 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Single Underwater Image Restoration by Contrastive Learning
Apr 15, 2021
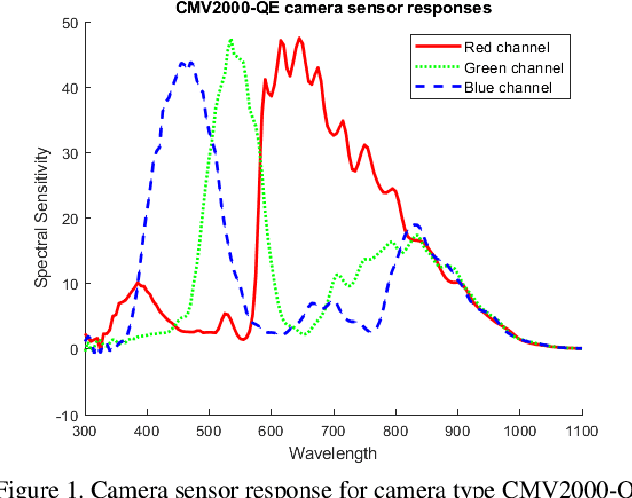
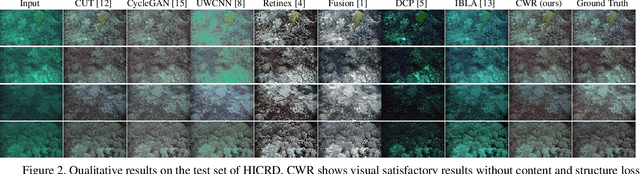
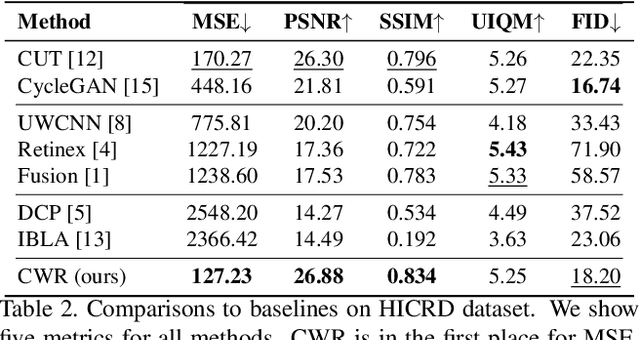
Underwater image restoration attracts significant attention due to its importance in unveiling the underwater world. This paper elaborates on a novel method that achieves state-of-the-art results for underwater image restoration based on the unsupervised image-to-image translation framework. We design our method by leveraging from contrastive learning and generative adversarial networks to maximize mutual information between raw and restored images. Additionally, we release a large-scale real underwater image dataset to support both paired and unpaired training modules. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method.
Restore from Restored: Single-image Inpainting
Feb 16, 2021
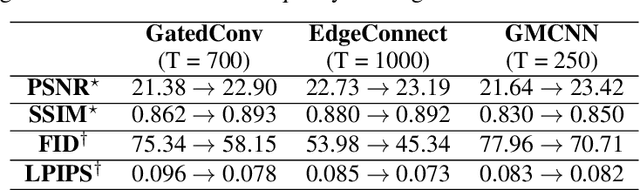
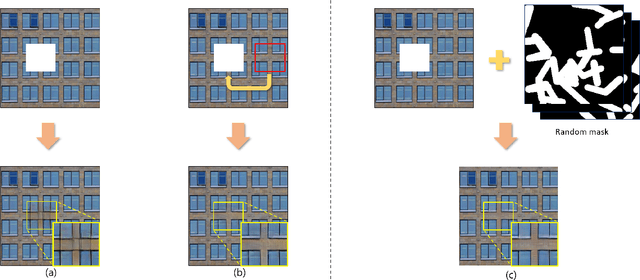
Recent image inpainting methods show promising results due to the power of deep learning, which can explore external information available from a large training dataset. However, many state-of-the-art inpainting networks are still limited in exploiting internal information available in the given input image at test time. To mitigate this problem, we present a novel and efficient self-supervised fine-tuning algorithm that can adapt the parameters of fully pretrained inpainting networks without using ground-truth clean image in this work. We upgrade the parameters of the pretrained networks by utilizing existing self-similar patches within the given input image without changing network architectures. Qualitative and quantitative experimental results demonstrate the superiority of the proposed algorithm and we achieve state-of-the-art inpainting results on publicly available numerous benchmark datasets.
