 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Denoising and Optical and SAR Image Classifications Based on Feature Extraction and Sparse Representation
Jun 03, 2021




Optical image data have been used by the Remote Sensing workforce to study land use and cover since such data is easily interpretable. Synthetic Aperture Radar (SAR) has the characteristic of obtaining images during all-day, all-weather and provides object information that is different from visible and infrared sensors. However, SAR images have more speckle noise and fewer dimensions. This paper presents a method for denoising, feature extraction and compares classifications of Optical and SAR images. The image was denoised using K-Singular Value Decomposition (K-SVD) algorithm. A method to map the extraordinary goal signatures to be had withinside the SAR or Optical image using support vector machine (SVM) through offering given the enter facts to the supervised classifier. Initially, the Gray Level Histogram (GLH) and Gray Level Co-occurrence Matrix (GLCM) are used for feature extraction. Secondly, the extracted feature vectors from the first step were combined using correlation analysis to reduce the dimensionality of the feature spaces. Thirdly, the Classification of SAR images was done in Sparse Representations Classification (SRC). The above-mentioned classifications techniques were developed and performance parameters are accuracy and Kappa Coefficient calculated using MATLAB 2018a.
Understanding peacefulness through the world news
Jun 03, 2021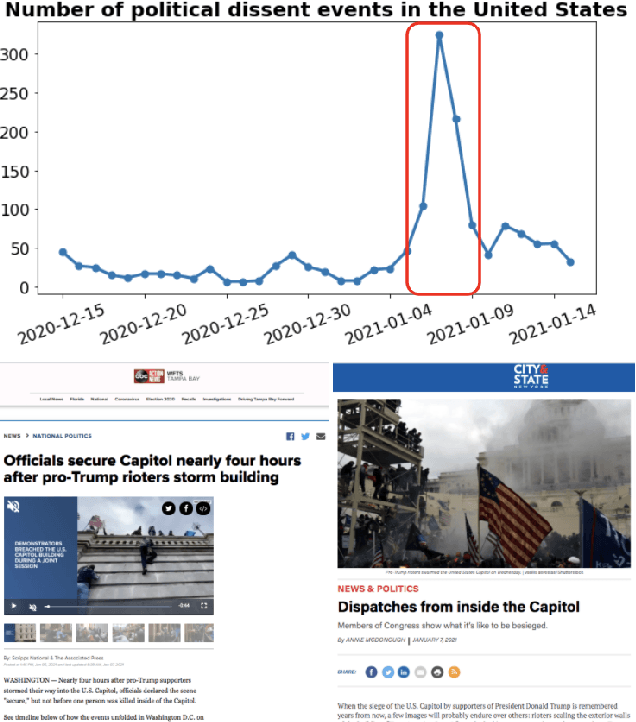

Peacefulness is a principal dimension of well-being for all humankind and is the way out of inequity and every single form of violence. Thus, its measurement has lately drawn the attention of researchers and policy-makers. During the last years, novel digital data streams have drastically changed the research in this field. In the current study, we exploit information extracted from Global Data on Events, Location, and Tone (GDELT) digital news database, to capture peacefulness through the Global Peace Index (GPI). Applying predictive machine learning models, we demonstrate that news media attention from GDELT can be used as a proxy for measuring GPI at a monthly level. Additionally, we use the SHAP methodology to obtain the most important variables that drive the predictions. This analysis highlights each country's profile and provides explanations for the predictions overall, and particularly for the errors and the events that drive these errors. We believe that digital data exploited by Social Good researchers, policy-makers, and peace-builders, with data science tools as powerful as machine learning, could contribute to maximize the societal benefits and minimize the risks to peacefulness.
