 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
May 16, 2021

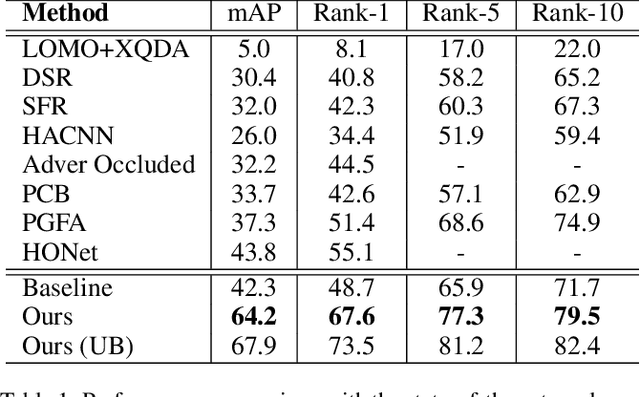
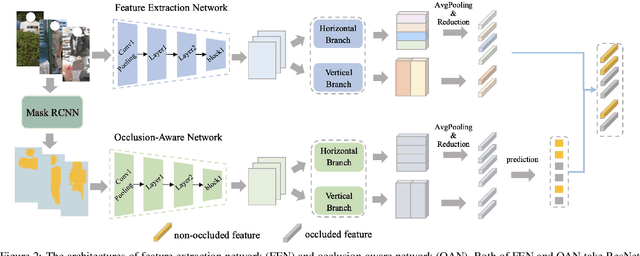
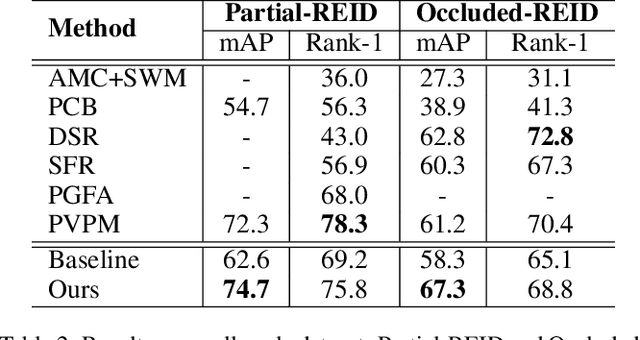
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance. To tackle this challenge, we propose to reconstruct the feature representation of occluded parts by fully exploiting the information of its neighborhood in a gallery image set. Specifically, we first introduce a visible part-based feature by body mask for each person image. Then we identify its neighboring samples using the visible features and reconstruct the representation of the full body by an outlier-removable graph neural network with all the neighboring samples as input. Extensive experiments show that the proposed approach obtains significant improvements. In the large-scale Occluded-DukeMTMC benchmark, our approach achieves 64.2% mAP and 67.6% rank-1 accuracy which outperforms the state-of-the-art approaches by large margins, i.e.,20.4% and 12.5%, respectively, indicating the effectiveness of our method on occluded Re-ID problem.
Rethinking of Radar's Role: A Camera-Radar Dataset and Systematic Annotator via Coordinate Alignment
May 11, 2021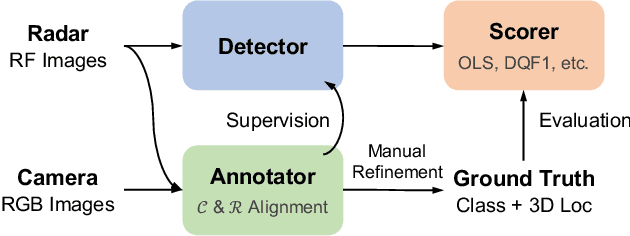
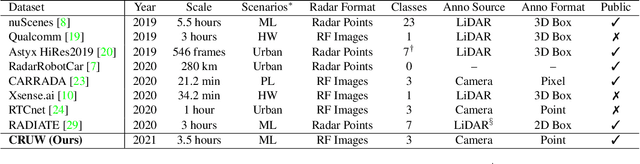
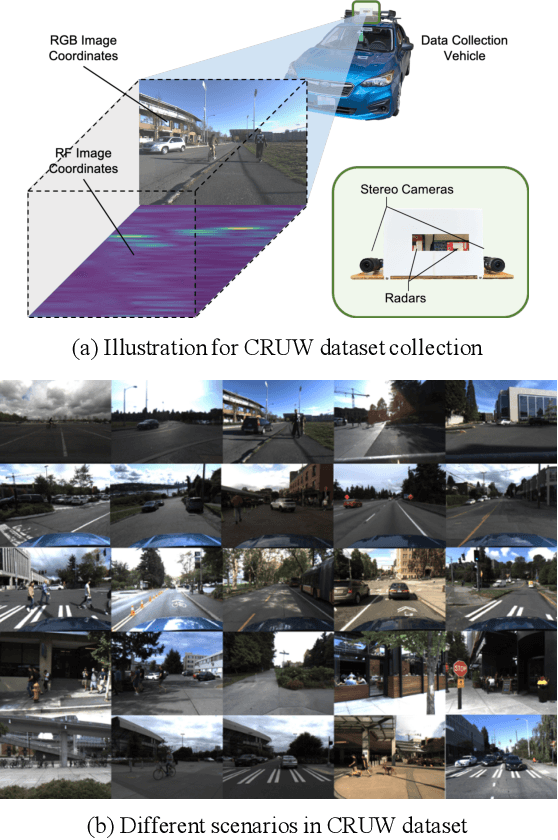
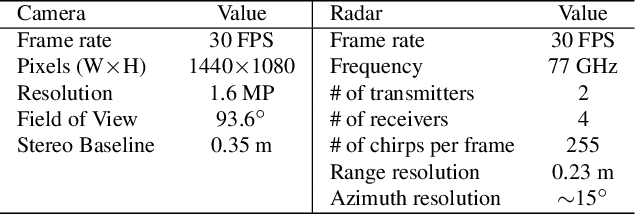
