 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Affect-driven Engagement Measurement from Videos
Jun 21, 2021
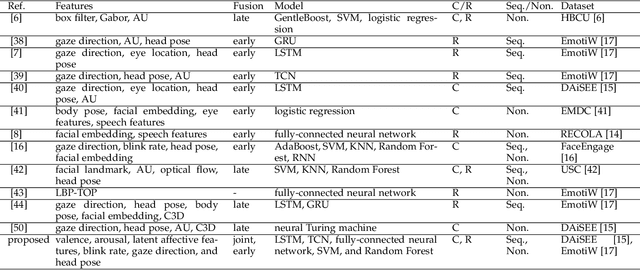
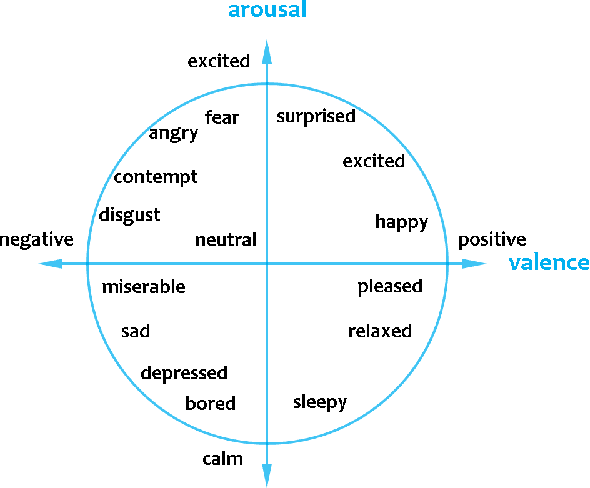
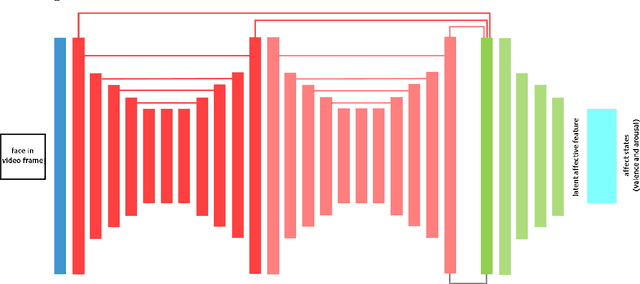
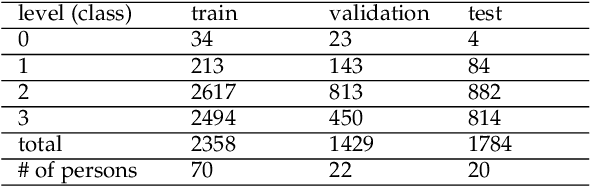
In education and intervention programs, person's engagement has been identified as a major factor in successful program completion. Automatic measurement of person's engagement provides useful information for instructors to meet program objectives and individualize program delivery. In this paper, we present a novel approach for video-based engagement measurement in virtual learning programs. We propose to use affect states, continuous values of valence and arousal extracted from consecutive video frames, along with a new latent affective feature vector and behavioral features for engagement measurement. Deep learning-based temporal, and traditional machine-learning-based non-temporal models are trained and validated on frame-level, and video-level features, respectively. In addition to the conventional centralized learning, we also implement the proposed method in a decentralized federated learning setting and study the effect of model personalization in engagement measurement. We evaluated the performance of the proposed method on the only two publicly available video engagement measurement datasets, DAiSEE and EmotiW, containing videos of students in online learning programs. Our experiments show a state-of-the-art engagement level classification accuracy of 63.3% and correctly classifying disengagement videos in the DAiSEE dataset and a regression mean squared error of 0.0673 on the EmotiW dataset. Our ablation study shows the effectiveness of incorporating affect states in engagement measurement. We interpret the findings from the experimental results based on psychology concepts in the field of engagement.
