 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Principled Hyperedge Prediction with Structural Spectral Features and Neural Networks
Jun 10, 2021
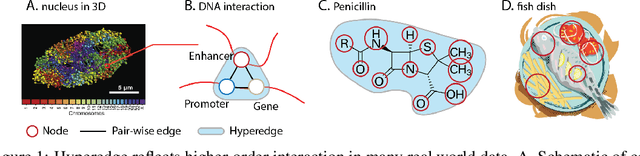

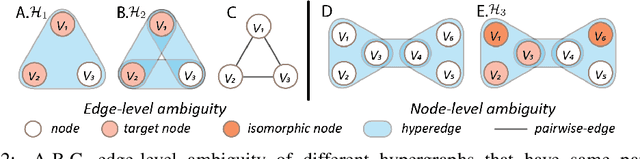

Hypergraph offers a framework to depict the multilateral relationships in real-world complex data. Predicting higher-order relationships, i.e hyperedge, becomes a fundamental problem for the full understanding of complicated interactions. The development of graph neural network (GNN) has greatly advanced the analysis of ordinary graphs with pair-wise relations. However, these methods could not be easily extended to the case of hypergraph. In this paper, we generalize the challenges of GNN in representing higher-order data in principle, which are edge- and node-level ambiguities. To overcome the challenges, we present SNALS that utilizes bipartite graph neural network with structural features to collectively tackle the two ambiguity issues. SNALS captures the joint interactions of a hyperedge by its local environment, which is retrieved by collecting the spectrum information of their connections. As a result, SNALS achieves nearly 30% performance increase compared with most recent GNN-based models. In addition, we applied SNALS to predict genetic higher-order interactions on 3D genome organization data. SNALS showed consistently high prediction accuracy across different chromosomes, and generated novel findings on 4-way gene interaction, which is further validated by existing literature.
GRASP: Graph Alignment through Spectral Signatures
Jun 10, 2021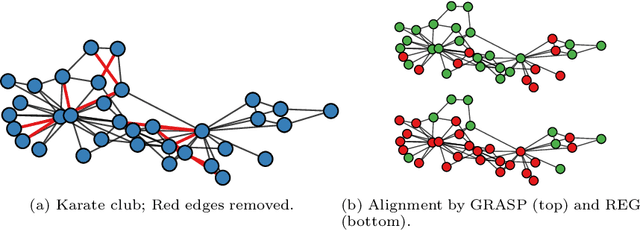
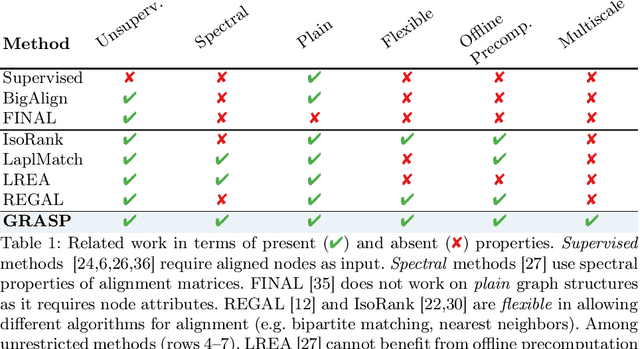
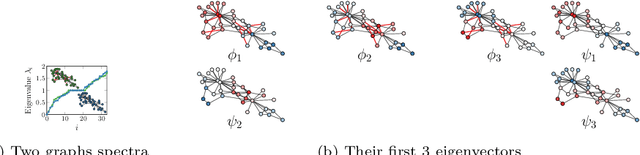
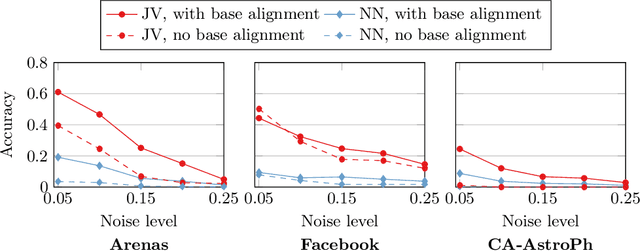
What is the best way to match the nodes of two graphs? This graph alignment problem generalizes graph isomorphism and arises in applications from social network analysis to bioinformatics. Some solutions assume that auxiliary information on known matches or node or edge attributes is available, or utilize arbitrary graph features. Such methods fare poorly in the pure form of the problem, in which only graph structures are given. Other proposals translate the problem to one of aligning node embeddings, yet, by doing so, provide only a single-scale view of the graph.In this paper, we transfer the shape-analysis concept of functional maps from the continuous to the discrete case, and treat the graph alignment problem as a special case of the problem of finding a mapping between functions on graphs. We present GRASP, a method that first establishes a correspondence between functions derived from Laplacian matrix eigenvectors, which capture multiscale structural characteristics,and then exploits this correspondence to align nodes. Our experimental study, featuring noise levels higher than anything used in previous studies, shows that GRASP outperforms state-of-the-art methods for graph alignment across noise levels and graph types.
