 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Phase Transition Adaptation
Apr 20, 2021
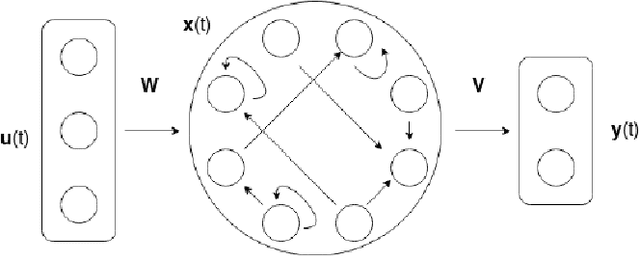
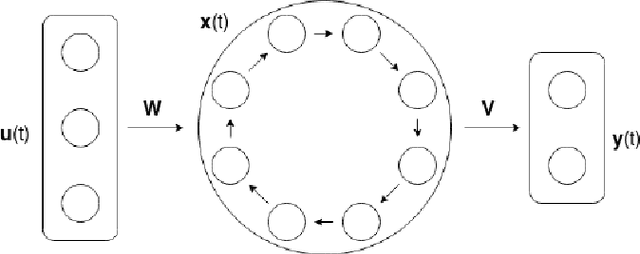
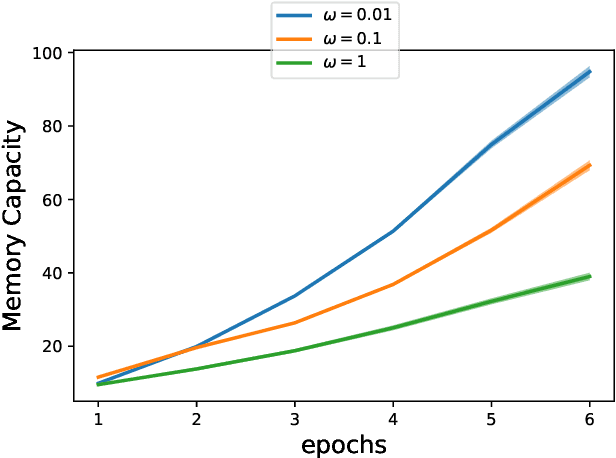

Artificial Recurrent Neural Networks are a powerful information processing abstraction, and Reservoir Computing provides an efficient strategy to build robust implementations by projecting external inputs into high dimensional dynamical system trajectories. In this paper, we propose an extension of the original approach, a local unsupervised learning mechanism we call Phase Transition Adaptation, designed to drive the system dynamics towards the `edge of stability'. Here, the complex behavior exhibited by the system elicits an enhancement in its overall computational capacity. We show experimentally that our approach consistently achieves its purpose over several datasets.
Chow-Liu++: Optimal Prediction-Centric Learning of Tree Ising Models
Jun 16, 2021
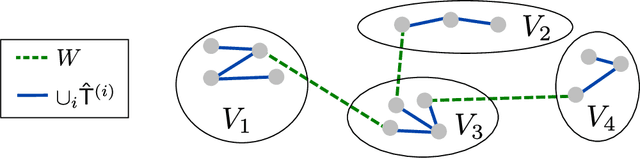
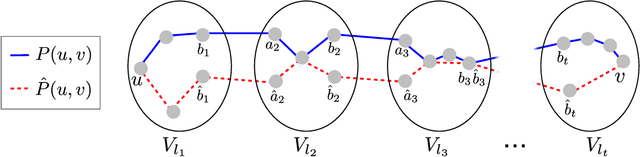
We consider the problem of learning a tree-structured Ising model from data, such that subsequent predictions computed using the model are accurate. Concretely, we aim to learn a model such that posteriors $P(X_i|X_S)$ for small sets of variables $S$ are accurate. Since its introduction more than 50 years ago, the Chow-Liu algorithm, which efficiently computes the maximum likelihood tree, has been the benchmark algorithm for learning tree-structured graphical models. A bound on the sample complexity of the Chow-Liu algorithm with respect to the prediction-centric local total variation loss was shown in [BK19]. While those results demonstrated that it is possible to learn a useful model even when recovering the true underlying graph is impossible, their bound depends on the maximum strength of interactions and thus does not achieve the information-theoretic optimum. In this paper, we introduce a new algorithm that carefully combines elements of the Chow-Liu algorithm with tree metric reconstruction methods to efficiently and optimally learn tree Ising models under a prediction-centric loss. Our algorithm is robust to model misspecification and adversarial corruptions. In contrast, we show that the celebrated Chow-Liu algorithm can be arbitrarily suboptimal.