 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Possibilistic Fuzzy Local Information C-Means for Sonar Image Segmentation
Sep 28, 2017
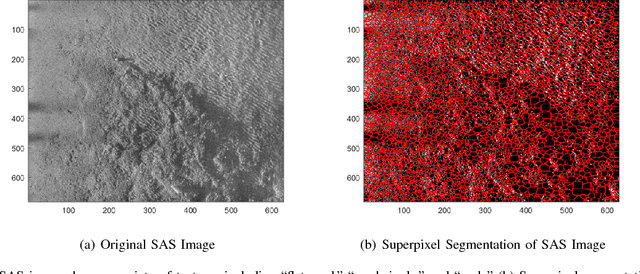

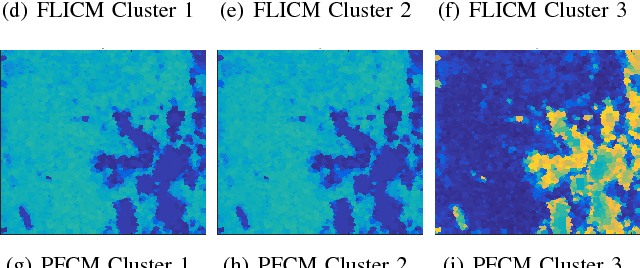

Side-look synthetic aperture sonar (SAS) can produce very high quality images of the sea-floor. When viewing this imagery, a human observer can often easily identify various sea-floor textures such as sand ripple, hard-packed sand, sea grass and rock. In this paper, we present the Possibilistic Fuzzy Local Information C-Means (PFLICM) approach to segment SAS imagery into sea-floor regions that exhibit these various natural textures. The proposed PFLICM method incorporates fuzzy and possibilistic clustering methods and leverages (local) spatial information to perform soft segmentation. Results are shown on several SAS scenes and compared to alternative segmentation approaches.
Unsupervised Anomaly Segmentation using Image-Semantic Cycle Translation
Mar 16, 2021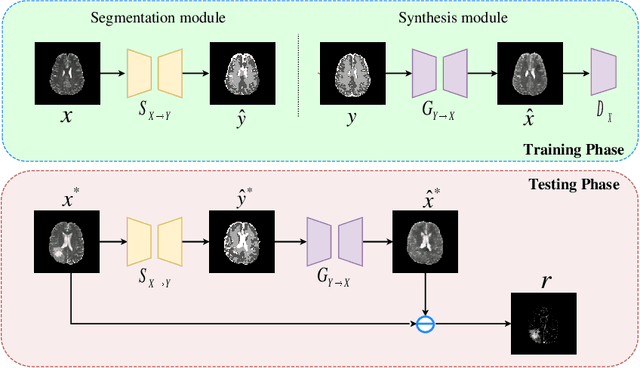

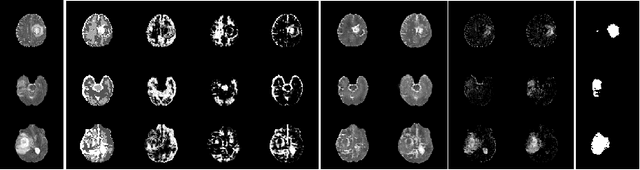
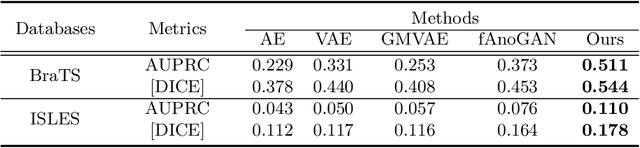
The goal of unsupervised anomaly segmentation (UAS) is to detect the pixel-level anomalies unseen during training. It is a promising field in the medical imaging community, e.g, we can use the model trained with only healthy data to segment the lesions of rare diseases. Existing methods are mainly based on Information Bottleneck, whose underlying principle is modeling the distribution of normal anatomy via learning to compress and recover the healthy data with a low-dimensional manifold, and then detecting lesions as the outlier from this learned distribution. However, this dimensionality reduction inevitably damages the localization information, which is especially essential for pixel-level anomaly detection. In this paper, to alleviate this issue, we introduce the semantic space of healthy anatomy in the process of modeling healthy-data distribution. More precisely, we view the couple of segmentation and synthesis as a special Autoencoder, and propose a novel cycle translation framework with a journey of 'image->semantic->image'. Experimental results on the BraTS and ISLES databases show that the proposed approach achieves significantly superior performance compared to several prior methods and segments the anomalies more accurately.
