 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic annotation for computational pathology: Multidisciplinary experience and best practice recommendations
Jun 25, 2021
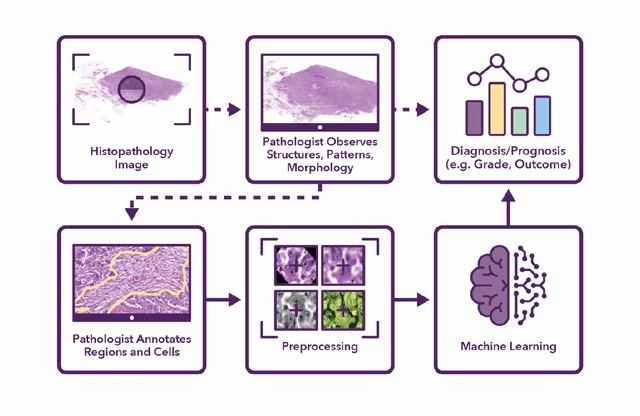

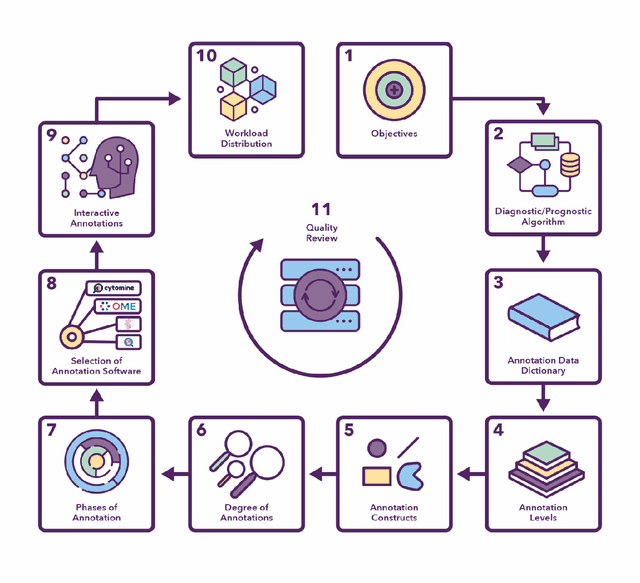
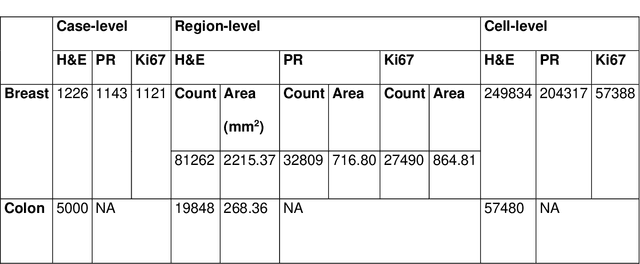
Recent advances in whole slide imaging (WSI) technology have led to the development of a myriad of computer vision and artificial intelligence (AI) based diagnostic, prognostic, and predictive algorithms. Computational Pathology (CPath) offers an integrated solution to utilize information embedded in pathology WSIs beyond what we obtain through visual assessment. For automated analysis of WSIs and validation of machine learning (ML) models, annotations at the slide, tissue and cellular levels are required. The annotation of important visual constructs in pathology images is an important component of CPath projects. Improper annotations can result in algorithms which are hard to interpret and can potentially produce inaccurate and inconsistent results. Despite the crucial role of annotations in CPath projects, there are no well-defined guidelines or best practices on how annotations should be carried out. In this paper, we address this shortcoming by presenting the experience and best practices acquired during the execution of a large-scale annotation exercise involving a multidisciplinary team of pathologists, ML experts and researchers as part of the Pathology image data Lake for Analytics, Knowledge and Education (PathLAKE) consortium. We present a real-world case study along with examples of different types of annotations, diagnostic algorithm, annotation data dictionary and annotation constructs. The analyses reported in this work highlight best practice recommendations that can be used as annotation guidelines over the lifecycle of a CPath project.
