 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Game Information System
Jun 10, 2010
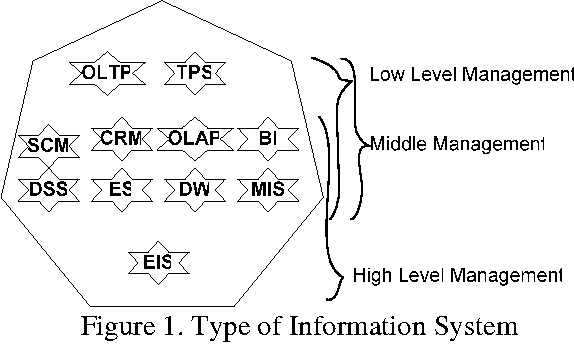
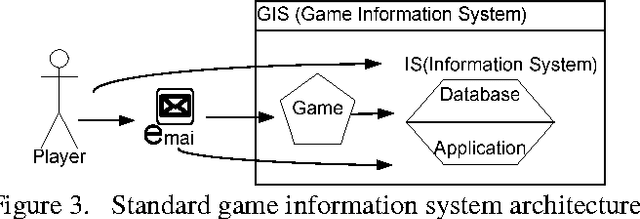


In this Information system age many organizations consider information system as their weapon to compete or gain competitive advantage or give the best services for non profit organizations. Game Information System as combining Information System and game is breakthrough to achieve organizations' performance. The Game Information System will run the Information System with game and how game can be implemented to run the Information System. Game is not only for fun and entertainment, but will be a challenge to combine fun and entertainment with Information System. The Challenge to run the information system with entertainment, deliver the entertainment with information system all at once. Game information system can be implemented in many sectors as like the information system itself but in difference's view. A view of game which people can joy and happy and do their transaction as a fun things.
* 14 pages
Classification and comparison of license plates localization algorithms
Apr 28, 2021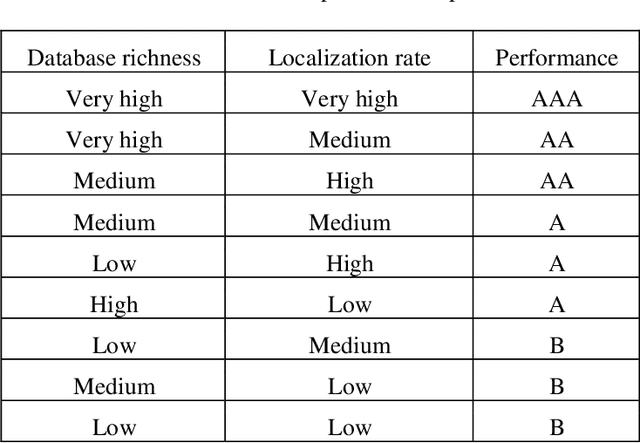
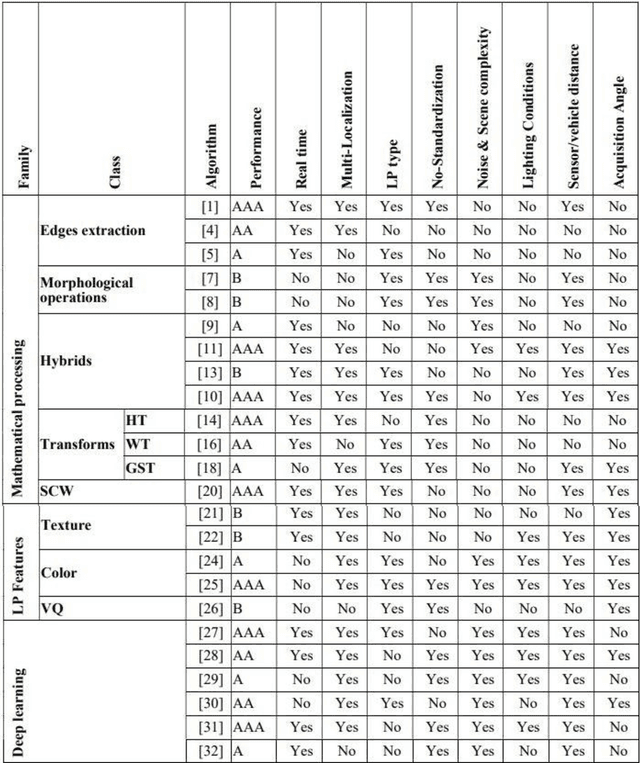
The Intelligent Transportation Systems (ITS) are the subject of a world economic competition. They are the application of new information and communication technologies in the transport sector, to make the infrastructures more efficient, more reliable and more ecological. License Plates Recognition (LPR) is the key module of these systems, in which the License Plate Localization (LPL) is the most important stage, because it determines the speed and robustness of this module. Thus, during this step the algorithm must process the image and overcome several constraints as climatic and lighting conditions, sensors and angles variety, LPs no-standardization, and the real time processing. This paper presents a classification and comparison of License Plates Localization (LPL) algorithms and describes the advantages, disadvantages and improvements made by each of them