Human De-occlusion: Invisible Perception and Recovery for Humans
Mar 22, 2021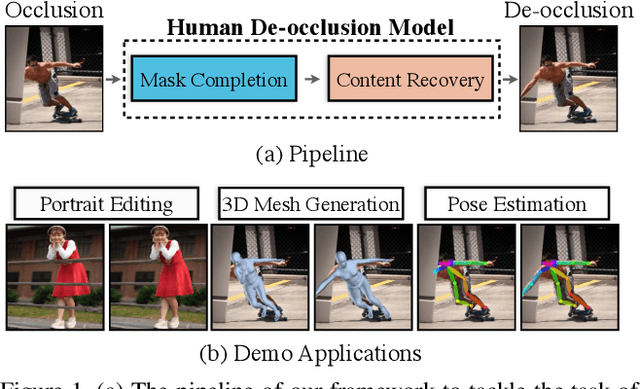
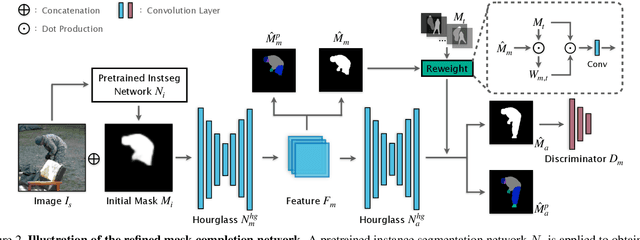
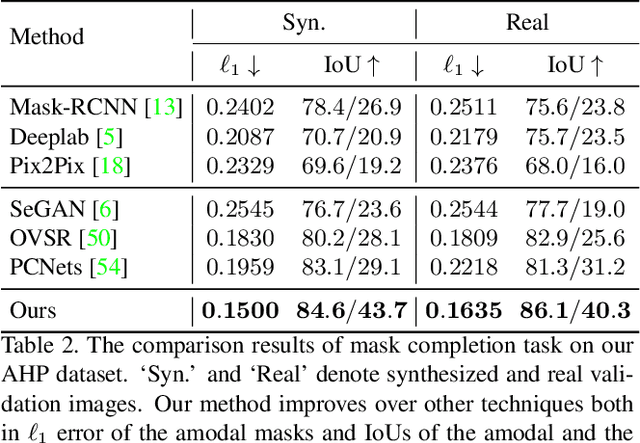
In this paper, we tackle the problem of human de-occlusion which reasons about occluded segmentation masks and invisible appearance content of humans. In particular, a two-stage framework is proposed to estimate the invisible portions and recover the content inside. For the stage of mask completion, a stacked network structure is devised to refine inaccurate masks from a general instance segmentation model and predict integrated masks simultaneously. Additionally, the guidance from human parsing and typical pose masks are leveraged to bring prior information. For the stage of content recovery, a novel parsing guided attention module is applied to isolate body parts and capture context information across multiple scales. Besides, an Amodal Human Perception dataset (AHP) is collected to settle the task of human de-occlusion. AHP has advantages of providing annotations from real-world scenes and the number of humans is comparatively larger than other amodal perception datasets. Based on this dataset, experiments demonstrate that our method performs over the state-of-the-art techniques in both tasks of mask completion and content recovery. Our AHP dataset is available at \url{https://sydney0zq.github.io/ahp/}.
