 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Source-Channel Coding for Sentence Semantic Transmission with HARQ
Jun 06, 2021
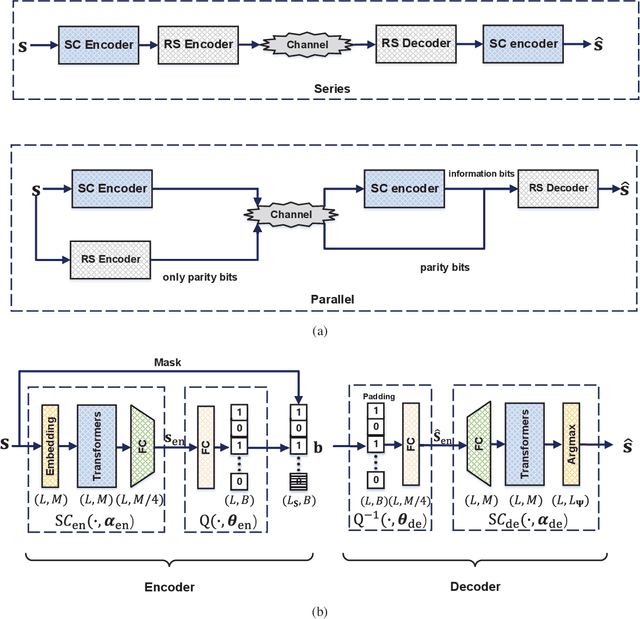
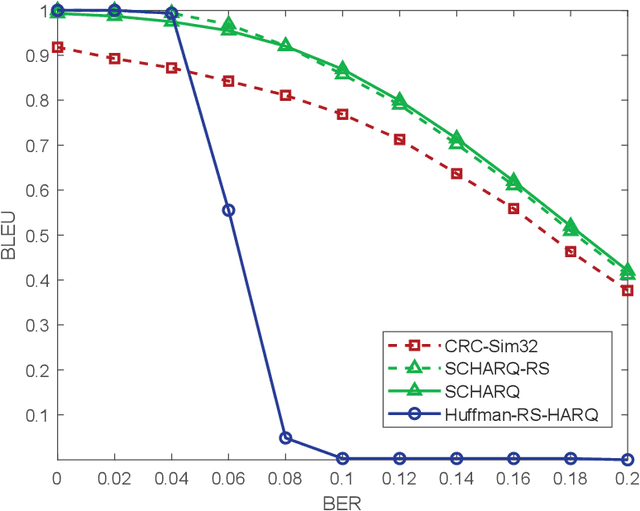
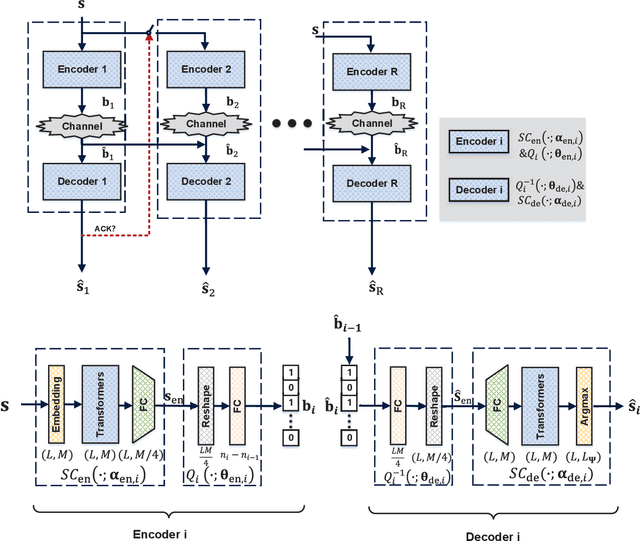
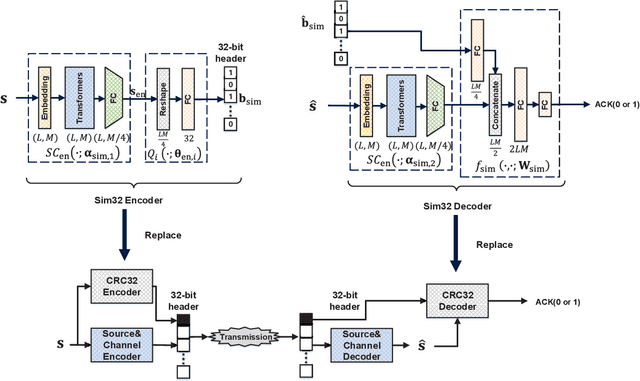
Recently, semantic communication has been brought to the forefront because of its great success in deep learning (DL), especially Transformer. Even if semantic communication has been successfully applied in the sentence transmission to reduce semantic errors, existing architecture is usually fixed in the codeword length and is inefficient and inflexible for the varying sentence length. In this paper, we exploit hybrid automatic repeat request (HARQ) to reduce semantic transmission error further. We first combine semantic coding (SC) with Reed Solomon (RS) channel coding and HARQ, called SC-RS-HARQ, which exploits the superiority of the SC and the reliability of the conventional methods successfully. Although the SC-RS-HARQ is easily applied in the existing HARQ systems, we also develop an end-to-end architecture, called SCHARQ, to pursue the performance further. Numerical results demonstrate that SCHARQ significantly reduces the required number of bits for sentence semantic transmission and sentence error rate. Finally, we attempt to replace error detection from cyclic redundancy check to a similarity detection network called Sim32 to allow the receiver to reserve the wrong sentences with similar semantic information and to save transmission resources.
