 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Gaze and Mouse Signal as additional Source for User Fingerprints in Browser Applications
Jan 17, 2021

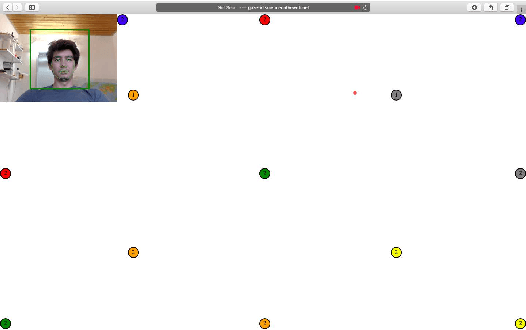
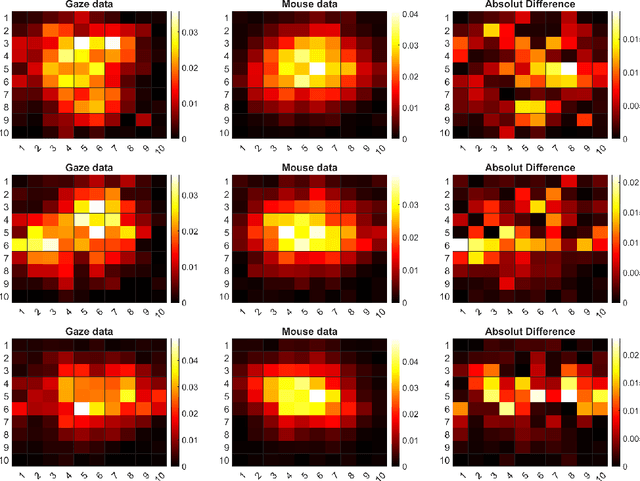
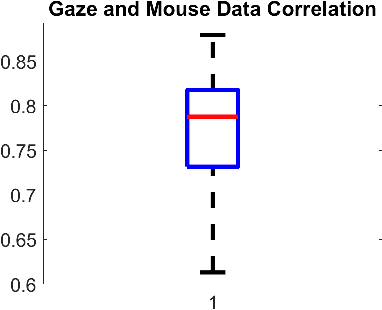
In this work we inspect different data sources for browser fingerprints. We show which disadvantages and limitations browser statistics have and how this can be avoided with other data sources. Since human visual behavior is a rich source of information and also contains person specific information, it is a valuable source for browser fingerprints. However, human gaze acquisition in the browser also has disadvantages, such as inaccuracies via webcam and the restriction that the user must first allow access to the camera. However, it is also known that the mouse movements and the human gaze correlate and therefore, the mouse movements can be used instead of the gaze signal. In our evaluation we show the influence of all possible combinations of the three information sources for user recognition and describe our simple approach in detail. The data and the Matlab code can be downloaded here https://atreus.informatik.uni-tuebingen.de/seafile/d/8e2ab8c3fdd444e1a135/?p=%2FThe%20Gaze%20and%20Mouse%20Signal%20as%20additional%20Source%20...&mode=list
A Little Pretraining Goes a Long Way: A Case Study on Dependency Parsing Task for Low-resource Morphologically Rich Languages
Feb 12, 2021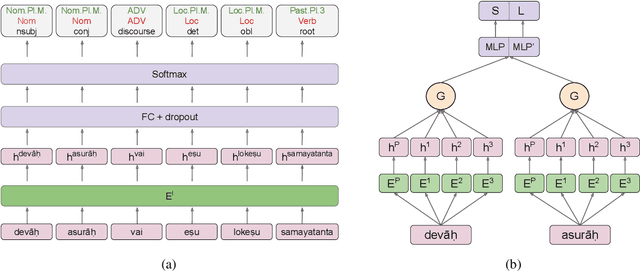
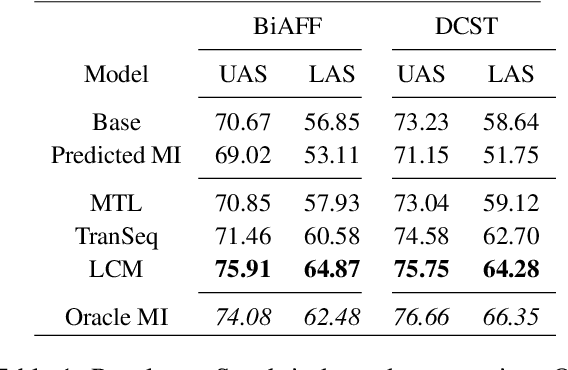
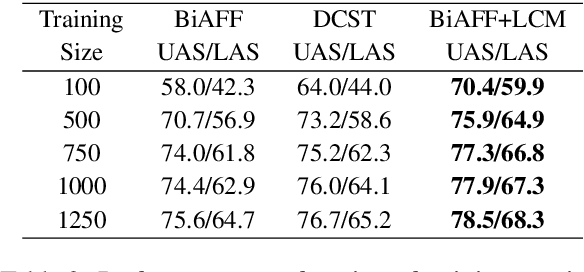
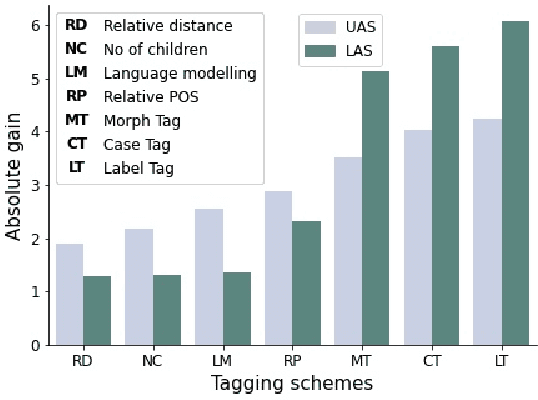