Gender Recognition in Informal and Formal Language Scenarios via Transfer Learning
Jun 23, 2021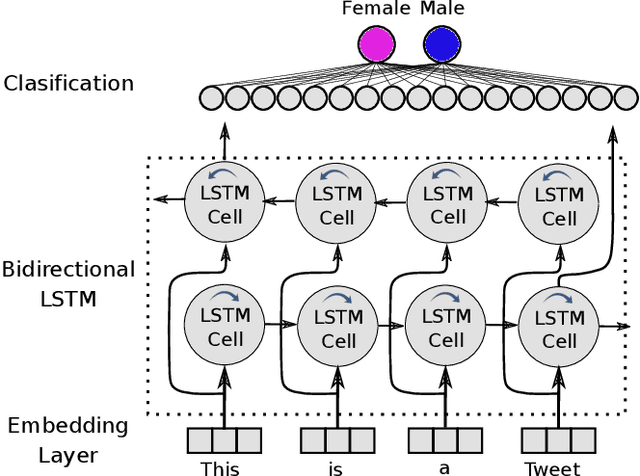
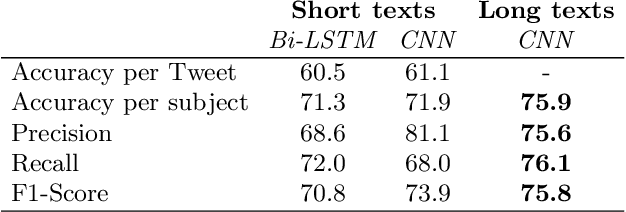
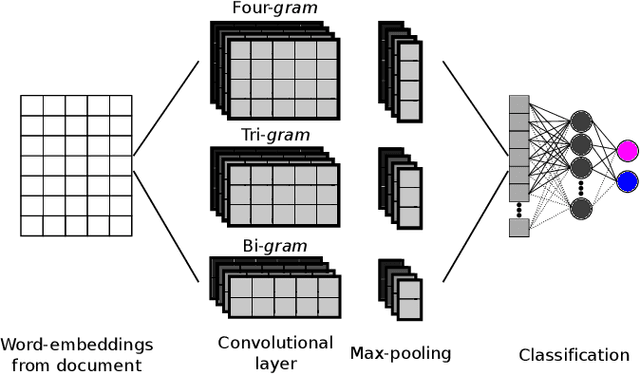
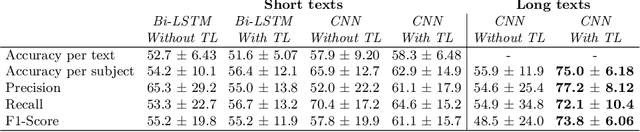
The interest in demographic information retrieval based on text data has increased in the research community because applications have shown success in different sectors such as security, marketing, heath-care, and others. Recognition and identification of demographic traits such as gender, age, location, or personality based on text data can help to improve different marketing strategies. For instance it makes it possible to segment and to personalize offers, thus products and services are exposed to the group of greatest interest. This type of technology has been discussed widely in documents from social media. However, the methods have been poorly studied in data with a more formal structure, where there is no access to emoticons, mentions, and other linguistic phenomena that are only present in social media. This paper proposes the use of recurrent and convolutional neural networks, and a transfer learning strategy for gender recognition in documents that are written in informal and formal languages. Models are tested in two different databases consisting of Tweets and call-center conversations. Accuracies of up to 75\% are achieved for both databases. The results also indicate that it is possible to transfer the knowledge from a system trained on a specific type of expressions or idioms such as those typically used in social media into a more formal type of text data, where the amount of data is more scarce and its structure is completely different.