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021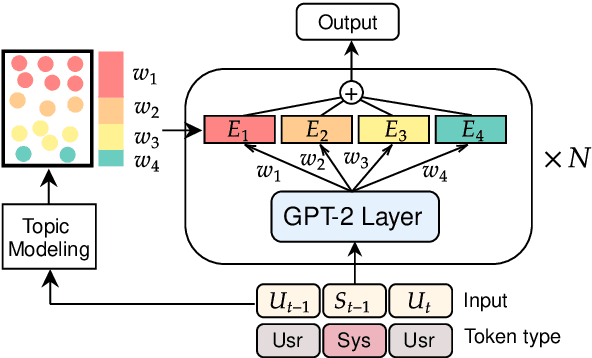
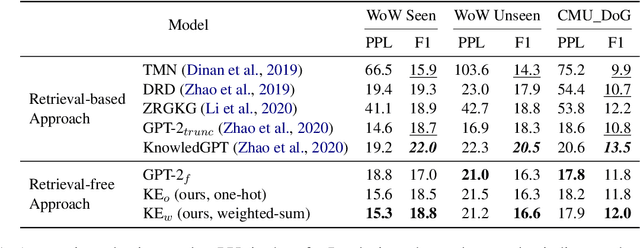
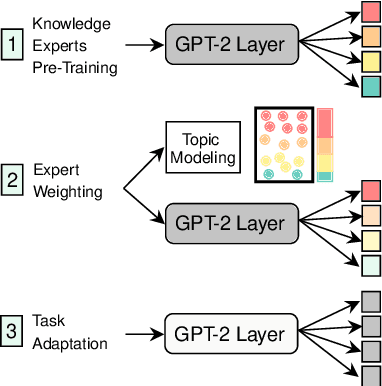

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Multiband VAE: Latent Space Partitioning for Knowledge Consolidation in Continual Learning
Jun 23, 2021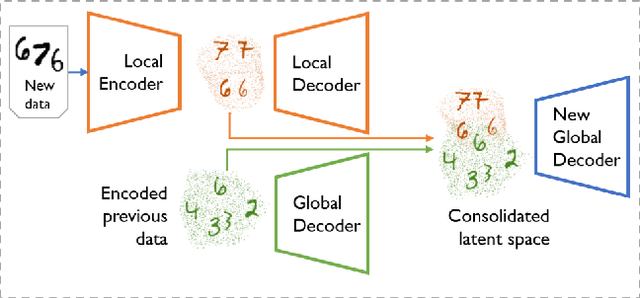
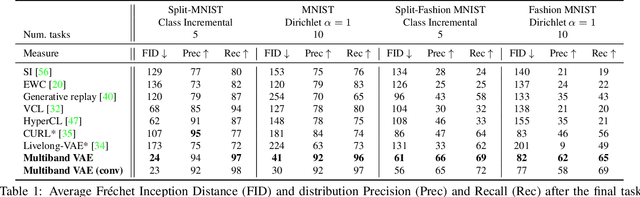
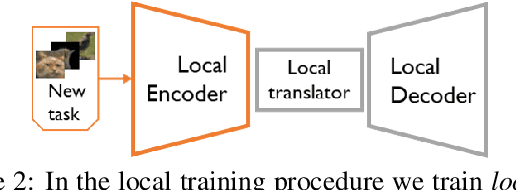
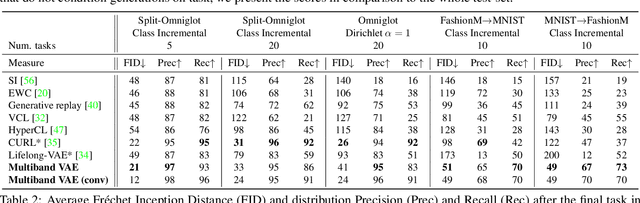
We propose a new method for unsupervised continual knowledge consolidation in generative models that relies on the partitioning of Variational Autoencoder's latent space. Acquiring knowledge about new data samples without forgetting previous ones is a critical problem of continual learning. Currently proposed methods achieve this goal by extending the existing model while constraining its behavior not to degrade on the past data, which does not exploit the full potential of relations within the entire training dataset. In this work, we identify this limitation and posit the goal of continual learning as a knowledge accumulation task. We solve it by continuously re-aligning latent space partitions that we call bands which are representations of samples seen in different tasks, driven by the similarity of the information they contain. In addition, we introduce a simple yet effective method for controlled forgetting of past data that improves the quality of reconstructions encoded in latent bands and a latent space disentanglement technique that improves knowledge consolidation. On top of the standard continual learning evaluation benchmarks, we evaluate our method on a new knowledge consolidation scenario and show that the proposed approach outperforms state-of-the-art by up to twofold across all testing scenarios.
