 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attend and Select: A Segment Attention based Selection Mechanism for Microblog Hashtag Generation
Jun 06, 2021


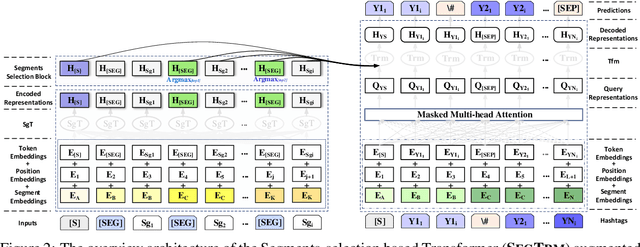
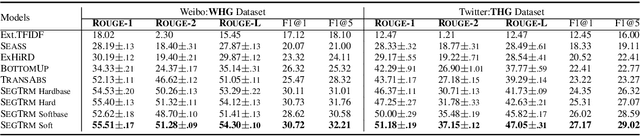
Automatic microblog hashtag generation can help us better and faster understand or process the critical content of microblog posts. Conventional sequence-to-sequence generation methods can produce phrase-level hashtags and have achieved remarkable performance on this task. However, they are incapable of filtering out secondary information and not good at capturing the discontinuous semantics among crucial tokens. A hashtag is formed by tokens or phrases that may originate from various fragmentary segments of the original text. In this work, we propose an end-to-end Transformer-based generation model which consists of three phases: encoding, segments-selection, and decoding. The model transforms discontinuous semantic segments from the source text into a sequence of hashtags. Specifically, we introduce a novel Segments Selection Mechanism (SSM) for Transformer to obtain segmental representations tailored to phrase-level hashtag generation. Besides, we introduce two large-scale hashtag generation datasets, which are newly collected from Chinese Weibo and English Twitter. Extensive evaluations on the two datasets reveal our approach's superiority with significant improvements to extraction and generation baselines. The code and datasets are available at \url{https://github.com/OpenSUM/HashtagGen}.
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
Jul 01, 2021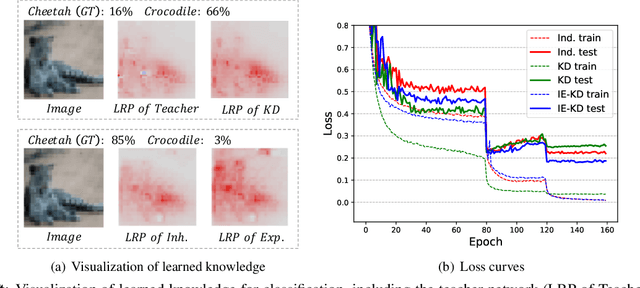

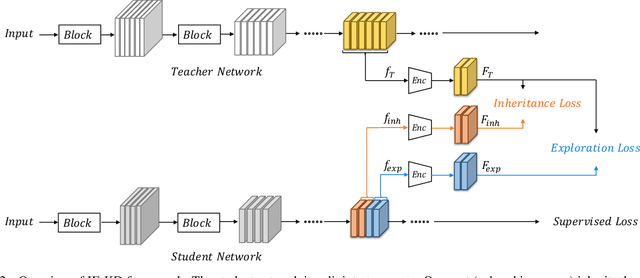

Knowledge Distillation (KD) is a popular technique to transfer knowledge from a teacher model or ensemble to a student model. Its success is generally attributed to the privileged information on similarities/consistency between the class distributions or intermediate feature representations of the teacher model and the student model. However, directly pushing the student model to mimic the probabilities/features of the teacher model to a large extent limits the student model in learning undiscovered knowledge/features. In this paper, we propose a novel inheritance and exploration knowledge distillation framework (IE-KD), in which a student model is split into two parts - inheritance and exploration. The inheritance part is learned with a similarity loss to transfer the existing learned knowledge from the teacher model to the student model, while the exploration part is encouraged to learn representations different from the inherited ones with a dis-similarity loss. Our IE-KD framework is generic and can be easily combined with existing distillation or mutual learning methods for training deep neural networks. Extensive experiments demonstrate that these two parts can jointly push the student model to learn more diversified and effective representations, and our IE-KD can be a general technique to improve the student network to achieve SOTA performance. Furthermore, by applying our IE-KD to the training of two networks, the performance of both can be improved w.r.t. deep mutual learning. The code and models of IE-KD will be make publicly available at https://github.com/yellowtownhz/IE-KD.
