 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gradient-based Label Binning in Multi-label Classification
Jun 22, 2021
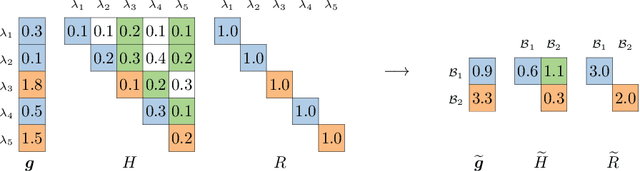
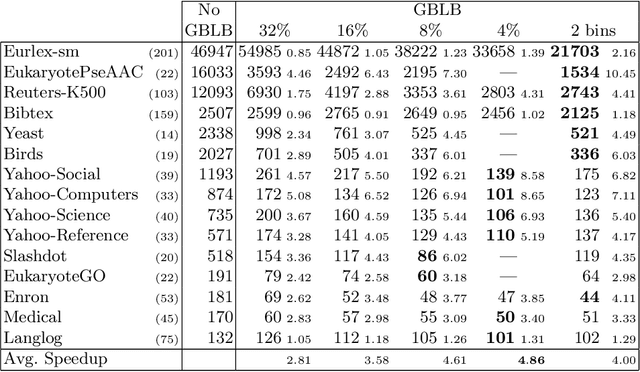
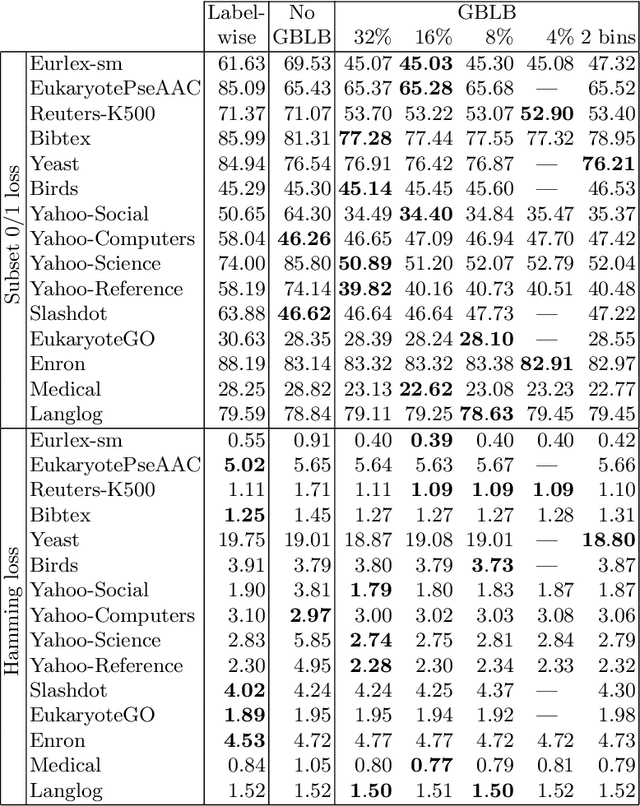
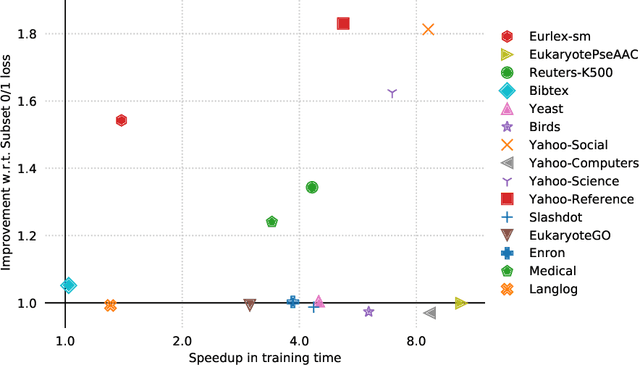
In multi-label classification, where a single example may be associated with several class labels at the same time, the ability to model dependencies between labels is considered crucial to effectively optimize non-decomposable evaluation measures, such as the Subset 0/1 loss. The gradient boosting framework provides a well-studied foundation for learning models that are specifically tailored to such a loss function and recent research attests the ability to achieve high predictive accuracy in the multi-label setting. The utilization of second-order derivatives, as used by many recent boosting approaches, helps to guide the minimization of non-decomposable losses, due to the information about pairs of labels it incorporates into the optimization process. On the downside, this comes with high computational costs, even if the number of labels is small. In this work, we address the computational bottleneck of such approach -- the need to solve a system of linear equations -- by integrating a novel approximation technique into the boosting procedure. Based on the derivatives computed during training, we dynamically group the labels into a predefined number of bins to impose an upper bound on the dimensionality of the linear system. Our experiments, using an existing rule-based algorithm, suggest that this may boost the speed of training, without any significant loss in predictive performance.
Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation
Sep 06, 2018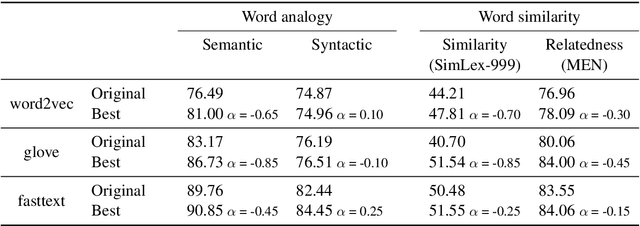
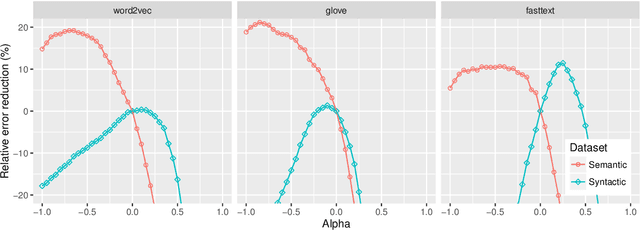
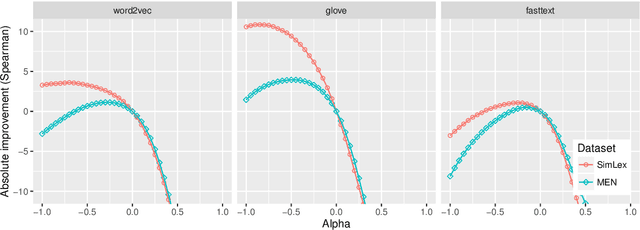
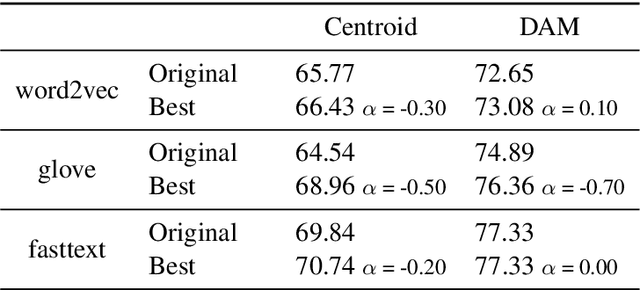
Following the recent success of word embeddings, it has been argued that there is no such thing as an ideal representation for words, as different models tend to capture divergent and often mutually incompatible aspects like semantics/syntax and similarity/relatedness. In this paper, we show that each embedding model captures more information than directly apparent. A linear transformation that adjusts the similarity order of the model without any external resource can tailor it to achieve better results in those aspects, providing a new perspective on how embeddings encode divergent linguistic information. In addition, we explore the relation between intrinsic and extrinsic evaluation, as the effect of our transformations in downstream tasks is higher for unsupervised systems than for supervised ones.