Improved feature extraction for CRNN-based multiple sound source localization
May 05, 2021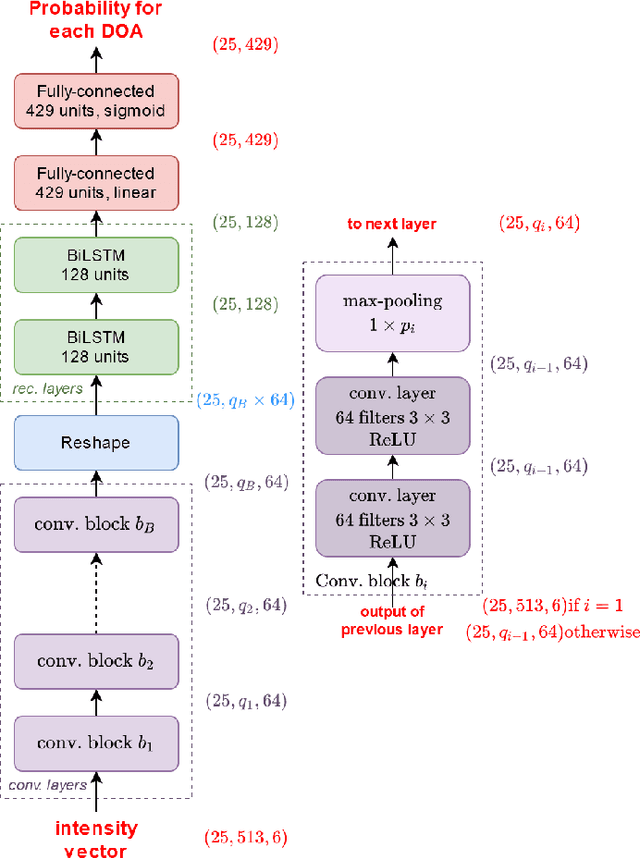
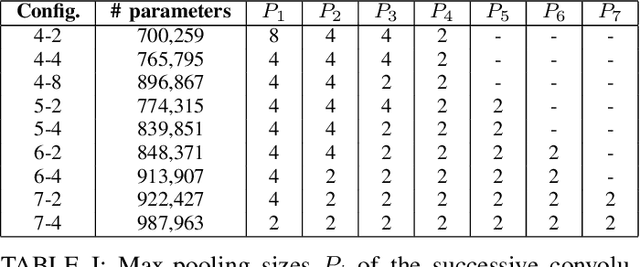
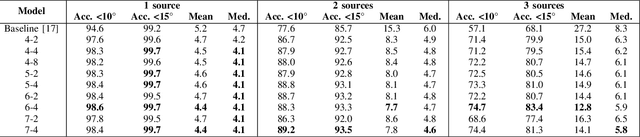
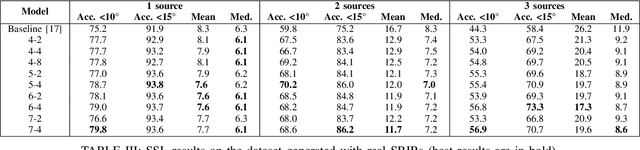
In this work, we propose to extend a state-of-the-art multi-source localization system based on a convolutional recurrent neural network and Ambisonics signals. We significantly improve the performance of the baseline network by changing the layout between convolutional and pooling layers. We propose several configurations with more convolutional layers and smaller pooling sizes in-between, so that less information is lost across the layers, leading to a better feature extraction. In parallel, we test the system's ability to localize up to 3 sources, in which case the improved feature extraction provides the most significant boost in accuracy. We evaluate and compare these improved configurations on synthetic and real-world data. The obtained results show a quite substantial improvement of the multiple sound source localization performance over the baseline network.
Deconditional Downscaling with Gaussian Processes
May 27, 2021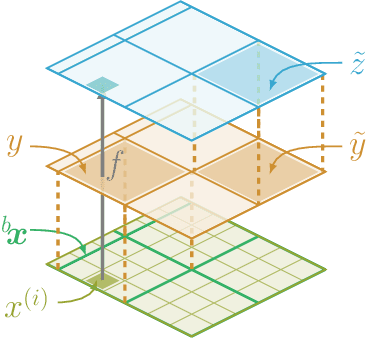

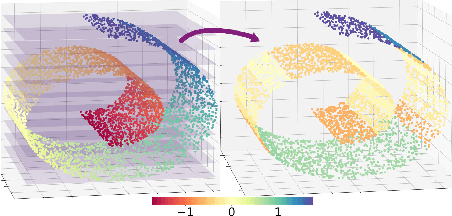
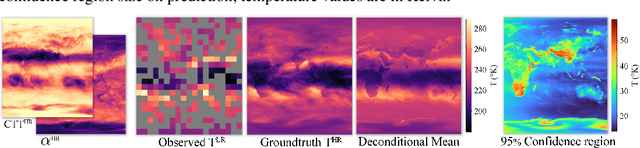
Refining low-resolution (LR) spatial fields with high-resolution (HR) information is challenging as the diversity of spatial datasets often prevents direct matching of observations. Yet, when LR samples are modeled as aggregate conditional means of HR samples with respect to a mediating variable that is globally observed, the recovery of the underlying fine-grained field can be framed as taking an "inverse" of the conditional expectation, namely a deconditioning problem. In this work, we introduce conditional mean processes (CMP), a new class of Gaussian Processes describing conditional means. By treating CMPs as inter-domain features of the underlying field, a posterior for the latent field can be established as a solution to the deconditioning problem. Furthermore, we show that this solution can be viewed as a two-staged vector-valued kernel ridge regressor and show that it has a minimax optimal convergence rate under mild assumptions. Lastly, we demonstrate its proficiency in a synthetic and a real-world atmospheric field downscaling problem, showing substantial improvements over existing methods.
