 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Study on the temporal pooling used in deep neural networks for speaker verification
May 10, 2021
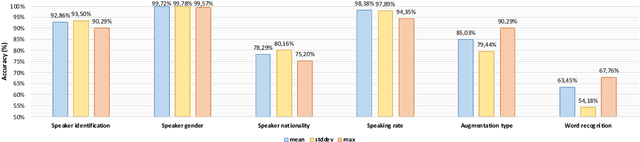
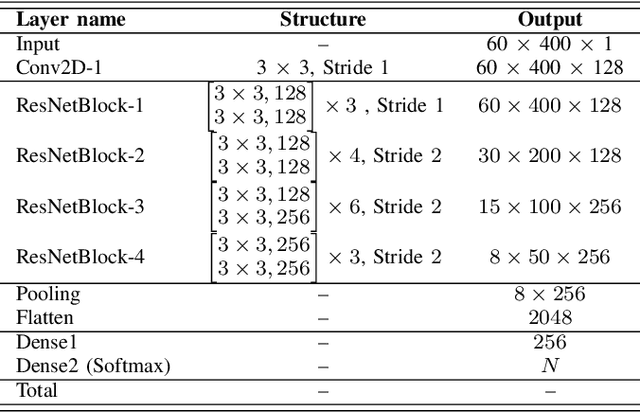
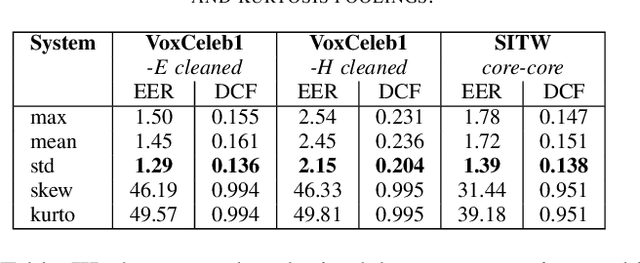
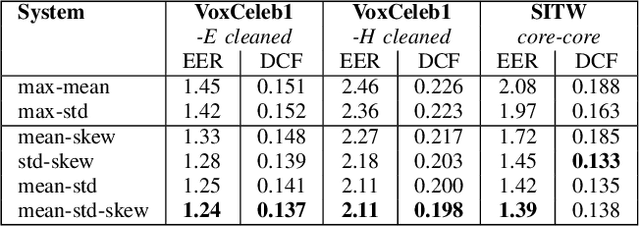
The x-vector architecture has recently achieved state-of-the-art results on the speaker verification task. This architecture incorporates a central layer, referred to as temporal pooling, which stacks statistical parameters of the acoustic frame distribution. This work proposes to highlight the significant effect of the temporal pooling content on the training dynamics and task performance. An evaluation with different pooling layers is conducted, that is, including different statistical measures of central tendency. Notably, 3rd and 4th moment-based statistics (skewness and kurtosis) are also tested to complete the usual mean and standard-deviation parameters. Our experiments show the influence of the pooling layer content in terms of speaker verification performance, but also for several classification tasks (speaker, channel or text related), and allow to better reveal the presence of external information to the speaker identity depending on the layer content.