CxGBERT: BERT meets Construction Grammar
Nov 09, 2020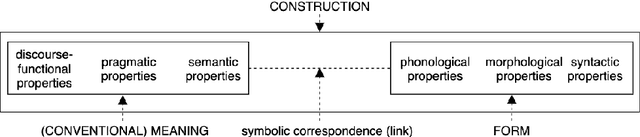
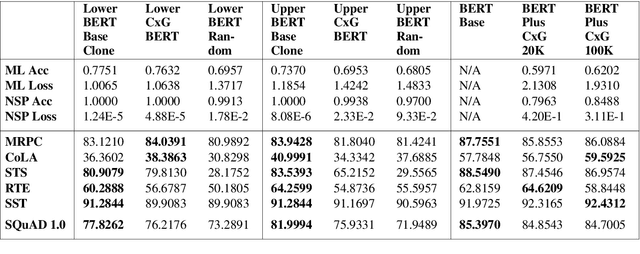
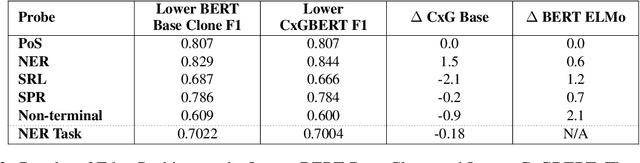
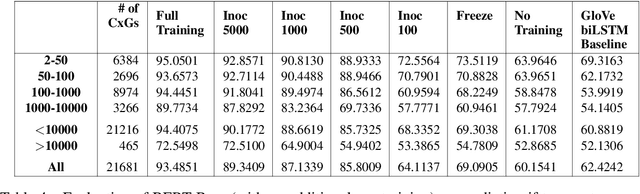
While lexico-semantic elements no doubt capture a large amount of linguistic information, it has been argued that they do not capture all information contained in text. This assumption is central to constructionist approaches to language which argue that language consists of constructions, learned pairings of a form and a function or meaning that are either frequent or have a meaning that cannot be predicted from its component parts. BERT's training objectives give it access to a tremendous amount of lexico-semantic information, and while BERTology has shown that BERT captures certain important linguistic dimensions, there have been no studies exploring the extent to which BERT might have access to constructional information. In this work we design several probes and conduct extensive experiments to answer this question. Our results allow us to conclude that BERT does indeed have access to a significant amount of information, much of which linguists typically call constructional information. The impact of this observation is potentially far-reaching as it provides insights into what deep learning methods learn from text, while also showing that information contained in constructions is redundantly encoded in lexico-semantics.
How to select and use tools? : Active Perception of Target Objects Using Multimodal Deep Learning
Jun 04, 2021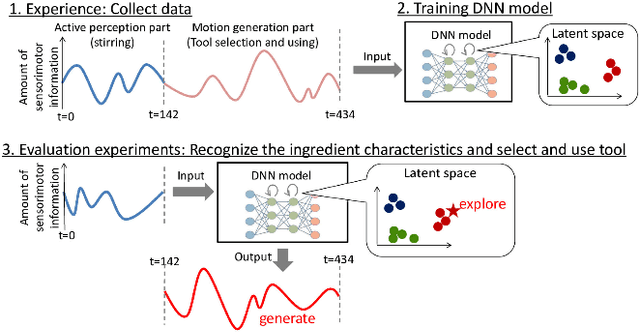
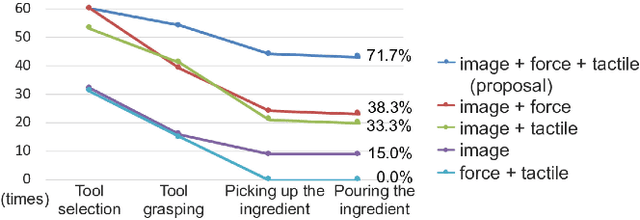
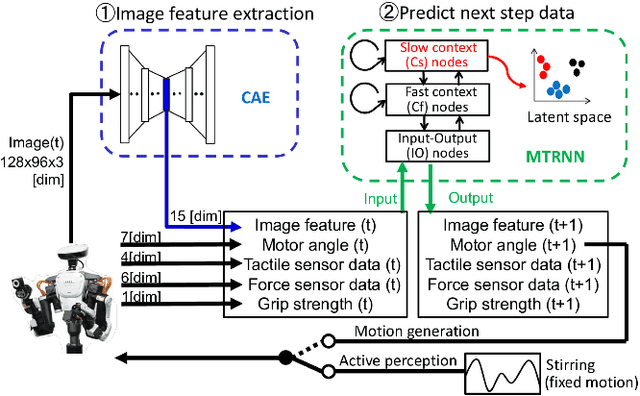

Selection of appropriate tools and use of them when performing daily tasks is a critical function for introducing robots for domestic applications. In previous studies, however, adaptability to target objects was limited, making it difficult to accordingly change tools and adjust actions. To manipulate various objects with tools, robots must both understand tool functions and recognize object characteristics to discern a tool-object-action relation. We focus on active perception using multimodal sensorimotor data while a robot interacts with objects, and allow the robot to recognize their extrinsic and intrinsic characteristics. We construct a deep neural networks (DNN) model that learns to recognize object characteristics, acquires tool-object-action relations, and generates motions for tool selection and handling. As an example tool-use situation, the robot performs an ingredients transfer task, using a turner or ladle to transfer an ingredient from a pot to a bowl. The results confirm that the robot recognizes object characteristics and servings even when the target ingredients are unknown. We also examine the contributions of images, force, and tactile data and show that learning a variety of multimodal information results in rich perception for tool use.
