 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Scalable Gradient-Free Method for Bayesian Experimental Design with Implicit Models
Mar 14, 2021
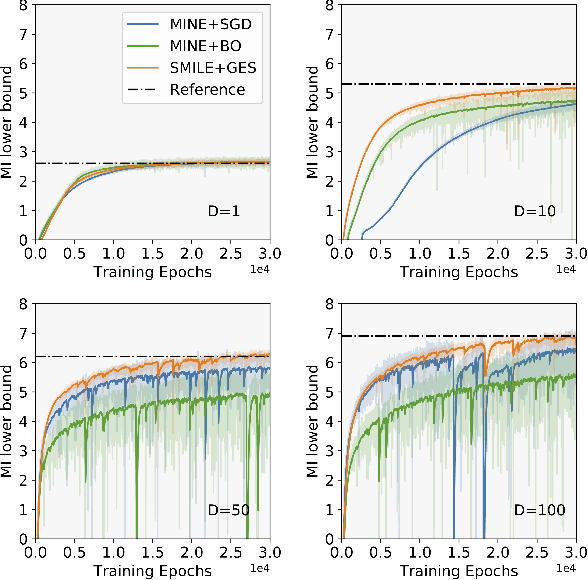

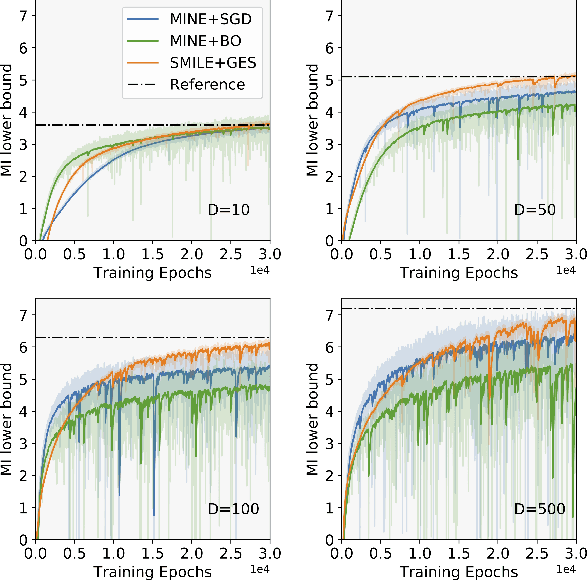
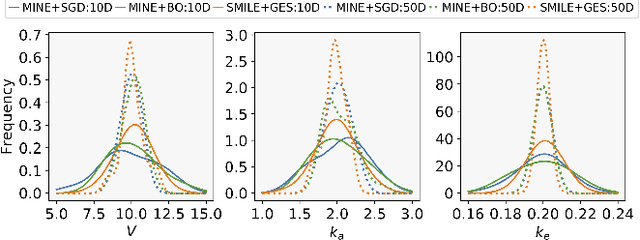
Bayesian experimental design (BED) is to answer the question that how to choose designs that maximize the information gathering. For implicit models, where the likelihood is intractable but sampling is possible, conventional BED methods have difficulties in efficiently estimating the posterior distribution and maximizing the mutual information (MI) between data and parameters. Recent work proposed the use of gradient ascent to maximize a lower bound on MI to deal with these issues. However, the approach requires a sampling path to compute the pathwise gradient of the MI lower bound with respect to the design variables, and such a pathwise gradient is usually inaccessible for implicit models. In this paper, we propose a novel approach that leverages recent advances in stochastic approximate gradient ascent incorporated with a smoothed variational MI estimator for efficient and robust BED. Without the necessity of pathwise gradients, our approach allows the design process to be achieved through a unified procedure with an approximate gradient for implicit models. Several experiments show that our approach outperforms baseline methods, and significantly improves the scalability of BED in high-dimensional problems.
