 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-aware Deep Framework for Collaborative Skin Lesion Segmentation and Melanoma Recognition
Jun 07, 2021
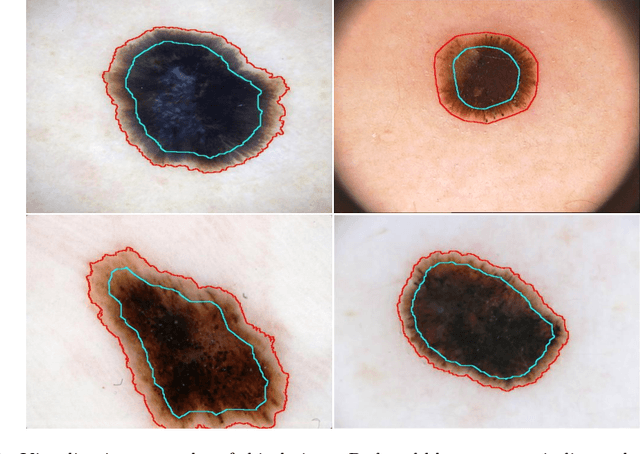
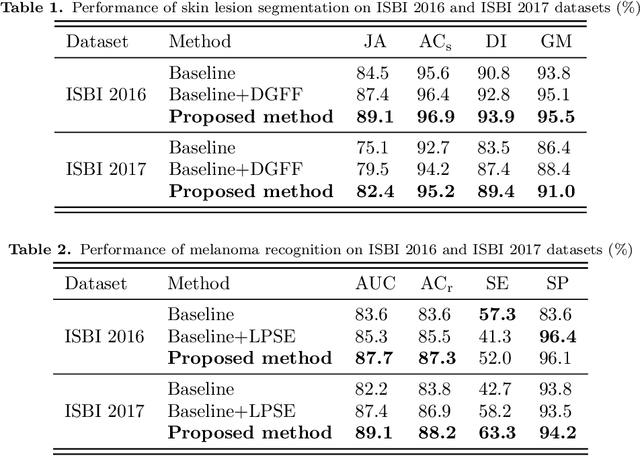
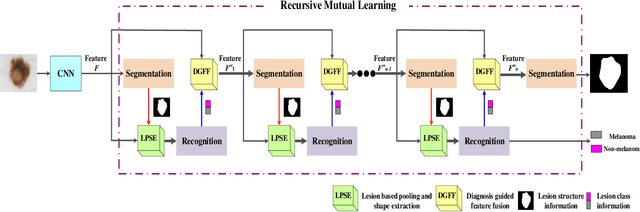
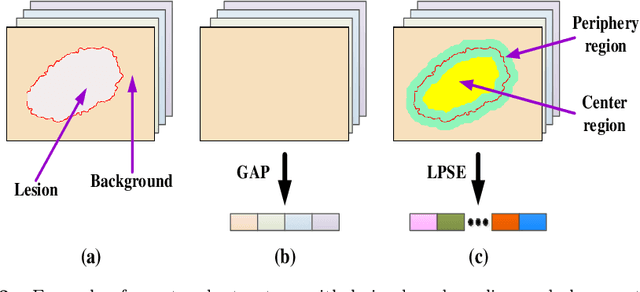
Deep learning techniques have shown their superior performance in dermatologist clinical inspection. Nevertheless, melanoma diagnosis is still a challenging task due to the difficulty of incorporating the useful dermatologist clinical knowledge into the learning process. In this paper, we propose a novel knowledge-aware deep framework that incorporates some clinical knowledge into collaborative learning of two important melanoma diagnosis tasks, i.e., skin lesion segmentation and melanoma recognition. Specifically, to exploit the knowledge of morphological expressions of the lesion region and also the periphery region for melanoma identification, a lesion-based pooling and shape extraction (LPSE) scheme is designed, which transfers the structure information obtained from skin lesion segmentation into melanoma recognition. Meanwhile, to pass the skin lesion diagnosis knowledge from melanoma recognition to skin lesion segmentation, an effective diagnosis guided feature fusion (DGFF) strategy is designed. Moreover, we propose a recursive mutual learning mechanism that further promotes the inter-task cooperation, and thus iteratively improves the joint learning capability of the model for both skin lesion segmentation and melanoma recognition. Experimental results on two publicly available skin lesion datasets show the effectiveness of the proposed method for melanoma analysis.