Conditional Coding for Flexible Learned Video Compression
Apr 16, 2021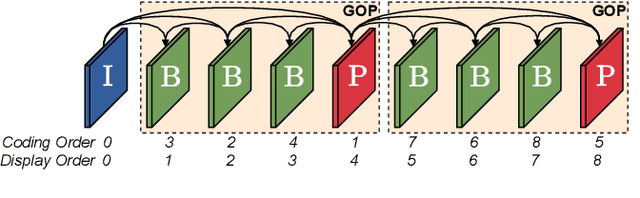

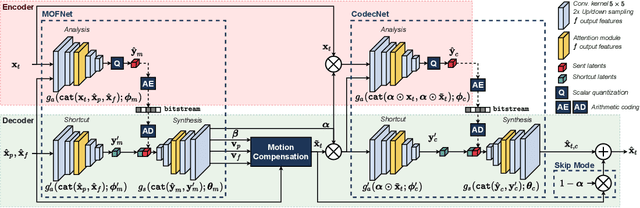
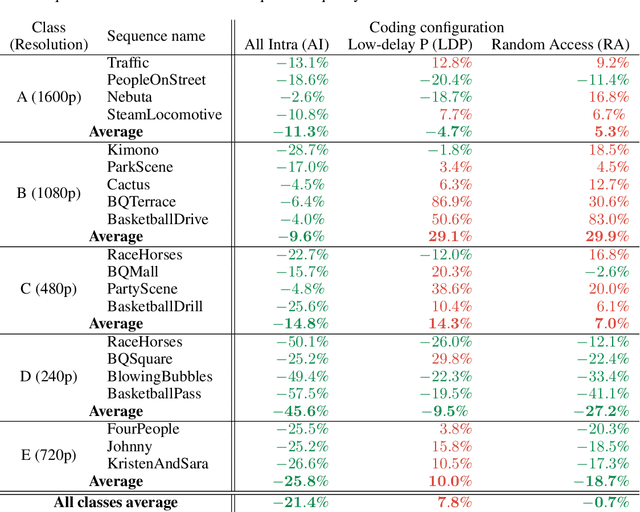
This paper introduces a novel framework for end-to-end learned video coding. Image compression is generalized through conditional coding to exploit information from reference frames, allowing to process intra and inter frames with the same coder. The system is trained through the minimization of a rate-distortion cost, with no pre-training or proxy loss. Its flexibility is assessed under three coding configurations (All Intra, Low-delay P and Random Access), where it is shown to achieve performance competitive with the state-of-the-art video codec HEVC.
Revisiting Locally Supervised Learning: an Alternative to End-to-end Training
Jan 26, 2021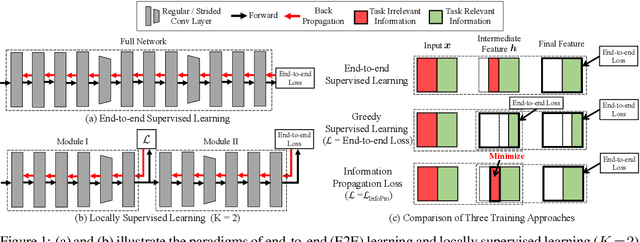
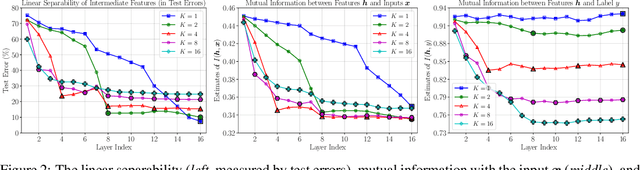
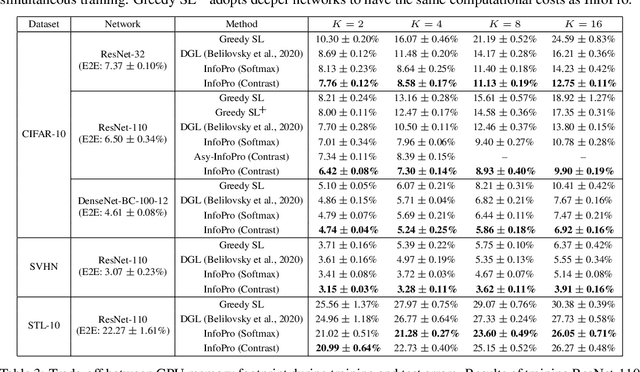
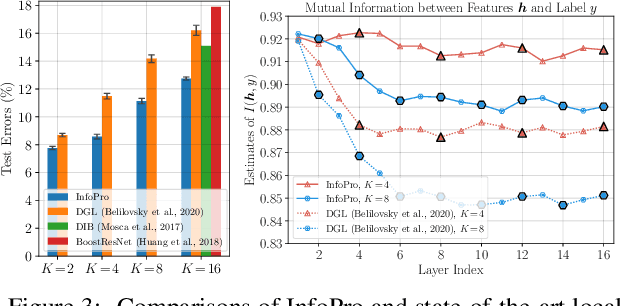
Due to the need to store the intermediate activations for back-propagation, end-to-end (E2E) training of deep networks usually suffers from high GPUs memory footprint. This paper aims to address this problem by revisiting the locally supervised learning, where a network is split into gradient-isolated modules and trained with local supervision. We experimentally show that simply training local modules with E2E loss tends to collapse task-relevant information at early layers, and hence hurts the performance of the full model. To avoid this issue, we propose an information propagation (InfoPro) loss, which encourages local modules to preserve as much useful information as possible, while progressively discard task-irrelevant information. As InfoPro loss is difficult to compute in its original form, we derive a feasible upper bound as a surrogate optimization