Self-Guided and Cross-Guided Learning for Few-Shot Segmentation
Mar 30, 2021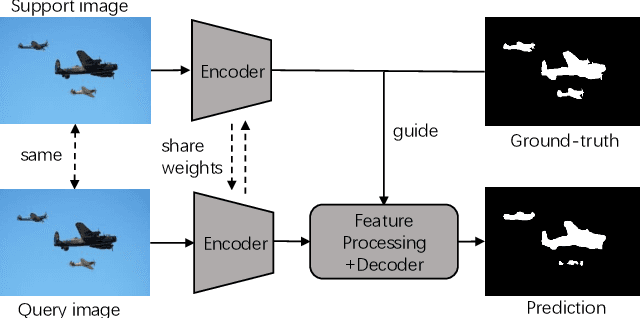
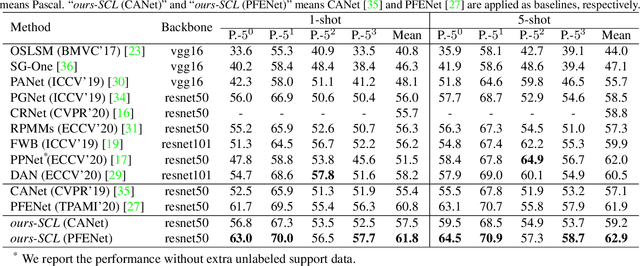
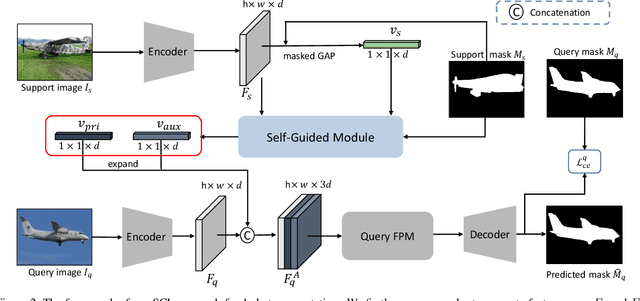

Few-shot segmentation has been attracting a lot of attention due to its effectiveness to segment unseen object classes with a few annotated samples. Most existing approaches use masked Global Average Pooling (GAP) to encode an annotated support image to a feature vector to facilitate query image segmentation. However, this pipeline unavoidably loses some discriminative information due to the average operation. In this paper, we propose a simple but effective self-guided learning approach, where the lost critical information is mined. Specifically, through making an initial prediction for the annotated support image, the covered and uncovered foreground regions are encoded to the primary and auxiliary support vectors using masked GAP, respectively. By aggregating both primary and auxiliary support vectors, better segmentation performances are obtained on query images. Enlightened by our self-guided module for 1-shot segmentation, we propose a cross-guided module for multiple shot segmentation, where the final mask is fused using predictions from multiple annotated samples with high-quality support vectors contributing more and vice versa. This module improves the final prediction in the inference stage without re-training. Extensive experiments show that our approach achieves new state-of-the-art performances on both PASCAL-5i and COCO-20i datasets.
Uncertainty in Minimum Cost Multicuts for Image and Motion Segmentation
May 16, 2021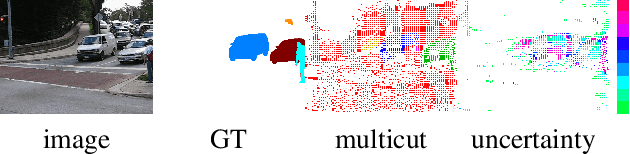

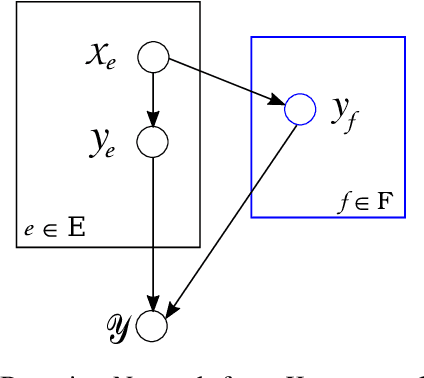

The minimum cost lifted multicut approach has proven practically good performance in a wide range of applications such as image decomposition, mesh segmentation, multiple object tracking, and motion segmentation. It addresses such problems in a graph-based model, where real-valued costs are assigned to the edges between entities such that the minimum cut decomposes the graph into an optimal number of segments. Driven by a probabilistic formulation of minimum cost multicuts, we provide a measure for the uncertainties of the decisions made during the optimization. We argue that access to such uncertainties is crucial for many practical applications and conduct an evaluation by means of sparsifications on three different, widely used datasets in the context of image decomposition (BSDS-500) and motion segmentation (DAVIS2016 and FBMS59) in terms of variation of information (VI) and Rand index (RI).