Conditional Deep Inverse Rosenblatt Transports
Jun 08, 2021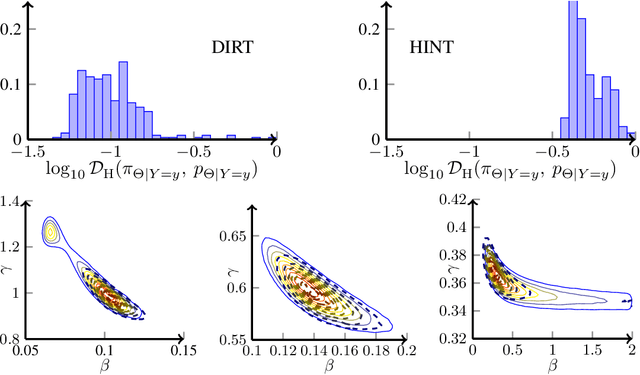
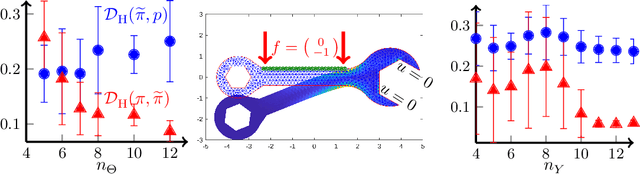
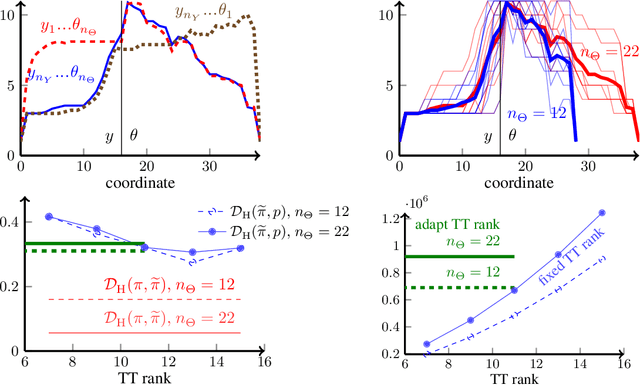
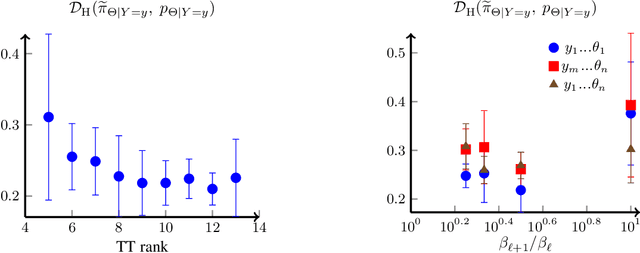
We present a novel offline-online method to mitigate the computational burden of the characterization of conditional beliefs in statistical learning. In the offline phase, the proposed method learns the joint law of the belief random variables and the observational random variables in the tensor-train (TT) format. In the online phase, it utilizes the resulting order-preserving conditional transport map to issue real-time characterization of the conditional beliefs given new observed information. Compared with the state-of-the-art normalizing flows techniques, the proposed method relies on function approximation and is equipped with thorough performance analysis. This also allows us to further extend the capability of transport maps in challenging problems with high-dimensional observations and high-dimensional belief variables. On the one hand, we present novel heuristics to reorder and/or reparametrize the variables to enhance the approximation power of TT. On the other, we integrate the TT-based transport maps and the parameter reordering/reparametrization into layered compositions to further improve the performance of the resulting transport maps. We demonstrate the efficiency of the proposed method on various statistical learning tasks in ordinary differential equations (ODEs) and partial differential equations (PDEs).