Recent Advances in Video Question Answering: A Review of Datasets and Methods
Jan 15, 2021
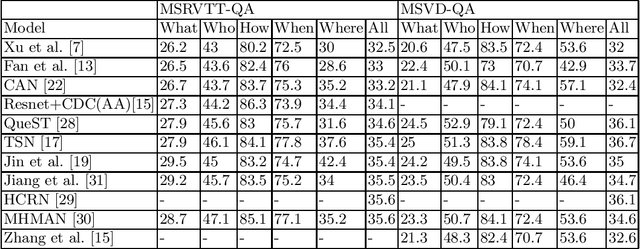
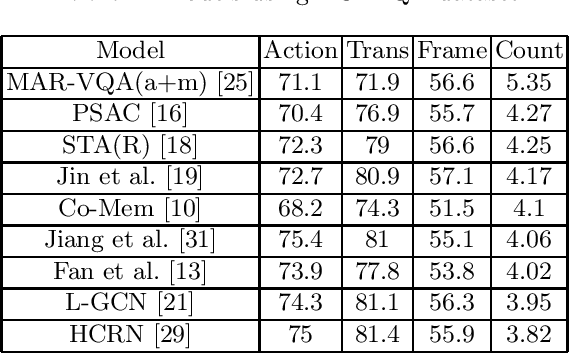
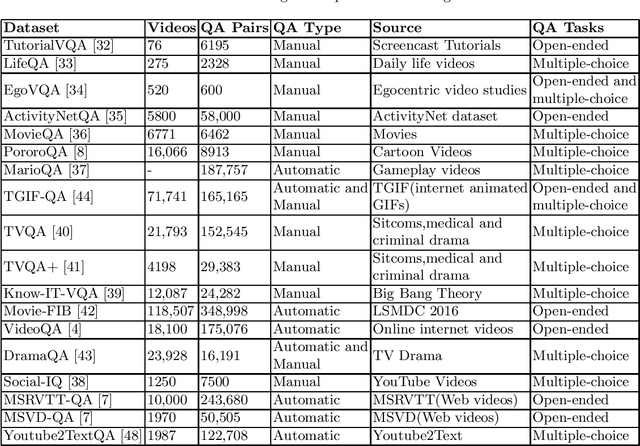
Video Question Answering (VQA) is a recent emerging challenging task in the field of Computer Vision. Several visual information retrieval techniques like Video Captioning/Description and Video-guided Machine Translation have preceded the task of VQA. VQA helps to retrieve temporal and spatial information from the video scenes and interpret it. In this survey, we review a number of methods and datasets for the task of VQA. To the best of our knowledge, no previous survey has been conducted for the VQA task.
