 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding who uses Reddit: Profiling individuals with a self-reported bipolar disorder diagnosis
Apr 23, 2021

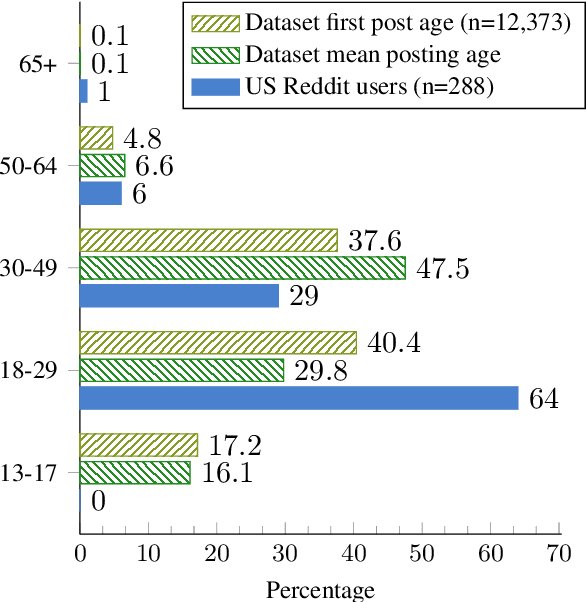
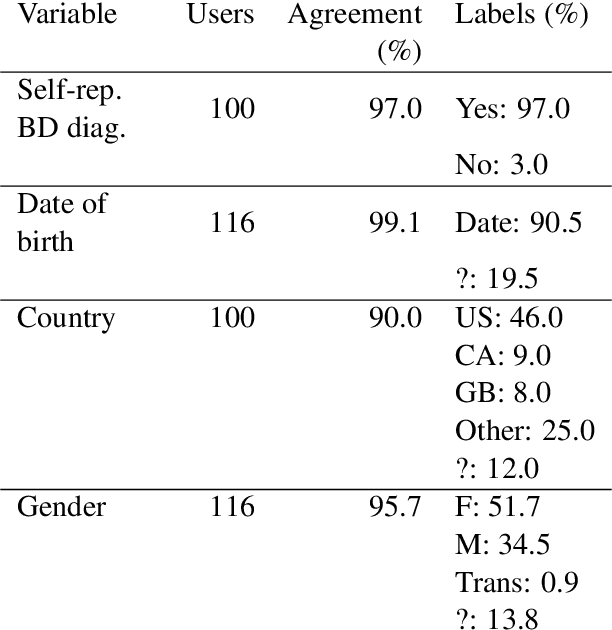
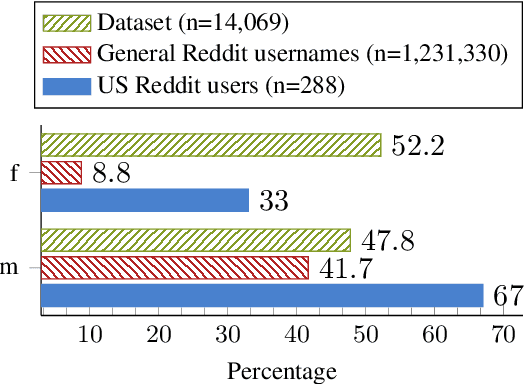
Recently, research on mental health conditions using public online data, including Reddit, has surged in NLP and health research but has not reported user characteristics, which are important to judge generalisability of findings. This paper shows how existing NLP methods can yield information on clinical, demographic, and identity characteristics of almost 20K Reddit users who self-report a bipolar disorder diagnosis. This population consists of slightly more feminine- than masculine-gendered mainly young or middle-aged US-based adults who often report additional mental health diagnoses, which is compared with general Reddit statistics and epidemiological studies. Additionally, this paper carefully evaluates all methods and discusses ethical issues.
