 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 11, 2021
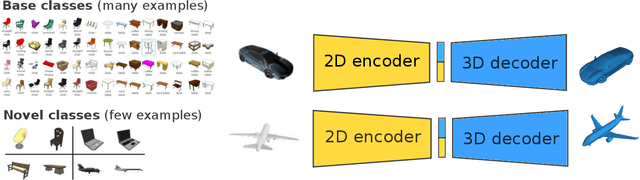
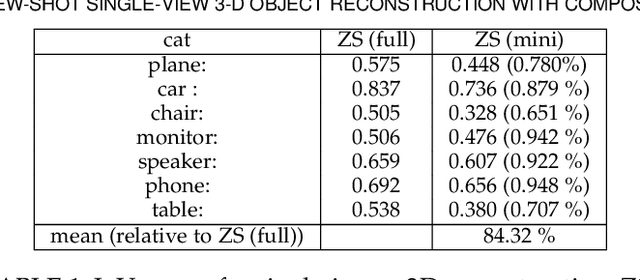
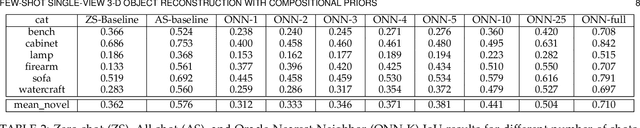
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.12
Ergodic imitation: Learning from what to do and what not to do
Mar 31, 2021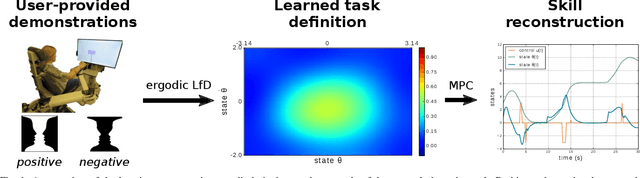
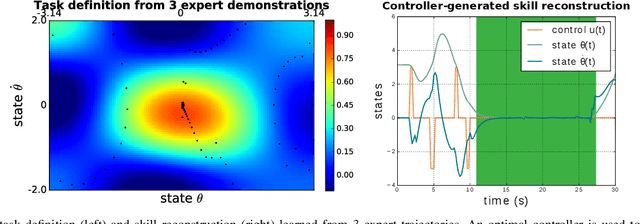
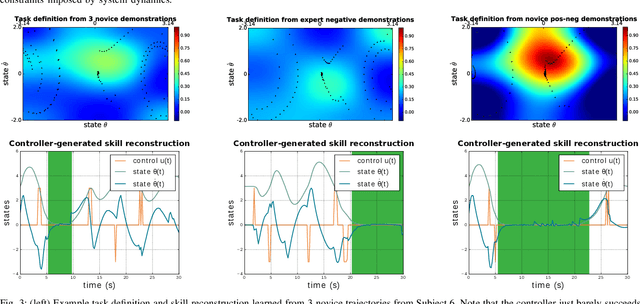
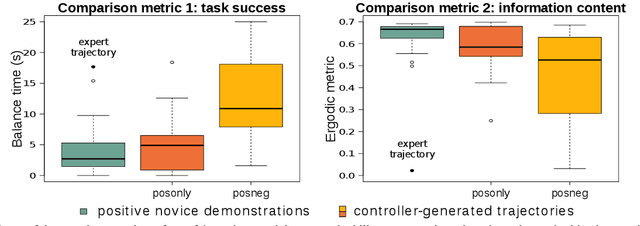
With growing access to versatile robotics, it is beneficial for end users to be able to teach robots tasks without needing to code a control policy. One possibility is to teach the robot through successful task executions. However, near-optimal demonstrations of a task can be difficult to provide and even successful demonstrations can fail to capture task aspects key to robust skill replication. Here, we propose a learning from demonstration (LfD) approach that enables learning of robust task definitions without the need for near-optimal demonstrations. We present a novel algorithmic framework for learning tasks based on the ergodic metric -- a measure of information content in motion. Moreover, we make use of negative demonstrations -- demonstrations of what not to do -- and show that they can help compensate for imperfect demonstrations, reduce the number of demonstrations needed, and highlight crucial task elements improving robot performance. In a proof-of-concept example of cart-pole inversion, we show that negative demonstrations alone can be sufficient to successfully learn and recreate a skill. Through a human subject study with 24 participants, we show that consistently more information about a task can be captured from combined positive and negative (posneg) demonstrations than from the same amount of just positive demonstrations. Finally, we demonstrate our learning approach on simulated tasks of target reaching and table cleaning with a 7-DoF Franka arm. Our results point towards a future with robust, data-efficient LfD for novice users.