Navigating to the Best Policy in Markov Decision Processes
Jun 05, 2021

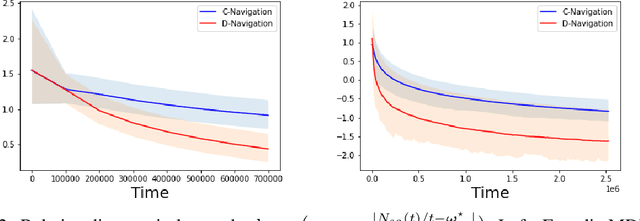
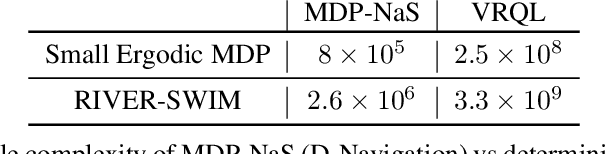
We investigate the classical active pure exploration problem in Markov Decision Processes, where the agent sequentially selects actions and, from the resulting system trajectory, aims at identifying the best policy as fast as possible. We propose an information-theoretic lower bound on the average number of steps required before a correct answer can be given with probability at least $1-\delta$. This lower bound involves a non-convex optimization problem, for which we propose a convex relaxation. We further provide an algorithm whose sample complexity matches the relaxed lower bound up to a factor $2$. This algorithm addresses general communicating MDPs; we propose a variant with reduced exploration rate (and hence faster convergence) under an additional ergodicity assumption. This work extends previous results relative to the \emph{generative setting}~\cite{marjani2020adaptive}, where the agent could at each step observe the random outcome of any (state, action) pair. In contrast, we show here how to deal with the \emph{navigation constraints}. Our analysis relies on an ergodic theorem for non-homogeneous Markov chains which we consider of wide interest in the analysis of Markov Decision Processes.
Deep Fair Discriminative Clustering
May 28, 2021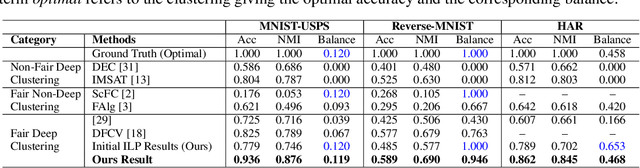

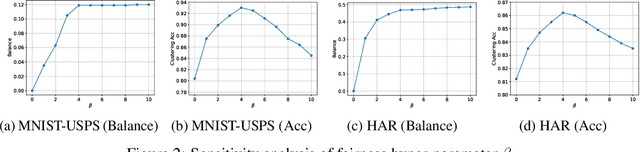
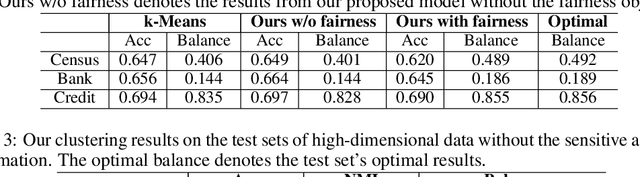
Deep clustering has the potential to learn a strong representation and hence better clustering performance compared to traditional clustering methods such as $k$-means and spectral clustering. However, this strong representation learning ability may make the clustering unfair by discovering surrogates for protected information which we empirically show in our experiments. In this work, we study a general notion of group-level fairness for both binary and multi-state protected status variables (PSVs). We begin by formulating the group-level fairness problem as an integer linear programming formulation whose totally unimodular constraint matrix means it can be efficiently solved via linear programming. We then show how to inject this solver into a discriminative deep clustering backbone and hence propose a refinement learning algorithm to combine the clustering goal with the fairness objective to learn fair clusters adaptively. Experimental results on real-world datasets demonstrate that our model consistently outperforms state-of-the-art fair clustering algorithms. Our framework shows promising results for novel clustering tasks including flexible fairness constraints, multi-state PSVs and predictive clustering.
Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS
Jun 18, 2021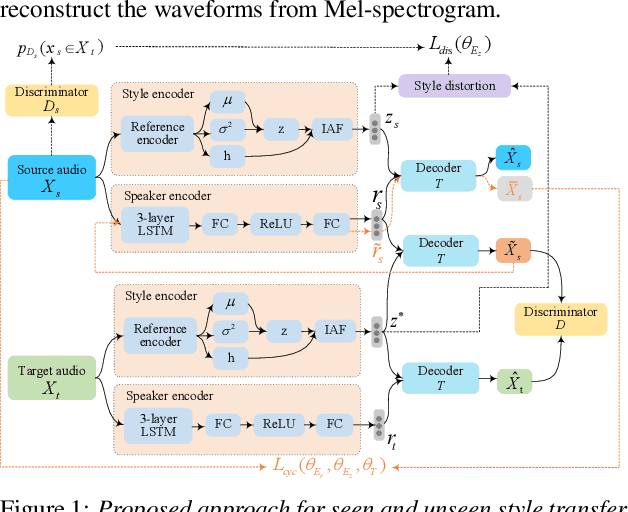
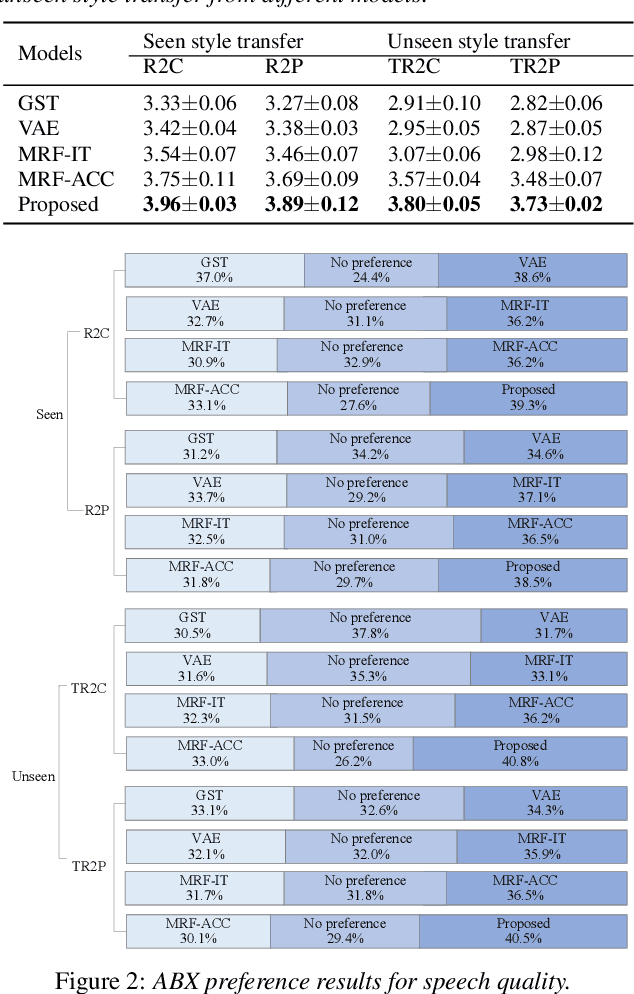
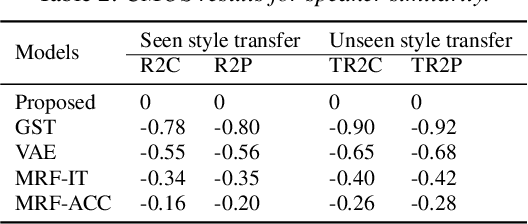

End-to-end neural TTS training has shown improved performance in speech style transfer. However, the improvement is still limited by the training data in both target styles and speakers. Inadequate style transfer performance occurs when the trained TTS tries to transfer the speech to a target style from a new speaker with an unknown, arbitrary style. In this paper, we propose a new approach to style transfer for both seen and unseen styles, with disjoint, multi-style datasets, i.e., datasets of different styles are recorded, each individual style is by one speaker with multiple utterances. To encode the style information, we adopt an inverse autoregressive flow (IAF) structure to improve the variational inference. The whole system is optimized to minimize a weighed sum of four different loss functions: 1) a reconstruction loss to measure the distortions in both source and target reconstructions; 2) an adversarial loss to "fool" a well-trained discriminator; 3) a style distortion loss to measure the expected style loss after the transfer; 4) a cycle consistency loss to preserve the speaker identity of the source after the transfer. Experiments demonstrate, both objectively and subjectively, the effectiveness of the proposed approach for seen and unseen style transfer tasks. The performance of the new approach is better and more robust than those of four baseline systems of the prior art.