Directed Acyclic Graph Neural Networks
Feb 02, 2021



Graph-structured data ubiquitously appears in science and engineering. Graph neural networks (GNNs) are designed to exploit the relational inductive bias exhibited in graphs; they have been shown to outperform other forms of neural networks in scenarios where structure information supplements node features. The most common GNN architecture aggregates information from neighborhoods based on message passing. Its generality has made it broadly applicable. In this paper, we focus on a special, yet widely used, type of graphs -- DAGs -- and inject a stronger inductive bias -- partial ordering -- into the neural network design. We propose the \emph{directed acyclic graph neural network}, DAGNN, an architecture that processes information according to the flow defined by the partial order. DAGNN can be considered a framework that entails earlier works as special cases (e.g., models for trees and models updating node representations recurrently), but we identify several crucial components that prior architectures lack. We perform comprehensive experiments, including ablation studies, on representative DAG datasets (i.e., source code, neural architectures, and probabilistic graphical models) and demonstrate the superiority of DAGNN over simpler DAG architectures as well as general graph architectures.
Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation
Sep 06, 2018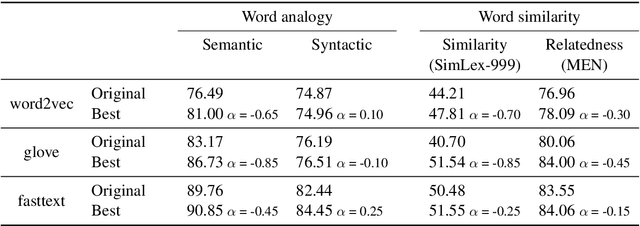
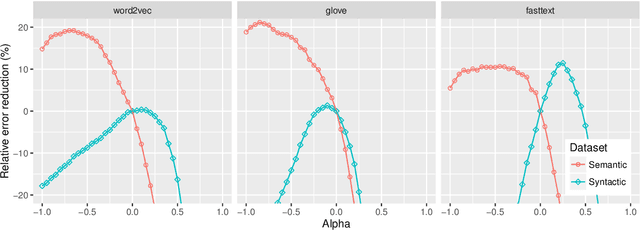
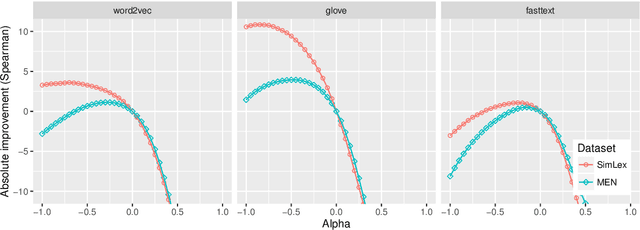
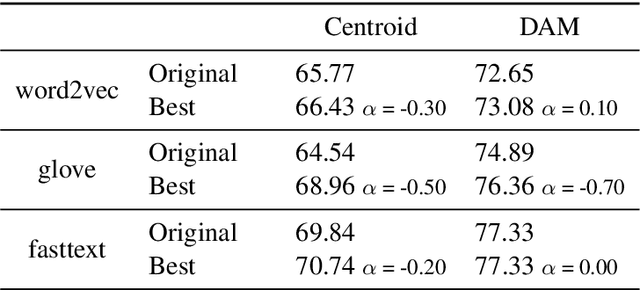
Following the recent success of word embeddings, it has been argued that there is no such thing as an ideal representation for words, as different models tend to capture divergent and often mutually incompatible aspects like semantics/syntax and similarity/relatedness. In this paper, we show that each embedding model captures more information than directly apparent. A linear transformation that adjusts the similarity order of the model without any external resource can tailor it to achieve better results in those aspects, providing a new perspective on how embeddings encode divergent linguistic information. In addition, we explore the relation between intrinsic and extrinsic evaluation, as the effect of our transformations in downstream tasks is higher for unsupervised systems than for supervised ones.
