 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
All Together Now: Teachers as Research Partners in the Design of Search Technology for the Classroom
May 08, 2021
In the classroom environment, search tools are the means for students to access Web resources. The perspectives of students, researchers, and industry practitioners lead the ongoing research debate in this area. In this article, we argue in favor of incorporating a new voice into this debate: teachers. We showcase the value of involving teachers in all aspects related to the design of search tools for the classroom; from the beginning till the end. Driven by our research experience designing, developing, and evaluating new tools to support children's information discovery in the classroom, we share insights on the role of the experts-in-the-loop, i.e., teachers who provide the connection between search tools and students. And yes, in our case, always involving a teacher as a research partner.
Comparing seven methods for state-of-health time series prediction for the lithium-ion battery packs of forklifts
Jul 06, 2021
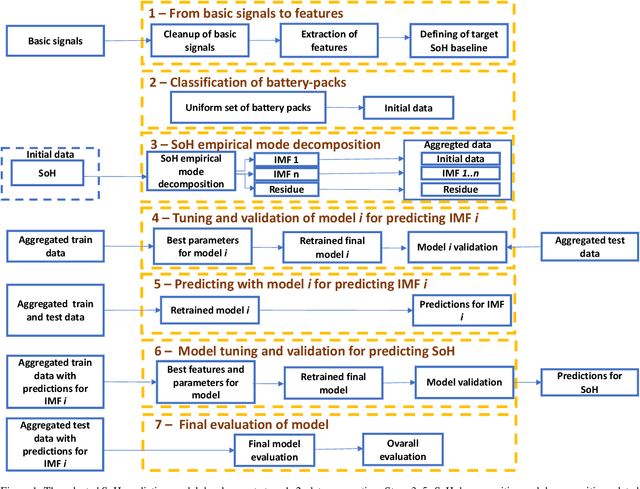
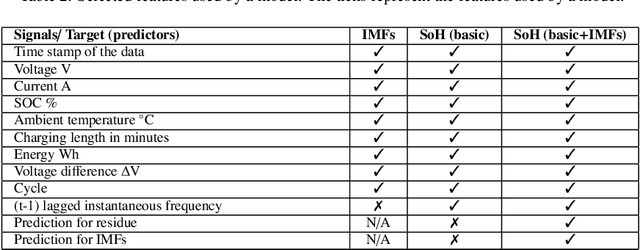
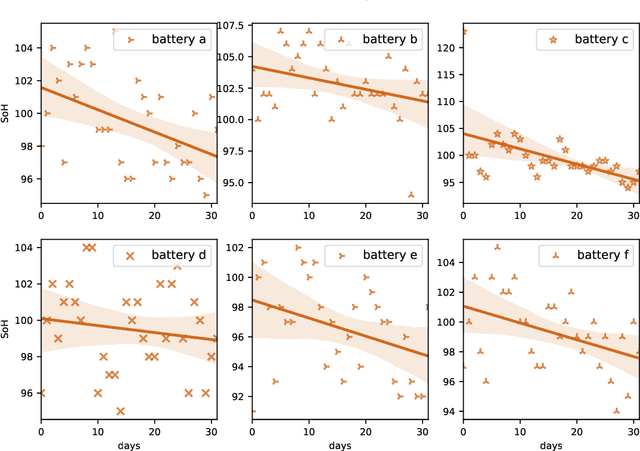
A key aspect for the forklifts is the state-of-health (SoH) assessment to ensure the safety and the reliability of uninterrupted power source. Forecasting the battery SoH well is imperative to enable preventive maintenance and hence to reduce the costs. This paper demonstrates the capabilities of gradient boosting regression for predicting the SoH timeseries under circumstances when there is little prior information available about the batteries. We compared the gradient boosting method with light gradient boosting, extra trees, extreme gradient boosting, random forests, long short-term memory networks and with combined convolutional neural network and long short-term memory networks methods. We used multiple predictors and lagged target signal decomposition results as additional predictors and compared the yielded prediction results with different sets of predictors for each method. For this work, we are in possession of a unique data set of 45 lithium-ion battery packs with large variation in the data. The best model that we derived was validated by a novel walk-forward algorithm that also calculates point-wise confidence intervals for the predictions; we yielded reasonable predictions and confidence intervals for the predictions. Furthermore, we verified this model against five other lithium-ion battery packs; the best model generalised to greater extent to this set of battery packs. The results about the final model suggest that we were able to enhance the results in respect to previously developed models. Moreover, we further validated the model for extracting cycle counts presented in our previous work with data from new forklifts; their battery packs completed around 3000 cycles in a 10-year service period, which corresponds to the cycle life for commercial Nickel-Cobalt-Manganese (NMC) cells.