GAHNE: Graph-Aggregated Heterogeneous Network Embedding
Dec 23, 2020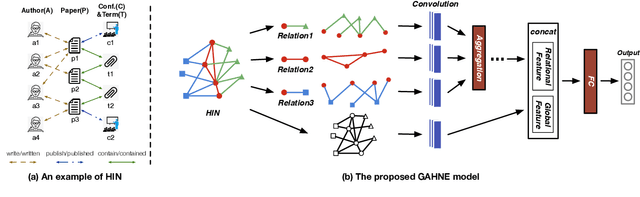

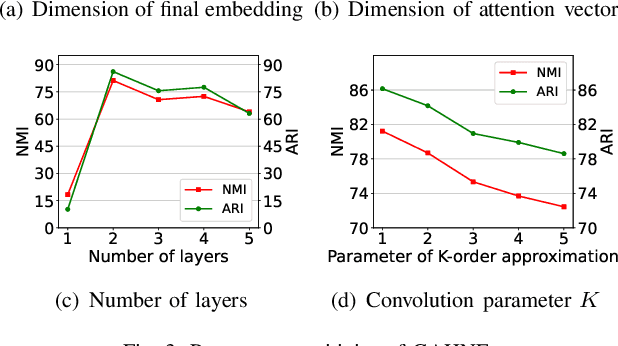
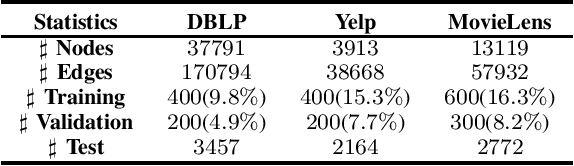
The real-world networks often compose of different types of nodes and edges with rich semantics, widely known as heterogeneous information network (HIN). Heterogeneous network embedding aims to embed nodes into low-dimensional vectors which capture rich intrinsic information of heterogeneous networks. However, existing models either depend on manually designing meta-paths, ignore mutual effects between different semantics, or omit some aspects of information from global networks. To address these limitations, we propose a novel Graph-Aggregated Heterogeneous Network Embedding (GAHNE), which is designed to extract the semantics of HINs as comprehensively as possible to improve the results of downstream tasks based on graph convolutional neural networks. In GAHNE model, we develop several mechanisms that can aggregate semantic representations from different single-type sub-networks as well as fuse the global information into final embeddings. Extensive experiments on three real-world HIN datasets show that our proposed model consistently outperforms the existing state-of-the-art methods.
EmpathBERT: A BERT-based Framework for Demographic-aware Empathy Prediction
Jan 30, 2021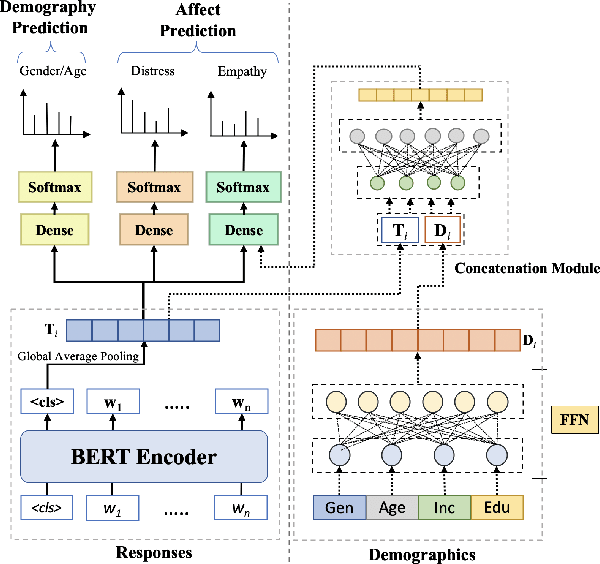

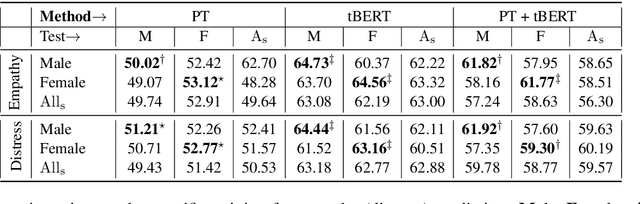
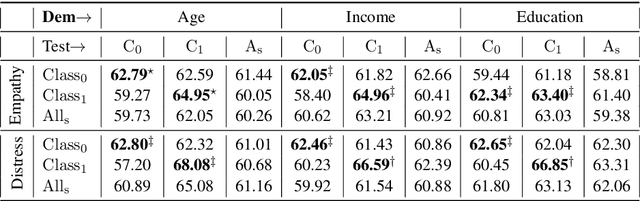
Affect preferences vary with user demographics, and tapping into demographic information provides important cues about the users' language preferences. In this paper, we utilize the user demographics, and propose EmpathBERT, a demographic-aware framework for empathy prediction based on BERT. Through several comparative experiments, we show that EmpathBERT surpasses traditional machine learning and deep learning models, and illustrate the importance of user demographics to predict empathy and distress in user responses to stimulative news articles. We also highlight the importance of affect information in the responses by developing affect-aware models to predict user demographic attributes.