Text Compression-aided Transformer Encoding
Feb 11, 2021
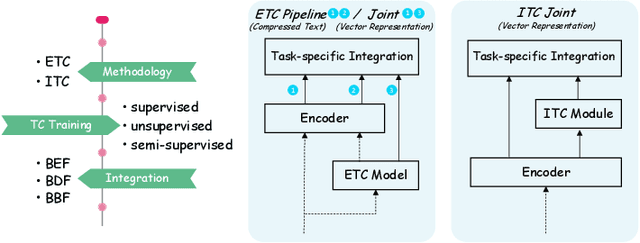
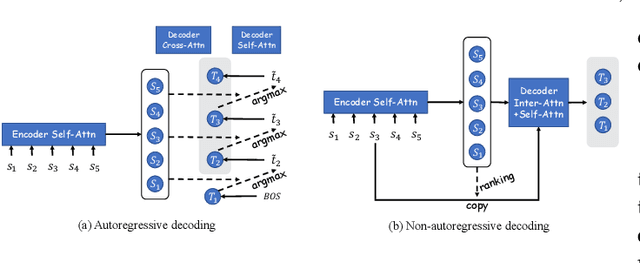
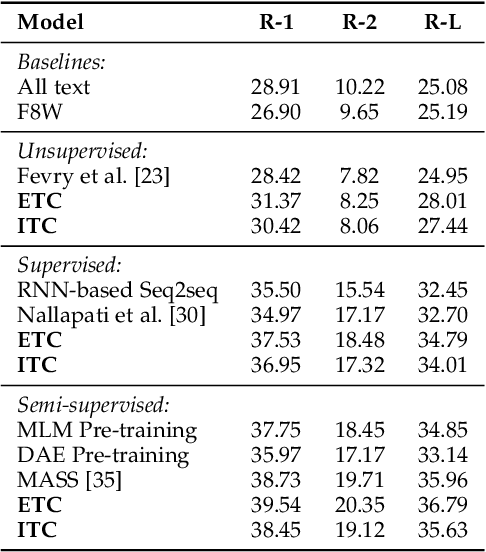
Text encoding is one of the most important steps in Natural Language Processing (NLP). It has been done well by the self-attention mechanism in the current state-of-the-art Transformer encoder, which has brought about significant improvements in the performance of many NLP tasks. Though the Transformer encoder may effectively capture general information in its resulting representations, the backbone information, meaning the gist of the input text, is not specifically focused on. In this paper, we propose explicit and implicit text compression approaches to enhance the Transformer encoding and evaluate models using this approach on several typical downstream tasks that rely on the encoding heavily. Our explicit text compression approaches use dedicated models to compress text, while our implicit text compression approach simply adds an additional module to the main model to handle text compression. We propose three ways of integration, namely backbone source-side fusion, target-side fusion, and both-side fusion, to integrate the backbone information into Transformer-based models for various downstream tasks. Our evaluation on benchmark datasets shows that the proposed explicit and implicit text compression approaches improve results in comparison to strong baselines. We therefore conclude, when comparing the encodings to the baseline models, text compression helps the encoders to learn better language representations.
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021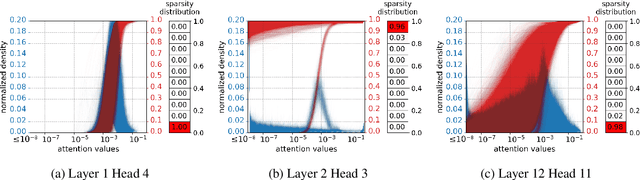
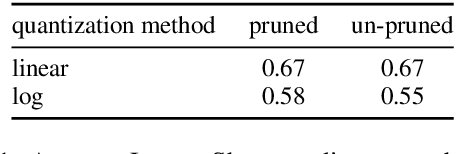
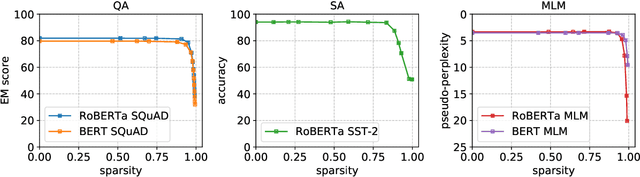
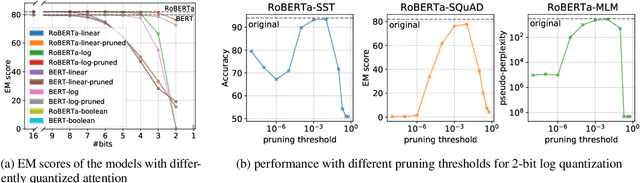
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
How is BERT surprised? Layerwise detection of linguistic anomalies
May 16, 2021



Transformer language models have shown remarkable ability in detecting when a word is anomalous in context, but likelihood scores offer no information about the cause of the anomaly. In this work, we use Gaussian models for density estimation at intermediate layers of three language models (BERT, RoBERTa, and XLNet), and evaluate our method on BLiMP, a grammaticality judgement benchmark. In lower layers, surprisal is highly correlated to low token frequency, but this correlation diminishes in upper layers. Next, we gather datasets of morphosyntactic, semantic, and commonsense anomalies from psycholinguistic studies; we find that the best performing model RoBERTa exhibits surprisal in earlier layers when the anomaly is morphosyntactic than when it is semantic, while commonsense anomalies do not exhibit surprisal at any intermediate layer. These results suggest that language models employ separate mechanisms to detect different types of linguistic anomalies.