Radar has long been a common sensor on autonomous vehicles for obstacle ranging and speed estimation. However, as a robust sensor to all-weather conditions, radar's capability has not been well-exploited, compared with camera or LiDAR. Instead of just serving as a supplementary sensor, radar's rich information hidden in the radio frequencies can potentially provide useful clues to achieve more complicated tasks, like object classification and detection. In this paper, we propose a new dataset, named CRUW, with a systematic annotator and performance evaluation system to address the radar object detection (ROD) task, which aims to classify and localize the objects in 3D purely from radar's radio frequency (RF) images. To the best of our knowledge, CRUW is the first public large-scale dataset with a systematic annotation and evaluation system, which involves camera RGB images and radar RF images, collected in various driving scenarios.
The Cold-start Problem: Minimal Users' Activity Estimation
May 31, 2021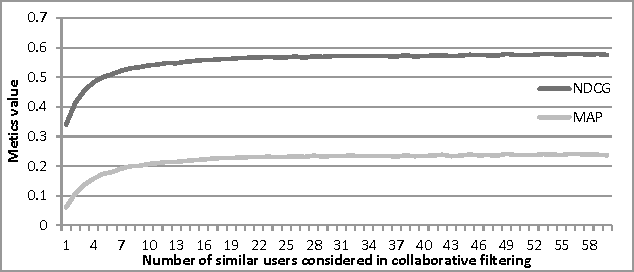
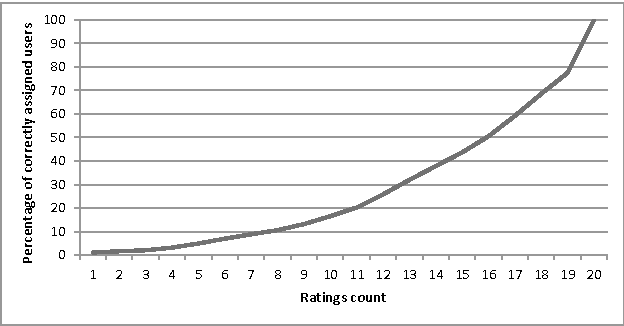
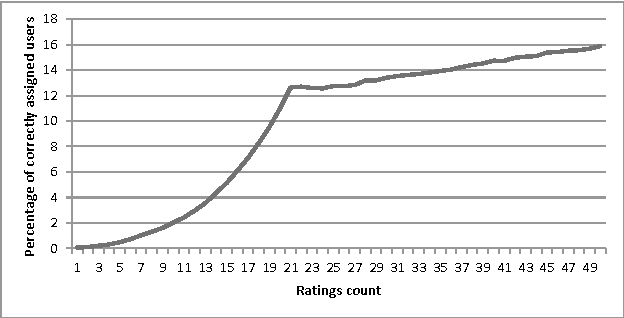
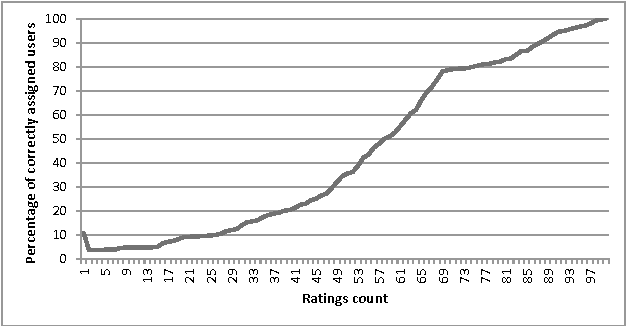
Cold-start problem, which arises upon the new users arrival, is one of the fundamental problems in today's recommender approaches. Moreover, in some domains as TV or multime-dia-items take long time to experience by