A Riemannian Newton Trust-Region Method for Fitting Gaussian Mixture Models
Apr 30, 2021
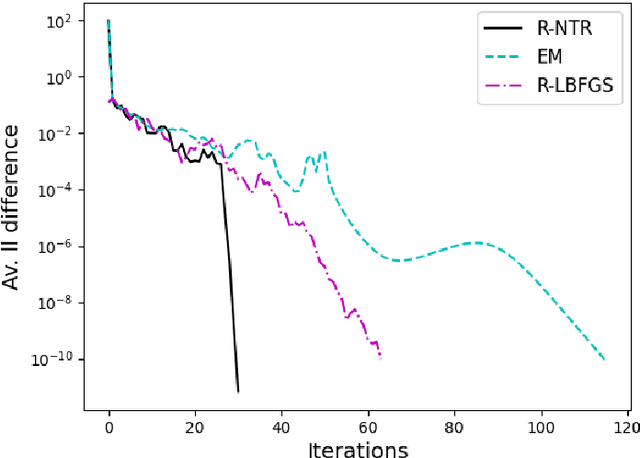
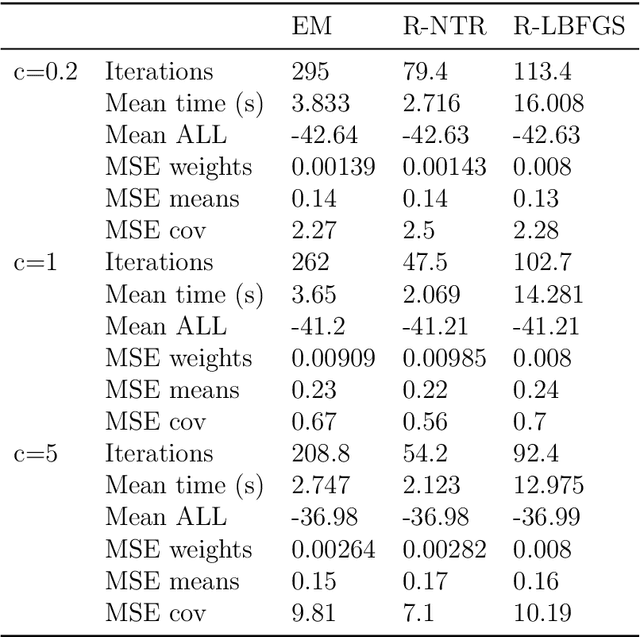
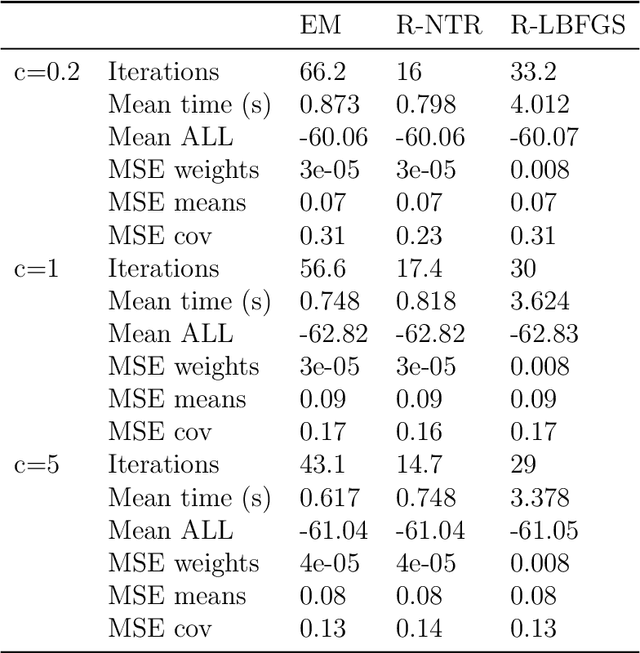
Gaussian Mixture Models are a powerful tool in Data Science and Statistics that are mainly used for clustering and density approximation. The task of estimating the model parameters is in practice often solved by the Expectation Maximization (EM) algorithm which has its benefits in its simplicity and low per-iteration costs. However, the EM converges slowly if there is a large share of hidden information or overlapping clusters. Recent advances in Manifold Optimization for Gaussian Mixture Models have gained increasing interest. We introduce a formula for the Riemannian Hessian for Gaussian Mixture Models. On top, we propose a new Riemannian Newton Trust-Region method which outperforms current approaches both in terms of runtime and number of iterations.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020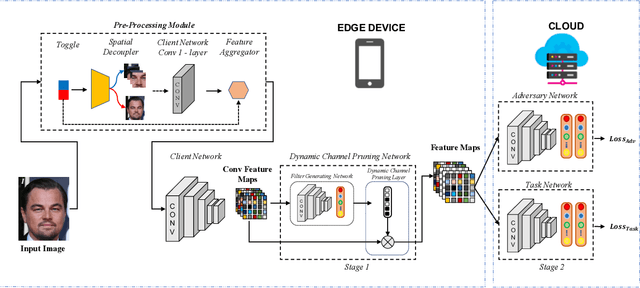
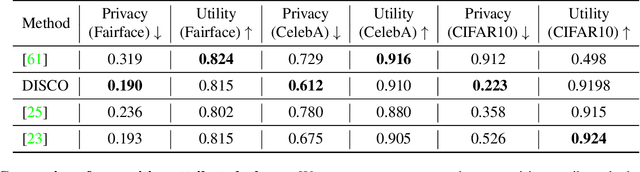

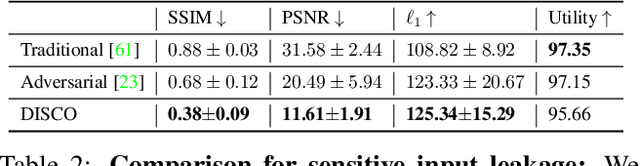