Focus Attention: Promoting Faithfulness and Diversity in Summarization
May 25, 2021

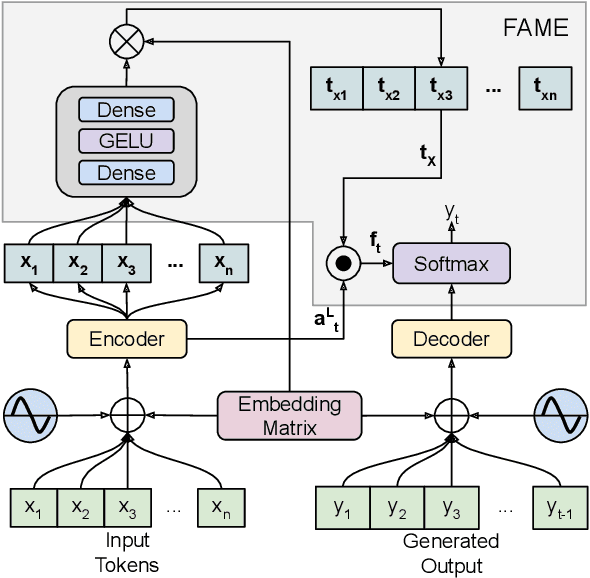
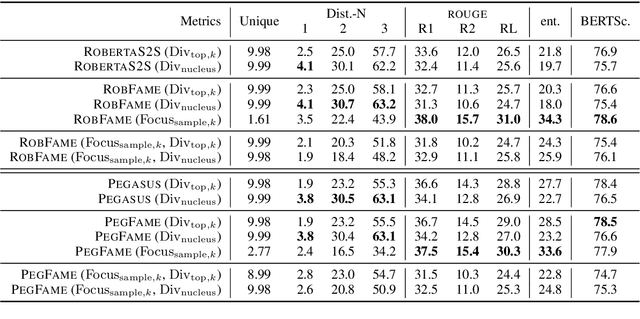
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on \rouge and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-$k$ or nucleus sampling-based decoding methods.