Comparing seven methods for state-of-health time series prediction for the lithium-ion battery packs of forklifts
Jul 06, 2021
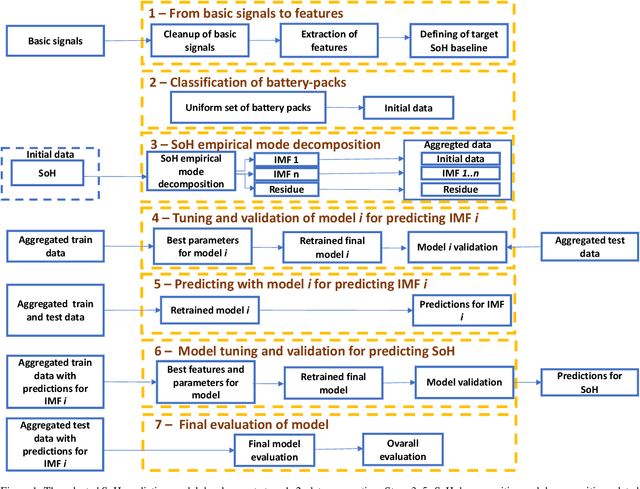
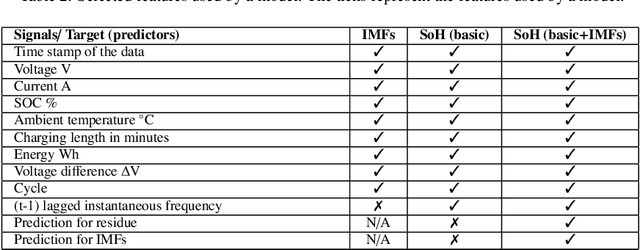
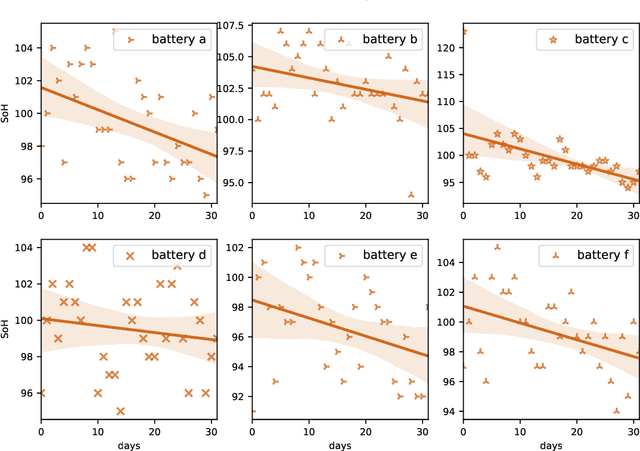
A key aspect for the forklifts is the state-of-health (SoH) assessment to ensure the safety and the reliability of uninterrupted power source. Forecasting the battery SoH well is imperative to enable preventive maintenance and hence to reduce the costs. This paper demonstrates the capabilities of gradient boosting regression for predicting the SoH timeseries under circumstances when there is little prior information available about the batteries. We compared the gradient boosting method with light gradient boosting, extra trees, extreme gradient boosting, random forests, long short-term memory networks and with combined convolutional neural network and long short-term memory networks methods. We used multiple predictors and lagged target signal decomposition results as additional predictors and compared the yielded prediction results with different sets of predictors for each method. For this work, we are in possession of a unique data set of 45 lithium-ion battery packs with large variation in the data. The best model that we derived was validated by a novel walk-forward algorithm that also calculates point-wise confidence intervals for the predictions; we yielded reasonable predictions and confidence intervals for the predictions. Furthermore, we verified this model against five other lithium-ion battery packs; the best model generalised to greater extent to this set of battery packs. The results about the final model suggest that we were able to enhance the results in respect to previously developed models. Moreover, we further validated the model for extracting cycle counts presented in our previous work with data from new forklifts; their battery packs completed around 3000 cycles in a 10-year service period, which corresponds to the cycle life for commercial Nickel-Cobalt-Manganese (NMC) cells.
