 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multivariate Information Bottleneck
Jan 10, 2013
The Information bottleneck method is an unsupervised non-parametric data organization technique. Given a joint distribution P(A,B), this method constructs a new variable T that extracts partitions, or clusters, over the values of A that are informative about B. The information bottleneck has already been applied to document classification, gene expression, neural code, and spectral analysis. In this paper, we introduce a general principled framework for multivariate extensions of the information bottleneck method. This allows us to consider multiple systems of data partitions that are inter-related. Our approach utilizes Bayesian networks for specifying the systems of clusters and what information each captures. We show that this construction provides insight about bottleneck variations and enables us to characterize solutions of these variations. We also present a general framework for iterative algorithms for constructing solutions, and apply it to several examples.
DimRad: A Radar-Based Perception System for Prosthetic Leg Barrier Traversing
May 30, 2021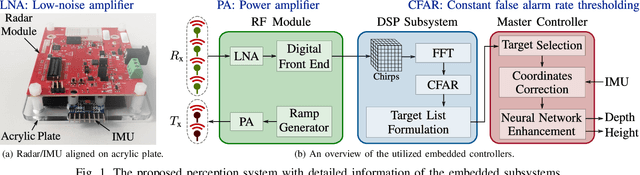
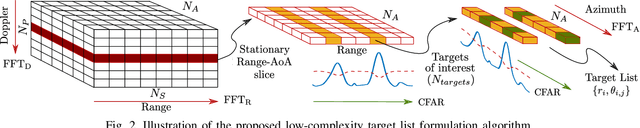
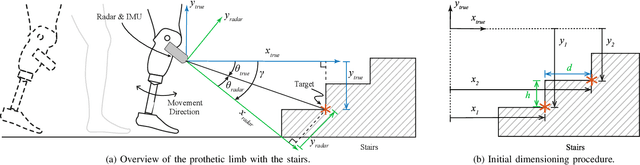
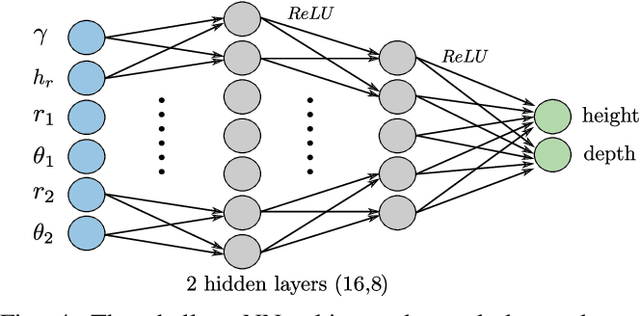
Lower extremity amputees face challenges in natural locomotion, which is partially compensated using powered assistive systems, e.g., micro-processor controlled prosthetic leg. In this paper, a radar-based perception system is proposed to assist prosthetic legs for autonomous obstacle traversing, focusing on multiple-step staircases. The presented perception system is composed of a radar module operating with a multiple-input-multiple-output (MIMO) configuration to localize consecutive stair corners. An inertial measurement unit (IMU) is integrated for coordinates correction due to the angular dis-positioning that occurs because of the knee angular motion. The captured information from both sensors is used for staircase dimensioning (depth and height). A shallow neural network (NN) is proposed to model the error due to the hardware limitations and enhance the dimension estimation accuracy (1 cm). The algorithm is implemented on a microcontroller subsystem of the radar kit to qualify the perception system for embedded integration in powered prosthetic legs.
