 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Level-aware Haze Image Synthesis by Self-Supervised Content-Style Disentanglement
Mar 11, 2021

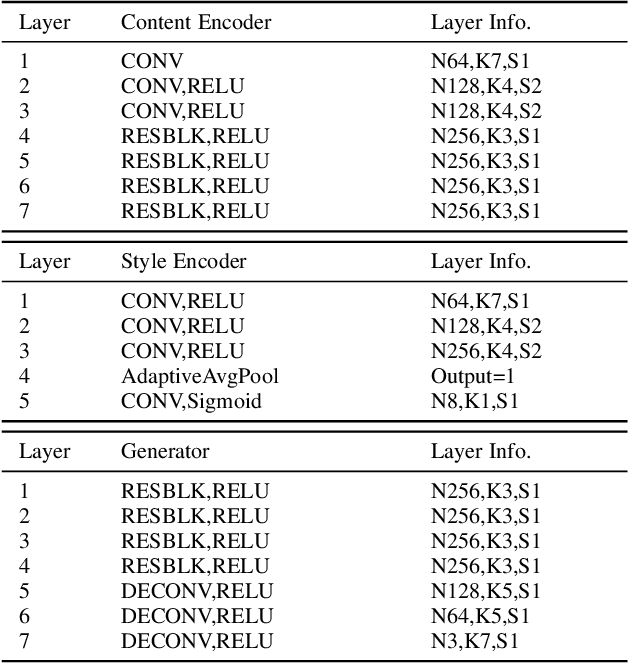
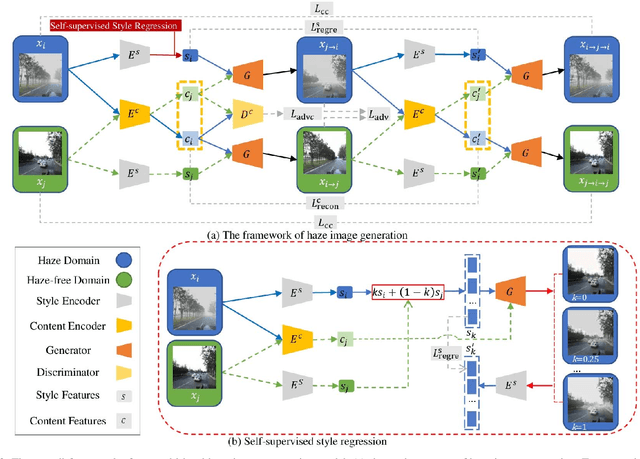
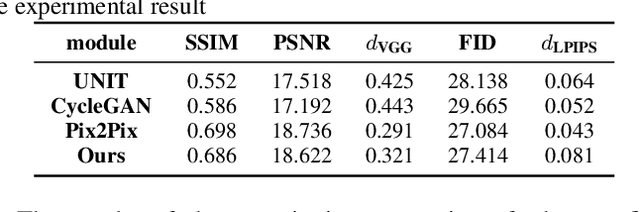
The key procedure of haze image translation through adversarial training lies in the disentanglement between the feature only involved in haze synthesis, i.e.style feature, and the feature representing the invariant semantic content, i.e. content feature. Previous methods separate content feature apart by utilizing it to classify haze image during the training process. However, in this paper we recognize the incompleteness of the content-style disentanglement in such technical routine. The flawed style feature entangled with content information inevitably leads the ill-rendering of the haze images. To address, we propose a self-supervised style regression via stochastic linear interpolation to reduce the content information in style feature. The ablative experiments demonstrate the disentangling completeness and its superiority in level-aware haze image synthesis. Moreover, the generated haze data are applied in the testing generalization of vehicle detectors. Further study between haze-level and detection performance shows that haze has obvious impact on the generalization of the vehicle detectors and such performance degrading level is linearly correlated to the haze-level, which, in turn, validates the effectiveness of the proposed method.