Learning stochastic decision trees
May 08, 2021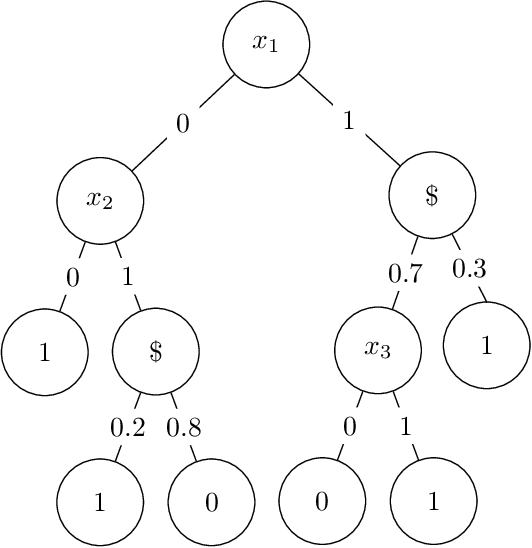
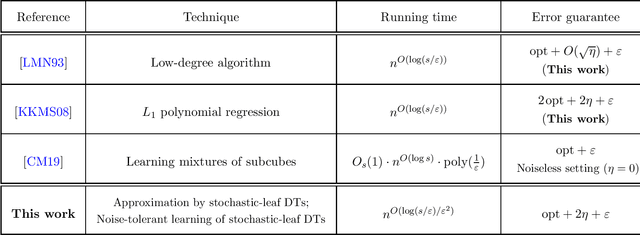

We give a quasipolynomial-time algorithm for learning stochastic decision trees that is optimally resilient to adversarial noise. Given an $\eta$-corrupted set of uniform random samples labeled by a size-$s$ stochastic decision tree, our algorithm runs in time $n^{O(\log(s/\varepsilon)/\varepsilon^2)}$ and returns a hypothesis with error within an additive $2\eta + \varepsilon$ of the Bayes optimal. An additive $2\eta$ is the information-theoretic minimum. Previously no non-trivial algorithm with a guarantee of $O(\eta) + \varepsilon$ was known, even for weaker noise models. Our algorithm is furthermore proper, returning a hypothesis that is itself a decision tree; previously no such algorithm was known even in the noiseless setting.