Neural dependency parsing has achieved remarkable performance for many domains and languages. The bottleneck of massive labeled data limits the effectiveness of these approaches for low resource languages. In this work, we focus on dependency parsing for morphological rich languages (MRLs) in a low-resource setting. Although morphological information is essential for the dependency parsing task, the morphological disambiguation and lack of powerful analyzers pose challenges to get this information for MRLs. To address these challenges, we propose simple auxiliary tasks for pretraining. We perform experiments on 10 MRLs in low-resource settings to measure the efficacy of our proposed pretraining method and observe an average absolute gain of 2 points (UAS) and 3.6 points (LAS). Code and data available at: https://github.com/jivnesh/LCM
Do End-to-End Speech Recognition Models Care About Context?
Feb 17, 2021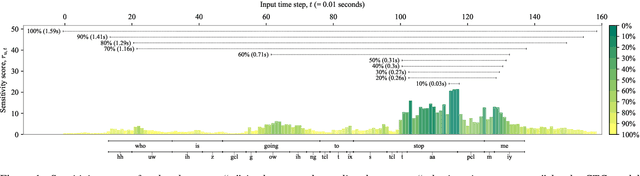
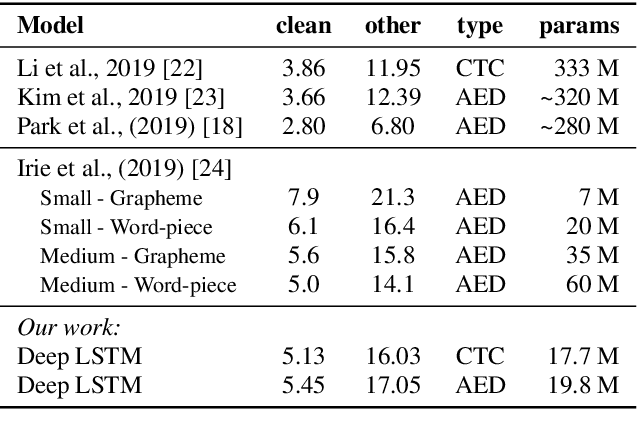
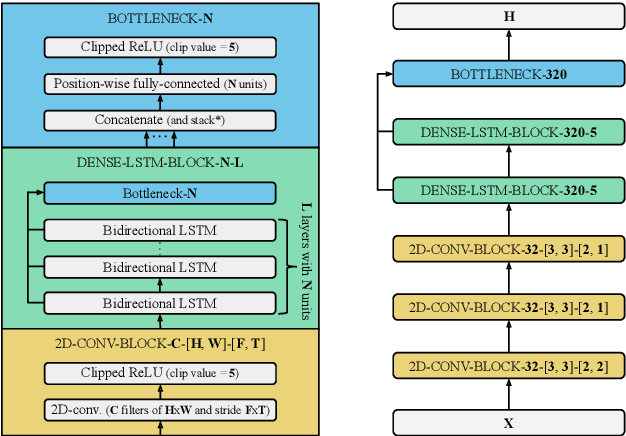
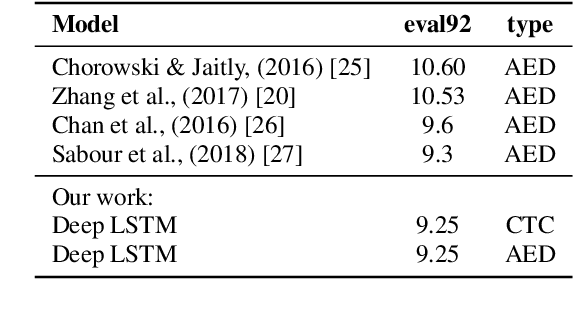
The two most common paradigms for end-to-end speech recognition are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. It has been argued that the latter is better suited for learning an implicit language model. We test this hypothesis by measuring temporal context sensitivity and evaluate how the models perform when we constrain the amount of contextual information in the audio input. We find that the AED model is indeed more context sensitive, but that the gap can be closed by adding self-attention to the CTC model. Furthermore, the two models perform similarly when contextual information is constrained. Finally, in contrast to previous research, our results show that the CTC model is highly competitive on WSJ and LibriSpeech without the help of an external language model.