Impact of detecting clinical trial elements in exploration of COVID-19 literature
May 25, 2021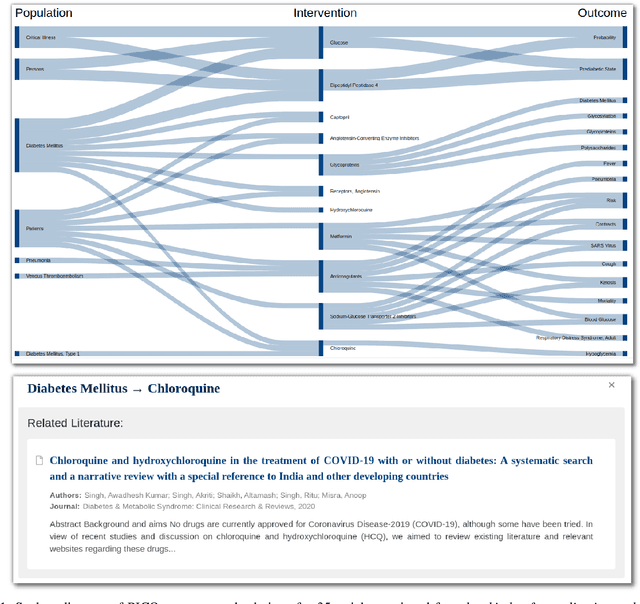
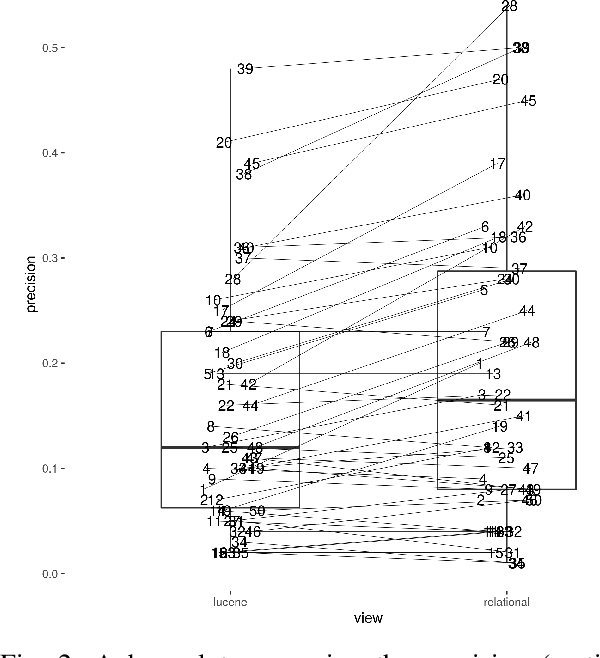
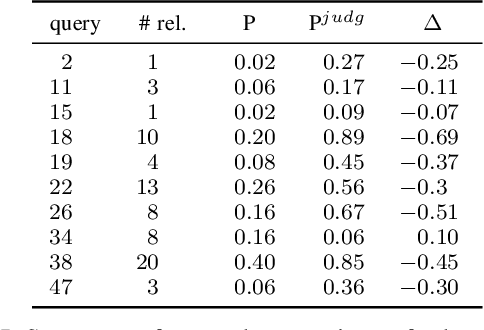

The COVID-19 pandemic has driven ever-greater demand for tools which enable efficient exploration of biomedical literature. Although semi-structured information resulting from concept recognition and detection of the defining elements of clinical trials (e.g. PICO criteria) has been commonly used to support literature search, the contributions of this abstraction remain poorly understood, especially in relation to text-based retrieval. In this study, we compare the results retrieved by a standard search engine with those filtered using clinically-relevant concepts and their relations. With analysis based on the annotations from the TREC-COVID shared task, we obtain quantitative as well as qualitative insights into characteristics of relational and concept-based literature exploration. Most importantly, we find that the relational concept selection filters the original retrieved collection in a way that decreases the proportion of unjudged documents and increases the precision, which means that the user is likely to be exposed to a larger number of relevant documents.
Teacher Model Fingerprinting Attacks Against Transfer Learning
Jun 23, 2021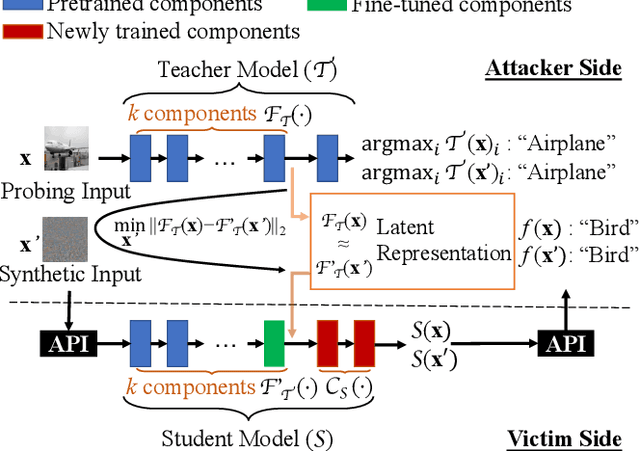
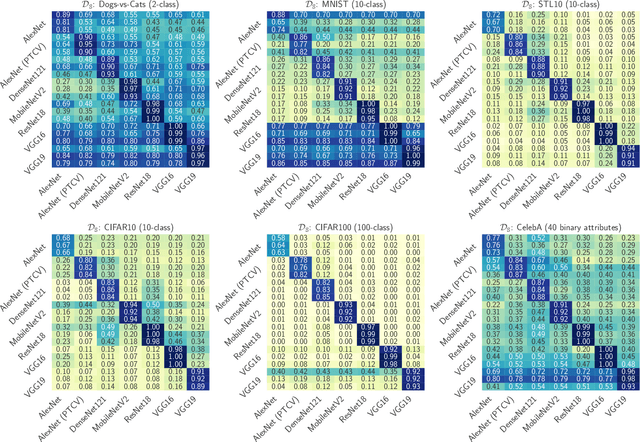
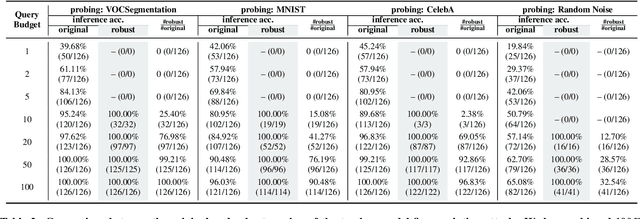
Transfer learning has become a common solution to address training data scarcity in practice. It trains a specified student model by reusing or fine-tuning early layers of a well-trained teacher model that is usually publicly available. However, besides utility improvement, the transferred public knowledge also brings potential threats to model confidentiality, and even further raises other security and privacy issues. In this paper, we present the first comprehensive investigation of the teacher model exposure threat in the transfer learning context, aiming to gain a deeper insight into the tension between public knowledge and model confidentiality. To this end, we propose a teacher model fingerprinting attack to infer the origin of a student model, i.e., the teacher model it transfers from. Specifically, we propose a novel optimization-based method to carefully generate queries to probe the student model to realize our attack. Unlike existing model reverse engineering approaches, our proposed fingerprinting method neither relies on fine-grained model outputs, e.g., posteriors, nor auxiliary information of the model architecture or training dataset. We systematically evaluate the effectiveness of our proposed attack. The empirical results demonstrate that our attack can accurately identify the model origin with few probing queries. Moreover, we show that the proposed attack can serve as a stepping stone to facilitating other attacks against machine learning models, such as model stealing.