users, thus users usually do not provide rich preference information. In this paper we analyze the minimal amount of ratings needs to be done by a user over a set of items, in order to solve or reduce the cold-start problem. In our analysis we applied clustering data mining technique in order to identify minimal amount of item's ratings required from recommender system's users, in order to be assigned to a correct cluster. In this context, cluster quality is being monitored and in case of reaching certain cluster quality threshold, the rec-ommender system could start to generate recommendations for given user, as in this point cold-start problem is considered as resolved. Our proposed approach is applicable to any domain in which user preferences are received based on explicit items rating. Our experiments are performed within the movie and jokes recommendation domain using the MovieLens and Jester dataset.
VSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021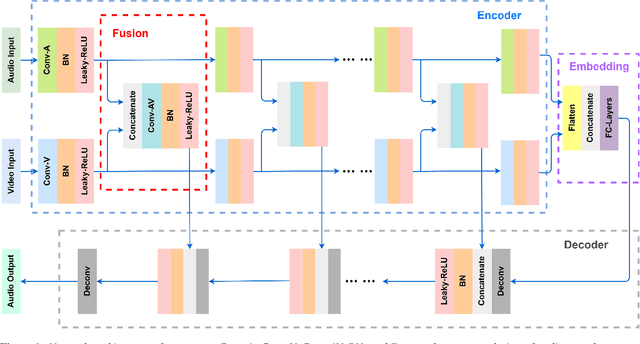

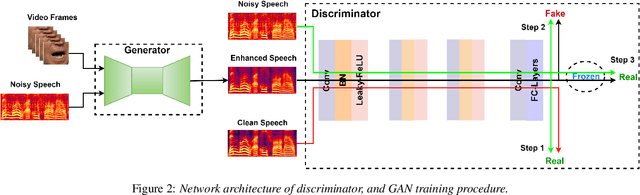
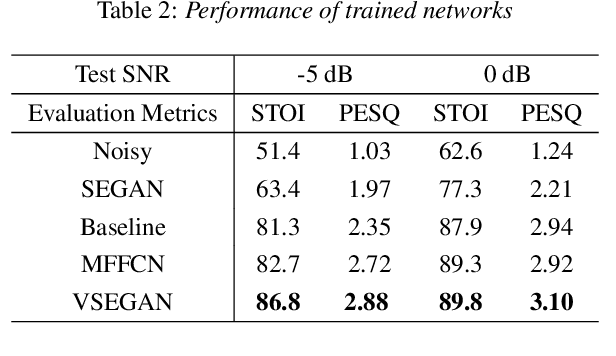
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
NISQ Algorithm for Semidefinite Programming
Jun 07, 2021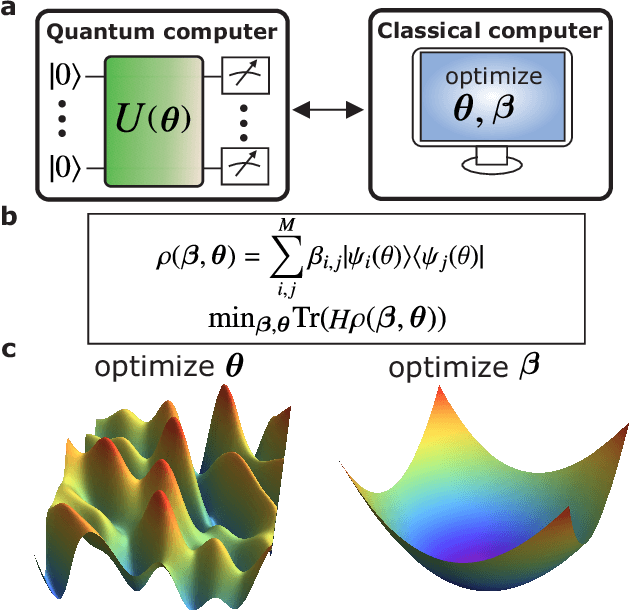
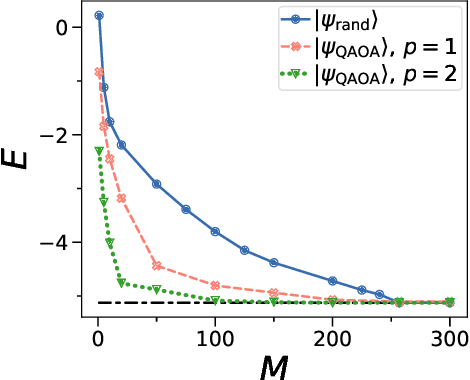
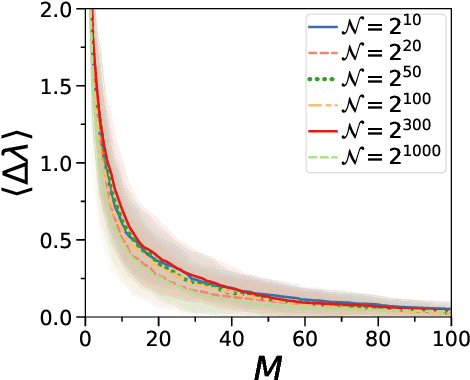
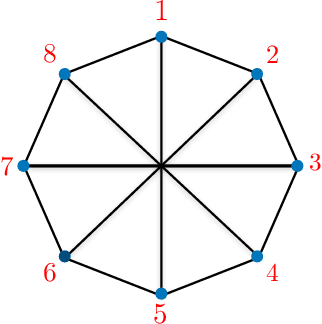
Semidefinite Programming (SDP) is a class of convex optimization programs with vast applications in control theory, quantum information, combinatorial optimization and operational research. Noisy intermediate-scale quantum (NISQ) algorithms aim to make an efficient use of the current generation of quantum hardware. However, optimizing variational quantum algorithms is a challenge as it is an NP-hard problem that in general requires an exponential time to solve and can contain many far from optimal local minima. Here, we present a current term NISQ algorithm for SDP. The classical optimization program of our NISQ solver is another SDP over a smaller dimensional ansatz space. We harness the SDP based formulation of the Hamiltonian ground state problem to design a NISQ eigensolver. Unlike variational quantum eigensolvers, the classical optimization program of our eigensolver is convex, can be solved in polynomial time with the number of ansatz parameters and every local minimum is a global minimum. Further, we demonstrate the potential of our NISQ SDP solver by finding the largest eigenvalue of up to $2^{1000}$ dimensional matrices and solving graph problems related to quantum contextuality. We also discuss NISQ algorithms for rank-constrained SDPs. Our work extends the application of NISQ computers onto one of the most successful algorithmic frameworks of the past few decades.
