 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How Well do Feature Visualizations Support Causal Understanding of CNN Activations?
Jun 23, 2021
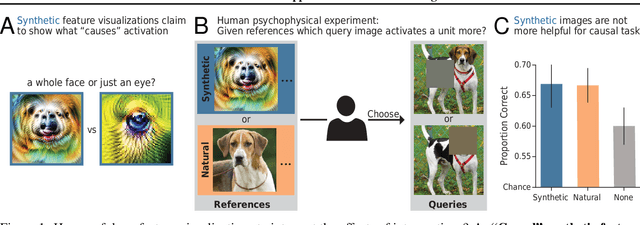

One widely used approach towards understanding the inner workings of deep convolutional neural networks is to visualize unit responses via activation maximization. Feature visualizations via activation maximization are thought to provide humans with precise information about the image features that cause a unit to be activated. If this is indeed true, these synthetic images should enable humans to predict the effect of an intervention, such as whether occluding a certain patch of the image (say, a dog's head) changes a unit's activation. Here, we test this hypothesis by asking humans to predict which of two square occlusions causes a larger change to a unit's activation. Both a large-scale crowdsourced experiment and measurements with experts show that on average, the extremely activating feature visualizations by Olah et al. (2017) indeed help humans on this task ($67 \pm 4\%$ accuracy; baseline performance without any visualizations is $60 \pm 3\%$). However, they do not provide any significant advantage over other visualizations (such as e.g. dataset samples), which yield similar performance ($66 \pm 3\%$ to $67 \pm 3\%$ accuracy). Taken together, we propose an objective psychophysical task to quantify the benefit of unit-level interpretability methods for humans, and find no evidence that feature visualizations provide humans with better "causal understanding" than simple alternative visualizations.
An Information-theoretic Framework for the Lossy Compression of Link Streams
Jul 18, 2018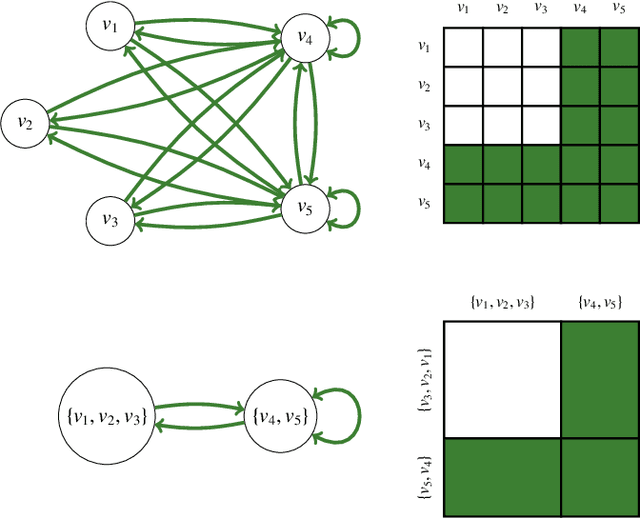

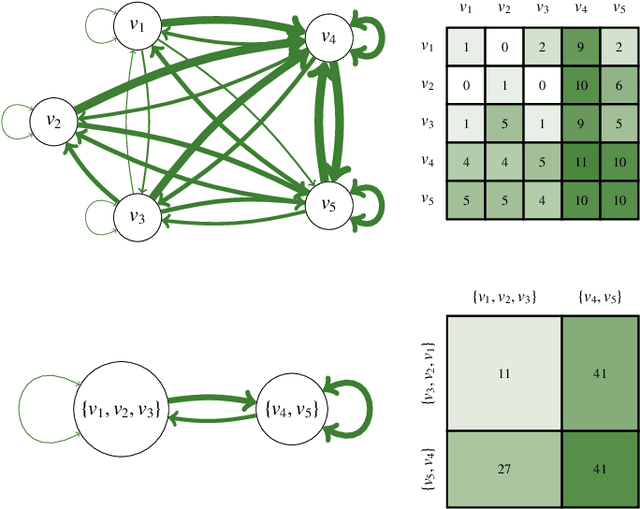
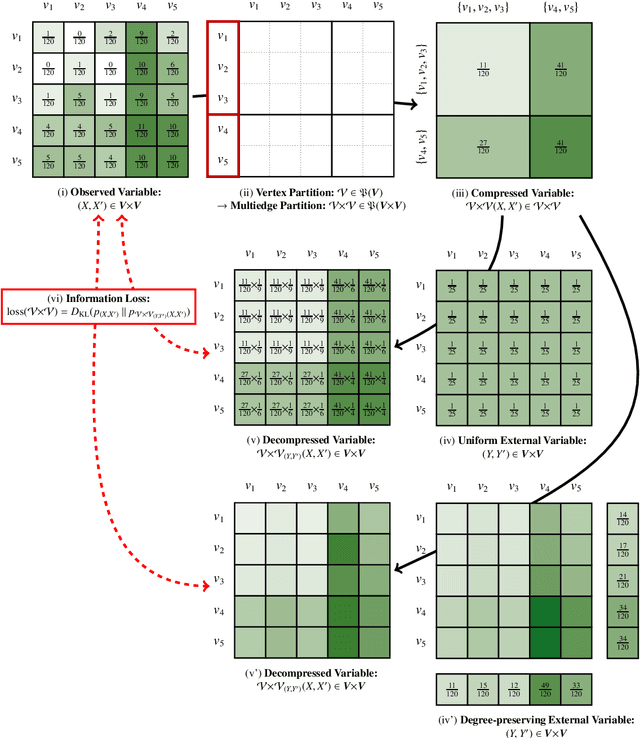
Graph compression is a data analysis technique that consists in the replacement of parts of a graph by more general structural patterns in order to reduce its description length. It notably provides interesting exploration tools for the study of real, large-scale, and complex graphs which cannot be grasped at first glance. This article proposes a framework for the compression of temporal graphs, that is for the compression of graphs that evolve with time. This framework first builds on a simple and limited scheme, exploiting structural equivalence for the lossless compression