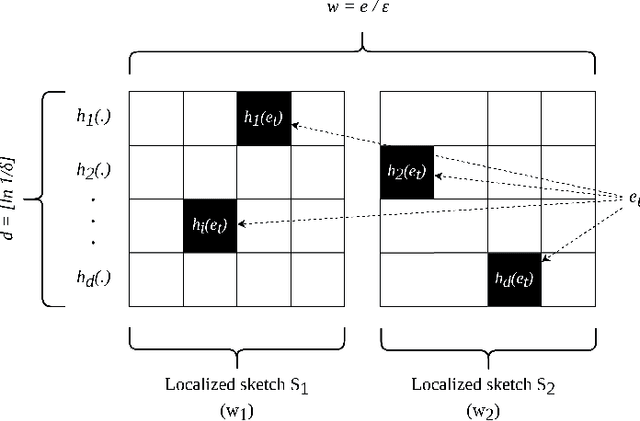
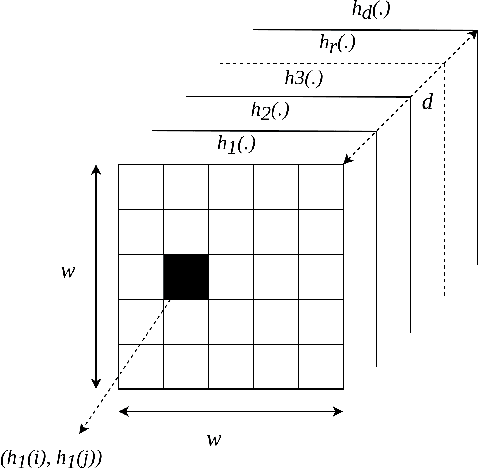
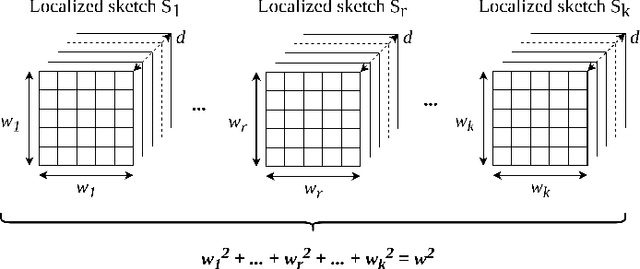
The amount of collected information on data repositories has vastly increased with the advent of the internet. It has become increasingly complex to deal with these massive data streams due to their sheer volume and the throughput of incoming data. Many of these data streams are mapped into graphs, which helps discover some of their properties. However, due to the difficulty in processing massive streaming graphs, they are summarized such that their properties can be approximately evaluated using the summaries. gSketch, TCM, and gMatrix are some of the major streaming graph summarization techniques. Our primary contribution is devising kMatrix, which is much more memory efficient than existing streaming graph summarization techniques. We achieved this by partitioning the allocated memory using a sample of the original graph stream. Through the experiments, we show that kMatrix can achieve a significantly less error for the queries using the same space as that of TCM and gMatrix.
SODA10M: Towards Large-Scale Object Detection Benchmark for Autonomous Driving
Jun 21, 2021

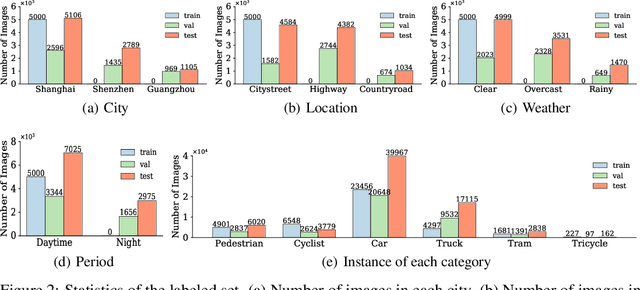
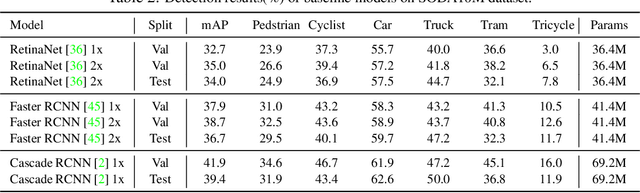
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale benchmark for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest benchmark to date. Existing autonomous driving systems heavily rely on `perfect' visual perception models (e.g., detection) trained using extensive annotated data to ensure the safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (e.g., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent powerful advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing dataset (e.g., KITTI, Waymo) either provides only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale Object Detection benchmark for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected every ten seconds per frame within 32 different cities under different weather conditions, periods and location scenes. We provide extensive experiments and deep analyses of existing supervised state-of-the-art detection models, popular self-supervised and semi-supervised approaches, and some insights about how to develop future models. The data and more up-to-date information have been released at https://soda-2d.github.io.