Zero-sample surface defect detection and classification based on semantic feedback neural network
Jun 15, 2021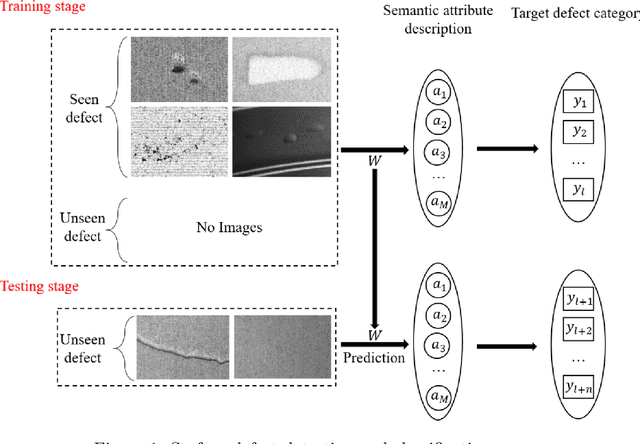



Defect detection and classification technology has changed from traditional artificial visual inspection to current intelligent automated inspection, but most of the current defect detection methods are training related detection models based on a data-driven approach, taking into account the difficulty of collecting some sample data in the industrial field. We apply zero-shot learning technology to the industrial field. Aiming at the problem of the existing "Latent Feature Guide Attribute Attention" (LFGAA) zero-shot image classification network, the output latent attributes and artificially defined attributes are different in the semantic space, which leads to the problem of model performance degradation, proposed an LGFAA network based on semantic feedback, and improved model performance by constructing semantic embedded modules and feedback mechanisms. At the same time, for the common domain shift problem in zero-shot learning, based on the idea of co-training algorithm using the difference information between different views of data to learn from each other, we propose an Ensemble Co-training algorithm, which adaptively reduces the prediction error in image tag embedding from multiple angles. Various experiments conducted on the zero-shot dataset and the cylinder liner dataset in the industrial field provide competitive results.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021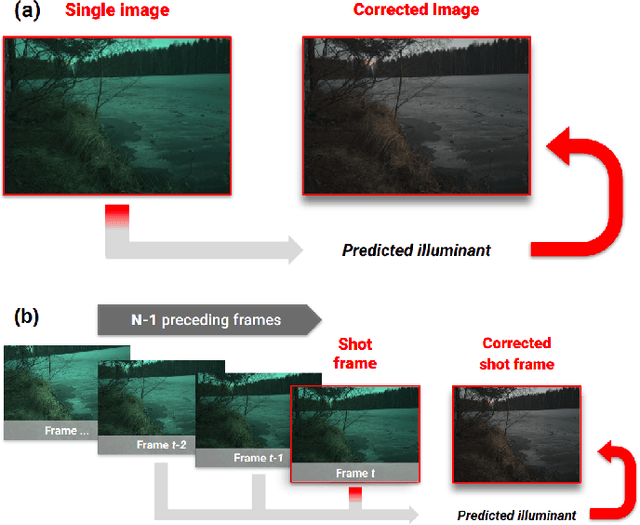
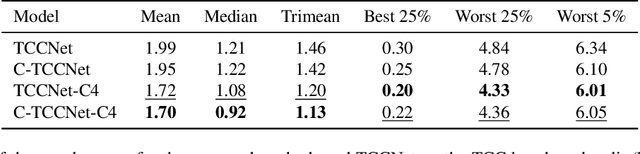
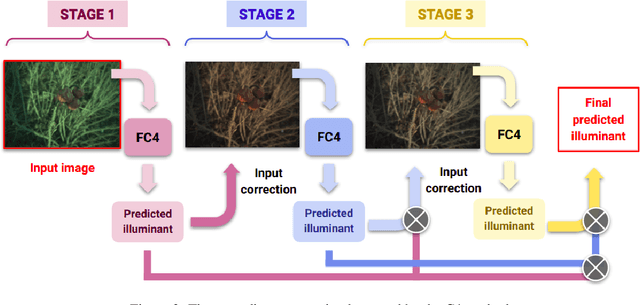
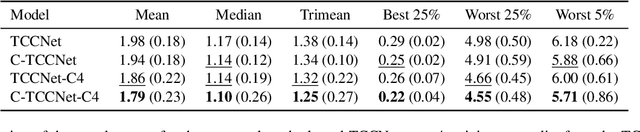
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.