* Kalinowska and Prabhakar contributed equally to this work
Memory compression and thermal efficiency of quantum implementations of non-deterministic hidden Markov models
May 13, 2021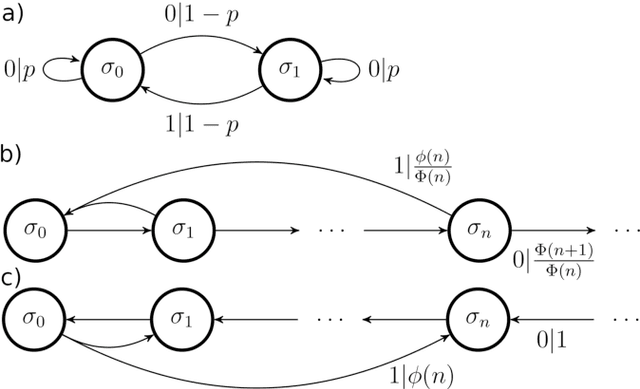
Stochastic modelling is an essential component of the quantitative sciences, with hidden Markov models (HMMs) often playing a central role. Concurrently, the rise of quantum technologies promises a host of advantages in computational problems, typically in terms of the scaling of requisite resources such as time and memory. HMMs are no exception to this, with recent results highlighting quantum implementations of deterministic HMMs exhibiting superior memory and thermal efficiency relative to their classical counterparts. In many contexts however, non-deterministic HMMs are viable alternatives; compared to them the advantages of current quantum implementations do not always hold. Here, we provide a systematic prescription for constructing quantum implementations of non-deterministic HMMs that re-establish the quantum advantages against this broader class. Crucially, we show that whenever the classical implementation suffers from thermal dissipation due to its need to process information in a time-local manner, our quantum implementations will both mitigate some of this dissipation, and achieve an advantage in memory compression.