DeepHate: Hate Speech Detection via Multi-Faceted Text Representations
Mar 14, 2021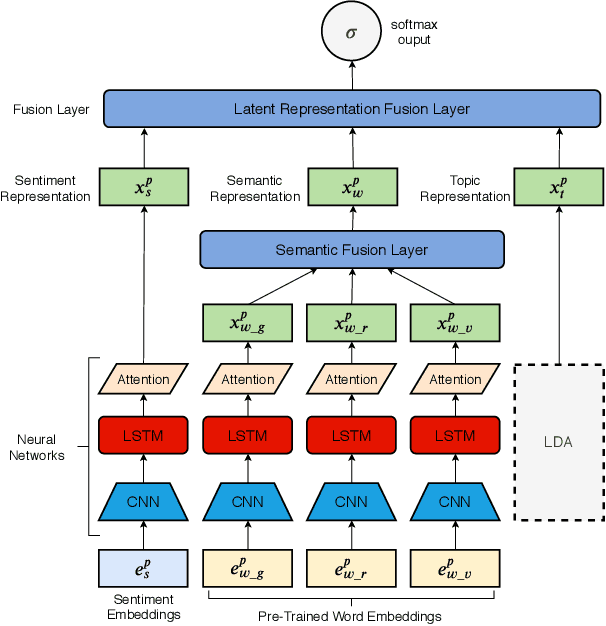
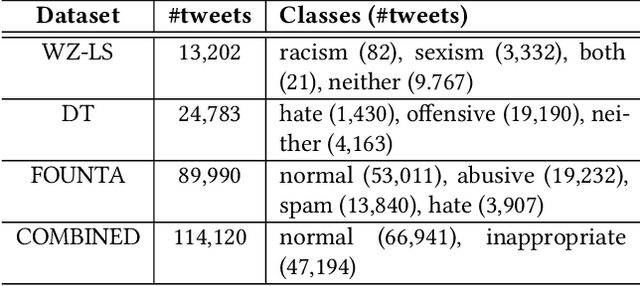
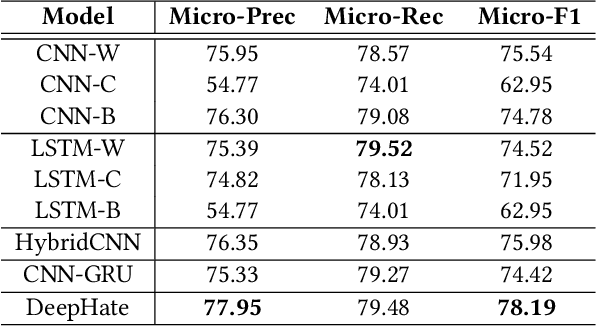
Online hate speech is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have developed many traditional machine learning and deep learning methods to detect hate speech in online social platforms automatically. However, most of these methods have only considered single type textual feature, e.g., term frequency, or using word embeddings. Such approaches neglect the other rich textual information that could be utilized to improve hate speech detection. In this paper, we propose DeepHate, a novel deep learning model that combines multi-faceted text representations such as word embeddings, sentiments, and topical information, to detect hate speech in online social platforms. We conduct extensive experiments and evaluate DeepHate on three large publicly available real-world datasets. Our experiment results show that DeepHate outperforms the state-of-the-art baselines on the hate speech detection task. We also perform case studies to provide insights into the salient features that best aid in detecting hate speech in online social platforms.
List-Decodable Coded Computing: Breaking the Adversarial Toleration Barrier
Jan 27, 2021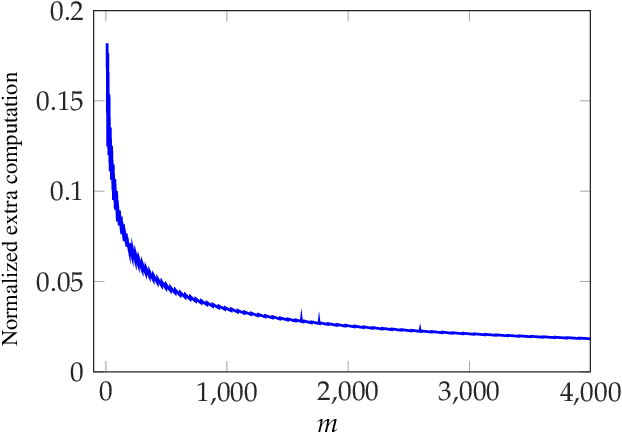
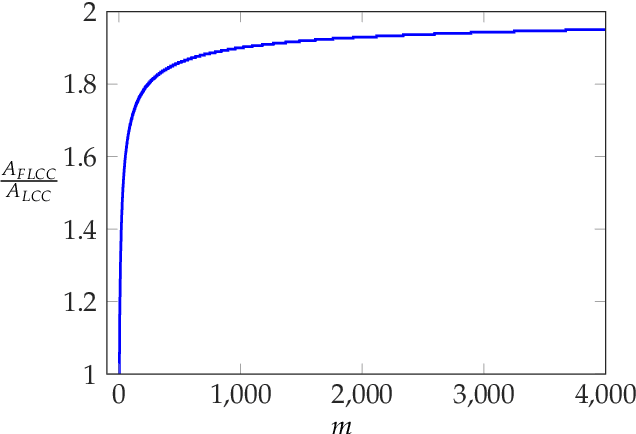
We consider the problem of coded computing where a computational task is performed in a distributed fashion in the presence of adversarial workers. We propose techniques to break the adversarial toleration threshold barrier previously known in coded computing. More specifically, we leverage list-decoding techniques for folded Reed-Solomon (FRS) codes and propose novel algorithms to recover the correct codeword using side information. In the coded computing setting, we show how the master node can perform certain carefully designed extra computations in order to obtain the side information. This side information will be then utilized to prune the output of list decoder in order to uniquely recover the true outcome. We further propose folded Lagrange coded computing, referred to as folded LCC or FLCC, to incorporate the developed techniques into a specific coded computing setting. Our results show that FLCC outperforms LCC by breaking the barrier on the number of adversaries that can be tolerated. In particular, the corresponding threshold in FLCC is improved by a factor of two compared to that of LCC.
