 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 24, 2021
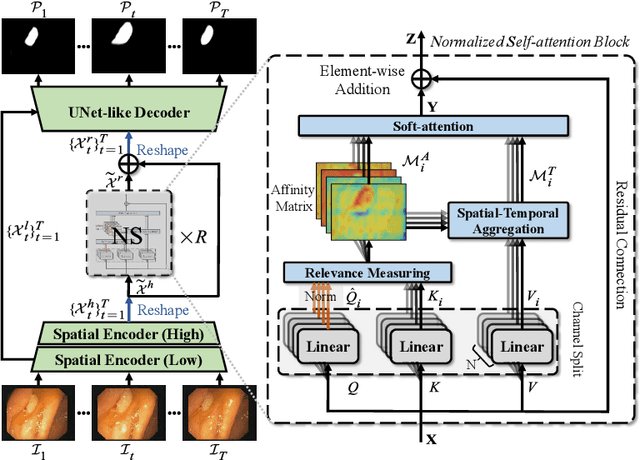
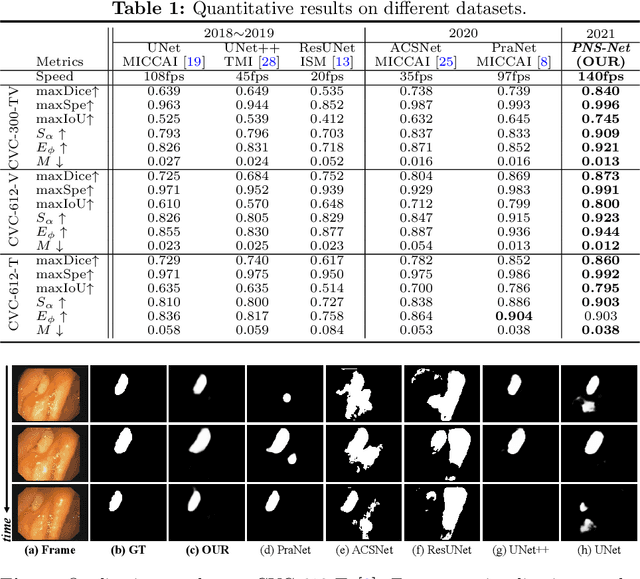
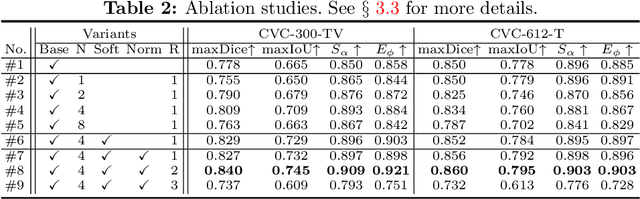
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
Directed Acyclic Graph Neural Networks
Feb 02, 2021



Graph-structured data ubiquitously appears in science and engineering. Graph neural networks (GNNs) are designed to exploit the relational inductive bias exhibited in graphs; they have been shown to outperform other forms of neural networks in scenarios where structure information supplements node features. The most common GNN architecture aggregates information from neighborhoods based on message passing. Its generality has made it broadly applicable. In this paper, we focus on a special, yet widely used, type of graphs -- DAGs -- and inject a stronger inductive bias -- partial ordering -- into the neural network design. We propose the \emph{directed acyclic graph neural network}, DAGNN, an architecture that processes information according to the flow defined by the partial order. DAGNN can be considered a framework that entails earlier works as special cases (e.g., models for trees and models updating node representations recurrently), but we identify several crucial components that prior architectures lack. We perform comprehensive experiments, including ablation studies, on representative DAG datasets (i.e., source code, neural architectures, and probabilistic graphical models) and demonstrate the superiority of DAGNN over simpler DAG architectures as well as general graph architectures.