Prescriptive Process Monitoring for Cost-Aware Cycle Time Reduction
May 15, 2021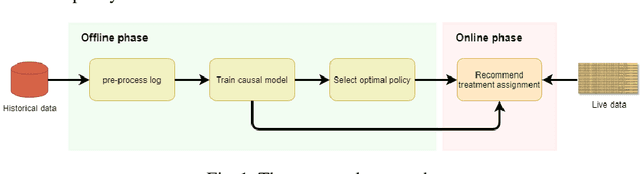


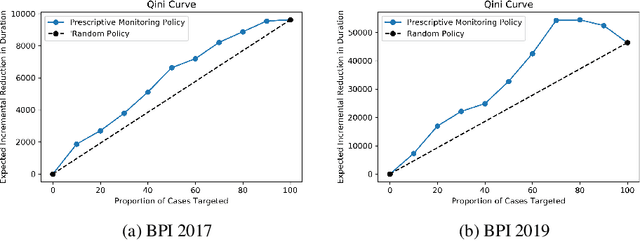
Reducing cycle time is a recurrent concern in the field of business process management. Depending on the process, various interventions may be triggered to reduce the cycle time of a case, for example, using a faster shipping service in an order-to-delivery process or giving a phone call to a customer to obtain missing information rather than waiting passively. Each of these interventions comes with a cost. This paper tackles the problem of determining if and when to trigger a time-reducing intervention in a way that maximizes the total net gain. The paper proposes a prescriptive process monitoring method that uses orthogonal random forest models to estimate the causal effect of triggering a time-reducing intervention for each ongoing case of a process. Based on this causal effect estimate, the method triggers interventions according to a user-defined policy. The method is evaluated on two real-life logs.
ASFM-Net: Asymmetrical Siamese Feature Matching Network for Point Completion
Apr 19, 2021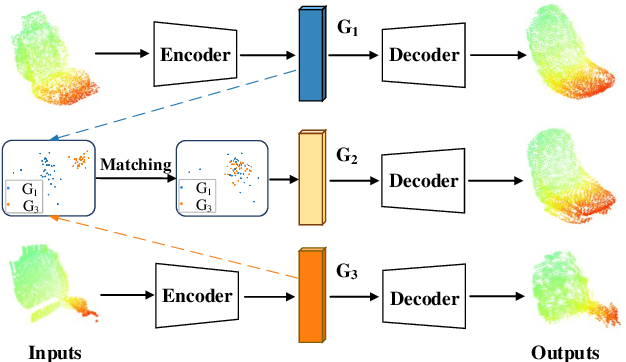

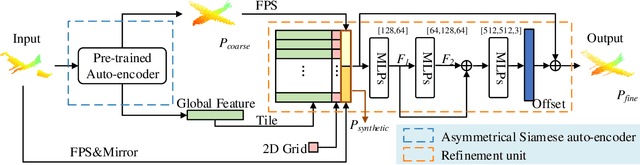
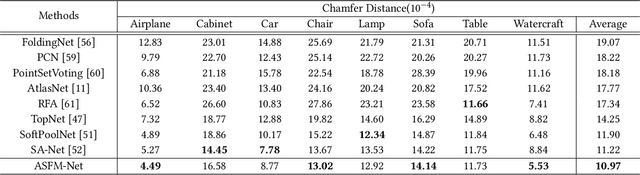
We tackle the problem of object completion from point clouds and propose a novel point cloud completion network using a feature matching strategy, termed as ASFM-Net. Specifically, the asymmetrical Siamese auto-encoder neural network is adopted to map the partial and complete input point cloud into a shared latent space, which can capture detailed shape prior. Then we design an iterative refinement unit to generate complete shapes with fine-grained details by integrating prior information. Experiments are conducted on the PCN dataset and the Completion3D benchmark, demonstrating the state-of-the-art performance of the proposed ASFM-Net. The codes and trained models will be open-sourced.