Recent Advances in Video Question Answering: A Review of Datasets and Methods
Jan 15, 2021
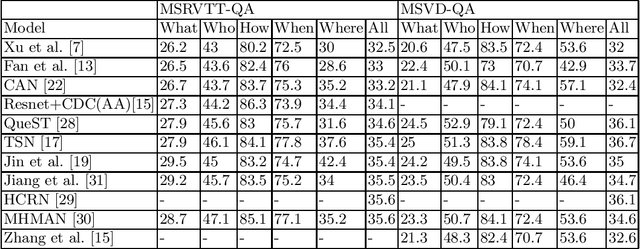
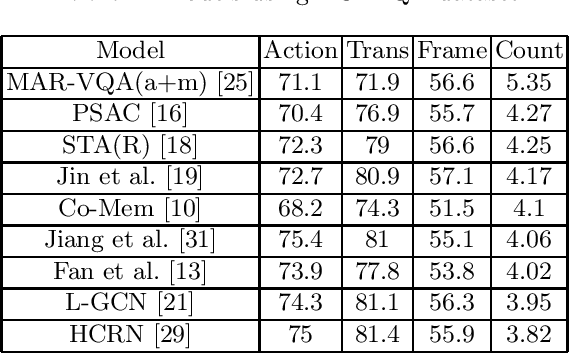
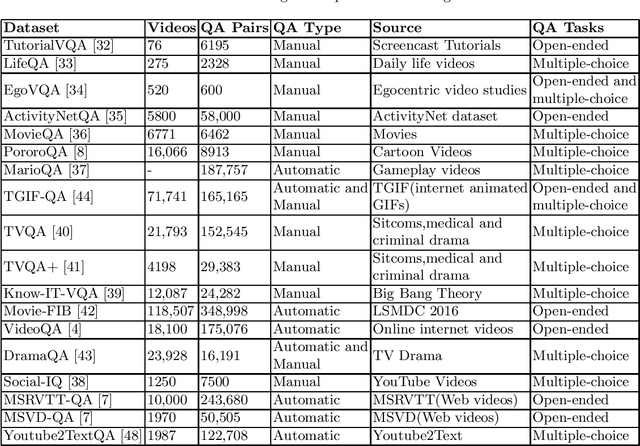
Video Question Answering (VQA) is a recent emerging challenging task in the field of Computer Vision. Several visual information retrieval techniques like Video Captioning/Description and Video-guided Machine Translation have preceded the task of VQA. VQA helps to retrieve temporal and spatial information from the video scenes and interpret it. In this survey, we review a number of methods and datasets for the task of VQA. To the best of our knowledge, no previous survey has been conducted for the VQA task.
Multi-Domain Active Learning: A Comparative Study
Jun 25, 2021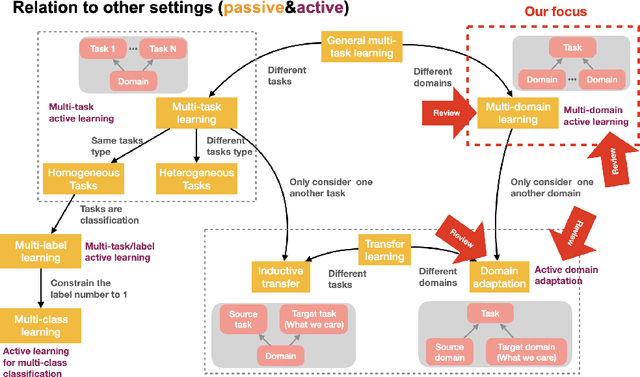
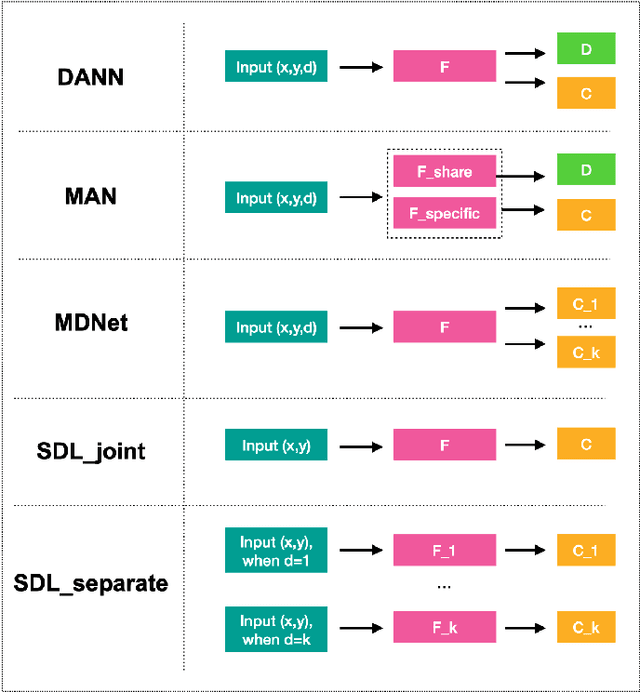
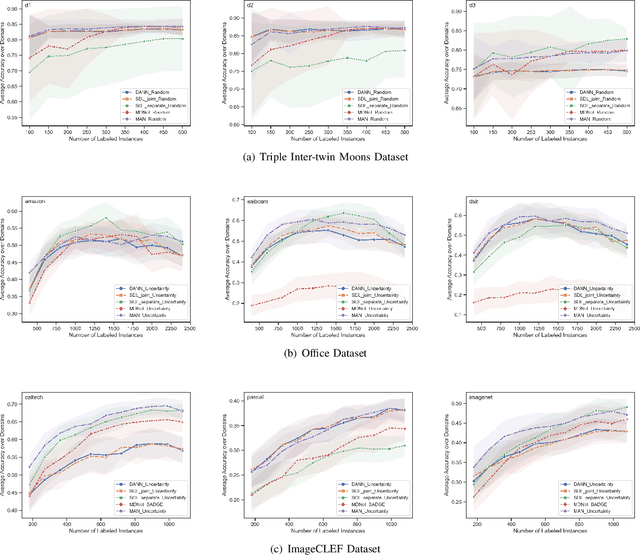
Building classifiers on multiple domains is a practical problem in the real life. Instead of building classifiers one by one, multi-domain learning (MDL) simultaneously builds classifiers on multiple domains. MDL utilizes the information shared among the domains to improve the performance. As a supervised learning problem, the labeling effort is still high in MDL problems. Usually, this high labeling cost issue could be relieved by using active learning. Thus, it is natural to utilize active learning to reduce the labeling effort in MDL, and we refer this setting as multi-domain active learning (MDAL). However, there are only few works which are built on this setting. And when the researches have to face this problem, there is no off-the-shelf solutions. Under this circumstance, combining the current multi-domain learning models and single-domain active learning strategies might be a preliminary solution for MDAL problem. To find out the potential of this preliminary solution, a comparative study over 5 models and 4 selection strategies is made in this paper. To the best of our knowledge, this is the first work provides the formal definition of MDAL. Besides, this is the first comparative work for MDAL problem. From the results, the Multinomial Adversarial Networks (MAN) model with a simple best vs second best (BvSB) uncertainty strategy shows its superiority in most cases. We take this combination as our off-the-shelf recommendation for the MDAL problem.
Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport
Jun 25, 2021
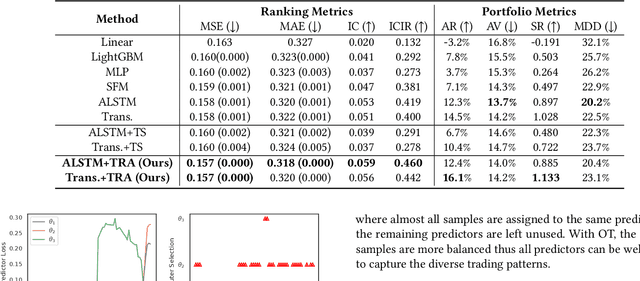
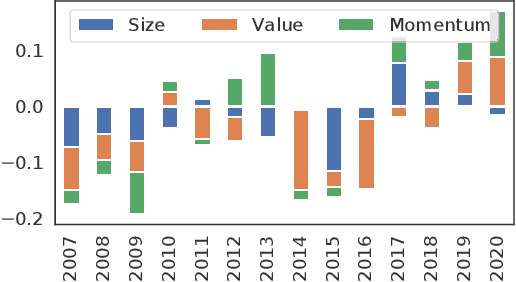
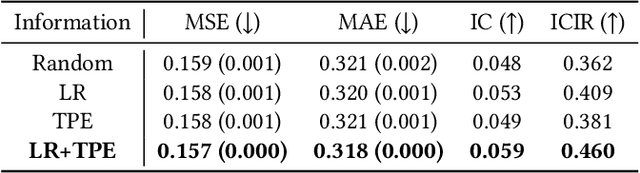
Successful quantitative investment usually relies on precise predictions of the future movement of the stock price. Recently, machine learning based solutions have shown their capacity to give more accurate stock prediction and become indispensable components in modern quantitative investment systems. However, the i.i.d. assumption behind existing methods is inconsistent with the existence of diverse trading patterns in the stock market, which inevitably limits their ability to achieve better stock prediction performance. In this paper, we propose a novel architecture, Temporal Routing Adaptor (TRA), to empower existing stock prediction models with the ability to model multiple stock trading patterns. Essentially, TRA is a lightweight module that consists of a set of independent predictors for learning multiple patterns as well as a router to dispatch samples to different predictors. Nevertheless, the lack of explicit pattern identifiers makes it quite challenging to train an effective TRA-based model. To tackle this challenge, we further design a learning algorithm based on Optimal Transport (OT) to obtain the optimal sample to predictor assignment and effectively optimize the router with such assignment through an auxiliary loss term. Experiments on the real-world stock ranking task show that compared to the state-of-the-art baselines, e.g., Attention LSTM and Transformer, the proposed method can improve information coefficient (IC) from 0.053 to 0.059 and 0.051 to 0.056 respectively. Our dataset and code used in this work are publicly available: https://github.com/microsoft/qlib/tree/main/examples/benchmarks/TRA.
Designing Multimodal Datasets for NLP Challenges
May 12, 2021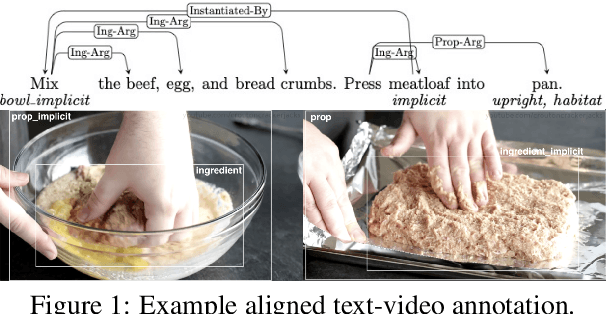


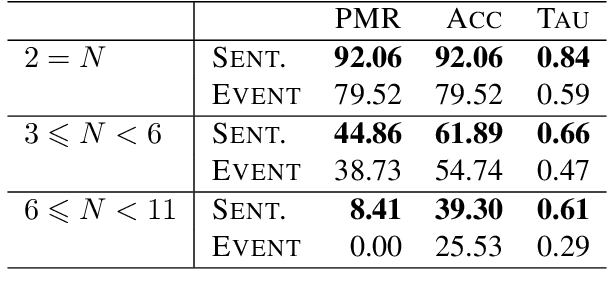