Holographic image reconstruction with phase recovery and autofocusing using recurrent neural networks
Feb 12, 2021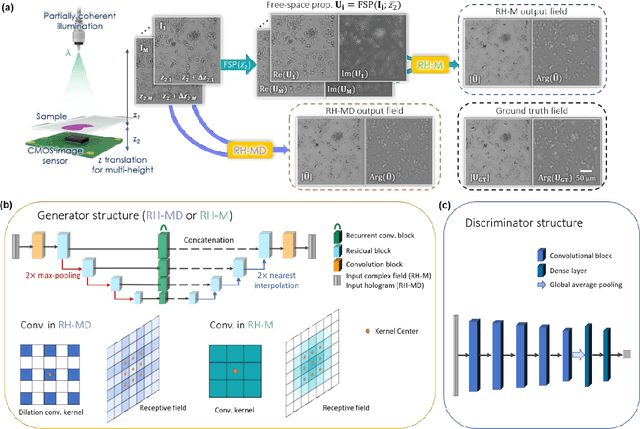
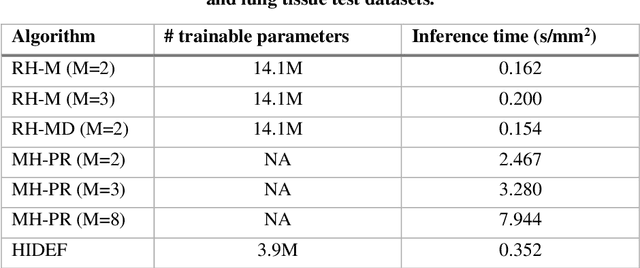
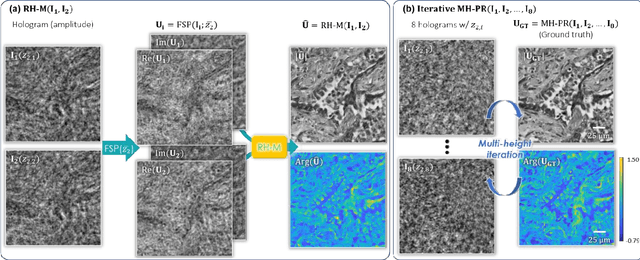
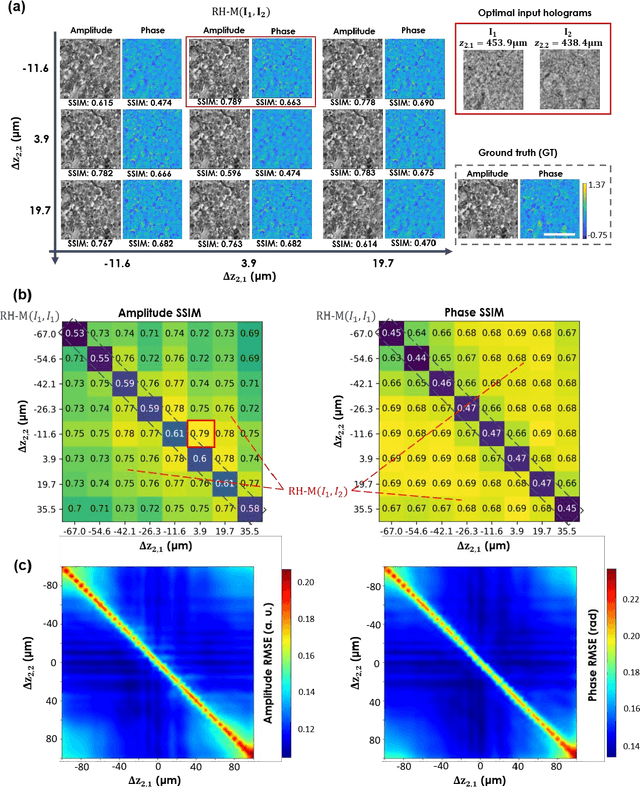
Digital holography is one of the most widely used label-free microscopy techniques in biomedical imaging. Recovery of the missing phase information of a hologram is an important step in holographic image reconstruction. Here we demonstrate a convolutional recurrent neural network (RNN) based phase recovery approach that uses multiple holograms, captured at different sample-to-sensor distances to rapidly reconstruct the phase and amplitude information of a sample, while also performing autofocusing through the same network. We demonstrated the success of this deep learning-enabled holography method by imaging microscopic features of human tissue samples and Papanicolaou (Pap) smears. These results constitute the first demonstration of the use of recurrent neural networks for holographic imaging and phase recovery, and compared with existing methods, the presented approach improves the reconstructed image quality, while also increasing the depth-of-field and inference speed.