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Definite Non-Ancestral Relations and Structure Learning
May 20, 2021
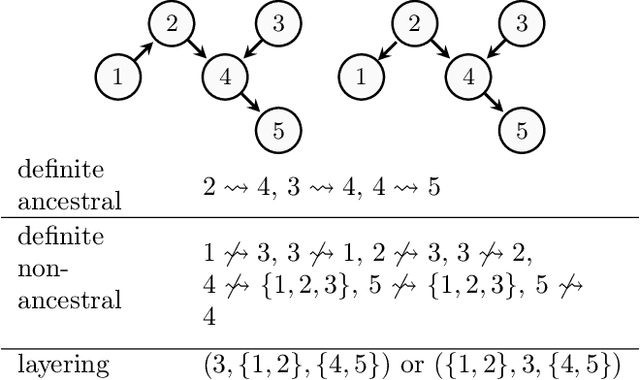
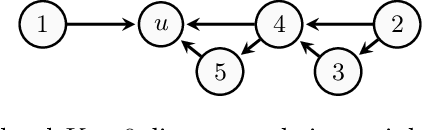
In causal graphical models based on directed acyclic graphs (DAGs), directed paths represent causal pathways between the corresponding variables. The variable at the beginning of such a path is referred to as an ancestor of the variable at the end of the path. Ancestral relations between variables play an important role in causal modeling. In existing literature on structure learning, these relations are usually deduced from learned structures and used for orienting edges or formulating constraints of the space of possible DAGs. However, they are usually not posed as immediate target of inference. In this work we investigate the graphical characterization of ancestral relations via CPDAGs and d-separation relations. We propose a framework that can learn definite non-ancestral relations without first learning the skeleton. This frame-work yields structural information that can be used in both score- and constraint-based algorithms to learn causal DAGs more efficiently.
