 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Ranking Models for Document Retrieval
Feb 23, 2021
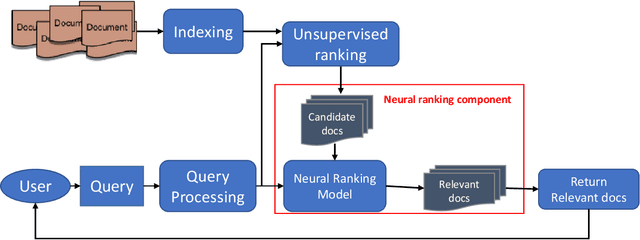
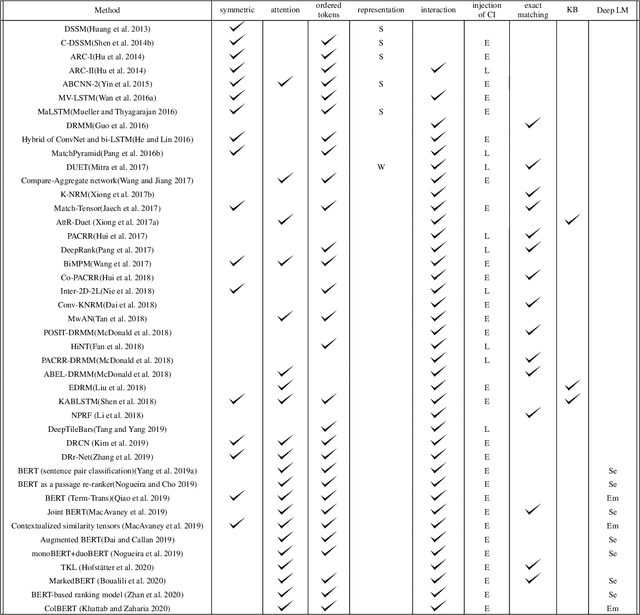
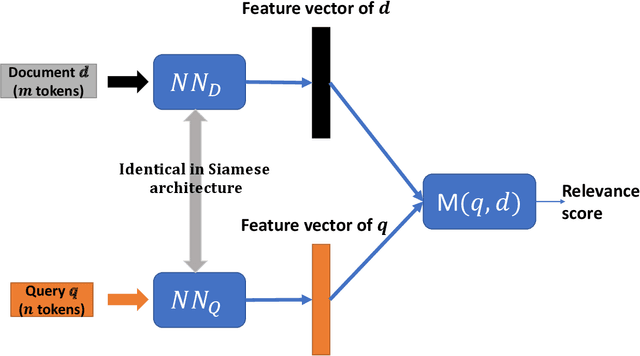
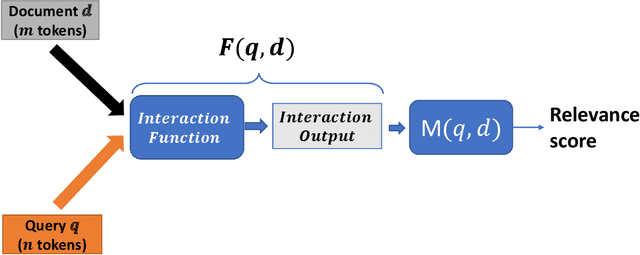
Ranking models are the main components of information retrieval systems. Several approaches to ranking are based on traditional machine learning algorithms using a set of hand-crafted features. Recently, researchers have leveraged deep learning models in information retrieval. These models are trained end-to-end to extract features from the raw data for ranking tasks, so that they overcome the limitations of hand-crafted features. A variety of deep learning models have been proposed, and each model presents a set of neural network components to extract features that are used for ranking. In this paper, we compare the proposed models in the literature along different dimensions in order to understand the major contributions and limitations of each model. In our discussion of the literature, we analyze the promising neural components, and propose future research directions. We also show the analogy between document retrieval and other retrieval tasks where the items to be ranked are structured documents, answers, images and videos.