* 16 pages, 10 figures and 10 tables
FireFly Autonomous Drone Project
Apr 15, 2021
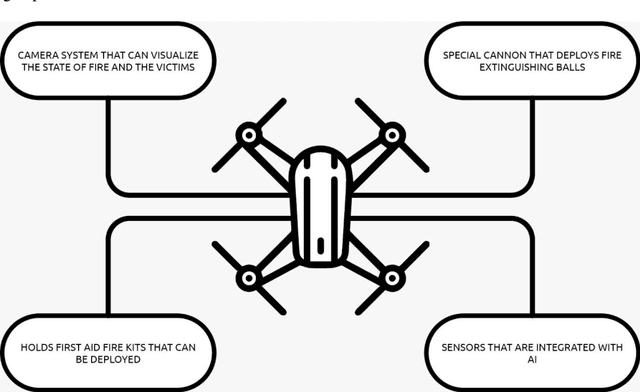
As a fire erupts, the first few minutes can be critical, and first respondents must race to the scene to analyze the situation and act fast before it gets out of hand. Factors such as road traffic condition and distance may not allow quick rescue operation using traditional means and methods, leading to unmanageable spreading of fire, injuries or even deaths that can be avoided. FireFly drone-based rescue consists of a squad of highly equipped drones that will be the first responders to the fire site. Their intervention will make the task of the fire rescue team much more effective and will contribute to reduce the overall damage. As soon as the fire is detected by in-building implanted sensors, the fire department would deploy a set of FireFly drones that would fly to the site, scan the building, and send live fire status information to the Fire fighter team. The drones would have the ability to identify trapped humans using AI based pattern recognition tools (using sensors and thermal cameras) and then drop them rescue kits as appropriate. The drones will also be equipped with fire detection and recognition capabilities and be able to drop fire extinguishing balls as first attempts to put off seeds of fires before they evolve. The integration of drones with firefighting will allow for ease of access and control of fire outbreaks. Drones will also result in increased response time, prevention of further damage, and allow relaying of vital information to out of reach places regarding the characteristics of the fire scene.
Restore from Restored: Single-image Inpainting
Feb 16, 2021
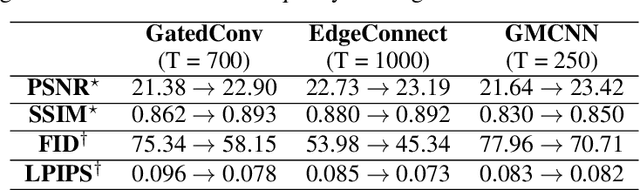
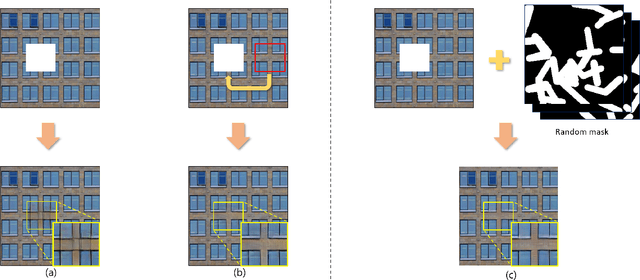
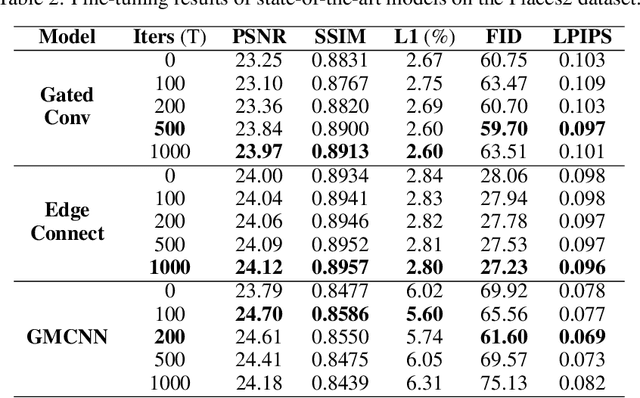
Recent image inpainting methods show promising results due to the power of deep learning, which can explore external information available from a large training dataset. However, many state-of-the-art inpainting networks are still limited in exploiting internal information available in the given input image at test time. To mitigate this problem, we present a novel and efficient self-supervised fine-tuning algorithm that can adapt the parameters of fully pretrained inpainting networks without using ground-truth clean image in this work. We upgrade the parameters of the pretrained networks by utilizing existing self-similar patches within the given input image without changing network architectures. Qualitative and quantitative experimental results demonstrate the superiority of the proposed algorithm and we achieve state-of-the-art inpainting results on publicly available numerous benchmark datasets.