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
Jul 01, 2021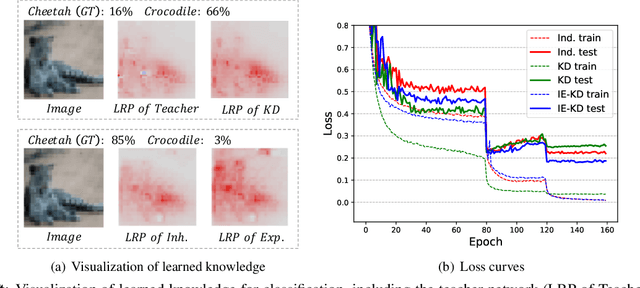

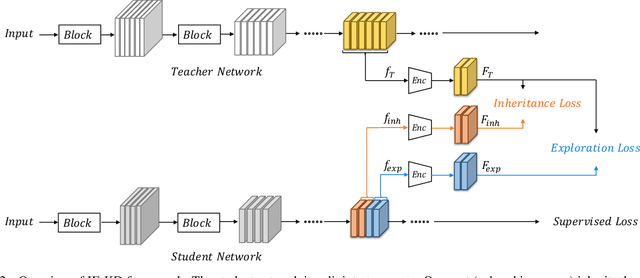

Knowledge Distillation (KD) is a popular technique to transfer knowledge from a teacher model or ensemble to a student model. Its success is generally attributed to the privileged information on similarities/consistency between the class distributions or intermediate feature representations of the teacher model and the student model. However, directly pushing the student model to mimic the probabilities/features of the teacher model to a large extent limits the student model in learning undiscovered knowledge/features. In this paper, we propose a novel inheritance and exploration knowledge distillation framework (IE-KD), in which a student model is split into two parts - inheritance and exploration. The inheritance part is learned with a similarity loss to transfer the existing learned knowledge from the teacher model to the student model, while the exploration part is encouraged to learn representations different from the inherited ones with a dis-similarity loss. Our IE-KD framework is generic and can be easily combined with existing distillation or mutual learning methods for training deep neural networks. Extensive experiments demonstrate that these two parts can jointly push the student model to learn more diversified and effective representations, and our IE-KD can be a general technique to improve the student network to achieve SOTA performance. Furthermore, by applying our IE-KD to the training of two networks, the performance of both can be improved w.r.t. deep mutual learning. The code and models of IE-KD will be make publicly available at https://github.com/yellowtownhz/IE-KD.