Automatic Cause Detection of Performance Problems in Web Applications
Mar 08, 2021
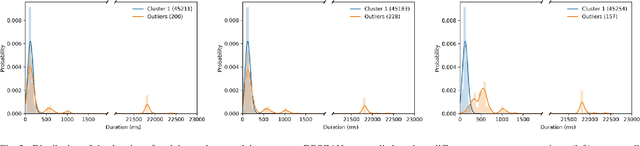
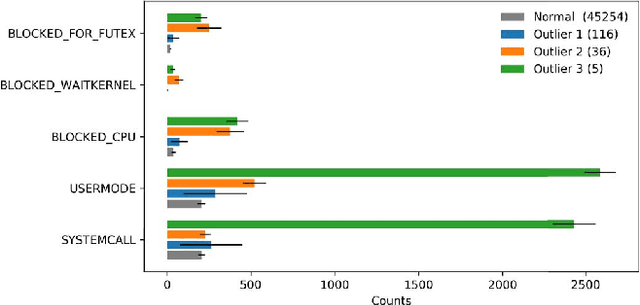
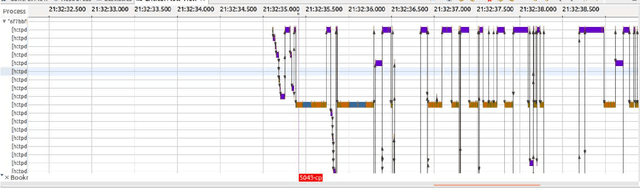
The execution of similar units can be compared by their internal behaviors to determine the causes of their potential performance issues. For instance, by examining the internal behaviors of different fast or slow web requests more closely and by clustering and comparing their internal executions, one can determine what causes some requests to run slowly or behave in unexpected ways. In this paper, we propose a method of extracting the internal behavior of web requests as well as introduce a pipeline that detects performance issues in web requests and provides insights into their root causes. First, low-level and fine-grained information regarding each request is gathered by tracing both the user space and the kernel space. Second, further information is extracted and fed into an outlier detector. Finally, these outliers are then clustered by their behavior, and each group is analyzed separately. Experiments revealed that this pipeline is indeed able to detect slow web requests and provide additional insights into their true root causes. Notably, we were able to identify a real PHP cache contention using the proposed approach.
* 8 pages, 7 figures, IEEE ISSREW 2019
A concise method for feature selection via normalized frequencies
Jun 10, 2021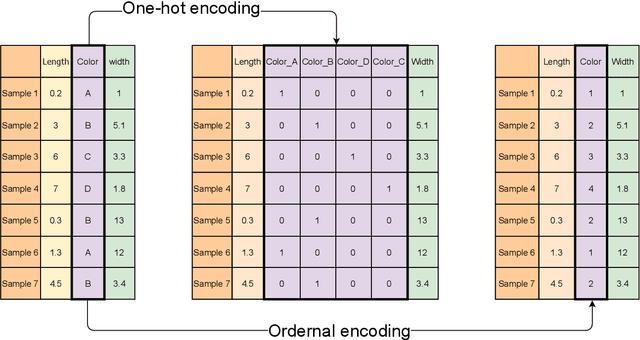

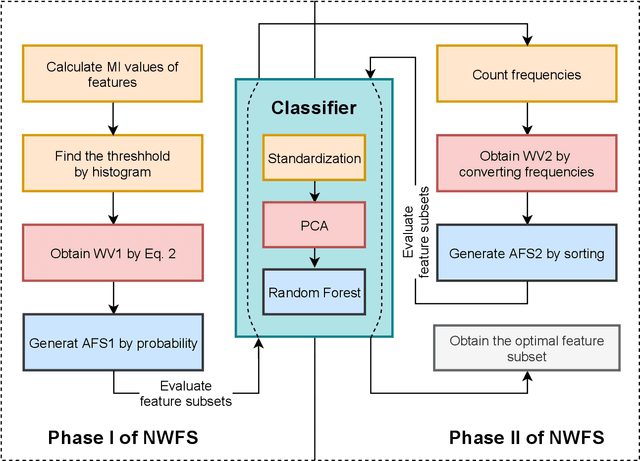

Feature selection is an important part of building a machine learning model. By eliminating redundant or misleading features from data, the machine learning model can achieve better performance while reducing the demand on com-puting resources. Metaheuristic algorithms are mostly used to implement feature selection such as swarm intelligence algorithms and evolutionary algorithms. However, they suffer from the disadvantage of relative complexity and slowness. In this paper, a concise method is proposed for universal feature selection. The proposed method uses a fusion of the filter method and the wrapper method, rather than a combination of them. In the method, one-hoting encoding is used to preprocess the dataset, and random forest is utilized as the classifier. The proposed method uses normalized frequencies to assign a value to each feature, which will be used to find the optimal feature subset. Furthermore, we propose a novel approach to exploit the outputs of mutual information, which allows for a better starting point for the experiments. Two real-world dataset in the field of intrusion detection were used to evaluate the proposed method. The evaluation results show that the proposed method outperformed several state-of-the-art related works in terms of accuracy, precision, recall, F-score and AUC.