Random Hash Code Generation for Cancelable Fingerprint Templates using Vector Permutation and Shift-order Process
May 21, 2021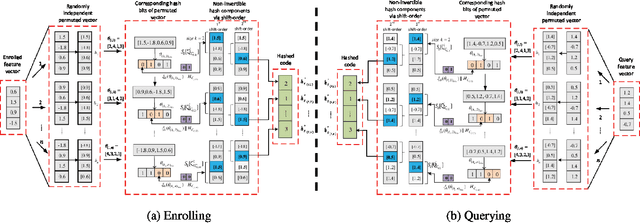
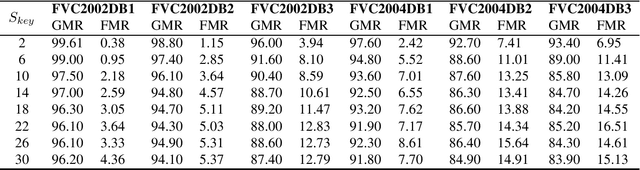
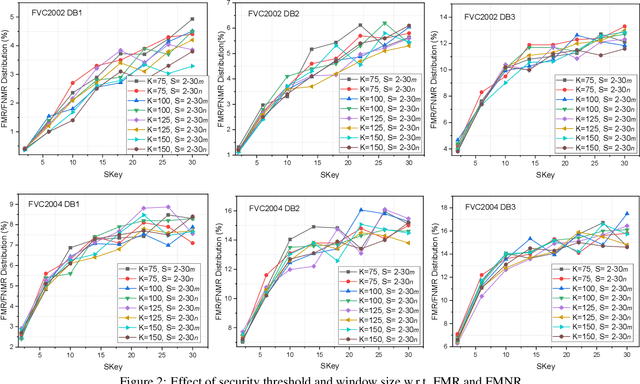
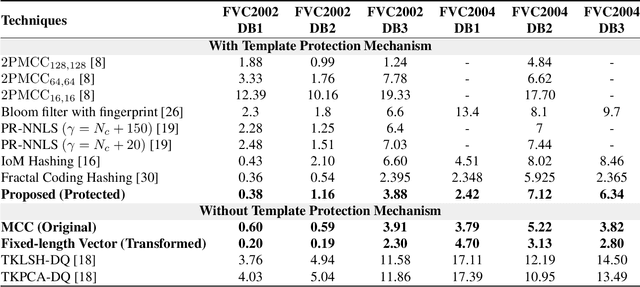
Cancelable biometric techniques have been used to prevent the compromise of biometric data by generating and using their corresponding cancelable templates for user authentication. However, the non-invertible distance preserving transformation methods employed in various schemes are often vulnerable to information leakage since matching is performed in the transformed domain. In this paper, we propose a non-invertible distance preserving scheme based on vector permutation and shift-order process. First, the dimension of feature vectors is reduced using kernelized principle component analysis (KPCA) prior to randomly permuting the extracted vector features. A shift-order process is then applied to the generated features in order to achieve non-invertibility and combat similarity-based attacks. The generated hash codes are resilient to different security and privacy attacks whilst fulfilling the major revocability and unlinkability requirements. Experimental evaluation conducted on 6 datasets of FVC2002 and FVC2004 reveals a high-performance accuracy of the proposed scheme better than other existing state-of-the-art schemes.