Deep Co-Attention Network for Multi-View Subspace Learning
Feb 15, 2021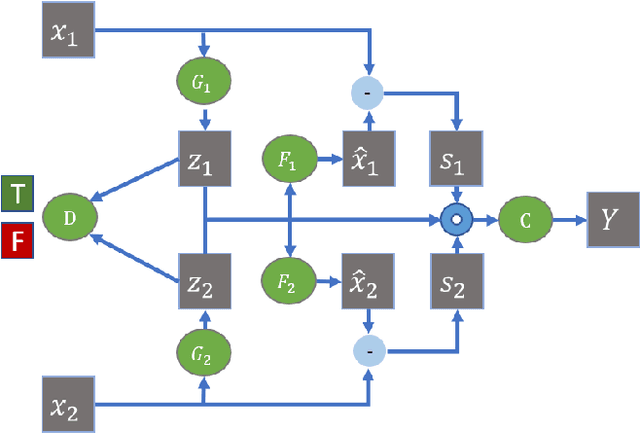
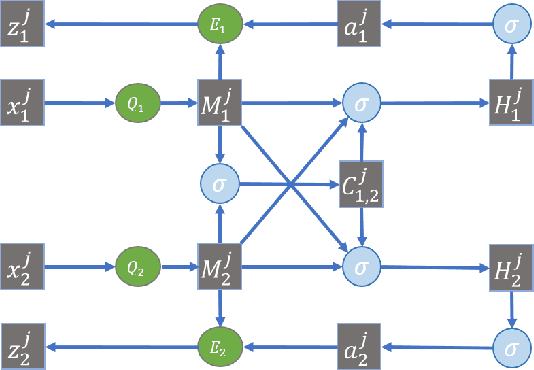
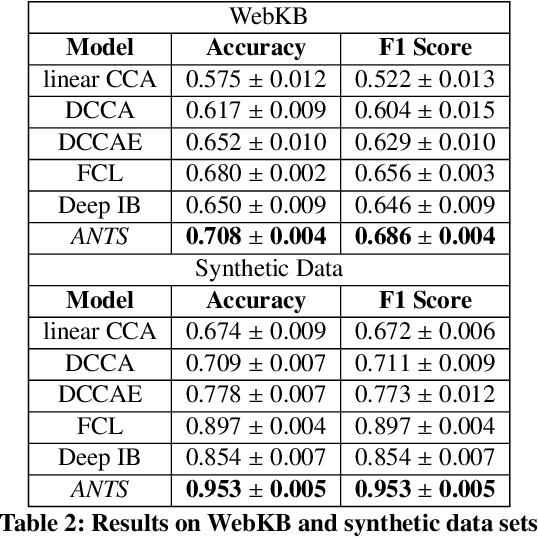
Many real-world applications involve data from multiple modalities and thus exhibit the view heterogeneity. For example, user modeling on social media might leverage both the topology of the underlying social network and the content of the users' posts; in the medical domain, multiple views could be X-ray images taken at different poses. To date, various techniques have been proposed to achieve promising results, such as canonical correlation analysis based methods, etc. In the meanwhile, it is critical for decision-makers to be able to understand the prediction results from these methods. For example, given the diagnostic result that a model provided based on the X-ray images of a patient at different poses, the doctor needs to know why the model made such a prediction. However, state-of-the-art techniques usually suffer from the inability to utilize the complementary information of each view and to explain the predictions in an interpretable manner. To address these issues, in this paper, we propose a deep co-attention network for multi-view subspace learning, which aims to extract both the common information and the complementary information in an adversarial setting and provide robust interpretations behind the prediction to the end-users via the co-attention mechanism. In particular, it uses a novel cross reconstruction loss and leverages the label information to guide the construction of the latent representation by incorporating the classifier into our model. This improves the quality of latent representation and accelerates the convergence speed. Finally, we develop an efficient iterative algorithm to find the optimal encoders and discriminator, which are evaluated extensively on synthetic and real-world data sets. We also conduct a case study to demonstrate how the proposed method robustly interprets the predictions on an image data set.