Railroad is not a Train: Saliency as Pseudo-pixel Supervision for Weakly Supervised Semantic Segmentation
May 19, 2021
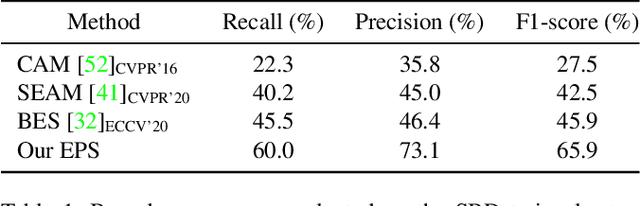
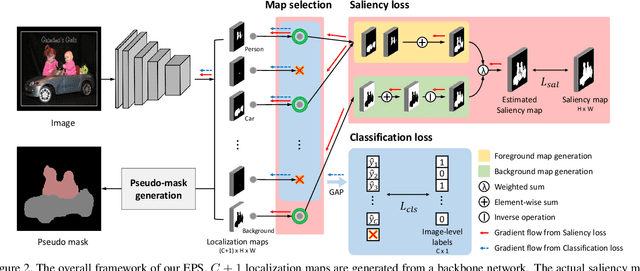
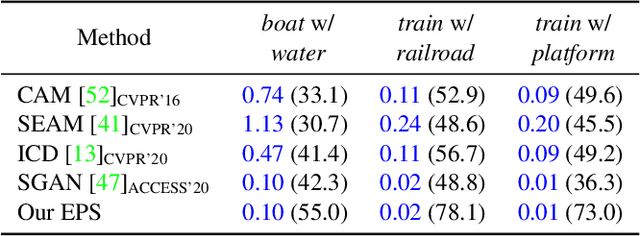
Existing studies in weakly-supervised semantic segmentation (WSSS) using image-level weak supervision have several limitations: sparse object coverage, inaccurate object boundaries, and co-occurring pixels from non-target objects. To overcome these challenges, we propose a novel framework, namely Explicit Pseudo-pixel Supervision (EPS), which learns from pixel-level feedback by combining two weak supervisions; the image-level label provides the object identity via the localization map and the saliency map from the off-the-shelf saliency detection model offers rich boundaries. We devise a joint training strategy to fully utilize the complementary relationship between both information. Our method can obtain accurate object boundaries and discard co-occurring pixels, thereby significantly improving the quality of pseudo-masks. Experimental results show that the proposed method remarkably outperforms existing methods by resolving key challenges of WSSS and achieves the new state-of-the-art performance on both PASCAL VOC 2012 and MS COCO 2014 datasets.