An In-depth Study on Internal Structure of Chinese Words
Jun 01, 2021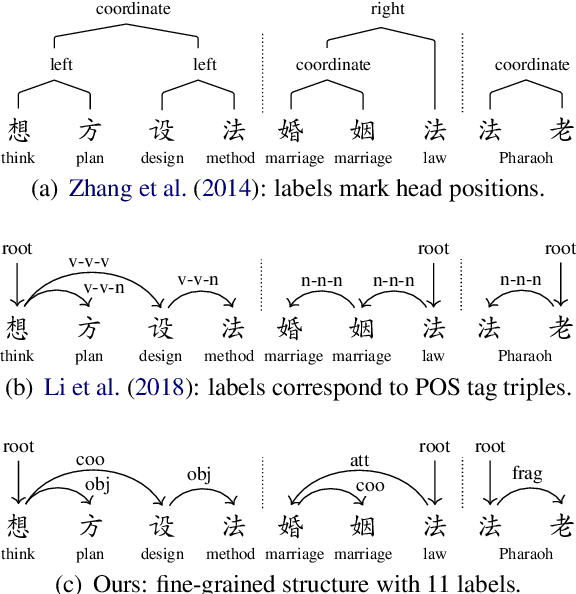
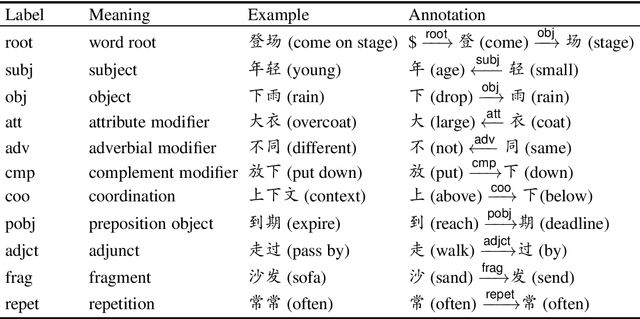
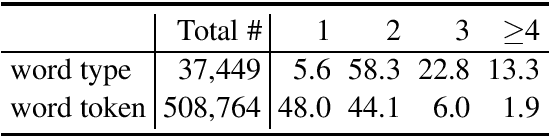
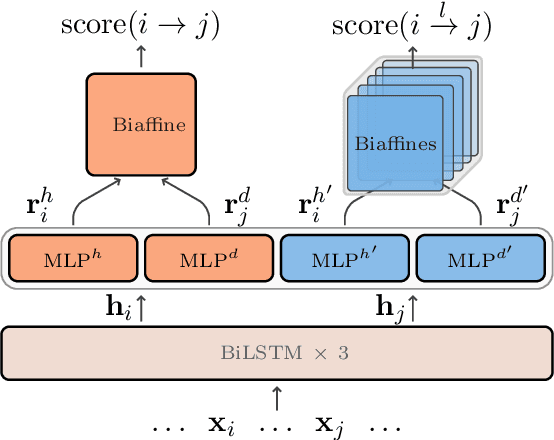
Unlike English letters, Chinese characters have rich and specific meanings. Usually, the meaning of a word can be derived from its constituent characters in some way. Several previous works on syntactic parsing propose to annotate shallow word-internal structures for better utilizing character-level information. This work proposes to model the deep internal structures of Chinese words as dependency trees with 11 labels for distinguishing syntactic relationships. First, based on newly compiled annotation guidelines, we manually annotate a word-internal structure treebank (WIST) consisting of over 30K multi-char words from Chinese Penn Treebank. To guarantee quality, each word is independently annotated by two annotators and inconsistencies are handled by a third senior annotator. Second, we present detailed and interesting analysis on WIST to reveal insights on Chinese word formation. Third, we propose word-internal structure parsing as a new task, and conduct benchmark experiments using a competitive dependency parser. Finally, we present two simple ways to encode word-internal structures, leading to promising gains on the sentence-level syntactic parsing task.