Massive Wireless Energy Transfer with Statistical CSI Beamforming
Jul 11, 2021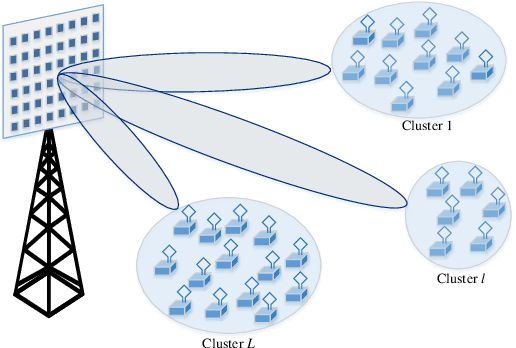
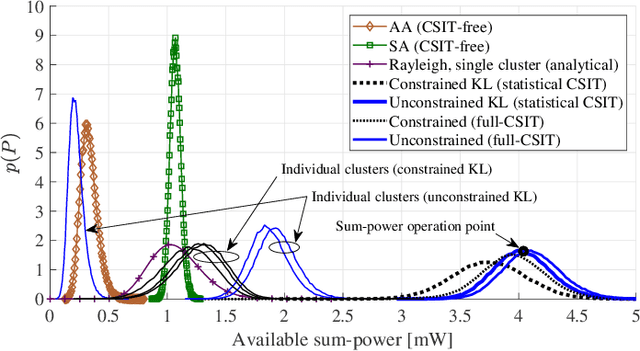
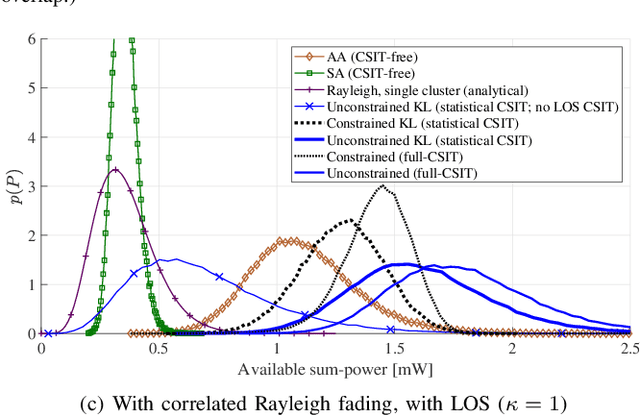
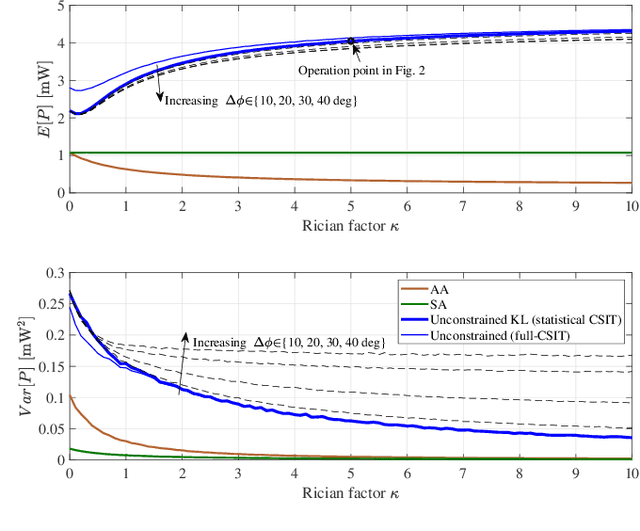
Wireless energy transfer (WET) is a promising solution to enable massive machine-type communications (mMTC) with low-complexity and low-powered wireless devices. Given the energy restrictions of the devices, instant channel state information at the transmitter (CSIT) is not expected to be available in practical WET-enabled mMTC. However, because it is common that the terminals appear spatially clustered, some degree of spatial correlation between their channels to the base station (BS) is expected to occur. The paper considers a massive antenna array at the BS for WET that only has access to i) the first and second order statistics of the Rician channel component of the multiple-input multiple-output (MIMO) channel and also to ii) the line-of-sight MIMO component. The optimal precoding scheme that maximizes the total energy available to the single-antenna devices is derived considering a continuous alphabet for the precoders, permitting any modulated or deterministic waveform. This may lead to some devices in the clusters being assigned a low fraction of the total available power in the cluster, creating a rather uneven situation among them. Consequently, a fairness criterion is introduced, imposing a minimum amount of power allocated to the terminals. A piece-wise linear harvesting circuit is considered at the terminals, with both saturation and a minimum sensitivity, and a constrained version of the precoder is also proposed by solving a non-linear programming problem. A paramount benefit of the constrained precoder is the encompassment of fairness in the power allocation to the different clusters. Moreover, given the polynomial complexity increase of the proposed unconstrained precoder, and the observed linear gain of the system's available sum-power with an increasing number of antennas at the ULA, the use of massive antenna arrays is desirable.