Embedded Deep Regularized Block HSIC Thermomics for Early Diagnosis of Breast Cancer
Jun 03, 2021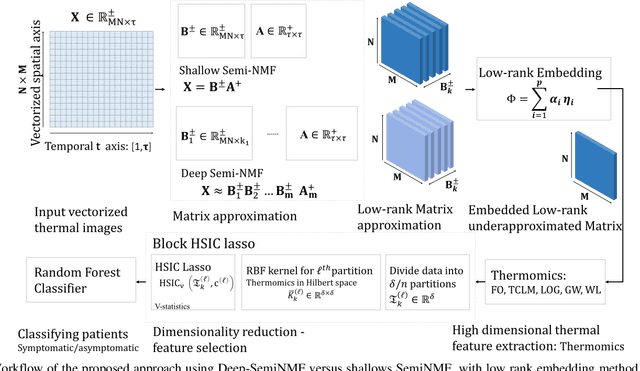


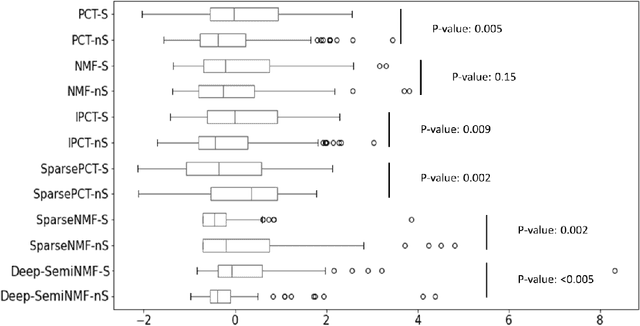
Thermography has been used extensively as a complementary diagnostic tool in breast cancer detection. Among thermographic methods matrix factorization (MF) techniques show an unequivocal capability to detect thermal patterns corresponding to vasodilation in cancer cases. One of the biggest challenges in such techniques is selecting the best representation of the thermal basis. In this study, an embedding method is proposed to address this problem and Deep-semi-nonnegative matrix factorization (Deep-SemiNMF) for thermography is introduced, then tested for 208 breast cancer screening cases. First, we apply Deep-SemiNMF to infrared images to extract low-rank thermal representations for each case. Then, we embed low-rank bases to obtain one basis for each patient. After that, we extract 300 thermal imaging features, called thermomics, to decode imaging information for the automatic diagnostic model. We reduced the dimensionality of thermomics by spanning them onto Hilbert space using RBF kernel and select the three most efficient features using the block Hilbert Schmidt Independence Criterion Lasso (block HSIC Lasso). The preserved thermal heterogeneity successfully classified asymptomatic versus symptomatic patients applying a random forest model (cross-validated accuracy of 71.36% (69.42%-73.3%)).
* Authors version. arXiv admin note: text overlap with arXiv:2010.06784
Enabling Full Mutualism for Symbiotic Radio with Massive Backscatter Devices
Jun 10, 2021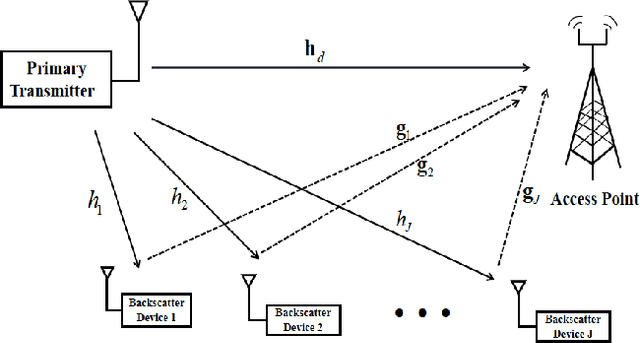
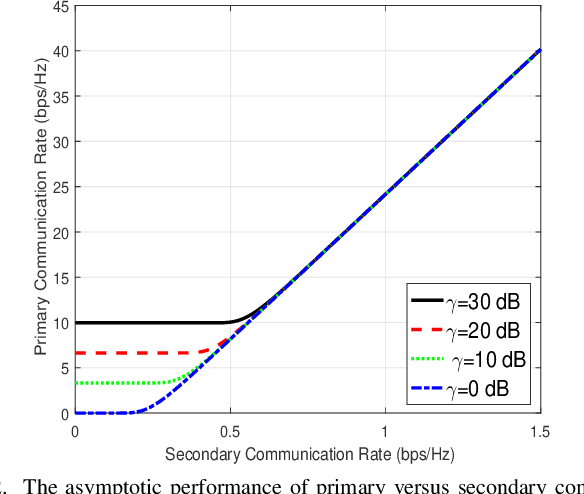
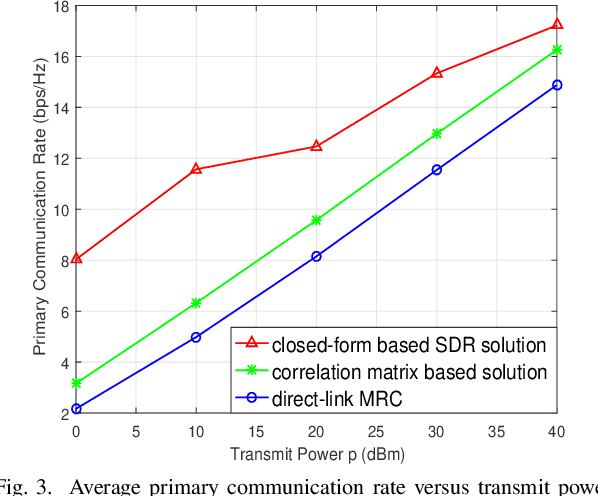
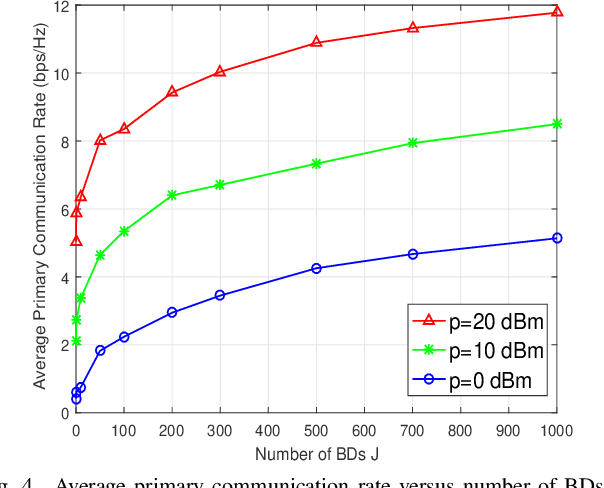