Person Re-Identification with a Locally Aware Transformer
Jun 08, 2021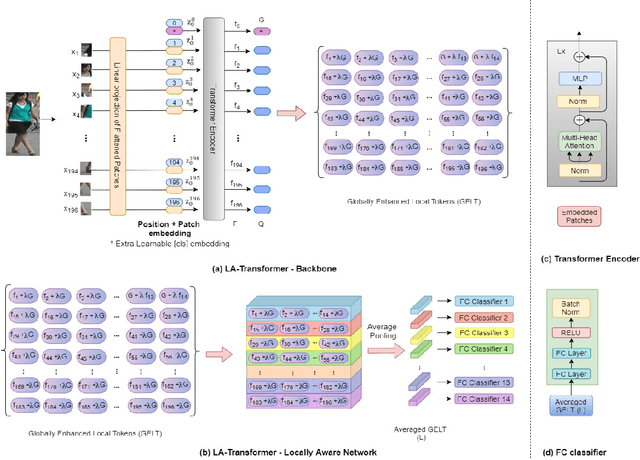
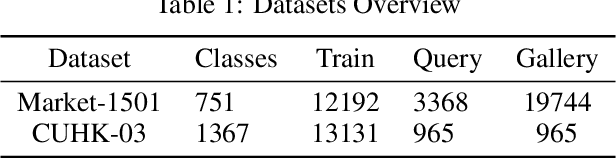
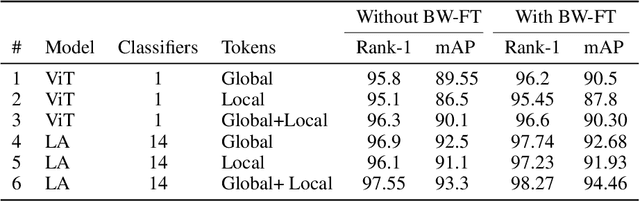
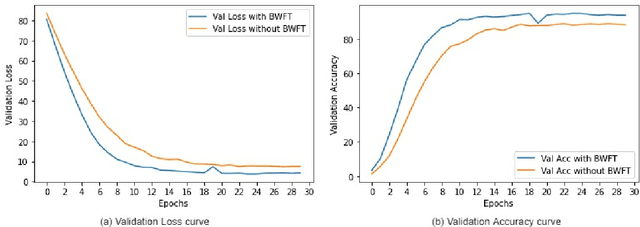
Person Re-Identification is an important problem in computer vision-based surveillance applications, in which the same person is attempted to be identified from surveillance photographs in a variety of nearby zones. At present, the majority of Person re-ID techniques are based on Convolutional Neural Networks (CNNs), but Vision Transformers are beginning to displace pure CNNs for a variety of object recognition tasks. The primary output of a vision transformer is a global classification token, but vision transformers also yield local tokens which contain additional information about local regions of the image. Techniques to make use of these local tokens to improve classification accuracy are an active area of research. We propose a novel Locally Aware Transformer (LA-Transformer) that employs a Parts-based Convolution Baseline (PCB)-inspired strategy for aggregating globally enhanced local classification tokens into an ensemble of $\sqrt{N}$ classifiers, where $N$ is the number of patches. An additional novelty is that we incorporate blockwise fine-tuning which further improves re-ID accuracy. LA-Transformer with blockwise fine-tuning achieves rank-1 accuracy of $98.27 \%$ with standard deviation of $0.13$ on the Market-1501 and $98.7\%$ with standard deviation of $0.2$ on the CUHK03 dataset respectively, outperforming all other state-of-the-art published methods at the time of writing.