objective, yielding a simple but effective algorithm. In fact, we show that the proposed method boils down to minimizing the combination of a reconstruction loss and a normal cross-entropy/contrastive term. Extensive empirical results on five datasets (i.e., CIFAR, SVHN, STL-10, ImageNet and Cityscapes) validate that InfoPro is capable of achieving competitive performance with less than 40% memory footprint compared to E2E training, while allowing using training data with higher-resolution or larger batch sizes under the same GPU memory constraint. Our method also enables training local modules asynchronously for potential training acceleration. Code is available at: https://github.com/blackfeather-wang/InfoPro-Pytorch.
Learning to Stylize Novel Views
May 27, 2021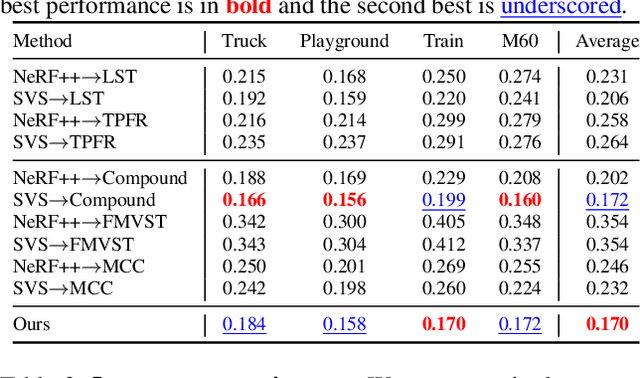

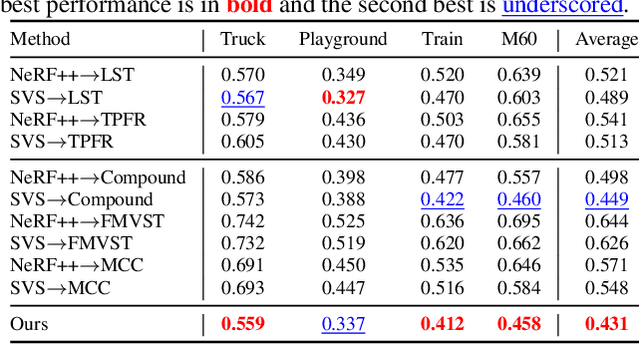
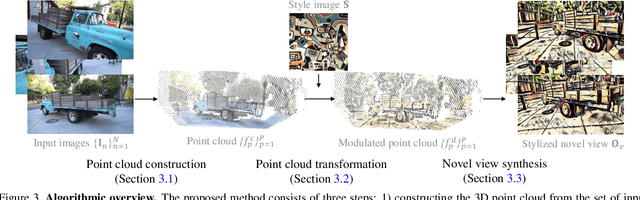
We tackle a 3D scene stylization problem - generating stylized images of a scene from arbitrary novel views given a set of images of the same scene and a reference image of the desired style as inputs. Direct solution of combining novel view synthesis and stylization approaches lead to results that are blurry or not consistent across different views. We propose a point cloud-based method for consistent 3D scene stylization. First, we construct the point cloud by back-projecting the image features to the 3D space. Second, we develop point cloud aggregation modules to gather the style information of the 3D scene, and then modulate the features in the point cloud with a linear transformation matrix. Finally, we project the transformed features to 2D space to obtain the novel views. Experimental results on two diverse datasets of real-world scenes validate that our method generates consistent stylized novel view synthesis results against other alternative approaches.