Sequential End-to-End Intent and Slot Label Classification and Localization
Jun 08, 2021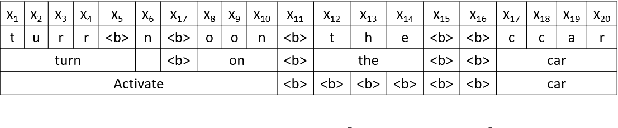

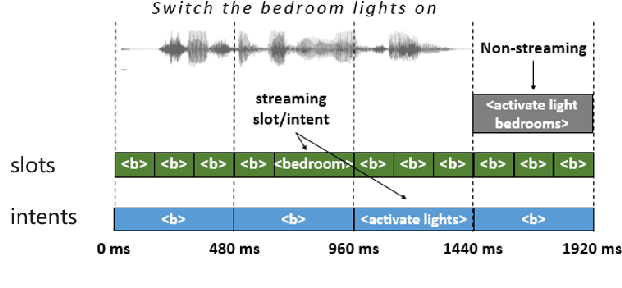
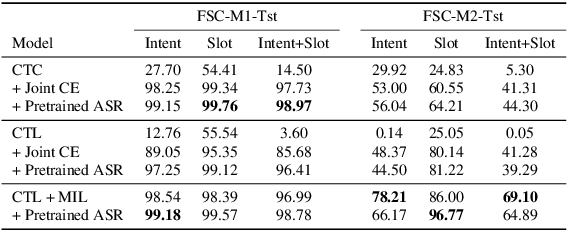
Human-computer interaction (HCI) is significantly impacted by delayed responses from a spoken dialogue system. Hence, end-to-end (e2e) spoken language understanding (SLU) solutions have recently been proposed to decrease latency. Such approaches allow for the extraction of semantic information directly from the speech signal, thus bypassing the need for a transcript from an automatic speech recognition (ASR) system. In this paper, we propose a compact e2e SLU architecture for streaming scenarios, where chunks of the speech signal are processed continuously to predict intent and slot values. Our model is based on a 3D convolutional neural network (3D-CNN) and a unidirectional long short-term memory (LSTM). We compare the performance of two alignment-free losses: the connectionist temporal classification (CTC) method and its adapted version, namely connectionist temporal localization (CTL). The latter performs not only the classification but also localization of sequential audio events. The proposed solution is evaluated on the Fluent Speech Command dataset and results show our model ability to process incoming speech signal, reaching accuracy as high as 98.97 % for CTC and 98.78 % for CTL on single-label classification, and as high as 95.69 % for CTC and 95.28 % for CTL on two-label prediction.
ChemRL-GEM: Geometry Enhanced Molecular Representation Learning for Property Prediction
Jul 08, 2021
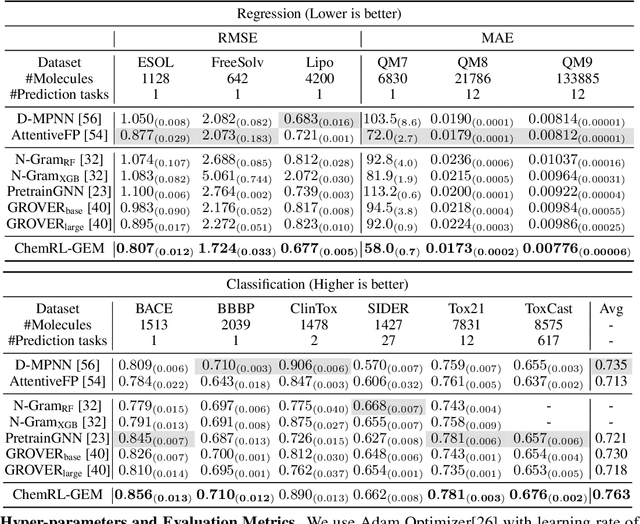
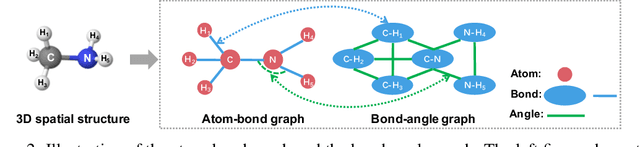
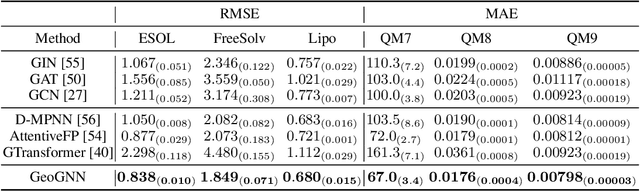