LPF: A Language-Prior Feedback Objective Function for De-biased Visual Question Answering
May 29, 2021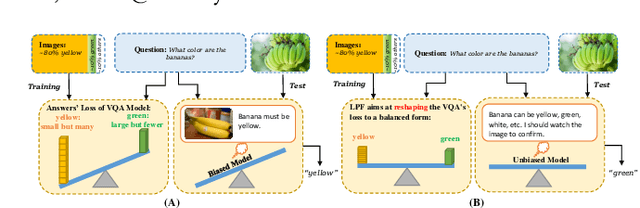
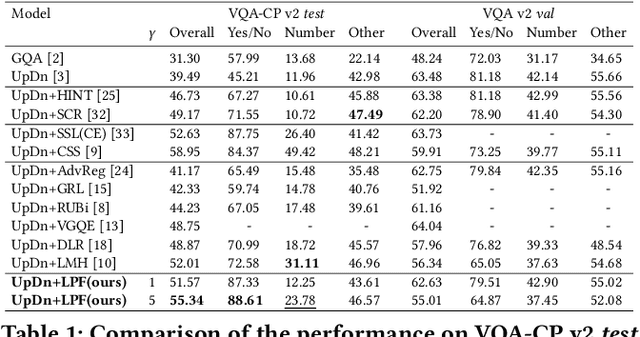
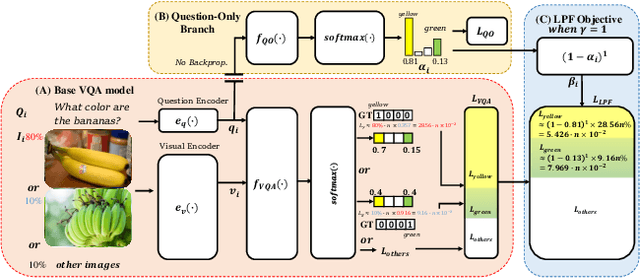
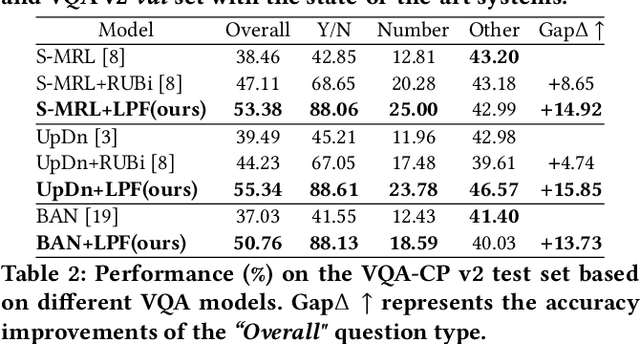
Most existing Visual Question Answering (VQA) systems tend to overly rely on language bias and hence fail to reason from the visual clue. To address this issue, we propose a novel Language-Prior Feedback (LPF) objective function, to re-balance the proportion of each answer's loss value in the total VQA loss. The LPF firstly calculates a modulating factor to determine the language bias using a question-only branch. Then, the LPF assigns a self-adaptive weight to each training sample in the training process. With this reweighting mechanism, the LPF ensures that the total VQA loss can be reshaped to a more balanced form. By this means, the samples that require certain visual information to predict will be efficiently used during training. Our method is simple to implement, model-agnostic, and end-to-end trainable. We conduct extensive experiments and the results show that the LPF (1) brings a significant improvement over various VQA models, (2) achieves competitive performance on the bias-sensitive VQA-CP v2 benchmark.