BraidNet: procedural generation of neural networks for image classification problems using braid theory
Apr 20, 2021
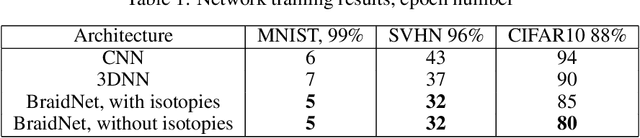
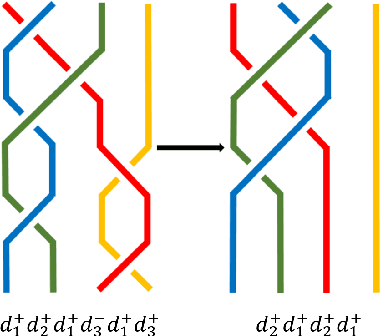
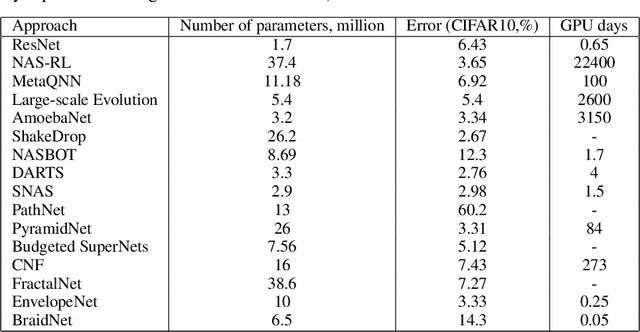
In this article, we propose the approach to procedural optimization of a neural network, based on the combination of information theory and braid theory. The network studied in the article implemented with the intersections between the braid strands, as well as simplified networks (a network with strands without intersections and a simple convolutional deep neural network), are used to solve various problems of multiclass image classification that allow us to analyze the comparative effectiveness of the proposed architecture. The simulation results showed BraidNet's comparative advantage in learning speed and classification accuracy.
Maximizing Marginal Fairness for Dynamic Learning to Rank
Feb 18, 2021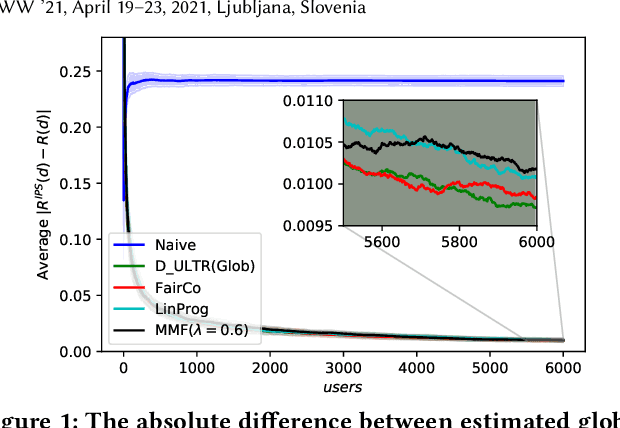
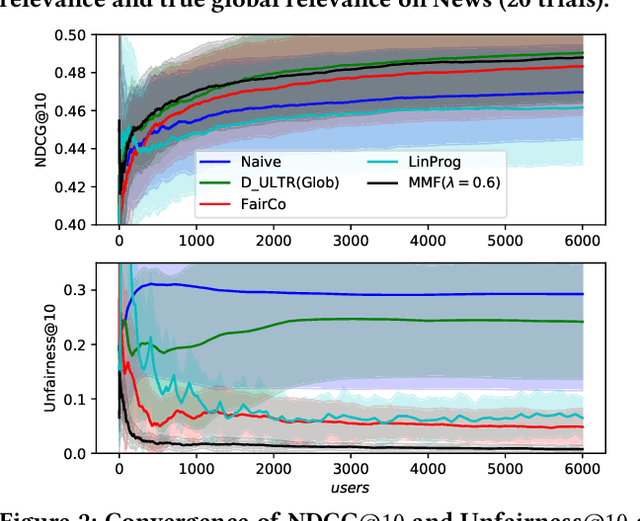
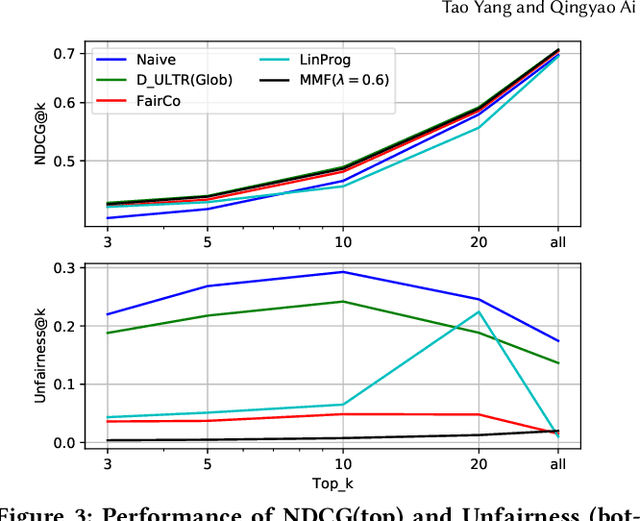
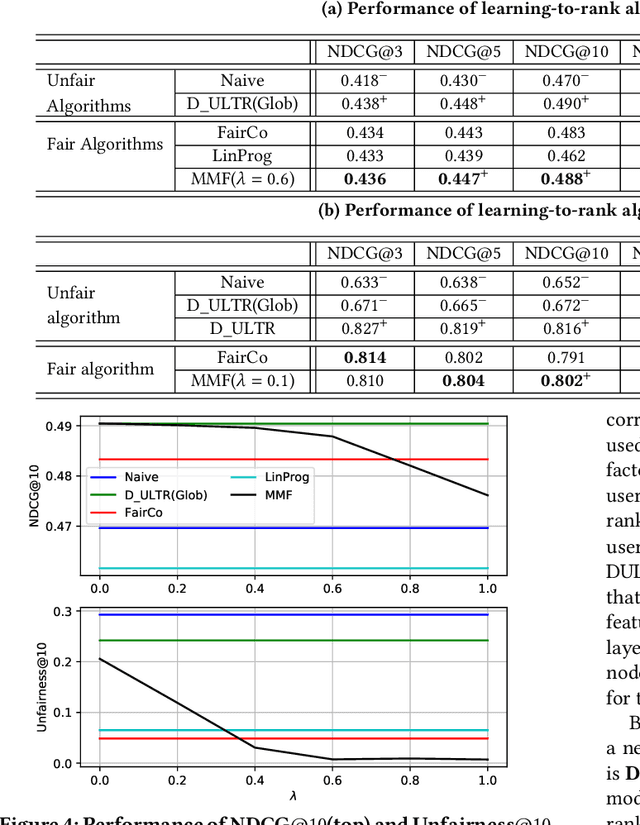
Rankings, especially those in search and recommendation systems, often determine how people access information and how information is exposed to people. Therefore, how to balance the relevance and fairness of information exposure is considered as one of the key problems for modern IR systems. As conventional ranking frameworks that myopically sorts documents with their relevance will inevitably introduce unfair result exposure, recent studies on ranking fairness mostly focus on dynamic ranking paradigms where result rankings can be adapted in real-time to support fairness in groups (i.e., races, genders, etc.). Existing studies on fairness in dynamic learning