* Best Paper Award of Cognitive Robotics in ICRA2021 IEEE Robotics and Automation Letters 2021, Proceedings of the 2021 International Conference on Robotics and Automation (ICRA 2021), 2021
Spoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Jun 11, 2021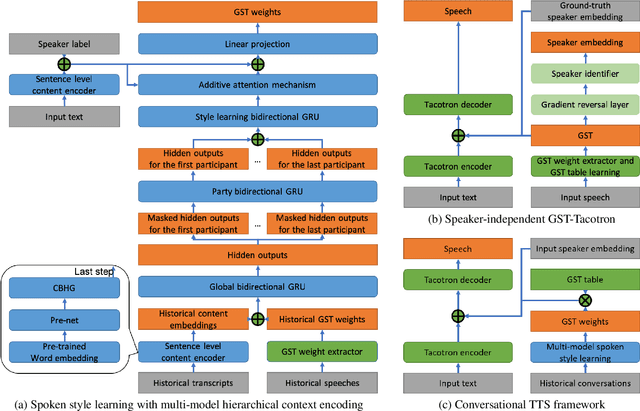

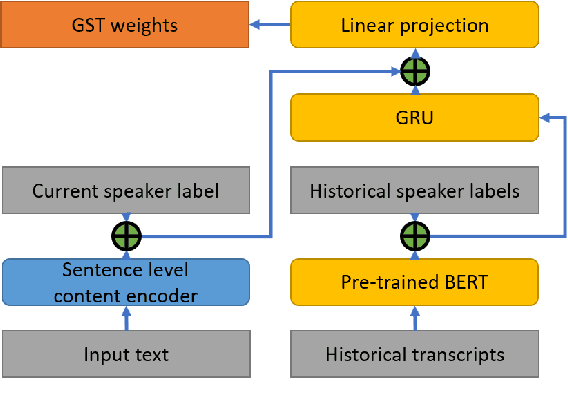

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.