Quality-Aware Memory Network for Interactive Volumetric Image Segmentation
Jun 20, 2021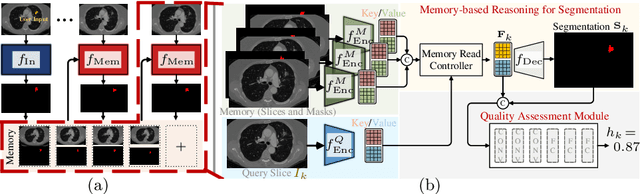
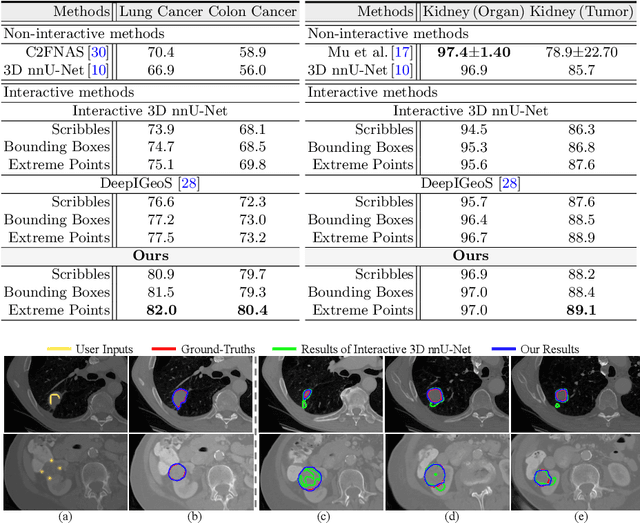
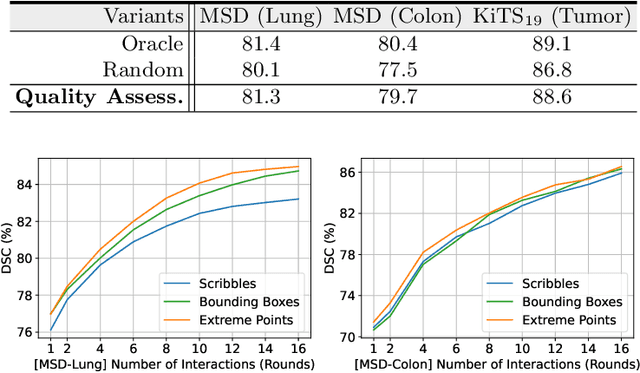
Despite recent progress of automatic medical image segmentation techniques, fully automatic results usually fail to meet the clinical use and typically require further refinement. In this work, we propose a quality-aware memory network for interactive segmentation of 3D medical images. Provided by user guidance on an arbitrary slice, an interaction network is firstly employed to obtain an initial 2D segmentation. The quality-aware memory network subsequently propagates the initial segmentation estimation bidirectionally over the entire volume. Subsequent refinement based on additional user guidance on other slices can be incorporated in the same manner. To further facilitate interactive segmentation, a quality assessment module is introduced to suggest the next slice to segment based on the current segmentation quality of each slice. The proposed network has two appealing characteristics: 1) The memory-augmented network offers the ability to quickly encode past segmentation information, which will be retrieved for the segmentation of other slices; 2) The quality assessment module enables the model to directly estimate the qualities of segmentation predictions, which allows an active learning paradigm where users preferentially label the lowest-quality slice for multi-round refinement. The proposed network leads to a robust interactive segmentation engine, which can generalize well to various types of user annotations (e.g., scribbles, boxes). Experimental results on various medical datasets demonstrate the superiority of our approach in comparison with existing techniques.