Model-based Safe Reinforcement Learning using Generalized Control Barrier Function
Mar 02, 2021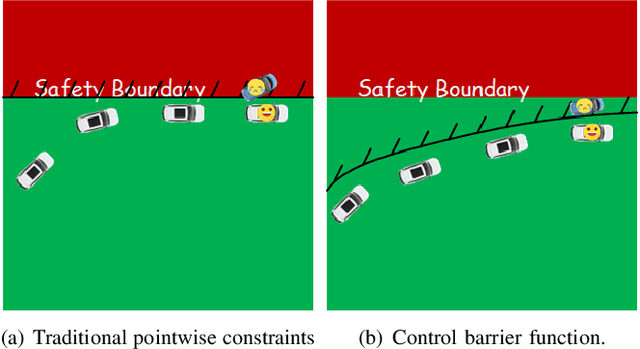
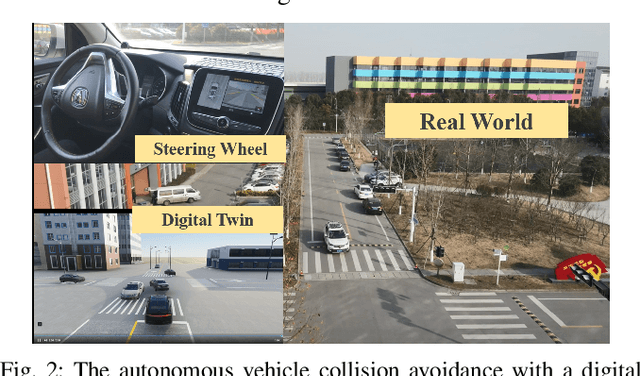
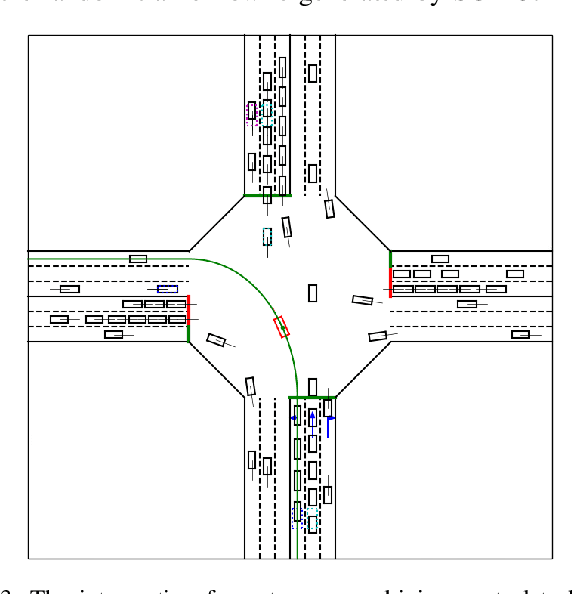
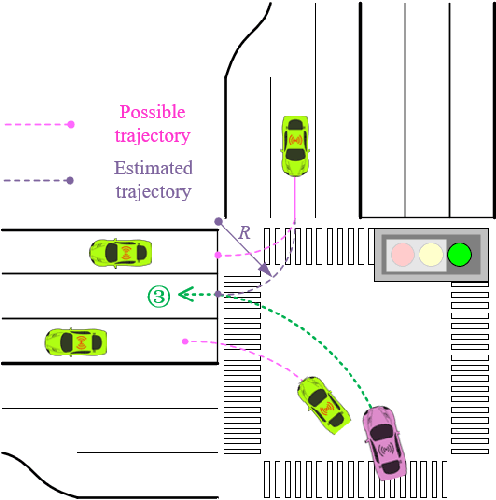
Model information can be used to predict future trajectories, so it has huge potential to avoid dangerous region when implementing reinforcement learning (RL) on real-world tasks, like autonomous driving. However, existing studies mostly use model-free constrained RL, which causes inevitable constraint violations. This paper proposes a model-based feasibility enhancement technique of constrained RL, which enhances the feasibility of policy using generalized control barrier function (GCBF) defined on the distance to constraint boundary. By using the model information, the policy can be optimized safely without violating actual safety constraints, and the sample efficiency is increased. The major difficulty of infeasibility in solving the constrained policy gradient is handled by an adaptive coefficient mechanism. We evaluate the proposed method in both simulations and real vehicle experiments in a complex autonomous driving collision avoidance task. The proposed method achieves up to four times fewer constraint violations and converges 3.36 times faster than baseline constrained RL approaches.