Collaborative Mapping of Archaeological Sites using multiple UAVs
May 17, 2021
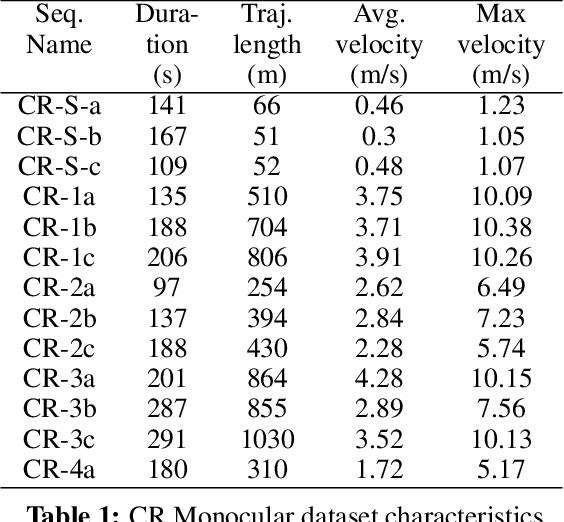
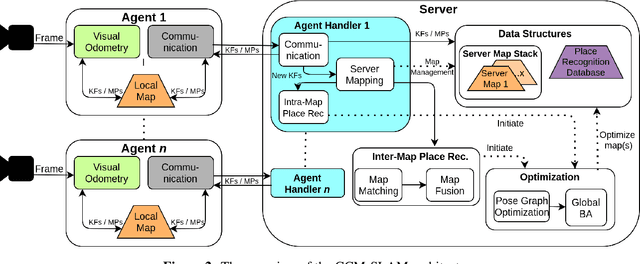
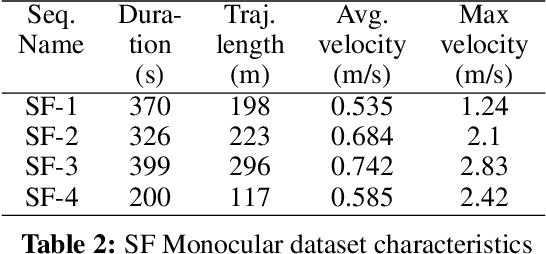
UAVs have found an important application in archaeological mapping. Majority of the existing methods employ an offline method to process the data collected from an archaeological site. They are time-consuming and computationally expensive. In this paper, we present a multi-UAV approach for faster mapping of archaeological sites. Employing a team of UAVs not only reduces the mapping time by distribution of coverage area, but also improves the map accuracy by exchange of information. Through extensive experiments in a realistic simulation (AirSim), we demonstrate the advantages of using a collaborative mapping approach. We then create the first 3D map of the Sadra Fort, a 15th Century Fort located in Gujarat, India using our proposed method. Additionally, we present two novel archaeological datasets recorded in both simulation and real-world to facilitate research on collaborative archaeological mapping. For the benefit of the community, we make the AirSim simulation environment, as well as the datasets publicly available.