DOCTOR: A Simple Method for Detecting Misclassification Errors
Jun 04, 2021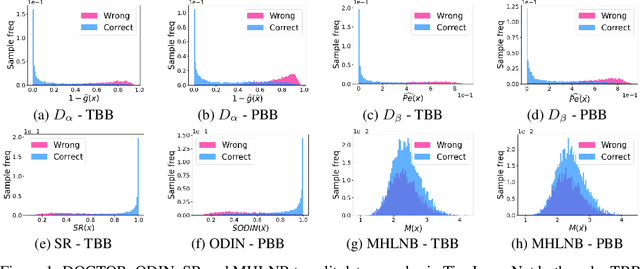
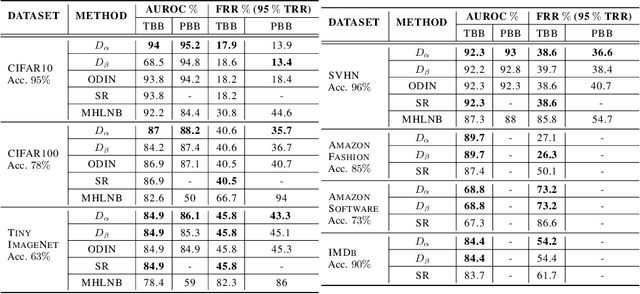
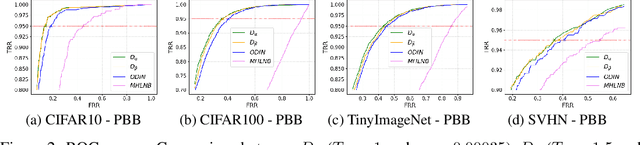
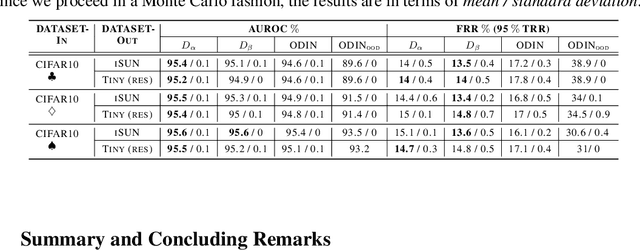
Deep neural networks (DNNs) have shown to perform very well on large scale object recognition problems and lead to widespread use for real-world applications, including situations where DNN are implemented as "black boxes". A promising approach to secure their use is to accept decisions that are likely to be correct while discarding the others. In this work, we propose DOCTOR, a simple method that aims to identify whether the prediction of a DNN classifier should (or should not) be trusted so that, consequently, it would be possible to accept it or to reject it. Two scenarios are investigated: Totally Black Box (TBB) where only the soft-predictions are available and Partially Black Box (PBB) where gradient-propagation to perform input pre-processing is allowed. Empirically, we show that DOCTOR outperforms all state-of-the-art methods on various well-known images and sentiment analysis datasets. In particular, we observe a reduction of up to $4\%$ of the false rejection rate (FRR) in the PBB scenario. DOCTOR can be applied to any pre-trained model, it does not require prior information about the underlying dataset and is as simple as the simplest available methods in the literature.
Vessel and Port Efficiency Metrics through Validated AIS data
Apr 30, 2021
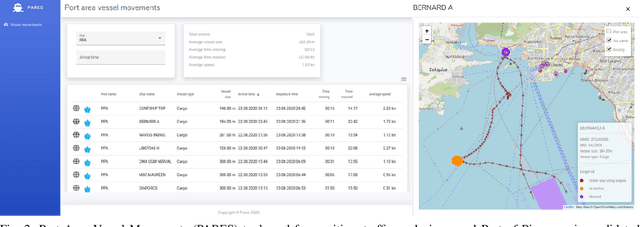
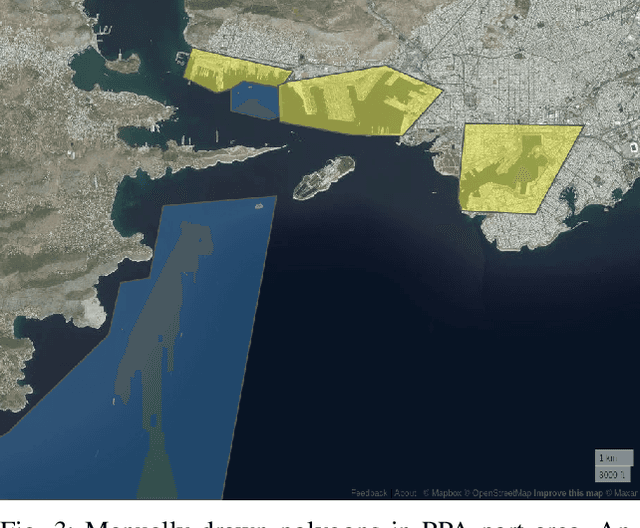
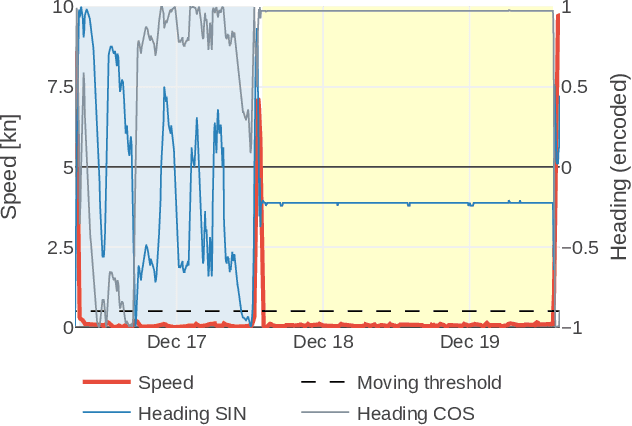
Automatic Identification System (AIS) data represents a rich source of information about maritime traffic and offers a great potential for data analytics and predictive modeling solutions, which can help optimizing logistic chains and to reduce environmental impacts. In this work, we address the main limitations of the validity of AIS navigational data fields, by proposing a machine learning-based data-driven methodology to detect and (to the possible extent) also correct erroneous data. Additionally, we propose a metric that can be used by vessel operators and ports to express numerically their business and environmental efficiency through time and spatial dimensions, enabled with the obtained validated AIS data. We also demonstrate Port Area Vessel Movements (PARES) tool, which demonstrates the proposed solutions.