ML and MAP Device Activity Detections for Grant-Free Massive Access in Multi-Cell Networks
Jun 19, 2021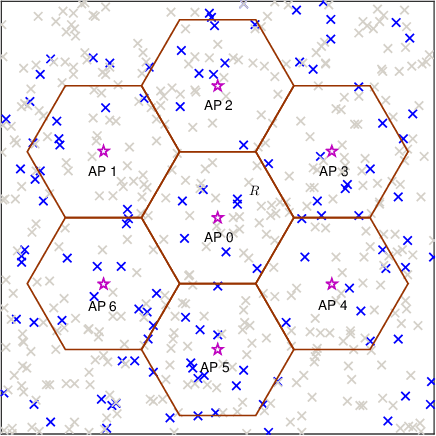
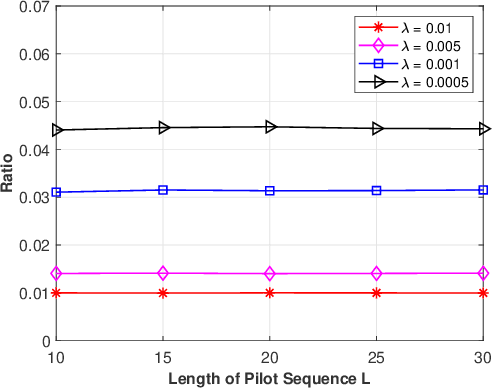
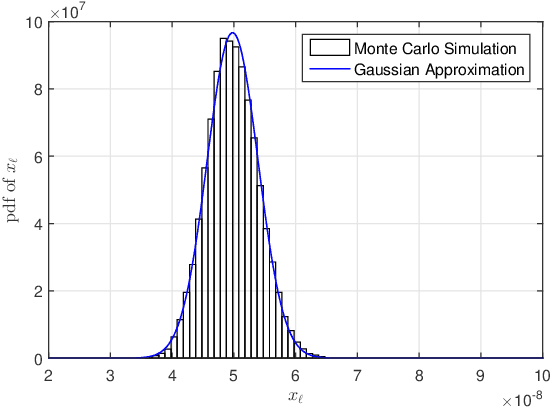
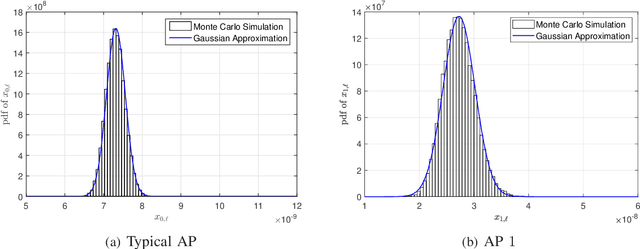
Device activity detection is one main challenge in grant-free massive access, which is recently proposed to support massive machine-type communications (mMTC). Existing solutions for device activity detection fail to consider inter-cell interference generated by massive IoT devices or important prior information on device activities and inter-cell interference. In this paper, given different numbers of observations and network parameters, we consider both non-cooperative device activity detection and cooperative device activity detection in a multi-cell network, consisting of many access points (APs) and IoT devices. Under each activity detection mechanism, we consider the joint maximum likelihood (ML) estimation and joint maximum a posterior probability (MAP) estimation of both device activities and interference powers, utilizing tools from probability, stochastic geometry, and optimization. Each estimation problem is a challenging non-convex problem, and a coordinate descent algorithm is proposed to obtain a stationary point. Each proposed joint ML estimation extends the existing one for a single-cell network by considering the estimation of interference powers, together with the estimation of device activities. Each proposed joint MAP estimation further enhances the corresponding joint ML estimation by exploiting prior distributions of device activities and interference powers. The proposed joint ML estimation and joint MAP estimation under cooperative detection outperform the respective ones under non-cooperative detection at the costs of increasing backhaul burden, knowledge of network parameters, and computational complexities.