EmpathBERT: A BERT-based Framework for Demographic-aware Empathy Prediction
Jan 30, 2021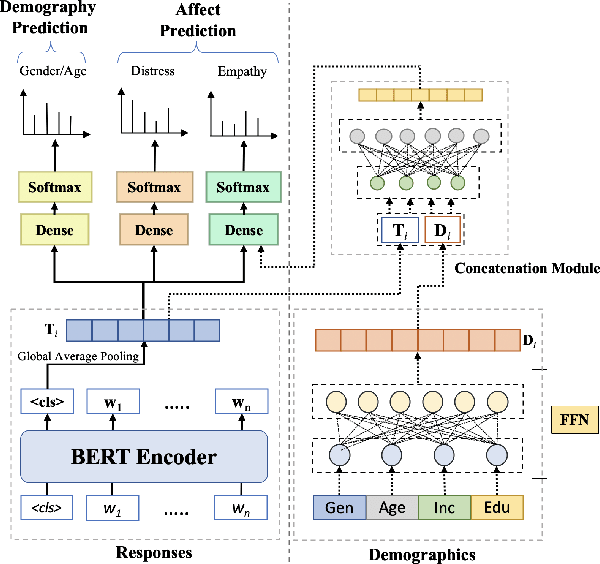

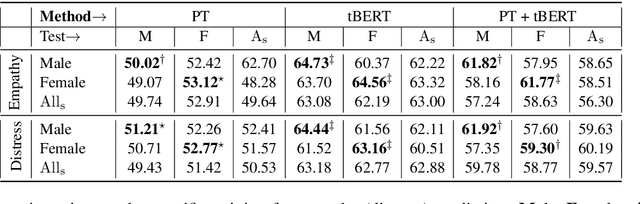
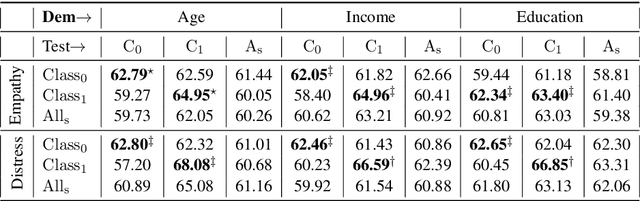
Affect preferences vary with user demographics, and tapping into demographic information provides important cues about the users' language preferences. In this paper, we utilize the user demographics, and propose EmpathBERT, a demographic-aware framework for empathy prediction based on BERT. Through several comparative experiments, we show that EmpathBERT surpasses traditional machine learning and deep learning models, and illustrate the importance of user demographics to predict empathy and distress in user responses to stimulative news articles. We also highlight the importance of affect information in the responses by developing affect-aware models to predict user demographic attributes.