The Local Approach to Causal Inference under Network Interference
May 09, 2021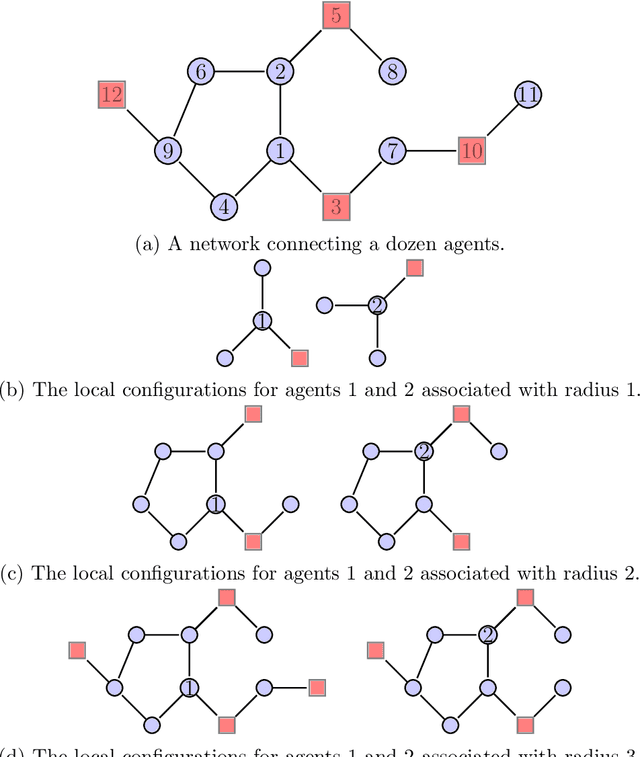
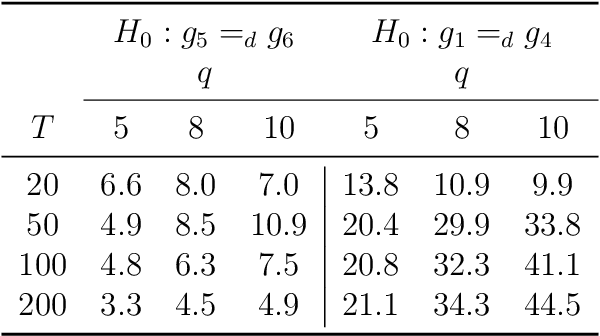
We propose a new unified framework for causal inference when outcomes depend on how agents are linked in a social or economic network. Such network interference describes a large literature on treatment spillovers, social interactions, social learning, information diffusion, social capital formation, and more. Our approach works by first characterizing how an agent is linked in the network using the configuration of other agents and connections nearby as measured by path distance. The impact of a policy or treatment assignment is then learned by pooling outcome data across similarly configured agents. In the paper, we propose a new nonparametric modeling approach and consider two applications to causal inference. The first application is to testing policy irrelevance/no treatment effects. The second application is to estimating policy effects/treatment response. We conclude by evaluating the finite-sample properties of our estimation and inference procedures via simulation.
Rhetorical relations for information retrieval
Apr 05, 2017

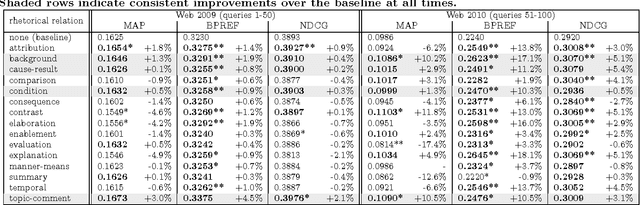
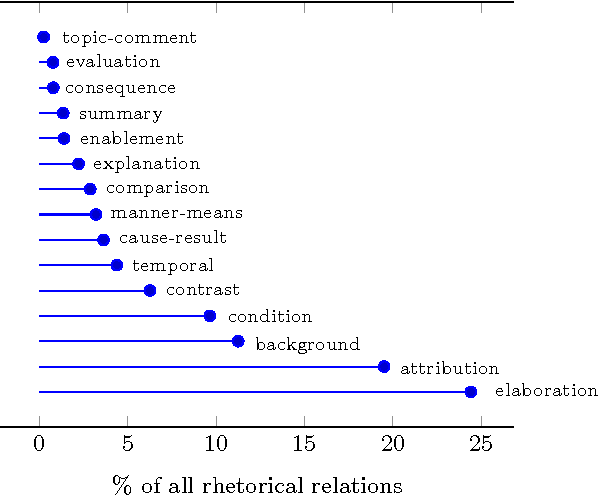
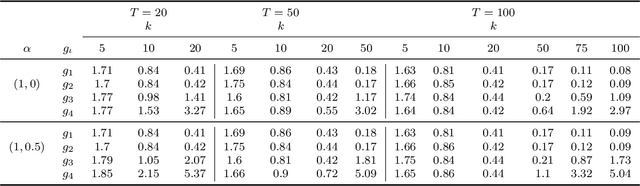
Typically, every part in most coherent text has some plausible reason for its presence, some function that it performs to the overall semantics of the text. Rhetorical relations, e.g. contrast, cause, explanation, describe how the parts of a text are linked to each other. Knowledge about this socalled discourse structure has been applied successfully to several natural language processing tasks. This work studies the use of rhetorical relations for Information Retrieval (IR): Is there a correlation between certain rhetorical relations and retrieval performance? Can knowledge about a document's rhetorical relations be useful to IR? We present a language model modification that considers rhetorical relations when estimating the relevance of a document to a query. Empirical evaluation of different versions of our model on TREC settings shows that certain rhetorical relations can benefit retrieval effectiveness notably (> 10% in mean average precision over a state-of-the-art baseline).