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
Jul 01, 2021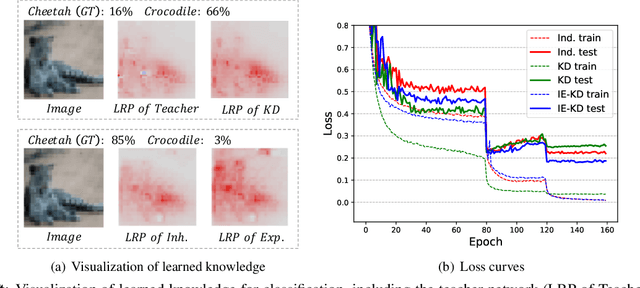

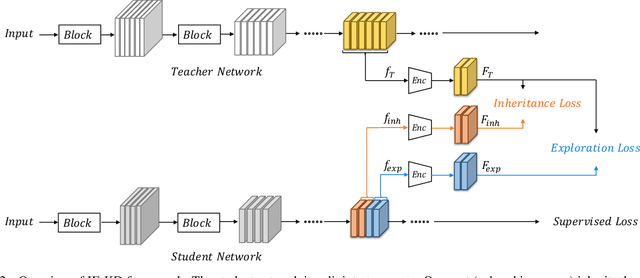

Knowledge Distillation (KD) is a popular technique to transfer knowledge from a teacher model or ensemble to a student model. Its success is generally attributed to the privileged information on similarities/consistency between the class distributions or intermediate feature representations of the teacher model and the student model. However, directly pushing the student model to mimic the probabilities/features of the teacher model to a large extent limits the student model in learning undiscovered knowledge/features. In this paper, we propose a novel inheritance and exploration knowledge distillation framework (IE-KD), in which a student model is split into two parts - inheritance and exploration. The inheritance part is learned with a similarity loss to transfer the existing learned knowledge from the teacher model to the student model, while the exploration part is encouraged to learn representations different from the inherited ones with a dis-similarity loss. Our IE-KD framework is generic and can be easily combined with existing distillation or mutual learning methods for training deep neural networks. Extensive experiments demonstrate that these two parts can jointly push the student model to learn more diversified and effective representations, and our IE-KD can be a general technique to improve the student network to achieve SOTA performance. Furthermore, by applying our IE-KD to the training of two networks, the performance of both can be improved w.r.t. deep mutual learning. The code and models of IE-KD will be make publicly available at https://github.com/yellowtownhz/IE-KD.
Attend and Select: A Segment Attention based Selection Mechanism for Microblog Hashtag Generation
Jun 06, 2021

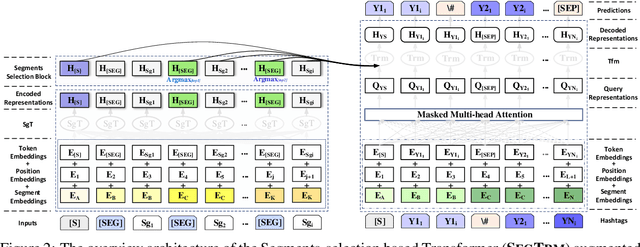
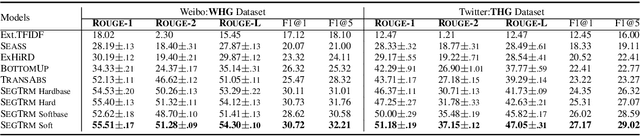
Automatic microblog hashtag generation can help us better and faster understand or process the critical content of microblog posts. Conventional sequence-to-sequence generation methods can produce phrase-level hashtags and have achieved remarkable performance on this task. However, they are incapable of filtering out secondary information and not good at capturing the discontinuous semantics among crucial tokens. A hashtag is formed by tokens or phrases that may originate from various fragmentary segments of the original text. In this work, we propose an end-to-end Transformer-based generation model which consists of three phases: encoding, segments-selection, and decoding. The model transforms discontinuous semantic segments from the source text into a sequence of hashtags. Specifically, we introduce a novel Segments Selection Mechanism (SSM) for Transformer to obtain segmental representations tailored to phrase-level hashtag generation. Besides, we introduce two large-scale hashtag generation datasets, which are newly collected from Chinese Weibo and English Twitter. Extensive evaluations on the two datasets reveal our approach's superiority with significant improvements to extraction and generation baselines. The code and datasets are available at \url{https://github.com/OpenSUM/HashtagGen}.