Learning a Skill-sequence-dependent Policy for Long-horizon Manipulation Tasks
May 12, 2021
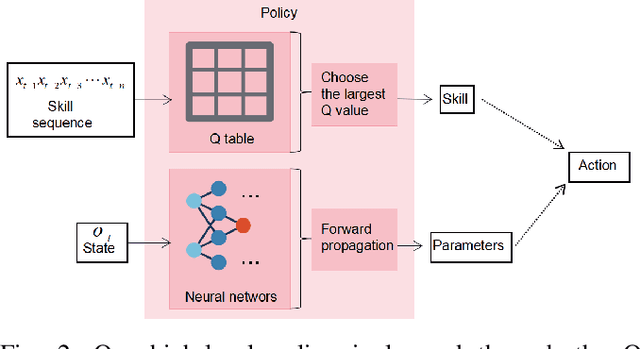

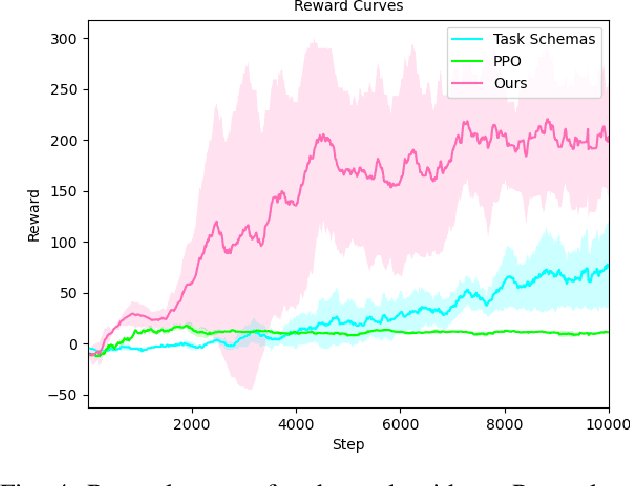
In recent years, the robotics community has made substantial progress in robotic manipulation using deep reinforcement learning (RL). Effectively learning of long-horizon tasks remains a challenging topic. Typical RL-based methods approximate long-horizon tasks as Markov decision processes and only consider current observation (images or other sensor information) as input state. However, such approximation ignores the fact that skill-sequence also plays a crucial role in long-horizon tasks. In this paper, we take both the observation and skill sequences into account and propose a skill-sequence-dependent hierarchical policy for solving a typical long-horizon task. The proposed policy consists of a high-level skill policy (utilizing skill sequences) and a low-level parameter policy (responding to observation) with corresponding training methods, which makes the learning much more sample-efficient. Experiments in simulation demonstrate that our approach successfully solves a long-horizon task and is significantly faster than Proximal Policy Optimization (PPO) and the task schema methods.
Revisit Visual Representation in Analytics Taxonomy: A Compression Perspective
Jun 16, 2021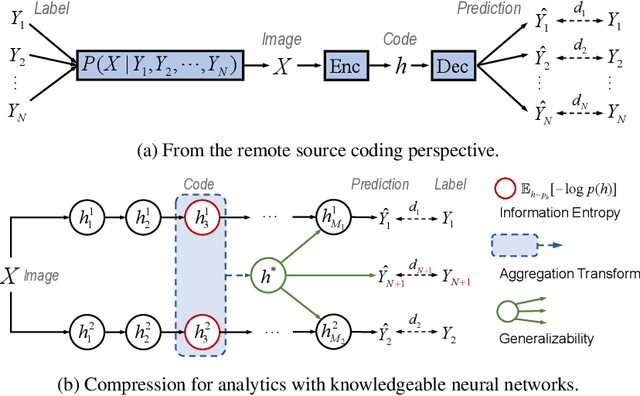
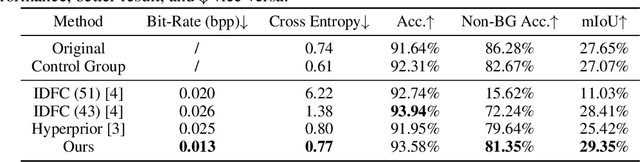
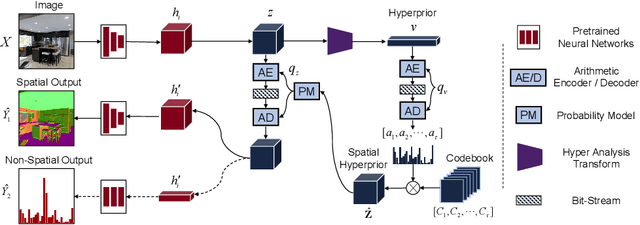
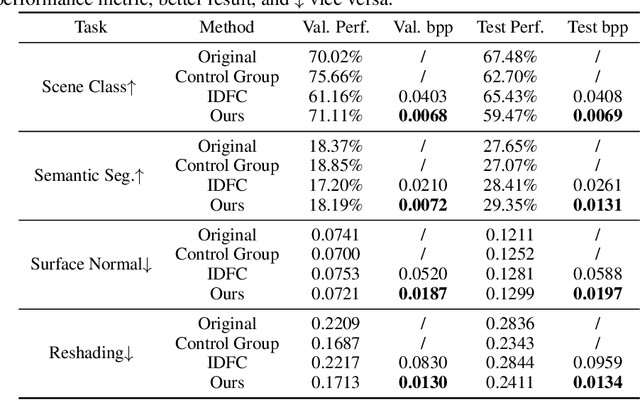
Visual analytics have played an increasingly critical role in the Internet of Things, where massive visual signals have to be compressed and fed into machines. But facing such big data and constrained bandwidth capacity, existing image/video compression methods lead to very low-quality representations, while existing feature compression techniques fail to support diversified visual analytics applications/tasks with low-bit-rate representations. In this paper, we raise and study the novel problem of supporting multiple machine vision analytics tasks with the compressed visual representation, namely, the information compression problem in analytics taxonomy. By utilizing the intrinsic transferability among different tasks, our framework successfully constructs compact and expressive representations at low bit-rates to support a diversified set of machine vision tasks, including both high-level semantic-related tasks and mid-level geometry analytic tasks. In order to impose compactness in the representations, we propose a codebook-based hyperprior, which helps map the representation into a low-dimensional manifold. As it well fits the signal structure of the deep visual feature, it facilitates more accurate entropy estimation, and results in higher compression efficiency. With the proposed framework and the codebook-based hyperprior, we further investigate the relationship of different task features owning different levels of abstraction granularity. Experimental results demonstrate that with the proposed scheme, a set of diversified tasks can be supported at a significantly lower bit-rate, compared with existing compression schemes.