A Semantic Segmentation Network for Urban-Scale Building Footprint Extraction Using RGB Satellite Imagery
Apr 02, 2021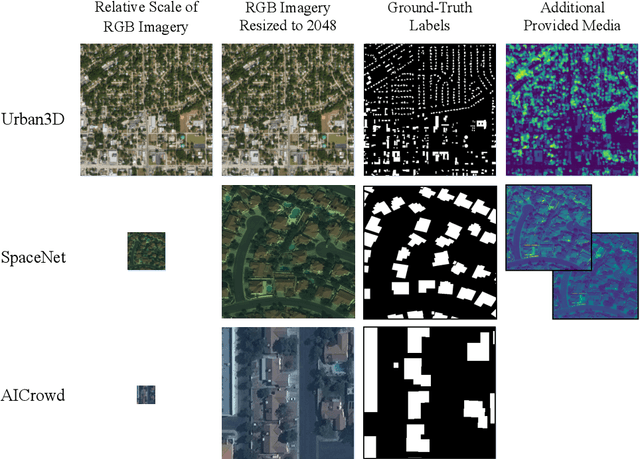
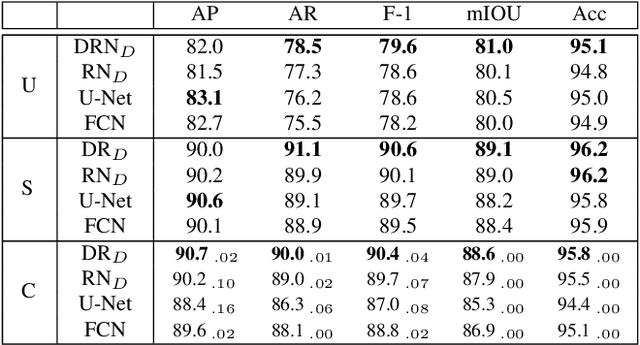
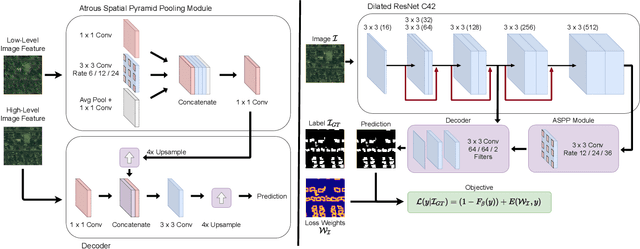
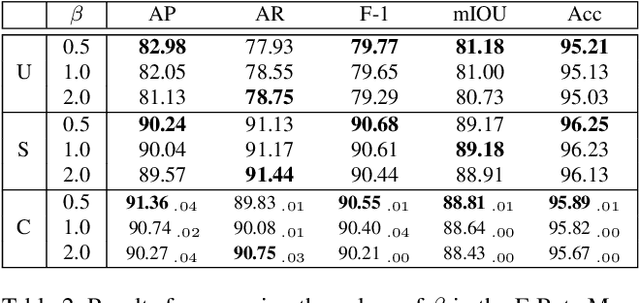
Urban areas consume over two-thirds of the world's energy and account for more than 70 percent of global CO2 emissions. As stated in IPCC's Global Warming of 1.5C report, achieving carbon neutrality by 2050 requires a scalable approach that can be applied in a global context. Conventional methods of collecting data on energy use and emissions of buildings are extremely expensive and require specialized geometry information that not all cities have readily available. High-quality building footprint generation from satellite images can accelerate this predictive process and empower municipal decision-making at scale. However, previous deep learning-based approaches use supplemental data such as point cloud data, building height information, and multi-band imagery - which has limited availability and is difficult to produce. In this paper, we propose a modified DeeplabV3+ module with a Dilated ResNet backbone to generate masks of building footprints from only three-channel RGB satellite imagery. Furthermore, we introduce an F-Beta measure in our objective function to help the model account for skewed class distributions. In addition to an F-Beta objective function, we incorporate an exponentially weighted boundary loss and use a cross-dataset training strategy to further increase the quality of predictions. As a result, we achieve state-of-the-art performance across three standard benchmarks and demonstrate that our RGB-only method is agnostic to the scale, resolution, and urban density of satellite imagery.