An RF-source-free microwave photonic radar with an optically injected semiconductor laser for high-resolution detection and imaging
Jun 11, 2021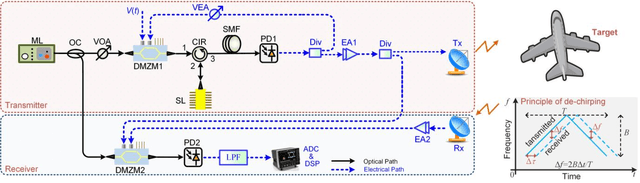
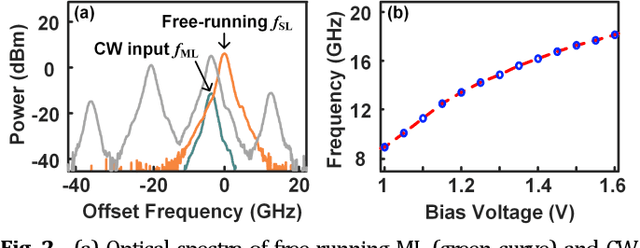
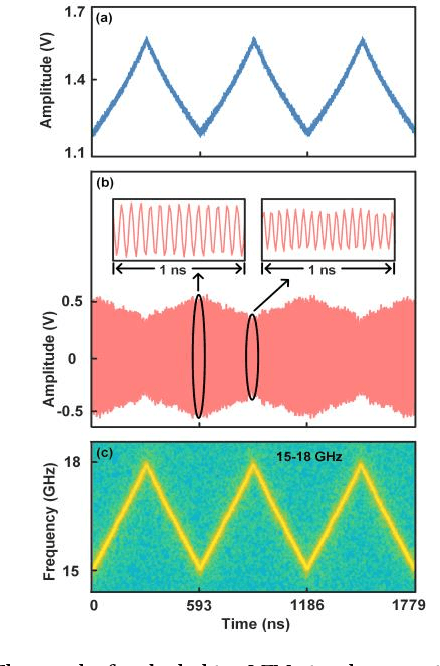
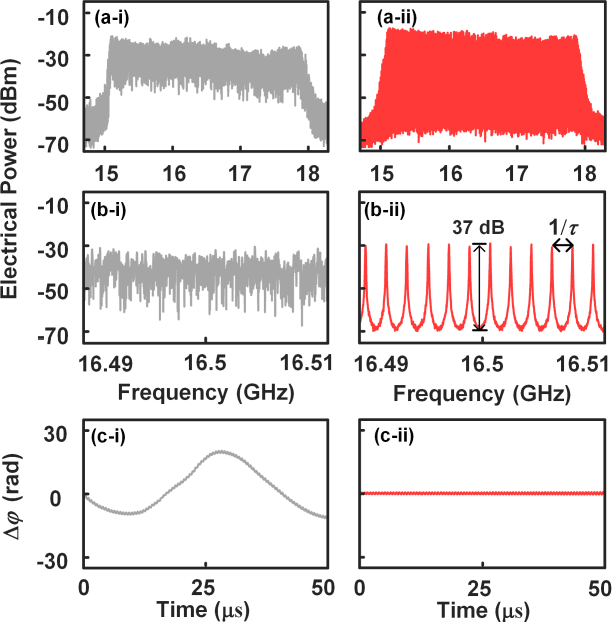
This paper presents a novel microwave photonic (MWP) radar scheme that is capable of optically generating and processing broadband linear frequency-modulated (LFM) microwave signals without using any radio-frequency (RF) sources. In the transmitter, a broadband LFM microwave signal is generated by controlling the period-one (P1) oscillation of an optically injected semiconductor laser. After targets reflection, photonic de-chirping is implemented based on a dual-drive Mach-Zehnder modulator (DMZM), which is followed by a low-speed analog-to-digital converter (ADC) and digital signal processer (DSP) to reconstruct target information. Without the limitations of external RF sources, the proposed radar has an ultra-flexible tunability, and the main operating parameters are adjustable, including central frequency, bandwidth, frequency band, and temporal period. In the experiment, a fully photonics-based Ku-band radar with a bandwidth of 4 GHz is established for high-resolution detection and inverse synthetic aperture radar (ISAR) imaging. Results show that a high range resolution reaching ~1.88 cm, and a two-dimensional (2D) imaging resolution as high as ~1.88 cm x ~2.00 cm are achieved with a sampling rate of 100 MSa/s in the receiver. The flexible tunability of the radar is also experimentally investigated. The proposed radar scheme features low cost, simple structure, and high reconfigurability, which, hopefully, is to be used in future multifunction adaptive and miniaturized radars.