Recommending Multiple Criteria Decision Analysis Methods with A New Taxonomy-based Decision Support System
Jun 08, 2021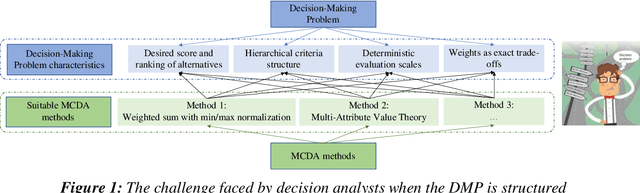
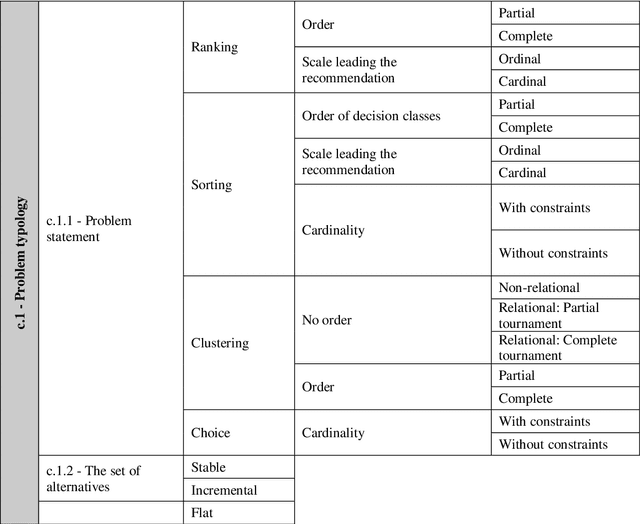

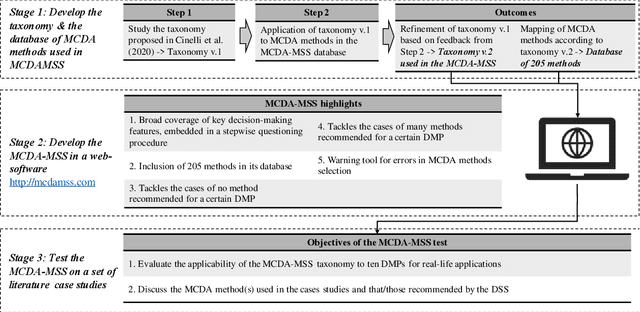
We present the Multiple Criteria Decision Analysis Methods Selection Software (MCDA-MSS). This decision support system helps analysts answering a recurring question in decision science: Which is the most suitable Multiple Criteria Decision Analysis method (or a subset of MCDA methods) that should be used for a given Decision-Making Problem (DMP)?. The MCDA-MSS includes guidance to lead decision-making processes and choose among an extensive collection (over 200) of MCDA methods. These are assessed according to an original comprehensive set of problem characteristics. The accounted features concern problem formulation, preference elicitation and types of preference information, desired features of a preference model, and construction of the decision recommendation. The applicability of the MCDA-MSS has been tested on several case studies. The MCDA-MSS includes the capabilities of (i) covering from very simple to very complex DMPs, (ii) offering recommendations for DMPs that do not match any method from the collection, (iii) helping analysts prioritize efforts for reducing gaps in the description of the DMPs, and (iv) unveiling methodological mistakes that occur in the selection of the methods. A community-wide initiative involving experts in MCDA methodology, analysts using these methods, and decision-makers receiving decision recommendations will contribute to expansion of the MCDA-MSS.