Effective molecular representation learning is of great importance to facilitate molecular property prediction, which is a fundamental task for the drug and material industry. Recent advances in graph neural networks (GNNs) have shown great promise in applying GNNs for molecular representation learning. Moreover, a few recent studies have also demonstrated successful applications of self-supervised learning methods to pre-train the GNNs to overcome the problem of insufficient labeled molecules. However, existing GNNs and pre-training strategies usually treat molecules as topological graph data without fully utilizing the molecular geometry information. Whereas, the three-dimensional (3D) spatial structure of a molecule, a.k.a molecular geometry, is one of the most critical factors for determining molecular physical, chemical, and biological properties. To this end, we propose a novel Geometry Enhanced Molecular representation learning method (GEM) for Chemical Representation Learning (ChemRL). At first, we design a geometry-based GNN architecture that simultaneously models atoms, bonds, and bond angles in a molecule. To be specific, we devised double graphs for a molecule: The first one encodes the atom-bond relations; The second one encodes bond-angle relations. Moreover, on top of the devised GNN architecture, we propose several novel geometry-level self-supervised learning strategies to learn spatial knowledge by utilizing the local and global molecular 3D structures. We compare ChemRL-GEM with various state-of-the-art (SOTA) baselines on different molecular benchmarks and exhibit that ChemRL-GEM can significantly outperform all baselines in both regression and classification tasks. For example, the experimental results show an overall improvement of 8.8% on average compared to SOTA baselines on the regression tasks, demonstrating the superiority of the proposed method.
Zero-shot Slot Filling with DPR and RAG
Apr 17, 2021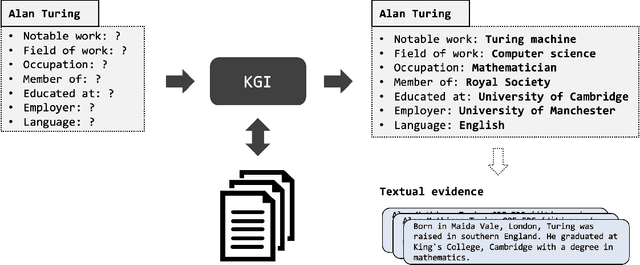