Document Collection Visual Question Answering
Apr 27, 2021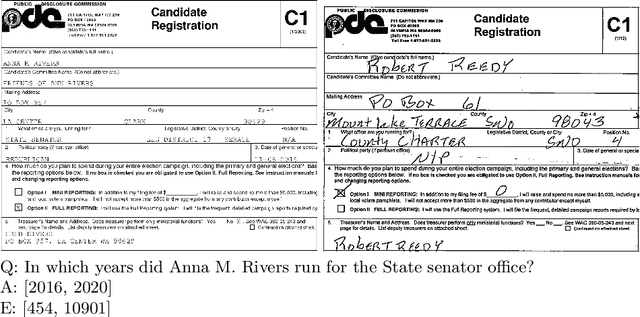


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.
Designing Multimodal Datasets for NLP Challenges
May 12, 2021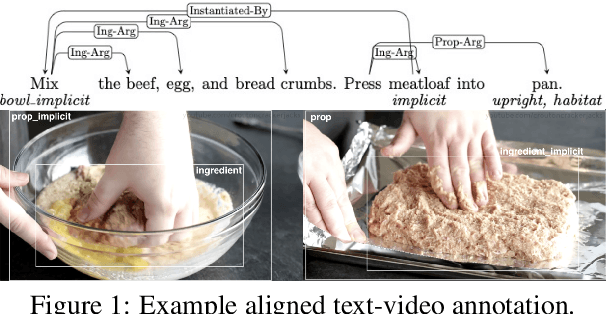


In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
DeepLoc: A Ubiquitous Accurate and Low-Overhead Outdoor Cellular Localization System
Jun 25, 2021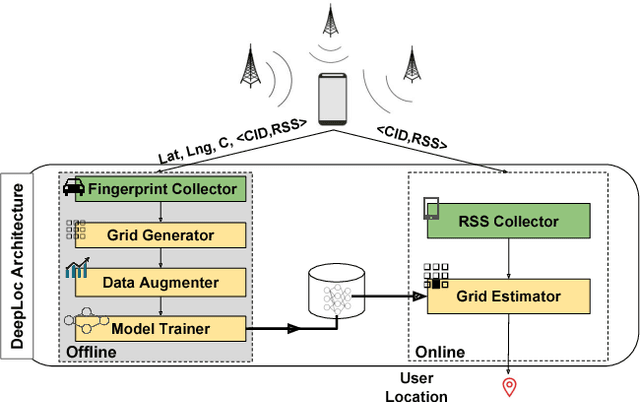
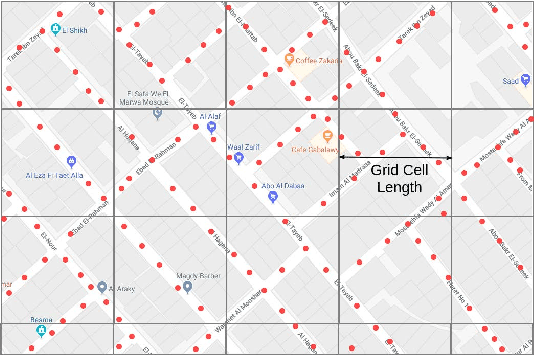

Recent years have witnessed fast growth in outdoor location-based services. While GPS is considered a ubiquitous localization system, it is not supported by low-end phones, requires direct line of sight to the satellites, and can drain the phone battery quickly. In this paper, we propose DeepLoc: a deep learning-based outdoor localization system that obtains GPS-like localization accuracy without its limitations. In particular, DeepLoc leverages the ubiquitous cellular signals received from the different cell towers heard by the mobile device as hints to localize it. To do that, crowd-sensed geo-tagged received signal strength information coming from different cell towers is used to train a deep model that is used to infer the user's position. As part of DeepLoc design, we introduce modules to address a number of practical challenges including scaling the data collection to large areas, handling the inherent noise in the cellular signal and geo-tagged data, as well as providing enough data that is required for deep learning models with low-overhead. We implemented DeepLoc on different Android devices. Evaluation results in realistic urban and rural environments show that DeepLoc can achieve a median localization accuracy within 18.8m in urban areas and within 15.7m in rural areas. This accuracy outperforms the state-of-the-art cellular-based systems by more than 470% and comes with 330% savings in power compared to the GPS. This highlights the promise of DeepLoc as a ubiquitous accurate and low-overhead localization system.