All Together Now: Teachers as Research Partners in the Design of Search Technology for the Classroom
May 08, 2021In the classroom environment, search tools are the means for students to access Web resources. The perspectives of students, researchers, and industry practitioners lead the ongoing research debate in this area. In this article, we argue in favor of incorporating a new voice into this debate: teachers. We showcase the value of involving teachers in all aspects related to the design of search tools for the classroom; from the beginning till the end. Driven by our research experience designing, developing, and evaluating new tools to support children's information discovery in the classroom, we share insights on the role of the experts-in-the-loop, i.e., teachers who provide the connection between search tools and students. And yes, in our case, always involving a teacher as a research partner.
Dogfight: Detecting Drones from Drones Videos
Apr 09, 2021
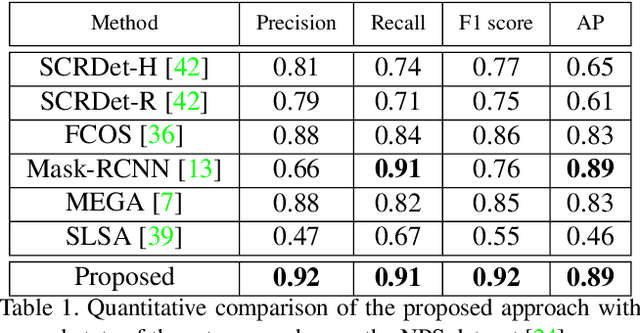
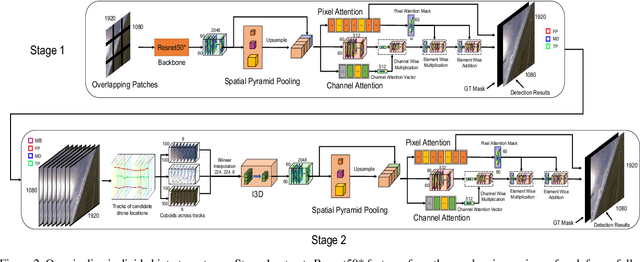
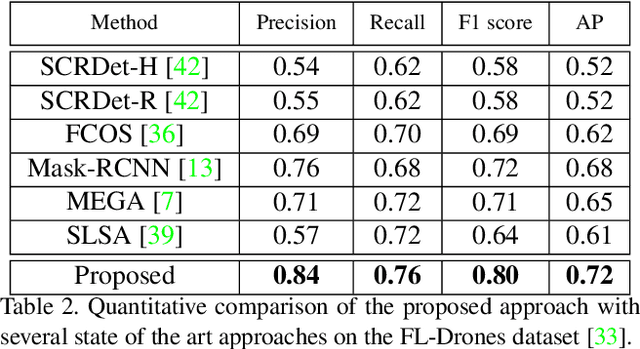
As airborne vehicles are becoming more autonomous and ubiquitous, it has become vital to develop the capability to detect the objects in their surroundings. This paper attempts to address the problem of drones detection from other flying drones. The erratic movement of the source and target drones, small size, arbitrary shape, large intensity variations, and occlusion make this problem quite challenging. In this scenario, region-proposal based methods are not able to capture sufficient discriminative foreground-background information. Also, due to the extremely small size and complex motion of the source and target drones, feature aggregation based methods are unable to perform well. To handle this, instead of using region-proposal based methods, we propose to use a two-stage segmentation-based approach employing spatio-temporal attention cues. During the first stage, given the overlapping frame regions, detailed contextual information is captured over convolution feature maps using pyramid pooling. After that pixel and channel-wise attention is enforced on the feature maps to ensure accurate drone localization. In the second stage, first stage detections are verified and new probable drone locations are explored. To discover new drone locations, motion boundaries are used. This is followed by tracking candidate drone detections for a few frames, cuboid formation, extraction of the 3D convolution feature map, and drones detection within each cuboid. The proposed approach is evaluated on two publicly available drone detection datasets and outperforms several competitive baselines.