of static graphs, then generalises it to the lossy compression of link streams, a recent formalism for the study of temporal graphs. Such generalisation relies on the natural extension of (bidimensional) relational data by the addition of a third temporal dimension. Moreover, we introduce an information-theoretic measure to quantify and to control the information that is lost during compression, as well as an algebraic characterisation of the space of possible compression patterns to enhance the expressiveness of the initial compression scheme. These contributions lead to the definition of a combinatorial optimisation problem, that is the Lossy Multistream Compression Problem, for which we provide an exact algorithm.
Max-Information, Differential Privacy, and Post-Selection Hypothesis Testing
Sep 09, 2016In this paper, we initiate a principled study of how the generalization properties of approximate differential privacy can be used to perform adaptive hypothesis testing, while giving statistically valid $p$-value corrections. We do this by observing that the guarantees of algorithms with bounded approximate max-information are sufficient to correct the $p$-values of adaptively chosen hypotheses, and then by proving that algorithms that satisfy $(\epsilon,\delta)$-differential privacy have bounded approximate max information when their inputs are drawn from a product distribution. This substantially extends the known connection between differential privacy and max-information, which previously was only known to hold for (pure) $(\epsilon,0)$-differential privacy. It also extends our understanding of max-information as a partially unifying measure controlling the generalization properties of adaptive data analyses. We also show a lower bound, proving that (despite the strong composition properties of max-information), when data is drawn from a product distribution, $(\epsilon,\delta)$-differentially private algorithms can come first in a composition with other algorithms satisfying max-information bounds, but not necessarily second if the composition is required to itself satisfy a nontrivial max-information bound. This, in particular, implies that the connection between $(\epsilon,\delta)$-differential privacy and max-information holds only for inputs drawn from product distributions, unlike the connection between $(\epsilon,0)$-differential privacy and max-information.