Lex2vec: making Explainable Word Embedding via Distant Supervision
Mar 03, 2021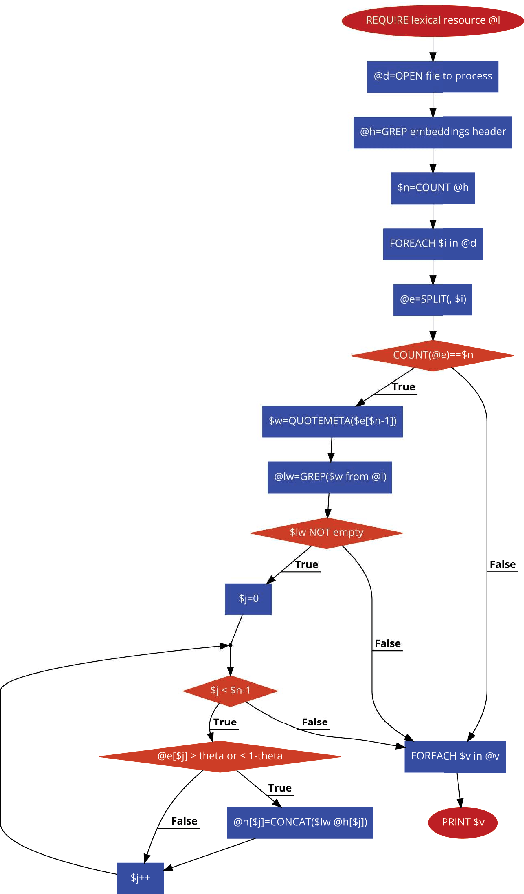
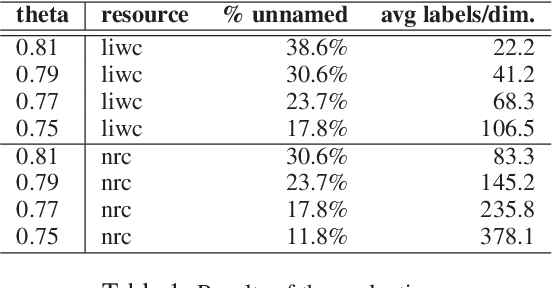
In this technical report we propose an algorithm, called Lex2vec, that exploits lexical resources to inject information into word embeddings and name the embedding dimensions by means of distant supervision. We evaluate the optimal parameters to extract a number of informative labels that is readable and has a good coverage for the embedding dimensions.
Machine Collaboration
May 06, 2021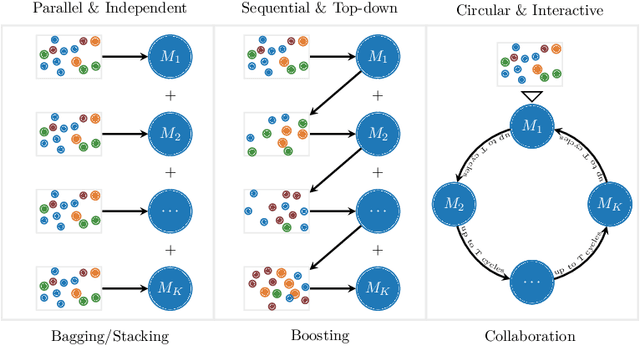
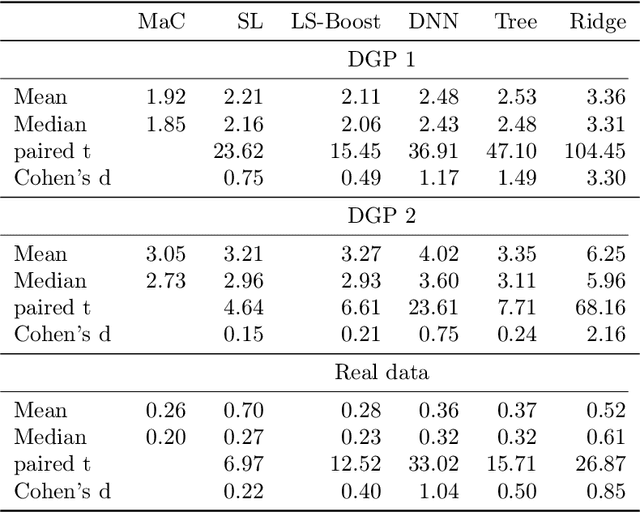
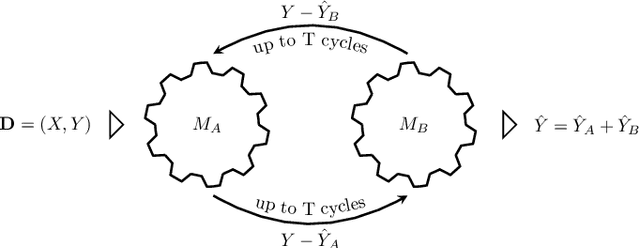
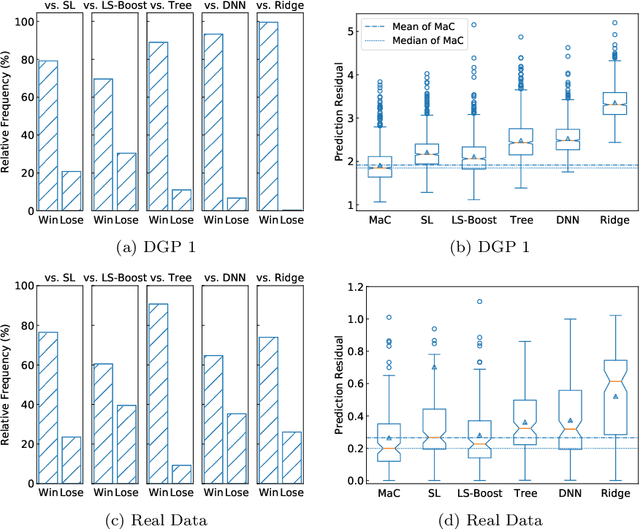
We propose a new ensemble framework for supervised learning, named machine collaboration (MaC), based on a collection of base machines for prediction tasks. Different from bagging/stacking (a parallel & independent framework) and boosting (a sequential & top-down framework), MaC is a type of circular & interactive learning framework. The circular & interactive feature helps the base machines to transfer information circularly and update their own structures and parameters accordingly. The theoretical result on the risk bound of the estimator based on MaC