gComm: An environment for investigating generalization in Grounded Language Acquisition
May 16, 2021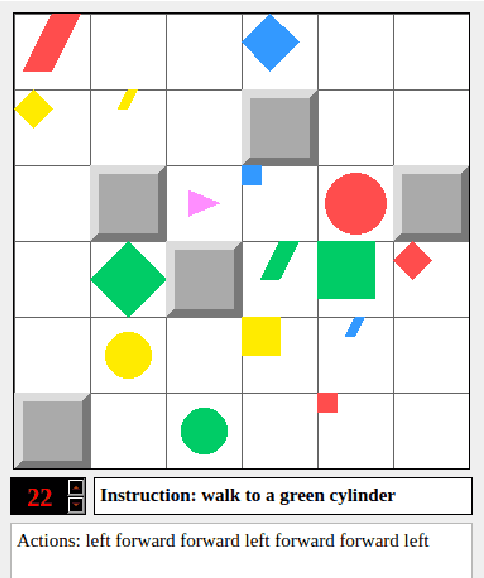
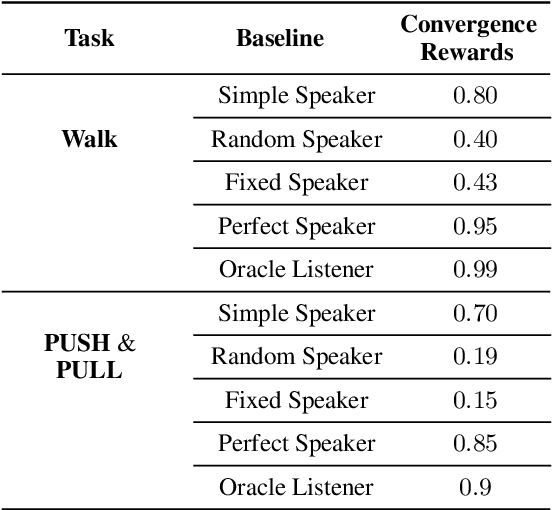
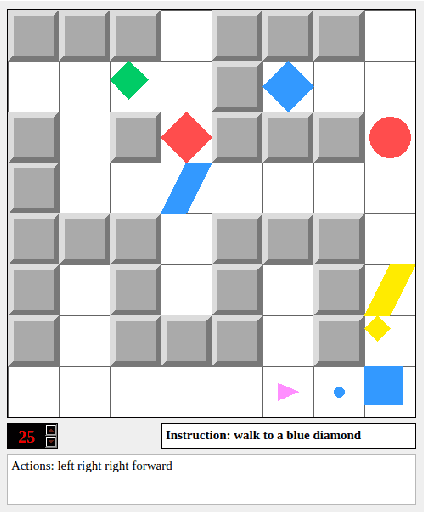
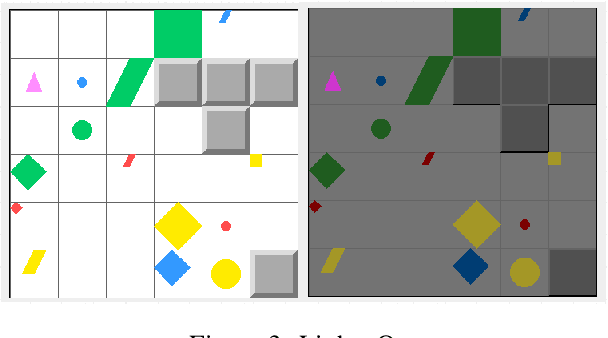
gComm is a step towards developing a robust platform to foster research in grounded language acquisition in a more challenging and realistic setting. It comprises a 2-d grid environment with a set of agents (a stationary speaker and a mobile listener connected via a communication channel) exposed to a continuous array of tasks in a partially observable setting. The key to solving these tasks lies in agents developing linguistic abilities and utilizing them for efficiently exploring the environment. The speaker and listener have access to information provided in different modalities, i.e. the speaker's input is a natural language instruction that contains the target and task specifications and the listener's input is its grid-view. Each must rely on the other to complete the assigned task, however, the only way they can achieve the same, is to develop and use some form of communication. gComm provides several tools for studying different forms of communication and assessing their generalization.