In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection in Autonomous Driving
Nov 27, 2020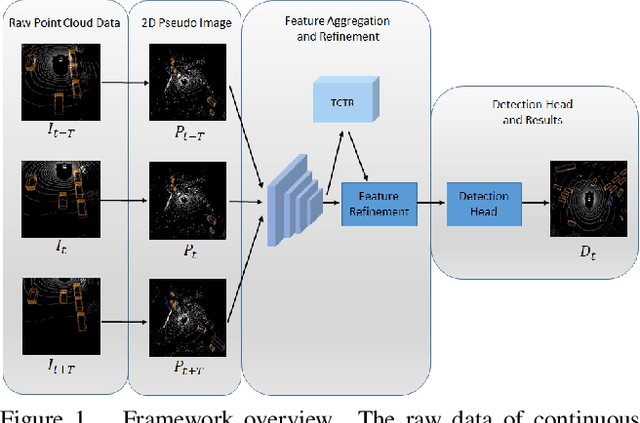
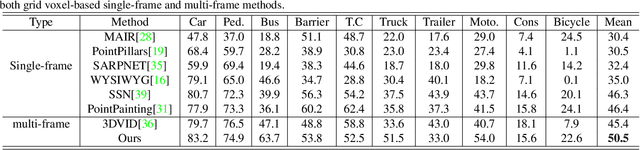
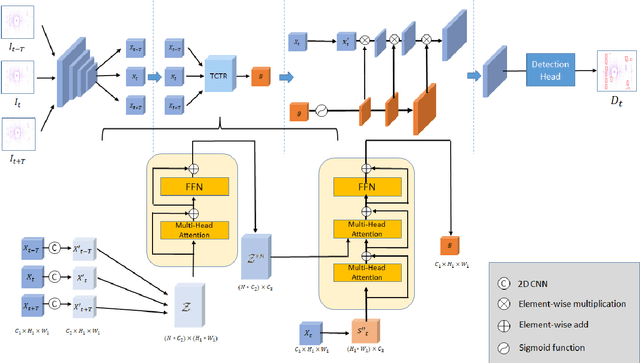
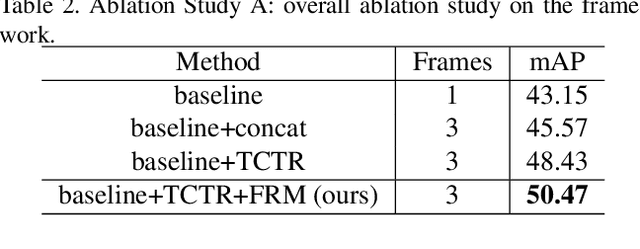
The strong demand of autonomous driving in the industry has lead to strong interest in 3D object detection and resulted in many excellent 3D object detection algorithms. However, the vast majority of algorithms only model single-frame data, ignoring the temporal information of the sequence of data. In this work, we propose a new transformer, called Temporal-Channel Transformer, to model the spatial-temporal domain and channel domain relationships for video object detecting from Lidar data. As a special design of this transformer, the information encoded in the encoder is different from that in the decoder, i.e. the encoder encodes temporal-channel information of multiple frames while the decoder decodes the spatial-channel information for the current frame in a voxel-wise manner. Specifically, the temporal-channel encoder of the transformer is designed to encode the information of different channels and frames by utilizing the correlation among features from different channels and frames. On the other hand, the spatial decoder of the transformer will decode the information for each location of the current frame. Before conducting the object detection with detection head, the gate mechanism is deployed for re-calibrating the features of current frame, which filters out the object irrelevant information by repetitively refine the representation of target frame along with the up-sampling process. Experimental results show that we achieve the state-of-the-art performance in grid voxel-based 3D object detection on the nuScenes benchmark.
Document Collection Visual Question Answering
Apr 27, 2021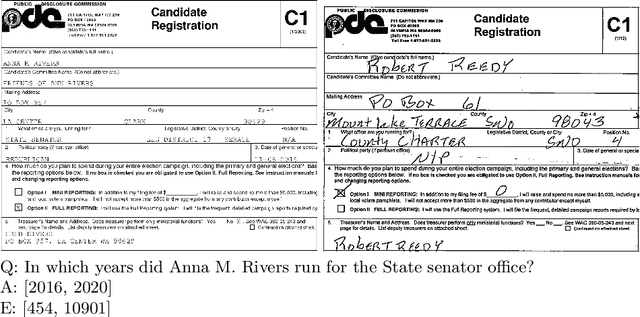


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.