shows that circular & interactive feature can help MaC reduce the risk via a parsimonious ensemble. We conduct extensive experiments on simulated data and 119 benchmark real data sets. The results of the experiments show that in most cases, MaC performs much better than several state-of-the-art methods, including CART, neural network, stacking, and boosting.
An Integrated Attribute Guided Dense Attention Model for Fine-Grained Generalized Zero-Shot Learning
Dec 31, 2020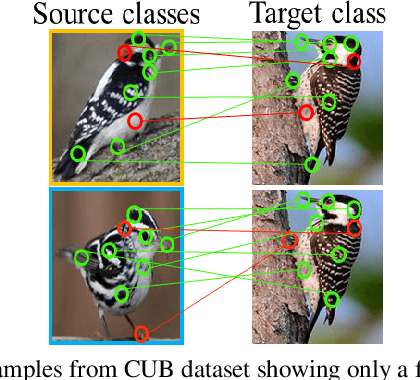
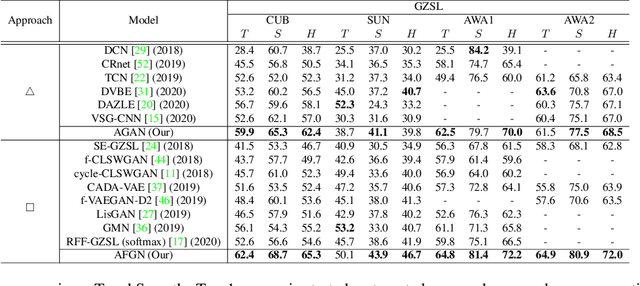
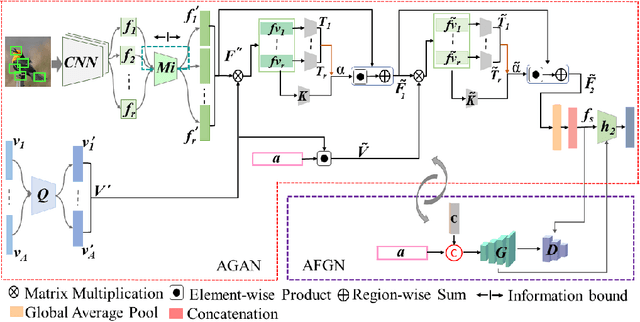
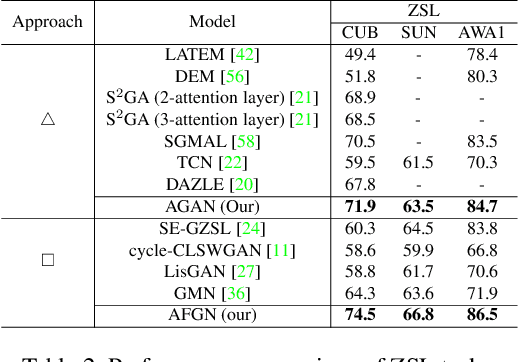
Fine-grained generalized zero-shot learning (GZSL) tasks require exploration of relevance between local visual features and attributes to discover fine distinctive information for satisfactory performance. Embedding learning and feature synthesizing are two of the popular categories of GZSL methods. However, these methods do not explore fine discriminative information as they ignore either the local features or direct guidance from the attributes. Consequently, they do not perform well. We propose a novel embedding learning network with a two-step dense attention mechanism, which uses direct attribute supervision to explore fine