Halo: Learning Semantics-Aware Representations for Cross-Lingual Information Extraction
May 21, 2018
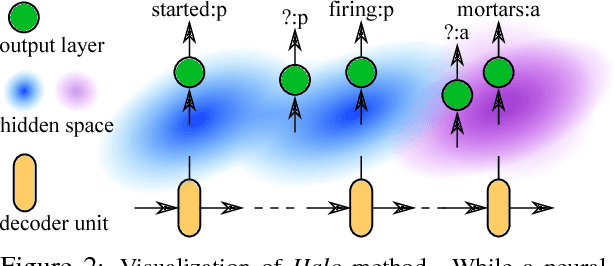
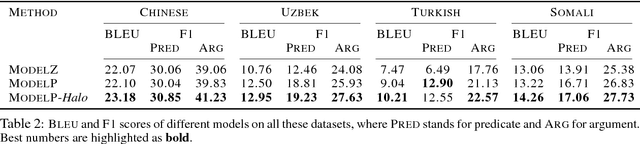
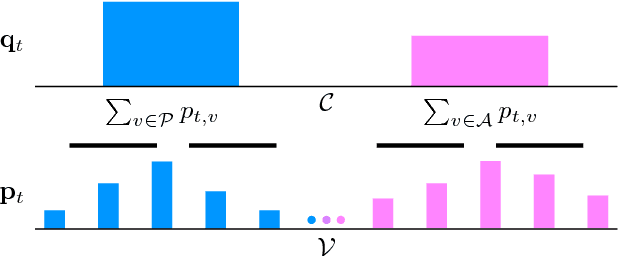
Cross-lingual information extraction (CLIE) is an important and challenging task, especially in low resource scenarios. To tackle this challenge, we propose a training method, called Halo, which enforces the local region of each hidden state of a neural model to only generate target tokens with the same semantic structure tag. This simple but powerful technique enables a neural model to learn semantics-aware representations that are robust to noise, without introducing any extra parameter, thus yielding better generalization in both high and low resource settings.
Mobile Sensing for Multipurpose Applications in Transportation
Jun 20, 2021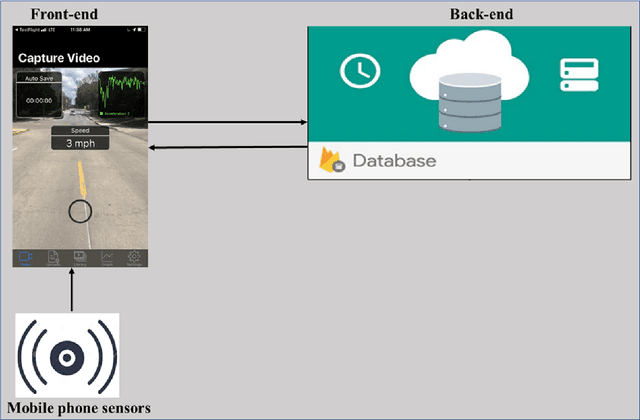
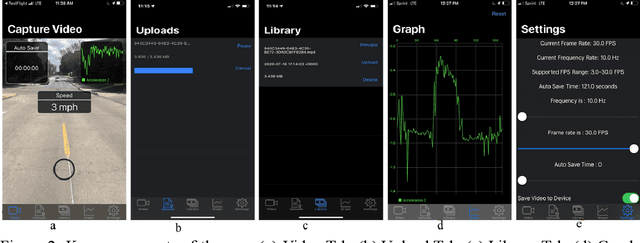
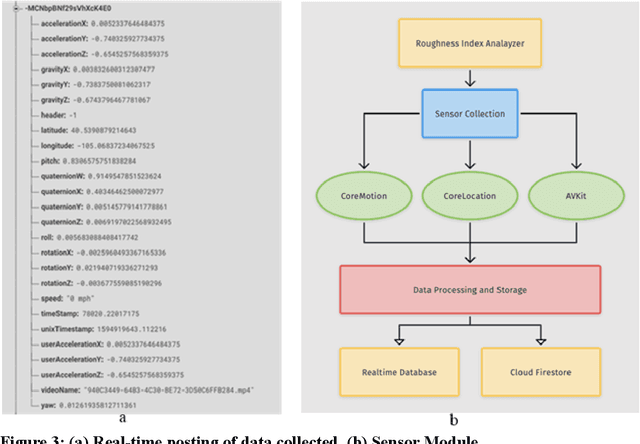

Routine and consistent data collection is required to address contemporary transportation issues.The cost of data collection increases significantly when sophisticated machines are used to collect data. Due to this constraint, State Departments of Transportation struggles to collect consistent data for analyzing and resolving transportation problems in a timely manner. Recent advancements in the sensors integrated into smartphones have resulted in a more affordable method of data collection.The primary objective of this study is to develop and implement a smartphone application for data collection.The currently designed app consists of three major modules: a frontend graphical user interface (GUI), a sensor module, and a backend module. While the frontend user interface enables interaction with the app, the sensor modules collect relevant data such as video and accelerometer readings while the app is in use. The backend, on the other hand, is made up of firebase storage, which is used to store the gathered data.In comparison to other developed apps for collecting pavement information, this current app is not overly reliant on the internet enabling the app to be used in areas of restricted internet access.The developed application was evaluated by collecting data on the i70W highway connecting Columbia, Missouri, and Kansas City, Missouri.The data was analyzed for a variety of purposes, including calculating the International Roughness Index (IRI), identifying pavement distresses, and understanding driver's behaviour and environment .The results of the application indicate that the data collected by the app is of high quality.