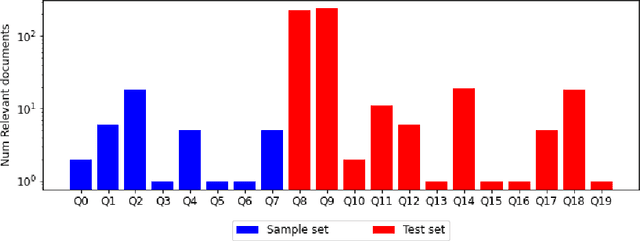
Mini-batch graphs for robust image classification
Apr 22, 2021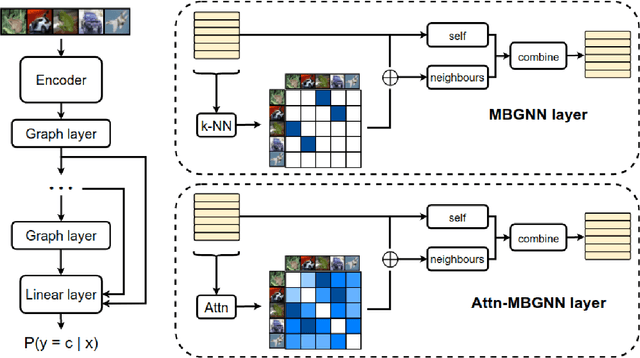
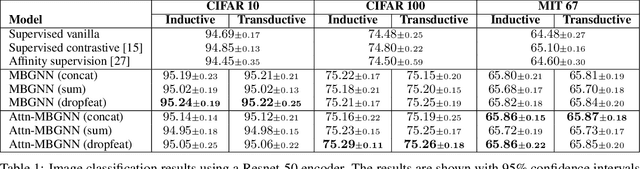

Current deep learning models for classification tasks in computer vision are trained using mini-batches. In the present article, we take advantage of the relationships between samples in a mini-batch, using graph neural networks to aggregate information from similar images. This helps mitigate the adverse effects of alterations to the input images on classification performance. Diverse experiments on image-based object and scene classification show that this approach not only improves a classifier's performance but also increases its robustness to image perturbations and adversarial attacks. Further, we also show that mini-batch graph neural networks can help to alleviate the problem of mode collapse in Generative Adversarial Networks.
Understanding the Security of Deepfake Detection
Jul 05, 2021
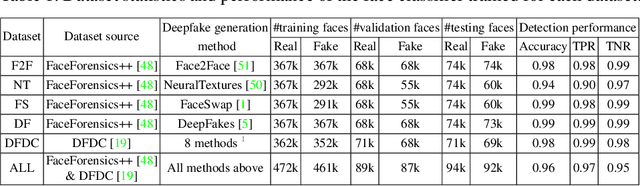
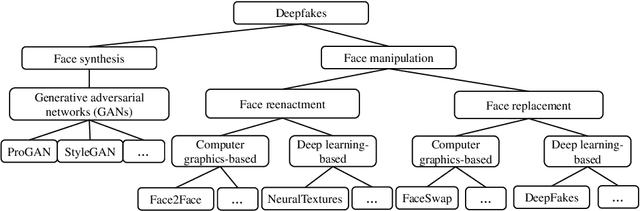
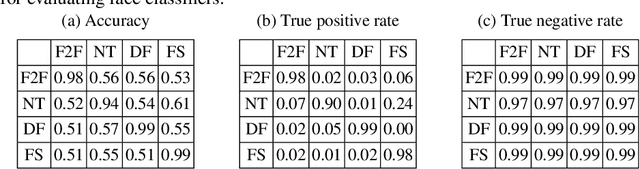
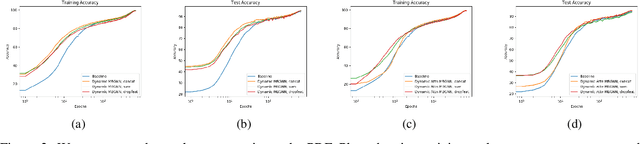
Deepfakes pose growing challenges to the trust of information on the Internet. Therefore,detecting deepfakes has attracted increasing attentions from both academia and industry. State-of-the-art deepfake detection methods consist of two key components, i.e., face extractor and face classifier, which extract the face region in an image and classify it to be real/fake, respectively. Existing studies mainly focused on improving the detection performance in non-adversarial settings, leaving security of deepfake detection in adversarial settings largely unexplored. In this work, we aim to bridge the gap. In particular, we perform a systematic measurement study to understand the security of the state-of-the-art deepfake detection methods in adversarial settings. We use two large-scale public deepfakes data sources including FaceForensics++ and Facebook Deepfake Detection Challenge, where the deepfakes are fake face