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

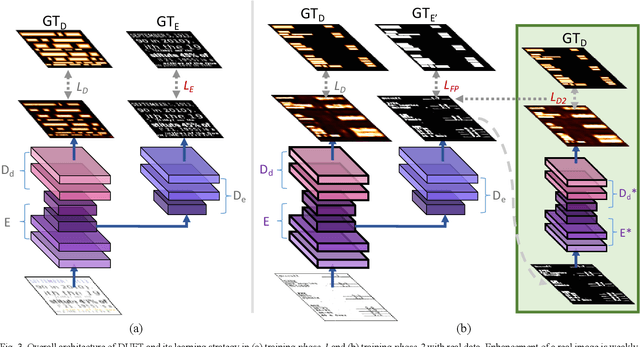

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.
Consistency-based Active Learning for Object Detection
Mar 23, 2021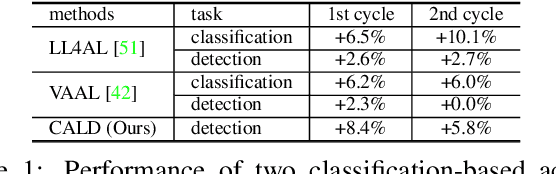
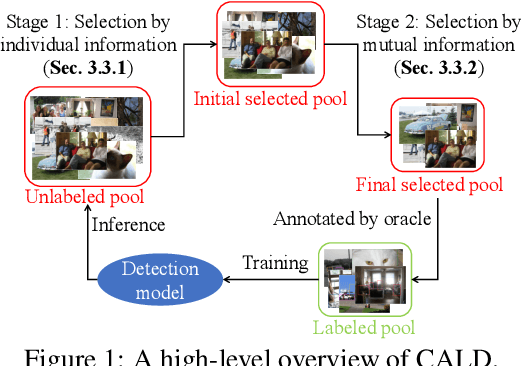
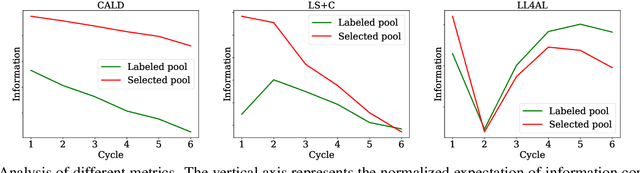
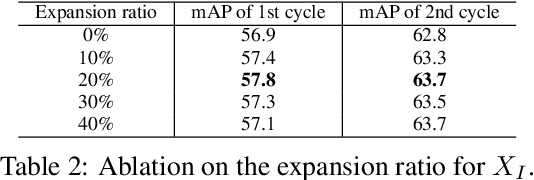
Active learning aims to improve the performance of task model by selecting the most informative samples with a limited budget. Unlike most recent works that focused on applying active learning for image classification, we propose an effective Consistency-based Active Learning method for object Detection (CALD), which fully explores the consistency between original and augmented data. CALD has three appealing benefits. (i) CALD is systematically designed by investigating the weaknesses of existing active learning methods, which do not take the unique challenges of object detection into account. (ii) CALD unifies box regression and classification with a single metric, which is not concerned by active learning methods for classification. CALD also focuses on the most informative local region rather than the whole image, which is beneficial for object detection. (iii) CALD not only gauges individual information for sample selection, but also leverages mutual information to encourage a balanced data distribution. Extensive experiments show that CALD significantly outperforms existing state-of-the-art task-agnostic and detection-specific active learning methods