Lifting Transformer for 3D Human Pose Estimation in Video
Apr 01, 2021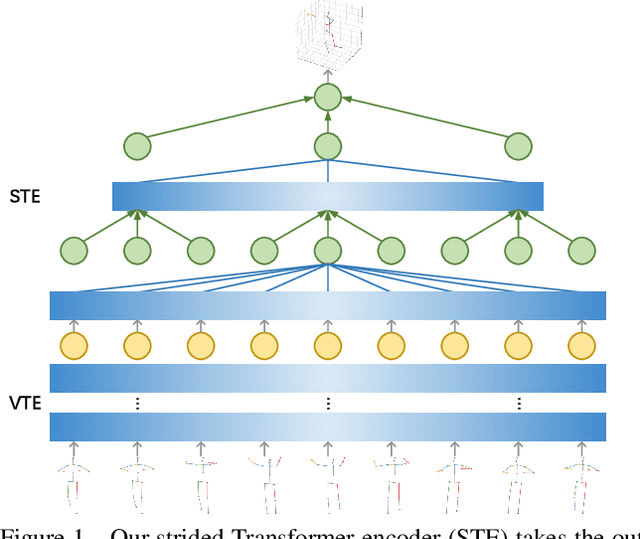
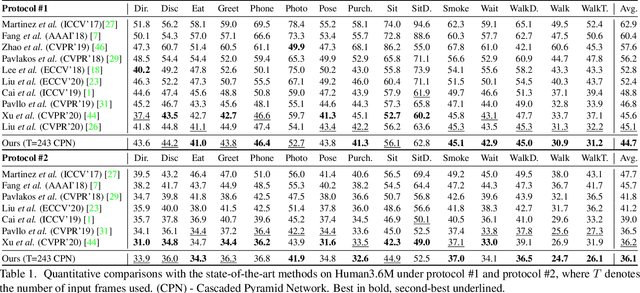
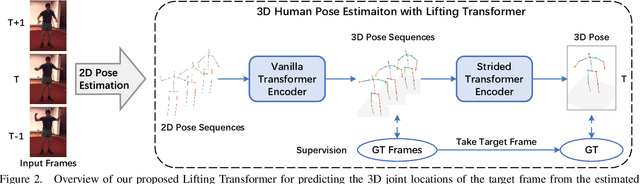
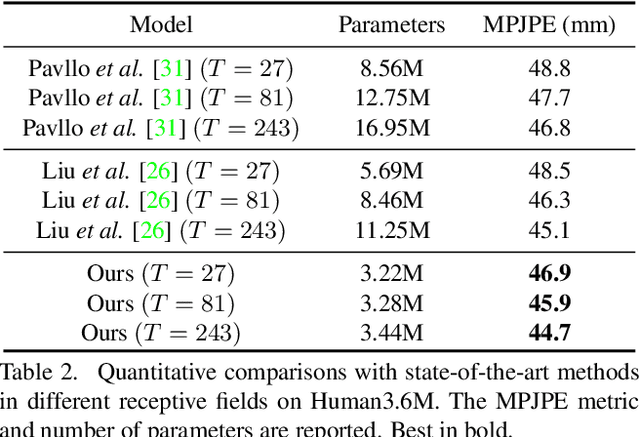
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021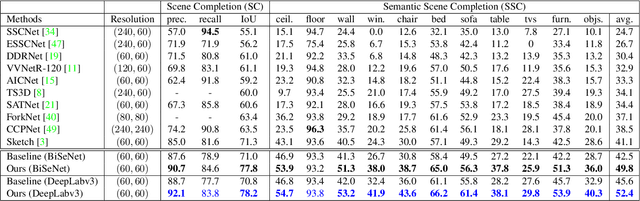

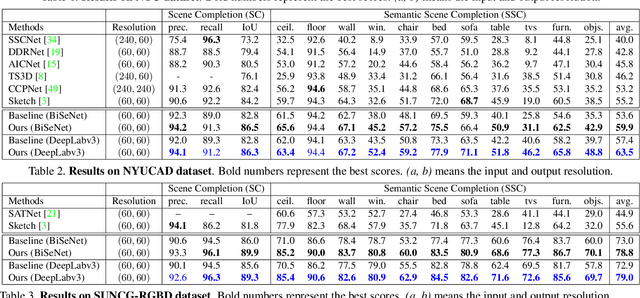
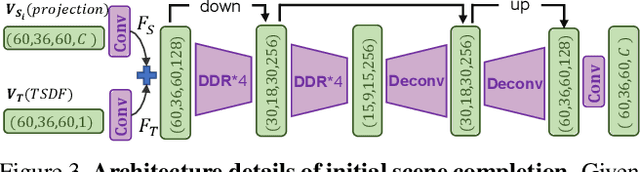
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.