3D Object Detection for Autonomous Driving: A Survey
Jun 21, 2021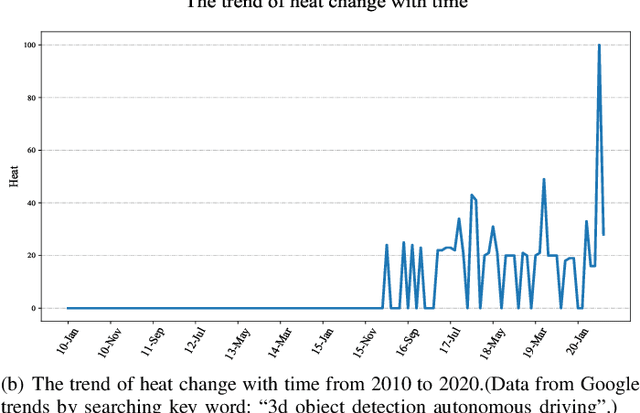
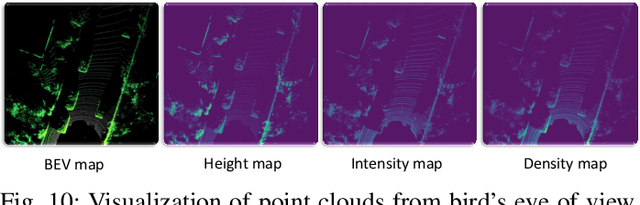
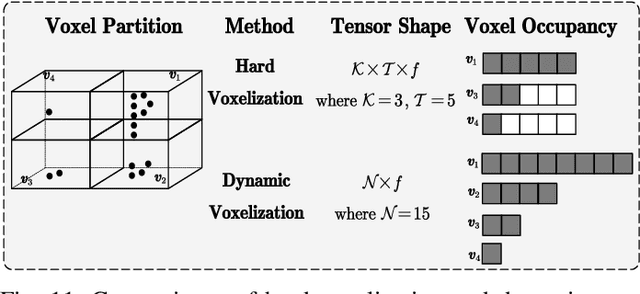
Autonomous driving is regarded as one of the most promising remedies to shield human beings from severe crashes. To this end, 3D object detection serves as the core basis of such perception system especially for the sake of path planning, motion prediction, collision avoidance, etc. Generally, stereo or monocular images with corresponding 3D point clouds are already standard layout for 3D object detection, out of which point clouds are increasingly prevalent with accurate depth information being provided. Despite existing efforts, 3D object detection on point clouds is still in its infancy due to high sparseness and irregularity of point clouds by nature, misalignment view between camera view and LiDAR bird's eye of view for modality synergies, occlusions and scale variations at long distances, etc. Recently, profound progress has been made in 3D object detection, with a large body of literature being investigated to address this vision task. As such, we present a comprehensive review of the latest progress in this field covering all the main topics including sensors, fundamentals, and the recent state-of-the-art detection methods with their pros and cons. Furthermore, we introduce metrics and provide quantitative comparisons on popular public datasets. The avenues for future work are going to be judiciously identified after an in-deep analysis of the surveyed works. Finally, we conclude this paper.