User profile-driven large-scale multi-agent learning from demonstration in federated human-robot collaborative environments
Mar 30, 2021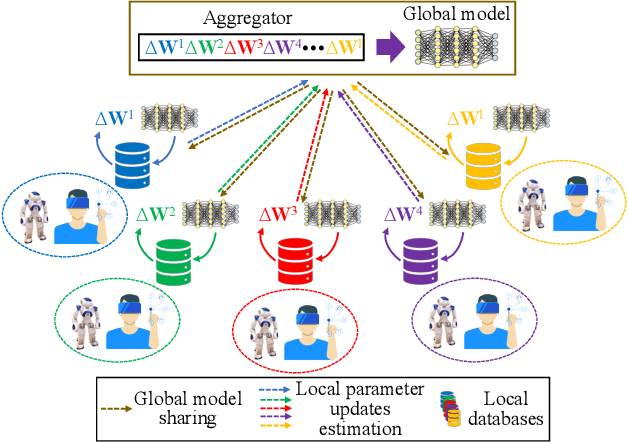
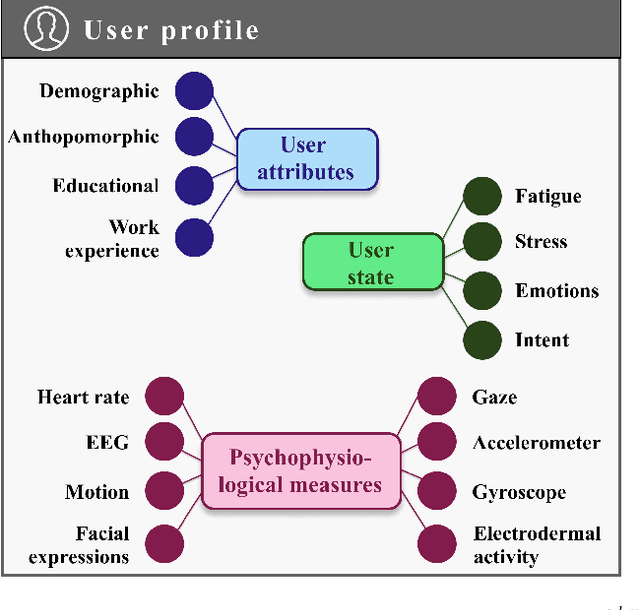
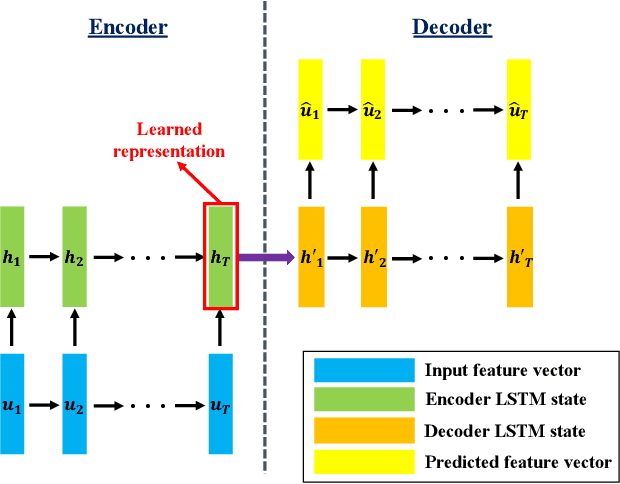
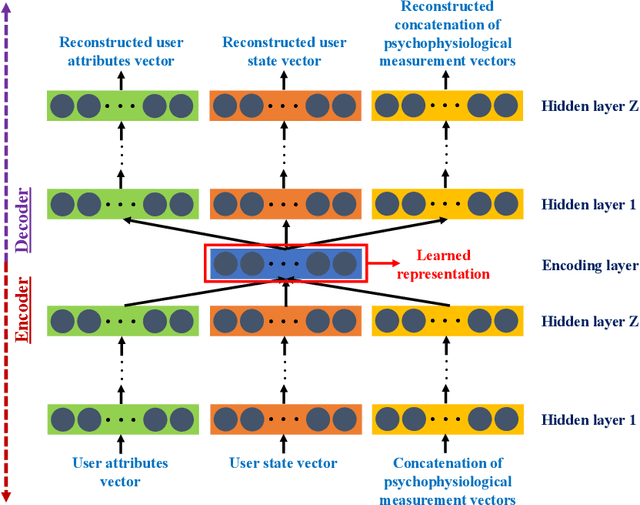
Learning from Demonstration (LfD) has been established as the dominant paradigm for efficiently transferring skills from human teachers to robots. In this context, the Federated Learning (FL) conceptualization has very recently been introduced for developing large-scale human-robot collaborative environments, targeting to robustly address, among others, the critical challenges of multi-agent learning and long-term autonomy. In the current work, the latter scheme is further extended and enhanced, by designing and integrating a novel user profile formulation for providing a fine-grained representation of the exhibited human behavior, adopting a Deep Learning (DL)-based formalism. In particular, a hierarchically organized set of key information sources is considered, including: a) User attributes (e.g. demographic, anthropomorphic, educational, etc.), b) User state (e.g. fatigue detection, stress detection, emotion recognition, etc.) and c) Psychophysiological measurements (e.g. gaze, electrodermal activity, heart rate, etc.) related data. Then, a combination of Long Short-Term Memory (LSTM) and stacked autoencoders, with appropriately