* 16 pages, 10 figures and 10 tables
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021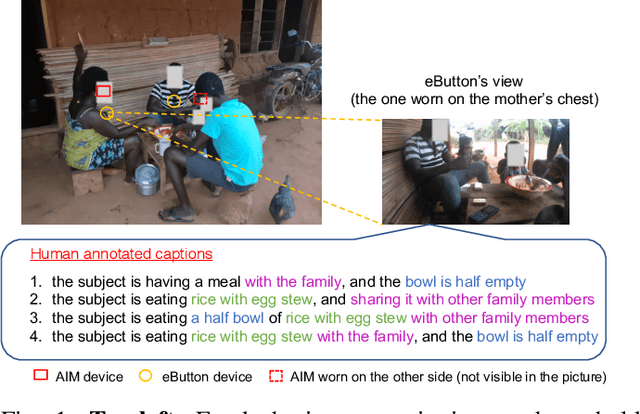
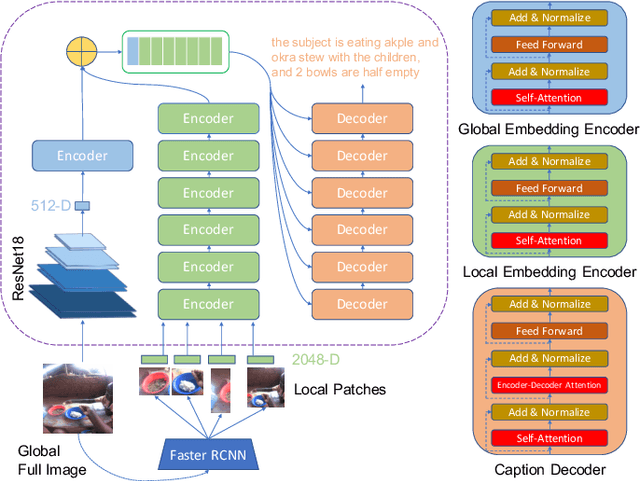
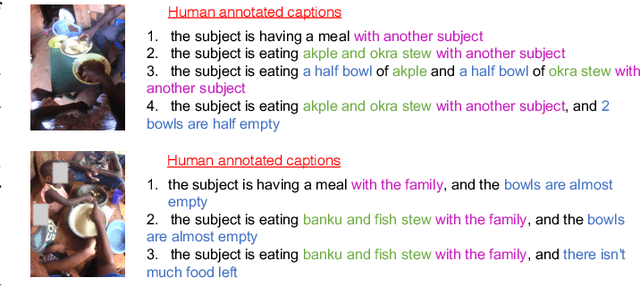
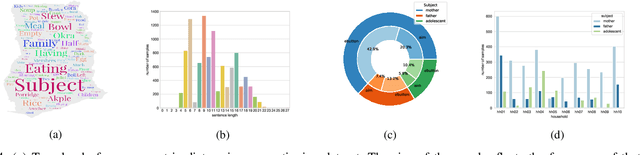
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
A Consistency-Based Loss for Deep Odometry Through Uncertainty Propagation
Jul 01, 2021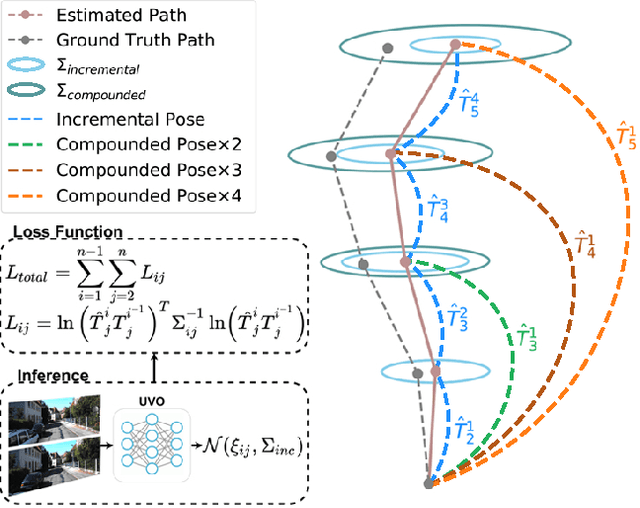
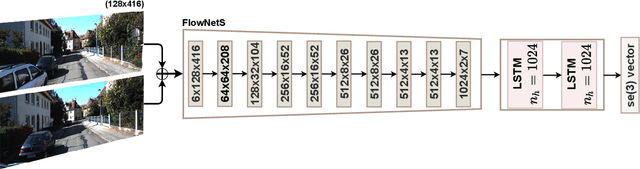
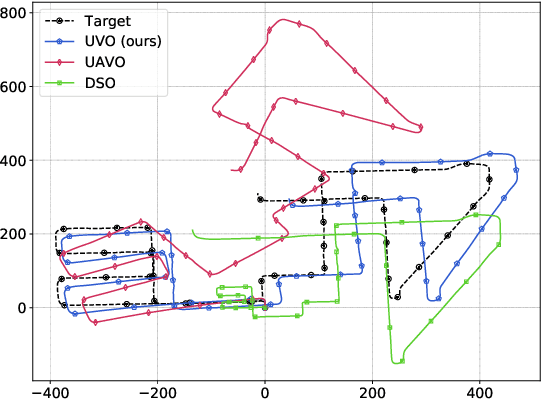
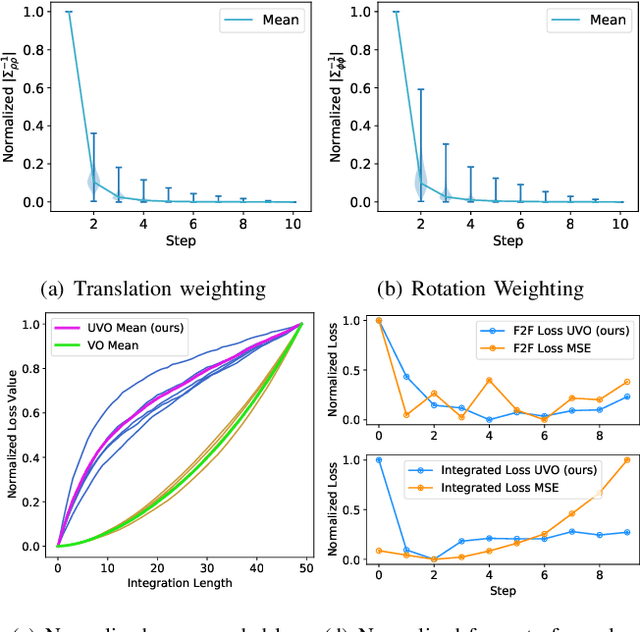
The incremental poses computed through odometry can be integrated over time to calculate the pose of a device with respect to an initial location. The resulting global pose may be used to formulate a second, consistency based, loss term in a deep odometry setting. In such cases where multiple losses are imposed on a network, the uncertainty over each output can be derived to weigh the different loss terms in a maximum likelihood setting. However, when imposing a constraint on the integrated transformation, due to how only odometry is estimated at each iteration of the algorithm, there is no information about the uncertainty associated with the global pose to weigh the global loss term. In this paper, we associate uncertainties with the output poses of a deep odometry network and propagate the uncertainties through each iteration. Our goal is to use the estimated covariance matrix at each incremental step to weigh the loss at the corresponding step while weighting the global loss term using the compounded uncertainty. This formulation provides an adaptive method to weigh the incremental and integrated loss terms against each other, noting the increase in uncertainty as new estimates arrive. We provide quantitative and qualitative analysis of pose estimates and show that our method surpasses the accuracy of the state-of-the-art Visual Odometry approaches. Then, uncertainty estimates are evaluated and comparisons against fixed baselines are provided. Finally, the uncertainty values are used in a realistic example to show the effectiveness of uncertainty quantification for localization.