On the Skew-Symmetric Binary Sequences and the Merit Factor Problem
Jun 07, 2021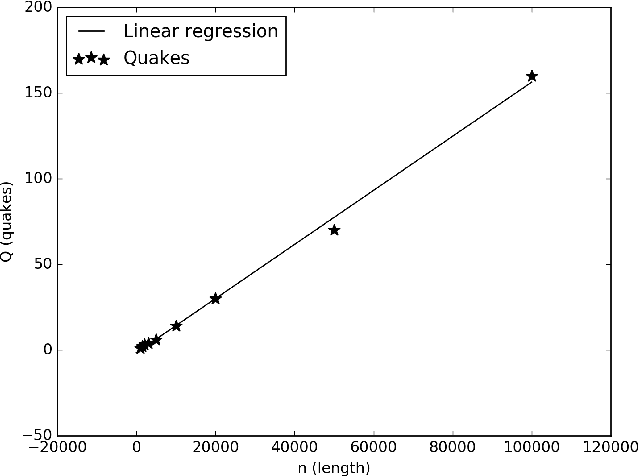
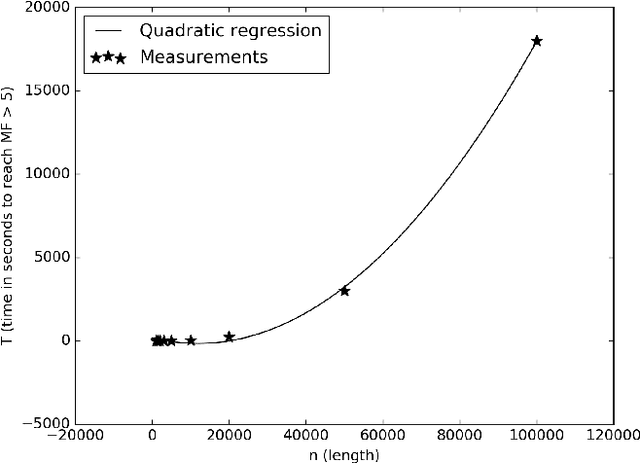
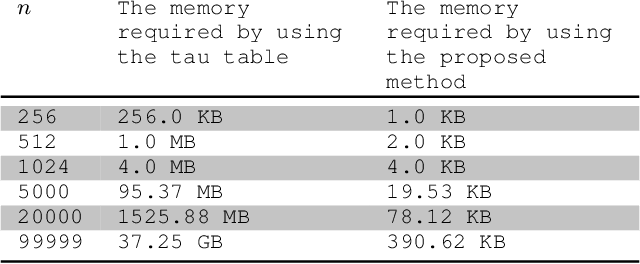
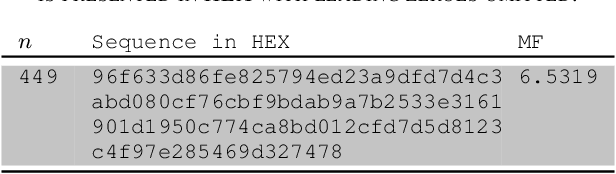
The merit factor problem is of practical importance to manifold domains, such as digital communications engineering, radars, system modulation, system testing, information theory, physics, chemistry. However, the merit factor problem is referenced as one of the most difficult optimization problems and it was further conjectured that stochastic search procedures will not yield merit factors higher than 5 for long binary sequences (sequences with lengths greater than 200). Some useful mathematical properties related to the flip operation of the skew-symmetric binary sequences are presented in this work. By exploiting those properties, the memory complexity of state-of-the-art stochastic merit factor optimization algorithms could be reduced from $O(n^2)$ to $O(n)$. As a proof of concept, a lightweight stochastic algorithm was constructed, which can optimize pseudo-randomly generated skew-symmetric binary sequences with long lengths (up to ${10}^5+1$) to skew-symmetric binary sequences with a merit factor greater than 5. An approximation of the required time is also provided. The numerical experiments suggest that the algorithm is universal and could be applied to skew-symmetric binary sequences with arbitrary lengths.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021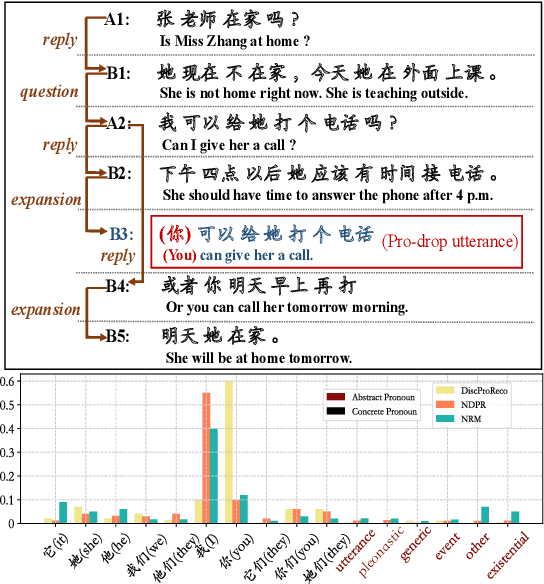
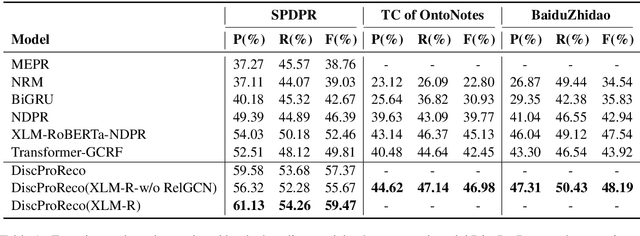
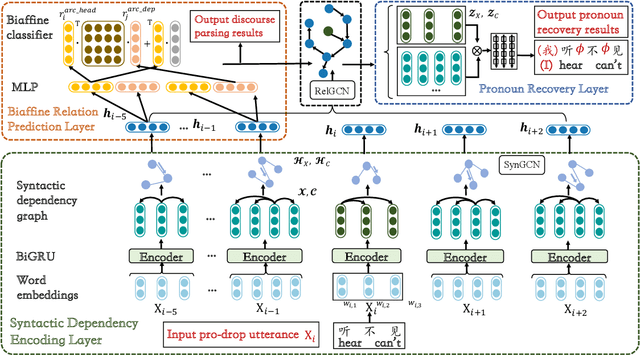
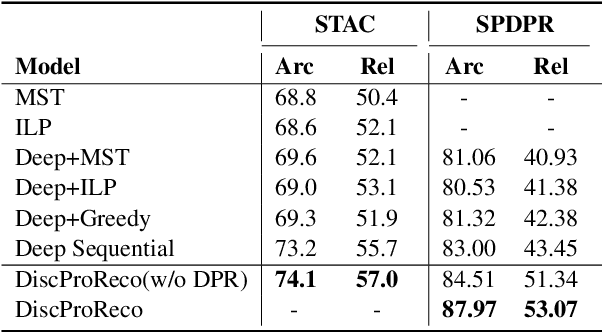