Where to look at the movies : Analyzing visual attention to understand movie editing
Feb 26, 2021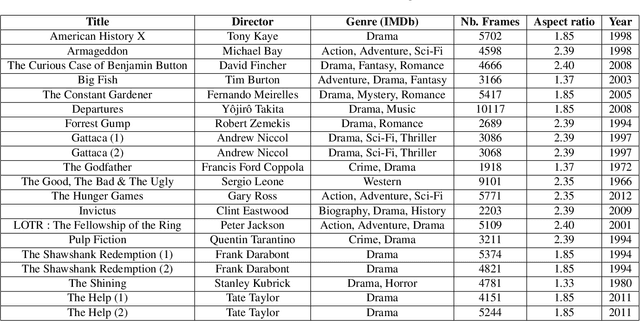
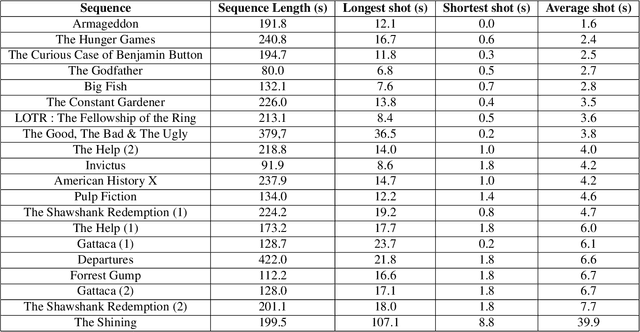


In the process of making a movie, directors constantly care about where the spectator will look on the screen. Shot composition, framing, camera movements or editing are tools commonly used to direct attention. In order to provide a quantitative analysis of the relationship between those tools and gaze patterns, we propose a new eye-tracking database, containing gaze pattern information on movie sequences, as well as editing annotations, and we show how state-of-the-art computational saliency techniques behave on this dataset. In this work, we expose strong links between movie editing and spectators scanpaths, and open several leads on how the knowledge of editing information could improve human visual attention modeling for cinematic content. The dataset generated and analysed during the current study is available at https://github.com/abruckert/eye_tracking_filmmaking
Hybrid Machine Learning Forecasts for the UEFA EURO 2020
Jun 07, 2021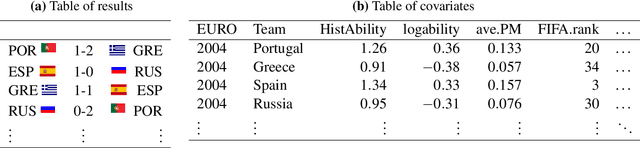
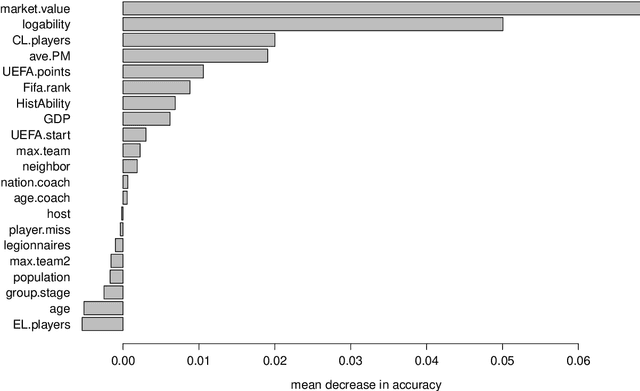
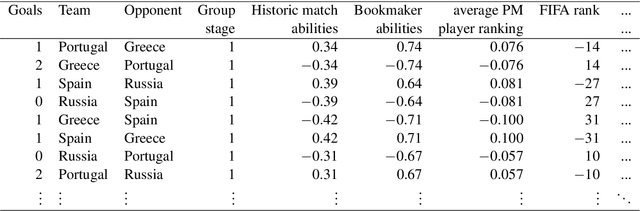
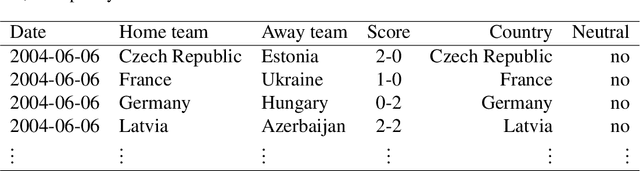
Three state-of-the-art statistical ranking methods for forecasting football matches are combined with several other predictors in a hybrid machine learning model. Namely an ability estimate for every team based on historic matches; an ability estimate for every team based on bookmaker consensus; average plus-minus player ratings based on their individual performances in their home clubs and national teams; and further team covariates (e.g., market value, team structure) and country-specific socio-economic factors (population, GDP). The proposed combined approach is used for learning the number of goals scored in the matches from the four previous UEFA EUROs 2004-2016 and then applied to current information to forecast the upcoming UEFA EURO 2020. Based on the resulting estimates, the tournament is simulated repeatedly and winning probabilities are obtained for all teams. A random forest model favors the current World Champion France with a winning probability of 14.8% before England (13.5%) and Spain (12.3%). Additionally, we provide survival probabilities for all teams and at all tournament stages.