defined neural network architectures, is employed for the modelling step. The overall designed scheme enables both short- and long-term analysis/interpretation of the human behavior (as observed during the feedback capturing sessions), so as to adaptively adjust the importance of the collected feedback samples when aggregating information originating from the same and different human teachers, respectively.
PPKE: Knowledge Representation Learning by Path-based Pre-training
Dec 07, 2020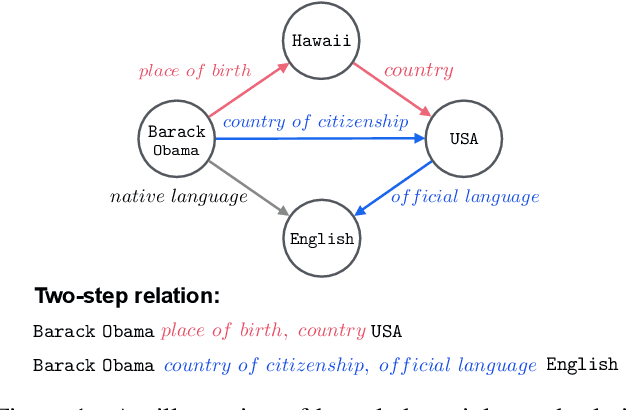

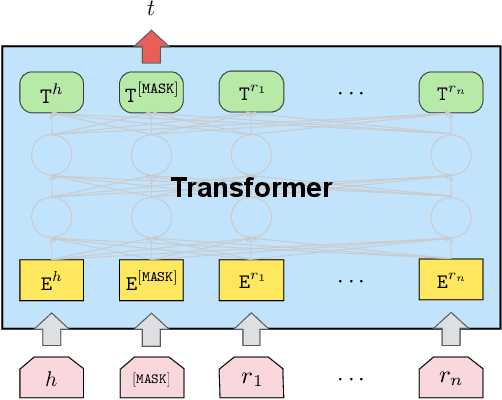
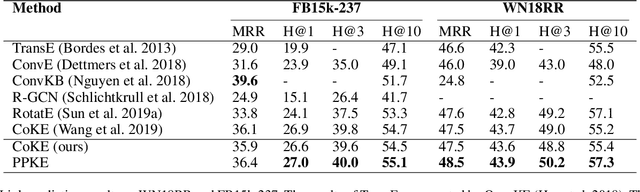
Entities may have complex interactions in a knowledge graph (KG), such as multi-step relationships, which can be viewed as graph contextual information of the entities. Traditional knowledge representation learning (KRL) methods usually treat a single triple as a training unit, and neglect most of the graph contextual information exists in the topological structure of KGs. In this study, we propose a Path-based Pre-training model to learn Knowledge Embeddings, called PPKE, which aims to integrate more graph contextual information between entities into the KRL model. Experiments demonstrate that our model achieves state-of-the-art results on several benchmark datasets for link prediction and relation prediction tasks, indicating that our model provides a feasible way to take advantage of graph contextual information in KGs.