Symbiotic radio is a promising technology to achieve spectrum- and energy-efficient wireless communications, where the secondary backscatter device (BD) leverages not only the spectrum but also the power of the primary signals for its own information transmission. In return, the primary communication link can be enhanced by the additional multipaths created by the BD. This is known as the mutualism relationship of symbiotic radio. However, as the backscattering link is much weaker than the direct link due to double attenuations, the improvement of the primary link brought by one single BD is extremely limited. To address this issue and enable full mutualism of symbiotic radio, in this paper, we study symbiotic radio with massive number of BDs. For symbiotic radio multiple access channel (MAC) with successive interference cancellation (SIC), we first derive the achievable rate of both the primary and secondary communications, based on which a receive beamforming optimization problem is formulated and solved. Furthermore, considering the asymptotic regime of massive number of BDs, closed-form expressions are derived for the primary and the secondary communication rates, both of which are shown to be increasing functions of the number of BDs. This thus demonstrates that the mutualism relationship of symbiotic radio can be fully exploited with massive BD access.
Temporal-Spatial Feature Pyramid for Video Saliency Detection
May 10, 2021
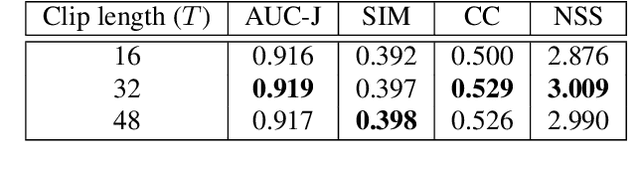
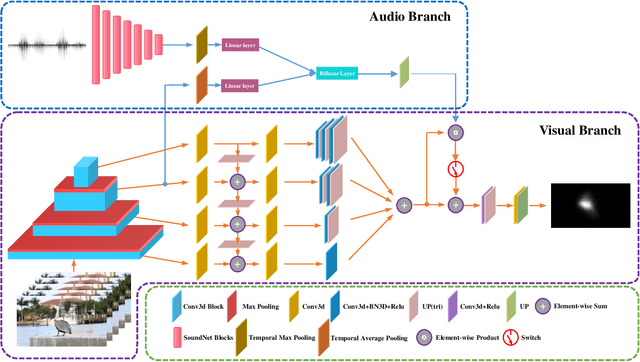
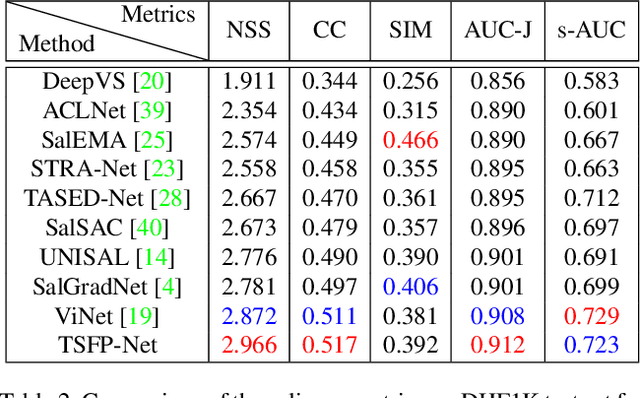
In this paper, we propose a 3D fully convolutional encoder-decoder architecture for video saliency detection, which combines scale, space and time information for video saliency modeling. The encoder extracts multi-scale temporal-spatial features from the input continuous video frames, and then constructs temporal-spatial feature pyramid through temporal-spatial convolution and top-down feature integration. The decoder performs hierarchical decoding of temporal-spatial features from different scales, and finally produces a saliency map from the integration of multiple video frames. Our model is simple yet effective, and can run in real time. We perform abundant experiments, and the results indicate that the well-designed structure can improve the precision of video saliency detection significantly. Experimental results on three purely visual video saliency benchmarks and six audio-video saliency benchmarks demonstrate that our method achieves state-of-theart performance.