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Dogfight: Detecting Drones from Drones Videos
Apr 09, 2021
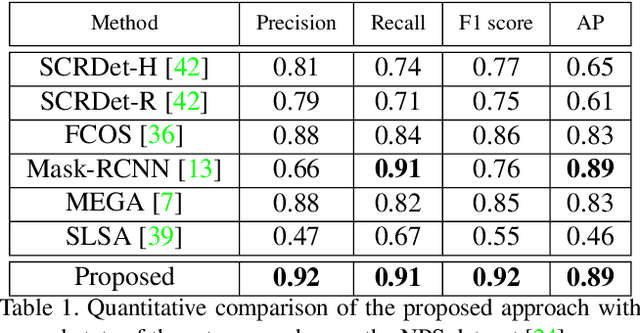
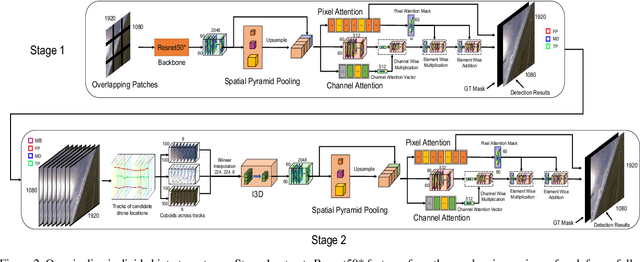
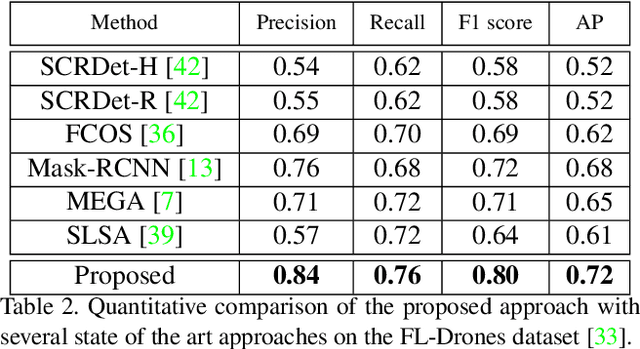
As airborne vehicles are becoming more autonomous and ubiquitous, it has become vital to develop the capability to detect the objects in their surroundings. This paper attempts to address the problem of drones detection from other flying drones. The erratic movement of the source and target drones, small size, arbitrary shape, large intensity variations, and occlusion make this problem quite challenging. In this scenario, region-proposal based methods are not able to capture sufficient discriminative foreground-background information. Also, due to the extremely small size and complex motion of the source and target drones, feature aggregation based methods are unable to perform well. To handle this, instead of using region-proposal based methods, we propose to use a two-stage segmentation-based approach employing spatio-temporal attention cues. During the first stage, given the overlapping frame regions, detailed contextual information is captured over convolution feature maps using pyramid pooling. After that pixel and channel-wise attention is enforced on the feature maps to ensure accurate drone localization. In the second stage, first stage detections are verified and new probable drone locations are explored. To discover new drone locations, motion boundaries are used. This is followed by tracking candidate drone detections for a few frames, cuboid formation, extraction of the 3D convolution feature map, and drones detection within each cuboid. The proposed approach is evaluated on two publicly available drone detection datasets and outperforms several competitive baselines.