On the Skew-Symmetric Binary Sequences and the Merit Factor Problem
Jun 07, 2021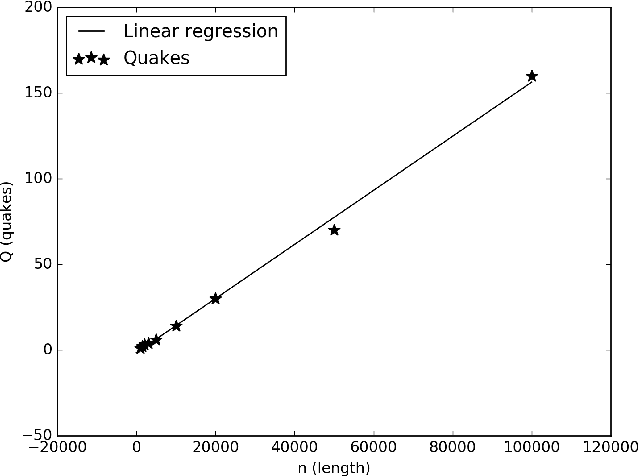
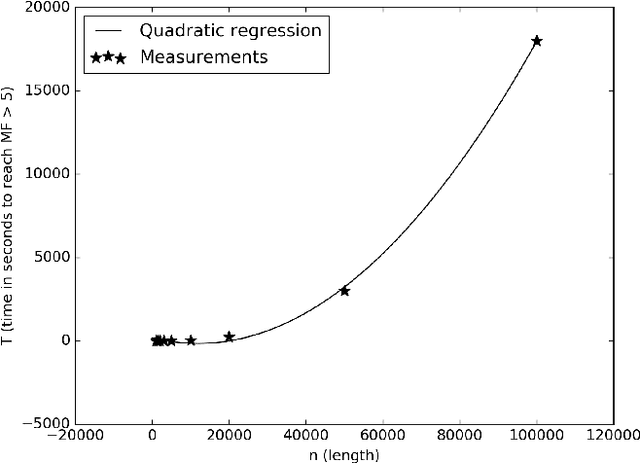
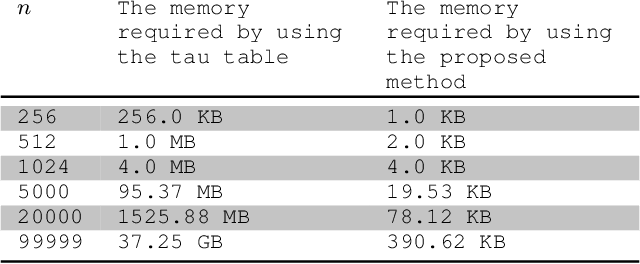
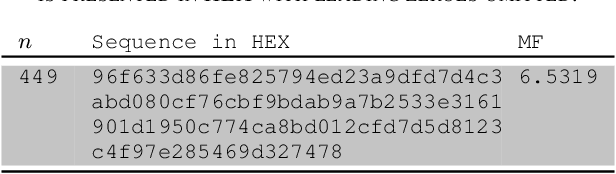
The merit factor problem is of practical importance to manifold domains, such as digital communications engineering, radars, system modulation, system testing, information theory, physics, chemistry. However, the merit factor problem is referenced as one of the most difficult optimization problems and it was further conjectured that stochastic search procedures will not yield merit factors higher than 5 for long binary sequences (sequences with lengths greater than 200). Some useful mathematical properties related to the flip operation of the skew-symmetric binary sequences are presented in this work. By exploiting those properties, the memory complexity of state-of-the-art stochastic merit factor optimization algorithms could be reduced from $O(n^2)$ to $O(n)$. As a proof of concept, a lightweight stochastic algorithm was constructed, which can optimize pseudo-randomly generated skew-symmetric binary sequences with long lengths (up to ${10}^5+1$) to skew-symmetric binary sequences with a merit factor greater than 5. An approximation of the required time is also provided. The numerical experiments suggest that the algorithm is universal and could be applied to skew-symmetric binary sequences with arbitrary lengths.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020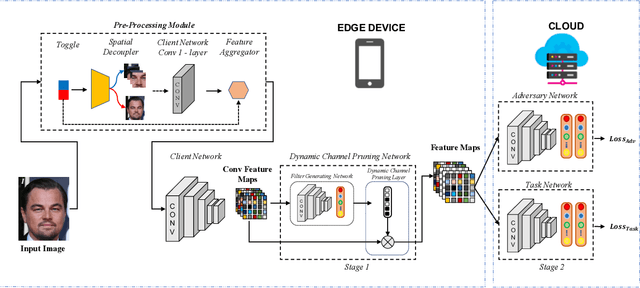