Initialization Matters: Regularizing Manifold-informed Initialization for Neural Recommendation Systems
Jun 09, 2021

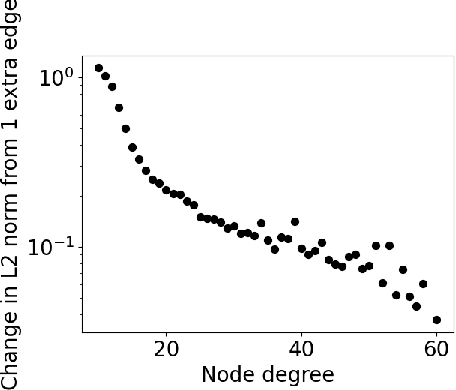
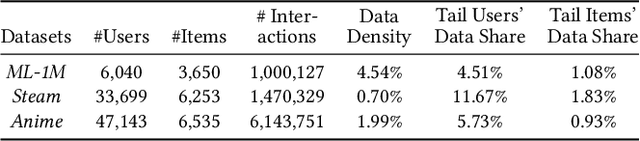
Proper initialization is crucial to the optimization and the generalization of neural networks. However, most existing neural recommendation systems initialize the user and item embeddings randomly. In this work, we propose a new initialization scheme for user and item embeddings called Laplacian Eigenmaps with Popularity-based Regularization for Isolated Data (LEPORID). LEPORID endows the embeddings with information regarding multi-scale neighborhood structures on the data manifold and performs adaptive regularization to compensate for high embedding variance on the tail of the data distribution. Exploiting matrix sparsity, LEPORID embeddings can be computed efficiently. We evaluate LEPORID in a wide range of neural recommendation models. In contrast to the recent surprising finding that the simple K-nearest-neighbor (KNN) method often outperforms neural recommendation systems, we show that existing neural systems initialized with LEPORID often perform on par or better than KNN. To maximize the effects of the initialization, we propose the Dual-Loss Residual Recommendation (DLR2) network, which, when initialized with LEPORID, substantially outperforms both traditional and state-of-the-art neural recommender systems.
Impacts of the Numbers of Colors and Shapes on Outlier Detection: from Automated to User Evaluation
Mar 10, 2021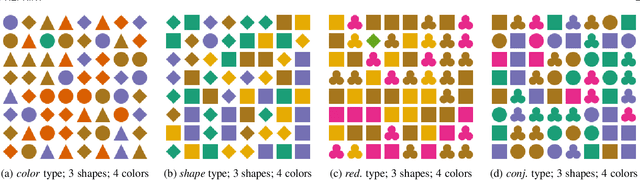
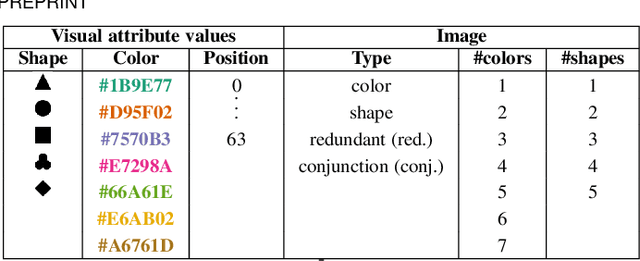
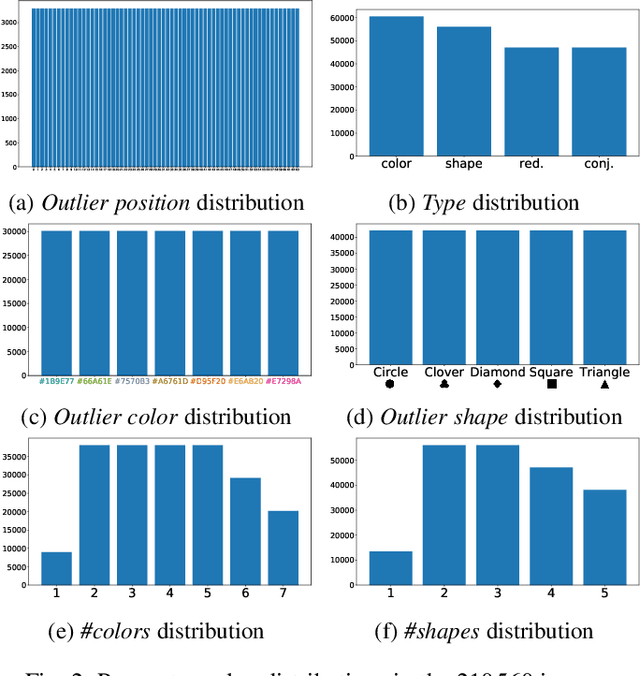
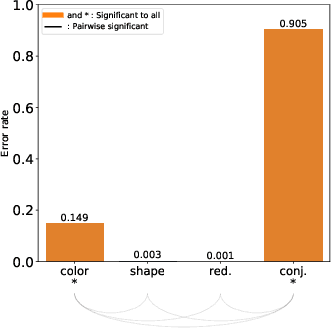
The design of efficient representations is well established as a fruitful way to explore and analyze complex or large data. In these representations, data are encoded with various visual attributes depending on the needs of the representation itself. To make coherent design choices about visual attributes, the visual search field proposes guidelines based on the human brain perception of features. However, information visualization representations frequently need to depict more data than