Mini-batch graphs for robust image classification
Apr 22, 2021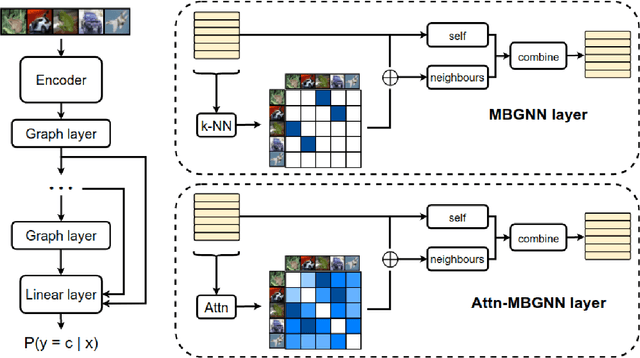
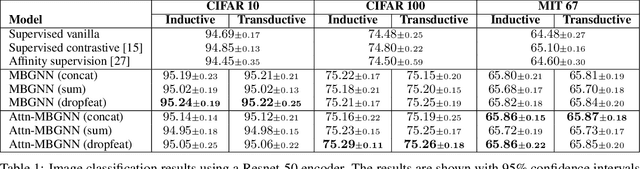
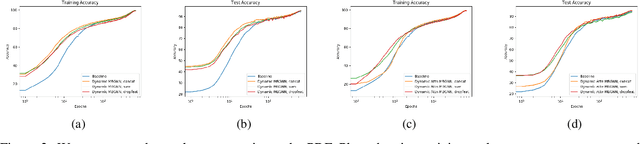

Current deep learning models for classification tasks in computer vision are trained using mini-batches. In the present article, we take advantage of the relationships between samples in a mini-batch, using graph neural networks to aggregate information from similar images. This helps mitigate the adverse effects of alterations to the input images on classification performance. Diverse experiments on image-based object and scene classification show that this approach not only improves a classifier's performance but also increases its robustness to image perturbations and adversarial attacks. Further, we also show that mini-batch graph neural networks can help to alleviate the problem of mode collapse in Generative Adversarial Networks.
Few-Shot Human Motion Transfer by Personalized Geometry and Texture Modeling
Mar 26, 2021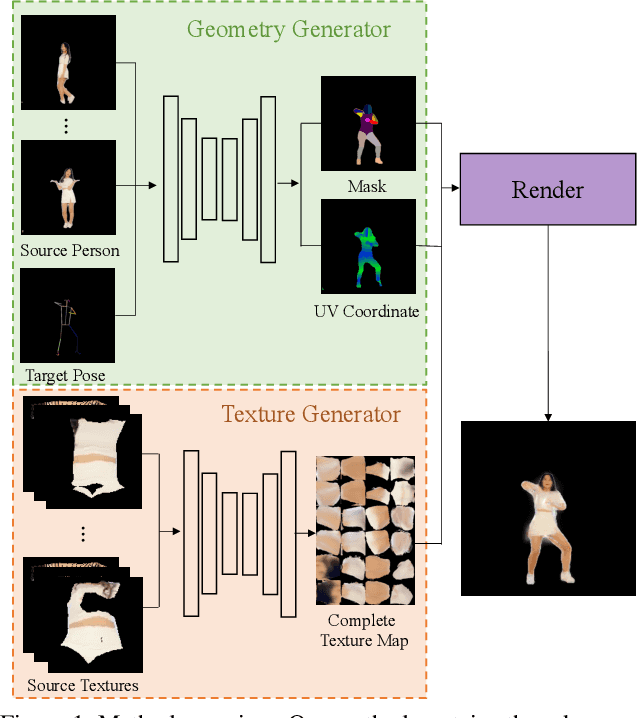

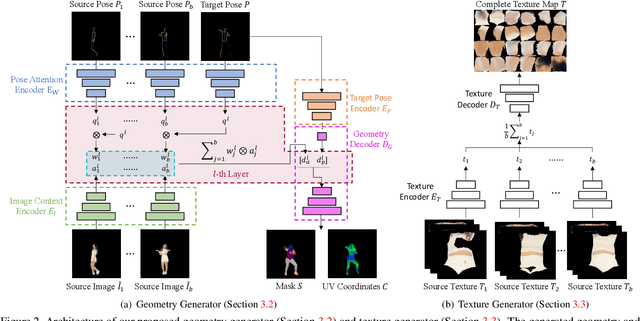
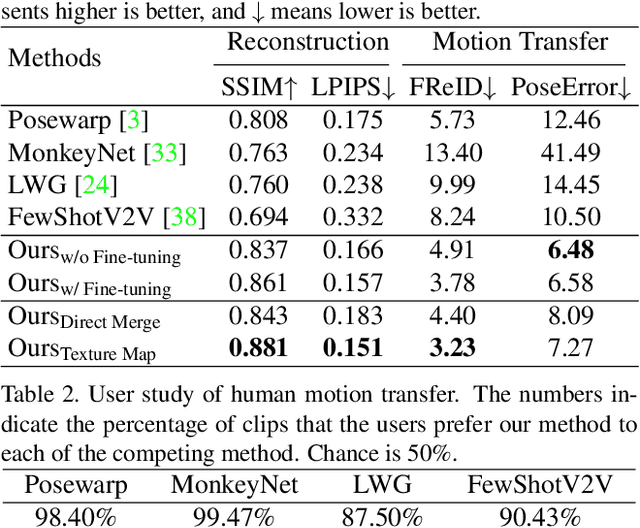
We present a new method for few-shot human motion transfer that achieves realistic human image generation with only a small number of appearance inputs. Despite recent advances in single person motion transfer, prior