Alternative Microfoundations for Strategic Classification
Jun 24, 2021
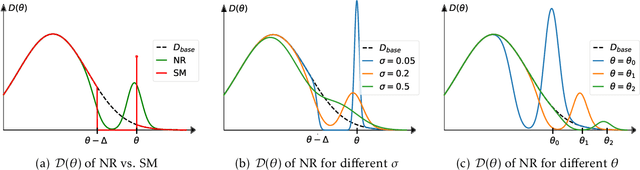
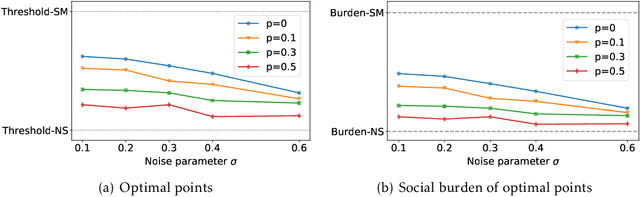
When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these standard ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points -- where the classifier is optimal for the data it entails -- cease to exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of possible assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We start by describing a set of desiderata that help navigate the space of possible assumptions about how agents respond to a decision rule. In particular, we analyze a natural constraint on feature manipulations, and discuss properties that are sufficient to guarantee the robust existence of stable points. Building on these insights, we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes a lower social burden at optimality.
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021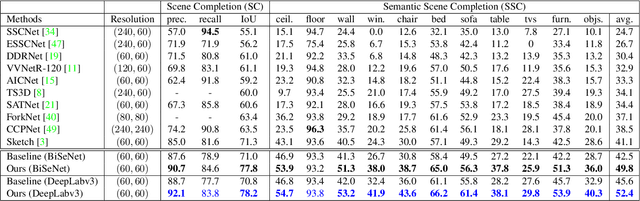

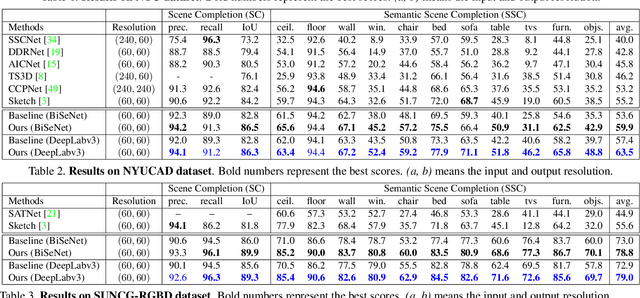
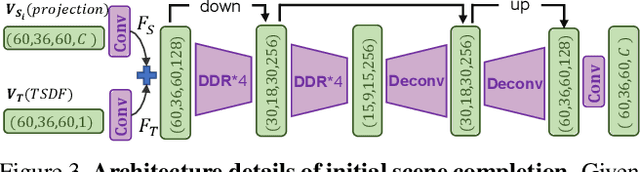
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.
CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues
May 20, 2021
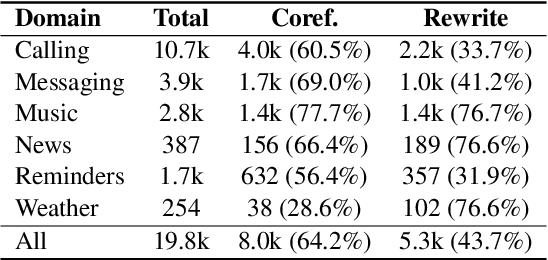

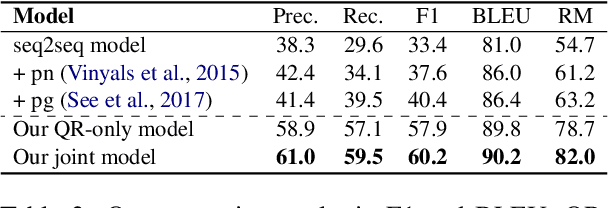
Anaphora and ellipses are two common phenomena in dialogues. Without resolving referring expressions and information omission, dialogue systems may fail to generate consistent and coherent responses. Traditionally, anaphora is resolved by coreference resolution and ellipses by query rewrite. In this work, we propose a novel joint learning framework of modeling coreference resolution and query rewriting for complex, multi-turn dialogue understanding. Given an ongoing dialogue between a user and a dialogue assistant, for the user query, our joint learning model first predicts coreference links between the query and the dialogue context, and then generates a self-contained rewritten user query. To evaluate our model, we annotate a dialogue based coreference resolution dataset, MuDoCo, with rewritten queries. Results show that the performance of query rewrite can be substantially boosted (+2.3% F1) with the aid of coreference modeling. Furthermore, our joint model outperforms the state-of-the-art coreference resolution model (+2% F1) on this dataset.
QD-GCN: Query-Driven Graph Convolutional Networks for Attributed Community Search
Apr 08, 2021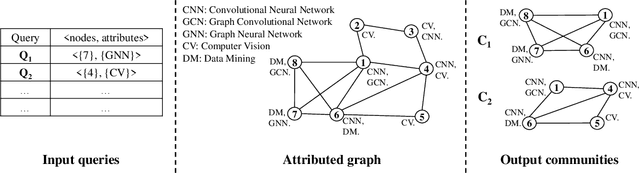
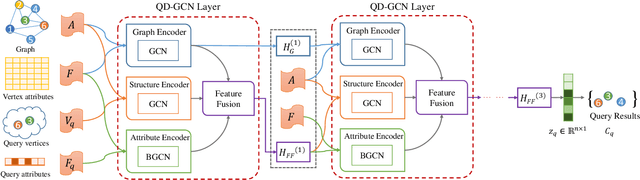
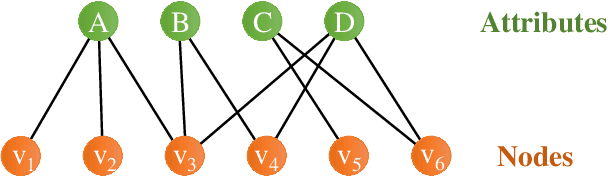
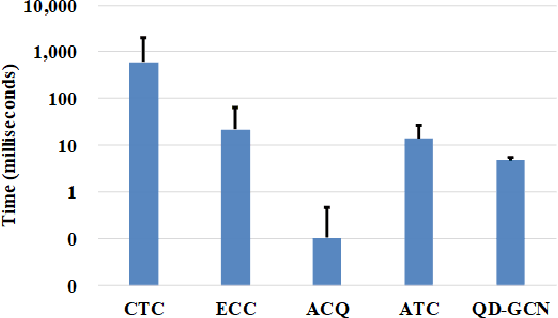
Recently, attributed community search, a related but different problem to community detection and graph clustering, has been widely studied in the literature. Compared with the community detection that finds all existing static communities from a graph, the attributed community search (ACS) is more challenging since it aims to find dynamic communities with both cohesive structures and homogeneous node attributes given arbitrary queries. To solve the ACS problem, the most popular paradigm is to simplify the problem as two sub-problems, that is, structural matching and attribute filtering and deal with them separately. However, in real-world graphs, the community structure and the node attributes are actually correlated to each other. In this vein, current studies cannot capture these correlations which are vital for the ACS problem. In this paper, we propose Query-Driven Graph Convolutional Networks (QD-GCN), an end-to-end framework that unifies the community structure as well as node attribute to solve the ACS problem. In particular, QD-GCN leverages the Graph Convolutional Networks, which is a powerful tool to encode the graph topology and node attributes concurrently, as the backbones to extract the query-dependent community information from the original graph. By utilizing this query-dependent community information, QD-GCN is able to predict the target community given any queries. Experiments on real-world graphs with ground-truth communities demonstrate that QD-GCN outperforms existing attributed community search algorithms in terms of both efficiency and effectiveness.