the amount these guidelines have been validated on. Since, the information visualization community has extended these guidelines to a wider parameter space. This paper contributes to this theme by extending visual search theories to an information visualization context. We consider a visual search task where subjects are asked to find an unknown outlier in a grid of randomly laid out distractor. Stimuli are defined by color and shape features for the purpose of visually encoding categorical data. The experimental protocol is made of a parameters space reduction step (i.e., sub-sampling) based on a machine learning model, and a user evaluation to measure capacity limits and validate hypotheses. The results show that the major difficulty factor is the number of visual attributes that are used to encode the outlier. When redundantly encoded, the display heterogeneity has no effect on the task. When encoded with one attribute, the difficulty depends on that attribute heterogeneity until its capacity limit (7 for color, 5 for shape) is reached. Finally, when encoded with two attributes simultaneously, performances drop drastically even with minor heterogeneity.
Represent Items by Items: An Enhanced Representation of the Target Item for Recommendation
Apr 26, 2021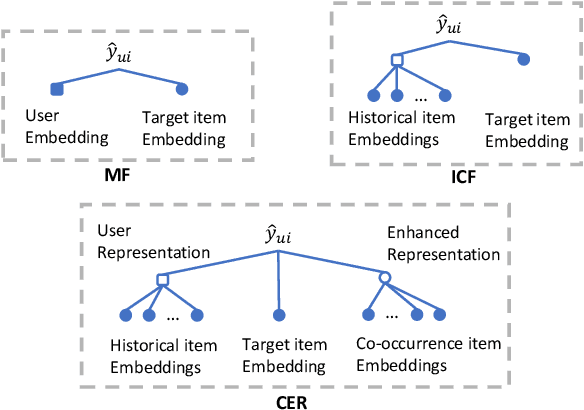

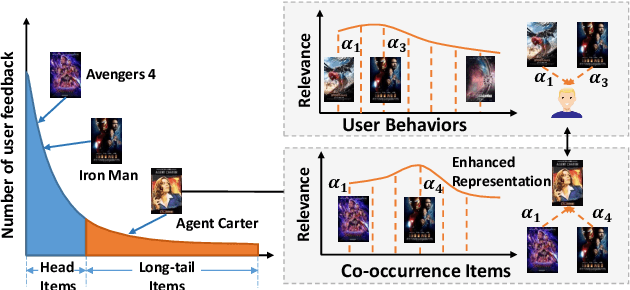
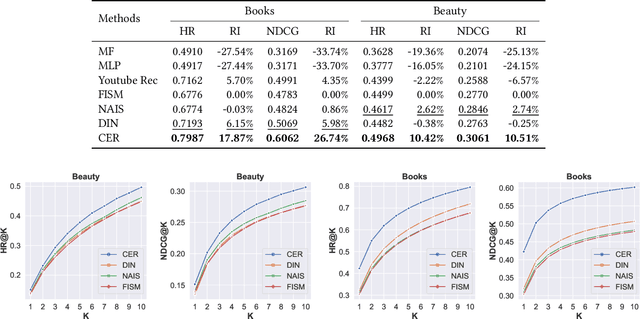
Item-based collaborative filtering (ICF) has been widely used in industrial applications such as recommender system and online advertising. It models users' preference on target items by the items they have interacted with. Recent models use methods such as attention mechanism and deep neural network to learn the user representation and scoring function more accurately. However, despite their effectiveness, such models still overlook a problem that performance of ICF methods heavily depends on the quality of item representation especially the target item representation. In fact, due to the long-tail distribution in the recommendation, most item embeddings can not represent the semantics of items accurately and thus degrade the performance of current ICF methods. In this paper, we propose an