Learning Signal Representations for EEG Cross-Subject Channel Selection and Trial Classification
Jun 20, 2021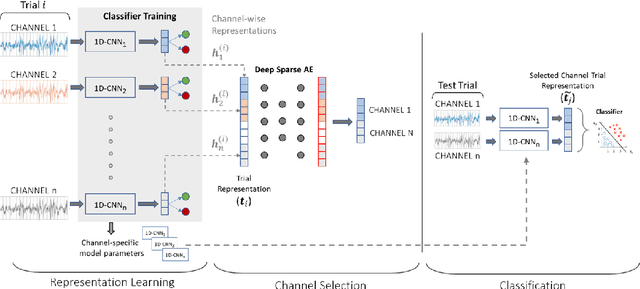
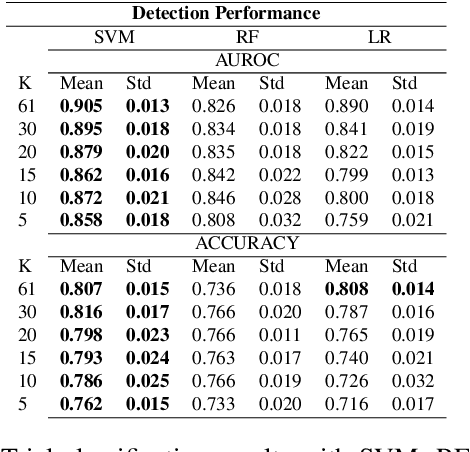
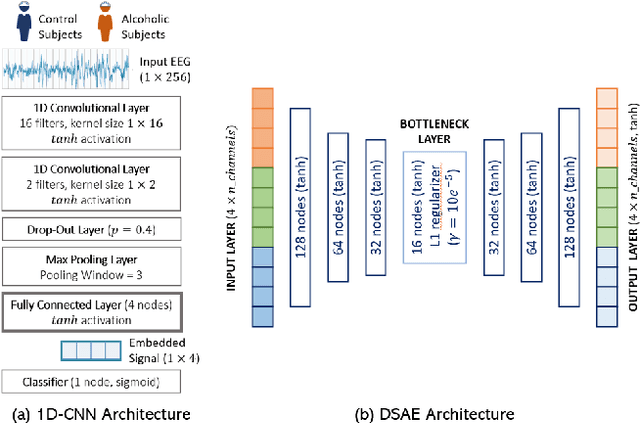
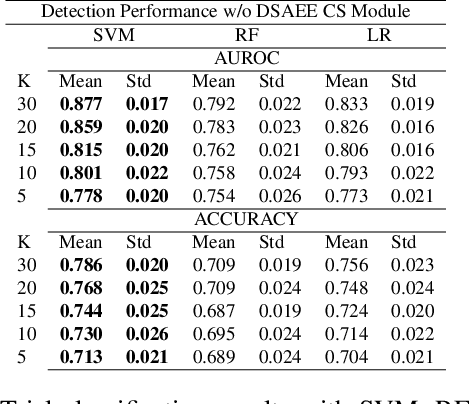
EEG technology finds applications in several domains. Currently, most EEG systems require subjects to wear several electrodes on the scalp to be effective. However, several channels might include noisy information, redundant signals, induce longer preparation times and increase computational times of any automated system for EEG decoding. One way to reduce the signal-to-noise ratio and improve classification accuracy is to combine channel selection with feature extraction, but EEG signals are known to present high inter-subject variability. In this work we introduce a novel algorithm for subject-independent channel selection of EEG recordings. Considering multi-channel trial recordings as statistical units and the EEG decoding task as the class of reference, the algorithm (i) exploits channel-specific 1D-Convolutional Neural Networks (1D-CNNs) as feature extractors in a supervised fashion to maximize class separability; (ii) it reduces a high dimensional multi-channel trial representation into a unique trial vector by concatenating the channels' embeddings and (iii) recovers the complex inter-channel relationships during channel selection, by exploiting an ensemble of AutoEncoders (AE) to identify from these vectors the most relevant channels to perform classification. After