Lifting Transformer for 3D Human Pose Estimation in Video
Apr 01, 2021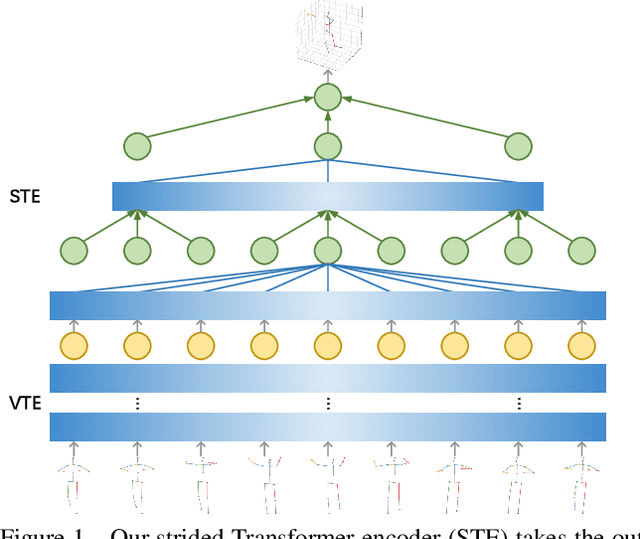
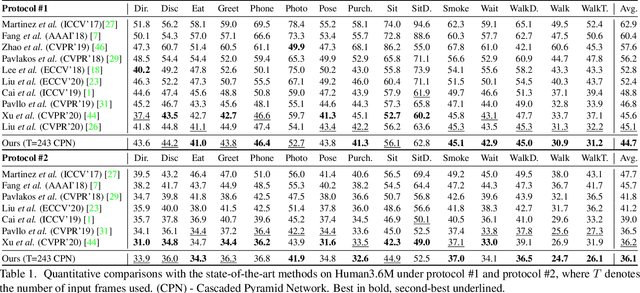
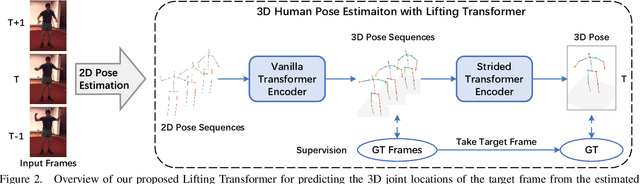
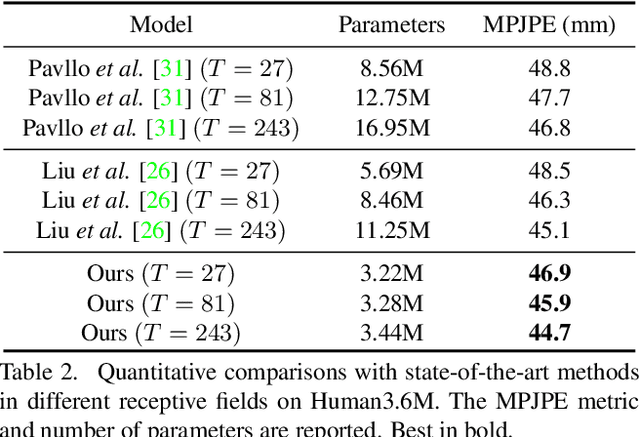
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.