methods often require a large number of training images and take long training time. One promising direction is to perform few-shot human motion transfer, which only needs a few of source images for appearance transfer. However, it is particularly challenging to obtain satisfactory transfer results. In this paper, we address this issue by rendering a human texture map to a surface geometry (represented as a UV map), which is personalized to the source person. Our geometry generator combines the shape information from source images, and the pose information from 2D keypoints to synthesize the personalized UV map. A texture generator then generates the texture map conditioned on the texture of source images to fill out invisible parts. Furthermore, we may fine-tune the texture map on the manifold of the texture generator from a few source images at the test time, which improves the quality of the texture map without over-fitting or artifacts. Extensive experiments show the proposed method outperforms state-of-the-art methods both qualitatively and quantitatively. Our code is available at https://github.com/HuangZhiChao95/FewShotMotionTransfer.
Document Collection Visual Question Answering
Apr 27, 2021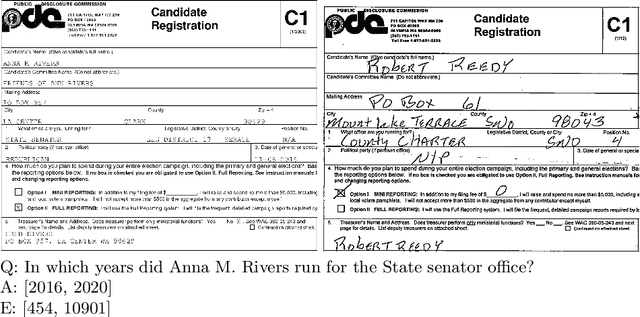
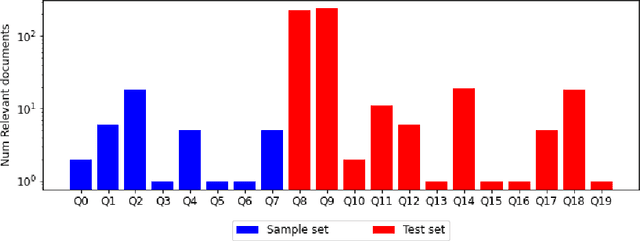


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.