Airflow-Inertial Odometry for Resilient State Estimation on Multirotors
May 27, 2021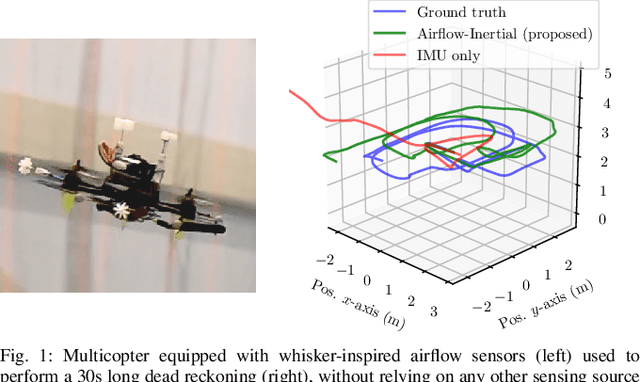
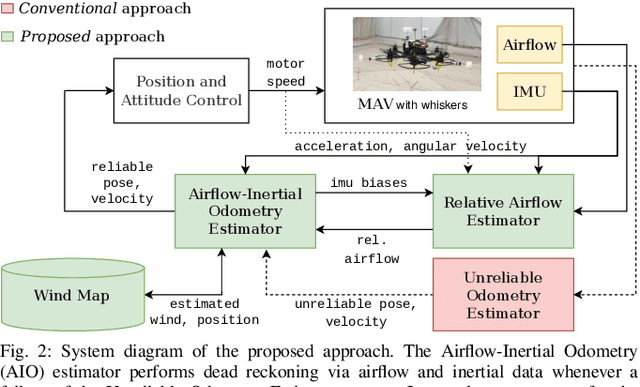
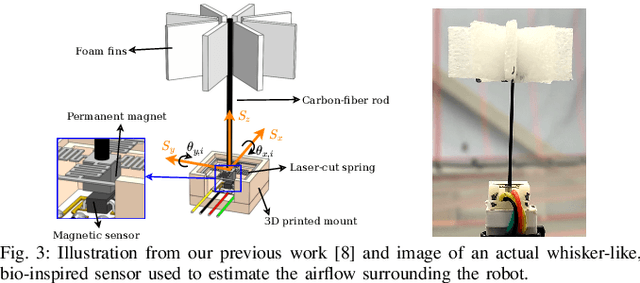
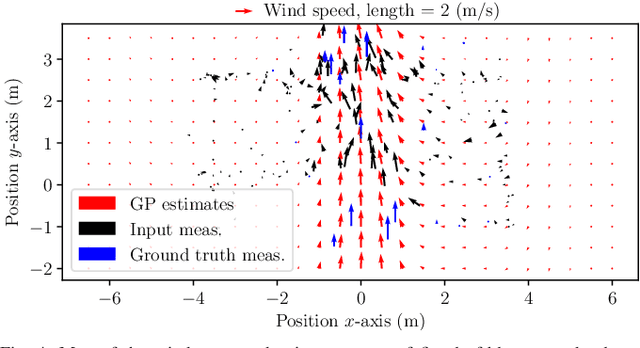
We present a dead reckoning strategy for increased resilience to position estimation failures on multirotors, using only data from a low-cost IMU and novel, bio-inspired airflow sensors. The goal is challenging, since low-cost IMUs are subject to large noise and drift, while 3D airflow sensing is made difficult by the interference caused by the propellers and by the wind. Our approach relies on a deep-learning strategy to interpret the measurements of the bio-inspired sensors, a map of the wind speed to compensate for position-dependent wind, and a filter to fuse the information and generate a pose and velocity estimate. Our results show that the approach reduces the drift with respect to IMU-only dead reckoning by up to an order of magnitude over 30 seconds after a position sensor failure in non-windy environments, and it can compensate for the challenging effects of turbulent, and spatially varying wind.