View-Guided Point Cloud Completion
Apr 12, 2021
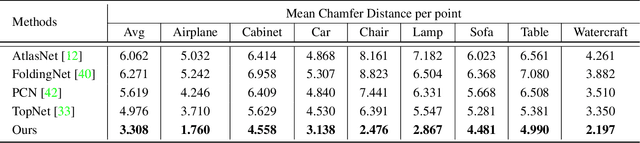
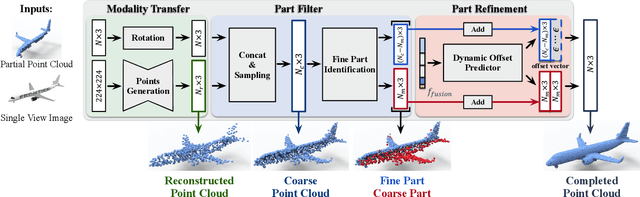
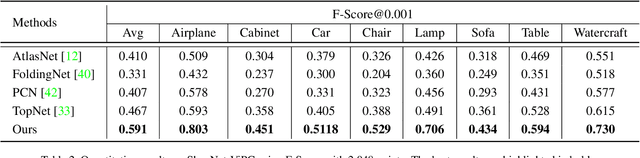
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
Incorporating Visual Layout Structures for Scientific Text Classification
Jun 01, 2021
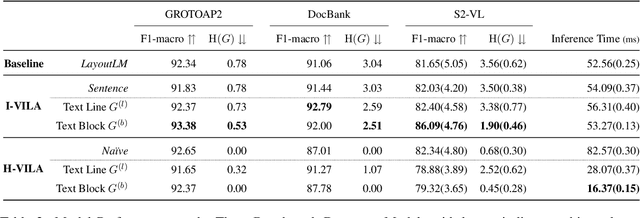
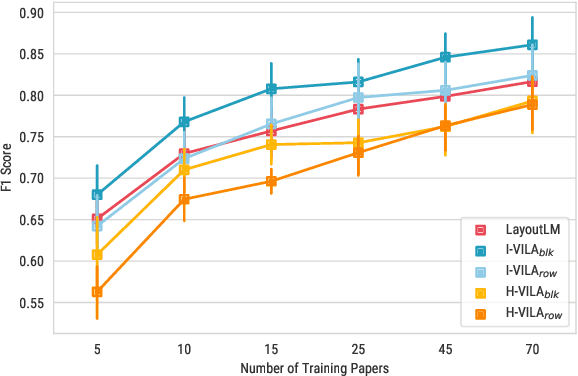
Classifying the core textual components of a scientific paper-title, author, body text, etc.-is a critical first step in automated scientific document understanding. Previous work has shown how using elementary layout information, i.e., each token's 2D position on the page, leads to more accurate classification. We introduce new methods for incorporating VIsual LAyout structures (VILA), e.g., the grouping of page texts into text lines or text blocks, into language models to further improve performance. We show that the I-VILA approach, which simply adds special tokens denoting boundaries between layout structures into model inputs, can lead to +1~4.5 F1 Score improvements in token classification tasks. Moreover, we design a hierarchical model H-VILA that encodes these layout structures and record a up-to 70% efficiency boost without hurting prediction accuracy. The experiments are conducted on a newly curated evaluation suite, S2-VLUE, with a novel metric measuring VILA awareness and a new dataset covering 19 scientific disciplines with gold annotations. Pre-trained weights, benchmark datasets, and source code will be available at https://github.com/allenai/VILA}{https://github.com/allenai/VILA.