Do Context-Aware Translation Models Pay the Right Attention?
May 21, 2021

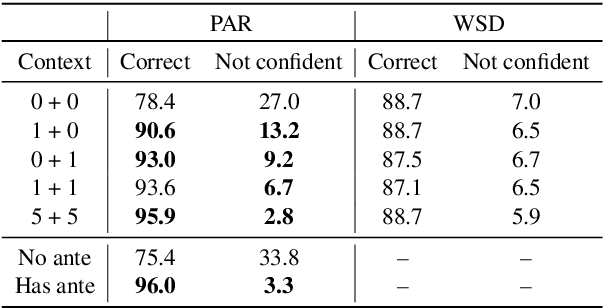
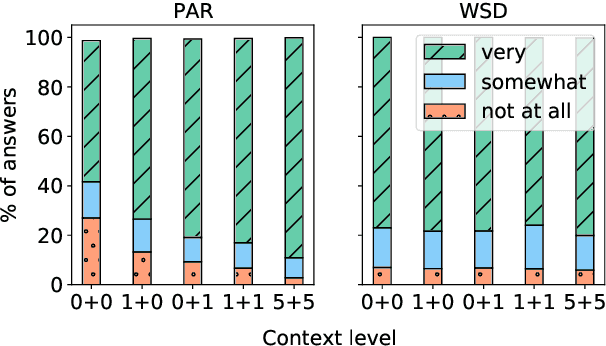
Context-aware machine translation models are designed to leverage contextual information, but often fail to do so. As a result, they inaccurately disambiguate pronouns and polysemous words that require context for resolution. In this paper, we ask several questions: What contexts do human translators use to resolve ambiguous words? Are models paying large amounts of attention to the same context? What if we explicitly train them to do so? To answer these questions, we introduce SCAT (Supporting Context for Ambiguous Translations), a new English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation. Using SCAT, we perform an in-depth analysis of the context used to disambiguate, examining positional and lexical characteristics of the supporting words. Furthermore, we measure the degree of alignment between the model's attention scores and the supporting context from SCAT, and apply a guided attention strategy to encourage agreement between the two.
Multi-Domain Active Learning: A Comparative Study
Jun 25, 2021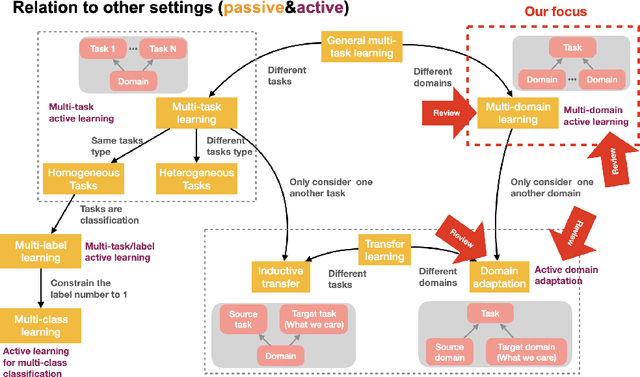
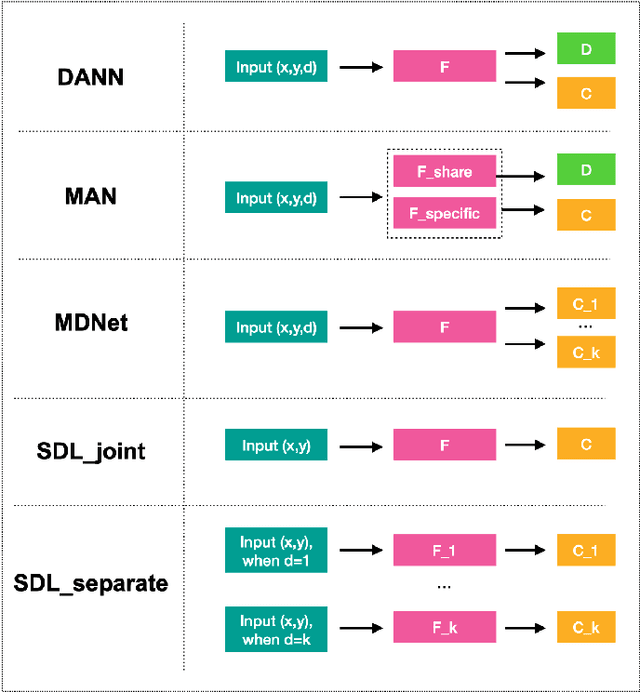
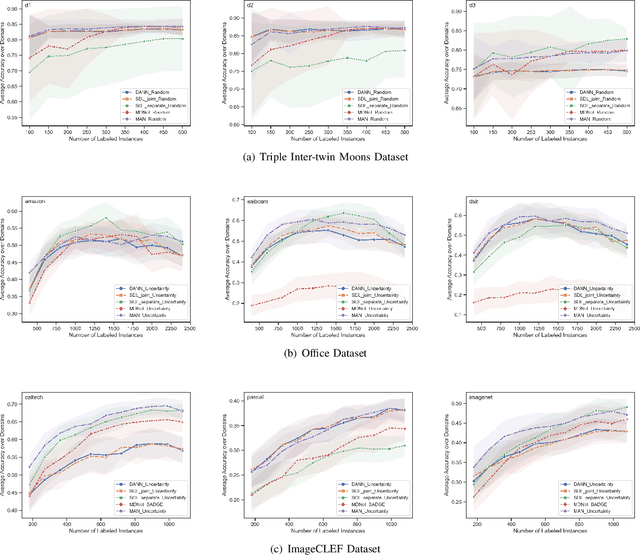
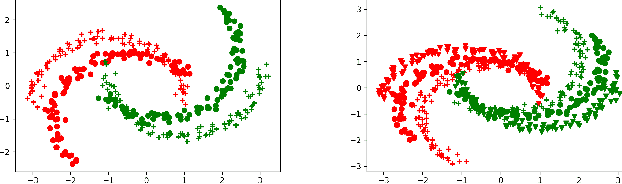
Building classifiers on multiple domains is a practical problem in the real life. Instead of building classifiers one by one, multi-domain learning (MDL) simultaneously builds classifiers on multiple domains. MDL utilizes the information shared among the domains to improve the performance. As a supervised learning problem, the labeling effort is still high in MDL problems. Usually, this high labeling cost issue could be relieved by using active learning. Thus, it is natural to utilize active learning to reduce the labeling effort in MDL, and we refer this setting as multi-domain active learning (MDAL). However, there are only few works which are built on this setting. And when the researches have to face this problem, there is no off-the-shelf solutions. Under this circumstance, combining the current multi-domain learning models and single-domain active learning strategies might be a preliminary solution for MDAL problem. To find out the potential of this preliminary solution, a comparative study over 5 models and 4 selection strategies is made in this paper. To the best of our knowledge, this is the first work provides the formal definition of MDAL. Besides, this is the first comparative work for MDAL problem. From the results, the Multinomial Adversarial Networks (MAN) model with a simple best vs second best (BvSB) uncertainty strategy shows its superiority in most cases. We take this combination as our off-the-shelf recommendation for the MDAL problem.
Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport
Jun 25, 2021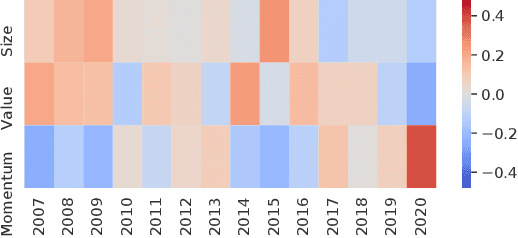
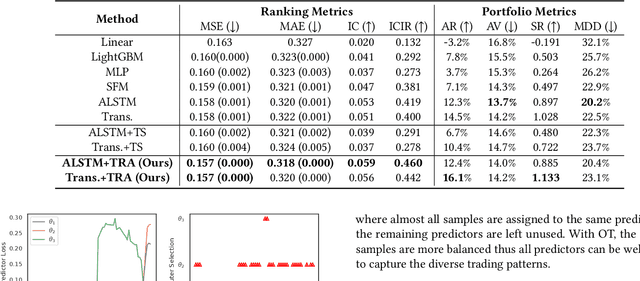
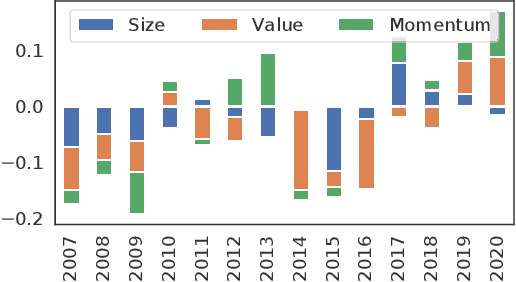
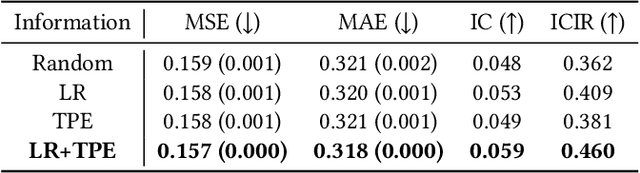
Successful quantitative investment usually relies on precise predictions of the future movement of the stock price. Recently, machine learning based solutions have shown their capacity to give more accurate stock prediction and become indispensable components in modern quantitative investment systems. However, the i.i.d. assumption behind existing methods is inconsistent with the existence of diverse trading patterns in the stock market, which inevitably limits their ability to achieve better stock prediction performance. In this paper, we propose a novel architecture, Temporal Routing Adaptor (TRA), to empower existing stock prediction models with the ability to model multiple stock trading patterns. Essentially, TRA is a lightweight module that consists of a set of independent predictors for learning multiple patterns as well as a router to dispatch samples to different predictors. Nevertheless, the lack of explicit pattern identifiers makes it quite challenging to train an effective TRA-based model. To tackle this challenge, we further design a learning algorithm based on Optimal Transport (OT) to obtain the optimal sample to predictor assignment and effectively optimize the router with such assignment through an auxiliary loss term. Experiments on the real-world stock ranking task show that compared to the state-of-the-art baselines, e.g., Attention LSTM and Transformer, the proposed method can improve information coefficient (IC) from 0.053 to 0.059 and 0.051 to 0.056 respectively. Our dataset and code used in this work are publicly available: https://github.com/microsoft/qlib/tree/main/examples/benchmarks/TRA.
A Reinforcement Learning Approach to Age of Information in Multi-User Networks
Jun 01, 2018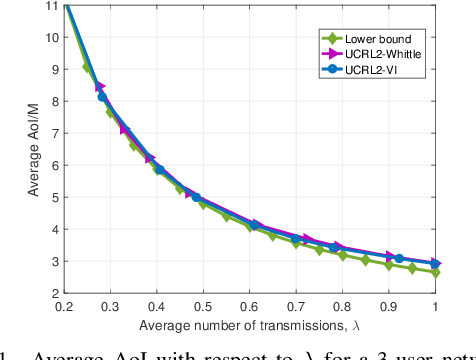
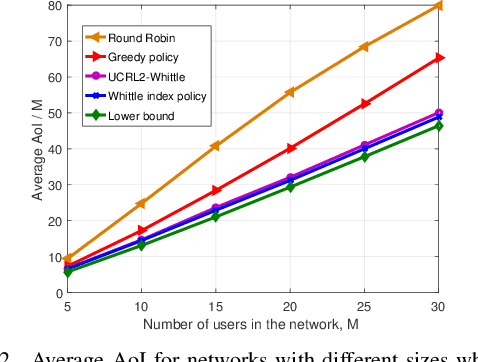
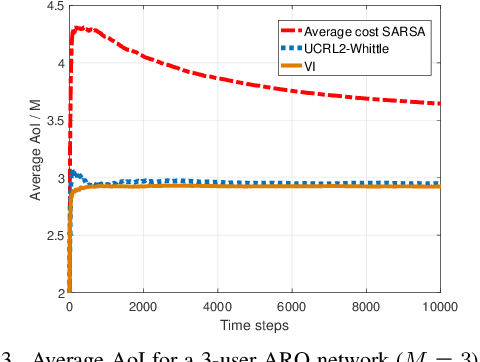