Text Compression-aided Transformer Encoding
Feb 11, 2021
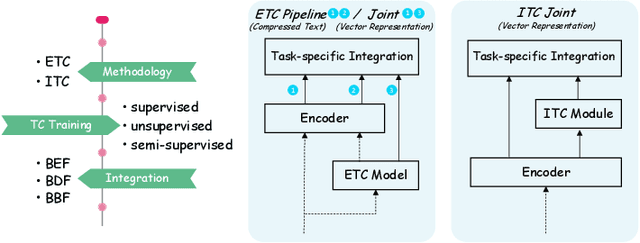
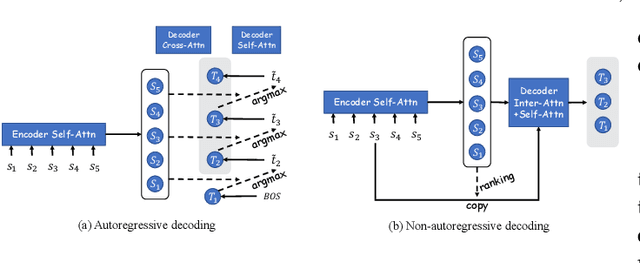
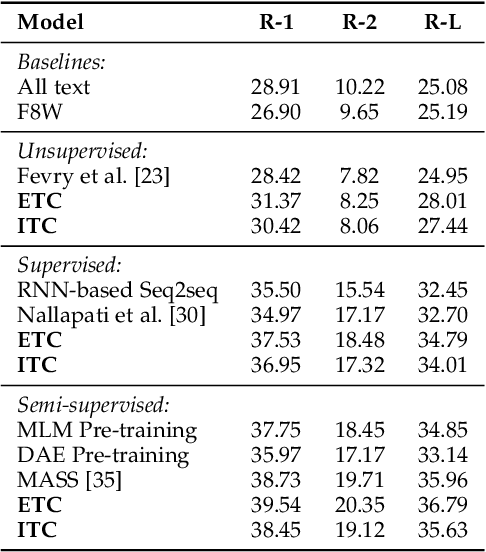
Text encoding is one of the most important steps in Natural Language Processing (NLP). It has been done well by the self-attention mechanism in the current state-of-the-art Transformer encoder, which has brought about significant improvements in the performance of many NLP tasks. Though the Transformer encoder may effectively capture general information in its resulting representations, the backbone information, meaning the gist of the input text, is not specifically focused on. In this paper, we propose explicit and implicit text compression approaches to enhance the Transformer encoding and evaluate models using this approach on several typical downstream tasks that rely on the encoding heavily. Our explicit text compression approaches use dedicated models to compress text, while our implicit text compression approach simply adds an additional module to the main model to handle text compression. We propose three ways of integration, namely backbone source-side fusion, target-side fusion, and both-side fusion, to integrate the backbone information into Transformer-based models for various downstream tasks. Our evaluation on benchmark datasets shows that the proposed explicit and implicit text compression approaches improve results in comparison to strong baselines. We therefore conclude, when comparing the encodings to the baseline models, text compression helps the encoders to learn better language representations.