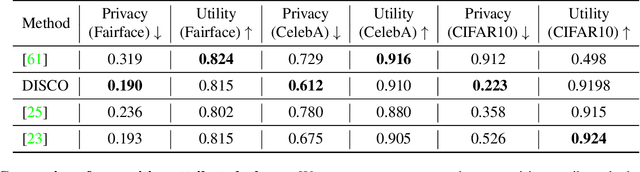

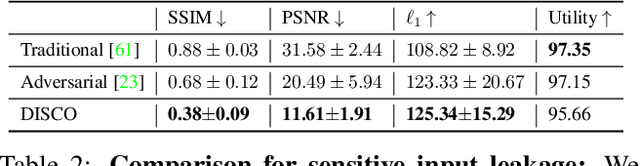
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Learning Signal Representations for EEG Cross-Subject Channel Selection and Trial Classification
Jun 20, 2021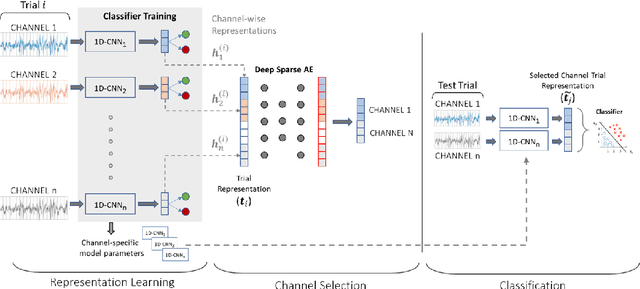
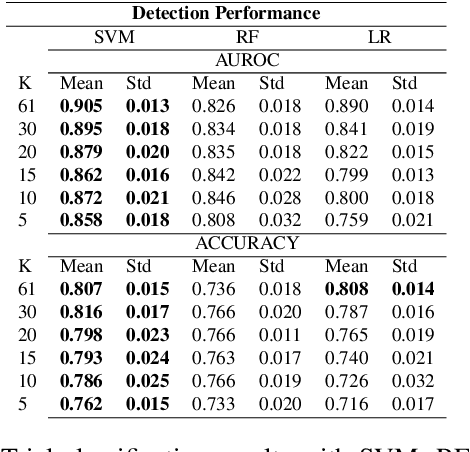
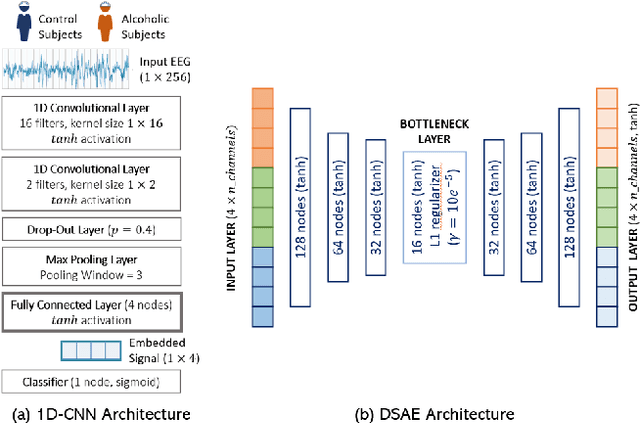
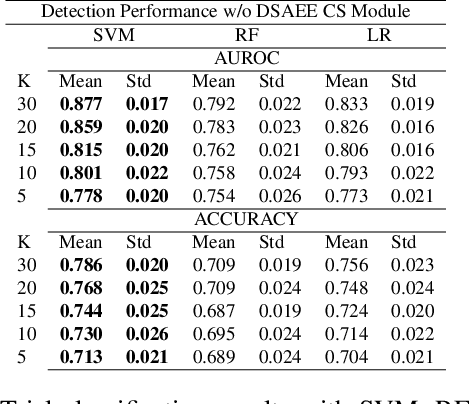
EEG technology finds applications in several domains. Currently, most EEG systems require subjects to wear several electrodes on the scalp to be effective. However, several channels might include noisy information, redundant signals, induce longer preparation times and increase computational times of any automated system for EEG decoding. One way to reduce the signal-to-noise ratio and improve classification accuracy is to combine channel selection with feature extraction, but EEG signals are known to present high inter-subject variability. In this work we introduce a novel algorithm for subject-independent channel selection of EEG recordings. Considering multi-channel trial recordings as statistical units and the EEG decoding task as the class of reference, the algorithm (i) exploits channel-specific 1D-Convolutional Neural Networks (1D-CNNs) as feature extractors in a supervised fashion to maximize class separability; (ii) it reduces a high dimensional multi-channel trial representation into a unique trial vector by concatenating the channels' embeddings and (iii) recovers the complex inter-channel relationships during