Understanding the Security of Deepfake Detection
Jul 05, 2021
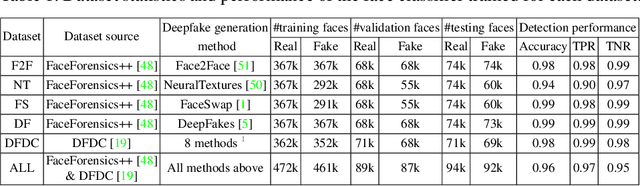
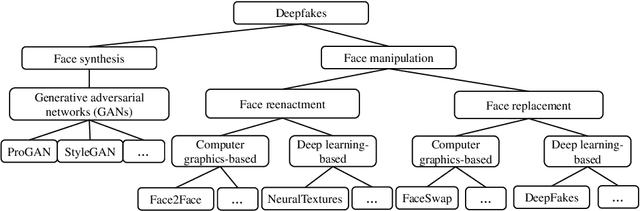
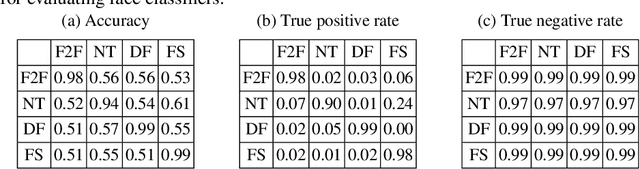
Deepfakes pose growing challenges to the trust of information on the Internet. Therefore,detecting deepfakes has attracted increasing attentions from both academia and industry. State-of-the-art deepfake detection methods consist of two key components, i.e., face extractor and face classifier, which extract the face region in an image and classify it to be real/fake, respectively. Existing studies mainly focused on improving the detection performance in non-adversarial settings, leaving security of deepfake detection in adversarial settings largely unexplored. In this work, we aim to bridge the gap. In particular, we perform a systematic measurement study to understand the security of the state-of-the-art deepfake detection methods in adversarial settings. We use two large-scale public deepfakes data sources including FaceForensics++ and Facebook Deepfake Detection Challenge, where the deepfakes are fake face images; and we train state-of-the-art deepfake detection methods. These detection methods can achieve 0.94--0.99 accuracies in non-adversarial settings on these datasets. However, our measurement results uncover multiple security limitations of the deepfake detection methods in adversarial settings. First, we find that an attacker can evade a face extractor, i.e., the face extractor fails to extract the correct face regions, via adding small Gaussian noise to its deepfake images. Second, we find that a face classifier trained using deepfakes generated by one method cannot detect deepfakes generated by another method, i.e., an attacker can evade detection via generating deepfakes using a new method. Third, we find that an attacker can leverage backdoor attacks developed by the adversarial machine learning community to evade a face classifier. Our results highlight that deepfake detection should consider the adversarial nature of the problem.