to rank, however, often achieve the overall fairness of document exposure in ranked lists by significantly sacrificing the performance of result relevance and fairness on the top results. To address this problem, we propose a fair and unbiased ranking method named Maximal Marginal Fairness (MMF). The algorithm integrates unbiased estimators for both relevance and merit-based fairness while providing an explicit controller that balances the selection of documents to maximize the marginal relevance and fairness in top-k results. Theoretical and empirical analysis shows that, with small compromises on long list fairness, our method achieves superior efficiency and effectiveness comparing to the state-of-the-art algorithms in both relevance and fairness for top-k rankings.
Collection and harmonization of system logs and prototypal Analytics services with the Elastic (ELK) suite at the INFN-CNAF computing centre
May 13, 2021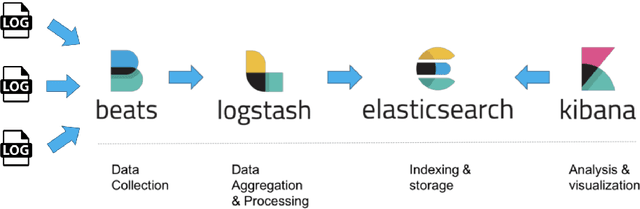
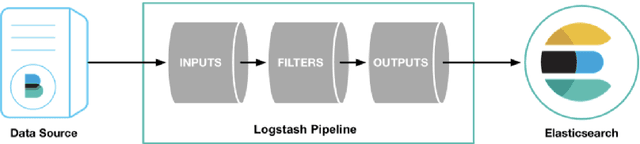
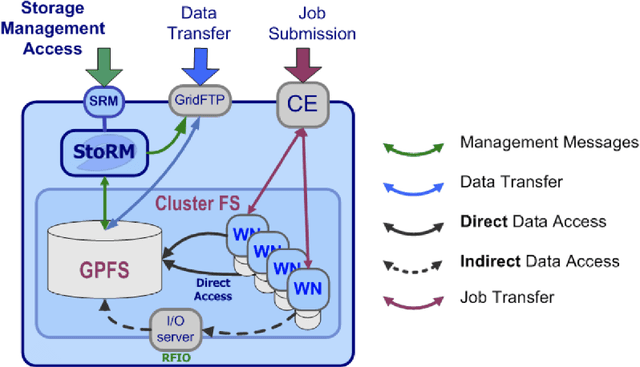
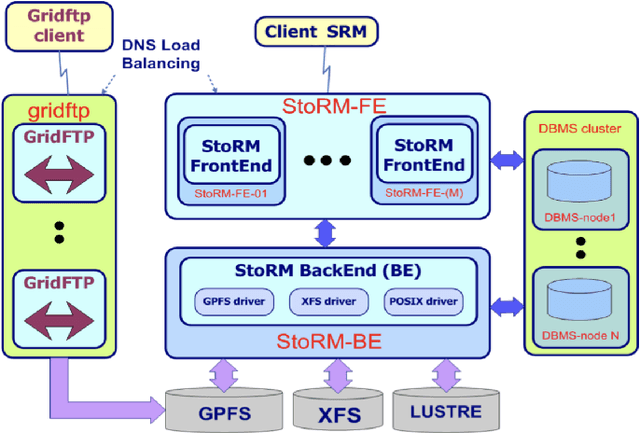
The distributed Grid infrastructure for High Energy Physics experiments at the Large Hadron Collider (LHC) in Geneva comprises a set of computing centres, spread all over the world, as part of the Worldwide LHC Computing Grid (WLCG). In Italy, the Tier-1 functionalities are served by the INFN-CNAF data center, which provides also computing and storage resources to more than twenty non-LHC experiments. For this reason, a high amount of logs are collected each day from various sources, which are highly heterogeneous and difficult to harmonize. In this contribution, a working implementation of a system that collects, parses and displays the log information from CNAF data sources and the investigation of a Machine Learning based predictive maintenance system, is presented.