Influence Estimation and Maximization via Neural Mean-Field Dynamics
Jun 03, 2021



We propose a novel learning framework using neural mean-field (NMF) dynamics for inference and estimation problems on heterogeneous diffusion networks. Our new framework leverages the Mori-Zwanzig formalism to obtain an exact evolution equation of the individual node infection probabilities, which renders a delay differential equation with memory integral approximated by learnable time convolution operators. Directly using information diffusion cascade data, our framework can simultaneously learn the structure of the diffusion network and the evolution of node infection probabilities. Connections between parameter learning and optimal control are also established, leading to a rigorous and implementable algorithm for training NMF. Moreover, we show that the projected gradient descent method can be employed to solve the challenging influence maximization problem, where the gradient is computed extremely fast by integrating NMF forward in time just once in each iteration. Extensive empirical studies show that our approach is versatile and robust to variations of the underlying diffusion network models, and significantly outperform existing approaches in accuracy and efficiency on both synthetic and real-world data.
Exploring Unsupervised Pretraining Objectives for Machine Translation
Jun 10, 2021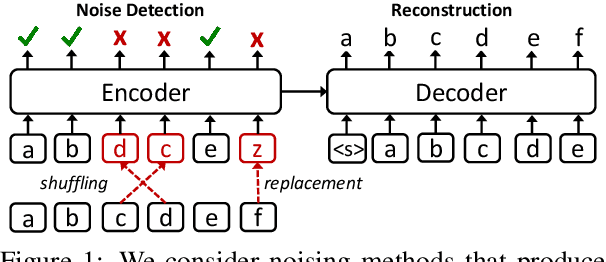
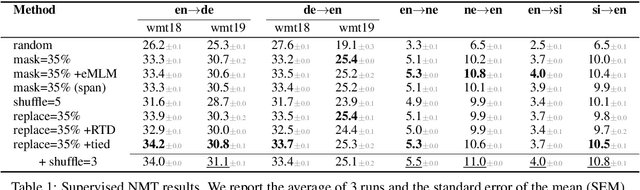
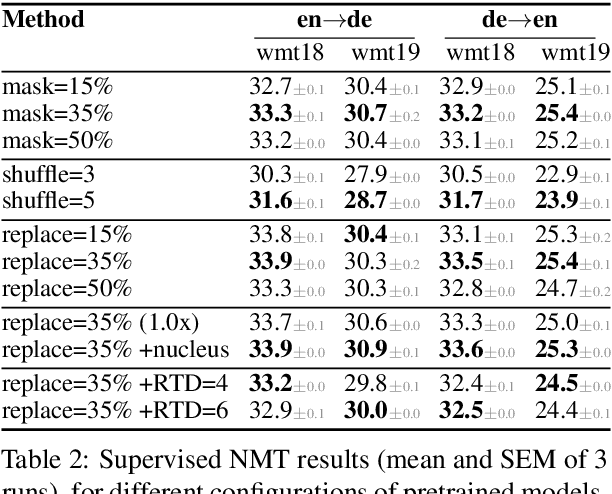
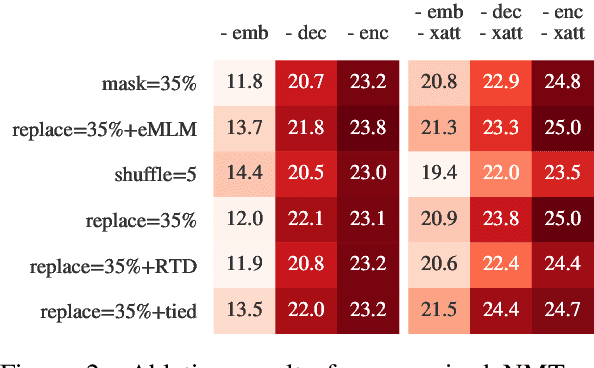
Unsupervised cross-lingual pretraining has achieved strong results in neural machine translation (NMT), by drastically reducing the need for large parallel data. Most approaches adapt masked-language modeling (MLM) to sequence-to-sequence architectures, by masking parts of the input and reconstructing them in the decoder. In this work, we systematically compare masking with alternative objectives that produce inputs resembling real (full) sentences, by reordering and replacing words based on their context. We pretrain models with different methods on English$\leftrightarrow$German, English$\leftrightarrow$Nepali