Regression Networks For Calculating Englacial Layer Thickness
Apr 10, 2021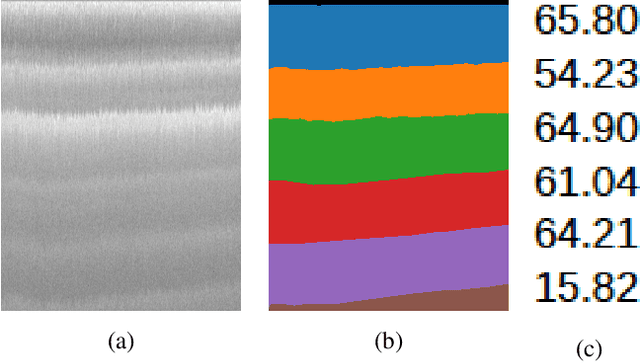
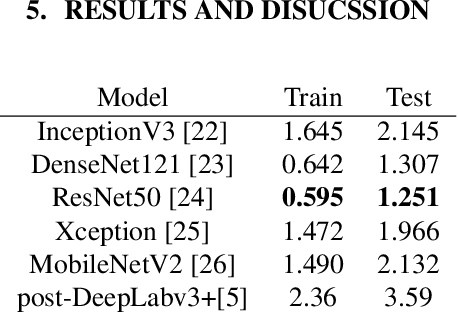
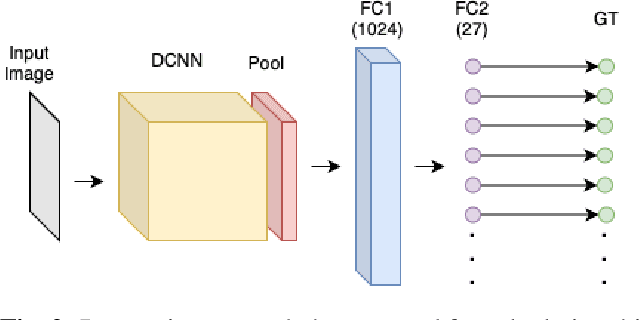
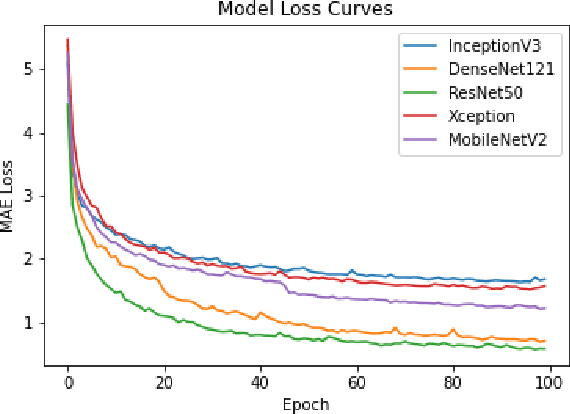
Ice thickness estimation is an important aspect of ice sheet studies. In this work, we use convolutional neural networks with multiple output nodes to regress and learn the thickness of internal ice layers in Snow Radar images collected in northwest Greenland. We experiment with some state-of-the-art networks and find that with the residual connections of ResNet50, we could achieve a mean absolute error of 1.251 pixels over the test set. Such regression-based networks can further be improved by embedding domain knowledge and radar information in the neural network in order to reduce the requirement of manual annotations.
Using Diachronic Distributed Word Representations as Models of Lexical Development in Children
May 11, 2021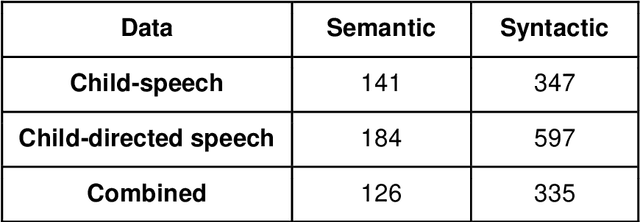
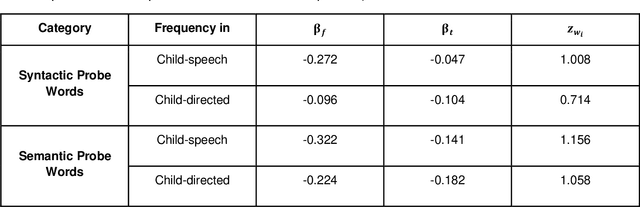
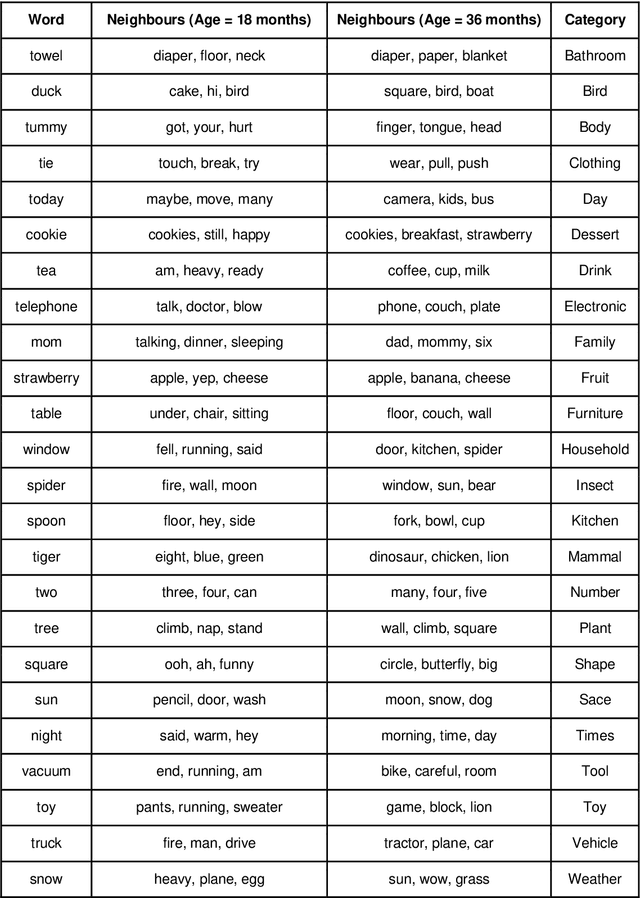
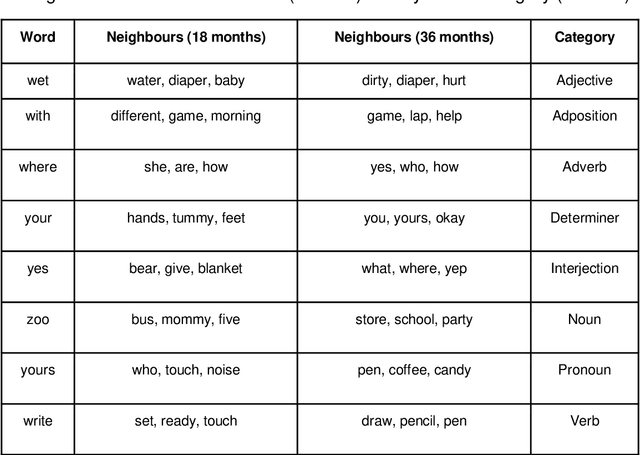
Recent work has shown that distributed word representations can encode abstract semantic and syntactic information from child-directed speech. In this paper, we use diachronic distributed word representations to perform temporal modeling and analysis of lexical development in children. Unlike all previous work, we use temporally sliced speech corpus to learn distributed word representations of child and child-directed speech. Through our modeling experiments, we demonstrate the dynamics of growing lexical knowledge in children over time, as