Markpainting: Adversarial Machine Learning meets Inpainting
Jun 01, 2021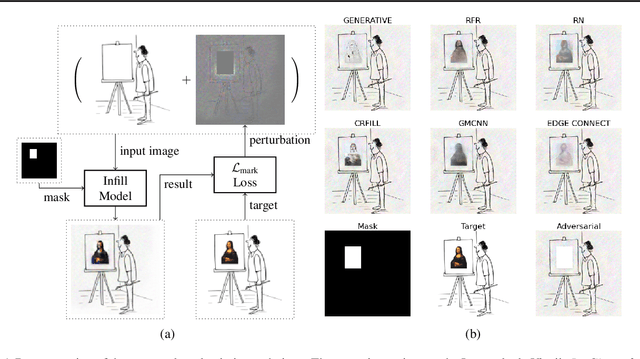
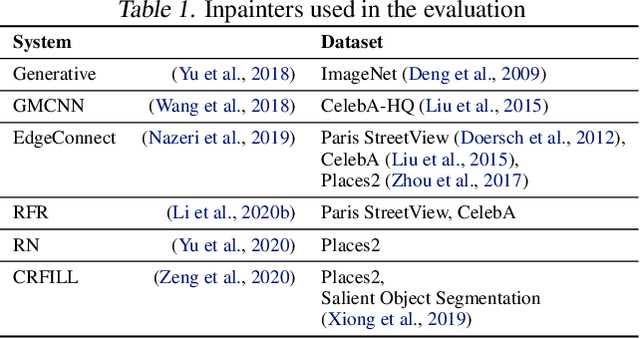

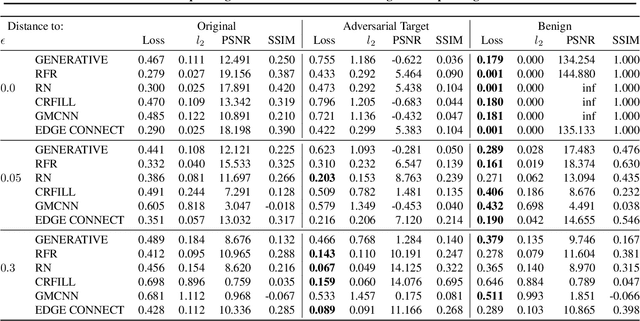
Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting.
ICDAR 2021 Competition on Components Segmentation Task of Document Photos
Jun 16, 2021


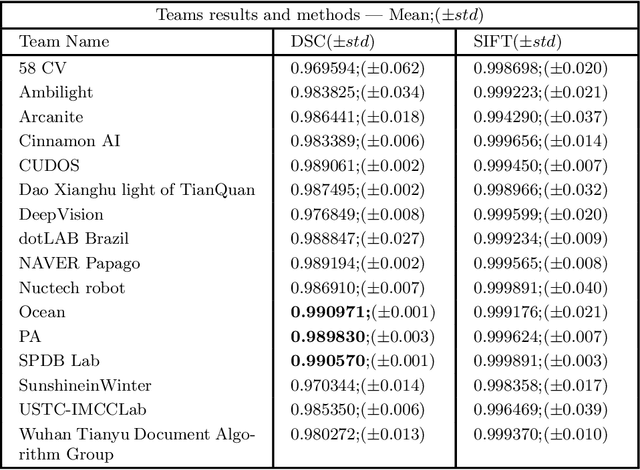
This paper describes the short-term competition on Components Segmentation Task of Document Photos that was prepared in the context of the 16th International Conference on Document Analysis and Recognition (ICDAR 2021). This competition aims to bring together researchers working on the filed of identification document image processing and provides them a suitable benchmark to compare their techniques on the component segmentation task of document images. Three challenge tasks were proposed entailing different segmentation assignments to be performed on a provided dataset. The collected data are from several types of Brazilian ID documents, whose personal information was conveniently replaced. There were 16 participants whose results obtained for some or all the three tasks show different rates for the adopted metrics, like Dice Similarity Coefficient ranging from 0.06 to 0.99. Different Deep Learning models were applied by the entrants with diverse strategies to achieve the best results in each of the tasks. Obtained results show that the current applied methods for solving one of the proposed tasks (document boundary detection) are already well stablished. However, for the other two challenge tasks (text zone and handwritten sign detection) research and development of more robust approaches are still required to achieve acceptable results.
Editorial introduction: The power of words and networks
May 24, 2021According to Freud "words were originally magic and to this day words have retained much of their ancient magical power". By words, behaviors are transformed and problems are solved. The way we use words reveals our intentions, goals and values. Novel tools for text analysis help understand the magical power of words. This power is multiplied, if it is combined with the study of social networks, i.e. with the analysis of relationships among social units. This special issue of the International Journal of Information Management, entitled "Combining Social Network Analysis and Text Mining: from Theory to Practice", includes heterogeneous and innovative research at the nexus of text mining and social network analysis. It aims to enrich work at the intersection of these fields, which still lags behind in theoretical, empirical, and methodological foundations. The nine articles accepted for inclusion in this special issue all present methods and tools that have business applications. They are summarized in this editorial introduction.