distinctive local visual features for fine-grained GZSL tasks. We further incorporate a feature synthesizing network, which uses the attribute-weighted visual features from the embedding learning network. Both networks are mutually trained in an end-to-end fashion to exploit mutually beneficial information. Consequently, the proposed method can test both scenarios: when only the images of unseen classes are available (using the feature synthesizing network) or when both images and semantic descriptors of the unseen classes are available (via the embedding learning network). Moreover, to reduce bias towards the source domain during testing, we compute source-target class similarity based on mutual information and transfer-learn the target classes. We demonstrate that our proposed method outperforms contemporary methods on benchmark datasets.
Counts@IITK at SemEval-2021 Task 8: SciBERT Based Entity And Semantic Relation Extraction For Scientific Data
Apr 03, 2021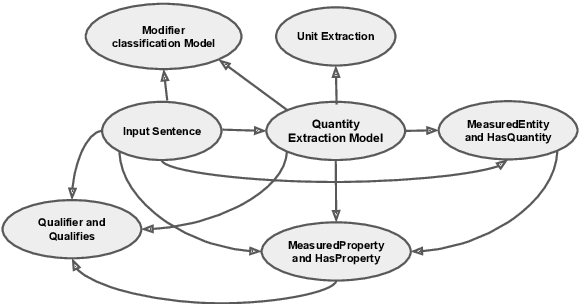
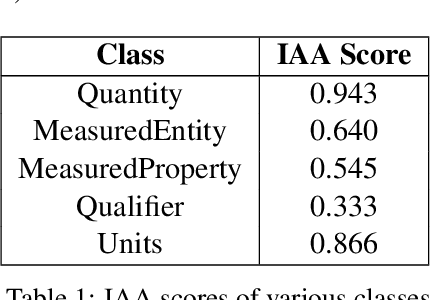
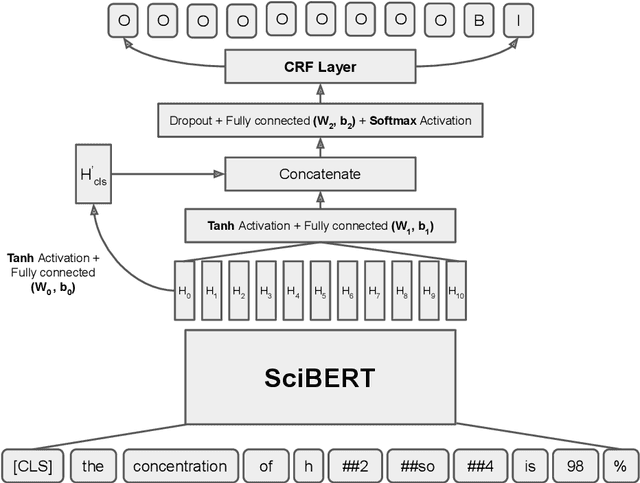
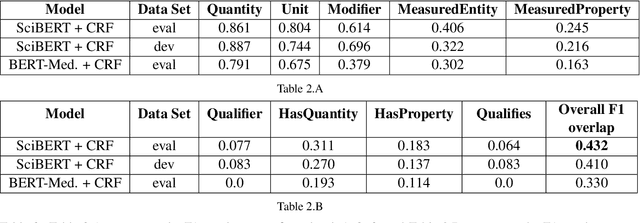