Feature Reuse and Fusion for Real-time Semantic segmentation
Jun 02, 2021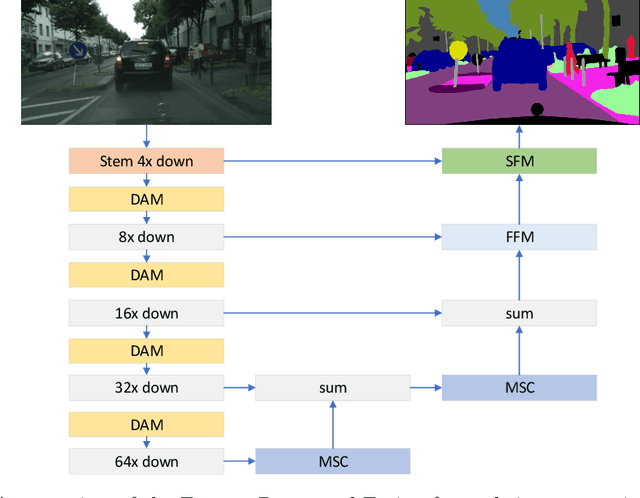
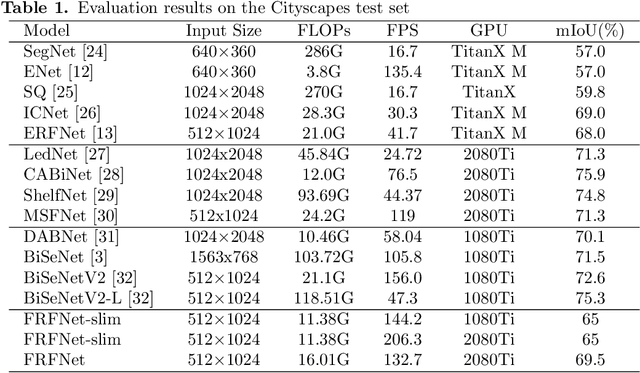
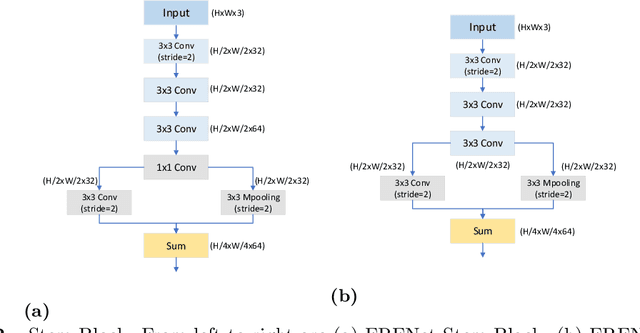

For real-time semantic segmentation, how to increase the speed while maintaining high resolution is a problem that has been discussed and solved. Backbone design and fusion design have always been two essential parts of real-time semantic segmentation. We hope to design a light-weight network based on previous design experience and reach the level of state-of-the-art real-time semantic segmentation without any pre-training. To achieve this goal, a encoder-decoder architectures are proposed to solve this problem by applying a decoder network onto a backbone model designed for real-time segmentation tasks and designed three different ways to fuse semantics and detailed information in the aggregation phase. We have conducted extensive experiments on two semantic segmentation benchmarks. Experiments on the Cityscapes and CamVid datasets show that the proposed FRFNet strikes a balance between speed calculation and accuracy. It achieves 69% Mean Intersection over Union (mIoU%) on the Cityscapes test dataset with the speed of 132on a single RTX 2080Ti card. The Code is available at https://github.com/favoMJ/FRFNet.