and English$\leftrightarrow$Sinhala monolingual data, and evaluate them on NMT. In (semi-) supervised NMT, varying the pretraining objective leads to surprisingly small differences in the finetuned performance, whereas unsupervised NMT is much more sensitive to it. To understand these results, we thoroughly study the pretrained models using a series of probes and verify that they encode and use information in different ways. We conclude that finetuning on parallel data is mostly sensitive to few properties that are shared by most models, such as a strong decoder, in contrast to unsupervised NMT that also requires models with strong cross-lingual abilities.
MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
Jun 10, 2021
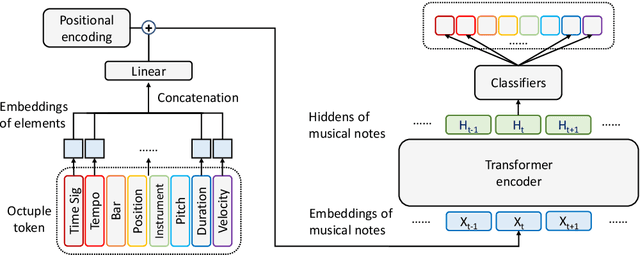
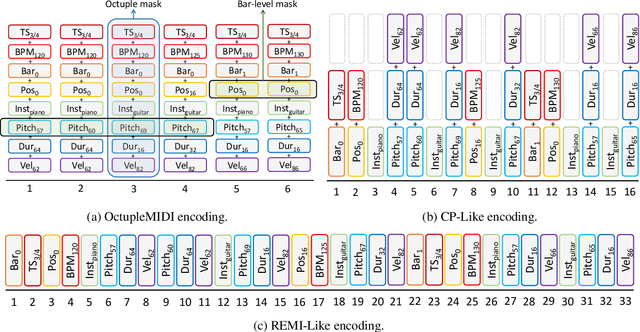
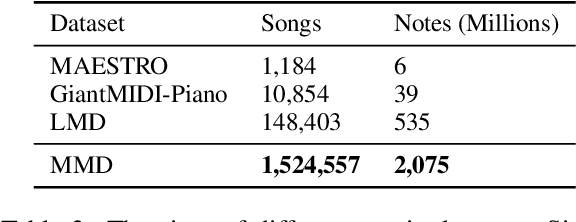
Symbolic music understanding, which refers to the understanding of music from the symbolic data (e.g., MIDI format, but not audio), covers many music applications such as genre classification, emotion classification, and music pieces matching. While good music representations are beneficial for these applications, the lack of training data hinders representation learning. Inspired by the success of pre-training models in natural language processing, in this paper, we develop MusicBERT, a large-scale pre-trained model for music understanding. To this end, we construct a large-scale symbolic music corpus that contains more than 1 million music songs. Since symbolic music contains more structural (e.g., bar, position) and diverse information (e.g., tempo, instrument, and pitch), simply adopting the pre-training techniques from NLP to symbolic music only brings marginal gains. Therefore, we design several mechanisms, including OctupleMIDI encoding and bar-level masking strategy, to enhance pre-training with symbolic music data. Experiments demonstrate the advantages of MusicBERT on four music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification. Ablation studies also verify the effectiveness of our designs of OctupleMIDI encoding and bar-level masking strategy in MusicBERT.