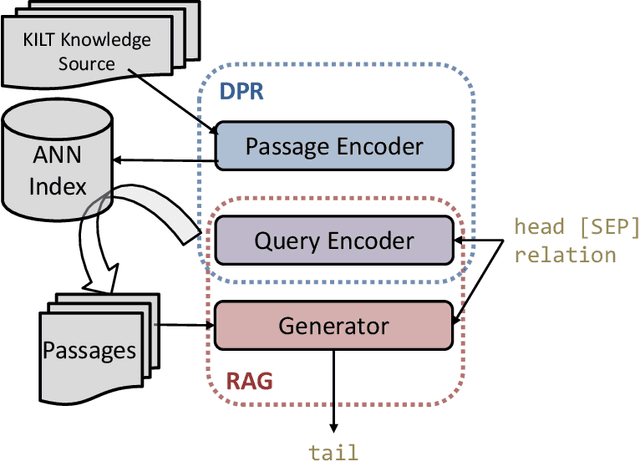
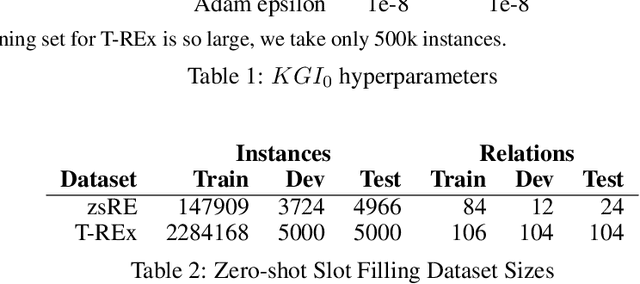
The ability to automatically extract Knowledge Graphs (KG) from a given collection of documents is a long-standing problem in Artificial Intelligence. One way to assess this capability is through the task of slot filling. Given an entity query in form of [Entity, Slot, ?], a system is asked to `fill' the slot by generating or extracting the missing value from a relevant passage or passages. This capability is crucial to create systems for automatic knowledge base population, which is becoming in ever-increasing demand, especially in enterprise applications. Recently, there has been a promising direction in evaluating language models in the same way we would evaluate knowledge bases, and the task of slot filling is the most suitable to this intent. The recent advancements in the field try to solve this task in an end-to-end fashion using retrieval-based language models. Models like Retrieval Augmented Generation (RAG) show surprisingly good performance without involving complex information extraction pipelines. However, the results achieved by these models on the two slot filling tasks in the KILT benchmark are still not at the level required by real-world information extraction systems. In this paper, we describe several strategies we adopted to improve the retriever and the generator of RAG in order to make it a better slot filler. Our KGI0 system (available at https://github.com/IBM/retrieve-write-slot-filling) reached the top-1 position on the KILT leaderboard on both T-REx and zsRE dataset with a large margin.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 15, 2021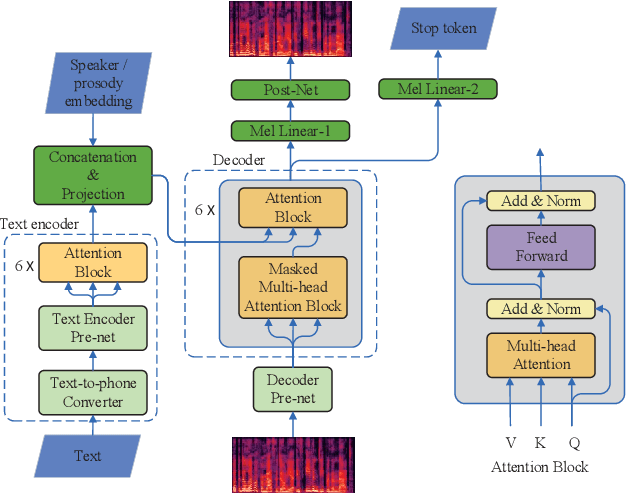
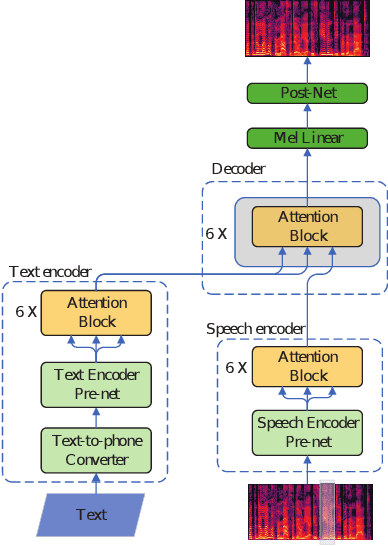
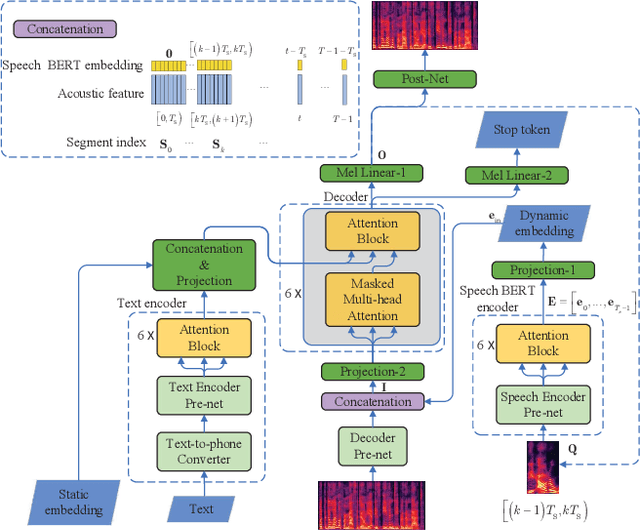
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.