on general object detection datasets. Based on the Faster R-CNN detector, CALD consistently surpasses the baseline method (random selection) by 2.9/2.8/0.8 mAP on average on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO. Code is available at \url{https://github.com/we1pingyu/CALD}
Fusion-DHL: WiFi, IMU, and Floorplan Fusion for Dense History of Locations in Indoor Environments
May 18, 2021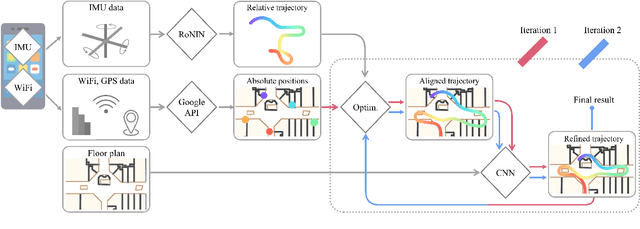
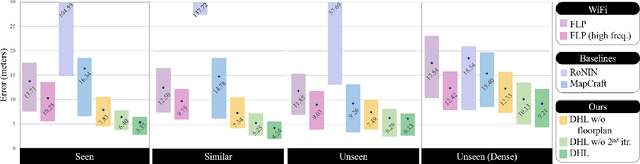
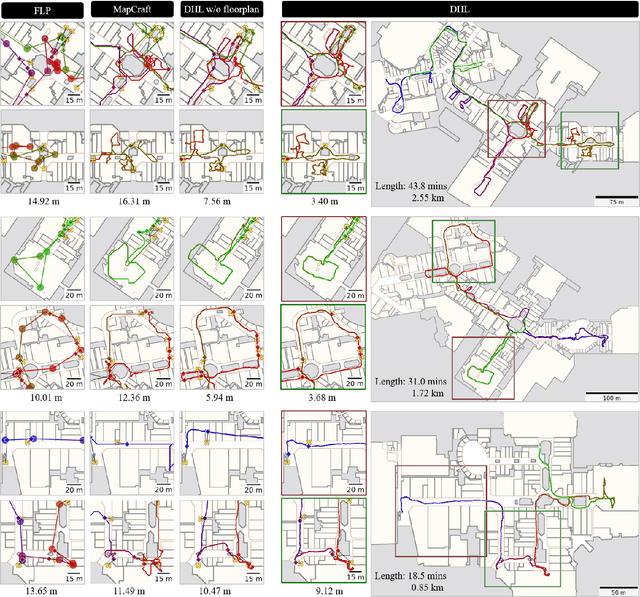
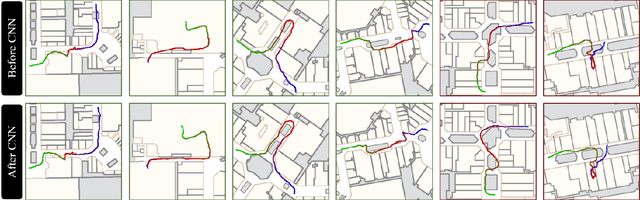
The paper proposes a multi-modal sensor fusion algorithm that fuses WiFi, IMU, and floorplan information to infer an accurate and dense location history in indoor environments. The algorithm uses 1) an inertial navigation algorithm to estimate a relative motion trajectory from IMU sensor data; 2) a WiFi-based localization API in industry to obtain positional constraints and geo-localize the trajectory; and 3) a convolutional neural network to refine the location history to be consistent with the floorplan. We have developed a data acquisition app to build a new dataset with WiFi, IMU, and floorplan data with ground-truth positions at 4 university buildings and 3 shopping malls. Our qualitative and quantitative evaluations demonstrate that the proposed system is able to produce twice as accurate and a few orders of magnitude denser location history than the current standard, while requiring minimal additional energy consumption. We will publicly share our code, data and models.