This paper presents the system for SemEval 2021 Task 8 (MeasEval). MeasEval is a novel span extraction, classification, and relation extraction task focused on finding quantities, attributes of these quantities, and additional information, including the related measured entities, properties, and measurement contexts. Our submitted system, which placed fifth (team rank) on the leaderboard, consisted of SciBERT with [CLS] token embedding and CRF layer on top. We were also placed first in Quantity (tied) and Unit subtasks, second in MeasuredEntity, Modifier and Qualifies subtasks, and third in Qualifier subtask.
Gender Bias in Machine Translation
Apr 15, 2021
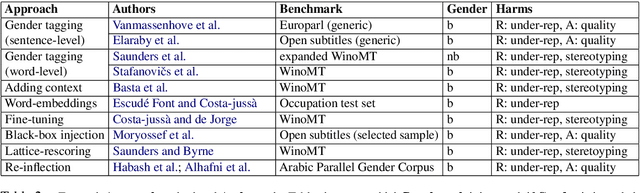
Machine translation (MT) technology has facilitated our daily tasks by providing accessible shortcuts for gathering, elaborating and communicating information. However, it can suffer from biases that harm users and society at large. As a relatively new field of inquiry, gender bias in MT still lacks internal cohesion, which advocates for a unified framework to ease future research. To this end, we: i) critically review current conceptualizations of bias in light of theoretical insights from related disciplines, ii) summarize previous analyses aimed at assessing gender bias in MT, iii) discuss the mitigating strategies proposed so far, and iv) point toward potential directions for future work.