compared against a saturated level of lexical knowledge in child-directed adult speech. We also fit linear mixed-effects models with the rate of semantic change in the diachronic representations and word frequencies. This allows us to inspect the role of word frequencies towards lexical development in children. Further, we perform a qualitative analysis of the diachronic representations from our model, which reveals the categorization and word associations in the mental lexicon of children.
Weakly-supervised multi-class object localization using only object counts as labels
Feb 23, 2021

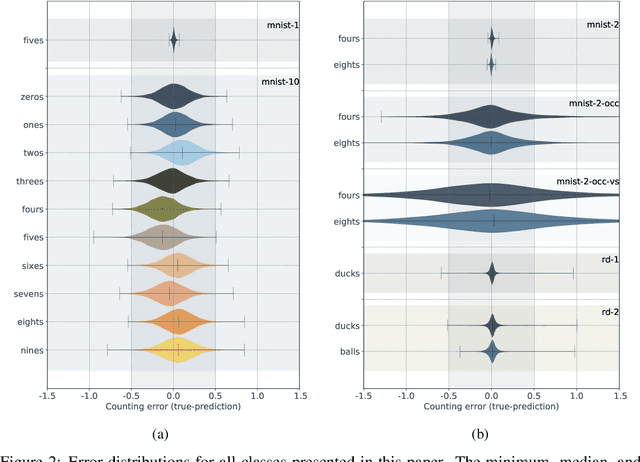

We demonstrate the use of an extensive deep neural network to localize instances of objects in images. The EDNN is naturally able to accurately perform multi-class counting using only ground truth count values as labels. Without providing any conceptual information, object annotations, or pixel segmentation information, the neural network is able to formulate its own conceptual representation of the items in the image. Using images labelled with only the counts of the objects present,the structure of the extensive deep neural network can be exploited to perform localization of the objects within the visual field. We demonstrate that a trained EDNN can be used to count objects in images much larger than those on which it was trained. In order to demonstrate our technique, we introduce seven new data sets: five progressively harder MNIST digit-counting data sets, and two datasets of 3d-rendered rubber ducks in various situations. On most of these datasets, the EDNN achieves greater than 99% test set accuracy in counting objects.