* To be published in ICRA 2021. Code and data: https://github.com/Sachini/Fusion-DHL
Graph-based non-linear least squares optimization for visual place recognition in changing environments
Dec 29, 2020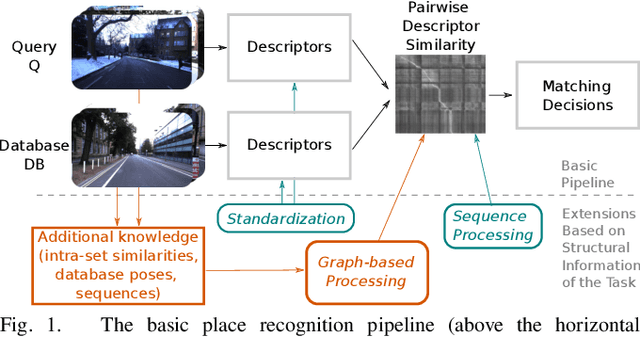
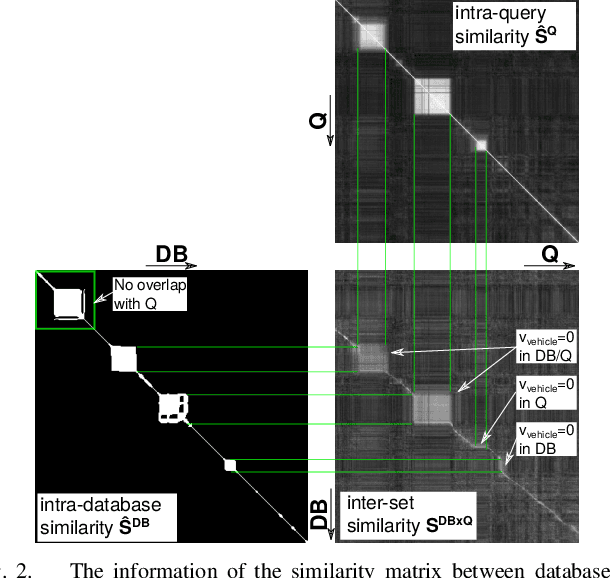
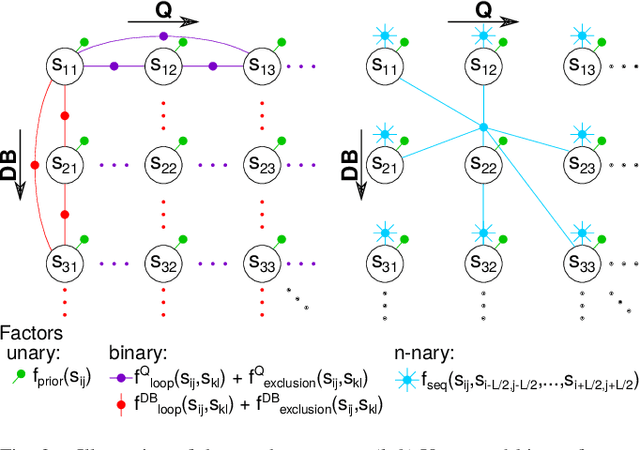
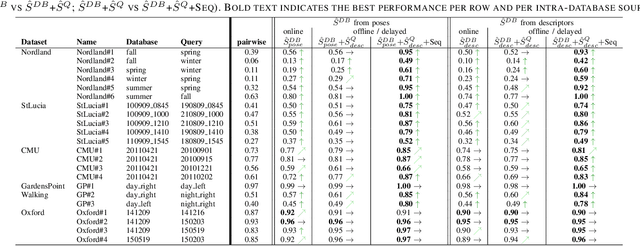
Visual place recognition is an important subproblem of mobile robot localization. Since it is a special case of image retrieval, the basic source of information is the pairwise similarity of image descriptors. However, the embedding of the image retrieval problem in this robotic task provides additional structure that can be exploited, e.g. spatio-temporal consistency. Several algorithms exist to exploit this structure, e.g., sequence processing approaches or descriptor standardization approaches for changing environments. In this paper, we propose a graph-based framework to systematically exploit different types of additional structure and information. The graphical model is used to formulate a non-linear least squares problem that can be optimized with standard tools. Beyond sequences and standardization, we propose the usage of intra-set similarities within the database and/or the query image set as additional source of information. If available, our approach also allows to seamlessly integrate additional knowledge about poses of database images. We evaluate the system on a variety of standard place recognition datasets and demonstrate performance improvements for a large number of different configurations including different sources of information, different types of constraints, and online or offline place recognition setups.
Learning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 16, 2021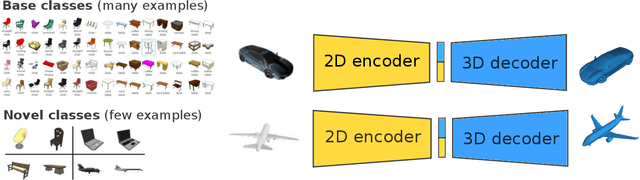
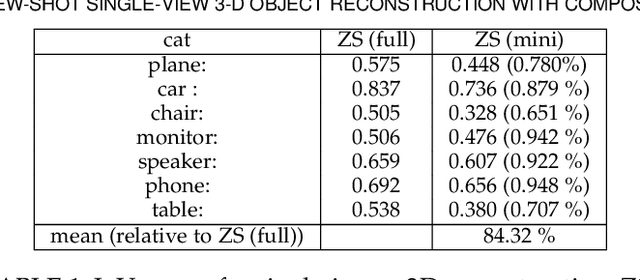
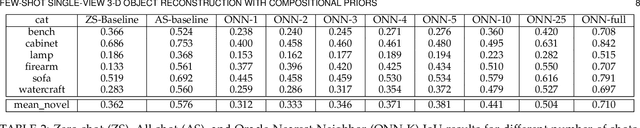
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.