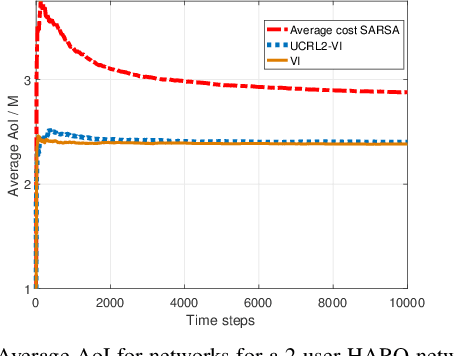
Scheduling the transmission of time-sensitive data to multiple users over error-prone communication channels is studied with the goal of minimizing the long-term average age of information (AoI) at the users under a constraint on the average number of transmissions at the source node. After each transmission, the source receives an instantaneous ACK/NACK feedback from the intended receiver and decides on what time and to which user to transmit the next update. The optimal scheduling policy is first studied under different feedback mechanisms when the channel statistics are known; in particular, the standard automatic repeat request (ARQ) and hybrid ARQ (HARQ) protocols are considered. Then a reinforcement learning (RL) approach is introduced, which does not assume any a priori information on the random processes governing the channel states. Different RL methods are verified and compared through numerical simulations.
Watershed of Artificial Intelligence: Human Intelligence, Machine Intelligence, and Biological Intelligence
May 07, 2021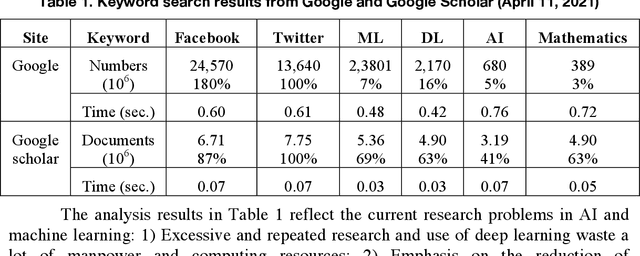
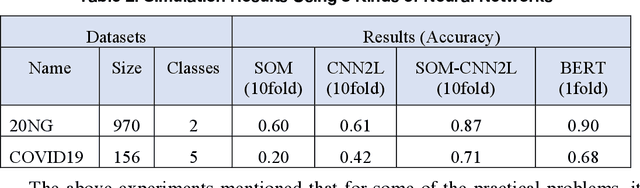
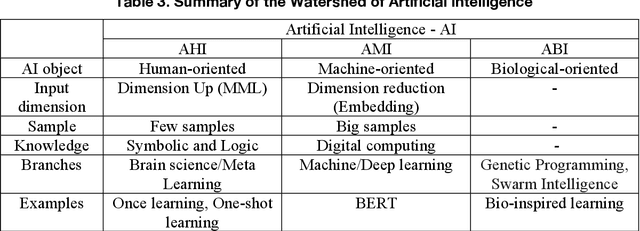
This article reviews the "Once learning" mechanism that was proposed 23 years ago and the subsequent successes of "One-shot learning" in image classification and "You Only Look Once - YOLO" in objective detection. Analyzing the current development of Artificial Intelligence (AI), the proposal is that AI should be clearly divided into the following categories: Artificial Human Intelligence (AHI), Artificial Machine Intelligence (AMI), and Artificial Biological Intelligence (ABI), which will also be the main directions of theory and application development for AI. As a watershed for the branches of AI, some classification standards and methods are discussed: 1) Human-oriented, machine-oriented, and biological-oriented AI R&D; 2) Information input processed by Dimensionality-up or Dimensionality-reduction; 3) The use of one/few or large samples for knowledge learning.