Efficient Object-Level Visual Context Modeling for Multimodal Machine Translation: Masking Irrelevant Objects Helps Grounding
Dec 18, 2020
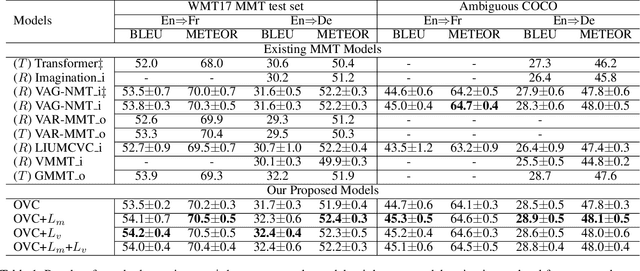
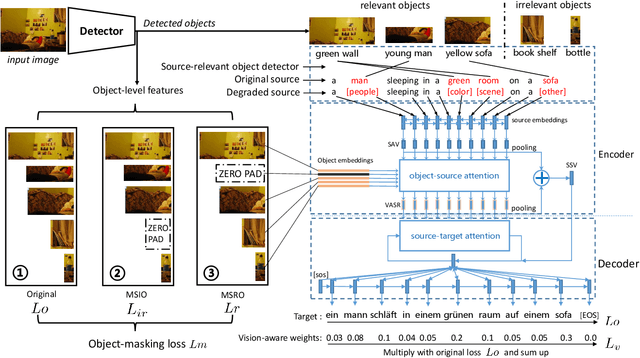
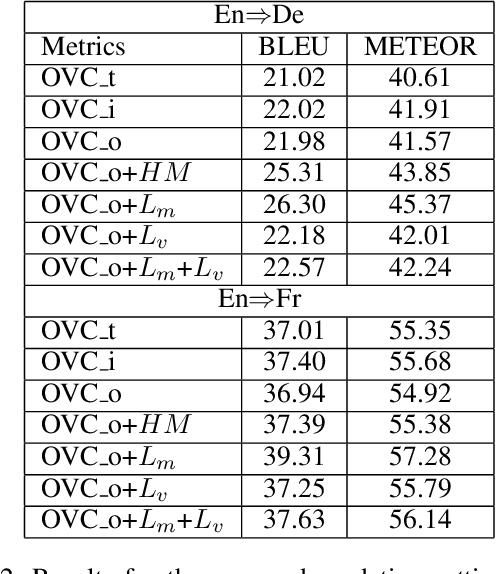
Visual context provides grounding information for multimodal machine translation (MMT). However, previous MMT models and probing studies on visual features suggest that visual information is less explored in MMT as it is often redundant to textual information. In this paper, we propose an object-level visual context modeling framework (OVC) to efficiently capture and explore visual information for multimodal machine translation. With detected objects, the proposed OVC encourages MMT to ground translation on desirable visual objects by masking irrelevant objects in the visual modality. We equip the proposed with an additional object-masking loss to achieve this goal. The object-masking loss is estimated according to the similarity between masked objects and the source texts so as to encourage masking source-irrelevant objects. Additionally, in order to generate vision-consistent target words, we further propose a vision-weighted translation loss for OVC. Experiments on MMT datasets demonstrate that the proposed OVC model outperforms state-of-the-art MMT models and analyses show that masking irrelevant objects helps grounding in MMT.
Weakly-supervised multi-class object localization using only object counts as labels
Feb 23, 2021

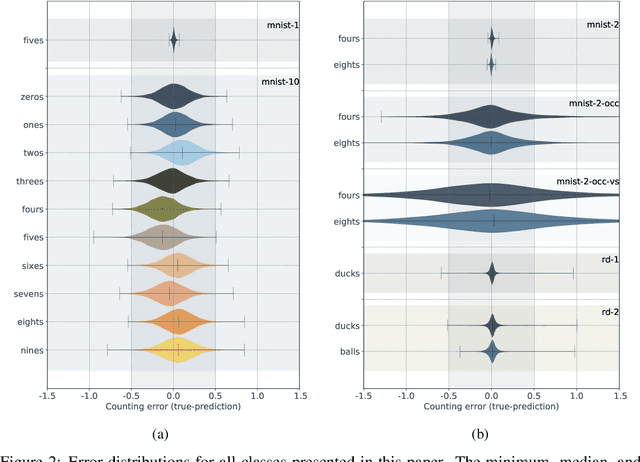

We demonstrate the use of an extensive deep neural network to localize instances of objects in images. The EDNN is naturally able to accurately perform multi-class counting using only ground truth count values as labels. Without providing any conceptual information, object annotations, or pixel segmentation information, the neural network is able to formulate its own conceptual representation of the items in the image. Using images labelled with only the counts of the objects present,the structure of the extensive deep neural network can be exploited to perform localization of the objects within the visual field. We demonstrate that a trained EDNN can be used to count objects in images much larger than those on which it was trained. In order to demonstrate our technique, we introduce seven new data sets: five progressively harder MNIST digit-counting data sets, and two datasets of 3d-rendered rubber ducks in various situations. On most of these datasets, the EDNN achieves greater than 99% test set accuracy in counting objects.