Topology Distillation for Recommender System
Jun 16, 2021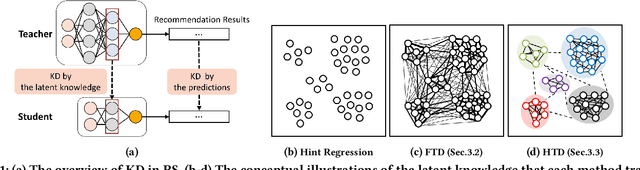
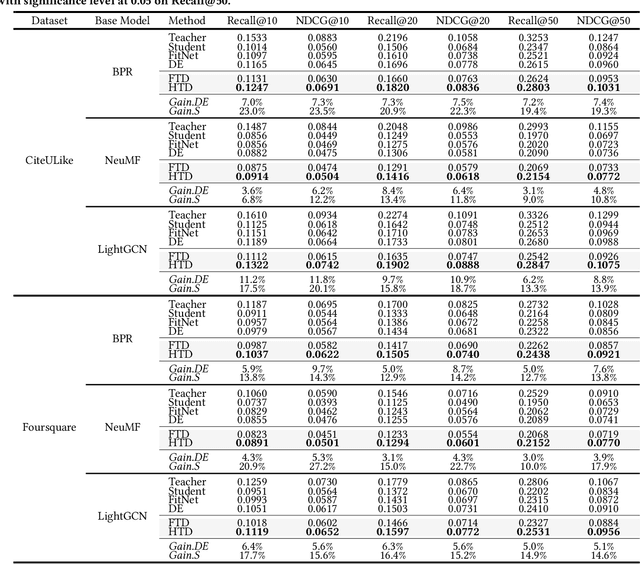
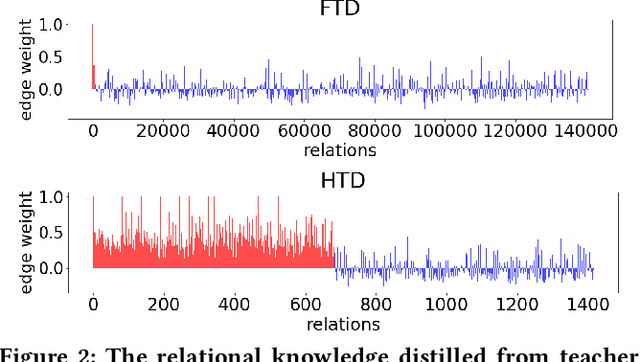
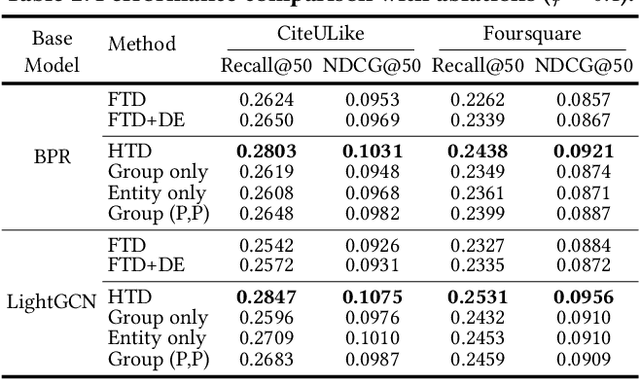
Recommender Systems (RS) have employed knowledge distillation which is a model compression technique training a compact student model with the knowledge transferred from a pre-trained large teacher model. Recent work has shown that transferring knowledge from the teacher's intermediate layer significantly improves the recommendation quality of the student. However, they transfer the knowledge of individual representation point-wise and thus have a limitation in that primary information of RS lies in the relations in the representation space. This paper proposes a new topology distillation approach that guides the student by transferring the topological structure built upon the relations in the teacher space. We first observe that simply making the student learn the whole topological structure is not always effective and even degrades the student's performance. We demonstrate that because the capacity of the student is highly limited compared to that of the teacher, learning the whole topological structure is daunting for the student. To address this issue, we propose a novel method named Hierarchical Topology Distillation (HTD) which distills the topology hierarchically to cope with the large capacity gap. Our extensive experiments on real-world datasets show that the proposed method significantly outperforms the state-of-the-art competitors. We also provide in-depth analyses to ascertain the benefit of distilling the topology for RS.