enhanced representation of the target item which distills relevant information from the co-occurrence items. We design sampling strategies to sample fix number of co-occurrence items for the sake of noise reduction and computational cost. Considering the different importance of sampled items to the target item, we apply attention mechanism to selectively adopt the semantic information of the sampled items. Our proposed Co-occurrence based Enhanced Representation model (CER) learns the scoring function by a deep neural network with the attentive user representation and fusion of raw representation and enhanced representation of target item as input. With the enhanced representation, CER has stronger representation power for the tail items compared to the state-of-the-art ICF methods. Extensive experiments on two public benchmarks demonstrate the effectiveness of CER.
Reinforce Security: A Model-Free Approach Towards Secure Wiretap Coding
Jun 01, 2021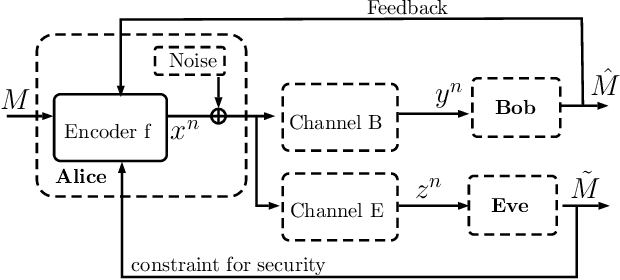
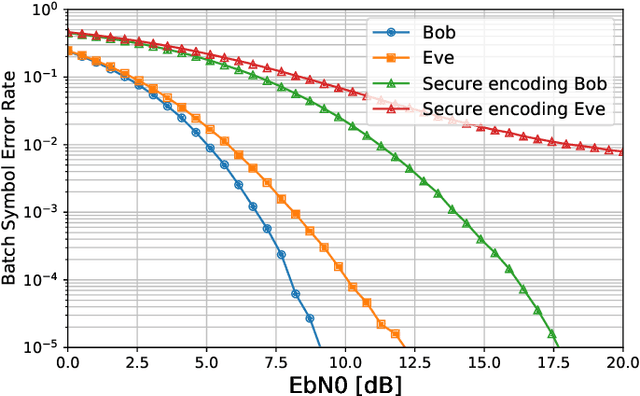
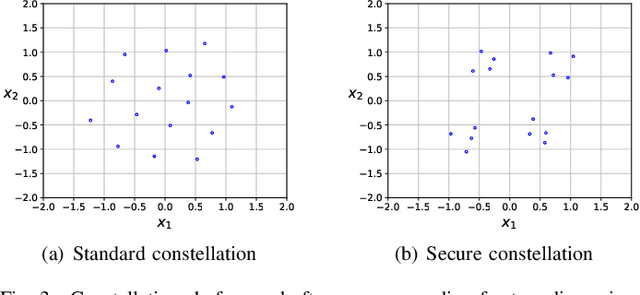
The use of deep learning-based techniques for approximating secure encoding functions has attracted considerable interest in wireless communications due to impressive results obtained for general coding and decoding tasks for wireless communication systems. Of particular importance is the development of model-free techniques that work without knowledge about the underlying channel. Such techniques utilize for example generative adversarial networks to estimate and model the conditional channel distribution, mutual information estimation as a reward function, or reinforcement learning. In this paper, the approach of reinforcement learning is studied and, in particular, the policy gradient method for a model-free approach of neural network-based secure encoding is investigated. Previously developed techniques for enforcing a certain co-set structure on the encoding process can be combined with recent reinforcement learning approaches. This new approach is evaluated by extensive simulations, and it is demonstrated that the resulting decoding performance of an eavesdropper is capped at a certain error level.