channel selection, by exploiting an ensemble of AutoEncoders (AE) to identify from these vectors the most relevant channels to perform classification. After training, the algorithm can be exploited by transferring only the parametrized subgroup of selected channel-specific 1D-CNNs to new signals from new subjects and obtain low-dimensional and highly informative trial vectors to be fed to any classifier.
GOO: A Dataset for Gaze Object Prediction in Retail Environments
May 22, 2021
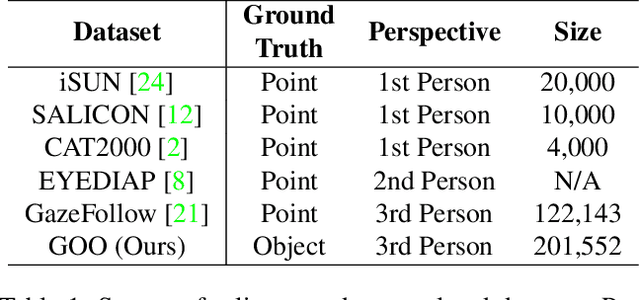
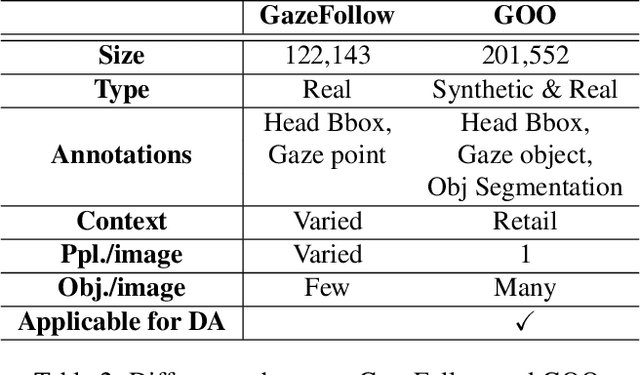

One of the most fundamental and information-laden actions humans do is to look at objects. However, a survey of current works reveals that existing gaze-related datasets annotate only the pixel being looked at, and not the boundaries of a specific object of interest. This lack of object annotation presents an opportunity for further advancing gaze estimation research. To this end, we present a challenging new task called gaze object prediction, where the goal is to predict a bounding box for a person's gazed-at object. To train and evaluate gaze networks on this task, we present the Gaze On Objects (GOO) dataset. GOO is composed of a large set of synthetic images (GOO Synth) supplemented by a smaller subset of real images (GOO-Real) of people looking at objects in a retail environment. Our work establishes extensive baselines on GOO by re-implementing and evaluating selected state-of-the art models on the task of gaze following and domain adaptation. Code is available on github.