DeepLoc: A Ubiquitous Accurate and Low-Overhead Outdoor Cellular Localization System
Jun 25, 2021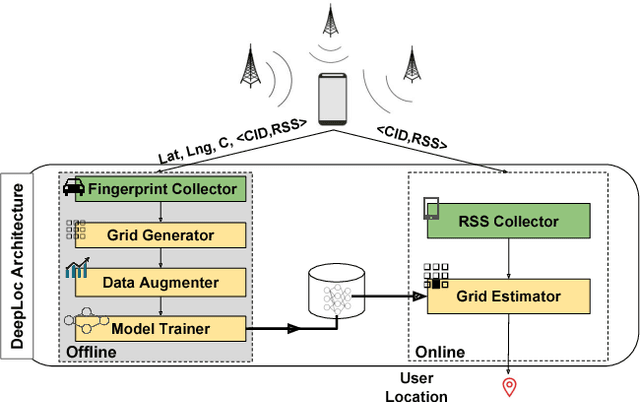
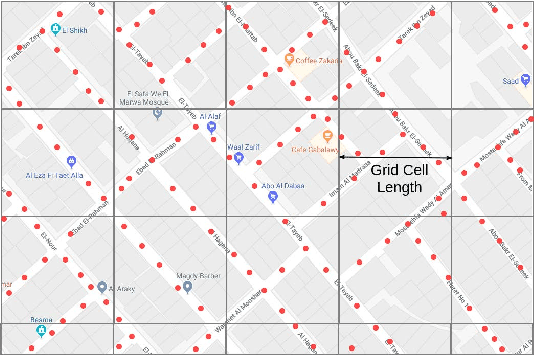

Recent years have witnessed fast growth in outdoor location-based services. While GPS is considered a ubiquitous localization system, it is not supported by low-end phones, requires direct line of sight to the satellites, and can drain the phone battery quickly. In this paper, we propose DeepLoc: a deep learning-based outdoor localization system that obtains GPS-like localization accuracy without its limitations. In particular, DeepLoc leverages the ubiquitous cellular signals received from the different cell towers heard by the mobile device as hints to localize it. To do that, crowd-sensed geo-tagged received signal strength information coming from different cell towers is used to train a deep model that is used to infer the user's position. As part of DeepLoc design, we introduce modules to address a number of practical challenges including scaling the data collection to large areas, handling the inherent noise in the cellular signal and geo-tagged data, as well as providing enough data that is required for deep learning models with low-overhead. We implemented DeepLoc on different Android devices. Evaluation results in realistic urban and rural environments show that DeepLoc can achieve a median localization accuracy within 18.8m in urban areas and within 15.7m in rural areas. This accuracy outperforms the state-of-the-art cellular-based systems by more than 470% and comes with 330% savings in power compared to the GPS. This highlights the promise of DeepLoc as a ubiquitous accurate and low-overhead localization system.
Attend and Select: A Segment Attention based Selection Mechanism for Microblog Hashtag Generation
Jun 06, 2021

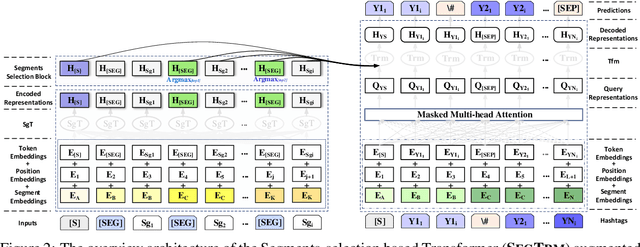
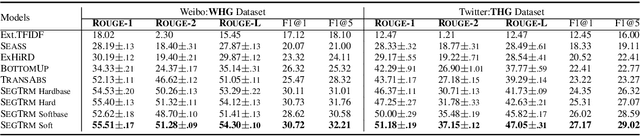
Automatic microblog hashtag generation can help us better and faster understand or process the critical content of microblog posts. Conventional sequence-to-sequence generation methods can produce phrase-level hashtags and have achieved remarkable performance on this task. However, they are incapable of filtering out secondary information and not good at capturing the discontinuous semantics among crucial tokens. A hashtag is formed by tokens or phrases that may originate from various fragmentary segments of the original text. In this work, we propose an end-to-end Transformer-based generation model which consists of three phases: encoding, segments-selection, and decoding. The model transforms discontinuous semantic segments from the source text into a sequence of hashtags. Specifically, we introduce a novel Segments Selection Mechanism (SSM) for Transformer to obtain segmental representations tailored to phrase-level hashtag generation. Besides, we introduce two large-scale hashtag generation datasets, which are newly collected from Chinese Weibo and English Twitter. Extensive evaluations on the two datasets reveal our approach's superiority with significant improvements to extraction and generation baselines. The code and datasets are available at \url{https://github.com/OpenSUM/HashtagGen}.