images; and we train state-of-the-art deepfake detection methods. These detection methods can achieve 0.94--0.99 accuracies in non-adversarial settings on these datasets. However, our measurement results uncover multiple security limitations of the deepfake detection methods in adversarial settings. First, we find that an attacker can evade a face extractor, i.e., the face extractor fails to extract the correct face regions, via adding small Gaussian noise to its deepfake images. Second, we find that a face classifier trained using deepfakes generated by one method cannot detect deepfakes generated by another method, i.e., an attacker can evade detection via generating deepfakes using a new method. Third, we find that an attacker can leverage backdoor attacks developed by the adversarial machine learning community to evade a face classifier. Our results highlight that deepfake detection should consider the adversarial nature of the problem.
Do Context-Aware Translation Models Pay the Right Attention?
May 21, 2021

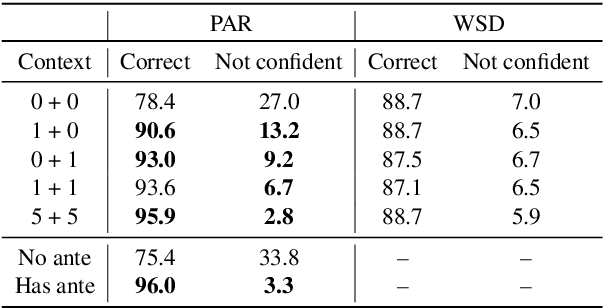
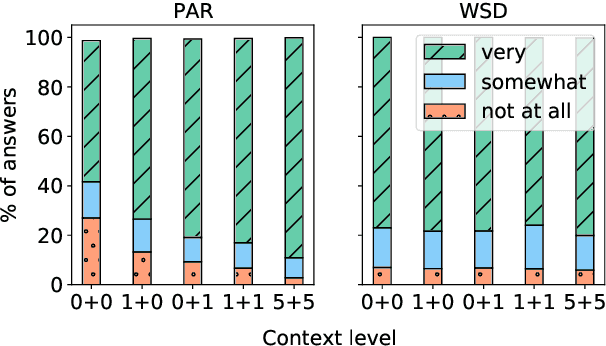
Context-aware machine translation models are designed to leverage contextual information, but often fail to do so. As a result, they inaccurately disambiguate pronouns and polysemous words that require context for resolution. In this paper, we ask several questions: What contexts do human translators use to resolve ambiguous words? Are models paying large amounts of attention to the same context? What if we explicitly train them to do so? To answer these questions, we introduce SCAT (Supporting Context for Ambiguous Translations), a new English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation. Using SCAT, we perform an in-depth analysis of the context used to disambiguate, examining positional and lexical characteristics of the supporting words. Furthermore, we measure the degree of alignment between the model's attention scores and the supporting context from SCAT, and apply a guided attention strategy to encourage agreement between the two.