Efficiently Explaining CSPs with Unsatisfiable Subset Optimization
May 25, 2021
We build on a recently proposed method for explaining solutions of constraint satisfaction problems. An explanation here is a sequence of simple inference steps, where the simplicity of an inference step is measured by the number and types of constraints and facts used, and where the sequence explains all logical consequences of the problem. We build on these formal foundations and tackle two emerging questions, namely how to generate explanations that are provably optimal (with respect to the given cost metric) and how to generate them efficiently. To answer these questions, we develop 1) an implicit hitting set algorithm for finding optimal unsatisfiable subsets; 2) a method to reduce multiple calls for (optimal) unsatisfiable subsets to a single call that takes constraints on the subset into account, and 3) a method for re-using relevant information over multiple calls to these algorithms. The method is also applicable to other problems that require finding cost-optimal unsatiable subsets. We specifically show that this approach can be used to effectively find sequences of optimal explanation steps for constraint satisfaction problems like logic grid puzzles.
GeoMol: Torsional Geometric Generation of Molecular 3D Conformer Ensembles
Jun 08, 2021
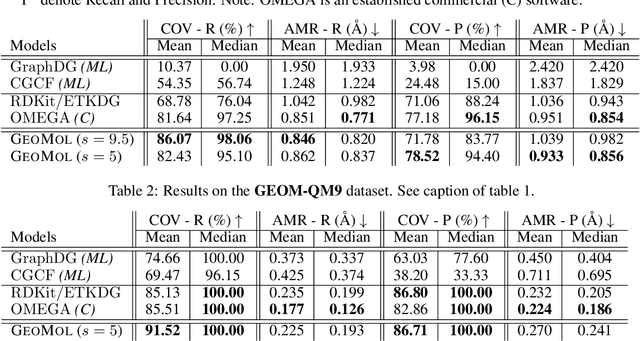
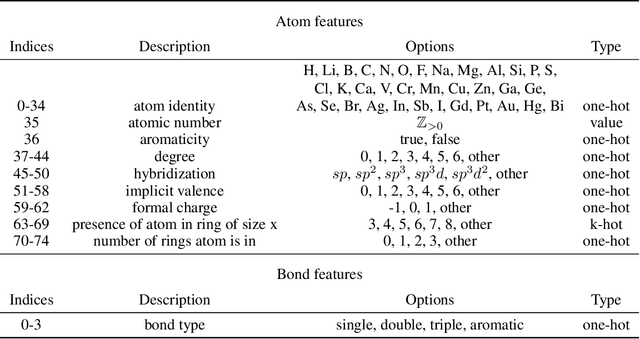
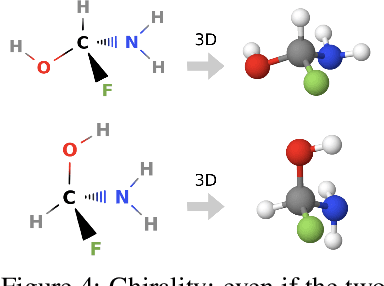