training, the algorithm can be exploited by transferring only the parametrized subgroup of selected channel-specific 1D-CNNs to new signals from new subjects and obtain low-dimensional and highly informative trial vectors to be fed to any classifier.
Level-aware Haze Image Synthesis by Self-Supervised Content-Style Disentanglement
Mar 11, 2021
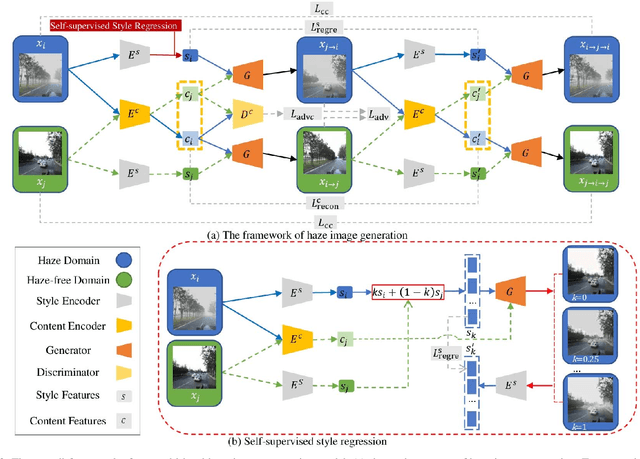
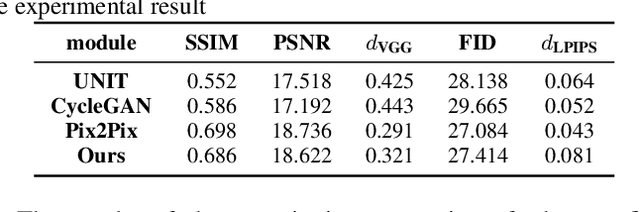
The key procedure of haze image translation through adversarial training lies in the disentanglement between the feature only involved in haze synthesis, i.e.style feature, and the feature representing the invariant semantic content, i.e. content feature. Previous methods separate content feature apart by utilizing it to classify haze image during the training process. However, in this paper we recognize the incompleteness of the content-style disentanglement in such technical routine. The flawed style feature entangled with content information inevitably leads the ill-rendering of the haze images. To address, we propose a self-supervised style regression via stochastic linear interpolation to reduce the content information in style feature. The ablative experiments demonstrate the disentangling completeness and its superiority in level-aware haze image synthesis. Moreover, the generated haze data are applied in the testing generalization of vehicle detectors. Further study between haze-level and detection performance shows that haze has obvious impact on the generalization of the vehicle detectors and such performance degrading level is linearly correlated to the haze-level, which, in turn, validates the effectiveness of the proposed method.