Opening the Black Box of Deep Neural Networks via Information
Apr 29, 2017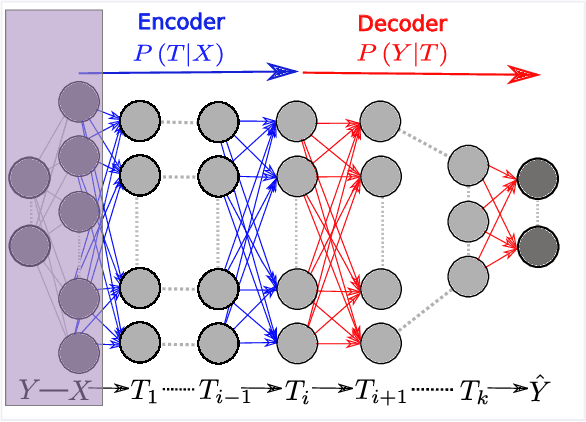
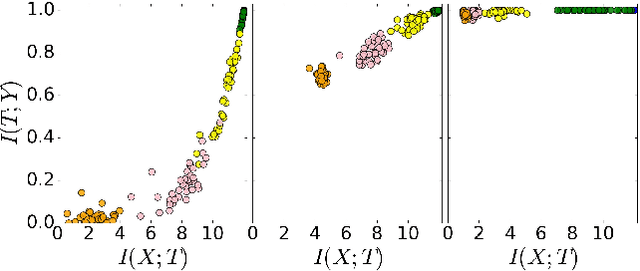
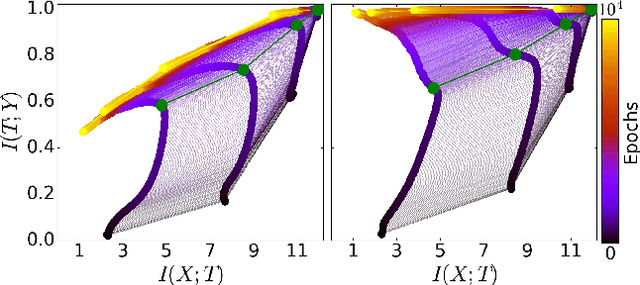
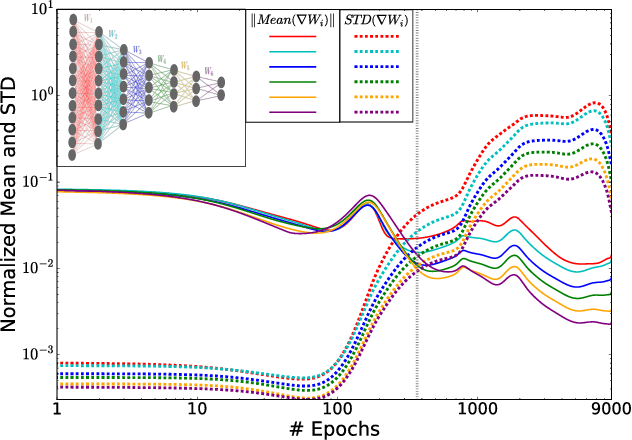
Despite their great success, there is still no comprehensive theoretical understanding of learning with Deep Neural Networks (DNNs) or their inner organization. Previous work proposed to analyze DNNs in the \textit{Information Plane}; i.e., the plane of the Mutual Information values that each layer preserves on the input and output variables. They suggested that the goal of the network is to optimize the Information Bottleneck (IB) tradeoff between compression and prediction, successively, for each layer. In this work we follow up on this idea and demonstrate the effectiveness of the Information-Plane visualization of DNNs. Our main results are: (i) most of the training epochs in standard DL are spent on {\emph compression} of the input to efficient representation and not on fitting the training labels. (ii) The representation compression phase begins when the training errors becomes small and the Stochastic Gradient Decent (SGD) epochs change from a fast drift to smaller training error into a stochastic relaxation, or random diffusion, constrained by the training error value. (iii) The converged layers lie on or very close to the Information Bottleneck (IB) theoretical bound, and the maps from the input to any hidden layer and from this hidden layer to the output satisfy the IB self-consistent equations. This generalization through noise mechanism is unique to Deep Neural Networks and absent in one layer networks. (iv) The training time is dramatically reduced when adding more hidden layers. Thus the main advantage of the hidden layers is computational. This can be explained by the reduced relaxation time, as this it scales super-linearly (exponentially for simple diffusion) with the information compression from the previous layer.