On the Effectiveness of Dataset Embeddings in Mono-lingual,Multi-lingual and Zero-shot Conditions
Mar 01, 2021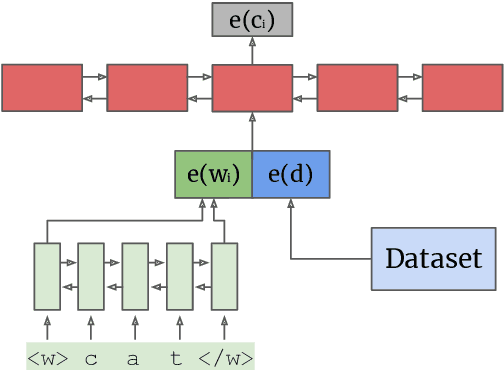

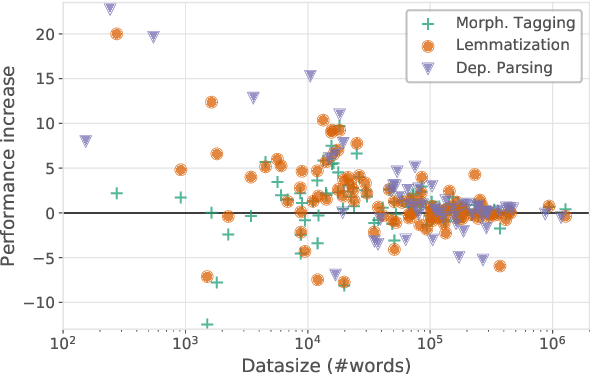
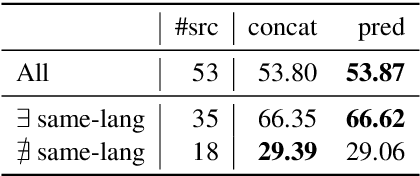
Recent complementary strands of research have shown that leveraging information on the data source through encoding their properties into embeddings can lead to performance increase when training a single model on heterogeneous data sources. However, it remains unclear in which situations these dataset embeddings are most effective, because they are used in a large variety of settings, languages and tasks. Furthermore, it is usually assumed that gold information on the data source is available, and that the test data is from a distribution seen during training. In this work, we compare the effect of dataset embeddings in mono-lingual settings, multi-lingual settings, and with predicted data source label in a zero-shot setting. We evaluate on three morphosyntactic tasks: morphological tagging, lemmatization, and dependency parsing, and use 104 datasets, 66 languages, and two different dataset grouping strategies. Performance increases are highest when the datasets are of the same language, and we know from which distribution the test-instance is drawn. In contrast, for setups where the data is from an unseen distribution, performance increase vanishes.