Information Recovery from Pairwise Measurements
May 06, 2016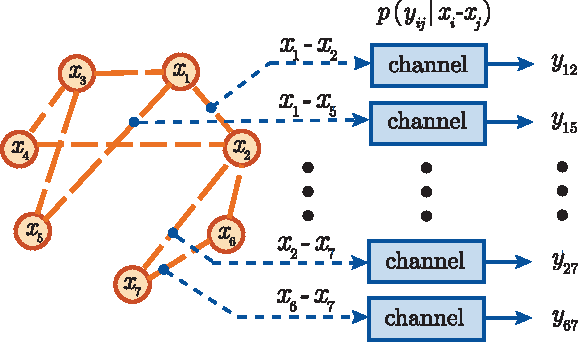
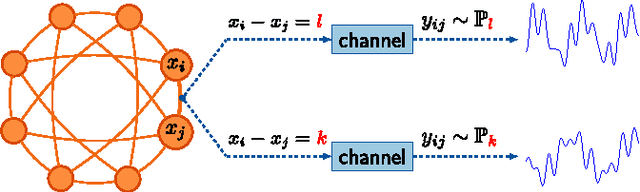
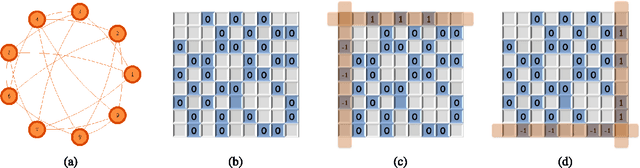
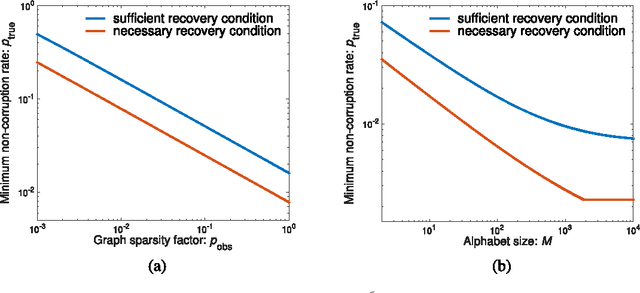
This paper is concerned with jointly recovering $n$ node-variables $\left\{ x_{i}\right\}_{1\leq i\leq n}$ from a collection of pairwise difference measurements. Imagine we acquire a few observations taking the form of $x_{i}-x_{j}$; the observation pattern is represented by a measurement graph $\mathcal{G}$ with an edge set $\mathcal{E}$ such that $x_{i}-x_{j}$ is observed if and only if $(i,j)\in\mathcal{E}$. To account for noisy measurements in a general manner, we model the data acquisition process by a set of channels with given input/output transition measures. Employing information-theoretic tools applied to channel decoding problems, we develop a \emph{unified} framework to characterize the fundamental recovery criterion, which accommodates general graph structures, alphabet sizes, and channel transition measures. In particular, our results isolate a family of \emph{minimum} \emph{channel divergence measures} to characterize the degree of measurement corruption, which together with the size of the minimum cut of $\mathcal{G}$ dictates the feasibility of exact information recovery. For various homogeneous graphs, the recovery condition depends almost only on the edge sparsity of the measurement graph irrespective of other graphical metrics; alternatively, the minimum sample complexity required for these graphs scales like \[ \text{minimum sample complexity }\asymp\frac{n\log n}{\mathsf{Hel}_{1/2}^{\min}} \] for certain information metric $\mathsf{Hel}_{1/2}^{\min}$ defined in the main text, as long as the alphabet size is not super-polynomial in $n$. We apply our general theory to three concrete applications, including the stochastic block model, the outlier model, and the haplotype assembly problem. Our theory leads to order-wise tight recovery conditions for all these scenarios.
Improving weakly supervised sound event detection with self-supervised auxiliary tasks
Jun 12, 2021

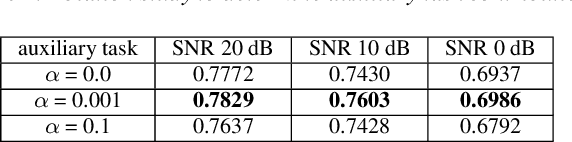
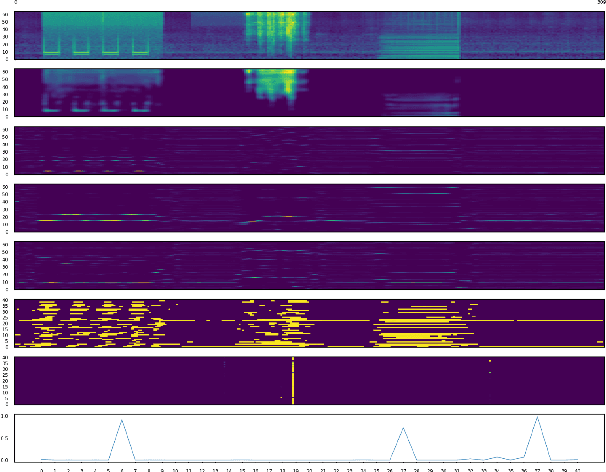
While multitask and transfer learning has shown to improve the performance of neural networks in limited data settings, they require pretraining of the model on large datasets beforehand. In this paper, we focus on improving the performance of weakly supervised sound event detection in low data and noisy settings simultaneously without requiring any pretraining task. To that extent, we propose a shared encoder architecture with sound event detection as a primary task and an additional secondary decoder for a self-supervised auxiliary task. We empirically evaluate the proposed framework for weakly supervised sound event detection on a remix dataset of the DCASE 2019 task 1 acoustic scene data with DCASE 2018 Task 2 sounds event data under 0, 10 and 20 dB SNR. To ensure we retain the localisation information of multiple sound events, we propose a two-step attention pooling mechanism that provides a time-frequency localisation of multiple audio events in the clip. The proposed framework with two-step attention outperforms existing benchmark models by 22.3%, 12.8%, 5.9% on 0, 10 and 20 dB SNR respectively. We carry out an ablation study to determine the contribution of the auxiliary task and two-step attention pooling to the SED performance improvement.