Learning Granularity-Aware Convolutional Neural Network for Fine-Grained Visual Classification
Mar 04, 2021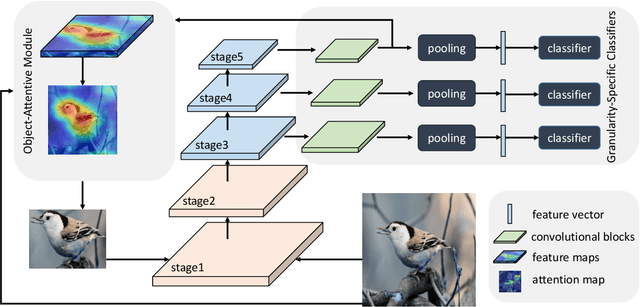
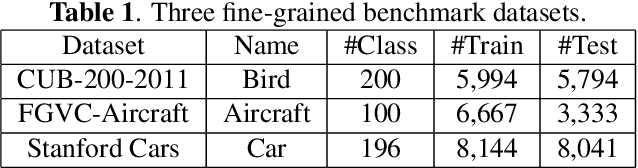

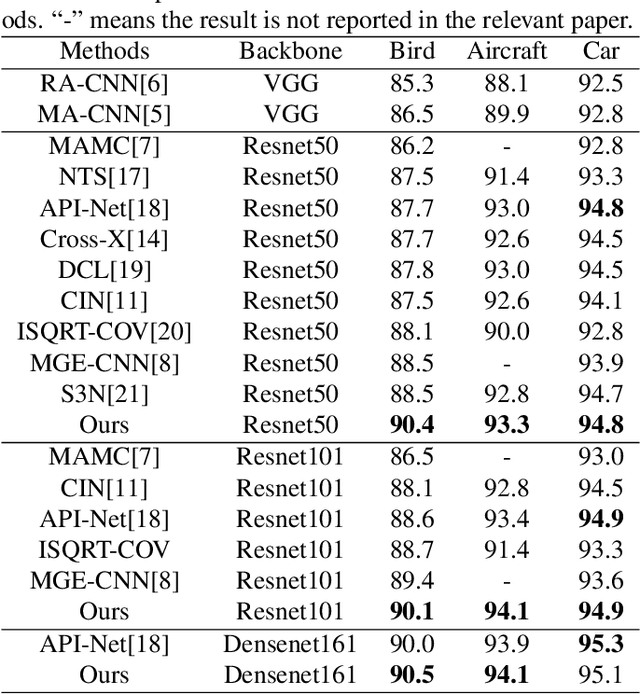
Locating discriminative parts plays a key role in fine-grained visual classification due to the high similarities between different objects. Recent works based on convolutional neural networks utilize the feature maps taken from the last convolutional layer to mine discriminative regions. However, the last convolutional layer tends to focus on the whole object due to the large receptive field, which leads to a reduced ability to spot the differences. To address this issue, we propose a novel Granularity-Aware Convolutional Neural Network (GA-CNN) that progressively explores discriminative features. Specifically, GA-CNN utilizes the differences of the receptive fields at different layers to learn multi-granularity features, and it exploits larger granularity information based on the smaller granularity information found at the previous stages. To further boost the performance, we introduce an object-attentive module that can effectively localize the object given a raw image. GA-CNN does not need bounding boxes/part annotations and can be trained end-to-end. Extensive experimental results show that our approach achieves state-of-the-art performances on three benchmark datasets.