Move Beyond Trajectories: Distribution Space Coupling for Crowd Navigation
Jun 25, 2021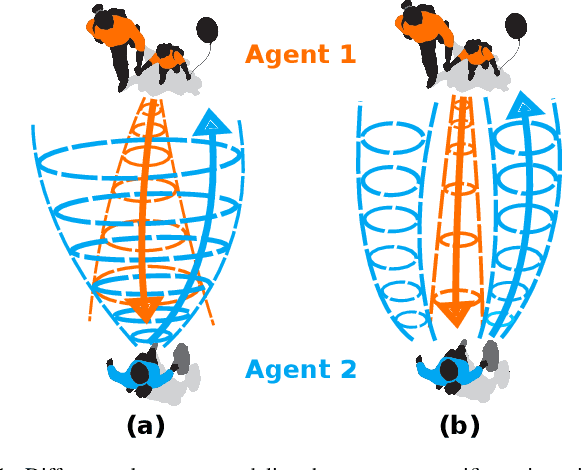
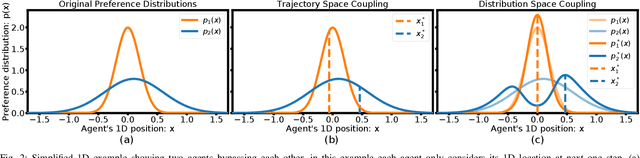
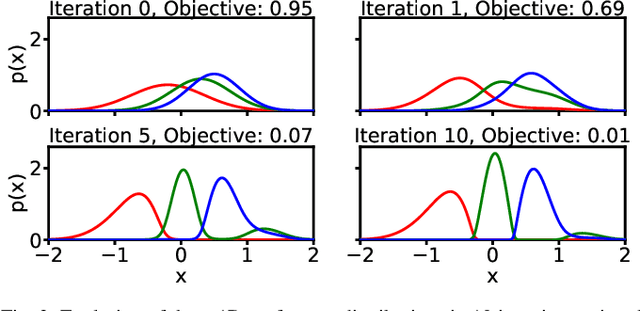
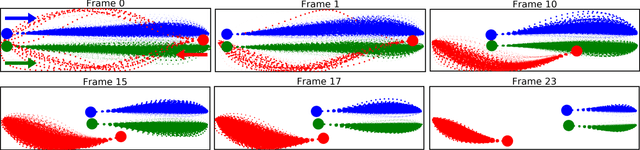
Cooperatively avoiding collision is a critical functionality for robots navigating in dense human crowds, failure of which could lead to either overaggressive or overcautious behavior. A necessary condition for cooperative collision avoidance is to couple the prediction of the agents' trajectories with the planning of the robot's trajectory. However, it is unclear that trajectory based cooperative collision avoidance captures the correct agent attributes. In this work we migrate from trajectory based coupling to a formalism that couples agent preference distributions. In particular, we show that preference distributions (probability density functions representing agents' intentions) can capture higher order statistics of agent behaviors, such as willingness to cooperate. Thus, coupling in distribution space exploits more information about inter-agent cooperation than coupling in trajectory space. We thus introduce a general objective for coupled prediction and planning in distribution space, and propose an iterative best response optimization method based on variational analysis with guaranteed sufficient decrease. Based on this analysis, we develop a sampling-based motion planning framework called DistNav that runs in real time on a laptop CPU. We evaluate our approach on challenging scenarios from both real world datasets and simulation environments, and benchmark against a wide variety of model based and machine learning based approaches. The safety and efficiency statistics of our approach outperform all other models. Finally, we find that DistNav is competitive with human safety and efficiency performance.