When is Memorization of Irrelevant Training Data Necessary for High-Accuracy Learning?
Dec 11, 2020
Modern machine learning models are complex and frequently encode surprising amounts of information about individual inputs. In extreme cases, complex models appear to memorize entire input examples, including seemingly irrelevant information (social security numbers from text, for example). In this paper, we aim to understand whether this sort of memorization is necessary for accurate learning. We describe natural prediction problems in which every sufficiently accurate training algorithm must encode, in the prediction model, essentially all the information about a large subset of its training examples. This remains true even when the examples are high-dimensional and have entropy much higher than the sample size, and even when most of that information is ultimately irrelevant to the task at hand. Further, our results do not depend on the training algorithm or the class of models used for learning. Our problems are simple and fairly natural variants of the next-symbol prediction and the cluster labeling tasks. These tasks can be seen as abstractions of image- and text-related prediction problems. To establish our results, we reduce from a family of one-way communication problems for which we prove new information complexity lower bounds.
FireFly Autonomous Drone Project
Apr 15, 2021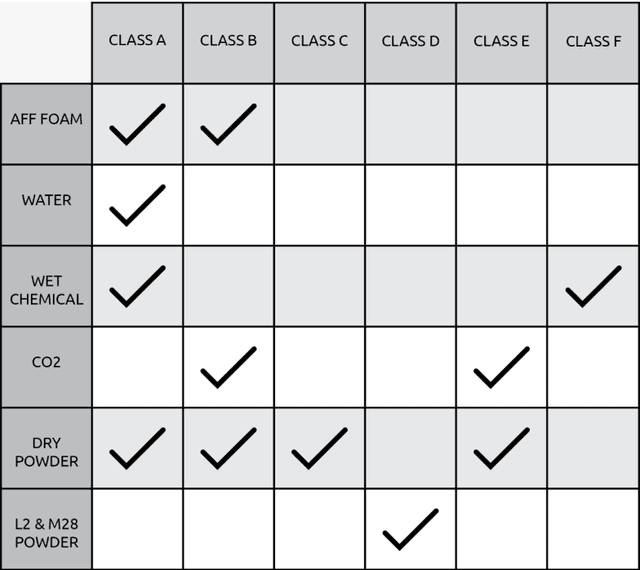
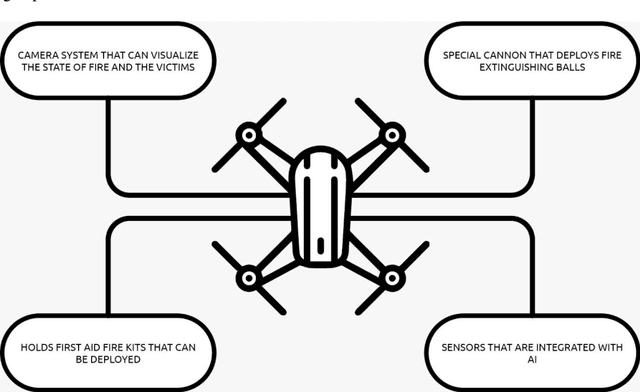
As a fire erupts, the first few minutes can be critical, and first respondents must race to the scene to analyze the situation and act fast before it gets out of hand. Factors such as road traffic condition and distance may not allow quick rescue operation using traditional means and methods, leading to unmanageable spreading of fire, injuries or even deaths that can be avoided. FireFly drone-based rescue consists of a squad of highly equipped drones that will be the first responders to the fire site. Their intervention will make the task of the fire rescue team much more effective and will contribute to reduce the overall damage. As soon as the fire is detected by in-building implanted sensors, the fire department would deploy a set of FireFly drones that would fly to the site, scan the building, and send live fire status information to the Fire fighter team. The drones would have the ability to identify trapped humans using AI based pattern recognition tools (using sensors and thermal cameras) and then drop them rescue kits as appropriate. The drones will also be equipped with fire detection and recognition capabilities and be able to drop fire extinguishing balls as first attempts to put off seeds of fires before they evolve. The integration of drones with firefighting will allow for ease of access and control of fire outbreaks. Drones will also result in increased response time, prevention of further damage, and allow relaying of vital information to out of reach places regarding the characteristics of the fire scene.