VA-GCN: A Vector Attention Graph Convolution Network for learning on Point Clouds
Jun 01, 2021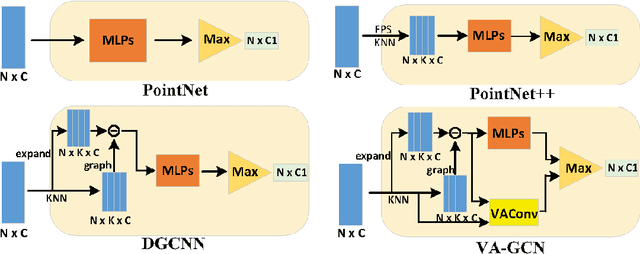
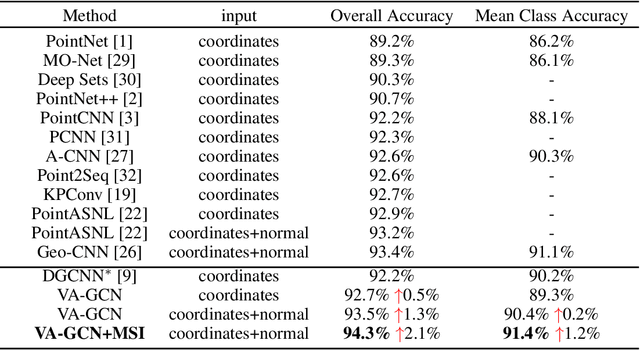
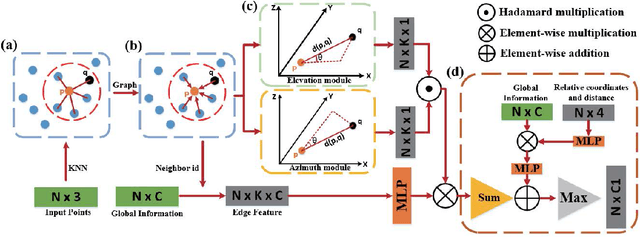
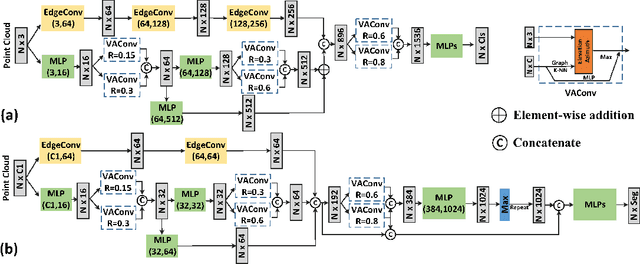
Owing to the development of research on local aggregation operators, dramatic breakthrough has been made in point cloud analysis models. However, existing local aggregation operators in the current literature fail to attach decent importance to the local information of the point cloud, which limits the power of the models. To fit this gap, we propose an efficient Vector Attention Convolution module (VAConv), which utilizes K-Nearest Neighbor (KNN) to extract the neighbor points of each input point, and then uses the elevation and azimuth relationship of the vectors between the center point and its neighbors to construct an attention weight matrix for edge features. Afterwards, the VAConv adopts a dual-channel structure to fuse weighted edge features and global features. To verify the efficiency of the VAConv, we connect the VAConvs with different receptive fields in parallel to obtain a Multi-scale graph convolutional network, VA-GCN. The proposed VA-GCN achieves state-of-the-art performance on standard benchmarks including ModelNet40, S3DIS and ShapeNet. Remarkably, on the ModelNet40 dataset for 3D classification, VA-GCN increased by 2.4% compared to the baseline.