View-Guided Point Cloud Completion
Apr 12, 2021
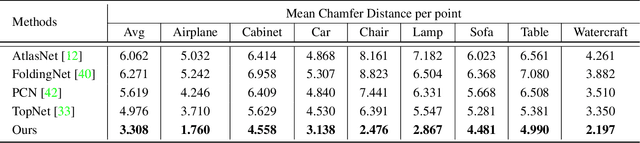
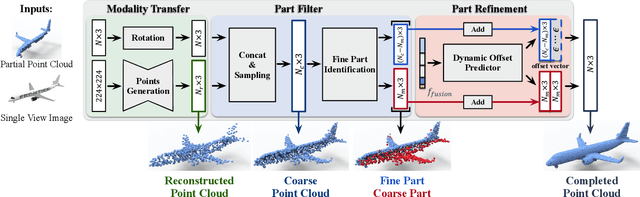
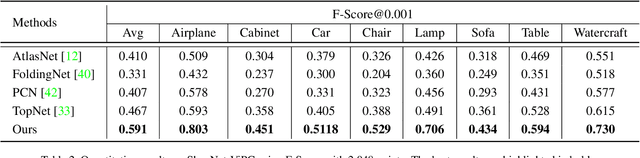
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
Learning to Predict Salient Faces: A Novel Visual-Audio Saliency Model
Mar 29, 2021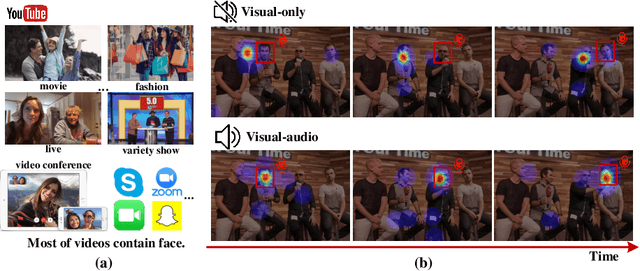
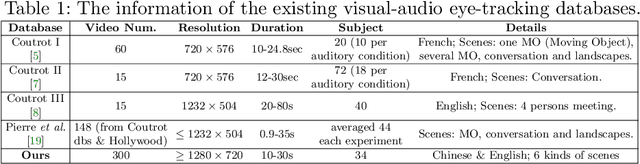
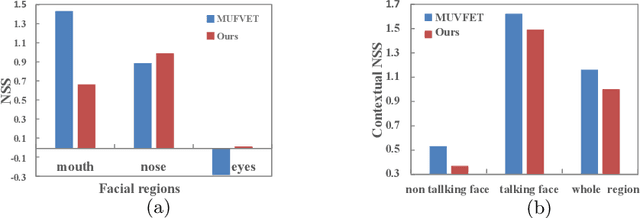
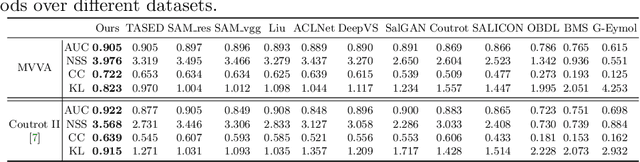
Recently, video streams have occupied a large proportion of Internet traffic, most of which contain human faces. Hence, it is necessary to predict saliency on multiple-face videos, which can provide attention cues for many content based applications. However, most of multiple-face saliency prediction works only consider visual information and ignore audio, which is not consistent with the naturalistic scenarios. Several behavioral studies have established that sound influences human attention, especially during the speech turn-taking in multiple-face videos. In this paper, we thoroughly investigate such influences by establishing a large-scale eye-tracking database of Multiple-face Video in Visual-Audio condition (MVVA). Inspired by the findings of our investigation, we propose a novel multi-modal video saliency model consisting of three branches: visual, audio and face. The visual branch takes the RGB frames as the input and encodes them into visual feature maps. The audio and face branches encode the audio signal and multiple cropped faces, respectively. A fusion module is introduced to integrate the information from three modalities, and to generate the final saliency map. Experimental results show that the proposed method outperforms 11 state-of-the-art saliency prediction works. It performs closer to human multi-modal attention.