Deep Unsupervised Hashing by Distilled Smooth Guidance
May 13, 2021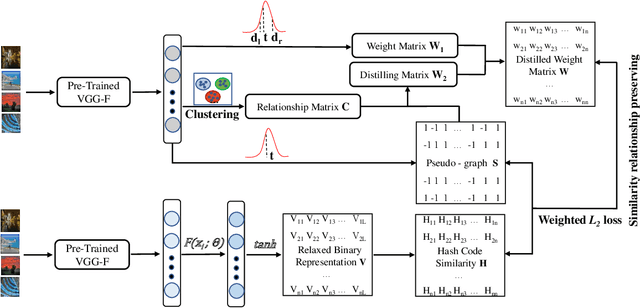
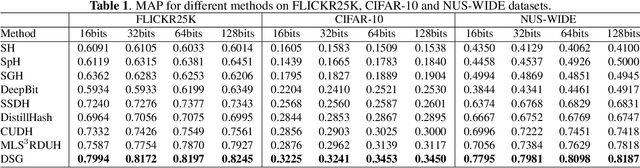

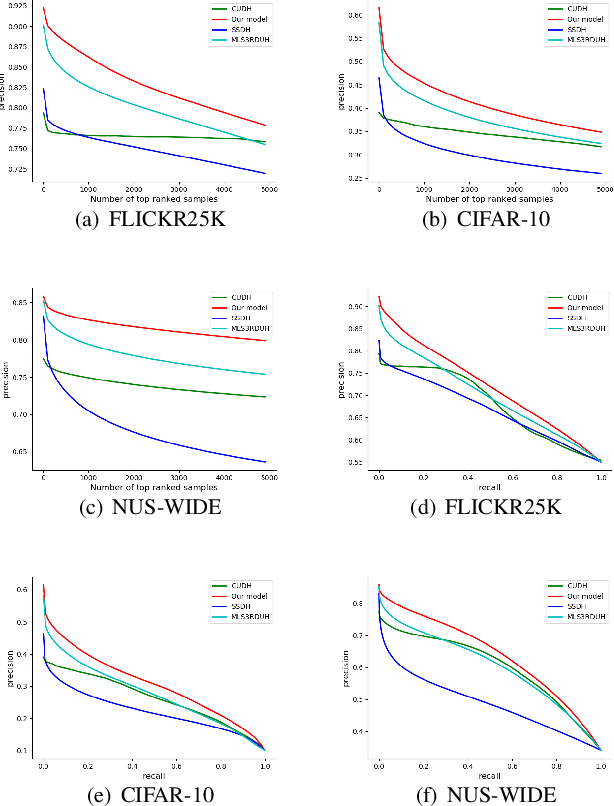
Hashing has been widely used in approximate nearest neighbor search for its storage and computational efficiency. Deep supervised hashing methods are not widely used because of the lack of labeled data, especially when the domain is transferred. Meanwhile, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable similarity signals. To tackle this problem, we propose a novel deep unsupervised hashing method, namely Distilled Smooth Guidance (DSG), which can learn a distilled dataset consisting of similarity signals as well as smooth confidence signals. To be specific, we obtain the similarity confidence weights based on the initial noisy similarity signals learned from local structures and construct a priority loss function for smooth similarity-preserving learning. Besides, global information based on clustering is utilized to distill the image pairs by removing contradictory similarity signals. Extensive experiments on three widely used benchmark datasets show that the proposed DSG consistently outperforms the state-of-the-art search methods.
* 7 pages, 3 figures
Gender Bias in Machine Translation
Apr 13, 2021
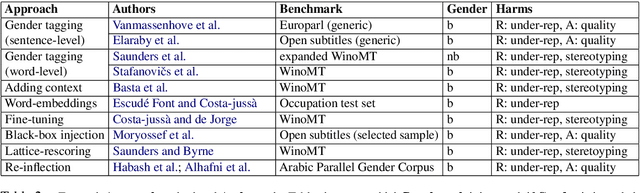
Machine translation (MT) technology has facilitated our daily tasks by providing accessible shortcuts for gathering, elaborating and communicating information. However, it can suffer from biases that harm users and society at large. As a relatively new field of inquiry, gender bias in MT still lacks internal cohesion, which advocates for a unified framework to ease future research. To this end, we: i)critically review current conceptualizations of bias in light of theoretical insights from related disciplines, ii) summarize previous analyses aimed at assessing gender bias in MT, iii)discuss the mitigating strategies proposed so far, and iv)point toward potential directions for future work.