* 12 pages
Verb Sense Clustering using Contextualized Word Representations for Semantic Frame Induction
May 27, 2021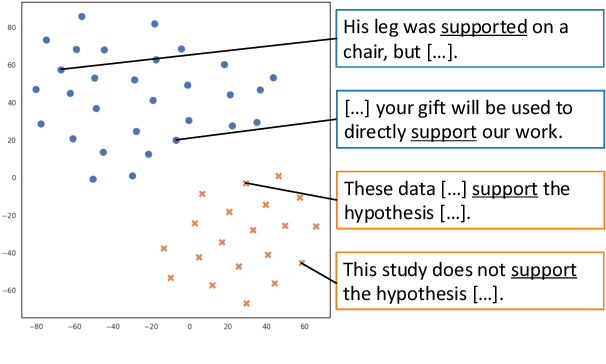
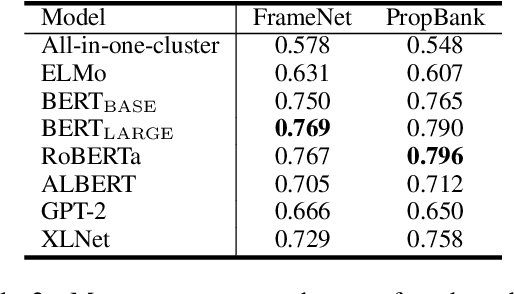
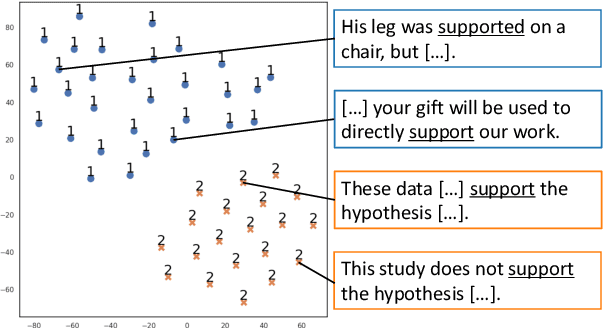
Contextualized word representations have proven useful for various natural language processing tasks. However, it remains unclear to what extent these representations can cover hand-coded semantic information such as semantic frames, which specify the semantic role of the arguments associated with a predicate. In this paper, we focus on verbs that evoke different frames depending on the context, and we investigate how well contextualized word representations can recognize the difference of frames that the same verb evokes. We also explore which types of representation are suitable for semantic frame induction. In our experiments, we compare seven different contextualized word representations for two English frame-semantic resources, FrameNet and PropBank. We demonstrate that several contextualized word representations, especially BERT and its variants, are considerably informative for semantic frame induction. Furthermore, we examine the extent to which the contextualized representation of a verb can estimate the number of frames that the verb can evoke.
A data-based comparative review and AI-driven symbolic model for longitudinal dispersion coefficient in natural streams
Jul 16, 2021
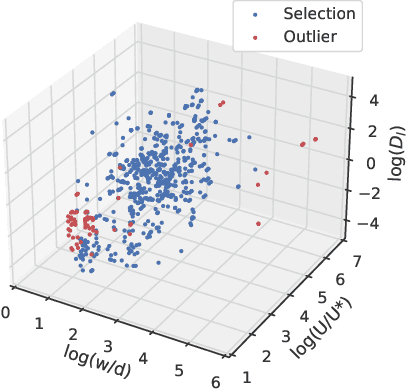

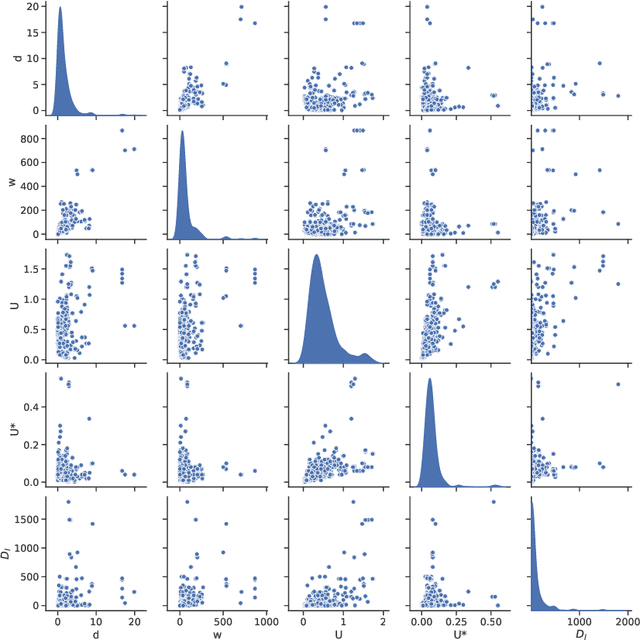
A better understanding of dispersion in natural streams requires knowledge of longitudinal dispersion coefficient(LDC). Various methods have been proposed for predictions of LDC. Those studies can be grouped into three types: analytical, statistical and ML-driven researches(Implicit and explicit). However, a comprehensive evaluation of them is still lacking. In this paper, we first present an in-depth analysis of those methods and find out their defects. This is carried out on an extensive database composed of 660 samples of hydraulic and channel properties worldwide. The reliability and representativeness of utilized data are enhanced through the deployment of the Subset Selection of Maximum Dissimilarity(SSMD) for testing set selection and the Inter Quartile Range(IQR) for removal of the outlier. The evaluation reveals the rank of those methods as: ML-driven method > the statistical method > the analytical method. Whereas implicit ML-driven methods are black-boxes in nature, explicit ML-driven methods have more potential in prediction of LDC. Besides, overfitting is a universal problem in existing models. Those models also suffer from a fixed parameter combination. To establish an interpretable model for LDC prediction with higher performance, we