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Jun 05, 2021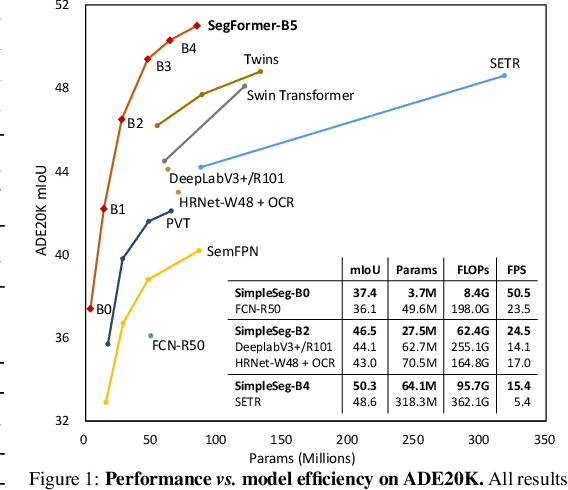
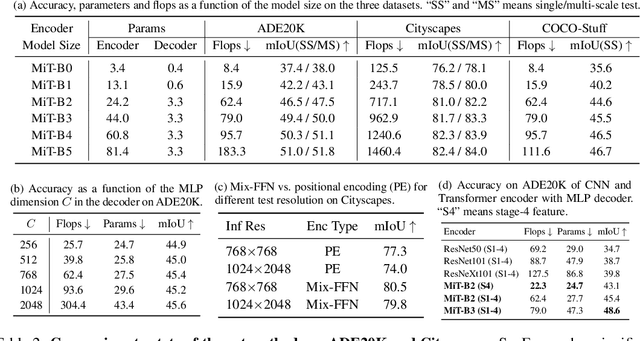
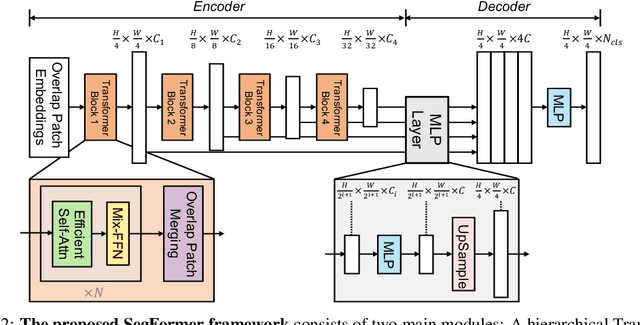
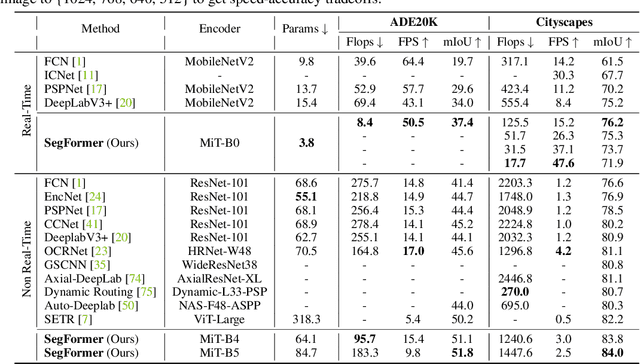
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C. Code will be released at: github.com/NVlabs/SegFormer.