Augmenting Molecular Deep Generative Models with Topological Data Analysis Representations
Jun 08, 2021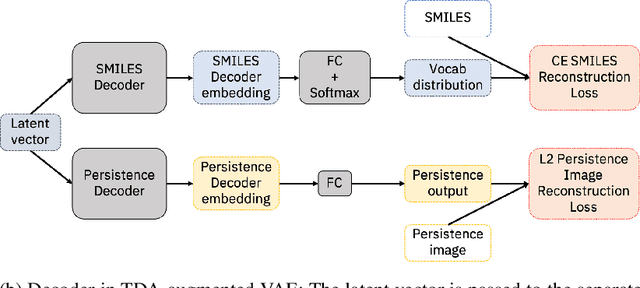


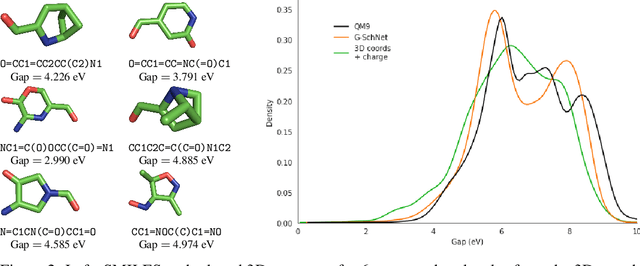
Deep generative models have emerged as a powerful tool for learning informative molecular representations and designing novel molecules with desired properties, with applications in drug discovery and material design. Deep generative auto-encoders defined over molecular SMILES strings have been a popular choice for that purpose. However, capturing salient molecular properties like quantum-chemical energies remains challenging and requires sophisticated neural net models of molecular graphs or geometry-based information. As a simpler and more efficient alternative, we present a SMILES Variational Auto-Encoder (VAE) augmented with topological data analysis (TDA) representations of molecules, known as persistence images. Our experiments show that this TDA augmentation enables a SMILES VAE to capture the complex relation between 3D geometry and electronic properties, and allows generation of novel, diverse, and valid molecules with geometric features consistent with the training data, which exhibit a varying range of global electronic structural properties, such as a small HOMO-LUMO gap - a critical property for designing organic solar cells. We demonstrate that our TDA augmentation yields better success in downstream tasks compared to models trained without these representations and can assist in targeted molecule discovery.
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021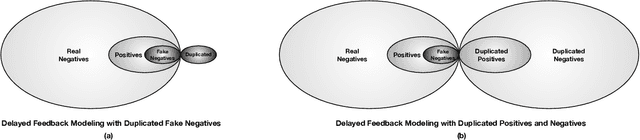

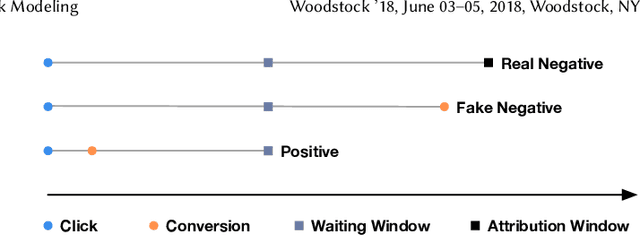
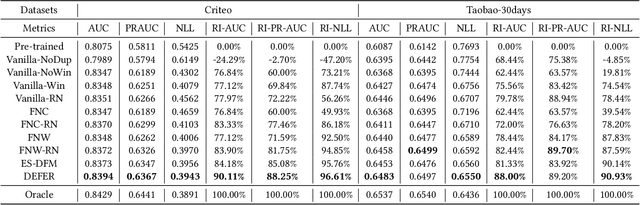
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.