Augmented Tensor Decomposition with Stochastic Optimization
Jun 15, 2021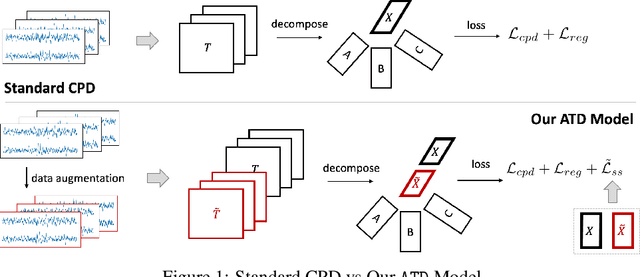

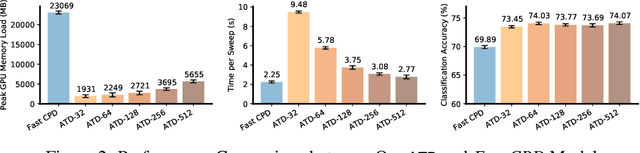
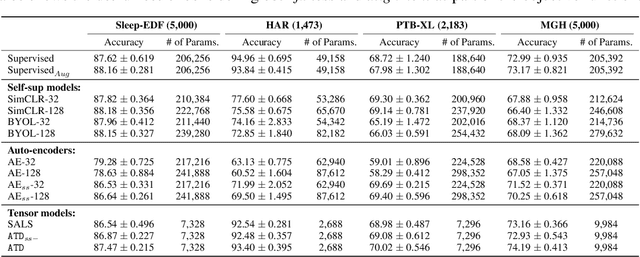
Tensor decompositions are powerful tools for dimensionality reduction and feature interpretation of multidimensional data such as signals. Existing tensor decomposition objectives (e.g., Frobenius norm) are designed for fitting raw data under statistical assumptions, which may not align with downstream classification tasks. Also, real-world tensor data are usually high-ordered and have large dimensions with millions or billions of entries. Thus, it is expensive to decompose the whole tensor with traditional algorithms. In practice, raw tensor data also contains redundant information while data augmentation techniques may be used to smooth out noise in samples. This paper addresses the above challenges by proposing augmented tensor decomposition (ATD), which effectively incorporates data augmentations to boost downstream classification. To reduce the memory footprint of the decomposition, we propose a stochastic algorithm that updates the factor matrices in a batch fashion. We evaluate ATD on multiple signal datasets. It shows comparable or better performance (e.g., up to 15% in accuracy) over self-supervised and autoencoder baselines with less than 5% of model parameters, achieves 0.6% ~ 1.3% accuracy gain over other tensor-based baselines, and reduces the memory footprint by 9X when compared to standard tensor decomposition algorithms.
Neural Abstractive Unsupervised Summarization of Online News Discussions
Jun 07, 2021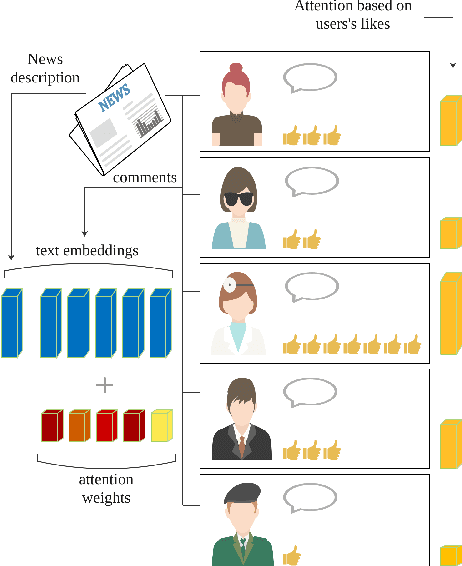
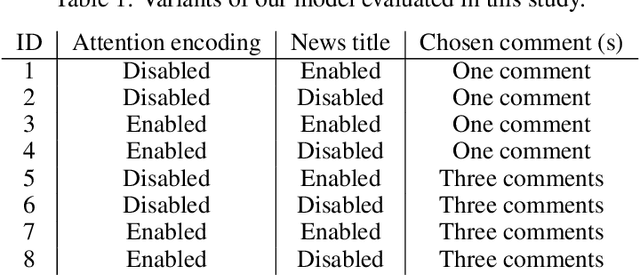
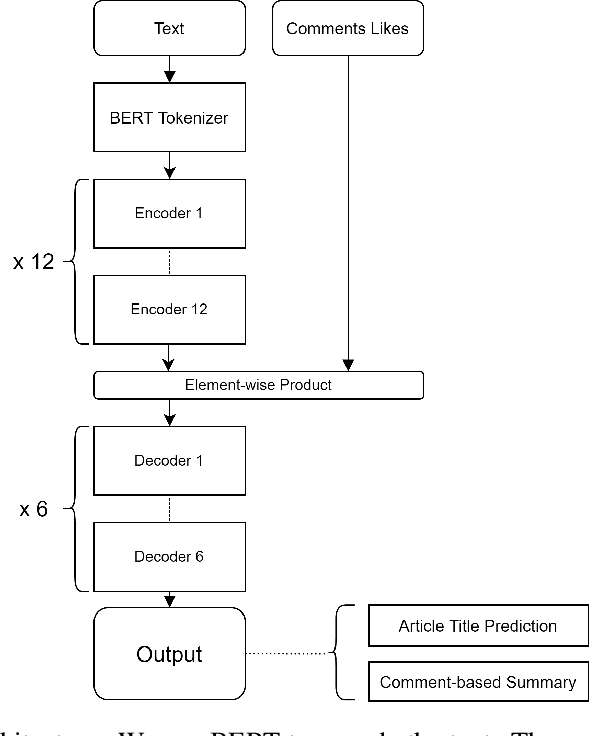
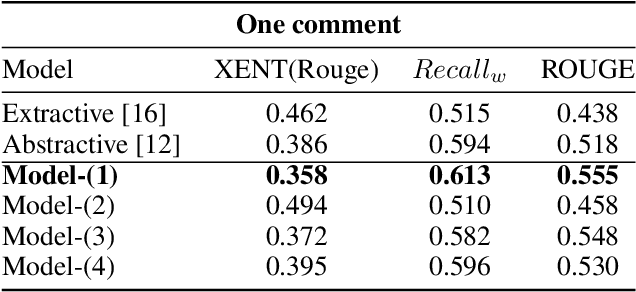