All Together Now: Teachers as Research Partners in the Design of Search Technology for the Classroom
May 08, 2021In the classroom environment, search tools are the means for students to access Web resources. The perspectives of students, researchers, and industry practitioners lead the ongoing research debate in this area. In this article, we argue in favor of incorporating a new voice into this debate: teachers. We showcase the value of involving teachers in all aspects related to the design of search tools for the classroom; from the beginning till the end. Driven by our research experience designing, developing, and evaluating new tools to support children's information discovery in the classroom, we share insights on the role of the experts-in-the-loop, i.e., teachers who provide the connection between search tools and students. And yes, in our case, always involving a teacher as a research partner.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021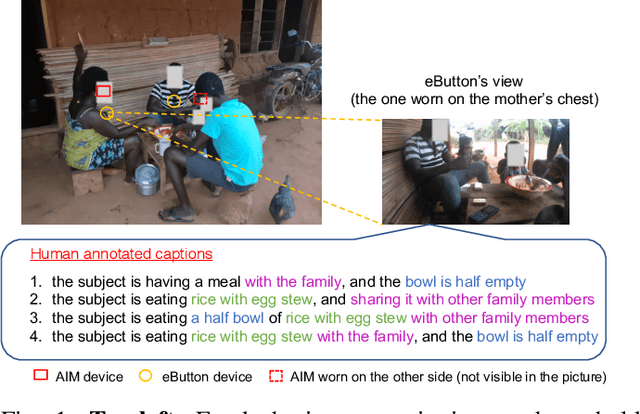
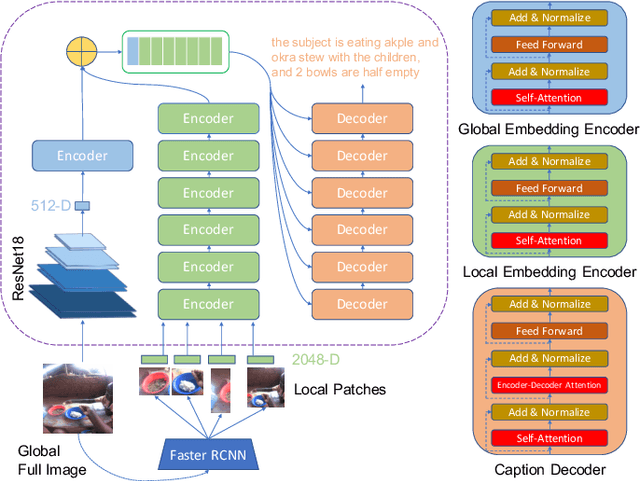
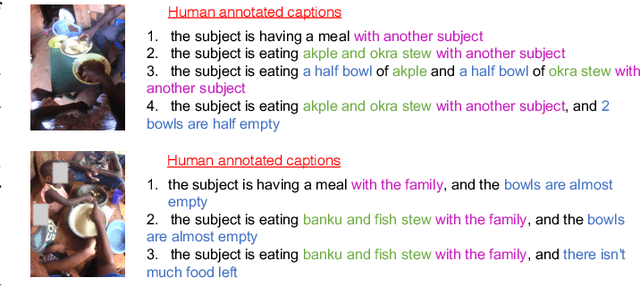
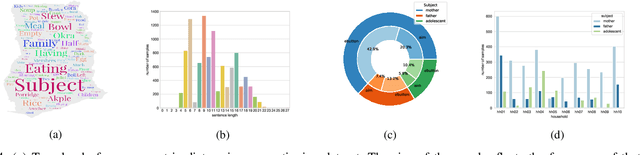
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.