then design a novel symbolic regression method called evolutionary symbolic regression network(ESRN). It is a combination of genetic algorithms and neural networks. Strategies are introduced to avoid overfitting and explore more parameter combinations. Results show that the ESRN model has superiorities over other existing symbolic models in performance. The proposed model is suitable for practical engineering problems due to its advantage in low requirement of parameters (only w and U* are required). It can provide convincing solutions for situations where the field test cannot be carried out or limited field information can be obtained.
A Generalized Vector Space Model for Ontology-Based Information Retrieval
Jul 20, 2018Named entities (NE) are objects that are referred to by names such as people, organizations and locations. Named entities and keywords are important to the meaning of a document. We propose a generalized vector space model that combines named entities and keywords. In the model, we take into account different ontological features of named entities, namely, aliases, classes and identifiers. Moreover, we use entity classes to represent the latent information of interrogative words in Wh-queries, which are ignored in traditional keyword-based searching. We have implemented and tested the proposed model on a TREC dataset, as presented and discussed in the paper.
Fairness in Supervised Learning: An Information Theoretic Approach
Jul 29, 2018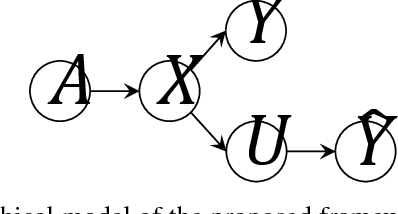
Automated decision making systems are increasingly being used in real-world applications. In these systems for the most part, the decision rules are derived by minimizing the training error on the available historical data. Therefore, if there is a bias related to a sensitive attribute such as gender, race, religion, etc. in the data, say, due to cultural/historical discriminatory practices against a certain demographic, the system could continue discrimination in decisions by including the said bias in its decision rule. We present an information theoretic framework for designing fair predictors from data, which aim to prevent discrimination against a specified sensitive attribute in a supervised learning setting. We use equalized odds as the criterion for discrimination, which demands that the prediction should be independent of the protected attribute conditioned on the actual label. To ensure fairness and generalization simultaneously, we compress the data to an auxiliary variable, which is used for the prediction task. This auxiliary variable is chosen such that it is decontaminated from the discriminatory attribute in the sense of equalized odds. The final predictor is obtained by applying a Bayesian decision rule to the auxiliary variable.