NLP is Not enough -- Contextualization of User Input in Chatbots
May 13, 2021AI chatbots have made vast strides in technology improvement in recent years and are already operational in many industries. Advanced Natural Language Processing techniques, based on deep networks, efficiently process user requests to carry out their functions. As chatbots gain traction, their applicability in healthcare is an attractive proposition due to the reduced economic and people costs of an overburdened system. However, healthcare bots require safe and medically accurate information capture, which deep networks aren't yet capable of due to user text and speech variations. Knowledge in symbolic structures is more suited for accurate reasoning but cannot handle natural language processing directly. Thus, in this paper, we study the effects of combining knowledge and neural representations on chatbot safety, accuracy, and understanding.
Separated-Spectral-Distribution Estimation Based on Bayesian Inference with Single RGB Camera
Jun 01, 2021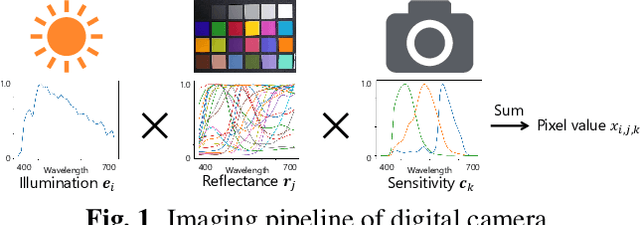
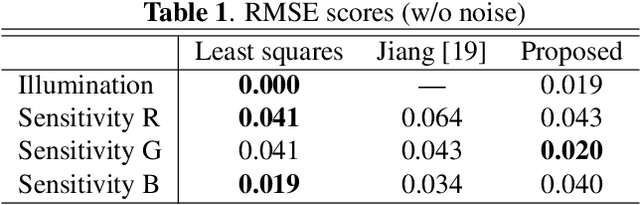
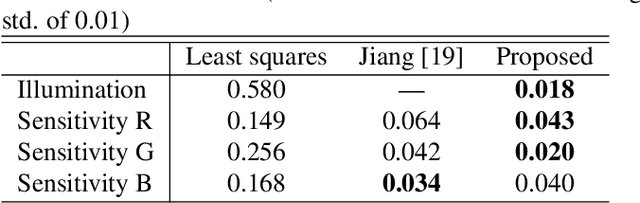
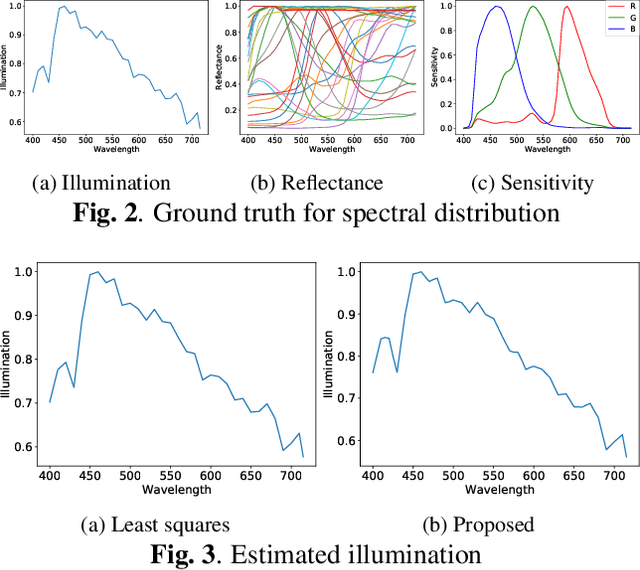
In this paper, we propose a novel method for separately estimating spectral distributions from images captured by a typical RGB camera. The proposed method allows us to separately estimate a spectral distribution of illumination, reflectance, or camera sensitivity, while recent hyperspectral cameras are limited to capturing a joint spectral distribution from a scene. In addition, the use of Bayesian inference makes it possible to take into account prior information of both spectral distributions and image noise as probability distributions. As a result, the proposed method can estimate spectral distributions in a unified way, and it can enhance the robustness of the estimation against noise, which conventional spectral-distribution estimation methods cannot. The use of Bayesian inference also enables us to obtain the confidence of estimation results. In an experiment, the proposed method is shown not only to outperform conventional estimation methods in terms of RMSE but also to be robust against noise.