ASFM-Net: Asymmetrical Siamese Feature Matching Network for Point Completion
Apr 19, 2021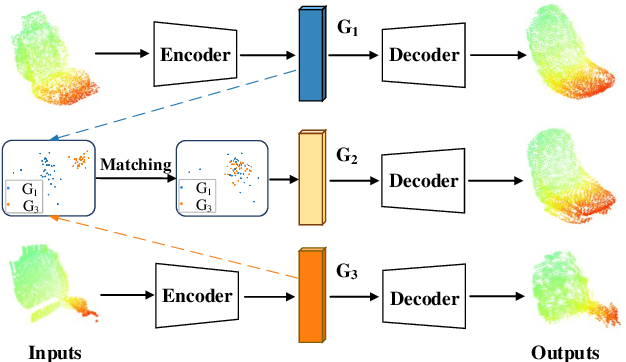

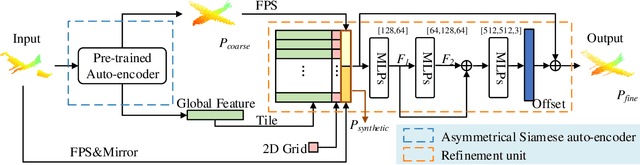
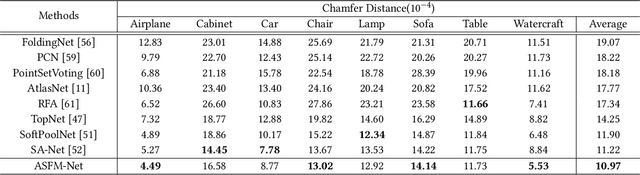
We tackle the problem of object completion from point clouds and propose a novel point cloud completion network using a feature matching strategy, termed as ASFM-Net. Specifically, the asymmetrical Siamese auto-encoder neural network is adopted to map the partial and complete input point cloud into a shared latent space, which can capture detailed shape prior. Then we design an iterative refinement unit to generate complete shapes with fine-grained details by integrating prior information. Experiments are conducted on the PCN dataset and the Completion3D benchmark, demonstrating the state-of-the-art performance of the proposed ASFM-Net. The codes and trained models will be open-sourced.
Diffusion Approximations for Thompson Sampling
May 19, 2021We study the behavior of Thompson sampling from the perspective of weak convergence. In the regime where the gaps between arm means scale as $1/\sqrt{n}$ with the time horizon $n$, we show that the dynamics of Thompson sampling evolve according to discrete versions of SDEs and random ODEs. As $n \to \infty$, we show that the dynamics converge weakly to solutions of the corresponding SDEs and random ODEs. (Recently, Wager and Xu (arXiv:2101.09855) independently proposed this regime and developed similar SDE and random ODE approximations.) Our weak convergence theory covers both the classical multi-armed and linear bandit settings, and can be used, for instance, to obtain insight about the characteristics of the regret distribution when there is information sharing among arms, as well as the effects of variance estimation, model mis-specification and batched updates in bandit learning. Our theory is developed from first-principles and can also be adapted to analyze other sampling-based bandit algorithms.