Summarization has usually relied on gold standard summaries to train extractive or abstractive models. Social media brings a hurdle to summarization techniques since it requires addressing a multi-document multi-author approach. We address this challenging task by introducing a novel method that generates abstractive summaries of online news discussions. Our method extends a BERT-based architecture, including an attention encoding that fed comments' likes during the training stage. To train our model, we define a task which consists of reconstructing high impact comments based on popularity (likes). Accordingly, our model learns to summarize online discussions based on their most relevant comments. Our novel approach provides a summary that represents the most relevant aspects of a news item that users comment on, incorporating the social context as a source of information to summarize texts in online social networks. Our model is evaluated using ROUGE scores between the generated summary and each comment on the thread. Our model, including the social attention encoding, significantly outperforms both extractive and abstractive summarization methods based on such evaluation.
Do language models learn typicality judgments from text?
May 06, 2021
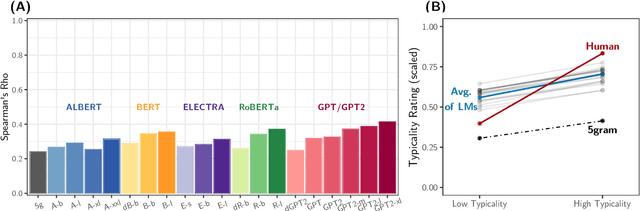

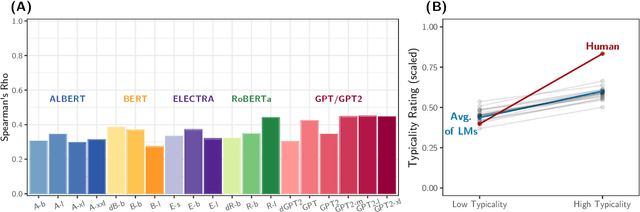
Building on research arguing for the possibility of conceptual and categorical knowledge acquisition through statistics contained in language, we evaluate predictive language models (LMs) -- informed solely by textual input -- on a prevalent phenomenon in cognitive science: typicality. Inspired by experiments that involve language processing and show robust typicality effects in humans, we propose two tests for LMs. Our first test targets whether typicality modulates LM probabilities in assigning taxonomic category memberships to items. The second test investigates sensitivities to typicality in LMs' probabilities when extending new information about items to their categories. Both tests show modest -- but not completely absent -- correspondence between LMs and humans, suggesting that text-based exposure alone is insufficient to acquire typicality knowledge.