Self-supervision of Feature Transformation for Further Improving Supervised Learning
Jun 09, 2021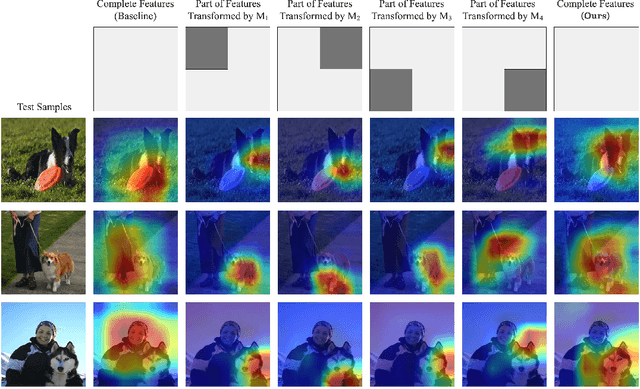

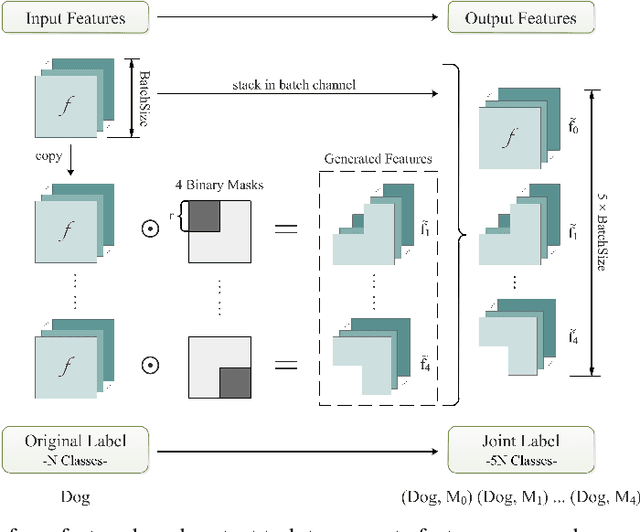

Self-supervised learning, which benefits from automatically constructing labels through pre-designed pretext task, has recently been applied for strengthen supervised learning. Since previous self-supervised pretext tasks are based on input, they may incur huge additional training overhead. In this paper we find that features in CNNs can be also used for self-supervision. Thus we creatively design the \emph{feature-based pretext task} which requires only a small amount of additional training overhead. In our task we discard different particular regions of features, and then train the model to distinguish these different features. In order to fully apply our feature-based pretext task in supervised learning, we also propose a novel learning framework containing multi-classifiers for further improvement. Original labels will be expanded to joint labels via self-supervision of feature transformations. With more semantic information provided by our self-supervised tasks, this approach can train CNNs more effectively. Extensive experiments on various supervised learning tasks demonstrate the accuracy improvement and wide applicability of our method.