Pragmatic Image Compression for Human-in-the-Loop Decision-Making
Jul 07, 2021

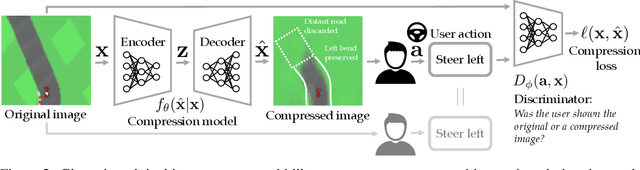
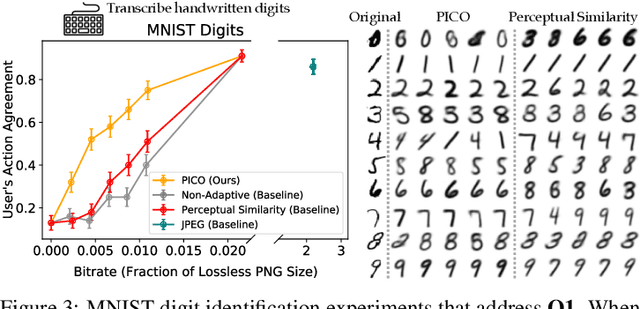
Standard lossy image compression algorithms aim to preserve an image's appearance, while minimizing the number of bits needed to transmit it. However, the amount of information actually needed by a user for downstream tasks -- e.g., deciding which product to click on in a shopping website -- is likely much lower. To achieve this lower bitrate, we would ideally only transmit the visual features that drive user behavior, while discarding details irrelevant to the user's decisions. We approach this problem by training a compression model through human-in-the-loop learning as the user performs tasks with the compressed images. The key insight is to train the model to produce a compressed image that induces the user to take the same action that they would have taken had they seen the original image. To approximate the loss function for this model, we train a discriminator that tries to distinguish whether a user's action was taken in response to the compressed image or the original. We evaluate our method through experiments with human participants on four tasks: reading handwritten digits, verifying photos of faces, browsing an online shopping catalogue, and playing a car racing video game. The results show that our method learns to match the user's actions with and without compression at lower bitrates than baseline methods, and adapts the compression model to the user's behavior: it preserves the digit number and randomizes handwriting style in the digit reading task, preserves hats and eyeglasses while randomizing faces in the photo verification task, preserves the perceived price of an item while randomizing its color and background in the online shopping task, and preserves upcoming bends in the road in the car racing game.