* Submitted to proceedings of International Symposium on Grids & Clouds 2019 (ISGC2019)
Change Detection from SAR Images Based on Deformable Residual Convolutional Neural Networks
Apr 06, 2021

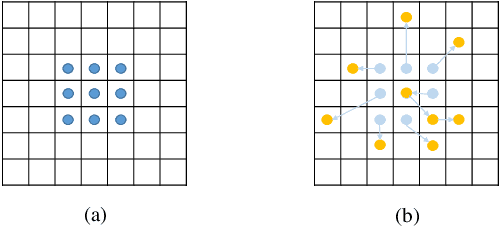
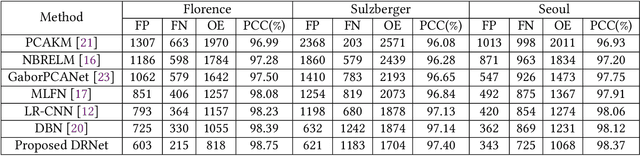
Convolutional neural networks (CNN) have made great progress for synthetic aperture radar (SAR) images change detection. However, sampling locations of traditional convolutional kernels are fixed and cannot be changed according to the actual structure of the SAR images. Besides, objects may appear with different sizes in natural scenes, which requires the network to have stronger multi-scale representation ability. In this paper, a novel \underline{D}eformable \underline{R}esidual Convolutional Neural \underline{N}etwork (DRNet) is designed for SAR images change detection. First, the proposed DRNet introduces the deformable convolutional sampling locations, and the shape of convolutional kernel can be adaptively adjusted according to the actual structure of ground objects. To create the deformable sampling locations, 2-D offsets are calculated for each pixel according to the spatial information of the input images. Then the sampling location of pixels can adaptively reflect the spatial structure of the input images. Moreover, we proposed a novel pooling module replacing the vanilla pooling to utilize multi-scale information effectively, by constructing hierarchical residual-like connections within one pooling layer, which improve the multi-scale representation ability at a granular level. Experimental results on three real SAR datasets demonstrate the effectiveness of the proposed DRNet.