Prediction of a molecule's 3D conformer ensemble from the molecular graph holds a key role in areas of cheminformatics and drug discovery. Existing generative models have several drawbacks including lack of modeling important molecular geometry elements (e.g. torsion angles), separate optimization stages prone to error accumulation, and the need for structure fine-tuning based on approximate classical force-fields or computationally expensive methods such as metadynamics with approximate quantum mechanics calculations at each geometry. We propose GeoMol--an end-to-end, non-autoregressive and SE(3)-invariant machine learning approach to generate distributions of low-energy molecular 3D conformers. Leveraging the power of message passing neural networks (MPNNs) to capture local and global graph information, we predict local atomic 3D structures and torsion angles, avoiding unnecessary over-parameterization of the geometric degrees of freedom (e.g. one angle per non-terminal bond). Such local predictions suffice both for the training loss computation, as well as for the full deterministic conformer assembly (at test time). We devise a non-adversarial optimal transport based loss function to promote diverse conformer generation. GeoMol predominantly outperforms popular open-source, commercial, or state-of-the-art machine learning (ML) models, while achieving significant speed-ups. We expect such differentiable 3D structure generators to significantly impact molecular modeling and related applications.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 08, 2021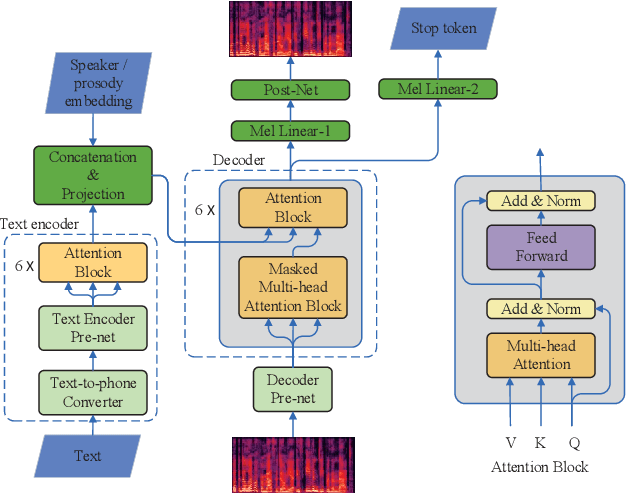
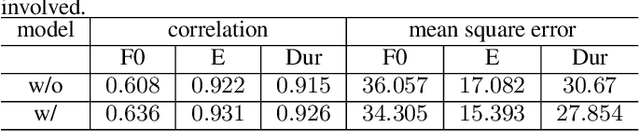
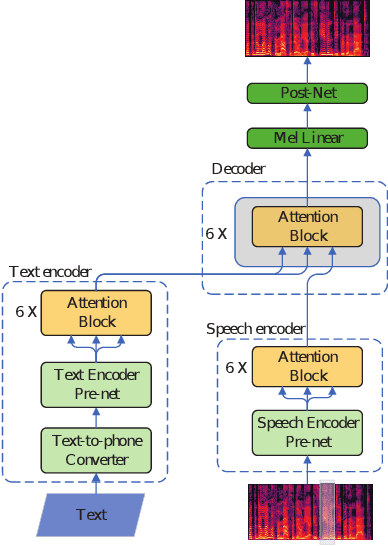
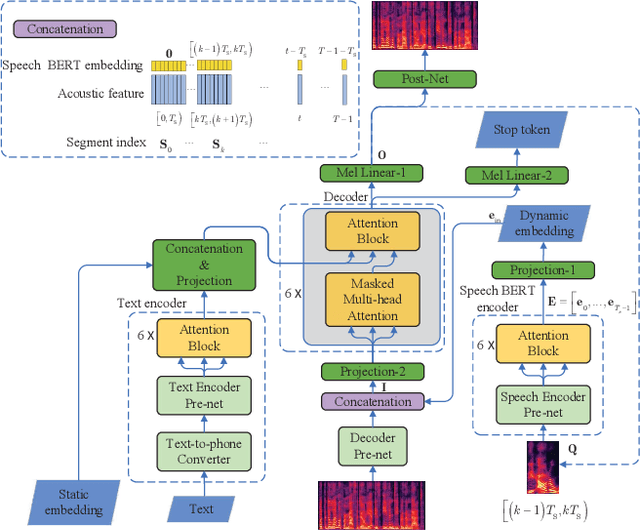
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.