Learning-Based Practical Light Field Image Compression Using A Disparity-Aware Model
Jun 23, 2021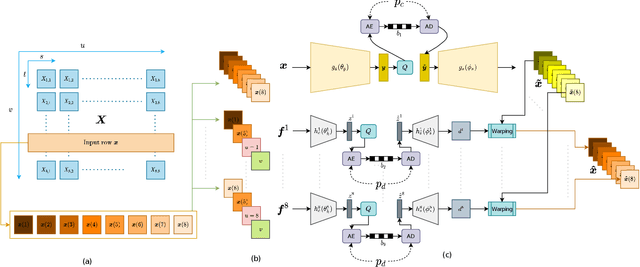
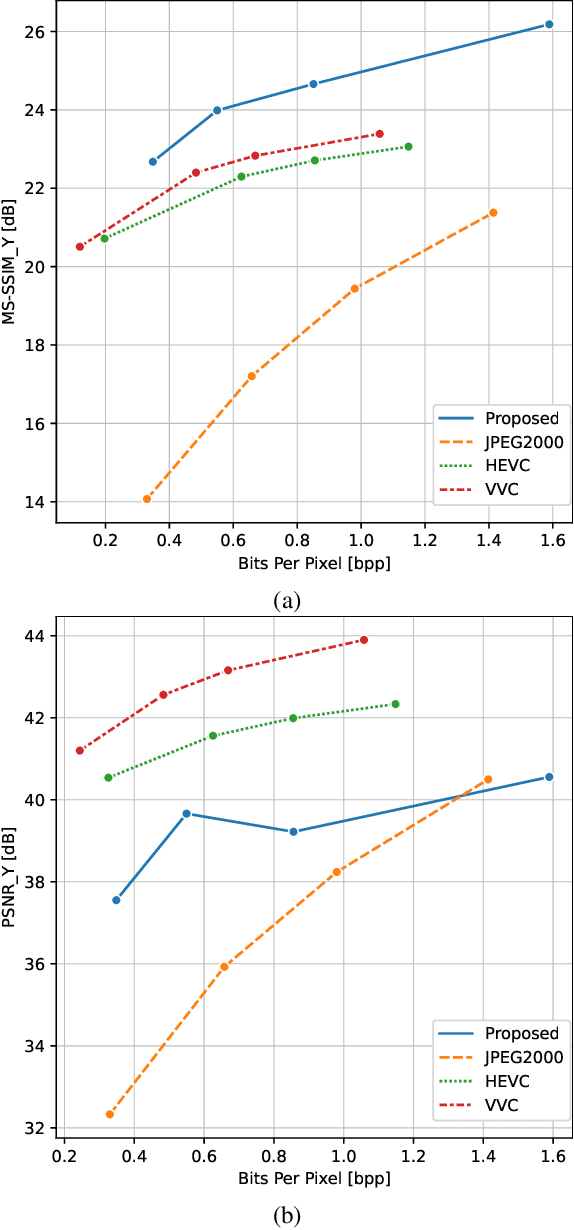

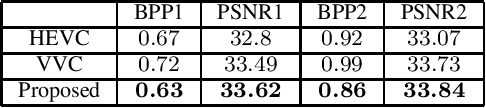
Light field technology has increasingly attracted the attention of the research community with its many possible applications. The lenslet array in commercial plenoptic cameras helps capture both the spatial and angular information of light rays in a single exposure. While the resulting high dimensionality of light field data enables its superior capabilities, it also impedes its extensive adoption. Hence, there is a compelling need for efficient compression of light field images. Existing solutions are commonly composed of several separate modules, some of which may not have been designed for the specific structure and quality of light field data. This increases the complexity of the codec and results in impractical decoding runtimes. We propose a new learning-based, disparity-aided model for compression of 4D light field images capable of parallel decoding. The model is end-to-end trainable, eliminating the need for hand-tuning separate modules and allowing joint learning of rate and distortion. The disparity-aided approach ensures the structural integrity of the reconstructed light fields. Comparisons with the state of the art show encouraging performance in terms of PSNR and MS-SSIM metrics. Also, there is a notable gain in the encoding and decoding runtimes. Source code is available at https://moha23.github.io/LF-DAAE.